目录
一.gflags的安装使用
1.1.安装gflags
gflags安装的过程其实很简单
bash
sudo apt-get install libgflags-dev
1.2.使用gflags
gflags是干啥的
gflags 是 Google 开发的一个开源库,**用于 C++ 应用程序中命令行参数的声明、定义 和解析。**gflags 库提供了一种简单的方式来添加、解析和文档化命令行标志(flags), 使得程序可以根据不同的运行时配置进行调整。
想象一下,你写了一个非常厉害的程序。这个程序在运行时,经常需要调整一些"开关"或"参数",比如:
- --port 8080:服务要监听哪个端口?
- --max_users 1000:最多允许多少人同时在线?
- --log_dir ./logs:程序运行的日志存到哪个文件夹?
- --enable_debug:要不要打开调试模式?
这些参数如果直接写死在程序代码里,每次想改(比如把端口从8080改成9090),你就得去翻源代码、重新编译,非常麻烦,在正式服务器上更是不可能这么做。
gflags 就是专门为了解决这个问题而生的一个C++库。它的核心作用,就是帮你优雅、统一地管理这些程序通过命令行来运行时参数。
你可以把它理解为一个智能、统一的"程序启动参数控制板"。它的工作原理和好处是:
1. 集中定义,随处可用
你在代码里一个专门的地方,用简单的宏定义好所有可能的参数(叫什么名字、是什么类型、默认值是多少、简单的说明文字)。
之后,在整个程序的任何一个角落,你都可以像使用普通变量一样来读取这些参数的值。gflags帮你做好了全局访问。
2. 多种方式灵活设置
程序启动时,你可以通过多种方式来设定这些参数的值,优先级通常从高到低:
-
命令行 (最常用):启动程序时直接加参数,比如
./my_program --port=9090 --log_dir=/var/log -
配置文件 :把参数写在一个文件里,启动时用
--flagfile=my.conf来指定。 -
环境变量:通过特定的环境变量来设置。
-
代码里直接改(不推荐,仅用于测试)。
3. 自动帮你的忙
-
类型检查 :你定义
--port是整数,如果用户输入了一个字符串,gflags会报错,而不是让程序崩溃。 -
自动生成"--help" :你只要定义参数时写了说明文字,程序运行时加上
--help或-help,gflags就会自动打印出一份漂亮、完整的参数使用说明,不需要你手动写。 -
支持复杂类型:除了基本的整数、布尔值、字符串,还支持列表等。
我知道,如果我们只是单纯的去讲解它的功能,很难理解,我们必须去用一用它。才能更好的理解。
1.2.1.宏的定义语法
gflags 提供了一系列宏来定义不同类型的命令行参数:
- 布尔类型
bash
DEFINE_bool(参数名, 默认值, "帮助信息");示例:
cpp
DEFINE_bool(enable_debug, false, "是否启用调试模式");
// 使用:--enable_debug 或 --enable_debug=true
// 关闭:--noenable_debug 或 --enable_debug=false
- 整数类型
cpp
DEFINE_int32(参数名, 默认值, "帮助信息"); // 32位整数
DEFINE_int64(参数名, 默认值, "帮助信息"); // 64位整数
DEFINE_uint32(参数名, 默认值, "帮助信息"); // 无符号32位
DEFINE_uint64(参数名, 默认值, "帮助信息"); // 无符号64位示例:
cpp
DEFINE_int32(server_port, 8080, "服务器监听端口");
DEFINE_int32(max_connections, 1000, "最大连接数");
// 使用:--server_port=9090 --max_connections=5000
- 浮点数类型
cpp
DEFINE_double(参数名, 默认值, "帮助信息");示例:
cpp
DEFINE_double(threshold, 0.85, "匹配阈值");
// 使用:--threshold=0.92
- 字符串类型
cpp
DEFINE_string(参数名, 默认值, "帮助信息");示例:
cpp
DEFINE_string(config_file, "config.ini", "配置文件路径");
DEFINE_string(log_dir, "/var/log/myapp", "日志目录");
// 使用:--config_file=production.conf --log_dir=/tmp/logs1.2.2.示例1------通过命令行修改变量
我们直接编写一个main.cpp
cpp
// 最简单gflags例子 - 打招呼程序
#include <iostream>
#include <gflags/gflags.h>
// 定义参数:就定义在 main 文件里,简单!
DEFINE_string(name, "小明", "要打招呼的人名"); // 名字,默认是"小明"
DEFINE_bool(loud, false, "是否大声打招呼"); // 是否大声,默认false
int main(int argc, char** argv) {
// 1. 解析命令行参数
google::ParseCommandLineFlags(&argc, &argv, true);
// 2. 打印结果
std::cout << "你好,";
// 使用 FLAGS_name 获取名字参数的值
std::cout << FLAGS_name;
std::cout << "!";
// 根据 loud 参数决定是否加感叹号
if (FLAGS_loud) {
std::cout << "!!!" << std::endl;
} else {
std::cout << "。" << std::endl;
}
return 0;
}大家注意:FLAGS_name和FLAGS_loud的由来:
在gflags中,当我们使用 DEFINE_xxx 宏定义参数时,宏会自动帮我们生成一个全局变量,这个变量的名字就是 FLAGS_ 加上参数名。
- 所以,DEFINE_string(name, ...) 会自动生成一个全局变量 FLAGS_name,类型是std::string。
- 同样,DEFINE_bool(loud, ...) 会自动生成一个全局变量 FLAGS_loud,类型是bool。
cpp
g++ main.cpp -o test -lgflags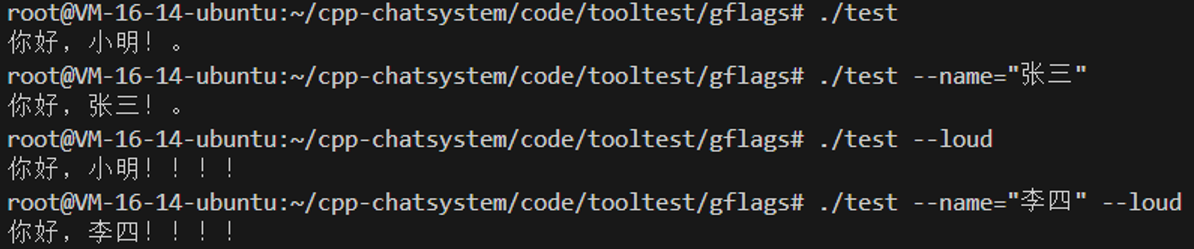
怎么样?我们居然可以通过命令行参数来设置里面的变量的值。是不是很神奇!!
......

1.2.3.示例2------通过配置文件修改变量
main.cpp
cpp
// main.cc - 演示gflags基本用法
#include <gflags/gflags.h>
#include <iostream>
// 定义命令行参数
DEFINE_bool(reuse_addr, true, "是否开启网络地址重用选项");
DEFINE_int32(log_level, 1, "日志等级:1-DEBUG, 2-WARN, 3-ERROR");
DEFINE_string(log_file, "stdout", "日志输出位置设置,默认为标准输出");
int main(int argc, char* argv[])
{
// 解析命令行参数
google::ParseCommandLineFlags(&argc, &argv, true);
// 输出参数值
std::cout << "reuse_addr: " << FLAGS_reuse_addr << std::endl;
std::cout << "log_level: " << FLAGS_log_level << std::endl;
std::cout << "log_file: " << FLAGS_log_file << std::endl;
return 0;
}配置文件编写:main.conf
bash
# main.conf - gflags配置文件
# 注意:配置文件中使用一个减号(-)而不是两个(--)
-reuse_addr=true
-log_level=3
-log_file=./log/main.logmakefile
cpp
main : main.cpp
g++ -std=c++17 $^ -o $@ -lgflags 测试1:查看帮助信息
......

测试2:使用默认参数运行

测试3. 通过命令行传递参数

测试4. 通过配置文件传递参数

测试5:参数优先级 :命令行参数会覆盖配置文件中的设置

现在是不是就很明白了。这个gflags的作用就很好理解了
二.spdlog的安装使用
1.1.安装spdlog
这个的安装其实是非常简单的
此外,我们需要注意:这个spdlog依赖于fmt库进行格式化输出。所以我们还需要安装fmt库
cpp
sudo apt-get install libspdlog-dev &&\
sudo apt-get install libfmt-dev1.2.使用spdlog
spdlog干啥用的
- 第一部分:什么是日志?为什么需要它?
