摘要:本文在 Decoder-only Transformer 架构的基础上,深入分析 DeepSeek LLM 的架构设计。内容包括:DeepSeek LLM 的整体架构定位、与 LLaMA 和标准 Transformer 的详细对比、关键架构改进(多步学习率调度器、深度优先设计、GQA 注意力机制)、架构参数配置(7B 和 67B)及其矩阵维度计算、以及架构设计的选择与权衡。旨在帮助读者理解 DeepSeek LLM 在架构层面的创新点与设计思路。
关键词:DeepSeek LLM;Decoder-only;LLaMA;多步学习率调度器;GQA;RMSNorm;SwiGLU;RoPE;大语言模型
💡 理解要点 :DeepSeek LLM 基于 LLaMA 的 Decoder-only 架构,在保持核心组件(RMSNorm、SwiGLU、RoPE)不变的基础上,通过多步学习率调度器 和深度优先的架构设计实现了关键改进,使其更适合持续训练和参数扩展。
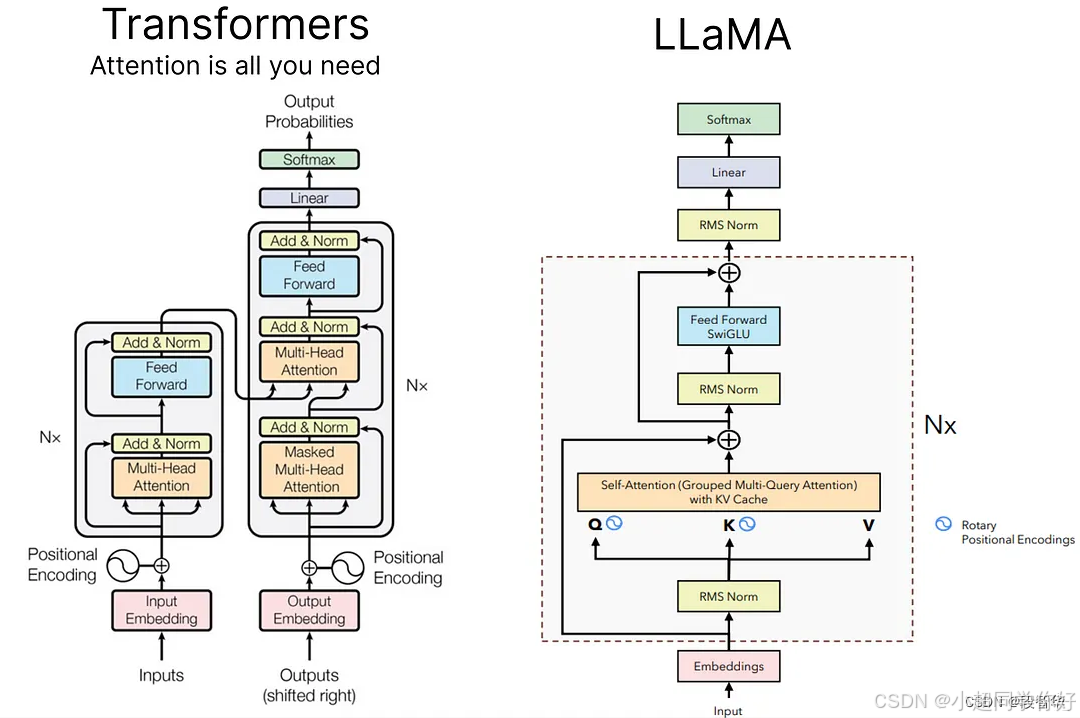
📊 架构图说明 :DeepSeek LLM 的架构图与标准 Decoder-only Transformer 相似,可参考 Decoder Only Transformer 架构图 中的图示。主要区别在于训练策略(学习率调度器)和参数分配(深度优先),而非架构组件的改变。如需查看论文中的详细架构图,请参考 DeepSeek LLM 论文。
1. 引言:DeepSeek LLM 的架构定位
DeepSeek LLM 是深度求索(DeepSeek)团队在 2024 年发布的开源大语言模型,采用了与 LLaMA 相似的 Decoder-only Transformer 架构。与许多开源模型直接复刻 LLaMA 不同,DeepSeek LLM 在架构层面做出了有针对性的改进,特别是在学习率调度策略 和模型深度设计上,体现了对长期训练和模型扩展的深入思考。
🔍 实际例子:想象一下,如果 LLaMA 是一辆经过验证的成熟车型,那么 DeepSeek LLM 就是在保持核心引擎(架构组件)不变的前提下,升级了导航系统(学习率调度器)和优化了车身结构(深度设计),使其更适合长途驾驶(持续训练)。
在深入分析之前,我们需要明确:DeepSeek LLM 的架构改进主要集中在训练策略 和参数分配上,而非 Transformer 核心组件的替换。这种"保守创新"的设计哲学,既保证了架构的稳定性,又通过关键改进实现了更好的训练效果。
2. 整体架构概览:Decoder-only 基础
DeepSeek LLM 采用 Decoder-only Transformer 架构,与 GPT、LLaMA、Qwen 等主流大语言模型保持一致。关于 Decoder-only 架构的详细原理,可参考 Decoder Only Transformer 架构以及每一步骤的详细计算;与 LLaMA 共享的组件(RMSNorm、SwiGLU、RoPE、Pre-Norm 等)及矩阵计算可参考 LLaMA 架构介绍以及与 Transformer 架构对比。
2.1 架构层次结构
DeepSeek LLM 的整体架构遵循标准的 Decoder-only 流程,其结构图与 Decoder Only Transformer 架构 中的图示基本一致:
数据流向:
输入文本
↓
Tokenization(文本 → Token ID 序列)
↓
Embedding(Token ID → 向量表示,$L \times d_{\text{model}}$)
↓
位置编码(RoPE,与 Embedding 融合)
↓
N 层 Decoder Layer(每层包含:掩码多头自注意力 + 前馈网络)
↓
输出层(线性层 + Softmax,预测下一个 token)🔍 实际例子 :以上流程图展示了 DeepSeek LLM 的完整数据流。对于 7B 模型, N = 30 N=30 N=30, d model = 4096 d_{\text{model}}=4096 dmodel=4096;对于 67B 模型, N = 95 N=95 N=95, d model = 8192 d_{\text{model}}=8192 dmodel=8192。每一层的详细计算过程可参考 Decoder Only Transformer 架构以及每一步骤的详细计算。
其中, L L L 为序列长度, d model d_{\text{model}} dmodel 为模型维度, N N N 为 Decoder 层数。
2.2 单层 Decoder 的核心组件
每一层 Decoder 包含以下组件(与 LLaMA 相同,详见 LLaMA 架构介绍):
-
