1.前置知识
1.1 云端大模型接入
进入阿里云百炼云平台,完整认证,创建API KEY:

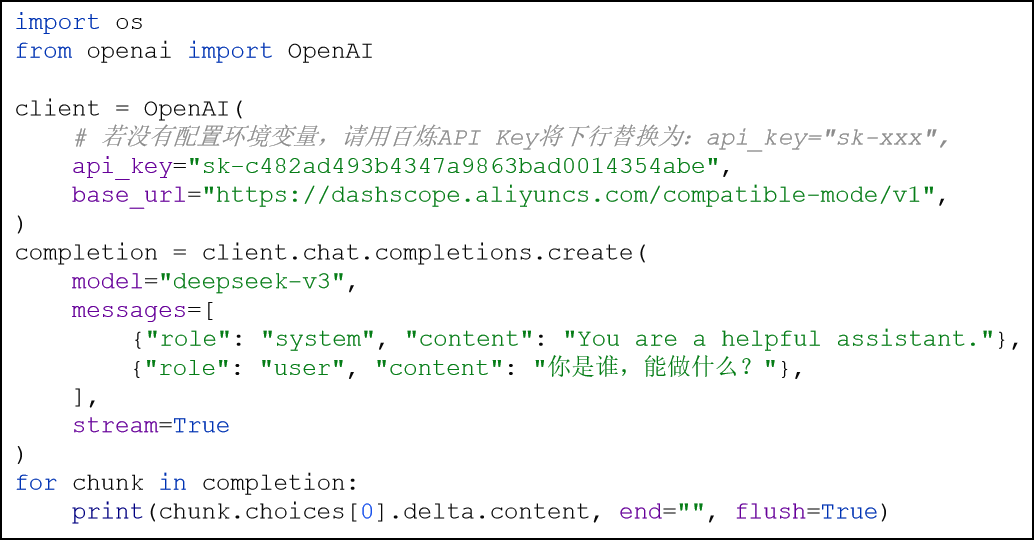
安装SDK并测试官方提供的调试代码:
python
# 基于pip安装openai库
pip install openai
安全优化:为避免在代码中明文出现APIKEY,可以使用dotenv库改造代码隐藏APIKEY
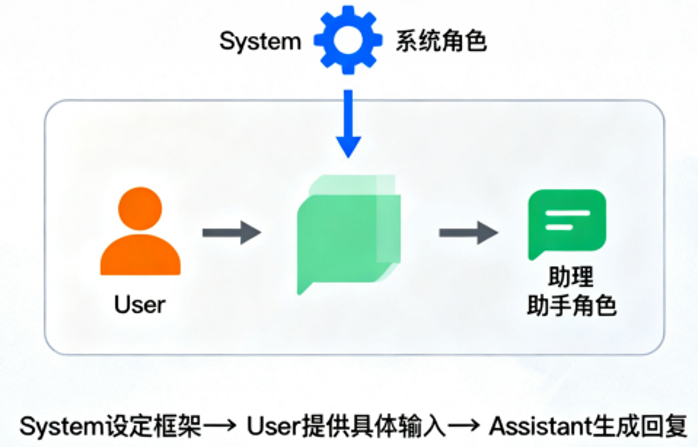
前文代码的messages是一个list,内嵌了多个字典。可以发现字典的结构是:{'role': ... , 'content': ...} 其中role表示的是角色,content表示的是内容。 在chat 大语言模型中,user、assistant、system 是三种核心角色,它们的定位和功能不同,共同构成对话的上下文结构。
使用环境变量保护APIKEY
如下代码,将APIKEY明文显示在代码中,是有很大的安全隐患的。我们可以通过环境变量来隐藏明文APIKEY。
将APIKEY暴露在代码中是不合理的 可以通过环境变量:OPENAI_API_KEY和DASHSCOPE_API_KEY记录值,代码会自动读取变量从而获取值
Windows系统通过图形化界面配置环境变量 Mac系统在终端内修改 .zshrc 文件添加环境变量 export OPENAI_API_KEY=xxx
export DASHSCOPE_API_KEY=xxx
配置完成后,重启PyCharm生效(如不生效可以重启电脑)
1.2 Ollama部署本地大模型
1.2.1 介绍
为了避免未来阿里云免费额度到期或不提供免费活动导致的无法开发,课程额外补充: 基于Ollama部署本地模型,供代码调用。
ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。 ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型) 通过ollama,开发者可以导入和定制自己的模型,无需关注复杂的底层实现细节。 网址:https://ollama.com
简单来说可以认为是阿里云百炼平台的本地版,在自己电脑上部署和运行大模型,由自己电脑的硬件提供算力支撑模型运行。
ollama 支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。用户可以根据需求选择合适的模型,并通过简单的命令行操作在本地运行。 ollama 官方模型库: https://ollama.com/library
1.2.2 本地部署
Ollama的部署还是很简单的,只需要进入官方网站点击Download按钮下载安装。 安装完成后,通过命令: ollama run 模型名称 即可运行对应的模型,并在命令行内做交互。
蒸馏模型:蒸馏模型就是对标准大模型核心技能的学习,并进行瘦身,从而获得更低的性能要求。 简单来说蒸馏模型就是标准大模型的学生,学到了老师的核心本领,但没有老师强。根据参数量的不同,参数量越大,蒸馏模型学到老师核心本领就越扎实,性能越好。
参数量选择:
集显:1.5b左右
4G独显:8b以内
8G独显:14b以内
...具体可以自己试一试 参数量越大对硬件要求越高,如果硬件能力不足,模型运算和吐字速度会下降。
1.2.3 基础命令
完成Ollama的部署和使用后,后续如果要管理电脑中的模型,可以使用Ollama命令。 主要介绍如下几个命令:
ollama list:列出当前已下载的模型
ollama pull 模型名称:联网下载指定的模型
ollama run 模型名称:运行指定的模型(如不存在会先下载)
ollama ---help:查看其它可用的命令帮助
1.2.4 代码调用Ollama本地模型
python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
)
completion = client.chat.completions.create(
model="qwen3:4b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁,能做什么?"},
],
stream=True
)
for chunk in completion:
print(chunk.choices[0].delta.content, end="", flush=True)1.3 OpenAI库
1.3.1 基础使用
OpenAI库是OpenAI官方推出的Python SDK,核心作用是让开发者能简单、高效地调用 OpenAI 的各类 API(如 GPT 聊天、DALL・E 绘图、语音转文字等),无需手动处理 HTTP 请求、身份验证等底层细节。 由于其发布较早且比较易用,现如今许多模型服务商(如阿里云百炼平台)均兼容OpenAI SDK的调用。

获取Client对象
python
# 1. 获取client对象,OpenAI类对象
client: OpenAI = OpenAI(
api_key="your_api_key_here",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)主要是用如上2个参数:
