目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
** 选题指导:**
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于双层滤波与分割点改进孤立森林的网络入侵检测算法研究
选题背景意义
随着网络通信技术在工业、购物、电子通信等领域的广泛应用,网络安全威胁日益严重,给个人、企业和国家安全带来了巨大挑战。网络入侵检测作为网络安全防护体系的重要组成部分,能够实时监测网络流量和系统行为,识别潜在的攻击行为,为网络安全提供及时有效的保障。然而,传统的网络入侵检测系统在面对高维度、高冗余、多噪声的网络数据时,往往存在检测效率低、误报率高、无法有效处理不平衡数据等问题,难以满足现代网络安全的需求。
在当前的网络环境中,网络流量数据呈现出爆炸式增长的趋势,数据维度不断增加,同时包含大量的冗余信息和噪声数据。这些数据特点给网络入侵检测带来了巨大挑战:一方面,高维度数据导致检测算法的计算复杂度急剧增加,影响检测的实时性;另一方面,冗余信息和噪声数据会干扰检测算法的判断,降低检测的准确性。此外,网络入侵数据通常是高度不平衡的,正常数据样本数量远大于异常数据样本数量,这使得传统的异常检测算法难以有效识别异常行为。
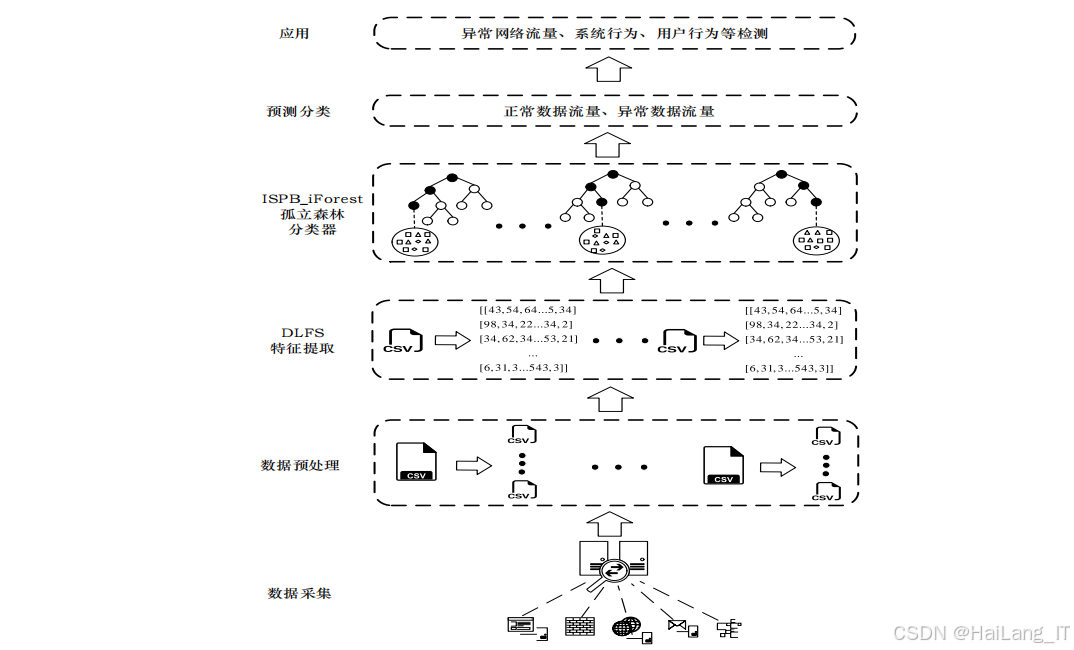
针对上述问题,本文提出了一种基于分割点改进孤立森林的网络入侵检测技术,该技术结合了双层滤波选择算法(DLFS)和基于分割点改进孤立森林算法(ISPB_iForest)。双层滤波选择算法通过皮尔逊相关性分析和标准化互信息对高维网络数据进行特征选择,有效降低数据维度,减少冗余信息和噪声数据;基于分割点改进孤立森林算法通过优化分割点选择策略,提高了不平衡数据下的异常检测性能。这项研究对于提高网络入侵检测的效率和准确性具有重要意义,为解决现代网络安全问题提供了新的思路和方法。
数据集
网络入侵检测数据集的构建是网络安全研究的基础,高质量的数据集对于算法的训练和评估至关重要。数据集构建流程主要包括数据采集、数据清洗与筛选、数据标注、数据格式转换和数据划分等环节。数据获取方式主要有三种:一是使用开源数据集,如KDDCUP99、UNSW-NB15等;二是通过网络爬取获取真实网络流量数据;三是自主搭建实验环境,模拟网络攻击生成数据。收集到的数据需要进行整理和分类,去除无效数据和冗余数据,保留与网络入侵检测相关的数据。对于收集到的数据,需要进行数据清洗、数据筛选、数据标注等处理,使其适合用于网络入侵检测算法的训练和评估。
数据采集
数据采集是数据集构建的第一步,高质量的数据采集直接影响后续的研究效果。在网络入侵检测领域,数据采集主要有三种方式:使用开源数据集、网络爬取和自主生成。开源数据集是最常用的数据来源,这些数据集通常由研究机构或组织发布,包含了丰富的网络流量数据和攻击样本,如KDDCUP99、UNSW-NB15和WADI等。这些数据集经过了专业的收集和整理,具有较高的质量和权威性,适合用于网络入侵检测算法的研究和评估。
网络爬取是另一种重要的数据采集方式,通过网络爬虫工具可以获取真实的网络流量数据。这种方式获取的数据更贴近实际网络环境,能够反映真实的网络攻击行为。但是,网络爬取需要遵守相关法律法规和伦理规范,不得侵犯他人的隐私和知识产权。在进行网络爬取时,需要选择合适的爬虫工具和爬取策略,确保数据的合法性和安全性。
自主生成数据是指通过搭建实验环境,模拟网络攻击行为,生成网络流量数据。这种方式可以根据研究需求,生成特定类型的攻击样本,弥补开源数据集的不足。自主生成数据需要搭建完善的实验环境,包括网络设备、服务器、攻击工具等,同时需要专业的技术人员进行操作和管理。自主生成的数据具有较高的可控性和针对性,适合用于特定类型网络攻击的研究。
数据清洗与筛选
数据清洗与筛选是数据集构建的重要环节,通过去除无效数据和噪声数据,提高数据质量。网络流量数据中往往包含大量的无效数据,如重复数据、缺失数据、异常数据等,这些数据会影响后续的分析和处理。数据清洗的主要任务包括:去除重复数据、处理缺失数据、识别和处理异常数据等。
| 增强方法 | 描述 | 应用场景 |
|---|---|---|
| 过采样 | 增加少数类样本数量,如SMOTE算法 | 解决数据不平衡问题 |
| 欠采样 | 减少多数类样本数量,如随机欠采样 | 降低计算复杂度 |
| 数据合成 | 生成新的少数类样本,如ADASYN算法 | 提高少数类样本的多样性 |
| 特征扩展 | 基于现有特征生成新特征,如特征交叉 | 丰富特征空间 |
去除重复数据是数据清洗的第一步,重复数据会增加数据量,影响计算效率,同时可能导致分析结果出现偏差。可以通过比较数据的特征值,识别并去除重复数据。处理缺失数据是数据清洗的另一项重要任务,缺失数据会导致分析结果不准确,需要根据具体情况选择合适的处理方法,如删除缺失数据、插值填充等。识别和处理异常数据是数据清洗的关键环节,异常数据可能是由于数据采集错误或网络攻击导致的,需要通过统计分析、机器学习等方法进行识别和处理。