带掩码的多头自注意力(Masked Multi-Head Attention)
- 7B 模型:使用标准 MHA(Multi-Head Attention)
- 67B 模型:使用 GQA(Grouped-Query Attention),减少 KV 缓存
-
前馈网络(FFN)
- 激活函数:SwiGLU
- 结构: d model → 4 ⋅ d model → d model d_{\text{model}} \to 4 \cdot d_{\text{model}} \to d_{\text{model}} dmodel→4⋅dmodel→dmodel
-
归一化与残差连接
- 归一化:RMSNorm(Root Mean Square Layer Normalization)
- 残差连接:Pre-Norm 结构(归一化在子层之前)
-
位置编码
- 方式:RoPE(Rotary Position Embedding)
💡 理解要点 :DeepSeek LLM 的架构基础与 LLaMA 高度一致,这保证了模型的稳定性和可复现性。真正的创新在于训练策略 和参数分配,而非架构组件的替换。
3. 与 LLaMA/标准 Transformer 的架构对比
虽然 DeepSeek LLM 在核心组件上与 LLaMA 保持一致,但在学习率调度器 和模型深度设计上有关键差异。下面我们详细对比这些差异。
3.1 学习率调度器:从余弦到多步
这是 DeepSeek LLM 最重要的架构层面改进(虽然严格来说属于训练策略,但直接影响模型架构的使用方式)。
3.1.1 标准做法:余弦学习率调度器
LLaMA 和大多数 Transformer 模型使用余弦学习率调度器(Cosine Learning Rate Scheduler),其数学表达式为:
LR ( t ) = LR min + ( LR max − LR min ) ⋅ 1 + cos ( π ⋅ t / T ) 2 \text{LR}(t) = \text{LR}{\text{min}} + (\text{LR}{\text{max}} - \text{LR}_{\text{min}}) \cdot \frac{1 + \cos(\pi \cdot t / T)}{2} LR(t)=LRmin+(LRmax−LRmin)⋅21+cos(π⋅t/T)
其中:
- t t t 为当前训练步数
- T T T 为总训练步数
- LR max \text{LR}_{\text{max}} LRmax 为最大学习率(通常在 warmup 后达到)
- LR min \text{LR}_{\text{min}} LRmin 为最小学习率(接近 0)
特点:
- 学习率从最大值平滑下降到最小值,呈余弦曲线
- 训练结束后学习率接近 0,模型参数"冻结"
- 不适合持续训练:如果要在已有模型上继续训练,需要重新设置学习率
🔍 实际例子:余弦调度器就像一条从山顶平滑滑到山底的路径,一旦到达底部就很难再爬回山上。如果中途需要继续前进(持续训练),就需要重新规划路线。
3.1.2 DeepSeek 改进:多步学习率调度器
DeepSeek LLM 采用多步学习率调度器(Multi-Step Learning Rate Scheduler),其设计思路是:
- Warmup 阶段:从较小学习率逐渐增加到最大学习率
- 第一阶段(0% → 80%):保持最大学习率
- 第二阶段(80% → 90%) :将学习率降至最大值的 31.6%(即 0.1 ≈ 0.316 \sqrt{0.1} \approx 0.316 0.1 ≈0.316)
- 第三阶段(90% → 100%):将学习率降至最大值的 10%
数学表达式(简化版):
LR ( t ) = { LR max ⋅ t T warmup if t < T warmup LR max if T warmup ≤ t < 0.8 T LR max ⋅ 0.316 if 0.8 T ≤ t < 0.9 T LR max ⋅ 0.1 if 0.9 T ≤ t ≤ T \text{LR}(t) = \begin{cases} \text{LR}{\text{max}} \cdot \frac{t}{T{\text{warmup}}} & \text{if } t < T_{\text{warmup}} \\ \text{LR}{\text{max}} & \text{if } T{\text{warmup}} \leq t < 0.8T \\ \text{LR}{\text{max}} \cdot 0.316 & \text{if } 0.8T \leq t < 0.9T \\ \text{LR}{\text{max}} \cdot 0.1 & \text{if } 0.9T \leq t \leq T \end{cases} LR(t)=⎩ ⎨ ⎧LRmax⋅TwarmuptLRmaxLRmax⋅0.316LRmax⋅0.1if t<Twarmupif Twarmup≤t<0.8Tif 0.8T≤t<0.9Tif 0.9T≤t≤T