api_key:模型服务商提供的APIKEY密钥
base_url:模型服务商的API接入地址 主要基于此参数来切换不同的模型服务商(如OpenAI、阿里云、腾讯云等)
调用模型
python
# 2. 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你是一个Python编程专家,并且不说废话简单回答"},
{"role": "assistant", "content": "好的,我是编程专家,并且话不多,你要问什么?"},
{"role": "user", "content": "输出1-10的数字,使用python代码"}
]
)client.chat.completions.create创建ChatCompletion对象 主要参数有2个:
model:选择所用模型,如代码的qwen3-max
messages:提供给模型的消息 类型:list,可以包含多个字典消息
每个字典消息包含2个key
role:角色
content:内容
system角色:设定助手的整体行为、角色和规则,为对话提供上下文框架(如指定助手身份、回答风格、核心要求),是全局的背景设定,影响后续所有交互。
assistant角色:代表 AI 助手的回答,可以在代码中认为设定
user角色:代表用户,发送问题、指令或需求
处理结果
python
# 3. 处理结果
print(response.choices[0].message.content)response变量就是ChatCompletion对象,其包含信息如下所示

1.3.2 流式调用
python
from openai import OpenAI
# 1. 获取client对象,OpenAI类对象
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 2. 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你是一个Python编程专家,并且话非常多"},
{"role": "assistant", "content": "好的,我是编程专家,并且话非常多,你要问什么?"},
{"role": "user", "content": "输出1-10的数字,使用python代码"}
],
stream=True # 开启了流式输出的功能
)
# 3. 处理结果
# print(response.choices[0].message.content)
for chunk in response:
print(
chunk.choices[0].delta.content,
end=" ", # 每一段之间以空格分隔
flush=True # 立刻刷新缓冲区
)可以设定结果输出为stream模式(流式输出),获得更好的使用体验。
开启流式输出主要就2步:
在client.chat.completions.create()调用模型的时候设定参数:stream=True
for循环response对象,并在循环内输出内容
1.3.3 附带历史消息调用模型
python
from openai import OpenAI
# 1. 获取client对象,OpenAI类对象
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 2. 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你是AI助理,回答很简洁"},
{"role": "user", "content": "小明有2条宠物狗"},
{"role": "assistant", "content": "好的"},
{"role": "user", "content": "小红有3只宠物猫"},
{"role": "assistant", "content": "好的"},
{"role": "user", "content": "总共有几个宠物?"}
],
stream=True # 开启了流式输出的功能
)
# 3. 处理结果
# print(response.choices[0].message.content)
for chunk in response:
print(
chunk.choices[0].delta.content,
end=" ", # 每一段之间以空格分隔
flush=True # 立刻刷新缓冲区
)调用模型传入的参数messages,其要求是list对象,即表明其支持非常多的消息在内。
我们可以基于此,将历史消息填入,让模型知晓对话的上下文,更好的回答。
当前的历史消息是一次性的,如果是生产系统可以将消息保存到文件、数据库等持久化工具内,需要的时候提取使用 后续学习LangChain库,会学习短期记忆和长期记忆的使用方法。
1.4 LLM介绍
大语言模型 (英文:Large Language Model,缩写LLM) 是一种人工智能模型, 旨在理解和生成人类语言. 大语言模型可以处理多种自然语言任务,如文本分类、问答、翻译、对话等等.