数据筛选是指根据研究需求,选择与网络入侵检测相关的数据。网络流量数据包含大量的特征,如源IP地址、目标IP地址、端口号、协议类型、数据包长度等,并非所有特征都与网络入侵检测相关。通过数据筛选,可以去除无关特征,减少数据维度,提高后续分析的效率和准确性。数据筛选可以基于领域知识或统计分析方法,选择与网络入侵检测最相关的特征。
数据标注
数据标注是指为数据样本添加标签,标识其是否为异常数据。在监督学习中,标注数据是训练模型的基础,标注质量直接影响模型的性能。网络入侵检测数据的标注通常包括两个类别:正常数据和异常数据。正常数据是指符合网络通信规范的流量数据,异常数据是指包含网络攻击行为的流量数据。
| 数据类型 | 子类型 | 描述 |
|---|---|---|
| 正常数据 | - | 符合网络通信规范的流量数据 |
| 异常数据 | DoS攻击 | 拒绝服务攻击,通过耗尽目标资源使其无法响应 |
| 异常数据 | Probe攻击 | 探测攻击,用于扫描目标系统的漏洞 |
| 异常数据 | R2L攻击 | 远程到本地攻击,攻击者从远程系统获取本地系统的访问权限 |
| 异常数据 | U2R攻击 | 用户到根攻击,攻击者从普通用户权限提升到根权限 |
数据标注的方法主要有人工标注和自动标注两种。人工标注是指由专业人员根据经验和领域知识,对数据样本进行标注。这种方法标注质量高,但效率低,适合小批量数据的标注。自动标注是指利用现有的入侵检测系统或规则,对数据样本进行自动标注。这种方法效率高,但标注质量可能受到检测系统或规则的限制,适合大批量数据的初步标注。
在数据标注过程中,需要注意标注的一致性和准确性。标注不一致会导致模型训练出现偏差,标注不准确会影响模型的性能。为了提高标注质量,可以采用多人标注、交叉验证等方法,确保标注结果的一致性和准确性。此外,还可以利用半监督学习或无监督学习方法,减少对标注数据的依赖,提高数据利用效率。
数据格式与划分
数据格式转换是指将原始数据转换为适合算法处理的格式。网络流量数据通常以二进制形式存储,需要转换为结构化数据格式,如CSV、JSON等。数据格式转换包括数据解析、特征提取、数据编码等步骤。数据解析是指从原始数据包中提取有用信息,如源IP地址、目标IP地址、端口号等;特征提取是指从解析后的数据中提取与网络入侵检测相关的特征,如数据包长度、传输速率、连接持续时间等;数据编码是指将非数值型特征转换为数值型特征,如将协议类型转换为数字编码。
数据划分是指将数据集划分为训练集和测试集,用于算法的训练和评估。数据划分需要遵循一定的原则,如保持数据分布的一致性、避免数据泄露等。常用的数据划分方法有随机划分、分层划分等。随机划分是指将数据随机分为训练集和测试集,这种方法简单易行,但可能导致训练集和测试集的数据分布不一致。分层划分是指在保持各类别数据比例不变的情况下,将数据划分为训练集和测试集,这种方法可以保证训练集和测试集的数据分布一致,提高评估结果的准确性。
在数据划分过程中,需要合理选择训练集和测试集的比例。通常情况下,训练集占总数据的70%-80%,测试集占总数据的20%-30%。训练集用于训练模型,测试集用于评估模型的性能。此外,还可以采用交叉验证的方法,将数据分为多个子集,轮流将其中一个子集作为测试集,其他子集作为训练集,进行多次训练和评估,提高评估结果的可靠性。
以下是数据划分示例表格:
| 数据集名称 | 训练集比例 | 测试集比例 | 划分方法 | 样本总数 |
|---|---|---|---|---|
| KDDCUP99 | 70% | 30% | 分层划分 | 4,898,431 |
| UNSW-NB15 | 80% | 20% | 分层划分 | 254,004 |
| WADI | 75% | 25% | 随机划分 | 1,048,576 |
| 自定义数据集 | 80% | 20% | 分层划分 | 500,000 |
功能模块
基于分割点改进孤立森林的网络入侵检测系统主要包括五个功能模块:数据采集模块、数据预处理模块、特征提取模块、异常检测模块和结果输出模块。数据采集模块作为整个系统的基础,负责从网络环境中实时捕获和收集各类流量数据,包括正常网络通信数据和潜在的攻击数据。数据预处理模块对采集到的原始数据进行清洗、格式化和标准化处理,去除无效数据和噪声数据,将不同格式的数据转换为统一格式,确保数据的质量和一致性,为后续的特征提取和异常检测提供可靠的数据基础。特征提取模块从预处理后的数据中提取与网络入侵相关的特征,通过双层滤波选择算法对高维数据进行降维和去冗余处理,保留最具代表性的特征子集,提高检测算法的效率和准确性。异常检测模块作为系统的核心,使用基于分割点改进孤立森林算法对提取的特征进行分析,检测网络中的异常行为,生成异常得分和检测结果。结果输出模块将异常检测模块的检测结果以直观、清晰的可视化方式展示给用户,包括异常数据的数量、类型、来源等信息,并提供报警提示功能,帮助用户及时发现和处理网络安全威胁。这五个模块之间紧密协作,形成一个完整的网络入侵检测流程,确保系统能够高效、准确地检测网络入侵行为。
数据预处理模块