优势:
- 便于持续训练:训练结束后学习率仍保持在一个可用的水平(10%),可以无缝继续训练
- 参数复用:训练好的模型可以作为新训练的起点,无需重新初始化
- 灵活扩展:支持在已有模型基础上添加新数据或微调
💡 理解要点:多步学习率调度器就像一条"阶梯式下山"的路径,每到一个平台都可以选择继续前进或停留。这种设计使得模型训练更具灵活性和可扩展性。
3.1.3 为什么这样改进?
论文中提到,这种改进主要是为了支持**长期主义(Longtermism)**的训练策略:
- 数据持续增长:DeepSeek 构建了 2 万亿 token 的数据集,且持续扩展
- 模型迭代需求:需要在已有模型基础上持续改进,而非每次都从头训练
- 计算资源优化:避免重复训练已学到的知识,提高计算效率
3.2 深度优先 vs 宽度优先:架构设计的权衡
DeepSeek LLM 在参数扩展上采用了深度优先的策略,这与许多模型的"宽度优先"形成对比。
3.2.1 标准做法:宽度优先
许多模型在扩展参数时,倾向于增加:
- 模型维度 d model d_{\text{model}} dmodel(如从 4096 增加到 8192)
- FFN 宽度 (如从 4 d 4d 4d 增加到 8 d 8d 8d,FFN = Feed-Forward Network)
- 注意力头数 h h h
这种做法的优势是:
- 每层的表达能力增强
- 梯度流动路径较短,训练相对稳定
3.2.2 DeepSeek 选择:深度优先
DeepSeek LLM 在从 7B 扩展到 67B 时,主要增加了层数:
| 模型 | 层数 N N N | 模型维度 d model d_{\text{model}} dmodel | 注意力头数 h h h | FFN 宽度 |
|---|---|---|---|---|
| DeepSeek 7B | 30 | 4096 | 32 | 4 d 4d 4d |
| DeepSeek 67B | 95 | 8192 | 64 | 4 d 4d 4d |
对比 LLaMA-2:
- LLaMA-2 7B:32 层,4096 维度
- LLaMA-2 70B:80 层,8192 维度
可以看到,DeepSeek 67B 的层数(95)比 LLaMA-2 70B(80)更多,体现了深度优先的设计。
优势:
- 更强的抽象能力:更深的网络可以学习更复杂的特征层次
- 参数效率:在相同参数量下,深度网络可能比宽度网络更高效
- 推理优化:配合 GQA,可以减少 KV 缓存的内存占用
挑战:
- 梯度消失/爆炸:需要更精细的归一化和残差连接设计
- 训练稳定性:需要更长的 warmup 和更小的学习率
🔍 实际例子:宽度优先就像建造一栋"宽而矮"的大楼,每层面积大但楼层少;深度优先就像建造一栋"窄而高"的大楼,每层面积适中但楼层多。DeepSeek 选择了后者,相信"高度"(深度)能带来更强的能力。
3.3 注意力机制:MHA vs GQA
DeepSeek LLM 在不同规模的模型上采用了不同的注意力机制:
3.3.1 7B 模型:标准 MHA
7B 模型使用标准的多头注意力(Multi-Head Attention, MHA):
- 32 个注意力头
- 每个头独立维护 Q、K、V 矩阵
- 总 KV 缓存: L × d model × 2 L \times d_{\text{model}} \times 2 L×dmodel×2(K 和 V 各一份)
3.3.2 67B 模型:GQA(Grouped-Query Attention)
67B 模型采用 GQA,这是对 MHA 的优化:
- 64 个 Query 头
- 8 个 Key-Value 头(每组 8 个 Query 头共享 1 个 KV 头)
- 总 KV 缓存: L × ( d model / 8 ) × 2 L \times (d_{\text{model}}/8) \times 2 L×(dmodel/8)×2,相比 MHA 减少 87.5%
GQA 的工作原理:
假设有 h q h_q hq 个 Query 头和 h k v h_{kv} hkv 个 KV 头( h k v < h q h_{kv} < h_q hkv<hq),则:
- 每个 KV 头被 h q / h k v h_q / h_{kv} hq/hkv 个 Query 头共享