想象一下,你写的程序就像一个复杂的机器人在执行任务。当它在运行时,你怎么知道:
-
它现在正在做什么?("开始连接数据库...")
-
它遇到了什么问题?("错误:网络连接失败!")
-
它的性能怎么样?("处理1000条数据耗时2.3秒")
-
程序崩溃了,崩溃前最后一刻发生了什么?
你不可能一直盯着屏幕看。这时,就需要日志 功能。它让程序在执行过程中,自动把关键信息、状态、警告和错误 记录下来,并输出到某个地方(比如屏幕上的控制台、或者一个文件里),供你事后查看和分析。这对调试程序、监控运行状态、分析线上问题至关重要。
- 第二部分:spdlog 是什么?它的核心优势
你可以把 spdlog 理解为专门为 C++ 程序设计的、一个现成的、高质量的"记录员"。你不需要从零开始自己写这个记录员,只需要"雇佣"它,并告诉它怎么记录就行。
它的核心优势就是你提到的:
-
高性能与超快速:这个记录员手速极快,记录信息时几乎不影响机器人(你的主程序)干活。尤其在"异步模式"下(后面会讲),它更是快到飞起。
-
零配置/易用 :就像你买了一个智能设备"开箱即用"一样,只需要包含头文件就可以使用,日志功能就启动了,非常简单。
-
功能丰富:这个记录员不仅会写字,还自带高级功能:能记录不同级别的事件、能自动加上时间和线程编号、能把记录同时写到好几个地方(如屏幕和文件)。
话不多说,我们直接先看一个例子
main.cpp
cpp
#include <iostream>
#include "spdlog/spdlog.h" // 包含spdlog头文件
int main() {
// 1. 最简单的用法 - 使用默认的日志记录器
spdlog::info("这是一个信息日志");
// 2. 不同类型的日志
spdlog::warn("这是一个警告日志");
spdlog::error("这是一个错误日志");
// 3. 带格式化的日志
spdlog::info("用户{}登录成功,年龄{}", "张三", 25);
// 4. 设置日志级别(只显示错误和更严重的日志)
spdlog::set_level(spdlog::level::err);
spdlog::info("这条不会显示"); // 不会显示,因为级别太低
spdlog::error("这条会显示"); // 会显示
return 0;
}编译
cpp
g++ main.cpp -o test -lspdlog -lfmt
1.2.1.日志等级
我们的spdlog定义了8种日志级别:
cpp
namespace level {
enum level_enum : int {
trace = SPDLOG_LEVEL_TRACE, // 0
debug = SPDLOG_LEVEL_DEBUG, // 1
info = SPDLOG_LEVEL_INFO, // 2
warn = SPDLOG_LEVEL_WARN, // 3
err = SPDLOG_LEVEL_ERROR, // 4
critical = SPDLOG_LEVEL_CRITICAL, // 5
off = SPDLOG_LEVEL_OFF, // 6
n_levels // 7 - 等级数量
};
}- trace(追踪级别)
**这是最低级别的日志,**用于输出最详细的程序执行信息。就像是程序的"显微镜",记录每一个微小的步骤和状态变化。当需要详细了解程序每一步如何执行时使用这个级别。由于信息量极大,通常只在开发复杂的算法或排查极其隐蔽的问题时开启,生产环境中几乎从不使用。
- debug(调试级别)
专门为调试程序而设计的级别。它记录开发者在调试过程中需要查看的各种中间状态、变量值和流程信息。就像程序的"日记本",详细记录了程序做了什么事情、怎么做的。这个级别通常只在开发和测试阶段使用,帮助开发者定位问题。
- info(信息级别)
**这是最常用的级别,用于记录程序正常运行的关键信息。**它就像是程序的"健康报告",告诉用户程序正在做什么重要的事情、运行状态如何。比如服务器启动成功、用户完成某个重要操作等。生产环境通常会保持这个级别开启,用于监控系统运行状态。
- warn(警告级别)
表示程序中出现了一些异常情况,但这些问题还不至于影响核心功能。就像汽车的"警示灯",提醒驾驶员注意某些潜在风险。这些信息需要关注但不需要立即处理,比如磁盘空间不足、网络连接偶尔失败等。
- err(错误级别)
表示程序中发生了真正的错误,导致某些功能无法正常工作。这就像是程序的"故障报告",指出出现了需要修复的问题。比如文件打开失败、数据库连接断开、业务逻辑错误等。这些错误通常需要人工介入处理。
- critical(严重级别)
最高级别的错误,表示程序遇到了可能导致崩溃或系统不可用的严重问题。这就像是程序的"急救信号",需要立即处理。比如内存耗尽、关键数据损坏、系统资源枯竭等。这类日志通常会触发警报机制。
- off(关闭级别)
这不是一个真正的日志级别,而是一个"开关"。当设置为这个值时,所有日志输出都会被关闭,程序将不记录任何日志。通常用于完全不需要日志的场景,或者在特殊调试时需要临时关闭所有日志。
- n_levels(级别数量)
这个值不是一个日志级别,而是一个技术性的枚举值,表示一共有多少个级别定义。它的值是7,对应着从trace到off的7个不同定义。在编程中,有时会用它来遍历所有级别或进行边界检查。
我们可以通过设置日志等级
main.cpp
cpp
#include "spdlog/spdlog.h"
int main() {
// 设置日志级别 - 只显示该级别及以上的日志
spdlog::set_level(spdlog::level::info);
// 这些会显示(因为级别 >= info)
spdlog::info("程序启动"); // 显示
spdlog::warn("内存不足"); // 显示
spdlog::error("文件错误"); // 显示
// 这些不会显示(因为级别 < info)
spdlog::trace("详细跟踪"); // 不显示
spdlog::debug("调试信息"); // 不显示
// 动态改变日志级别
spdlog::set_level(spdlog::level::debug);
spdlog::debug("现在debug可以显示了"); // 显示
// 检查当前级别
auto current_level = spdlog::get_level();
spdlog::info("当前日志级别:{}",
spdlog::level::to_string_view(current_level));
return 0;
}我们编译运行
cpp
g++ main.cpp -o test -lspdlog -lfmt
怎么样?是不是理解了?
1.2.2.日志输出格式自定义
核心概念:格式占位符
spdlog 使用**% 符号加上一个字母**来表示不同的日志信息部分。就像填空题一样,每个占位符会在输出时被对应的实际值替换。
基本占位符讲解
- 时间日期类
这些占位符会被替换为具体的时间值:
- %Y → 年份,如:2024
- %m → 月份,01到12
- %d → 日期,01到31
- %H → 小时(24小时制),00到23
- %M → 分钟,00到59
- %S → 秒,00到59
时间组合示例:
- %Y-%m-%d %H:%M:%S → 2024-01-15 14:30:25
- %m/%d %H:%M → 01/15 14:30
- 日志内容类
- %v →这是最重要的,就是你写的日志消息内容
- %l → 日志级别,比如 INFO、ERROR、DEBUG
- %t → 线程ID,每个线程有不同的数字
- %n → 日志器名称,如果你给日志器起了名字
对齐和宽度控制语法
格式:% + 对齐符号 + 宽度数字 + 占位符字母
-
- 左对齐:%-数字
%-7l → 日志级别左对齐,占7个字符宽度
示例:
INFO → "INFO "(INFO后加3个空格)
ERROR → "ERROR "(ERROR后加2个空格)
WARNING → "WARNING"(正好7个字符)
-
- 右对齐:%数字
%7l → 日志级别右对齐,占7个字符宽度
示例:
INFO → " INFO"(前面加3个空格)
ERROR → " ERROR"(前面加2个空格)
为什么需要对齐?