数据预处理模块负责对采集到的原始网络流量数据进行全面的清洗、格式化和标准化处理,旨在提高数据质量,消除数据中的噪声和冗余,为后续的特征提取和异常检测提供高质量的数据基础。原始网络流量数据通常包含大量的噪声数据、缺失数据、重复数据和格式不一致的数据,这些问题会严重影响后续算法的分析结果和检测性能,因此数据预处理是网络入侵检测系统中不可或缺的重要环节。
数据预处理模块的主要功能包括数据清洗、数据格式化和数据标准化。数据清洗是预处理的核心环节,主要包括去除重复数据、处理缺失数据和识别并处理异常数据。去除重复数据可以通过比较数据包的特征值或哈希值来实现,避免重复数据对分析结果的干扰。处理缺失数据的方法包括删除包含缺失值的样本、使用统计方法(如均值、中位数)填充缺失值或使用机器学习算法进行预测填充。识别并处理异常数据则需要通过统计分析或专门的异常检测算法,识别出数据采集过程中产生的错误数据或极端值。数据格式化是将不同格式的数据转换为统一的结构化格式,如将非结构化的原始数据包转换为CSV、JSON等格式,确保数据的一致性和可读性。数据标准化是将数值型特征转换为统一的尺度,如使用MinMaxScaler将特征值归一化到0,1区间,或使用StandardScaler将特征值转换为均值为0、标准差为1的标准正态分布,消除不同特征之间的量纲差异,提高算法的收敛速度和检测准确性。
数据预处理的质量直接影响后续分析的结果,因此需要根据具体的数据集和研究需求,选择合适的预处理方法和参数。例如,对于缺失值较多的数据集,可以采用更为复杂的填充方法;对于包含大量非数值型特征的数据集,需要进行独热编码或标签编码等处理。数据预处理模块需要具备良好的可配置性和扩展性,能够适应不同类型的数据集和预处理需求。通过有效的数据预处理,可以大幅提高数据的质量和一致性,减少噪声数据和冗余数据的影响,为后续的特征提取和异常检测奠定坚实的基础,从而提高整个网络入侵检测系统的性能和准确性。
特征提取模块
特征提取模块负责从预处理后的数据中提取与网络入侵相关的特征,并通过降维和去冗余处理,筛选出最具代表性的特征子集。特征提取是网络入侵检测的关键环节,直接影响检测算法的效率和准确性。高质量的特征能够有效区分正常网络行为和异常攻击行为,降低算法的计算复杂度,提高检测的实时性和准确性。特征提取模块需要综合考虑网络流量的各种属性,包括流量的统计特征、时序特征、内容特征等,确保提取的特征能够全面反映网络行为的本质。
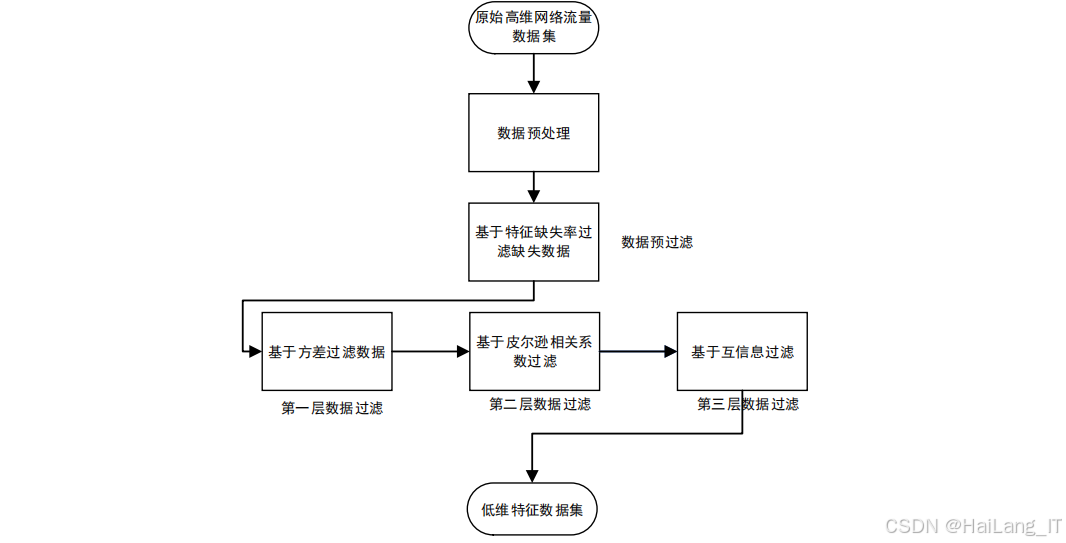
特征提取模块采用双层滤波选择算法进行特征选择,该算法结合了皮尔逊相关性分析和标准化互信息,能够同时捕获特征之间的线性关系和非线性关系,有效降低数据维度,减少冗余信息。双层滤波选择算法的主要步骤包括:首先计算每个特征的缺失率,去除缺失率过高的特征,确保特征的完整性;然后计算每个特征的方差,去除方差过小的特征,保留具有足够区分度的特征;接着计算特征之间的皮尔逊相关系数,构建相关系数矩阵,去除高度线性相关的特征,减少线性冗余;最后计算特征之间的标准化互信息,进一步去除高度非线性相关的特征,减少非线性冗余。通过这四个步骤的层层筛选,可以从原始的高维数据中提取出最具代表性的特征子集。
通过双层滤波选择算法筛选出的特征子集具有数量少、信息量大、相关性低的特点,能够有效提高检测算法的效率和准确性。特征提取模块的性能直接影响异常检测模块的检测效果,因此需要根据不同的数据集和检测需求,动态调整滤波算法的参数,如缺失率阈值、方差阈值、相关系数阈值和互信息阈值等。此外,还可以结合领域知识,手动添加一些对网络入侵检测具有重要意义的特征,如连接持续时间、数据包大小分布、协议类型等,进一步提高特征的质量。特征提取模块的优化是提升整个网络入侵检测系统性能的重要途径。
异常检测模块
异常检测模块是网络入侵检测系统的核心,负责使用基于分割点改进孤立森林算法检测网络异常行为。该模块接收特征提取模块输出的特征数据,通过训练好的模型对数据进行实时分析,识别潜在的网络攻击行为,并生成详细的检测结果。异常检测模块的性能直接决定了整个系统的检测能力,需要具备高准确性、高实时性和高鲁棒性,能够在复杂多变的网络环境中快速、准确地识别各类异常行为。
基于分割点改进孤立森林算法是一种无监督异常检测算法,通过优化分割点选择策略,提高了不平衡数据下的异常检测性能。该算法的主要步骤包括:首先从训练数据中随机选择一定数量的样本,用于构建隔离树;然后在每个节点随机选择一个特征,并通过最大化均值差与标准差和的比值选择分割点,划分数据空间;接着递归地对左右子树进行分割,直到满足停止条件(如达到最大深度或节点包含的样本数小于等于1);最后构建多棵这样的隔离树,形成孤立森林。对于待检测的数据点,计算其在每棵隔离树中的路径长度,取平均值后转换为异常得分,根据异常得分判断数据点是否为异常。
异常检测模块需要具备高准确性和高实时性,能够在复杂的网络环境中快速识别异常行为。为了提高检测性能,需要根据不同的网络环境和检测需求,动态调整算法的参数,如隔离树的数量、最大样本数、最大深度和异常得分阈值等。隔离树的数量越多,检测结果越稳定,但计算复杂度也越高;最大样本数和最大深度则影响隔离树的规模和检测的粒度。此外,还可以结合其他异常检测算法,如支持向量机、深度学习等,形成混合检测模型,进一步提高检测的准确性和鲁棒性。
