一、初识Redis
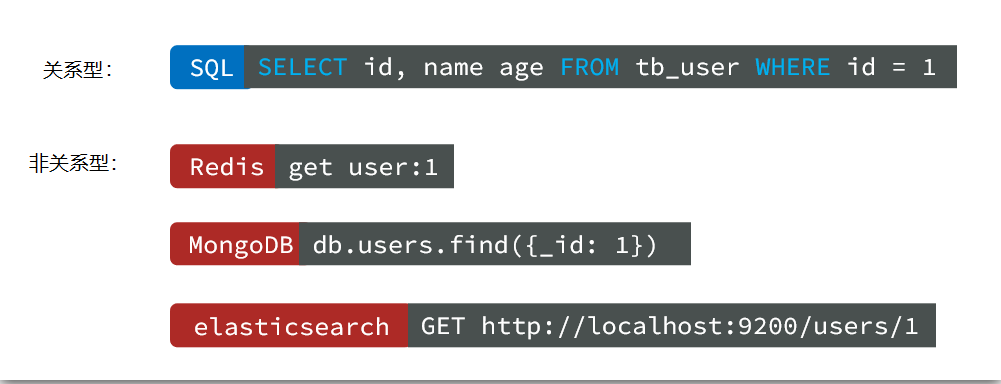
Redis是一种键值型的NoSql数据库,这里有两个关键字:
-
键值型
-
NoSql
其中键值型 ,是指Redis中存储的数据都是以key、value对的形式存储,而value的形式多种多样,可以是字符串、数值、甚至json: 
1.认识NoSql
NoSql 可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
1.1结构化与非结构化
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束等等信息,插入的数据必须遵守这些约束:
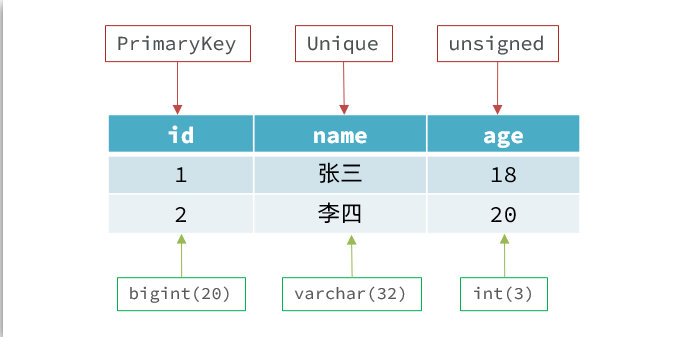
而NoSql则对数据库格式没有严格约束,往往形式松散,自由。
可以是键值型:

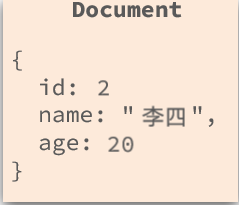
也可以是文档型:
还可以是图形:
1.2.关联和非关联
传统数据库的表与表之间往往存在关联,例如外键:
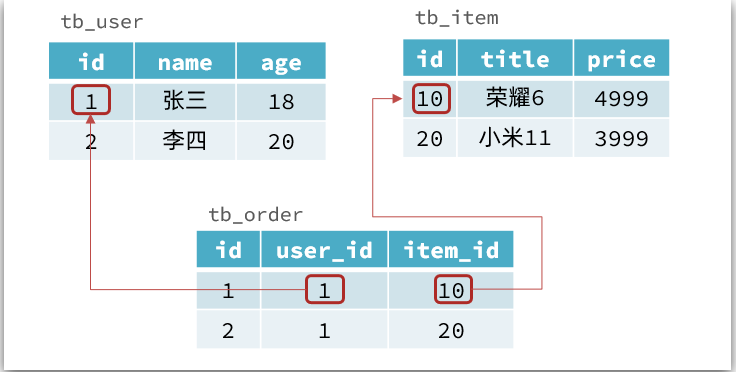
而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
