在MySQL日常开发中,count()函数是最常用的聚合函数之一,用于统计记录行数。但同样是计数,count(*)、count(1)、count(主键字段)、count(普通字段)的执行效率却天差地别,不少开发者在选择时凭感觉踩坑。
今天我们就从原理、执行过程、性能差异到优化方案,一次性把count()函数讲透,帮你在实际开发中精准选型,避开那些隐藏的性能陷阱。
1.核心结论:性能优先级排序
先抛出核心结论帮你快速建立认知,后续再逐步拆解原因:count(*) = count(1) > count(主键字段) > count(普通字段)。需要注意的是,这个排序仅针对InnoDB存储引擎(目前主流生产环境默认引擎),MyISAM因特性不同不适用此结论,下文会详细说明。
2
count()函数的本质作用
很多人误以为count()是统计总记录数,其实这是对它的误解,其本质是统计符合查询条件的记录中,函数指定参数不为NULL的记录数量。这一核心逻辑可拆解为两个关键要点:
-
参数灵活性:count()的参数不仅限于字段,还可以是数字、表达式(如count(1+2)),甚至是常量(如count('a'));
-
判空核心逻辑:无论参数类型如何,计数的核心都围绕"非NULL"展开,参数为NULL时不计数,非NULL时则计数。
3
不同count用法的执行过程与性能
要理解上述性能排序的原因,关键在于搞懂每种用法的执行流程,我前面分享过的文章MySQL的一条SQL查询语句执行过程全解析,里面详细分析了sql查询的执行流程,通过上帝视角,我们可以了解到过程中经历的每个组件,这有助于我们进一步分析。
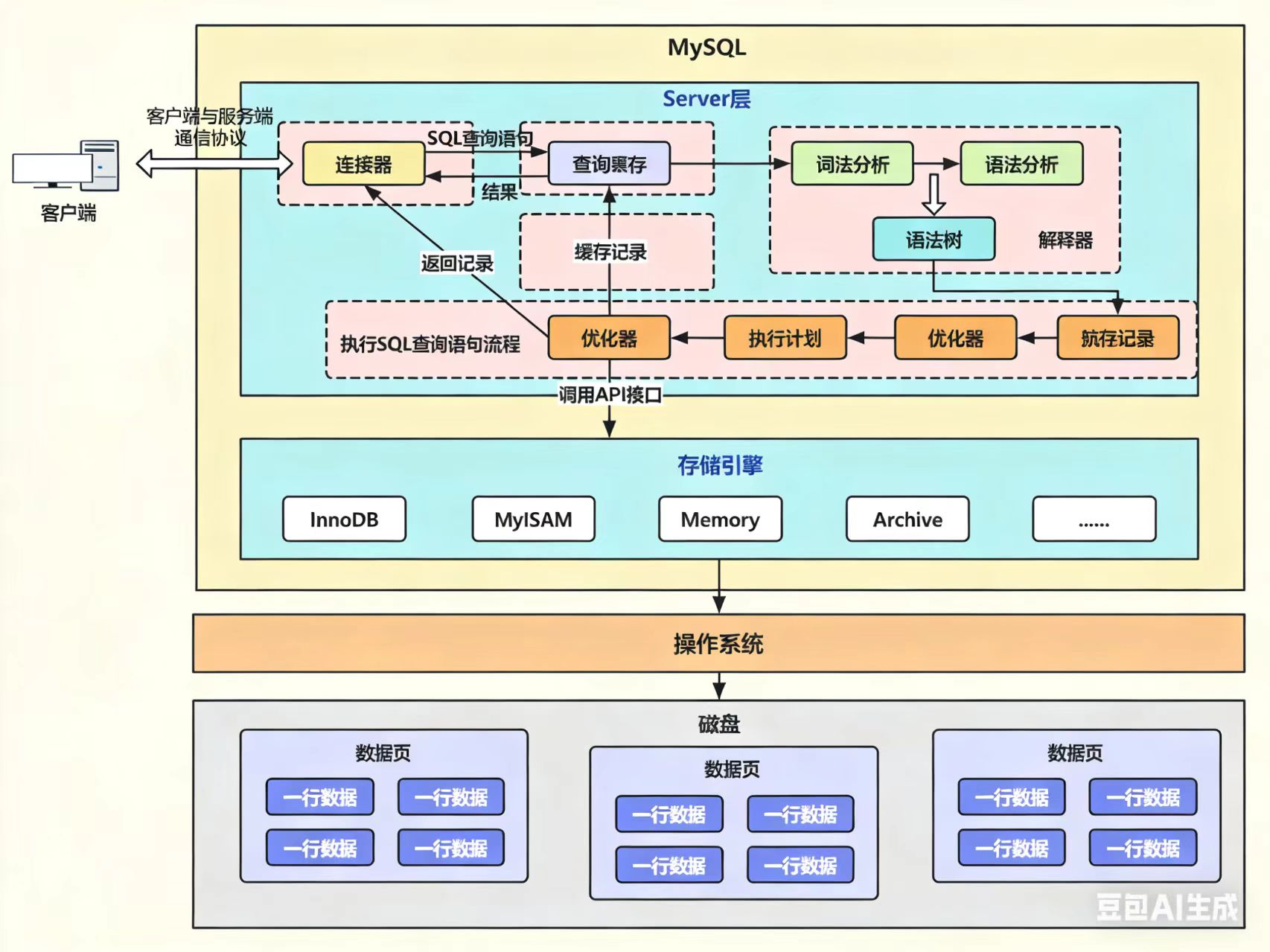 以下均基于InnoDB存储引擎分析,且默认表存在二级索引(无二级索引时会退化为遍历聚簇索引)。
以下均基于InnoDB存储引擎分析,且默认表存在二级索引(无二级索引时会退化为遍历聚簇索引)。
- count(主键字段)
Server层会维护一个count变量,循环向InnoDB请求读取记录,由于这里假设存在二级索引,因此查询优化器会优先选择二级索引,而不是遍历聚簇索引(二级索引占用内存更小,叶子节点存的就是主键值)。InnoDB返回二级索引中的主键值,Server层判断非NULL后将count加1,遍历完成后返回结果。
结论:count(主键字段)的优势是有索引优化,劣势是需额外读取主键字段值,效率略逊。
- count(1)
执行流程与count(主键字段)相似,但有核心优化:同样优先遍历二级索引,InnoDB仅返回记录存在标识,不读取任何字段(无需解析字段值),Server层直接判定参数1为非NULL,计数加1,避免了字段读取和解析的开销。
结论:最终效率略高于count(主键字段),属于高效计数方式。
- count(*)
大多数人会存在一些常见认知误区,认为count(*)会读取所有字段,但实际count(*)的性能表现优异。count(*)并不会读取所有字段,MySQL会将其转化为非NULL常量(如0)处理,等价于count(0)。其执行逻辑与count(1)完全一致,优先遍历二级索引,无需读取字段直接计数。
结论:count(*)和count(1)性能无差异,均为InnoDB最优计数方案。
- count(普通字段)
