第一章:使用 Ollama 本地部署 Qwen3:4B 模型
1:安装 Ollama
前往 Ollama 官网 下载并安装适用于你操作系统的客户端(支持 macOS、Windows 和 Linux)。
步骤 2:拉取 Qwen3:4B 模型镜像
打开终端,执行以下命令拉取 Qwen3 的 4B 参数版本:
ollama pull qwen3:4b
步骤 3:验证已安装的模型
 步骤 4:测试模型运行
步骤 4:测试模型运行
ollama run qwen3:4b
>>> 你好!
第二章:Java 应用对接本地大模型(Spring Boot 3 + Spring AI)
步骤 1:创建 Spring Boot 3 项目
使用 Spring Initializr 或 IDE 创建一个基于 Spring Boot 3.x 的新项目。
✅ 确保 JDK 版本 ≥ 17,Spring Boot 3 要求 Java 17+。
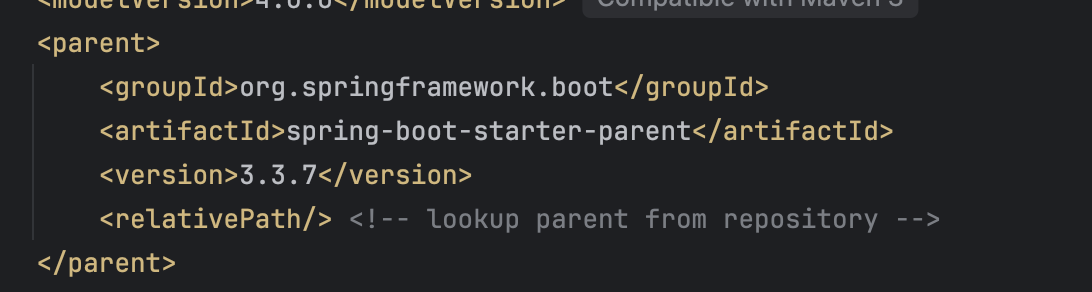
步骤 2:添加依赖
在 pom.xml 中添加以下依赖:
XML
<dependencies>
<!-- Web 支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI - Ollama 集成 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<!-- Spring AI 版本管理 -->
<properties>
<spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>步骤 3:配置 Ollama 客户端
3.1 YAML 配置
在 application.yml 中指定 Ollama 服务地址和模型名称:
java
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen3:4b3.2 创建 ChatClient 配置类
java
@Configuration
public class OllamaChatClientConfig {
@Bean
public ChatClient chatClient(OllamaChatModel model) {
return ChatClient.builder(model)
.defaultSystem("你的名字叫小美,你是一个人工客服")
.build();
}
}步骤 4:创建控制器接口
java
@RestController
@RequestMapping("/ai")
public class SpringAIController {
@Autowired
private ChatClient chatClient;
//阻塞式响应
@GetMapping("/chat")
public String chat(@RequestParam(defaultValue = "你是谁!") String message) {
return chatClient.prompt().user(message).call().content();
}
//流式响应
@RequestMapping(value = "/chat-stream",produces = "text/html;charset=UTF-8")
public Flux<String> chatStream(@RequestParam(defaultValue = "你是谁!") String message) {
return chatClient.prompt().user(message).stream().content();
}
}步骤 5:验证功能

第三章:实现大模型对话记忆功能:ChatMemory配置指南
在完成大模型对接后,您可能会发现每次提问都无法与之前的对话内容关联,这是因为系统缺乏记忆功能。为了解决这个问题,我们需要通过ChatMemory来实现对话记忆。
一、ChatMemory的作用
ChatMemory是Spring AI框架中用于管理对话历史的核心组件,它能够:
- 保存用户与AI的对话记录
- 在后续对话中自动关联上下文
- 提供连贯的对话体验
二、配置实现步骤
1. 创建ChatMemory Bean
在OllamaChatClientConfig配置类中定义ChatMemory Bean:
java
@Configuration
public class OllamaChatClientConfig {
/**
* 配置聊天记忆存储
* 使用InMemoryChatMemory将对话存储在内存中
* 如需持久化存储,可自定义实现ChatMemory接口
*/
@Bean
public ChatMemory chatMemory() {
return new InMemoryChatMemory();
}
/**
* 配置聊天客户端
* 集成模型、系统提示和记忆功能
*/
@Bean
public ChatClient chatClient(OllamaChatModel model, ChatMemory chatMemory) {
return ChatClient.builder(model)
.defaultSystem("你的名字叫小美,你是一个人工客服")
.defaultAdvisors(
new SimpleLoggerAdvisor(), // 日志记录
new MessageChatMemoryAdvisor(chatMemory) // 对话记忆
)
.build();
}
}三、存储方案选择
1. 内存存储(默认方案)
- 实现类 :
InMemoryChatMemory - 特点:简单快速,适合开发测试
- 限制:应用重启后记忆丢失
2. 持久化存储(生产环境推荐)
如需将对话存储在数据库或Redis中,需要自定义实现ChatMemory接口:
java
public interface ChatMemory {
void add(Message message); // 添加对话记录