- Query 矩阵: Q ∈ R L × h q × d k Q \in \mathbb{R}^{L \times h_q \times d_k} Q∈RL×hq×dk
- Key/Value 矩阵: K , V ∈ R L × h k v × d k K, V \in \mathbb{R}^{L \times h_{kv} \times d_k} K,V∈RL×hkv×dk
在 DeepSeek 67B 中: h q = 64 h_q = 64 hq=64, h k v = 8 h_{kv} = 8 hkv=8,每组 8 个 Query 头共享 1 个 KV 头。
优势:
- 减少内存占用:KV 缓存大幅减少,适合长序列推理
- 加速推理:减少 KV 矩阵的计算量
- 性能保持:实验表明,GQA 在大多数任务上与 MHA 性能相当
💡 理解要点:GQA 就像"共享会议室"的概念:多个团队(Query 头)可以共享同一个会议室(KV 头),既节省空间(内存)又保持工作效率(性能)。
3.4 架构组件对比表
下面给出 DeepSeek LLM 与 LLaMA-2、标准 Transformer 的详细对比:
| 组件 | 标准 Transformer | LLaMA-2 | DeepSeek LLM |
|---|---|---|---|
| 架构类型 | Encoder-Decoder | Decoder-only | Decoder-only |
| 归一化 | LayerNorm | RMSNorm | RMSNorm |
| 归一化位置 | Post-Norm | Pre-Norm | Pre-Norm |
| 激活函数 | ReLU | SwiGLU | SwiGLU |
| 位置编码 | 正弦/余弦 | RoPE | RoPE |
| 注意力机制 | MHA | MHA (7B/13B) GQA (70B) | MHA (7B) GQA (67B) |
| 学习率调度 | 余弦/线性 | 余弦 | 多步 |
| 扩展策略 | 宽度优先 | 宽度优先 | 深度优先 |
4. 架构参数配置详解
4.1 DeepSeek 7B 配置
核心参数:
- 层数 N = 30 N = 30 N=30
- 模型维度 d model = 4096 d_{\text{model}} = 4096 dmodel=4096
- 注意力头数 h = 32 h = 32 h=32
- 每头维度 d k = d model / h = 4096 / 32 = 128 d_k = d_{\text{model}} / h = 4096 / 32 = 128 dk=dmodel/h=4096/32=128
- FFN 宽度 d f f = 4 ⋅ d model = 16384 d_{ff} = 4 \cdot d_{\text{model}} = 16384 dff=4⋅dmodel=16384
- 词表大小 V = 102400 V = 102400 V=102400(通常)
矩阵维度计算 (以序列长度 L = 2048 L = 2048 L=2048 为例):
-
Embedding 层输出:
- 输入:Token ID 序列,长度 L = 2048 L = 2048 L=2048
- 输出: X ∈ R 2048 × 4096 X \in \mathbb{R}^{2048 \times 4096} X∈R2048×4096
-
单层 Decoder 的注意力层:
- 输入: X ∈ R 2048 × 4096 X \in \mathbb{R}^{2048 \times 4096} X∈R2048×4096
- Q/K/V 投影: W Q , W K , W V ∈ R 4096 × 128 W_Q, W_K, W_V \in \mathbb{R}^{4096 \times 128} WQ,WK,WV∈R4096×128(每头)
- 每头输出: head ( i ) ∈ R 2048 × 128 \text{head}^{(i)} \in \mathbb{R}^{2048 \times 128} head(i)∈R2048×128
- 多头拼接: Concat ∈ R 2048 × 4096 \text{Concat} \in \mathbb{R}^{2048 \times 4096} Concat∈R2048×4096
- 输出投影: W O ∈ R 4096 × 4096 W_O \in \mathbb{R}^{4096 \times 4096} WO∈R4096×4096
- 最终输出: X attn ∈ R 2048 × 4096 X_{\text{attn}} \in \mathbb{R}^{2048 \times 4096} Xattn∈R2048×4096
-