count(普通字段)是效率最低的用法,核心问题集中在两点:一是存在全表扫描风险,当无索引时会触发全表扫描(explain分析type=ALL),遍历聚簇索引所有记录;二是需要逐行判空,即需读取每条记录的目标字段,判断是否为NULL后再计数。
结论:count(普通字段)即便有索引,仍需读取索引字段并判空,效率远低于前三种方式。
04
为何InnoDB必须循环遍历计数
相信大家应该都知道MyISAM在count()计数的时间复杂度是O(1),那么为什么InnoDB却必须循环遍历计数呢?答案是两种存储引擎的计数逻辑差异,根源在于自身特性。
对于MyISAM引擎,其每张表都会维护meta元数据,里面存储row_count值记录表总行数,依托表级锁保证并发一致性,执行count()时直接读取该值,因此无需遍历表。
但是对于InnoDB引擎,循环遍历计数则不可避免。原因是InnoDB引擎支持事务和MVCC,在同一时刻不同事务可见的数据不同,无法维护全局统一的row_count值,因此需遍历记录并结合隔离级别,计算当前事务可见行数。
05
count(*)的优化方案有哪些
当表数据量达百万、千万级时,即使count(*)走二级索引,遍历耗时也会显著增加,可根据业务需求选择对应的优化方案。
1. 近似值优化:非精准场景首选
适用于后台概览、统计报表等对精度要求不高的场景,可实现O(1)时间计数:
-
show table status:通过TABLE_ROWS字段获取,InnoDB中为估算值,误差通常在10%以内;
-
explain命令:通过rows字段获取估算行数,依赖MySQL统计信息;
-
MySQL8.0+直方图:ANALYZE TABLE生成直方图,优化数据倾斜场景的估算精度。
特别说明,MySQL的统计信息通过采样算法生成,MySQL 会从表的索引(主键索引 / 辅助索引)中随机抽取部分数据页,默认20个数据页,对抽取到的数据页内的所有记录进行统计,再通过抽样结果推算全表的统计信息(如记录总数、字段值分布、索引选择性等)。另外,当数据变化超10%、执行ANALYZE TABLE或重启后首次访问表时,会触发更新。
2. 计数表优化:精准场景必备
通过维护一个独立的计数表的方式来实现精确计数,该方案适用于订单总数、用户总数等需精准计数的场景,实现O(1)查询。大致过程可以是:
-
创建计数表:如
create table count_table (table_name varchar(50) primary key, row_count int default 0); -
同步维护:主表插入/删除时,同步更新计数表数值;
-
并发保障:通过事务或乐观锁保证计数准确性;
-
注意事项:需处理批量操作、事务回滚场景的同步逻辑,避免一致性问题。
06
总结与实战选型建议
相信看到这里,大家对count()计数方法的执行过程和性能分析有了比较清晰的认识了,这里结合前文分析,按场景给出明确选型指南总结:
-
全表非NULL计数(无过滤条件):优先count(*)或count(1),性能最优;
-
主键相关计数:可选count(主键字段),效率略低,按需使用;
-
普通字段非NULL计数:仅业务必须时使用,务必给字段加索引减少全表扫描;
-
大数据量表计数:非精准用show table status/explain,精准用计数表。
最后提醒:实际开发中需结合explain分析执行计划,确认是否走索引,避免因索引失效导致的性能问题。