为了让日志在终端或文件中看起来整齐,所有级别名称占用同样宽度,便于阅读。
示例
示例1
cpp
#include <spdlog/spdlog.h>
int main() {
// 设置自定义日志格式
spdlog::set_pattern("[%Y-%m-%d %H:%M:%S] [%l] %v");
// 输出不同级别的日志
spdlog::info("这是一条信息日志");
spdlog::warn("这是一条警告日志");
spdlog::error("这是一条错误日志");
// 使用对齐功能
spdlog::set_pattern("[%Y-%m-%d %H:%M:%S] [%-7l] %v");
spdlog::info("使用左对齐的日志");
spdlog::warn("看到级别名称对齐了吗?");
spdlog::error("错误级别也占7个字符宽度");
// 添加线程ID
spdlog::set_pattern("[%Y-%m-%d %H:%M:%S] [%-7l] [thread:%t] %v");
spdlog::info("这条日志包含线程ID");
return 0;
}我们进行编译
cpp
g++ main.cpp -o test -lspdlog -lfmt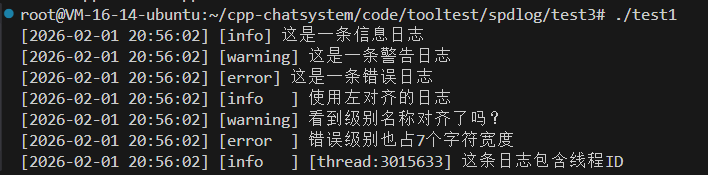
实例2
cpp
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h>
#include <thread>
#include <vector>
#include<iostream>
int main() {
// 示例1:基础格式设置
std::cout << "=== 示例1:基础格式 ===" << std::endl;
spdlog::set_pattern("[%Y-%m-%d %H:%M:%S] [%l] %v");
spdlog::info("用户登录成功");
spdlog::warn("内存使用率超过80%");
spdlog::error("数据库连接失败");
// 示例2:对齐和宽度控制
std::cout << "\n=== 示例2:对齐控制 ===" << std::endl;
spdlog::set_pattern("[%H:%M:%S] [%-8l] [%-6t] %v");
spdlog::info("开始处理请求");
spdlog::debug("调试信息");
spdlog::error("文件不存在");
// 示例3:多线程场景
std::cout << "\n=== 示例3:多线程日志 ===" << std::endl;
spdlog::set_pattern("[%H:%M:%S] [thread:%-5t] [%-5l] %v");
std::vector<std::thread> threads;
for (int i = 0; i < 3; ++i) {
threads.emplace_back([i] {
spdlog::info("线程 {} 开始执行", i);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
spdlog::info("线程 {} 执行完成", i);
});
}
for (auto& t : threads) {
t.join();
}
return 0;
}我们进行编译
cpp
g++ main.cpp -o test -lspdlog -lfmt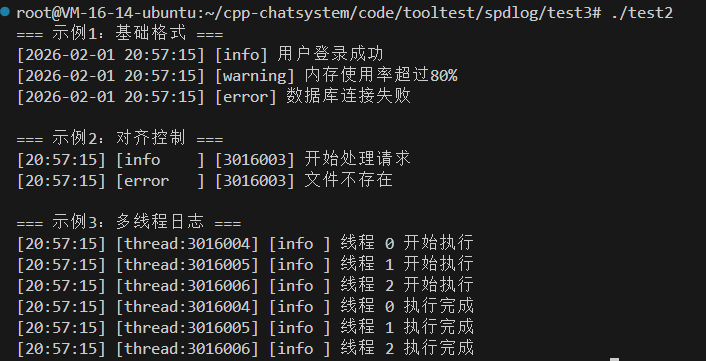
1.2.3.日志记录器类1------默认的logger类
这个日志记录器类------logger类就是用来记录我们的日志的。
有人就好奇了,我上面不是已经通过类似spdlog::info,spdlog::warn等全局函数打印出了日志了吗?为什么还需要来搞一个日志记录器类?
就像:spdlog::info("用户登录成功");
spdlog::warn("内存使用率超过80%");
事实上,我们上面可以通过全局函数来打印日志,其实还是因为我们的spdlog内部自带有一个默认的,全局的logger类,我们通过spdlog::info等全局函数来打印日志,其实都是调用了这个全局的logger类内部的方法来调用,包括我们使用这个spdlog::set_pattern来设置这个日志输出格式,也都是在修改这个默认的logger类内部的设置。
当然,这个默认的logger类也不是一开始就存在的,他也是有创建时机的。
那什么时候会创建默认的logger类?
cpp
// 当第一次调用以下任何函数时,会自动创建默认logger:
spdlog::info("Hello"); // 自动创建默认logger
// 或者
spdlog::default_logger(); // 自动创建默认logger
// 创建的是:控制台输出、带颜色、名为""注意这里创建的是spdlog 库默认的、全局共享的 logger 实例
❌ 错误理解(以为会构造新的)
cpp
// 很多人会误以为这样创建了新的logger
auto logger = spdlog::default_logger(); // ❌ 以为这里创建了新对象
// 然后再次调用,以为会有两个不同的logger
auto logger2 = spdlog::default_logger(); // ❌ 以为这是第二个logger✅ 正确理解(获取同一个实例)
cpp
// 实际上,这两个获取的是同一个logger实例
auto logger1 = spdlog::default_logger(); // 获取默认logger
auto logger2 = spdlog::default_logger(); // 获取的是同一个logger
// 验证:修改一个会影响另一个
logger1->set_pattern("[简单格式] %v");
// 现在logger2的输出格式也变了,因为它们是同一个对象实际上,整个程序只有一个默认logger,所有全局函数调用都使用同一个默认logger实例。
我们直接看例子
实例
示例1
cpp
#include <spdlog/spdlog.h>
#include <iostream>
int main() {
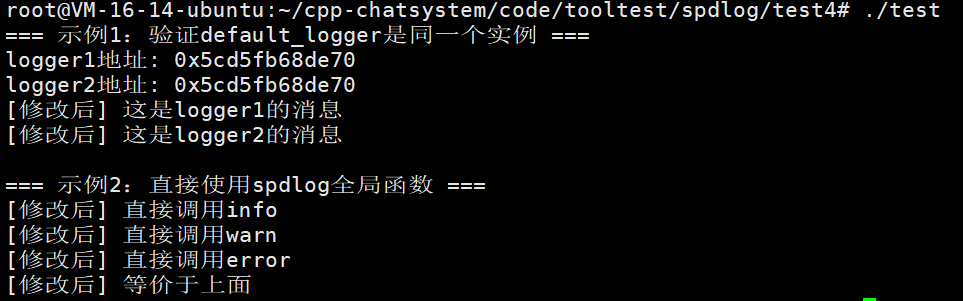
std::cout << "=== 示例1:验证default_logger是同一个实例 ===" << std::endl;
// 获取默认logger两次
auto logger1 = spdlog::default_logger();
auto logger2 = spdlog::default_logger();
// 输出它们的地址(应该是相同的)
std::cout << "logger1地址: " << logger1.get() << std::endl;
std::cout << "logger2地址: " << logger2.get() << std::endl;
// 验证:修改一个会影响另一个
logger1->set_pattern("[修改后] %v");
logger1->info("这是logger1的消息");
logger2->info("这是logger2的消息"); // 也会使用新格式
std::cout << "\n=== 示例2:直接使用spdlog全局函数 ===" << std::endl;
// 这些全局函数使用默认logger
spdlog::info("直接调用info");
spdlog::warn("直接调用warn");
spdlog::error("直接调用error");
// 等价于:
spdlog::default_logger()->info("等价于上面");
return 0;
}
都是一个意思。都是在操作了自己内置的那个logger。
1.2.4.日志记录器类2------自定义日志记录器类
除了这个默认的logger,由于整个程序只有一个默认logger,所有全局函数调用都使用同一个默认logger实例,万一我们需要更多定制化的操作怎么办?这个时候我们就可以自己来创建自己的logger
输出目标的指定------Sink
一、什么是Sink?