List<Message> get(); // 获取对话历史
void clear(); // 清除对话记录
}四、配置要点说明
- defaultSystem设置:定义AI的系统角色和行为准则
- defaultAdvisors配置 :
SimpleLoggerAdvisor:记录对话日志,便于调试MessageChatMemoryAdvisor:启用对话记忆功能
- Bean依赖注入:确保ChatMemory正确注入到ChatClient中
五、最佳实践建议
- 开发环境 :使用
InMemoryChatMemory快速验证功能 - 生产环境:实现持久化存储,确保对话历史不丢失
- 性能优化:根据业务需求设置合理的记忆长度
- 安全考虑:敏感对话内容需要加密存储
第四章:Tools 功能使用指南
4.1 Tools 简介
什么是 Tools? Tools 是 Spring AI 提供的功能扩展机制,允许大模型调用外部工具来完成特定任务。
典型应用场景:
- 订单管理(查询、取消、修改)
- 天气查询
- 数据库操作
- API 调用
4.2 Tools 配置实现
4.2.1 创建 Tools 组件
java
package com.example.tools;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.tool.Tool;
import org.springframework.ai.tool.ToolParam;
import org.springframework.stereotype.Component;
/**
* 订单管理工具类
* 提供订单取消功能
*/
@Slf4j
@Component
public class OrderManagementTools {
/**
* 取消订单工具
*
* @param orderId 订单号(必须包含数字和字母)
* @return 操作结果
*/
@Tool(name = "cancelOrder", description = "取消指定的订单,输入参数是需要被取消的订单号")
public String cancelOrder(
@ToolParam(description = "要取消的订单号,必须包含数字和字母") String orderId) {
log.info("取消订单工具被调用,订单号:{}", orderId);
// 这里调用实际的订单取消逻辑
// 例如:orderService.cancelOrder(orderId);
return String.format("订单号:%s 【取消订单成功】", orderId);
}
/**
* 查询订单工具
*
* @param orderId 订单号
* @return 订单信息
*/
@Tool(name = "queryOrder", description = "查询指定订单的详细信息")
public String queryOrder(
@ToolParam(description = "要查询的订单号") String orderId) {
log.info("查询订单工具被调用,订单号:{}", orderId);
// 这里调用实际的订单查询逻辑
// 例如:Order order = orderService.getOrderById(orderId);
return String.format("订单号:%s 的详细信息:...", orderId);
}
}4.2.2 配置 ChatClient 支持 Tools
java
package com.example.config;
import com.example.tools.OrderManagementTools;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.chat.memory.MessageChatMemoryAdvisor;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.retry.SimpleLoggerAdvisor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 支持 Tools 的 ChatClient 配置
*/
@Configuration
public class OllamaChatClientConfig {
@Bean
public ChatMemory chatMemory() {
return new InMemoryChatMemory();
}
@Bean
public ChatClient chatClient(
OllamaChatModel model,
ChatMemory chatMemory,
OrderManagementTools orderTools) {
return ChatClient.builder(model)
.defaultSystem("""
你的名字叫小美,你是一个人工客服。
你拥有以下工具可以使用:
1. cancelOrder: 取消订单工具,需要订单号作为参数
2. queryOrder: 查询订单工具,需要订单号作为参数
使用规则:
- 当用户表达想要取消订单时,使用 cancelOrder 工具
- 当用户询问订单信息时,使用 queryOrder 工具
- 如果用户分多次发送信息(如先说"我想取消订单",然后发送订单号),
你需要记住上下文并正确使用工具
- 订单号通常由数字和字母混合组成
""")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
new MessageChatMemoryAdvisor(chatMemory)
)
// 注册 Tools
.defaultTools(orderTools)
.build();
}
}4.3 使用示例
用户:我想取消订单
AI:好的,请提供您要取消的订单号。
用户:订单号是 ABC123456
AI:正在为您取消订单...