1.4.1 语言模型LM
语言模型(Language Model)旨在建模词汇序列的生成概率,提升机器的语言智能水平,使机器能够模拟人类说话、写作的模式进行自动文本输出。
通俗理解: 用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率. 标准定义:对于某个句子序列, 如S = {W1, W2, W3, ..., Wn}, 语言模型就是计算该序列发生的概率, 即P(S). 如果给定的词序列符合语用习惯, 则给出高概率, 否则给出低概率.

1.4.2 LLM主要类别架构
LLM本身基于transformer架构。自2017年,attention is all you need诞生起,原始的transformer模型为不同领域的模型提供了灵感和启发。
基于原始的Transformer框架,衍生出了一系列模型,一些模型仅仅使用encoder或decoder,有些模型同时使用encoder+decoder。
LLM分类一般分为三种:自编码模型(encoder)、自回归模型(decoder)和序列到序列模型(encoder-decoder)。
1.4.3 自编码模型 (AutoEncoder model,AE)
AE模型,代表作BERT,其特点为:Encoder-Only, 基本原理:是在输入中随机MASK掉一部分单词,根据上下文预测这个词。AE模型通常用于内容理解任务,比如自然语言理解(NLU)中的分类任务:情感分析、提取式问答。 代表模型 BERT
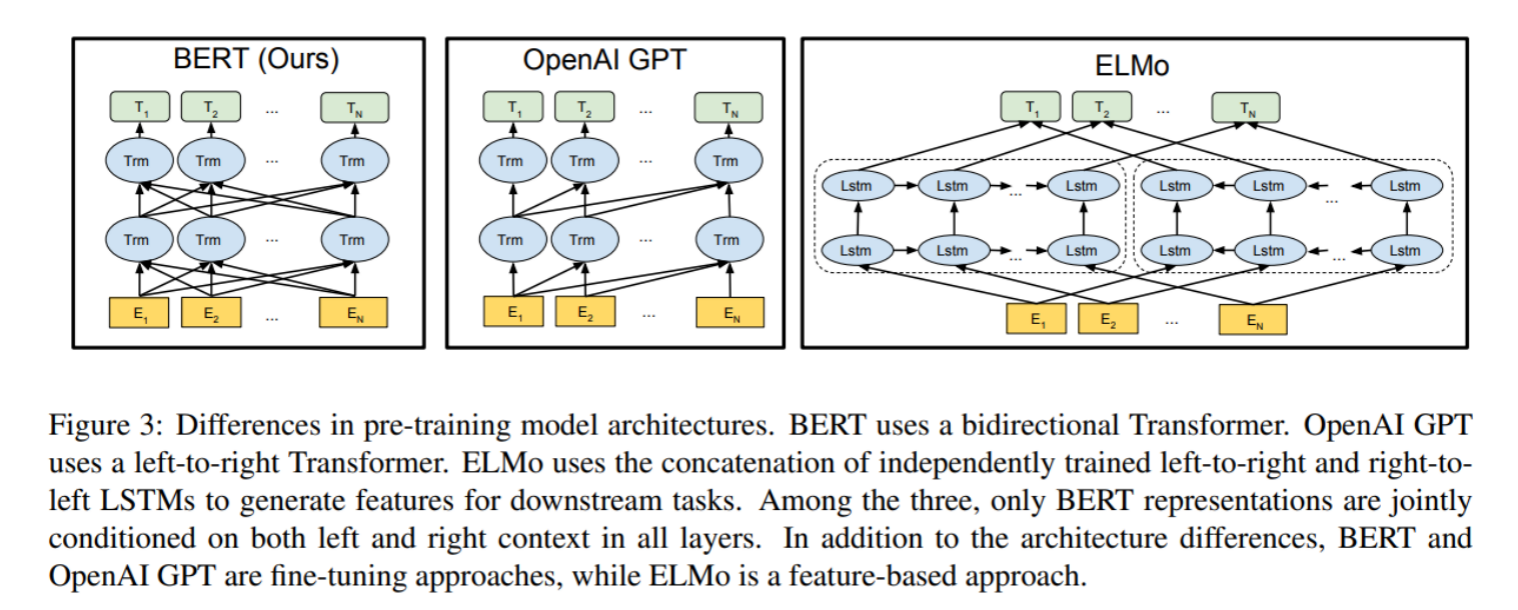
1.4.4 自回归模型 (Autoregressive model,AR)
AR模型,代表作GPT,其特点为:Decoder-Only,基本原理:从左往右学习的模型,只能利用上文或者下文的信息,比如:AR模型从一系列time steps中学习,并将上一步的结果作为回归模型的输入,以预测下一个time step的值。 AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽象问答。 代表模型 GPT
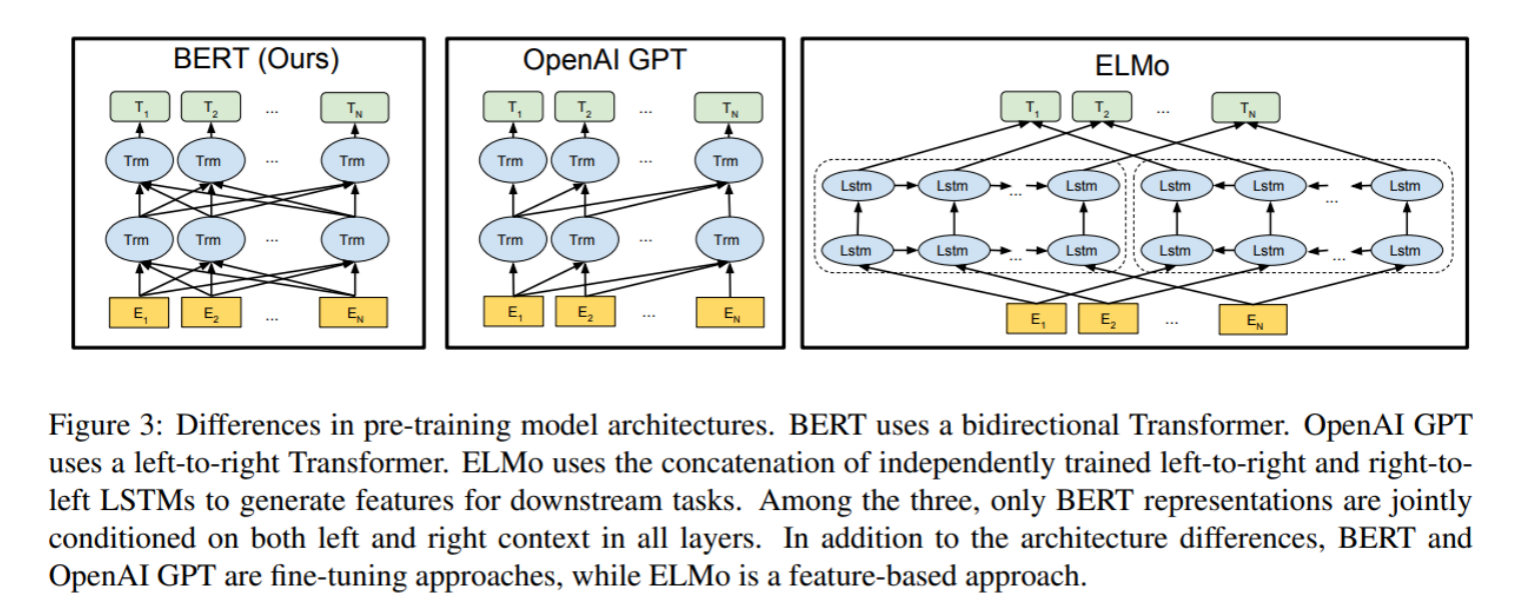
1.4.5 序列到序列(Sequence to Sequence Model)
encoder-decoder模型同时使用编码器和解码器。它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或者图像到文本的多模态任务)。对于文本分类任务来说,编码器将文本作为输入,解码器生成文本标签。 Encoder-decoder模型通常用于需要内容理解和生成的任务,比如机器翻译。 代表模型T5
1.4.6 主流LLM介绍
随着ChatGPT迅速火爆,引发了大模型的时代变革,国内外各大公司也快速跟进生成式AI市场,近百款大模型发布及应用。 目前,比较流行的开源的大语言模型主要以下几种:LLaMA大模型、ChatGLM大模型、Qwen大模型、DeepSeek大模型
|----------|----------------|----------------|------------------|-----------------|----------|----------------------|---------------|