- Sink是日志的目的地,即日志写到哪里去。
- 每个Sink代表一种日志输出方式,比如输出到控制台、文件、网络等。
二、Sink的分类(按输出目标)
控制台Sink:将日志输出到控制台(终端)
- stdout_sink_mt:输出到标准输出(白色文字)
- stderr_sink_mt:输出到标准错误
- stdout_color_sink_mt:输出到标准输出,且不同级别用不同颜色
- stderr_color_sink_mt:输出到标准错误,且不同级别用不同颜色
文件Sink:将日志输出到文件
- basic_file_sink_mt:输出到单个文件,文件会不断增大
- rotating_file_sink_mt:滚动文件,当文件达到指定大小后,会新建一个文件,并保留指定数量的文件
网络Sink:将日志输出到网络
- tcp_sink_mt:通过TCP协议发送日志到远程服务器
- udp_sink_mt:通过UDP协议发送日志到远程服务器
- kafka_sink_mt:将日志发送到Kafka消息队列
- mongo_sink_mt:将日志存储到MongoDB数据库
其他Sink:如系统日志、事件日志等(根据平台不同)
三、Sink的线程安全版本(_mt)和非线程安全版本(_st)
_mt(多线程版本):
- 线程安全,可以在多个线程中同时使用,内部有锁机制。
- 适用于多线程程序,但性能略低于_st版本。
_st(单线程版本):
- 非线程安全,只能在单个线程中使用,没有锁,因此性能更高。
- 适用于单线程程序,或者确保只在单线程中使用的场景。
那么我们这里只需要了解两种输出目标(其实就是两个类)
- 标准输出彩色日志输出目标(多线程版):spdlog::sinks::stdout_color_sink_mt
- 基础文件日志输出目标(多线程版):spdlog::sinks::basic_file_sink_mt
对于这个基础文件日志输出目标,我想多说几嘴
cpp
basic_file_sink_mt("文件路径", 是否清空文件)文件路径:如 "logs/app.log"
是否清空文件:
- true = 程序启动时清空文件内容(从头开始写)
- false = 在文件末尾追加(保留之前的日志)
我们直接看例子
cpp
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h> // 控制台带颜色输出
#include <spdlog/sinks/basic_file_sink.h> // 文件输出
int main() {
// ========== 示例1:控制台输出 ==========
std::cout << "=== 示例1:控制台输出 ===" << std::endl;
// 创建控制台输出目标(带颜色)
auto console_sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();
// 创建logger并指定控制台输出
spdlog::logger console_logger("console_logger", console_sink);
console_logger.set_level(spdlog::level::info);
console_logger.info("这条日志会显示在控制台");
console_logger.warn("这是警告信息(通常显示为黄色)");
console_logger.error("这是错误信息(通常显示为红色)");
// ========== 示例2:文件输出 ==========
std::cout << "\n=== 示例2:文件输出 ===" << std::endl;
// 创建文件输出目标(日志保存到文件)
auto file_sink = std::make_shared<spdlog::sinks::basic_file_sink_mt>("logs/app.log", true);
spdlog::logger file_logger("file_logger", file_sink);
file_logger.set_level(spdlog::level::debug);
file_logger.debug("调试信息会保存到文件");
file_logger.info("这条信息也会保存到logs/app.log文件中");
// ========== 示例3:同时输出到控制台和文件 ==========
std::cout << "\n=== 示例3:同时输出到控制台和文件 ===" << std::endl;
// 创建多个输出目标
std::vector<spdlog::sink_ptr> sinks;
sinks.push_back(console_sink); // 输出到控制台
sinks.push_back(file_sink); // 输出到文件
// 创建logger并指定多个输出目标
spdlog::logger multi_sink_logger("multi_logger", sinks.begin(), sinks.end());
multi_sink_logger.set_level(spdlog::level::debug);
// 这条日志会同时显示在控制台和写入文件
multi_sink_logger.info("这条日志会同时输出到控制台和文件");
multi_sink_logger.error("错误信息也会同时输出到两个地方");
return 0;
}注意:spdlog::sink_ptr 就是日志输出目标的智能指针
cpp
// 这是spdlog内部定义
using sink_ptr = std::shared_ptr<spdlog::sinks::sink>;- std::shared_ptr = 智能指针(自动管理内存)
- spdlog::sinks::sink = 所有输出目标的基类
所以 sink_ptr = 智能指针指向输出目标基类
刷新策略
我们的日志也可能不是立即到达这个输出目标的,他也有他自己的刷新策略,那么我们就可以通过下面这个接口来进行刷新
cpp
// 立即刷新所有缓存日志到输出目标
logger.flush();
// 设置当日志级别达到或超过warn时立即刷新
logger.flush_on(spdlog::level::warn);
// 这意味着:
// trace, debug, info 级别的日志可能被缓存
// warn, error, critical 级别的日志会立即输出设置日志级别
cpp
// 只记录info及以上级别的日志
logger.set_level(spdlog::level::info);
// 设置不同的级别
logger.set_level(spdlog::level::trace); // 记录所有日志
logger.set_level(spdlog::level::error); // 只记录error和critical设置输出格式
cpp
// 自定义日志格式
logger.set_pattern("[%Y-%m-%d %H:%M:%S] [%l] %v");
// %Y-%m-%d: 年-月-日
// %H:%M:%S: 时:分:秒
// %l: 日志级别
// %v: 日志消息记录日志
这个是logger类最核心的功能。
我们记住下面6个接口,这6个是最重要的
cpp
logger->trace("This is a trace message");
logger->debug("This is a debug message");
logger->info("This is an info message");
logger->warn("This is a warning message");
logger->error("This is an error message");
logger->critical("This is a critical message");main1.cpp
我们看看最简单的用法
cpp
#include <spdlog/spdlog.h>
#include <iostream>
int main() {
// 创建一个默认的logger(输出到控制台)
auto logger = spdlog::default_logger();
std::cout << "=== 示例1:基本日志输出 ===" << std::endl;
// 基本用法:直接输出字符串
logger->info("应用程序启动");
logger->warn("请注意:测试模式");
logger->error("发生了一个错误");
return 0;
}编译语句都是
cpp
g++ main.cpp -o test -lspdlog -lfmt
main2.cpp
我们看看格式化输出版本
cpp
#include <string>
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h> // 控制台带颜色输出
#include <spdlog/sinks/basic_file_sink.h> // 文件输出
int main() {
auto logger = spdlog::default_logger();
// 创建控制台输出目标(带颜色)
auto console_sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();
// 创建logger并指定控制台输出
spdlog::logger console_logger("console_logger", console_sink);
// 示例变量
std::string username = "张三";
int userId = 1001;
double accountBalance = 1234.56;
bool isVip = true;
const char* ip = "192.168.1.100";
// 格式化输出,使用 {} 作为占位符
logger->info("用户 {} 登录成功", username); // 字符串参数
logger->info("用户ID: {}, IP地址: {}", userId, ip); // 整数和字符串
logger->info("余额: {} 元", accountBalance); // 浮点数
logger->info("VIP用户: {}", isVip); // 布尔值
logger->info("用户信息: ID={}, 姓名={}, 余额={}",
userId, username, accountBalance); // 多个参数
return 0;
}编译语句都是
cpp
g++ main.cpp -o test -lspdlog -lfmt
main3.cpp
cpp
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h> // 控制台带颜色输出
#include <spdlog/sinks/basic_file_sink.h> // 文件输出
#include <cmath>
int main() {
auto logger = spdlog::default_logger();
// 创建控制台输出目标(带颜色)
auto console_sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();
// 创建logger并指定控制台输出
spdlog::logger console_logger("console_logger", console_sink);
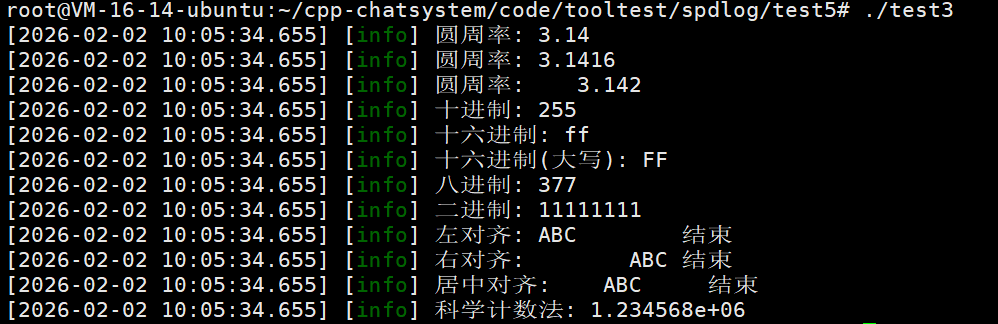
double pi = 3.141592653589793;
int number = 255;
double largeNum = 1234567.89;
// 控制浮点数精度
logger->info("圆周率: {:.2f}", pi); // 保留2位小数
logger->info("圆周率: {:.4f}", pi); // 保留4位小数
logger->info("圆周率: {:8.3f}", pi); // 总宽度8,保留3位小数
// 整数格式化
logger->info("十进制: {}", number); // 十进制
logger->info("十六进制: {:x}", number); // 十六进制
logger->info("十六进制(大写): {:X}", number); // 十六进制大写
logger->info("八进制: {:o}", number); // 八进制
logger->info("二进制: {:b}", number); // 二进制
// 对齐和填充
logger->info("左对齐: {:<10} 结束", "ABC"); // 左对齐,宽度10
logger->info("右对齐: {:>10} 结束", "ABC"); // 右对齐,宽度10
logger->info("居中对齐: {:^10} 结束", "ABC"); // 居中对齐,宽度10
// 数字格式
logger->info("科学计数法: {:e}", largeNum); // 1.234568e+06
return 0;
}
1.2.5.spdlog日志记录器工厂类
工厂类就是"日志记录器生成器",帮你用一行代码创建配置好的logger,不用自己拼装各种组件。
对比:不用工厂 vs 用工厂
cpp
// ❌ 不用工厂(麻烦)
#include <spdlog/sinks/stdout_color_sinks.h>
#include <memory>
// 要写很多代码
auto sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();//要指定sink
auto logger = std::make_shared<spdlog::logger>("my_logger", sink);//要自己创建logger对象
logger->set_pattern(...);
logger->set_level(...);
// ✅ 用工厂(简单)
#include <spdlog/spdlog.h>
// 一行代码搞定!
auto logger = spdlog::stdout_color_mt("my_logger");这些工厂函数会创建一个logger,并且已经附加了对应的sink(日志输出地址)。所以,我们不需要自己创建sink然后组装到logger上,直接使用这些工厂函数即可。
那么,都有哪些工厂类呢?