订单号:ABC123456 【取消订单成功】
测试代码:
java
@RequestMapping(value = "/chat-tool",produces = "text/html;charset=UTF-8")
public String chatTool(@RequestParam(defaultValue = "我要取消订单jd123hh") String message) {
return chatClient.prompt().user(message).call().content();
}第五章:ChatPDF - 基于PDF内容的智能问答
5.1 功能概述
ChatPDF功能允许我们将PDF文档上传给模型,然后基于文档内容进行提问和回答。这个功能的核心优势在于限定模型回答范围,让模型的回答更加准确和有针对性。
为什么需要使用向量?
大语言模型有token上限限制,如果直接将整个PDF内容传给模型,很容易超过这个限制。通过向量技术,我们只将最相关的内容片段传递给模型,这样既保证了回答的准确性,又避免了token超限的问题。
工作原理:
- 将PDF内容转换为向量存储
- 将用户问题也转换为向量
- 通过向量相似度匹配,找到最相关的内容片段
- 将匹配的内容和问题一起传给模型生成回答
5.2 实现步骤
第一步:添加依赖
在pom.xml中添加PDF文档读取器依赖:
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>第二步:配置向量模型
在application.yml中配置向量模型(在原有配置基础上增加):
XML
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen3:4b
embedding:#向量模型
model: nomic-embed-text获取向量模型:
ollama pull nomic-embed-text
第三步:创建向量存储配置类
创建VectorStoreConfig.java配置类:
java
@Configuration
public class VectorStoreConfig {
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel)
.build();
}
}这个配置类创建了一个简单的内存向量存储,用于存储和检索文档向量。
第四步:功能验证
4.1 初始化向量存储
创建初始化接口,将PDF文档加载到向量存储中:
java
@RequestMapping("/init-vectorstore")
public void initVectorStore() {
// 指定PDF文件路径
FileSystemResource resource = new FileSystemResource("ttt123.pdf");
// 创建PDF文档读取器,每页作为一个文档单元
PagePdfDocumentReader reader = new PagePdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1) // 每页作为一个独立文档
.build()
);
// 读取PDF文件为Document格式
List<Document> documents = reader.read();
// 将文档写入向量数据库(本地内存方式)
vectorStore.add(documents);
System.out.println("PDF文档已成功加载到向量存储,共 " + documents.size() + " 页");
}4.2 执行相似度搜索
创建搜索接口,基于问题查找最相关的内容:
java
@RequestMapping("/search")
public void searchVectorStore() {
// 构建搜索请求
SearchRequest request = SearchRequest.builder()
.query("2月份工资奖金多少钱") // 用户问题
.topK(1) // 返回最相关的1个结果
.similarityThreshold(0.1) // 相似度阈值
.filterExpression("file_name == 'ttt123.pdf'") // 文件过滤
.build();
// 执行相似度搜索
List<Document> docs = vectorStore.similaritySearch(request);
// 处理搜索结果
if (docs == null || docs.isEmpty()) {
System.out.println("没有找到匹配的文档");
return;
}
// 输出匹配的文档内容
for (Document doc : docs) {
System.out.println("匹配内容:");
System.out.println(doc.getFormattedContent());
System.out.println("相似度分数:" + doc.getMetadata().get("similarity"));
}
}5.3 完整使用流程
- 启动服务:确保Ollama服务和Spring Boot应用都已启动
- 加载PDF :访问
/init-vectorstore接口,将PDF文档加载到向量存储 - 执行搜索 :访问
/search接口,输入问题进行搜索 - 查看结果:控制台会输出最匹配的文档内容和相似度分数
5.4 关键参数说明
- topK: 返回最相关的文档数量,建议设置为1-3
- similarityThreshold: 相似度阈值,范围0-1,值越小匹配越宽松
- filterExpression: 文件过滤表达式,可以限制搜索范围
- withPagesPerDocument: 每个文档包含的页数,设置为1表示每页独立处理
5.5 注意事项
- 首次使用需要先调用
/init-vectorstore初始化向量存储 - PDF文件路径要正确,建议使用绝对路径
- 向量模型需要提前下载,否则会报错
- 内存向量存储在应用重启后会丢失,生产环境建议使用持久化存储
- 大文件可能需要较长时间处理,建议分批次处理
5.6 扩展建议
- 持久化存储:可以使用Redis、Elasticsearch等作为向量存储后端
- 批量处理:支持同时处理多个PDF文件
- 实时更新:实现文档的动态添加和删除
- 权限控制 :为不同用户设置不同的文档访问权限
第六章:向量存储持久化 - 使用 Redis 实现数据持久化
6.1 为什么要使用持久化存储?