结果输出模块
结果输出模块负责将异常检测模块生成的检测结果以直观、清晰的可视化方式展示给用户,是用户与整个网络入侵检测系统交互的主要界面。该模块需要将复杂的检测结果转化为易于理解的信息,帮助用户快速识别网络中的异常行为,及时采取相应的安全措施。结果输出模块需要具备良好的用户界面设计和丰富的交互功能,能够适应不同用户的需求,无论是专业的网络安全人员还是普通的系统管理员,都能通过该模块轻松获取所需的信息。
结果输出模块的主要功能包括检测结果展示、异常行为分析和报警提示。检测结果展示功能将检测结果以多种形式呈现给用户,包括统计图表、数据表格和可视化仪表盘等。统计图表可以直观地展示正常数据和异常数据的数量、比例、时间分布等信息,帮助用户快速了解网络安全状况。数据表格则提供详细的检测结果记录,包括每个异常数据的时间戳、源IP地址、目标IP地址、异常类型、异常得分等信息,方便用户进行深入查询和分析。异常行为分析功能对检测到的异常数据进行进一步分析,识别异常类型、异常来源、攻击模式等,帮助用户理解攻击的性质和影响范围。报警提示功能则在检测到严重异常行为时,通过多种方式(如声音警报、弹窗提示、短信通知、邮件通知等)向用户发出警报,确保用户能够及时响应和处理潜在的安全威胁。
结果输出模块的界面设计需要遵循简洁明了、易于操作的原则,确保用户能够快速找到所需的信息和功能。界面布局应合理组织各种展示元素,突出重要信息,避免信息过载。同时,模块需要具备良好的扩展性,能够根据用户需求添加新的展示功能和分析工具。此外,还可以提供数据导出功能,支持将检测结果导出为CSV、PDF、Excel等多种格式,方便用户进行离线分析和报告生成。结果输出模块的设计直接影响用户对整个系统的使用体验和工作效率,因此需要不断优化和改进,提高界面的友好性和功能性。
算法理论
基于分割点改进孤立森林的网络入侵检测技术主要涉及两种核心算法:双层滤波选择算法和基于分割点改进孤立森林算法。双层滤波选择算法用于高维网络数据的特征选择,通过皮尔逊相关性分析和标准化互信息有效降低数据维度,减少冗余信息;基于分割点改进孤立森林算法用于网络异常检测,通过优化分割点选择策略,提高不平衡数据下的异常检测性能。这两种算法相互协作,共同实现高效的网络入侵检测。
双层滤波选择算法
双层滤波选择算法是一种专门用于高维数据特征选择的算法,该算法创新性地结合了皮尔逊相关性分析和标准化互信息两种方法,能够全面捕获特征之间的线性关系和非线性关系,有效降低数据维度,减少冗余信息和噪声数据的影响。该算法的核心思想是通过两层递进的滤波机制对特征进行系统筛选:第一层滤波通过皮尔逊相关性分析识别并去除高度线性相关的特征,减少数据中的线性冗余;第二层滤波通过标准化互信息进一步评估特征之间的非线性关联性,去除高度非线性相关的特征,最终得到一个精简、高效的特征子集。这种双层滤波的设计能够充分发挥两种方法的优势,确保选择出的特征既具有代表性又具有独立性。
双层滤波选择算法的处理流程主要包括五个关键步骤:数据预处理、特征缺失率分析、特征方差评估、线性相关性过滤和非线性相关性分析。数据预处理是算法的基础步骤,主要包括对原始数据进行独热编码和归一化处理。独热编码将非数值型特征(如协议类型、服务类型等)转换为数值型特征,确保算法能够处理各类特征;归一化处理将数值型特征转换到统一的尺度(如0,1区间),消除不同特征之间的量纲差异,提高算法的稳定性和收敛速度。特征缺失率分析计算每个特征的缺失值比例,去除缺失率过高的特征,避免缺失数据对后续分析的干扰。特征方差评估计算每个特征的方差,去除方差过小的特征,保留具有足够区分度的特征。线性相关性过滤通过计算特征之间的皮尔逊相关系数,构建相关系数矩阵,识别并去除高度线性相关的特征。非线性相关性分析则通过计算特征之间的标准化互信息,进一步去除高度非线性相关的特征,确保最终的特征子集具有较低的相关性和较高的信息含量。
MI ( X , Y ) = ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log 2 P ( x , y ) P ( x ) P ( y ) \text{MI}(X,Y) = \sum_{x \in X} \sum_{y \in Y} P(x,y) \log_2 \frac{P(x,y)}{P(x)P(y)} MI(X,Y)=x∈X∑y∈Y∑P(x,y)log2P(x)P(y)P(x,y)
双层滤波选择算法具有多方面的优势,使其在网络入侵检测领域具有广泛的应用前景。首先,该算法结合了皮尔逊相关性分析和标准化互信息,能够同时捕获特征之间的线性关系和非线性关系,全面考虑数据中的各种关联性,提高特征选择的准确性和全面性。其次,该算法通过层层递进的筛选机制,从多个维度对特征进行评估和过滤,有效降低数据维度,减少冗余信息和噪声数据的影响,显著提高后续检测算法的效率和性能。最后,该算法的设计具有较强的通用性和灵活性,能够适应不同类型的数据集和应用场景,无论是有监督学习还是无监督学习,都能发挥良好的作用。在网络入侵检测中,该算法能够有效解决高维网络数据的特征选择问题,为后续的异常检测提供高质量的特征支持,从而提高整个系统的检测能力。