| 模型大小 | 训练显存需求 | 推理显存需求 | CPU 内存需求 | 计算资源 | 训练时间 | 多 GPU 需求 | 推荐使用场景 |
| 7B | 20-24GB (单卡) | 10-14GB (FP16) | 16-32GB | 单卡(A100/A6000) | 数天至数周 | 可选(单卡/双卡) | 中小企业应用部署 |
| 13B | 40-48GB (双卡) | 20-26GB (FP16) | 32-64GB | 双卡(A100 40G) | 1-2周 | 双卡以上 | 企业级应用、中等负载任务 |
| 32B | 160-200GB (多卡) | 64-70GB (FP16) | 64-128GB | 4-8卡(A100/H100) | 2-4周 | 必需(4+卡) | 复杂NLP任务、云端服务 |
| 70B | 400GB+ (多卡集群) | 140GB+ (FP16) | 128-256GB | 8-16卡(H100集群) | 1-3个月 | 必需(16+卡) | 超大规模任务、行业解决方案 |
| 304B更大 | 1.5TB+ (分布式) | 600GB+ (需量化) | 512GB+ | 数百卡(超算集群) | 数月以上 | 必需(百卡级) | 国家/科研级超级计算 |
LLaMA模型
LLaMA(Large Language Model Meta AI),由 Meta AI 于2023年发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。
LLaMA训练数据是以英语为主的拉丁语系,另外还包含了来自 GitHub 的代码数据。 训练数据以英文为主,不包含中韩日文,所有训练数据都是开源的。 其中LLaMA-65B 和 LLaMA-33B 是在 1.4万亿 (1.4T) 个 token上训练的 而最小的模型 LLaMA-7B 和LLaMA-13B 是在 1万亿 (1T) 个 token 上训练的。
ChatGLM模型
ChatGLM 是清华大学提出的一个开源、支持中英双语的对话语言模型。 该模型使用了和 ChatGPT 相似的技术 经过约 1T 标识符的中英双语训练(中英文比例为 1:1) 辅以监督微调、反馈自助、人类反馈强化学习等技术的加持 62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
Qwen模型
通义千问是由阿里云自主研发的大模型,用于理解和分析用户输入的自然语言,以及图片、音频、视频等多模态数据。Qwen模型也是 Decoder-only架构,但结合前人的工作做了一些改进,比如: 位置编码:使用 RoPE(Rotary Positional Embedding),增强长文本建模能力。 归一化层:采用 RMSNorm,替代传统 LayerNorm,提升训练稳定性。 激活函数:使用 SwiGLU,相比 GeLU 能更好地提取特征。
DeepSeek模型
DeepSeek 模型是由杭州深度求索人工智能基础技术研究有限公司开发的一系列人工智能模型。该系列模型以 Transformer 架构为基础,核心采用创新的 DeepSeekMoE(混合专家)与 MLA(多头潜在注意力)技术路线,覆盖通用语言、代码、视觉、数学等多个领域.