在第五章中,我们使用的是 SimpleVectorStore(内存向量存储),这种方式虽然简单快速,但存在一个致命缺陷:应用重启后,所有向量数据都会丢失,需要重新加载和处理 PDF 文件。
为了解决这个问题,我们需要引入持久化向量存储,将向量数据保存到外部存储中,即使应用重启,数据依然存在。
6.2 技术选型:Redis 作为向量存储
选择 Redis 的理由:
- ✅ 性能优异:Redis 是内存数据库,读写速度极快
- ✅ 支持向量搜索:Redis 7.0+ 原生支持向量相似度搜索
- ✅ 易于部署:单机部署简单,适合本地开发和生产环境
- ✅ 数据持久化:支持 RDB 和 AOF 两种持久化方式
- ✅ 生态完善:与 Spring Boot 集成度高,使用方便
- ✅ 官网支持: https://docs.spring.io/spring-ai/reference/api/vectordbs/redis.html
6.3 实现步骤
6.3.1 引入依赖
在 pom.xml 中添加 Redis 相关依赖:
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>6.3.2 配置 Redis 连接
在 application.yml 中添加 Redis 配置:
XML
spring:
redis:
host: localhost # Redis 服务器地址
port: 6379 # Redis 端口
password: # 密码
database: 0 # 数据库索引
timeout: 5000ms # 连接超时时间6.3.3 配置 RedisVectorStore
根据 Spring AI 官方文档,有两种配置方式:
方式一:自动配置(推荐)
添加配置属性即可自动创建 RedisVectorStore:
XML
spring:
ai:
vectorstore:
redis:
index-name: pdf_vector_index # 索引名称
prefix: pdf:doc: # Key 前缀
distance-metric: COSINE # 相似度算法:COSINE / EUCLIDEAN / INNER_PRODUCT
dimensions: 768 # 向量维度(nomic-embed-text 的维度)
initialize-schema: true # 自动初始化索引方式二:手动配置
如果需要更灵活的控制,可以手动创建配置类:
java
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.RedisVectorStore;
import org.springframework.ai.vectorstore.RedisVectorStore.RedisVectorStoreConfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
@Configuration
public class VectorStoreConfig {
/**
* Redis 向量存储配置
*
* @param embeddingModel 向量模型
* @param connectionFactory Redis 连接工厂
* @return RedisVectorStore 实例
*/
@Bean
public RedisVectorStore vectorStore(EmbeddingModel embeddingModel,
RedisConnectionFactory connectionFactory) {
// 配置 Redis 向量存储参数
RedisVectorStoreConfig config = RedisVectorStoreConfig.builder()
.withIndexName("pdf_vector_index") // 向量索引名称
.withPrefix("pdf:doc:") // Redis key 前缀
.withDistanceMetric(RedisVectorStore.DistanceMetric.COSINE) // 相似度计算方式
.withDimensions(768) // 向量维度
.withInitializeSchema(true) // 自动初始化索引
.build();
// 创建并返回 Redis 向量存储实例
return new RedisVectorStore(connectionFactory, embeddingModel, config);
}
}6.3.4 验证持久化效果
原有 Controller 代码无需任何修改,直接使用即可:
java
@RestController
@RequestMapping("/chatpdf")
public class ChatPDFController {
@Autowired
private VectorStore vectorStore;
/**
* 初始化:将 PDF 加载到向量存储
*/
@PostMapping("/init")
public String initVectorStore(@RequestParam String filePath) {
FileSystemResource resource = new FileSystemResource(filePath);
PagePdfDocumentReader reader = new PagePdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
.withPagesPerDocument(1)
.build()
);
List<Document> documents = reader.read();
vectorStore.add(documents); // 数据会自动持久化到 Redis