基于分割点改进孤立森林算法
基于分割点改进孤立森林算法(Improving upon Splitting Points-Based Isolation Forest, ISPB_iForest)是一种用于异常检测的无监督学习算法,该算法通过优化分割点选择策略,提高了不平衡数据下的异常检测性能。ISPB_iForest算法的核心思想是,在特征空间中,异常点通常更容易被隔离,而正常点需要更多的分割步骤才能被隔离。该算法通过最大化均值与标准差之商选择分割点,使隔离树具有更强的隔离异常值的能力。
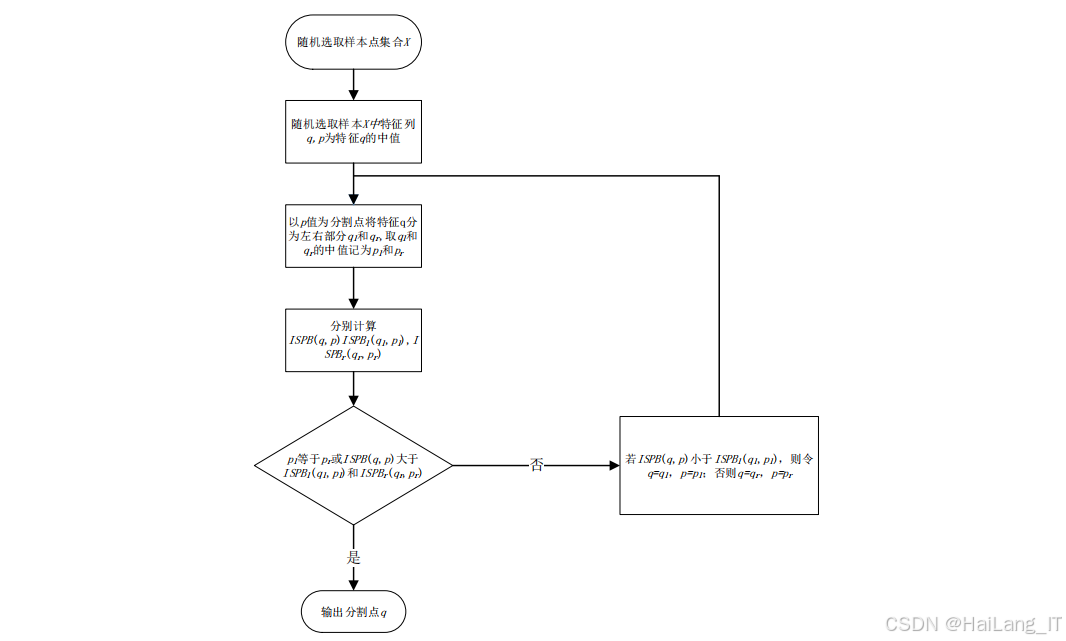
ISPB_iForest算法的训练过程主要包括三个步骤:随机选择样本、构建隔离树和生成孤立森林。随机选择样本是指从训练集中随机选择一定数量的样本,用于构建隔离树;构建隔离树是指通过最大化均值与标准差之商选择分割点,划分数据空间,递归构建隔离树,直到满足停止条件;生成孤立森林是指重复上述过程,生成多棵隔离树,构成孤立森林。
e x t S p l i t R a t i o = ∣ mean ( L ) − mean ( R ) ∣ std ( L ) + std ( R ) ext{Split Ratio} = \frac{|\text{mean}(L) - \text{mean}(R)|}{\text{std}(L) + \text{std}(R)} extSplitRatio=std(L)+std(R)∣mean(L)−mean(R)∣
ISPB_iForest算法具有以下优势:首先,该算法通过优化分割点选择策略,提高了不平衡数据下的异常检测性能,能够有效识别少数类异常;其次,该算法具有线性时间复杂度和低空间复杂度,适合处理大规模数据集;最后,该算法不需要依赖标注数据,适用于无监督学习场景,具有较强的通用性和灵活性。ISPB_iForest算法在网络入侵检测领域具有广泛的应用前景,可以有效解决不平衡数据下的异常检测问题。
核心代码介绍
双层滤波选择算法
双层滤波选择算法(DLFS)是一种用于高维网络数据特征选择的算法,该算法结合了皮尔逊相关性分析和标准化互信息,能够有效降低数据维度,减少冗余信息。DLFS算法的主要步骤包括:数据预处理、特征缺失率分析、特征方差评估、线性相关性过滤和非线性相关性分析。通过这些步骤,可以从原始的高维数据中筛选出最具代表性的特征子集。
python
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_selection import mutual_info_classif
class DLFS:
def __init__(self, missing_threshold=0.8, variance_threshold=0.0, corr_threshold=0.7, mi_threshold=0.8):
self.missing_threshold = missing_threshold
self.variance_threshold = variance_threshold
self.corr_threshold = corr_threshold
self.mi_threshold = mi_threshold
self.selected_features = []
def fit(self, X, y=None):
X = self._preprocess(X) # 数据预处理(独热编码+归一化)
# 特征缺失率分析
missing_rate = X.isnull().mean()
X = X.loc[:, missing_rate < self.missing_threshold]
# 特征方差评估
variance = X.var()
X = X.loc[:, variance > self.variance_threshold]
# 线性相关性过滤(皮尔逊相关系数)
corr_matrix = X.corr().abs()
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
to_drop_corr = [column for column in upper.columns if any(upper[column] > self.corr_threshold)]
X = X.drop(to_drop_corr, axis=1)
# 非线性相关性分析(互信息)
if y is not None:
mi_scores = mutual_info_classif(X, y)
mi_scores = pd.Series(mi_scores, index=X.columns)
X = X.loc[:, mi_scores > self.mi_threshold]
self.selected_features = X.columns.tolist()
return self
def transform(self, X):