此处要维护"张三"的订单与商品"荣耀"和"小米11"的关系,不得不冗余的将这两个商品保存在张三的订单文档中,不够优雅。还是建议用业务来维护关联关系。
java
{
id: 1,
name: "张三",
orders: [
{
id: 1,
item: {
id: 10, title: "荣耀6", price: 4999
}
},
{
id: 2,
item: {
id: 20, title: "小米11", price: 3999
}
}
]
}1.3.查询方式
传统关系型数据库会基于Sql语句做查询,语法有统一标准;
而不同的非关系数据库查询语法差异极大,五花八门各种各样。
1.4.事务
传统关系型数据库能满足事务ACID的原则。
- 原子性 :Redis 事务通过
MULTI(开启)、EXEC(执行)、DISCARD(取消)实现,命令会入队批量执行 ,但执行中若部分命令失败,不会自动回滚已成功的命令(仅跳过失败命令,继续执行后续),严格来说不满足完整原子性;- 一致性 :Redis 可保证事务执行前后数据合法,若事务执行失败(如
DISCARD取消),数据会恢复到事务前状态,满足一致性;- 隔离性 :Redis 事务是单线程执行 ,
EXEC执行时会独占线程,事务内的命令连续执行,不会被其他命令插入,天然满足最高隔离级别(串行化);- 持久性:依赖 Redis 的持久化机制(RDB 快照、AOF 日志)。若开启持久化,事务提交后数据会持久化到磁盘,满足持久性;若未开启,事务结果仅存内存,系统崩溃会丢失,不满足持久性。