单层 Decoder 的 FFN 层:
- 输入: X attn ∈ R 2048 × 4096 X_{\text{attn}} \in \mathbb{R}^{2048 \times 4096} Xattn∈R2048×4096
- 第一层: W 1 ∈ R 4096 × 16384 W_1 \in \mathbb{R}^{4096 \times 16384} W1∈R4096×16384,输出 z 1 ∈ R 2048 × 16384 z_1 \in \mathbb{R}^{2048 \times 16384} z1∈R2048×16384
- 激活:SwiGLU
- 第二层: W 2 ∈ R 16384 × 4096 W_2 \in \mathbb{R}^{16384 \times 4096} W2∈R16384×4096,输出 X ffn ∈ R 2048 × 4096 X_{\text{ffn}} \in \mathbb{R}^{2048 \times 4096} Xffn∈R2048×4096
-
输出层:
- 输入:最后一层最后一个位置的向量 h L ∈ R 4096 \mathbf{h}_L \in \mathbb{R}^{4096} hL∈R4096
- 线性层: W out ∈ R 4096 × 102400 W_{\text{out}} \in \mathbb{R}^{4096 \times 102400} Wout∈R4096×102400
- 输出: s ∈ R 102400 \mathbf{s} \in \mathbb{R}^{102400} s∈R102400(词表上的 logits)
参数量估算(单层):
- 注意力层: 4 ⋅ d model 2 = 4 × 4096 2 = 67 , 108 , 864 4 \cdot d_{\text{model}}^2 = 4 \times 4096^2 = 67,108,864 4⋅dmodel2=4×40962=67,108,864
- FFN 层: 8 ⋅ d model 2 = 8 × 4096 2 = 134 , 217 , 728 8 \cdot d_{\text{model}}^2 = 8 \times 4096^2 = 134,217,728 8⋅dmodel2=8×40962=134,217,728
- LayerNorm: 2 ⋅ d model = 8192 2 \cdot d_{\text{model}} = 8192 2⋅dmodel=8192
- 单层合计 :约 201 , 338 , 784 201,338,784 201,338,784 参数
- 30 层合计 :约 6.04 6.04 6.04 亿参数
- 加上 Embedding 和输出层 :总计约 7B 参数
4.2 DeepSeek 67B 配置
核心参数:
- 层数 N = 95 N = 95 N=95
- 模型维度 d model = 8192 d_{\text{model}} = 8192 dmodel=8192
- Query 头数 h q = 64 h_q = 64 hq=64
- KV 头数 h k v = 8 h_{kv} = 8 hkv=8
- 每头维度 d k = d model / h q = 8192 / 64 = 128 d_k = d_{\text{model}} / h_q = 8192 / 64 = 128 dk=dmodel/hq=8192/64=128
- FFN 宽度 d f f = 4 ⋅ d model = 32768 d_{ff} = 4 \cdot d_{\text{model}} = 32768 dff=4⋅dmodel=32768
- 词表大小 V = 102400 V = 102400 V=102400(通常)
矩阵维度计算 (以序列长度 L = 2048 L = 2048 L=2048 为例):
-
Embedding 层输出:
- 输出: X ∈ R 2048 × 8192 X \in \mathbb{R}^{2048 \times 8192} X∈R2048×8192
-
单层 Decoder 的注意力层(GQA):
- 输入: X ∈ R 2048 × 8192 X \in \mathbb{R}^{2048 \times 8192} X∈R2048×8192
- Query 投影: W Q ∈ R 8192 × 128 W_Q \in \mathbb{R}^{8192 \times 128} WQ∈R8192×128(64 个头)
- Key/Value 投影: W K , W V ∈ R 8192 × 128 W_K, W_V \in \mathbb{R}^{8192 \times 128} WK,WV∈R8192×128(8 个头)