2.大模型prompt工程指南
2.1 prompt技巧
提示工程(Prompt Engineering),也称为 In-Context Prompting,是指在不更新模型权重的情况下如何与大模型交互以引导其行为以获得所需结果的方法。
在人工智能领域,Prompt指的是用户给大型语言模型发出的指令。
例如,"「讲个笑话」"、"「用Python编个贪吃蛇游戏」"、"「写封情书」"等。 虽然看似简单,但实际上,Prompt的设计对于模型的结果影响很大。 因此如何设计prompt,进而与模型更好的交互,是研究人员必备的必不可少的技能(提示工程)。
任何Prompt技巧,都不如清晰的表达你的需求。这就类似人与人沟通,如果话说不明白,不可能让别人理解你的思想。因此,写出清晰的指令,是核心。 技巧1:详细的描述
任何Prompt技巧,都不如清晰的表达你的需求。这就类似人与人沟通,如果话说不明白,不可能让别人理解你的思想。因此,写出清晰的指令,是核心。 技巧2:让模型充当某个角色
技巧3:使用分隔符标明输入的不同部分 中括号、XML标签、三引号等分隔符可以帮助划分要区别对待的文本,也可以帮助模型更好的理解文本内容。常用''''''把内容框起来
技巧4:对任务指定步骤 对于可以拆分的任务可以尽量拆开,最好能为其指定一系列步骤,明确步骤可以让模型更容易实现它们。
技巧5:提供例子 本质类似于few-shot leaning。先扔给大模型举例,然后让模型按照例子来输出
基于文本文档,辅助大模型问答,降低模型"幻觉"(一本正经的胡说八道)问题。 即使用参考文本作答 经典的知识库用法,让大模型使用我们提供的信息来组成答案。
2.2 提示词实战案例
2.2.1 问题背景
当前金融领域信息化发展的时代,金融数据大量激增,许多投资者和研究者试图通过对这些数据进行深度分析而获得一些有效的决策和帮助,尽可能减少决策失误带来的损失。 所以,针对金融数据的分析方法研究是目前十分有益且热门的话题。
当前案例主要有三大业务场景实现:
基于大模型完成:金融文本分类
基于大模型完成:金融文本信息抽取
基于大模型完成:金融文本匹配
大模型选择:Qwen在线大模型(阿里云通义千问 qwen3-max)
采用方法:基于Few-Shot + Zero-Shot的思想,设计prompt(提示词), 进而应用大模型完成相应的任务
Zero-shot思想
Zero-shot学习(Zero-shot Learning)是指在训练阶段不存在与测试阶段完全相同的类别,但是模型可以使用训练过的知识来推广到测试集中的新类别上。
这种能力被称为"零样本"学习,因为模型在训练时从未见过测试集中的新类别,在模型训练和提示词优化中均有体现。
在模型训练中: 已知马(四脚兽)、虎(有条纹)、熊猫(黑白色)的特征,但未训练过斑马的数据(不认识)
告知模型:斑马是四脚兽、有黑白色的条纹
模型可以在已知数据中进行推理,从而识别斑马。
在提示词优化中: Zero-shot思想用于基于已训练的能力,不提供任何示例,仅通过语言去描述任务的要求、目标和约束,让模型直接生成结果。 简单来说就是"用语言定义任务,解放(信任)模型的预训练知识" 比如: 请判断""包围的用户评论中的情感倾向,输出 正面 或 负面。 "这款代餐鸡胸肉饱腹感很强,吃起来也不柴,很推荐!"