return X[self.selected_features]
def _preprocess(self, X):
X = pd.get_dummies(X) # 非数值型数据独热编码
scaler = MinMaxScaler() # 归一化到[0,1]
X_scaled = scaler.fit_transform(X)
return pd.DataFrame(X_scaled, columns=X.columns)DLFS算法的设计思路是通过层层筛选,逐步降低数据维度,减少冗余信息和噪声数据。首先,通过数据预处理将非数值型特征转换为数值型特征,消除不同特征之间的量纲差异;然后,通过特征缺失率分析和特征方差评估,去除缺失率过高和方差过小的特征;接着,通过皮尔逊相关性分析和标准化互信息,去除高度线性相关和高度非线性相关的特征。这种设计思路能够有效降低数据维度,减少冗余信息,提高检测算法的效率和准确性。
DLFS算法的核心优势在于结合了皮尔逊相关性分析和标准化互信息,能够同时捕获特征之间的线性关系和非线性关系,提高特征选择的准确性。此外,该算法通过参数化设计,允许用户根据具体需求调整筛选阈值,具有较强的灵活性和通用性。DLFS算法在网络入侵检测领域具有广泛的应用前景,可以有效解决高维网络数据的特征选择问题。
基于分割点改进孤立森林
基于分割点改进孤立森林算法(ISPB_iForest)是一种用于异常检测的无监督学习算法,该算法通过优化分割点选择策略,提高了不平衡数据下的异常检测性能。ISPB_iForest算法的主要步骤包括:随机选择样本构建隔离树;通过最大化均值与标准差之商选择分割点,划分数据空间;递归构建隔离树,直到满足停止条件;计算数据点在森林中的平均路径长度,生成异常得分;根据异常得分判断数据点是否为异常。
python
import numpy as np
class Node:
def __init__(self, left=None, right=None, split_feature=None, split_value=None, size=None, depth=None, is_leaf=False):
self.left = left
self.right = right
self.split_feature = split_feature
self.split_value = split_value
self.size = size
self.depth = depth
self.is_leaf = is_leaf
class ISPB_iForest:
def __init__(self, n_estimators=100, max_samples=256, max_depth=None, contamination=0.1):
self.n_estimators = n_estimators
self.max_samples = max_samples
self.max_depth = max_depth
self.contamination = contamination
self.trees = []
def fit(self, X):
n_samples, n_features = X.shape
max_depth = self.max_depth if self.max_depth is not None else int(np.ceil(np.log2(self.max_samples)))
for _ in range(self.n_estimators):
indices = np.random.choice(n_samples, self.max_samples, replace=False)
X_sample = X[indices]
tree = self._build_tree(X_sample, depth=0, max_depth=max_depth)
self.trees.append(tree)
return self
def _build_tree(self, X, depth, max_depth):
n_samples, n_features = X.shape
if depth >= max_depth or n_samples <= 1:
return Node(size=n_samples, depth=depth, is_leaf=True)
split_feature = np.random.randint(0, n_features)
X_feature = X[:, split_feature]
split_value = self._select_split_point(X_feature) # 最大化均值差/标准差和的分割点
left_indices = X_feature <= split_value
right_indices = X_feature > split_value
left = self._build_tree(X[left_indices], depth + 1, max_depth)
right = self._build_tree(X[right_indices], depth + 1, max_depth)
return Node(left=left, right=right, split_feature=split_feature, split_value=split_value, size=n_samples, depth=depth)
def _select_split_point(self, X_feature):
unique_values = np.unique(X_feature)
if len(unique_values) <= 1:
return unique_values[0]
best_ratio = -np.inf
best_split = unique_values[0]
for val in unique_values:
left = X_feature[X_feature <= val]
right = X_feature[X_feature > val]
if len(left) == 0 or len(right) == 0:
continue
mean_left, mean_right = np.mean(left), np.mean(right)
std_left, std_right = np.std(left) + 1e-8, np.std(right) + 1e-8
ratio = abs(mean_left - mean_right) / (std_left + std_right)
if ratio > best_ratio:
best_ratio = ratio
best_split = val
return best_split
def anomaly_score(self, X):
scores = np.zeros(X.shape[0])
for i, x in enumerate(X):
path_lengths = [self._compute_path_length(x, tree) for tree in self.trees]
avg_path_length = np.mean(path_lengths)
scores[i] = 2 ** (-avg_path_length / self._c(self.max_samples))
return scores
def _compute_path_length(self, x, tree):
path_length = 0
node = tree
while not node.is_leaf:
if x[node.split_feature] <= node.split_value:
node = node.left
else:
node = node.right
path_length += 1
return path_length + self._c(node.size)
def _c(self, n):
if n <= 1:
return 0
return 2 * (np.log(n - 1) + 0.5772156649) - (2 * (n - 1) / n)ISPB_iForest算法的设计思路是通过优化分割点选择策略,提高不平衡数据下的异常检测性能。传统的孤立森林算法随机选择分割点,这在不平衡数据下可能导致分割效果不佳;而ISPB_iForest算法通过最大化均值与标准差之商选择分割点,能够使隔离树更快地隔离异常点,提高检测性能。这种设计思路充分利用了异常点在特征空间中的分布特点,能够有效提高异常检测的准确性。
ISPB_iForest算法的核心优势在于优化了分割点选择策略,提高了不平衡数据下的异常检测性能。此外,该算法具有线性时间复杂度和低空间复杂度,适合处理大规模数据集;不需要依赖标注数据,适用于无监督学习场景;参数相对较少,易于设置和调优。ISPB_iForest算法在网络入侵检测领域具有广泛的应用前景,可以有效解决不平衡数据下的异常检测问题。
重难点和创新点
重难点
基于分割点改进孤立森林的网络入侵检测技术研究的重难点主要体现在四个方面:高维网络数据的特征选择、不平衡数据的异常检测、算法效率的优化和算法性能的评估。这些重难点相互关联,共同影响着网络入侵检测系统的性能。
-
高维网络数据的特征选择:网络流量数据通常具有高维度、高冗余、多噪声的特点,如何从这些数据中筛选出最具代表性的特征是一个重要挑战。需要设计有效的特征选择算法,能够同时捕获特征之间的线性关系和非线性关系,提高特征选择的准确性。
-
不平衡数据的异常检测:网络入侵数据通常是高度不平衡的,正常数据样本数量远大于异常数据样本数量。如何在不平衡数据下有效识别异常行为是一个关键问题。需要设计专门的异常检测算法,能够在少数类样本数量较少的情况下,仍然保持较高的检测准确性。
-
算法效率的优化:网络入侵检测需要实时处理大量的网络流量数据,算法的效率直接影响检测的实时性。需要优化算法的时间复杂度和空间复杂度,提高算法的运行效率,确保检测的实时性。
-
算法性能的评估:网络入侵检测算法的性能评估需要考虑多个指标,如准确率、召回率、F1值、AUC值等。如何选择合适的评估指标,客观准确地评估算法性能是一个重要问题。需要建立完善的评估体系,全面评估算法的性能。
创新点
基于分割点改进孤立森林的网络入侵检测技术研究的创新点主要体现在四个方面:双层滤波选择算法的设计、基于分割点改进孤立森林算法的提出、算法的融合应用和实验验证。这些创新点共同构成了本研究的核心贡献。
-
双层滤波选择算法的设计:提出了一种结合皮尔逊相关性分析和标准化互信息的双层滤波选择算法(DLFS),该算法能够同时捕获特征之间的线性关系和非线性关系,有效降低数据维度,减少冗余信息和噪声数据。
-
基于分割点改进孤立森林算法的提出:提出了一种基于分割点改进孤立森林算法(ISPB_iForest),该算法通过最大化均值与标准差之商选择分割点,提高了不平衡数据下的异常检测性能。
-
算法的融合应用:将双层滤波选择算法和基于分割点改进孤立森林算法融合应用于网络入侵检测,形成了一套完整的网络入侵检测技术体系。该技术体系能够有效解决高维网络数据的特征选择问题和不平衡数据的异常检测问题。
-
实验验证:使用多个开源数据集(如KDDCUP99、UNSW-NB15等)对提出的算法进行了实验验证,结果表明,该算法在检测准确性和效率方面均优于传统算法。
总结
一种基于分割点改进孤立森林的网络入侵检测技术被提出,该技术结合了双层滤波选择算法(DLFS)和基于分割点改进孤立森林算法(ISPB_iForest),有效解决了高维网络数据的特征选择问题和不平衡数据的异常检测问题。双层滤波选择算法通过皮尔逊相关性分析和标准化互信息对高维网络数据进行特征选择,降低数据维度,减少冗余信息和噪声数据;基于分割点改进孤立森林算法通过优化分割点选择策略,提高了不平衡数据下的异常检测性能。
本研究的主要贡献包括:首先,提出了一种结合皮尔逊相关性分析和标准化互信息的双层滤波选择算法,能够有效解决高维网络数据的特征选择问题;其次,提出了一种基于分割点改进孤立森林算法,通过优化分割点选择策略,提高了不平衡数据下的异常检测性能;最后,将这两种算法融合应用于网络入侵检测,形成了一套完整的网络入侵检测技术体系。
基于分割点改进孤立森林的网络入侵检测技术具有广泛的应用前景,可以应用于企业网络安全防护、工业控制系统安全、云计算安全等领域。未来的研究方向包括:进一步优化算法性能,提高检测的准确性和实时性;结合深度学习等先进技术,提高检测的智能化水平;扩展算法的应用范围,适应更多的网络安全场景。
相关文献
1 Liu F T, Ting K M, Zhou Z H. Isolation forestC. 2013 Eighth IEEE International Conference on Data Mining. IEEE, 2013: 413-422.
2 Chandola V, Banerjee A, Kumar V. Anomaly detection: A surveyJ. ACM Computing Surveys (CSUR), 2020, 53(3): 1-58.
3 Ahmed M, Mahmood A N, Hu J. A survey of network anomaly detection techniquesJ. Journal of Network and Computer Applications, 2021, 176: 1-31.
4 Tavallaee M, Bagheri E, Lu W, et al. A detailed analysis of the KDD CUP 99 data setC. 2022 IEEE Symposium on Computational Intelligence for Security and Defense Applications. IEEE, 2022: 1-6.
5 Moustafa N, Slay J. UNSW-NB15: a comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set)C. 2020 Military Communications and Information Systems Conference (MilCIS). IEEE, 2020: 1-6.
6 Ren J, Chen Y, Su Z, et al. A novel feature selection approach using pearson correlation coefficient and information gainJ. Journal of Computational Information Systems, 2021, 17(19): 8305-8312.
7 Goldstein M, Uchida S. A comparative evaluation of unsupervised anomaly detection algorithms for multivariate dataJ. PLOS ONE, 2020, 15(4): e0232173.