- 每头输出: head ( i ) ∈ R 2048 × 128 \text{head}^{(i)} \in \mathbb{R}^{2048 \times 128} head(i)∈R2048×128
- 多头拼接: Concat ∈ R 2048 × 8192 \text{Concat} \in \mathbb{R}^{2048 \times 8192} Concat∈R2048×8192
- 最终输出: X attn ∈ R 2048 × 8192 X_{\text{attn}} \in \mathbb{R}^{2048 \times 8192} Xattn∈R2048×8192
-
单层 Decoder 的 FFN 层:
- 输入: X attn ∈ R 2048 × 8192 X_{\text{attn}} \in \mathbb{R}^{2048 \times 8192} Xattn∈R2048×8192
- 第一层: W 1 ∈ R 8192 × 32768 W_1 \in \mathbb{R}^{8192 \times 32768} W1∈R8192×32768,输出 z 1 ∈ R 2048 × 32768 z_1 \in \mathbb{R}^{2048 \times 32768} z1∈R2048×32768
- 激活:SwiGLU
- 第二层: W 2 ∈ R 32768 × 8192 W_2 \in \mathbb{R}^{32768 \times 8192} W2∈R32768×8192,输出 X ffn ∈ R 2048 × 8192 X_{\text{ffn}} \in \mathbb{R}^{2048 \times 8192} Xffn∈R2048×8192
参数量估算(单层):
- 注意力层(GQA):约 3 ⋅ d model 2 + ( h q + 2 h k v ) ⋅ d model ⋅ d k + d model 2 ≈ 268 , 435 , 456 3 \cdot d_{\text{model}}^2 + (h_q + 2h_{kv}) \cdot d_{\text{model}} \cdot d_k + d_{\text{model}}^2 \approx 268,435,456 3⋅dmodel2+(hq+2hkv)⋅dmodel⋅dk+dmodel2≈268,435,456
- FFN 层: 8 ⋅ d model 2 = 8 × 8192 2 = 536 , 870 , 912 8 \cdot d_{\text{model}}^2 = 8 \times 8192^2 = 536,870,912 8⋅dmodel2=8×81922=536,870,912
- LayerNorm: 2 ⋅ d model = 16384 2 \cdot d_{\text{model}} = 16384 2⋅dmodel=16384
- 单层合计 :约 805 , 322 , 752 805,322,752 805,322,752 参数
- 95 层合计 :约 76.5 76.5 76.5 亿参数
- 加上 Embedding 和输出层 :总计约 67B 参数
🔍 实际例子:7B 模型就像一栋 30 层的建筑,每层面积 4096 平方米;67B 模型就像一栋 95 层的建筑,每层面积 8192 平方米。虽然总"建筑面积"(参数量)增加了约 9.6 倍,但"楼层数"(深度)增加了 3.2 倍,体现了深度优先的设计理念。
4.3 参数对比表
| 参数 | DeepSeek 7B | DeepSeek 67B | LLaMA-2 7B | LLaMA-2 70B |
|---|---|---|---|---|
| 层数 N N N | 30 | 95 | 32 | 80 |
| 模型维度 d model d_{\text{model}} dmodel | 4096 | 8192 | 4096 | 8192 |
| 注意力头数 h h h | 32 (MHA) | 64 (GQA) | 32 (MHA) | 64 (GQA) |
| KV 头数 | 32 | 8 | 32 | 8 |
| FFN 宽度 | 16384 | 32768 | 16384 | 32768 |
| 总参数量 | ~7B | ~67B | ~7B | ~70B |
| 深度/宽度比 | 30/4096 | 95/8192 | 32/4096 | 80/8192 |
可以看到,DeepSeek 67B 的层数(95)明显多于 LLaMA-2 70B(80),体现了深度优先的设计。
5. 架构设计的选择与权衡
5.1 为什么保持 LLaMA 的核心架构?