return "PDF 已加载,共 " + documents.size() + " 页";
}
/**
* 搜索:基于问题查找相关文档
*/
@GetMapping("/search")
public List<Document> search(@RequestParam String query) {
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(3)
.build();
return vectorStore.similaritySearch(request);
}
}第七章: 基于 PDF 内容的智能对话
7.1 功能目标
前两章我们完成了:
- ✅ 第五章:将 PDF 内容向量化并存储
- ✅ 第六章:使用 Redis 实现向量数据持久化
本章将实现完整的问答流程:用户提问 → 检索相关文档 → 调用大模型生成精准回答,让模型真正基于 PDF 内容进行对话,而非凭空"幻觉"回答。
7.2 核心原理:RAG(检索增强生成)
采用 RAG(Retrieval-Augmented Generation) 架构:
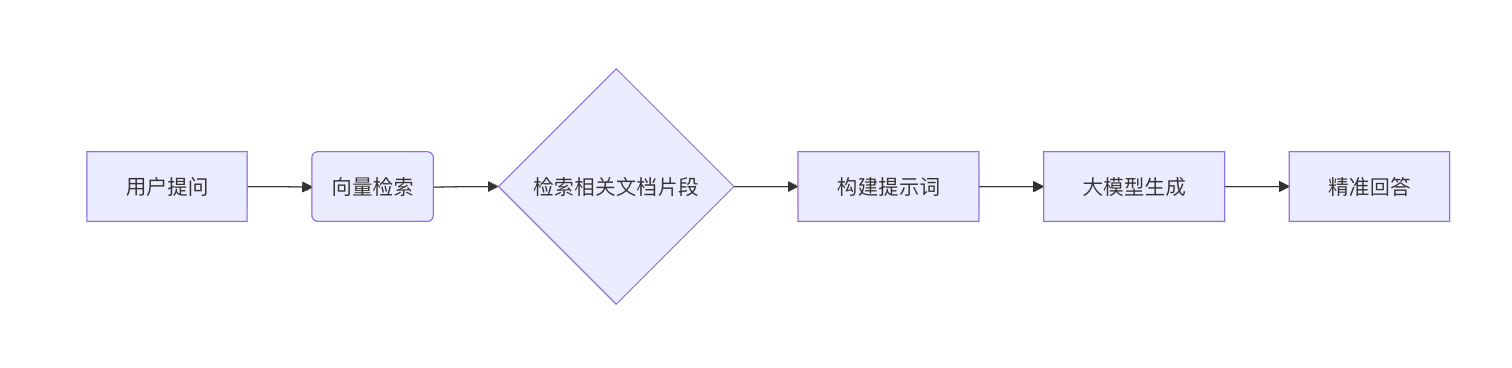
RAG 的优势:
- 🔒 限定回答范围:模型只能基于检索到的文档回答,避免"幻觉"
- 📚 知识可更新:只需更新 PDF 文档,无需重新训练模型
- ⚡ 高效利用 Token:只传递最相关的内容,避免超限
7.3 实现步骤
7.3.1 创建问答 Service
创建 PdfChatService.java,封装完整的问答逻辑:
java
@Service
public class PdfChatServiceImpl implements PdfChatService{
private final VectorStore vectorStore;
private final ChatClient chatClient;
// 检索相关度阈值
private static final double SIMILARITY_THRESHOLD = 0.65;
// 最大返回文档数
private static final int TOP_K = 3;
public PdfChatService(VectorStore vectorStore, ChatClient chatClient) {
this.vectorStore = vectorStore;
this.chatClient = chatClient;
}
/**
* 基于 PDF 内容回答问题
*
* @param query 用户问题
* @param fileName 限定文件名(可选)
* @return 问答结果
*/
public PdfChatResponse chat(String query, String fileName) {
// 1. 检索相关文档
List<Document> relevantDocs = searchRelevantDocuments(query, fileName);
// 2. 构建响应
PdfChatResponse response = new PdfChatResponse();
response.setQuestion(query);
response.setSourceDocuments(relevantDocs);
// 3. 无相关文档时直接返回
if (CollectionUtils.isEmpty(relevantDocs)) {
response.setAnswer("抱歉,根据提供的文档内容无法回答这个问题。");
response.setRetrievalStatus("NO_RELEVANT_CONTENT");
return response;
}
// 4. 构建提示词
String prompt = buildPrompt(query, relevantDocs);
// 5. 调用大模型生成回答
Message message = new UserMessage(prompt);
String answer = chatClient.call(new Prompt(message)).getResult().getOutput().getContent();
response.setAnswer(answer);
response.setRetrievalStatus("SUCCESS");
return response;
}
/**
* 检索相关文档
*/
private List<Document> searchRelevantDocuments(String query, String fileName) {
SearchRequest.SearchRequestBuilder builder = SearchRequest.builder()
.query(query)
.topK(TOP_K)
.similarityThreshold(SIMILARITY_THRESHOLD);
// 如果指定了文件名,添加过滤条件
if (fileName != null && !fileName.isEmpty()) {
builder.filterExpression("file_name == '" + fileName + "'");
}
return vectorStore.similaritySearch(builder.build());
}
/**
* 构建提示词(核心:注入检索到的文档作为上下文)
*/
private String buildPrompt(String query, List<Document> documents) {
StringBuilder context = new StringBuilder();
for (int i = 0; i < documents.size(); i++) {
Document doc = documents.get(i);