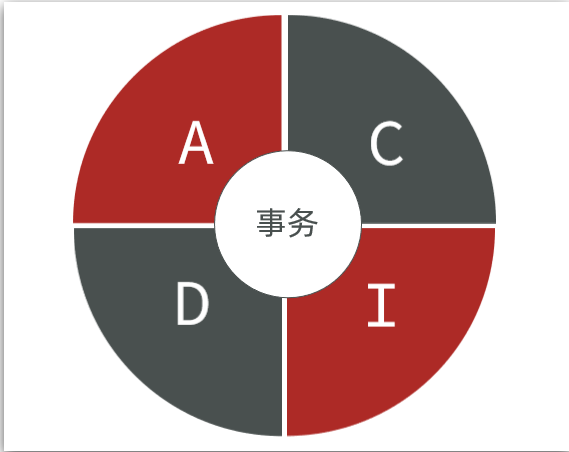
而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
1.5总结
除了上述四点以外,在存储方式、扩展性、查询性能上关系型与非关系型也都有着显著差异,总结如下:
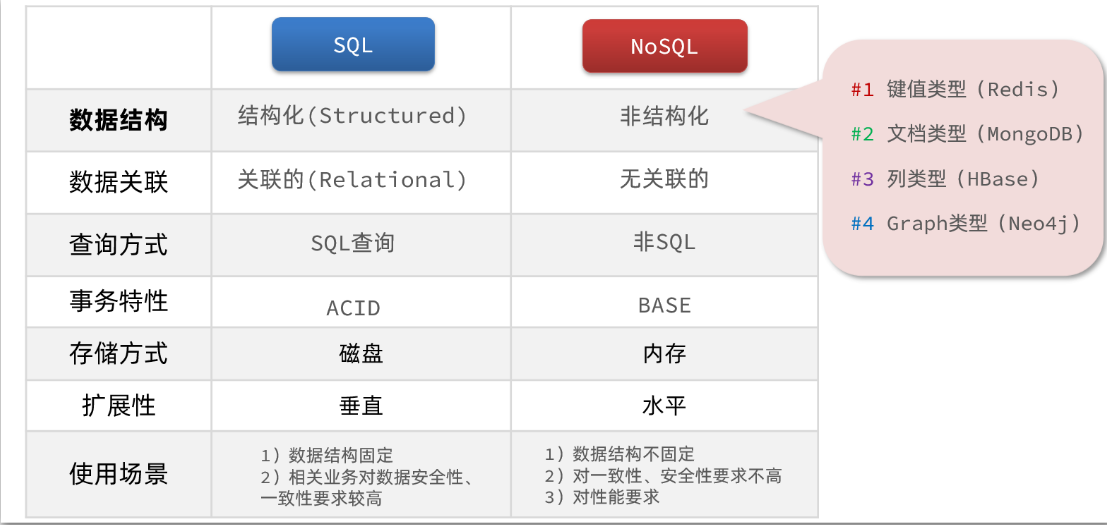
存储方式
关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快性能自然会好一些
扩展性
关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
2.认识Redis
Redis诞生于2009年全称是Re mote D ictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
-
键值(key-value)型,value支持多种不同数据结构,功能丰富
-
单线程,每个命令具备原子性
-
低延迟,速度快(基于内存、IO多路复用、良好的编码)。
-
支持数据持久化
-
支持主从集群、分片集群
-
支持多语言客户端
主从集群是为了不宕机、数据不丢 ,数据全量复制,所有节点存的都是完整数据,**不能扩容存储,只能分担读压力,也就是子节点能够备份父节点数据。**若父节点数据出了问题,可以从子节点的获取