一、控制台输出工厂函数
- 彩色控制台输出
-
stdout_color_mt - 彩色标准输出(多线程安全,同步)
-
stdout_color_st - 彩色标准输出(单线程,同步)
-
stderr_color_mt - 彩色标准错误输出(多线程安全,同步)
-
stderr_color_st - 彩色标准错误输出(单线程,同步)
- 无颜色控制台输出
-
stdout_logger_mt - 标准输出无颜色(多线程安全,同步)
-
stdout_logger_st - 标准输出无颜色(单线程,同步)
-
stderr_logger_mt - 标准错误输出无颜色(多线程安全,同步)
-
stderr_logger_st - 标准错误输出无颜色(单线程,同步)
二、文件输出工厂函数
- 基础文件输出
-
basic_logger_mt - 基础文件输出(多线程安全,同步)
-
basic_logger_st - 基础文件输出(单线程,同步)
- 循环文件输出(按大小)
-
rotating_logger_mt - 按大小轮转文件(多线程安全,同步)
-
rotating_logger_st - 按大小轮转文件(单线程,同步)
- 每日文件输出
-
daily_logger_mt - 每日轮转文件(多线程安全,同步)
-
daily_logger_st - 每日轮转文件(单线程,同步)
- 每小时文件输出
-
hourly_logger_mt - 每小时轮转文件(多线程安全,同步)
-
hourly_logger_st - 每小时轮转文件(单线程,同步)
......
上面这些都是工厂类,这些工厂函数会创建一个logger,并且已经附加了对应的sink。所以,我们不需要自己创建sink然后组装到logger上,直接使用这些工厂函数即可。
我们就来看看这个到底怎么使用?我们以这个stdout_color_mt为例
- stdout_color_mt - 彩色标准输出(多线程安全,同步)
cpp
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h>
int main() {
// 创建彩色控制台日志记录器(多线程安全)
auto console_logger = spdlog::stdout_color_mt("my_console_logger");
//每个 logger 都有一个唯一的名字,用来区分不同的 logger
//我们这里的logger唯一的名字是my_console_logger
// 使用日志记录器
console_logger->info("这是一条信息日志");
console_logger->warn("这是一条警告日志(黄色)");
console_logger->error("这是一条错误日志(红色)");
return 0;
}
至于其他的,你们自己去试着去用即可。
但是,大家需要注意一个情况:spdlog并没有一个直接的工厂函数来创建一个多sink的日志器。
也就是说,我们使用工厂类,不能直接生成一个日志可以同时输出到多个目的地(控制台和文件)的日志控制器。这个时候,我们就还是必须使用spdlog::logger类来实现
异步版本
我们先看看同步和异步日志有啥区别???
- 同步日志:logger->info("xxx") 会等待写入完成才继续执行
- 异步日志:logger->info("xxx") 立即返回,后台线程帮你写入
我们上面那些所有的工厂类,都是默认是创建一个同步版本的日志记录器。
cpp
// 默认是同步的
auto logger = spdlog::stdout_color_mt("my_logger");那么如果我们需要创建异步版本的日志记录器,那么我们就需要加上异步工厂模板参数,就像下面这样子
cpp
// 加上 <spdlog::async_factory> 变成异步
auto logger = spdlog::stdout_color_mt<spdlog::async_factory>("my_logger");那么异步工厂模板参数一共有2种
-
async_factory - 异步工厂(阻塞模式)
-
async_factory_nb - 异步工厂(非阻塞模式)
任何工厂函数都可以加上 <spdlog::async_factory> 或 <spdlog::async_factory_nb> 变成异步版本,大家按需求去设定即可
注意:异步工厂的关键点:
- 必须先用 spdlog::init_thread_pool() 初始化线程池
- 所有工厂函数都可以加上 <spdlog::async_factory> 变成异步(当然这个async_factory_nb也是可以的)
- 程序结束前必须调用 spdlog::shutdown()
- 根据场景选择阻塞或非阻塞策略
- 异步日志提升性能,但可能丢失队列中的日志
记住这个万能公式:
cpp
spdlog::init_thread_pool(队列大小, 线程数); // 第一步
auto logger = 任何工厂函数<spdlog::async_factory>(参数); // 第二步
// 使用logger...
spdlog::shutdown(); // 最后一步(当然这个async_factory_nb也是可以的)
那么话不多说,我们直接使用一下
示例
同步版本
cpp
#include "spdlog/spdlog.h"
#include "spdlog/sinks/basic_file_sink.h"
int main() {
// 1. 创建同步日志器(前台写入)
auto logger = spdlog::basic_logger_mt("sync_logger", "logs/my_log.txt");
// 2. 使用它
logger->info("这是一条日志");
logger->warn("这是一个警告");
return 0;
}异步版本
cpp
#include <iostream>
#include "spdlog/spdlog.h"
#include "spdlog/async.h" // 异步需要这个头文件
#include "spdlog/sinks/basic_file_sink.h"
int main() {
// 1. 设置异步日志(后台写入)
spdlog::init_thread_pool(8192, 1); // 创建后台线程
// 2. 创建异步日志器(写到文件)
auto logger = spdlog::basic_logger_mt<spdlog::async_factory>(
"async_logger",
"logs/my_log.txt"
);
// 3. 使用它!
logger->info("这是一条日志");
logger->warn("这是一个警告");
logger->error("这是一个错误");
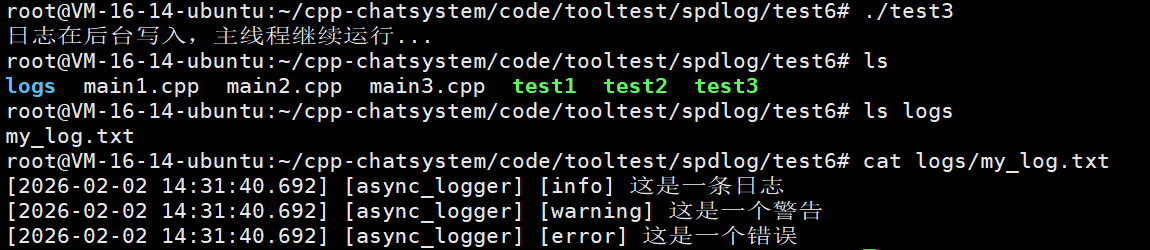
std::cout << "日志在后台写入,主线程继续运行..." << std::endl;
// 4. 程序结束前清理
spdlog::shutdown();
return 0;
}我们来看看这两个函数的作用:
-
spdlog::init_thread_pool(8192, 1);-
这是初始化异步日志的线程池。
-
第一个参数
8192是队列的最大项目数,也就是日志消息队列最多可以存放8192条日志消息。 -
第二个参数
1是线程池中的线程数量,这里设置为1,表示有一个后台线程专门负责写日志。 -
为什么需要这个?因为异步日志的原理是:当你调用日志记录函数(如
info)时,日志消息被放入一个队列,然后由后台线程从队列中取出并写入文件(或其他sink)。这样就不会阻塞主线程。所以,这个线程池就是用来管理这些后台线程的。
-
-
spdlog::shutdown();-
这是用来关闭所有日志器并释放资源。
-
在程序退出前,我们需要确保所有的日志都被写入(因为异步日志可能还在队列中,没有来得及写入文件)。调用
shutdown会等待所有日志写入完成,然后清理资源。 -
如果不调用
shutdown,程序退出时可能还有日志在队列中没有被写入,就会丢失日志。同时,也可能导致资源(如线程)没有正确释放。
-
所以,这两个函数是异步日志中非常重要的初始化和清理步骤。

可以说它们完成的任务是一样的
1.2.6.全局接口
我们主要介绍三个全局接口:set_level, flush_every, flush_on。这些接口可以设置日志的级别和刷新策略。
注意:这些接口是全局的,会影响所有日志器(除非你单独设置某个日志器的策略)。
-
set_level: 设置日志级别,只有不低于该级别的日志才会被输出。
-
flush_every: 每隔一定时间自动刷新日志(将缓冲区的内容写入到目标,如文件)。
-
flush_on: 当遇到不低于指定级别的日志时,立即刷新。
一次设置,全局生效 - 所有日志器都会受到影响!
