搭建人工智能的大模型,属于一项系统工程,它涉及种种环节,像是数据准备,模型架构设计,训练优化以及部署应用等。从技术实施的角度去看,这一过程得综合考量算法创新,计算资源以及工程实践的平衡。
构建大模型所依据的基础能够归纳成三个关键要素,分别是,具备高水准的数据,拥有先进的算法,以及具备强健的算力。就数据而言,当下占据主流地位的大模型在开展训练时,一般都会需要达到万亿级别的文本token。举例来说,有一些公开的文献表明,GPT - 3进行训练所使用的数据涵盖了大概4990亿个token,这些数据取自 Crawl、、、以及等诸多语料库。这些数据,要历经严格的将其清洗,还要进行去重,更得予以过滤,把低质量的内容予以去除,把有害的信息也彻底消除掉,以此来保障训练数据的纯净程度以及多样性。
大模型搭建的技术关键在于模型架构设计,架构自2017年提出之后,成了大模型的主要选用架构,它基于自注意力机制,可有效应对长距离依赖关系,典型的模型涵盖编码器与解码器两部分,每一部分由多个一样的层堆叠起来形成。就拿GPT系列模型来说,其中GPT-3选用了纯解码器架构,它有着96层块,每一层的隐藏维度是12288,这个模型的注意力头数为96,况且其总参数量多达1750亿个。
在大模型搭建时,其中训练过程是最为耗费大量资源其中环节之一,训练一般情形下会被划分成为预训练以及微调这两个不同阶段,预训练阶段运用的乃是自监督学习方式,依靠预测文本里的下一时间将会出现的词来进行对于语言内在规律的学习,而这一整个过程是需要巨量计算资源予以支撑的,有相关研究表明,要是训练一个具备千亿参数规模的模型,在1024张A100 GPU上是需要进行连续不间断运行大约34天时间的,在训练的整个过程之中是需要采用混合精度训练、梯度累积,还有模型并行等多种不同优化技术,以此来提升训练的效率以及稳定性。
一种东西,叫做硬件配置,它是大模型搭建所需要的物质基础。当下主流的大模型训练,一般会使用GPU集群,每一张GPU,都得具备充足的内存容量,以此来存储模型参数以及中间状态。拿训练一个有着700亿参数的模型来说,要是采用FP16精度,仅仅是模型参数,就大概需要140GB显存,再加上优化器状态和梯度,总的显存需求,或许会超过420GB。所以,通常得有多张高端GPU借助互联,从而形成计算节点。八张显存八十GB的H100 GPU,可被配置于单个节点,借由达成高速互联,此互联所及带宽达九百GB每秒。
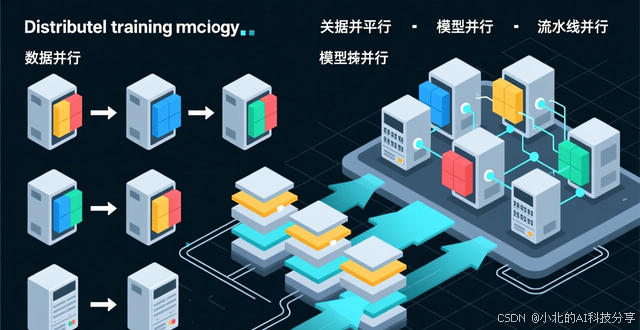
在分布式训练里头,数据并行与模型并行属于关键技术,数据并行会把训练数据划分成不同片,分到不一样的计算设备上,每个设备都持有完整的模型副本,各自独立计算梯度之后再去同步,模型并行是把模型参数拆分到多个设备上,这适用于单个设备没办法容纳整个模型的情形,流水线并行又将模型依照层分到不同设备,借助流水线的方式提升设备利用率,在实际开展部署的时候,这三种并行策略经常组合起来使用。
大模型搭建的最后阶段包含微调和推理优化,预训练完成之后,模型得借助指令微调、人类反馈强化学习等办法来对齐人类偏好,推理阶段还得考量延迟、吞吐量以及成本之间的平衡,量化技术能够把模型从FP16精度转变为INT8或INT4精度,在几乎不造成精度损失的状况下将模型大小缩减2至4倍,知识蒸馏技术则可把大模型的知识迁移至小模型内,从而降低部署成本。
计算成本高昂是大模型搭建面临的主要挑战之一,能源消耗巨大也是,面临的主要挑战之一还有数据需求庞大,技术复杂度高同样是主要挑战。为解决这些问题,业界正在探索多种技术路径。稀疏专家模型通过引入门控机制,每次推理时只激活部分参数。它可以在保持模型容量的情况下降低计算开销。有研究显示, 的参数量达到1.6万亿。但是每次推理激活的参数仅为1050亿。这显著降低了计算需求。
还有一个颇为关键的趋向是开源生态的进展,开源大模型像Llama系列、Qwen系列以及系列的现身,使技术门槛得到了降低,这些模型给出了完备的训练代码、数据配方以及评估基准,让更多的研究机构与企业能够投身到大模型开发之中,开源社区还奉献出了丰富的工具链,包含训练框架、评估工具和部署方案,构建成了完整的技术生态。
混合架构以及边缘计算同样堪称重要的发展趋向,于某些对延迟具备敏感特性或者对数据隐私有着严格要求的场景当中,能够于本地开展较小规模模型的部署工作,与此同时依据实际需求去调用云端的大模型,这般一种混合架构一方面能够确保响应的速度以及数据的安全,另一方面还能够借助云端模型所拥有的强大能力,本地部署一般而言需要将硬件选型、功耗控制以及散热设计等工程方面的问题纳入考量范围之内。

大模型搭建技术在未来会朝着愈发高效、愈发智能、愈发易用的趋向去发展,于模型架构层面,有可能会出现超越的全新架构,进而进一步提高计算效率以及表达能力,在训练方法上,持续学习、终身学习等技术能让模型持续不断地吸收新知识却不会遗忘旧知识,在硬件层面,专用AI芯片的发展会提供更高的能效比,同时,自动化机器学习技术将把模型设计以及调参过程予以简化,降低技术门槛。
从工程实践的角度去看,成功搭建大模型这件事,是需要跨学科团队协作的,这里面涵盖算法研究人员,还有数据工程师,以及系统架构师,另外还有领域专家。这个团队,是需要建立完善的开发流程的,这流程包括需求分析,还有方案设计,再就是实验验证,然后是性能评估,最后是持续迭代。文档编写以及知识管理,同样是至关重要的,要确保技术成果能够有效地积累以及传承。
大模型搭建可不是单一的技术挑战,还和伦理以及社会责任交织着,开发进程里要考量数据偏见、内容安全、隐私保护以及环境影响诸般问题,构建起负责任的AI开发框架,于技术创新之际保证契合伦理规范,这是行业能健康发展的必要前提条件,是不能忽视的重要因素,是有着关键意义的必要情形。
总体来讲,AI大模型搭建属于一个快速进步的技术范畴,它既要求有深厚的理论根基,又要求有丰富的工程阅历。伴随技术的进展以及生态的成熟,大模型开发会变得愈发普及,进而推动人工智能技术在各个行业里的深度运用。在这个过程当中,持续的技术革新、开放的协作生态以及负责任的发展观念将一同塑造人工智能的未来。