Few-shot思想
Few-shot学习(Few-shot Learning)是指少样本学习,当模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,对应的有one-shot learning,单样本学习,也算样本少到为一的情况下的一种few-shot learning。
在模型训练中(相似度判断方法): 基于少量企鹅样本并结合相识度判断,推论未知图片内含"企鹅"
在提示词优化中: Few-shot主要用于基于少量示例,让模型参考示例回答。
简单来说就是"用示例定义任务,在模型的预训练知识的基础上,提升模型回答的对齐精度(比如参考示例的格式)" 比如: 请抽取产品名称和核心卖点2个字段,格式为Json,我提供2个示例。 示例1:MacBookPro高效节能,性能强大,适合牛马工作使用 输出:{"产品名称": "MacBookPro", "产品卖点": "高效节能,性能强大"}
示例2:联想笔记本拥有RTX4060独立显卡,畅玩游戏,丝滑流畅 输出:{"产品名称": "联想笔记本", "产品卖点": "畅玩游戏,丝滑流畅"}
请处理:华为MatepadPro,高清大屏,长效续航,你的好帮手。
{"产品名称": "华为MatepadPro", "产品卖点": "高清大屏,长效续航"}
小总结:
在模型训练层面:
Zero-shot:零样本,基于模型训练阶段学习的属性/语义关联,去迁移到未知的新类别
Few-shot:少样本,基于少量样本,快速泛化识别新样本
在提示词优化层面:
Zero-shot:无提示,语言描述任务,依赖模型预训练知识回答
Few-shot:给与模型少量示例,引导模型对齐示例输出结果
2.2.2 LLM文本分类任务介绍
下面几段文本来自某平台发布的金融领域文本:
1."今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。", 2."ABC公司今日发布公告称,已成功完成对XYZ公司股权的收购交易。本次交易是ABC公司在扩大业务范围、加强市场竞争力方面的重要举措。据悉,此次收购将进一步巩固ABC公司在行业中的地位,并为未来业务发展提供更广阔的发展空间。详情请见公司官方网站公告栏", 3."公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。", 4."最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会",
我们的目的是期望模型能够帮助我们识别出这4段话中,每一句话描述的是一个什么类型的报告。 即期望的输出结果为:'新闻报道', '公司公告', '财务公告 '分析师报告'
2.2.3 Prompt设计
于大模型来讲,prompt 的设计非常重要,一个 明确 的 prompt 能够帮助我们更好从大模型中获得我们想要的结果。 在该任务的 prompt 设计中,我们主要考虑 2 点:
需要向模型解释什么叫作「文本分类任务」
需要让模型按照我们指定的格式输出
为了让模型知道什么叫做「文本分类」,我们借用 FewShot 的方式,给模型展示一些正确的例子:
bash
User: "今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。" 是['新闻报道', '公司公告', '财务公告 '分析师报告']里的什么类别?
Bot: 新闻报道
User: "本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。"是['新闻报道', '公司公告', '财务公告 '分析师报告']里的什么类别?
Bot: 财务报告 其中,User 代表我们输入给模型的句子,Bot 代表模型的回复内容。 注意:上述例子中 Bot 的部分也是由人工输入的,其目的是希望看到在看到类似 User 中的句子时,模型应当做出类似 Bot 的回答。
2.2.4 分类任务代码实现
python
from openai import OpenAI
# 1. 获取client对象,OpenAI类对象
client = OpenAI(
# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
base_url="http://localhost:11434/v1"
)
examples_data = { # 示例数据
'新闻报道': '今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。',
'财务报告': '本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。',
'公司公告': '本公司高兴地宣布成功完成最新一轮并购交易,收购了一家在人工智能领域领先的公司。这一战略举措将有助于扩大我们的业务领域,提高市场竞争力',
'分析师报告': '最新的行业分析报告指出,科技公司的创新将成为未来增长的主要推动力。云计算、人工智能和数字化转型被认为是引领行业发展的关键因素,投资者应关注这些趋势'
}
# 分类列表
examples_types = ['新闻报道', '财务报道', '公司公告', '分析师报告']
# 提问数据
questions = [
"今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",
"ABC公司今日发布公告称,已成功完成对XYZ公司股权的收购交易。本次交易是ABC公司在扩大业务范围、加强市场竞争力方面的重要举措。据悉,此次收购将进一步巩固ABC公司在行业中的地位,并为未来业务发展提供更广阔的发展空间。详情请见公司官方网站公告栏",
"公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。",
"最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会",
"小明喜欢小新哟"
]
"""
[
{"role": "system", "content": "你是金融专家,将文本分类为['新闻报道', '财务报道', '公司公告', '分析师报告'],不清楚的分类为'不清楚类别' 下面有示例:"},
{"role": "user", "content": "今日,央行发布公告宣布降............."},
{"role": "assistant", "content": "新闻报道"},