cpp
#include <spdlog/spdlog.h>
int main() {
// 设置全局日志级别为 "警告" (warn)
spdlog::set_level(spdlog::level::warn);
// 创建默认日志器
auto logger = spdlog::default_logger();
// 测试不同级别的日志
logger->debug("调试信息"); // 被过滤掉(看不到)
logger->info("普通信息"); // 被过滤掉(看不到)
logger->warn("警告信息"); // 能看到(黄色)
logger->error("错误信息"); // 能看到(红色)
// 调整级别为 "信息" (info)
spdlog::set_level(spdlog::level::info);
logger->info("现在能看到我了!"); // 这次能看到了
}
cpp
#include "spdlog/spdlog.h"
#include <thread>
int main() {
auto logger = spdlog::basic_logger_mt("file_logger", "game_log.txt");
// 每3秒自动刷新一次(把缓冲区的内容写入文件)
spdlog::flush_every(std::chrono::seconds(3));
// 模拟游戏运行
for (int i = 1; i <= 10; i++) {
logger->info("游戏第{}秒", i);
std::this_thread::sleep_for(std::chrono::seconds(1));
// 假设在第5秒游戏崩溃了...
if (i == 5) {
std::cout << "游戏崩溃!但日志已经保存到第3秒了" << std::endl;
// 没有flush_every的话,可能什么都没保存!
break;
}
}
}
cpp
#include "spdlog/spdlog.h"
int main() {
auto logger = spdlog::basic_logger_mt("system_logger", "system.log");
// 当遇到错误(error)及以上级别的日志时,立即刷新
spdlog::flush_on(spdlog::level::err);
// 普通日志(不立即刷新,缓冲区积累)
logger->info("系统启动");
logger->info("加载配置文件");
logger->info("初始化数据库");
// 这里假设程序要崩溃了...
logger->error("数据库连接失败!"); // 立即刷新,确保这条写到文件
// 如果程序在这里崩溃,上面的error日志已经保存了!
// 而前面的info日志可能还在缓冲区,可能丢失
std::cout << "即使程序马上崩溃,错误日志也已经保存了!" << std::endl;
}这些例子大家看看就行了,我不会多说一句
1.2.7.多Sink日志示例
但是,大家需要注意一个情况:spdlog并没有一个直接的工厂函数来创建一个多sink的日志器。
也就是说,我们使用工厂类,不能直接生成一个日志可以同时输出到多个目的地(控制台和文件)的日志控制器。这个时候,我们就还是必须使用spdlog::logger类来实现
那么我们现在就来写这么一个例子
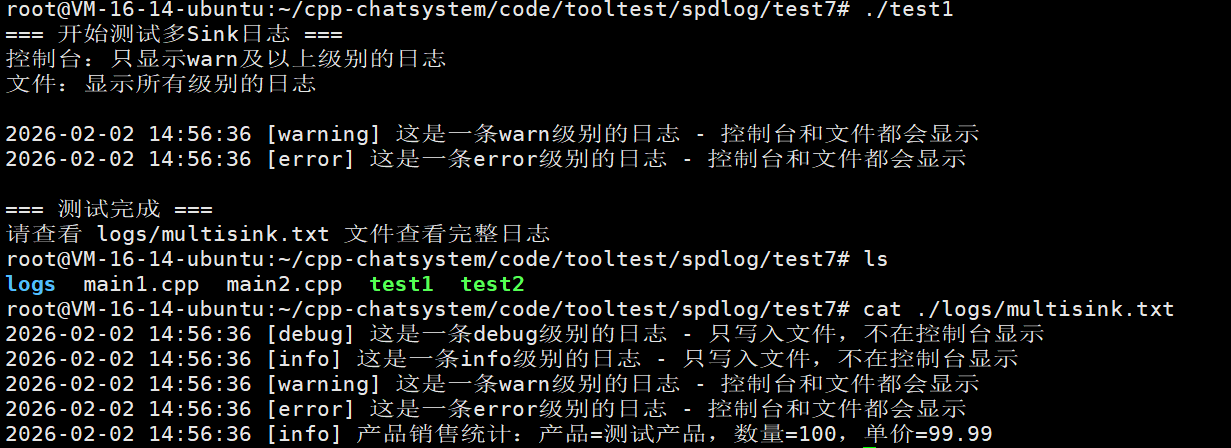
这个程序展示了如何创建一个同时输出到控制台和文件的日志器,并且可以为不同的输出目的地设置不同的日志级别。
程序目的:
演示如何将日志同时输出到多个目的地(控制台和文件),并且分别控制每个目的地的日志级别和格式。
程序步骤:
-
创建控制台Sink:创建一个彩色的控制台输出Sink,并设置它只接收警告(warn)及以上级别的日志。同时设置了控制台输出的格式,使其显示日志级别并带有颜色。
-
创建文件Sink :创建一个文件输出Sink,将日志写入到文件
logs/multisink.txt中,并设置它接收所有级别的日志(从trace开始,即最详细的日志)。 -
创建日志器:创建一个名为"multi_sink"的日志器,并将上面两个Sink绑定到这个日志器上。然后设置日志器本身的日志级别为debug(这意味着debug及以上级别的日志都会进入日志器,但每个Sink还会根据自己的级别进行过滤)。
-
测试日志输出:分别输出debug、info、warn、error级别的日志,以及一条格式化日志。根据设置,控制台只会显示warn和error级别的日志,而文件会记录所有级别的日志。
-
清理资源 :在程序结束前,调用
spdlog::shutdown()来确保所有日志被刷新并释放资源。
cpp
// 多Sink日志示例程序
// 编译命令:g++ -std=c++17 main.cpp -o multi_sink_demo -lspdlog -lfmt
#include <iostream>
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h>
#include <spdlog/sinks/basic_file_sink.h>
int main()
{
// 示例1:创建多Sink日志器
// 一个日志可以同时输出到多个目的地(控制台和文件)
// 1. 创建控制台输出的Sink对象(彩色输出,多线程安全版本)
auto console_sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();
// 设置控制台Sink的日志级别:只显示警告(warn)及以上级别的日志
// 这样info和debug级别的日志就不会显示在控制台
console_sink->set_level(spdlog::level::warn);
// 设置控制台输出的日志格式
// [multi_sink_example] [级别] 日志内容
// %^%l%$:%l表示日志级别,%^和%$表示颜色开始和结束标记
console_sink->set_pattern("[multi_sink_example] [%^%l%$] %v");
// 2. 创建文件输出的Sink对象
// 参数1:日志文件名,参数2:true表示清空原有文件内容
auto file_sink = std::make_shared<spdlog::sinks::basic_file_sink_mt>("logs/multisink.txt", true);
// 设置文件Sink的日志级别:显示所有级别的日志(从trace开始)
// trace是最详细的日志级别,会记录所有信息
file_sink->set_level(spdlog::level::trace);
// 3. 创建日志器对象,同时绑定两个Sink
// 参数1:日志器名称,参数2:Sink列表
spdlog::logger logger("multi_sink", {console_sink, file_sink});
// 设置日志器的全局日志级别:debug及以上级别都会经过日志器
// 注意:日志器级别是初步过滤,然后每个Sink还会根据自己设置的级别进行二次过滤
logger.set_level(spdlog::level::debug);
// 设置日志器的默认日志格式
// 年-月-日 时:分:秒 [级别] 日志内容
logger.set_pattern("%Y-%m-%d %H:%M:%S [%l] %v");
// 4. 测试不同级别的日志输出
std::cout << "=== 开始测试多Sink日志 ===" << std::endl;
std::cout << "控制台:只显示warn及以上级别的日志" << std::endl;
std::cout << "文件:显示所有级别的日志" << std::endl;
std::cout << std::endl;
// 输出debug级别的日志:不会显示在控制台,但会写入文件
logger.debug("这是一条debug级别的日志 - 只写入文件,不在控制台显示");
// 输出info级别的日志:不会显示在控制台,但会写入文件
logger.info("这是一条info级别的日志 - 只写入文件,不在控制台显示");
// 输出warn级别的日志:会在控制台和文件中都显示
logger.warn("这是一条warn级别的日志 - 控制台和文件都会显示");
// 输出error级别的日志:会在控制台和文件中都显示
logger.error("这是一条error级别的日志 - 控制台和文件都会显示");
// 输出格式化日志
int count = 100;
double price = 99.99;
std::string product = "测试产品";
logger.info("产品销售统计:产品={},数量={},单价={:.2f}", product, count, price);
std::cout << std::endl;
std::cout << "=== 测试完成 ===" << std::endl;
std::cout << "请查看 logs/multisink.txt 文件查看完整日志" << std::endl;
// 5. 清理资源
spdlog::shutdown();
return 0;
}
1.2.8.异步日志示例
对于异步日志,我们更应该好好的去了解一下
cpp
// 异步日志示例程序
// 编译命令:g++ -std=c++17 main_async.cpp -o async_demo -lspdlog -lfmt
#include <spdlog/spdlog.h>
#include <spdlog/sinks/basic_file_sink.h>
#include <spdlog/async.h>
#include <iostream>
#include <chrono>
#include <thread>
int main()
{
// 示例2:创建异步日志器