DeepSeek LLM 选择在 LLaMA 架构基础上改进,而非完全重新设计,主要基于以下考虑:
- 稳定性验证:LLaMA 架构经过大规模验证,稳定可靠
- 社区兼容性:与 LLaMA 兼容的模型更容易被社区接受和使用
- 工程效率:复用成熟的架构组件,降低工程风险
- 对比基准:便于与 LLaMA 进行公平对比
💡 理解要点:在 AI 领域,"站在巨人肩膀上"往往比"重新发明轮子"更明智。DeepSeek 选择了前者,将创新聚焦在关键改进点上。
5.2 学习率调度器改进的实际意义
多步学习率调度器的改进带来了以下实际影响:
-
持续训练能力:
- 可以在已有模型基础上无缝添加新数据
- 支持模型版本的迭代升级
- 避免重复训练已学到的知识
-
资源利用效率:
- 减少计算资源的浪费
- 支持增量式模型改进
- 便于模型的长周期维护
-
实验灵活性:
- 可以随时暂停和恢复训练
- 支持多阶段训练策略
- 便于超参数调优
🔍 实际例子:传统的余弦调度器就像"一次性电池",用完就扔;多步调度器就像"可充电电池",可以反复使用和补充能量。
5.3 深度优先设计的影响
深度优先的设计选择带来了以下影响:
优势:
- 更强的抽象能力:更深的网络可以学习更复杂的特征层次
- 参数效率:在相同参数量下,可能获得更好的性能
- 推理优化:配合 GQA,可以减少内存占用
挑战:
- 训练难度:需要更精细的训练策略(如更长的 warmup)
- 梯度问题:需要更稳定的归一化(RMSNorm + Pre-Norm)
- 计算开销:前向传播需要更多层计算
5.4 对训练和推理的影响
训练阶段:
- 多步学习率调度器使得训练过程更加灵活
- 深度优先设计需要更长的 warmup 阶段
- GQA 在训练时与 MHA 计算量相近,但内存占用更少
推理阶段:
- GQA 显著减少 KV 缓存,适合长序列推理
- 深度优先设计对推理速度影响较小(主要是内存访问)
- 模型可以无缝加载和继续训练
6. 总结:架构特点与启示
6.1 关键改进点总结
DeepSeek LLM 在架构层面的关键改进可以总结为:
-
多步学习率调度器:
- 替代余弦调度器,支持持续训练
- 训练结束后学习率保持可用水平(10%)
- 便于模型迭代和参数复用
-
深度优先设计:
- 通过增加层数而非宽度来扩展参数
- 67B 模型达到 95 层,比 LLaMA-2 70B 更深
- 配合 GQA 优化推理效率
-
GQA 注意力机制(67B):
- 减少 KV 缓存 87.5%
- 保持与 MHA 相近的性能
- 适合长序列推理场景
6.2 对开源 LLM 架构设计的启示
DeepSeek LLM 的架构设计为开源 LLM 的发展提供了以下启示:
- 保守创新:在保持核心架构稳定的前提下,聚焦关键改进点
- 长期主义:考虑模型的持续训练和迭代需求
- 工程实践:平衡理论创新与工程可行性
- 性能优化:在扩展参数时考虑推理效率(如 GQA)
💡 理解要点 :DeepSeek LLM 的成功表明,架构改进不一定需要颠覆性创新,有时在关键点上做精准改进,就能带来显著的效果提升。
6.3 未来发展方向
基于 DeepSeek LLM 的架构设计,我们可以展望以下发展方向:
- 更灵活的训练策略:多步学习率调度器的进一步优化
- 深度与宽度的平衡:探索最优的深度/宽度比例
- 注意力机制优化:GQA 的进一步改进和变体
- 推理效率提升:在保持性能的前提下优化推理速度
参考文献
-
DeepSeek Team. (2024). DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. arXiv preprint arXiv:2401.02954.
-
Touvron, H., et al. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971.
-
Touvron, H., et al. (2023). LLaMA 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288.
相关文档: