目录
[1.对于下面的有向图,应用基于DFS 的算法来解拓扑排序问题。](#1.对于下面的有向图,应用基于DFS 的算法来解拓扑排序问题。)
a.请证明,当且仅当有向图是无环时,它的拓扑排序问题才是有解的。
b.对于一个具有n个顶点的有向图,拓扑排序问题最多会有多少个不同的解?
[a.基于 DFS 的拓扑排序算法的时间效率是怎样的?](#a.基于 DFS 的拓扑排序算法的时间效率是怎样的?)
[b.我们如何修改基于DFS 的算法,使得可以避免对DFS生成的顶点序列进行逆序?](#b.我们如何修改基于DFS 的算法,使得可以避免对DFS生成的顶点序列进行逆序?)
[4.我们是否能够利用顶点进入 DFS栈的顺序(代替它们从栈中退出的顺序)来解拓扑排序问题?](#4.我们是否能够利用顶点进入 DFS栈的顺序(代替它们从栈中退出的顺序)来解拓扑排序问题?)
b.在用邻接矩阵表示的有向图中,我们如何求得一个源(或者确定这样一个顶点不存在)?这种操作的时间效率如何?
c.在用邻接链表表示的有向图中,我们如何求得一个没有输入边的顶点(或者确定这样一个顶点不存在)?这种操作的时间效率如何?
7.我们是否能够对一个用邻接矩阵表示的有向图实现源删除算法,使得它的运行时间属于O(|V|+|E|)?
8.任选一种语言实现这两种拓扑排序算法并做一个实验来比较它们的运行时间。
[9.如果对于任意两个不同的顶点u和v,存在一个从u到v的有向路径以及一条从v到u的有向路径,这样的有向图被称为是强连通(strongly connected)的。一般来说,一个有向图的顶点可以分割成一些顶点的互不相交的最大子集,每个子集的顶点之间可以通过有向图中的有向路径相互访问,这些子集被称为强连通分量(strongly connected component)。有两种基于 DFS 的算法来确定强连通分量。以下是两个中较简单(但效率较低)的一种。](#9.如果对于任意两个不同的顶点u和v,存在一个从u到v的有向路径以及一条从v到u的有向路径,这样的有向图被称为是强连通(strongly connected)的。一般来说,一个有向图的顶点可以分割成一些顶点的互不相交的最大子集,每个子集的顶点之间可以通过有向图中的有向路径相互访问,这些子集被称为强连通分量(strongly connected component)。有两种基于 DFS 的算法来确定强连通分量。以下是两个中较简单(但效率较低)的一种。)
b.该算法属于哪种时间效率类型?对于一个输入图的邻接矩阵表示法和邻接链表表示法分别回答这个问题。
1.对于下面的有向图,应用基于DFS 的算法来解拓扑排序问题。
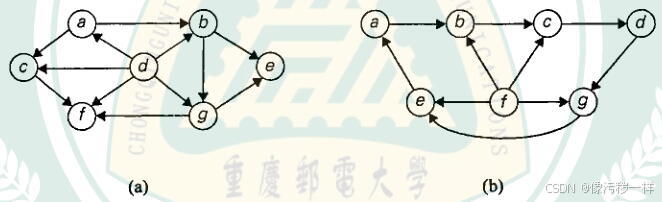
DFS 遍历(按字母顺序访问):
对于a:从a开始,a->b->e,g->f,c,d,逐次压栈,弹栈得出结果e,f,g,b,c,a,d并逆序输出:
d->a->c->b->g->f->e
对于b:从a开始,a->b->c->d->g->e->a,存在回路,因此不存在拓扑排序
2.
a.请证明,当且仅当有向图是无环时,它的拓扑排序问题才是有解的。
必要性:
用反证法:假设图中存在环 v1→v2→⋯→vk→v1。在拓扑排序中,所有边必须满足:起点在终点之前。
- 对环上的边 vi→vi+1,要求 vi 排在 vi+1 之前;
- 对最后一条边 vk→v1,要求 vk 排在 v1 之前。
这会推出 v1 排在 vk 之前,同时 vk 又排在 v1 之前,矛盾。因此,若存在拓扑排序,图中不可能有环。
充分性:
证明思路:归纳法 + 不断删除入度为 0 的顶点
- 基例:n=1,单个顶点本身就是拓扑排序。
- 归纳假设:假设所有顶点数 < n 的 DAG 都存在拓扑排序。
- 归纳步骤 :对 n 个顶点的 DAG:
- 由于图无环,必然存在至少一个入度为 0 的顶点 v(否则可沿着入边无限回溯,必然形成环)。
- 删除 v 及其所有出边,得到的子图仍是 DAG(原图无环,删除顶点不会产生新环)。
- 根据归纳假设,子图存在拓扑排序 S′。
- 将 v 放在 S′ 最前面,得到的序列 v+S′ 就是原图的一个拓扑排序。
因此,所有 DAG 都存在拓扑排序。
b.对于一个具有n个顶点的有向图,拓扑排序问题最多会有多少个不同的解?
- 当图是无边的 DAG (即没有任何边,顶点之间没有任何约束)时,顶点的任意排列都是合法的拓扑排序。
- 此时,不同的拓扑排序数量等于 n 个顶点的全排列数,即 n!。
3.
a.基于 DFS 的拓扑排序算法的时间效率是怎样的?
Θ(n^2)
b.我们如何修改基于DFS 的算法,使得可以避免对DFS生成的顶点序列进行逆序?
将长度为 |V| 的数组填充为从右到左从 DFS 遍历栈中弹出的顶点。
4.我们是否能够利用顶点进入 DFS栈的顺序(代替它们从栈中退出的顺序)来解拓扑排序问题?
**不能。**因为拓扑排序要求边 u→v 对应 u 在 v 之前,而 DFS 入栈顺序是 "先访问先入栈",这会导致后继节点 v 反而出现在前驱节点 u 之前(违反拓扑序)。必须使用退栈顺序(完成时间)** 才能保证拓扑有序。
5.对第1题中的有向图应用源删除算法。
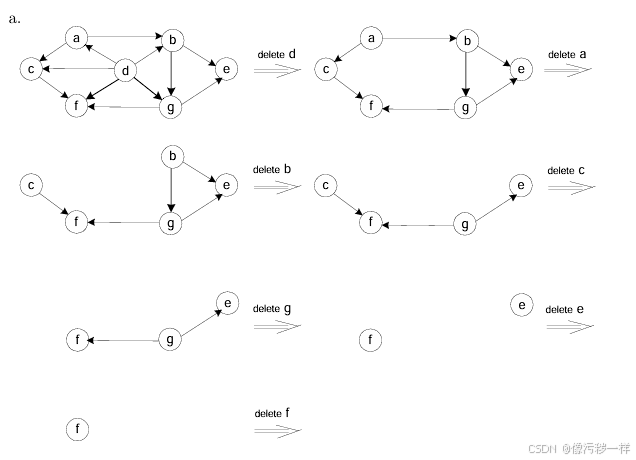
b同样不存在
6.
a.请证明一个无环有向图必定至少具有一个源。
反证法:
假设一个有向图 G 是无环的,但 G 中没有源点 ,即:所有顶点的入度 ≥ 1。
- 任取一个顶点 v0,因为入度 ≥1,存在前驱 v1→v0。
- v1 入度也 ≥1,存在前驱 v2→v1。
- 依此类推,可得一条无限长的顶点序列:⋯→v3→v2→v1→v0
- 但图中只有有限个顶点 ,根据鸽巢原理,这条路径上必有顶点重复。
- 重复顶点之间就形成了环,与 "G 无环" 矛盾。
因此假设不成立。结论:无环有向图一定至少有一个源。
b.在用邻接矩阵表示的有向图中,我们如何求得一个源(或者确定这样一个顶点不存在)?这种操作的时间效率如何?
- 对每一列 j=0,...,n−1
- 检查该列所有元素 Aij 是否都为 0
- 若全 0,则 j 是源;否则不是
c.在用邻接链表表示的有向图中,我们如何求得一个没有输入边的顶点(或者确定这样一个顶点不存在)?这种操作的时间效率如何?
做法:
- 先建立一个入度数组 in_degree 0..n-1,初始化为 0
- 遍历每个顶点的邻接链表:对每条边 u→v,执行
in_degree[v]++ - 遍历 in_degree 数组,找到值为 0 的顶点即为源点
时间效率:
O(n+E)
- 建入度数组:遍历所有边 O(E)
- 遍历入度数组:O(n)
7.我们是否能够对一个用邻接矩阵表示的有向图实现源删除算法,使得它的运行时间属于O(|V|+|E|)?