// 异步日志不会阻塞主线程,适合高性能场景
std::cout << "=== 开始测试异步日志 ===" << std::endl;
std::cout << "异步日志会在后台线程写入文件,不会阻塞主线程" << std::endl;
std::cout << std::endl;
// 1. 初始化异步日志的线程池
// 参数1:队列大小(32768) - 最多可以缓存32768条日志
// 参数2:线程数量(1) - 使用1个后台线程处理日志
std::cout << "初始化线程池..." << std::endl;
spdlog::init_thread_pool(32768, 1);
// 2. 通过工厂模式创建异步日志记录器
// 注意:basic_logger_mt后面的<spdlog::async_factory>表示使用异步工厂
// 参数1:日志器名称
// 参数2:日志文件名
std::cout << "创建异步日志器..." << std::endl;
auto async_logger = spdlog::basic_logger_mt<spdlog::async_factory>(
"async_file_logger",
"logs/async_log.txt"
);
// 3. 设置异步日志器的日志格式
// 年-月-日 时:分:秒 [级别] 日志内容
async_logger->set_pattern("%Y-%m-%d %H:%M:%S [%l] %v");
// 4. 设置全局日志级别为info
// 这样debug级别的日志会被过滤掉
async_logger->set_level(spdlog::level::info);
// 5. 测试异步日志性能
std::cout << "开始写入1000条异步日志..." << std::endl;
std::cout << "主线程不会阻塞,可以继续执行其他任务" << std::endl;
// 记录开始时间
auto start_time = std::chrono::high_resolution_clock::now();
// 循环输出1000条异步日志
for (int i = 1; i <= 1000; ++i) {
// 注意:spdlog使用{}作为占位符,可以自动识别数据类型
async_logger->info("异步日志消息 #{} - 当前时间: {}", i, time(nullptr));
// 每100条日志输出一次进度
if (i % 100 == 0) {
std::cout << "已提交 " << i << " 条日志到异步队列" << std::endl;
}
// 模拟主线程的其他工作
// 如果使用同步日志,这里会被阻塞
// 但使用异步日志,主线程可以继续执行
std::this_thread::sleep_for(std::chrono::microseconds(100));
}
// 记录结束时间
auto end_time = std::chrono::high_resolution_clock::now();
// 计算耗时
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end_time - start_time);
std::cout << std::endl;
std::cout << "=== 异步日志性能测试结果 ===" << std::endl;
std::cout << "总耗时: " << duration.count() << " 毫秒" << std::endl;
std::cout << "平均每条日志耗时: " << duration.count() / 1000.0 << " 毫秒" << std::endl;
std::cout << std::endl;
// 6. 输出一些其他级别的日志
async_logger->warn("这是一个异步警告消息");
async_logger->error("这是一个异步错误消息");
// 7. 演示格式化功能
std::cout << "=== 测试异步日志格式化功能 ===" << std::endl;
int apples = 10;
double price_per_apple = 2.5;
std::string fruit = "苹果";
// 自动识别数据类型并格式化
async_logger->info("水果销售:{}个{},单价{:.2f}元,总价{:.2f}元",
apples, fruit, price_per_apple, apples * price_per_apple);
// 8. 清理资源
std::cout << std::endl;
std::cout << "等待所有异步日志写入完成..." << std::endl;
spdlog::shutdown(); // 这会等待所有异步日志写入完成
std::cout << "=== 异步日志测试完成 ===" << std::endl;
std::cout << "请查看 logs/async_log.txt 文件查看日志内容" << std::endl;
return 0;
}程序执行流程:
-
程序开始,打印开始测试的提示信息。
-
初始化线程池:创建一个可以存储32768条日志的队列,并启动1个后台线程来处理队列中的日志(即将日志写入文件)。
-
创建异步日志记录器:该日志器将日志写入文件"logs/async_log.txt",并且使用异步方式(即日志消息先放入队列,然后由后台线程写入文件)。
-
设置日志格式和日志级别:格式为"年-月-日 时:分:秒 级别 日志内容",级别设置为info,这样debug级别的日志会被过滤掉。
-
测试异步日志性能:记录开始时间,然后循环1000次,每次写入一条异步日志(包含序号和当前时间),同时每100条打印一次进度。在每次写入日志后,主线程睡眠100微秒,模拟其他工作。记录结束时间,并计算总耗时和平均每条日志的耗时(注意:这里计算的是主线程提交日志的时间,不包括后台线程写入文件的时间,因为异步日志的提交是非阻塞的)。
-
输出其他级别的日志(警告和错误)以及一条格式化的日志(水果销售信息)。
-
清理资源:调用shutdown,等待后台线程将队列中所有日志写入文件,然后程序结束。
注意:由于是异步日志,主线程提交日志的速度可能快于后台线程写入的速度,但因为有队列,所以主线程不会被阻塞。但是,如果队列满了,主线程再提交日志就会被阻塞(除非设置其他策略)。在这个例子中,队列大小为32768,足够大,所以不会阻塞。
运行这个程序,你会看到控制台输出提交日志的进度,并且程序运行的总时间会非常短(因为提交日志只是将日志放入队列,然后立即返回)。但是,请注意,实际上后台线程可能还在处理队列中的日志,所以在最后调用shutdown来确保所有日志都被写入文件。
1.3.封装spdlog进行二次封装
封装原因
-
避免单例模式的锁竞争
spdlog 默认提供的单例日志器在多线程高并发场景下可能出现锁竞争,影响性能。因此,我们选择直接创建全局的、线程安全的日志器对象,每个线程独立使用,从而减少锁冲突。
-
增强日志信息可追溯性
spdlog 默认输出不包含文件名和行号,在调试时难以快速定位日志来源。因此,我们通过宏封装,在输出日志时自动附加**FILE 和 LINE**信息,提升调试效率。
-
提供统一的初始化接口
为简化日志器的配置与使用,我们封装一个统一的初始化接口,根据运行模式动态设置日志输出目标与级别,使日志配置更加灵活和集中。
封装核心思想
设计一个全局可访问的日志接口,用户通过该接口完成日志器的创建与初始化,无需关心内部实现细节。
初始化接口设计
初始化函数支持以下参数,以适应不同运行环境:
-
运行模式 (
bool类型)-
true表示调试模式:日志输出至标准输出(控制台),便于实时查看。 -
false表示发布模式:日志输出至指定文件,用于持久化存储。
-
-
输出文件名 (
std::string类型)- 在发布模式下,指定日志文件的存储路径与名称。
-
输出日志等级 (
spdlog::level::level_enum类型)- 设置日志输出级别,在发布模式下可灵活控制日志详细程度,提升运行效率。
那么我们其实也很快就能封装出这个日志函数,大家直接看源码即可。
cpp
#pragma once
#include <spdlog/spdlog.h>
#include <spdlog/sinks/stdout_color_sinks.h>
#include <spdlog/sinks/basic_file_sink.h>
#include <spdlog/async.h>
#include <iostream>
// mode - 运行模式: true-发布模式; false调试模式
namespace instant_messenger
{
// 全局日志器实例,使用shared_ptr管理生命周期
// 该日志器默认初始化为空指针,需要调用init_logger进行初始化
std::shared_ptr<spdlog::logger> g_default_logger;
// 初始化全局日志器
// mode: 运行模式,false为调试模式,true为发布模式
// file: 发布模式下日志输出文件的路径
// level: 发布模式下日志输出等级,使用spdlog::level::level_enum枚举值
// 注意这个level有下面这几种:
// trace (0) - 最详细的日志级别,用于追踪程序的执行流程
// debug (1) - 调试信息,用于开发过程中排查问题
// info (2) - 一般信息,用于记录程序正常运行状态
// warn (3) - 警告信息,表示可能出现问题但程序仍可继续运行
// err (4) - 错误信息,表示发生了错误但程序仍可尝试恢复
// critical (5) - 严重错误,表示程序无法继续正常运行
// off (6) - 关闭所有日志输出
void init_logger(bool mode, const std::string &file, int32_t level)
{
if (mode == false) // 调试模式
{
// 调试模式:创建标准输出日志器(控制台输出)
// 使用彩色输出,便于在控制台中区分不同级别的日志
g_default_logger = spdlog::stdout_color_mt("default-logger"); // 利用了工厂类来创建logger对象,采用同步模式
// 工厂类stdout_color_mt - 彩色标准输出(多线程安全,同步)
// 设置日志输出等级为trace(最低级别),输出所有日志
g_default_logger->set_level(spdlog::level::level_enum::trace);
// 设置立即刷新等级为trace,确保所有日志立即输出到控制台
g_default_logger->flush_on(spdlog::level::level_enum::trace);
// flush_on: 当遇到不低于指定级别的日志时,立即刷新
}
else // 发布模式
{
// 发布模式:创建文件输出日志器
// 将日志输出到指定文件中,便于后续分析和问题排查
g_default_logger = spdlog::basic_logger_mt("default-logger", file);
// 设置日志输出等级,根据传入参数确定输出级别
// 使用强制类型转换将int32_t转换为spdlog的日志等级枚举
g_default_logger->set_level((spdlog::level::level_enum)level);
// 设置立即刷新等级,与输出等级保持一致
g_default_logger->flush_on((spdlog::level::level_enum)level);
// flush_on: 当遇到不低于指定级别的日志时,立即刷新
}
// 设置统一的日志输出格式
// 格式说明:
// [%n] - 日志器名称,就比如上面的default-logger就是日志器名称
// [%H:%M:%S] - 时间戳(时:分:秒)
// [%t] - 线程ID
// [%-8l] - 日志级别(左对齐,宽度为8)
// %v - 实际的日志消息
g_default_logger->set_pattern("[%n][%H:%M:%S][%t][%-8l]%v");
}
//注意,我们之前是使用%s来进行占位的,但是spdlog是使用{}来进行占位的,那么这个__FILE__和__LINE__会替换掉对应的{}
#define LOG_TRACE(format, ...) instant_messenger::g_default_logger->trace(std::string("[{}:{}] ") + format, __FILE__, __LINE__, ##__VA_ARGS__)
#define LOG_DEBUG(format, ...) instant_messenger::g_default_logger->debug(std::string("[{}:{}] ") + format, __FILE__, __LINE__, ##__VA_ARGS__)
#define LOG_INFO(format, ...) instant_messenger::g_default_logger->info(std::string("[{}:{}] ") + format, __FILE__, __LINE__, ##__VA_ARGS__)
#define LOG_WARN(format, ...) instant_messenger::g_default_logger->warn(std::string("[{}:{}] ") + format, __FILE__, __LINE__, ##__VA_ARGS__)
#define LOG_ERROR(format, ...) instant_messenger::g_default_logger->error(std::string("[{}:{}] ") + format, __FILE__, __LINE__, ##__VA_ARGS__)
#define LOG_FATAL(format, ...) instant_messenger::g_default_logger->critical(std::string("[{}:{}] ") + format, __FILE__, __LINE__, ##__VA_ARGS__)
//这6个宏其实就是封装了logger类的下面6个日志打印函数
/*
logger->trace("This is a trace message");
logger->debug("This is a debug message");
logger->info("This is an info message");
logger->warn("This is a warning message");
logger->error("This is an error message");
logger->critical("This is a critical message");
*/
}__FILE__和__LINE__的含义
您可以把__FILE__和__LINE__理解为两个"魔法标记",它们的作用是在编译时,由编译器自动填入当前代码所在的位置信息。
它们的具体含义如下:
- FILE
- 它是什么:它是一个字符串常量。
- 它代表什么:它代表了**当前源代码文件的完整路径名或文件名。**编译器在处理这行代码时,会将它替换成当前源文件的名字。例如,如果你的文件叫做 main.c,那么 FILE 就会被替换为 "main.c"。在某些编译环境中,它可能会包含完整的文件路径,如 "D:/project/src/main.c"。
- LINE
- 它是什么:它是一个整数常量。
- 它代表什么:它代表了**当前代码在源文件中的行号。**编译器会将它替换成一个数字,这个数字就是这行代码(即 LINE 这行本身)在文件中的具体行数。如果你把这段代码移动到文件的第50行,那么 LINE 的值在下次编译时就会变成50。
cpp
#include<iostream>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
printf("[%s:%d] Hello World!\n",__FILE__,__LINE__);
}
可以看到。
##__VA_ARGS__的由来
C99标准引入了不定参数宏,允许宏接受可变数量的参数。语法类似于可变参数函数,使用 ... 表示可变参数部分,并在替换部分使用 VA_ARGS 来引用这些参数。
cpp
#define PRINT(...) printf(__VA_ARGS__)
int main() {
PRINT("Hello, %s!\n", "world");
PRINT("Number: %d\n", 42);
return 0;
}注意:在C语言中,字符串常量相邻会自动连接成一个字符串
因为format是一个字符串参数,在预处理时,它会被替换成用户传入的字符串,然后与周围的字符串连接,形成一个完整的格式字符串。
cpp
#define LOG(format, ...) printf("[%s:%d] " format "\n", __FILE__, __LINE__, __VA_ARGS__)
// 使用示例
int x = 42;
LOG("Value: %d", x);
cpp
// 宏展开后的代码:
printf("[%s:%d] " "Value: %d" "\n", __FILE__, __LINE__, x);
// 编译器会处理为:
printf("[%s:%d] Value: %d\n", __FILE__, __LINE__, x);但是现在还有一个问题。
如果说我传递的是只是1个参数进去
cpp
LOG(LDBG);那么宏函数的不定参数就会报错啊。
上面的LOG宏定义中,format 和 ... 是分开的,这样调用时就需要至少两个参数(level和format),然后可变参数至少一个(因为__VA_ARGS__至少需要一个参数)。
- 使用C99标准中的__VA_ARGS__,并确保在调用时至少提供一个参数(但这样就不能完全省略可变参数)。
- 使用##VA_ARGS(GCC扩展),这样当可变参数为空时,就没有一点问题。
如果你希望允许可变参数为空,则需要使用**##VA_ARGS**。
测试
那么现在我们就写一个小程序进行测试一下
cpp
#include "logger.hpp"
#include <gflags/gflags.h>
DEFINE_bool(run_mode, false, "程序的运行模式,false-调试; true-发布;");
DEFINE_string(log_file, "", "发布模式下,用于指定日志的输出文件");
DEFINE_int32(log_level, 0, "发布模式下,用于指定日志输出等级");
int main(int argc, char *argv[])
{
google::ParseCommandLineFlags(&argc, &argv, true);
//通过命令行参数来设定这个logger
init_logger(FLAGS_run_mode, FLAGS_log_file, FLAGS_log_level);
LOG_DEBUG("你好:{}", "世界");
LOG_INFO("你好:{}", "世界");
LOG_WARN("你好:{}", "世界");
LOG_ERROR("你好:{}", "世界");
LOG_FATAL("你好:{}", "世界");
LOG_DEBUG("这是一个测试");
return -1;
}
没有一点问题。
cpp
./main --run_mode=true --log_file=./main.log --log_level=3执行这个可以看到它就不在这个控制台进行输出了,它把日志打印到main.log里面去了