{"role": "user", "content": "ABC公司今日发布公告称,已成功完成对XYZ公司股................."},
{"role": "assistant", "content": "财务报告},
{"role": "user", "content": "公司资产负债表显示,公司偿债能力强劲,现金流充足..................."},
{"role": "assistant", "content": "公司公告"},
{"role": "user", "content": "最新的分析报告指出,可再生能源............."},
{"role": "assistant", "content": "分析师报告"},
{"role": "user", "content": "要提问的问题"}
]
"""
messages = [
{"role": "system", "content": "你是金融专家,将文本分类为['新闻报道', '财务报道', '公司公告', '分析师报告'],不清楚的分类为'不清楚类别' 下面有示例:"},
]
for key, value in examples_data.items():
messages.append({"role": "user", "content": value})
messages.append({"role": "assistant", "content": key})
# 向模型提问
for q in questions:
response = client.chat.completions.create(
# model="qwen3-max",
model="qwen3:4b",
messages=messages + [{"role": "user", "content": f"按照示例,回答这段文本的分类类别:{q}"}]
)
print(response.choices[0].message.content)2.3 JSON数据格式
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。 Json是带有格式的字符串,主要用于数据交换,即程序和程序之间的信息互传,使用Json会更加方便,如下示例:
Json主要有2种结构:Json对象和Json数组
JSON对象:
key必须是字符串 value可以是: 数字 字符串 列表 Json对象或Json数组

JSON数组:
即一堆Json对象的组合体

Json对象 => Python字典
Json数组 => Python列表内含多个字典
Json在Python中,就是 字典和列表套字典的字符串表现形式。
Python中使用Json主要完成:
将Python字典、列表转换为Json字符串
读取Json字符串,转换为Python字典或列表
主要使用Python内置的json库
json.dumps(字典或列表, ensure_ascii=False):
将字典或列表转换为Json字符串 ensure_ascii参数确保中文能正常显示 返回值:Json字符串 json.loads(json字符串):
将Json字符串转换为Python字典或列表 返回值:Python字典 或 Python列表
python
import json
d = {
"name": "周杰轮",
"age": 11,
"gender": "男"
}
s = json.dumps(d, ensure_ascii=False)
print(s)
l = [
{
"name": "周杰轮",
"age": 11,
"gender": "男"
},
{
"name": "蔡依临",
"age": 12,
"gender": "女"
},
{
"name": "小明",
"age": 16,
"gender": "男"
}
]
print(json.dumps(l, ensure_ascii=False))
json_str = '{"name": "周杰轮", "age": 11, "gender": "男"}'
json_array_str = '[{"name": "周杰轮", "age": 11, "gender": "男"}, {"name": "蔡依临", "age": 12, "gender": "女"}, {"name": "小明", "age": 16, "gender": "男"}]'
res_dict = json.loads(json_str)
print(res_dict, type(res_dict))
res_list = json.loads(json_array_str)
print(res_list, type(res_list))2.4 LLM实现金融文本信息抽取
首先,我们定义信息抽取的Schema:
python
# 定义不同实体下的具备属性
schema = {
'金融': ['日期', '股票名称', '开盘价', '收盘价', '成交量'],
}
下面几段文本来自某平台发布的股票信息:
python
1.'2023-02-15,寓意吉祥的节日,股票佰笃[BD]美股开盘价10美元,虽然经历了波动,但最终以13美元收盘,成交量微幅增加至460,000,投资者情绪较为平稳。',
2.'2023-04-05,市场迎来轻松氛围,股票盘古(0021)开盘价23元,尽管经历了波动,但最终以26美元收盘,成交量缩小至310,000,投资者保持观望态度。',
我们的目的是期望模型能够帮助我们识别出这2段话中的SPO三元组信息。
在该任务的 prompt 设计中,我们主要考虑 2 点:
需要向模型解释什么叫作「信息抽取任务」 需要让模型按照我们指定的格式(json)输出
为了让模型知道什么叫做「信息抽取」,我们借用 FewShot 的方式,先给模型展示几个正确的例子:
User:'2023-01-10,股市震荡。股票古哥-DEOOE美股今日开盘价100美元,一度飙升至105美元,随后回落至98美元,最终以102美元收盘,成交量达到520000。'。提取上述句子中"金融"('日期', '股票名称', '开盘价', '收盘价', '成交量')类型的实体,并按照JSON格式输出,上述句子中没有的信息用'原文中未提及'来表示,多个值之间用','分隔。 Bot: {'日期': '2023-01-10','股票名称': '古哥-D\[EOOE美股'],'开盘价': '100美元', '收盘价': '102美元',成交量': '520000'} ...