不能。因为邻接矩阵的大小为 |V|×|V|,查找入度为 0 的顶点与更新入度都必须花费 O (|V|) 时间,总时间为 O (|V|²),无法达到 O (|V|+|E|)。
8.任选一种语言实现这两种拓扑排序算法并做一个实验来比较它们的运行时间。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define MAXN 1000 // 最大顶点数
// 邻接表节点
typedef struct Node {
int to;
struct Node* next;
} Node;
Node* graph[MAXN]; // 邻接表
int in_degree[MAXN];// 入度数组(Kahn用)
int visited[MAXN]; // 访问标记(DFS用)
int result[MAXN]; // 结果数组
int res_idx; // 结果下标
// 创建邻接表节点
Node* createNode(int v) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->to = v;
newNode->next = NULL;
return newNode;
}
// 添加有向边 u->v
void addEdge(int u, int v) {
Node* newNode = createNode(v);
newNode->next = graph[u];
graph[u] = newNode;
in_degree[v]++;
}
// ----------------------------
// 1. DFS 拓扑排序
// ----------------------------
void dfs(int u) {
visited[u] = 1;
Node* p = graph[u];
while (p != NULL) {
int v = p->to;
if (!visited[v])
dfs(v);
p = p->next;
}
result[res_idx++] = u; // 递归结束时加入
}
void dfsTopo(int n) {
memset(visited, 0, sizeof(visited));
res_idx = 0;
for (int i = 0; i < n; i++)
if (!visited[i])
dfs(i);
// 逆序输出(真正拓扑序)
// for (int i = n-1; i >= 0; i--) printf("%d ", result[i]);
}
// ----------------------------
// 2. Kahn 源删除拓扑排序
// ----------------------------
int queue[MAXN], front, rear;
void kahnTopo(int n) {
front = rear = 0;
int cnt = 0;
for (int i = 0; i < n; i++)
if (in_degree[i] == 0)
queue[rear++] = i;
while (front < rear) {
int u = queue[front++];
cnt++;
Node* p = graph[u];
while (p != NULL) {
int v = p->to;
in_degree[v]--;
if (in_degree[v] == 0)
queue[rear++] = v;
p = p->next;
}
}
}
// ----------------------------
// 生成随机 DAG
// ----------------------------
void generateGraph(int n, int edgeNum) {
for (int i = 0; i < n; i++) {
graph[i] = NULL;
in_degree[i] = 0;
}
int cnt = 0;
while (cnt < edgeNum) {
int u = rand() % n;
int v = rand() % n;
if (u < v) { // u<v 保证无环
addEdge(u, v);
cnt++;
}
}
}
int main() {
srand((unsigned)time(NULL));
int n = 500; // 顶点数
int m = 2000; // 边数
printf("顶点数:%d,边数:%d\n", n, m);
generateGraph(n, m);
// 测试 DFS
clock_t s1 = clock();
dfsTopo(n);
clock_t e1 = clock();
printf("DFS 拓扑排序时间:%.4f ms\n", (double)(e1 - s1) * 1000 / CLOCKS_PER_SEC);
// 重新建图
generateGraph(n, m);
// 测试 Kahn
clock_t s2 = clock();
kahnTopo(n);
clock_t e2 = clock();
printf("源删除(Kahn)时间:%.4f ms\n", (double)(e2 - s2) * 1000 / CLOCKS_PER_SEC);
return 0;
}两者时间复杂度均为 O (V+E),但实际运行中,源删除算法比 DFS 更快,因为它是非递归的迭代实现,开销更小。
9.如果对于任意两个不同的顶点u和v,存在一个从u到v的有向路径以及一条从v到u的有向路径,这样的有向图被称为是强连通(strongly connected)的。一般来说,一个有向图的顶点可以分割成一些顶点的互不相交的最大子集,每个子集的顶点之间可以通过有向图中的有向路径相互访问,这些子集被称为强连通分量(strongly connected component)。有两种基于 DFS 的算法来确定强连通分量。以下是两个中较简单(但效率较低)的一种。
第一步: 对给定的有向图执行一次 DFS 遍历,然后按照顶点变成死端的顺序对它们进行编号。
第二步: 颠倒有向图中所有边的方向。
第三步: 对于新的有向图,从仍未访问过的顶点中编号最大的顶点开始(而且,如果有必要的话,可以重新开始)做一遍DFS遍历。
在最后一次遍历中得到的每一棵DFS树的顶点构成的子集就是一个强连通分量。
a.对下图应用该算法,确定它的强连通分量。
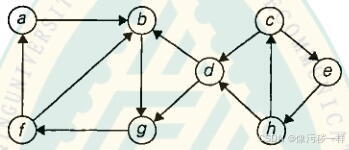
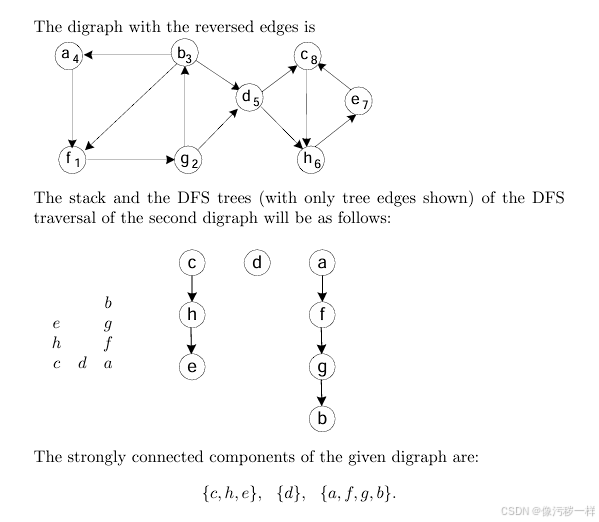
b.该算法属于哪种时间效率类型?对于一个输入图的邻接矩阵表示法和邻接链表表示法分别回答这个问题。
邻接链表:时间效率:O (|V| + |E|) 邻接矩阵:时间效率:O (|V|²)
c.一个无环有向图会有多少个强连通分量?
n 个(每个顶点自己就是一个强连通分量)