context.append("【参考片段 ").append(i + 1).append("】\n");
context.append(doc.getFormattedContent().trim());
context.append("\n\n");
}
return String.format(
"""
你是一个专业的文档助手,请严格基于以下提供的文档内容回答问题。
【重要规则】
1. 仅使用下方【文档内容】中的信息回答问题
2. 如果文档中没有相关信息,请明确告知"根据文档内容无法回答"
3. 不要编造、推测或补充文档中不存在的信息
4. 回答要简洁、准确、直接
【文档内容】
%s
【用户问题】
%s
【回答】
""",
context.toString(),
query
);
}
/**
* 问答响应封装类
*/
public static class PdfChatResponse {
private String question; // 用户问题
private String answer; // 模型回答
private String retrievalStatus; // 检索状态:SUCCESS / NO_RELEVANT_CONTENT
private List<Document> sourceDocuments; // 参考的文档片段
// Getters and Setters
public String getQuestion() { return question; }
public void setQuestion(String question) { this.question = question; }
public String getAnswer() { return answer; }
public void setAnswer(String answer) { this.answer = answer; }
public String getRetrievalStatus() { return retrievalStatus; }
public void setRetrievalStatus(String retrievalStatus) { this.retrievalStatus = retrievalStatus; }
public List<Document> getSourceDocuments() { return sourceDocuments; }
public void setSourceDocuments(List<Document> sourceDocuments) { this.sourceDocuments = sourceDocuments; }
}
}7.3.2 创建问答 Controller
创建 PdfChatController.java,提供 RESTful 接口:
java
@RestController
@RequestMapping("/api/chatpdf")
public class PdfChatController {
@Autowired
private PdfChatService pdfChatService;
/**
* 问答接口
*
* 示例请求:
* POST /api/chatpdf/ask
* Body: {"query": "2月份工资奖金多少钱", "fileName": "ttt123.pdf"}
*/
@PostMapping("/ask")
public PdfChatResponse ask(@RequestBody AskRequestDto dto) {
return pdfChatService.chat(dto.getQuery(), dto.getFileName());
}
/**
* 简化版问答接口(GET)
*
* 示例请求:
* GET /api/chatpdf/ask?query=2月份工资奖金多少钱&fileName=ttt123.pdf
*/
@GetMapping("/ask")
public PdfChatResponse askSimple(@RequestParam String query,
@RequestParam(required = false) String fileName) {
return pdfChatService.chat(query, fileName);
}
/**
* 请求体封装
*/
public static class AskRequestDto {
private String query; // 用户问题
private String fileName; // 限定文件名(可选)
public String getQuery() { return query; }
public void setQuery(String query) { this.query = query; }
public String getFileName() { return fileName; }
public void setFileName(String fileName) { this.fileName = fileName; }
}
}7.3.4 预期响应
java
{
"question": "2月份工资奖金多少钱",
"answer": "根据银行流水记录,2月份工资奖金共计 15,800 元,其中基本工资 12,000 元,绩效奖金 3,800 元。",
"retrievalStatus": "SUCCESS",
"sourceDocuments": [
{
"content": "2024年2月工资入账 15,800.00 元(基本工资12,000.00 + 绩效奖金3,800.00)",
"metadata": {
"page": "3",
"file_name": "ttt123.pdf",
"similarity": "0.87"
}
}
]
}