分片集群是为了存更多数据、扛更大并发 ,数据分散存储,同时自带主从备份,既扩容又高可用,是大规模场景的首选,比如一T的数据分给不同电脑存
| 类型 | 核心作用 | 数据存储 | 解决问题 |
|---|---|---|---|
| 主从集群 | 高可用(不宕机) | 所有节点存完整数据 | 怕服务挂、怕数据丢,分担读压力 |
| 分片集群 | 扩容 + 高可用 | 数据拆分,各节点存部分 | 单机存不下、扛不住高并发读写 |
作者:Antirez
Redis的官方网站地址:https://redis.io/
3.安装Redis
(1)windos安装
安装中文版
https://github.com/tporadowski/redis/releases
下载后
在下载好的文件夹里cmd,运行
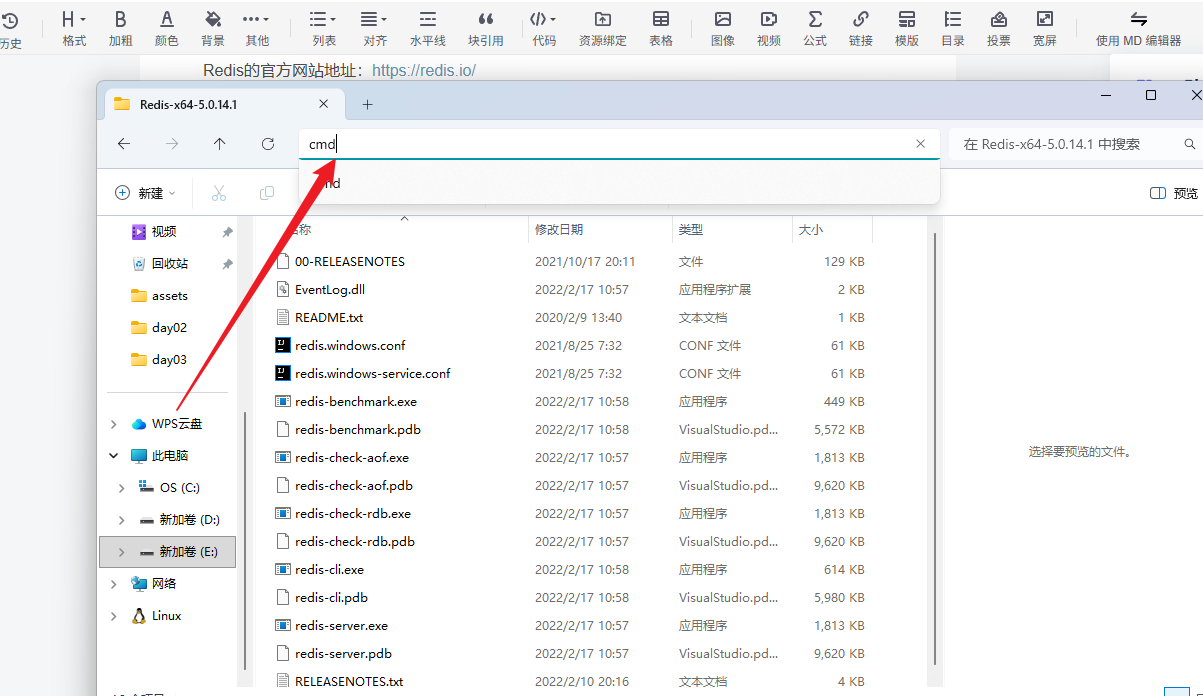
输入
redis-service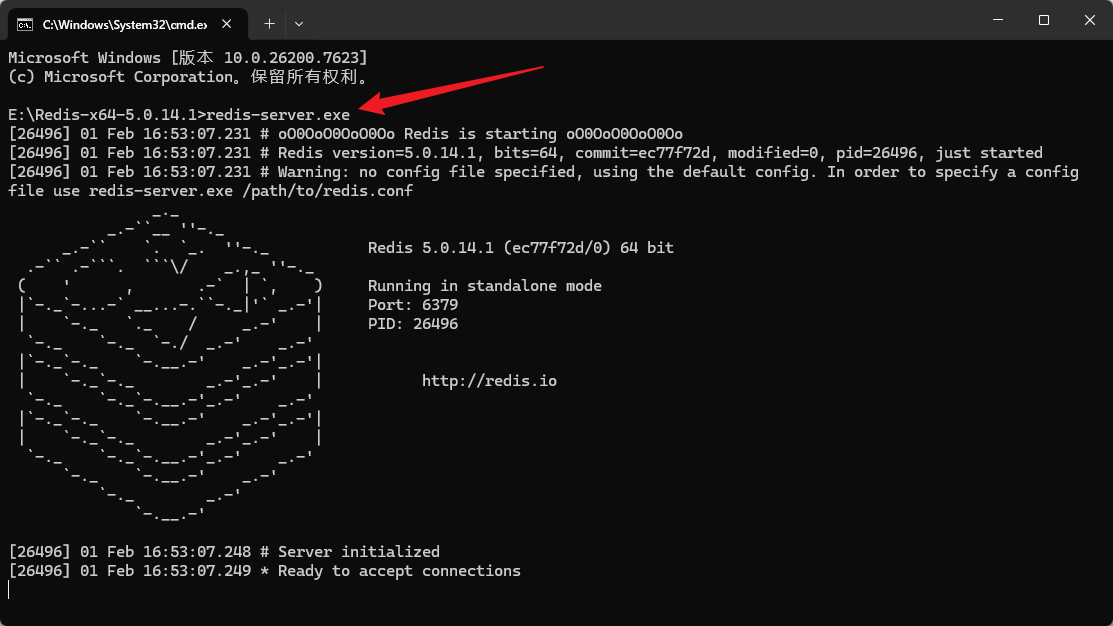
即可运行
(2)docker安装
首先先下载dockerdesk top
搜索镜像
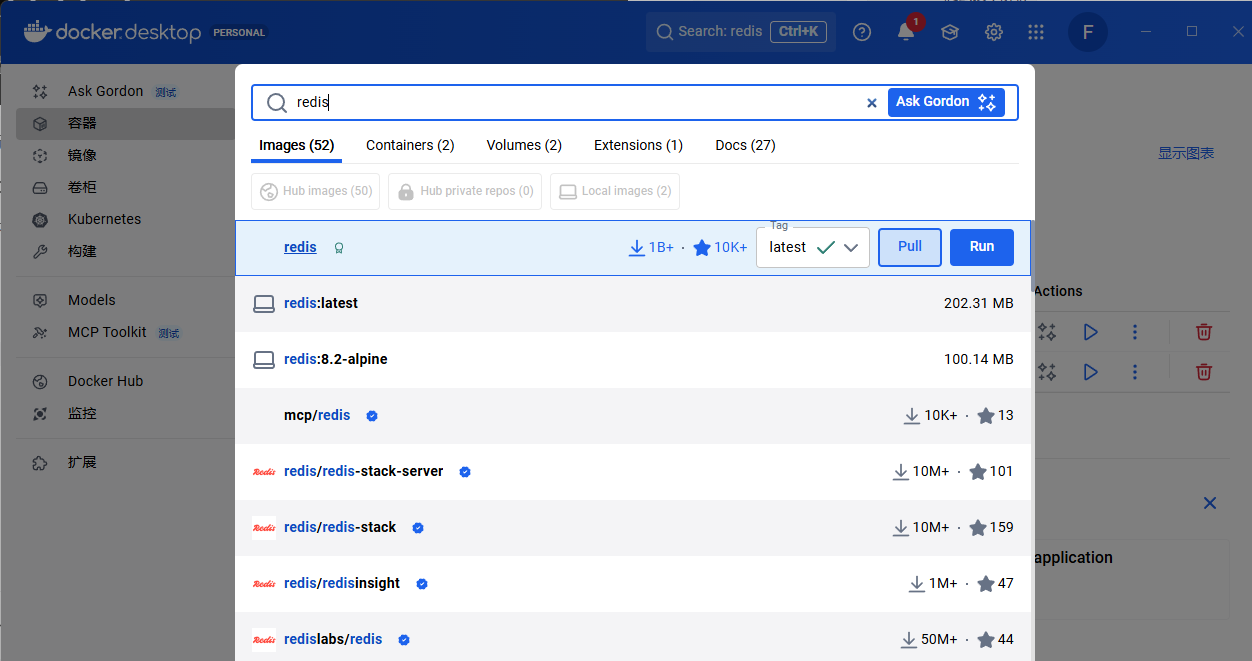
然后在镜像中找到下载的redis
run一下,设计参数
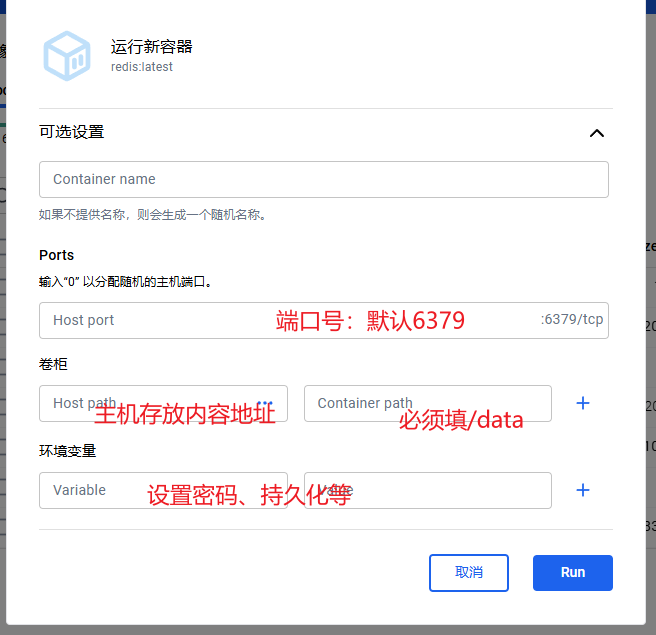
然后在容器里找到,启动即可