其中,User 代表我们输入给模型的句子,Bot 代表模型的回复内容。 注意:上述例子中 Bot 的部分也是由人工输入的,其目的是希望看到在看到类似 User 中的句子时,模型应当做出类似 Bot 的回答。
本次信息抽取任务实现的主要过程:构造prompt -> 对句子做分类 -> 进行信息抽取
python
from openai import OpenAI
import json
client = OpenAI(
# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
base_url="http://localhost:11434/v1"
)
schema = ['日期', '股票名称', '开盘价', '收盘价', '成交量']
examples_data = [ # 示例数据
{
"content": "2023-01-10,股市震荡。股票强大科技A股今日开盘价100人民币,一度飙升至105人民币,随后回落至98人民币,最终以102人民币收盘,成交量达到520000。",
"answers": {
"日期": "2023-01-10",
"股票名称": "强大科技A股",
"开盘价": "100人民币",
"收盘价": "102人民币",
"成交量": "520000"
}
},
{
"content": "2024-05-16,股市利好。股票英伟达美股今日开盘价105美元,一度飙升至109美元,随后回落至100美元,最终以116美元收盘,成交量达到3560000。",
"answers": {
"日期": "2024-05-16",
"股票名称": "英伟达美股",
"开盘价": "105美元",
"收盘价": "116美元",
"成交量": "3560000"
}
}
]
questions = [ # 提问问题
"2025-06-16,股市利好。股票传智教育A股今日开盘价66人民币,一度飙升至70人民币,随后回落至65人民币,最终以68人民币收盘,成交量达到123000。",
"2025-06-06,股市利好。股票黑马程序员A股今日开盘价200人民币,一度飙升至211人民币,随后回落至201人民币,最终以206人民币收盘。"
]
"""
[
{"role": "system", "content": f"你帮我完成信息抽取,我给你句子,你抽取{schema}信息,按JSON字符串输出,如果某些信息不存在,用'原文未提及'表示,请参考如下示例:"},
{"role": "user", "content": "2023-01-10,股市震荡。股票强大科技A股今日开盘价100人民币,一度飙升至105人民币,随后回落至98人民币,最终以102人民币收盘,成交量达到520000。"},
{"role": "assistant", "content": '{"日期":"2023-01-10","股票名称":"强大科技A股","开盘价":"100人民币","收盘价":"102人民币","成交量":"520000"}'},
{"role": "user", "content": "2024-05-16,股市利好。股票英伟达美股今日开盘价105美元,一度飙升至109美元,随后回落至100美元,最终以116美元收盘,成交量达到3560000。"},
{"role": "assistant", "content": '{"日期":"2024-05-16","股票名称":"英伟达美股","开盘价":"105美元","收盘价":"116美元","成交量":"3560000"}'},
{"role": "user", "content": f"按照上述示例,现在抽取这个句子的信息:{要抽取的句子文本}"}]}
]
"""
messages = [
{"role": "system", "content": f"你帮我完成信息抽取,我给你句子,你抽取{schema}信息,按JSON字符串输出,如果某些信息不存在,用'原文未提及'表示,请参考如下示例:"}
]
for example in examples_data:
messages.append(
{"role": "user", "content": example["content"]}
)
messages.append(
{"role": "assistant", "content": json.dumps(example["answers"], ensure_ascii=False)}
)
for q in questions:
response = client.chat.completions.create(
model="qwen3:4b",
messages=messages + [{"role": "user", "content": f"按照上述的示例,现在抽取这个句子的信息:{q}"}]
)
print(response.choices[0].message.content)2.5 LLM实现金融文本匹配


python
from openai import OpenAI
client = OpenAI(
# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
base_url="http://localhost:11434/v1"
)
examples_data = {
"是": [
("公司ABC发布了季度财报,显示盈利增长。", "财报披露,公司ABC利润上升。"),
("公司ITCAST发布了年度财报,显示盈利大幅度增长。", "财报披露,公司ITCAST更赚钱了。")
],
"不是": [
("黄金价格下跌,投资者抛售。", "外汇市场交易额创下新高。"),
("央行降息,刺激经济增长。", "新能源技术的创新。")
]
}
questions = [
("利率上升,影响房地产市场。", "高利率对房地产有一定的冲击。"),
("油价大幅度下跌,能源公司面临挑战。", "未来智能城市的建设趋势越加明显。"),
("股票市场今日大涨,投资者乐观。", "持续上涨的市场让投资者感到满意。")
]
"""
{"role": "system", "content": f"你帮我完成文本匹配,我给你2个句子,被[]包围,你判断它们是否匹配,回答是或不是,请参考如下示例:"},
{"role": "user", "content": "句子1:[公司ABC发布了季度财报,显示盈利增长。]句子2:[财报披露,公司ABC利润上升。]"},
{"role": "assistant", "content": "是"},
{"role": "user", "content": "句子1:[公司ITCAST发布了年度财报,显示盈利大幅度增长。]句子2:[财报披露,公司ITCAST更赚钱了。]"},
{"role": "assistant", "content": "是"},
{"role": "user", "content": "句子1:[黄金价格下跌,投资者抛售。]句子2:[外汇市场交易额创下新高。]"},
{"role": "assistant", "content": "不是"},
{"role": "user", "content": "句子1:[央行降息,刺激经济增长。]句子2:[新能源技术的创新。]"},
{"role": "assistant", "content": "不是"},
{"role": "user", "content": f"按照上述示例,回答这2个句子的情况。句子1: [...],句子2: [...]"}
"""
messages = [
{"role": "system", "content": f"你帮我完成文本匹配,我给你2个句子,被[]包围,你判断它们是否匹配,回答是或不是,请参考如下示例:"},
]
for key, value in examples_data.items():
for t in value:
messages.append(
{"role": "user", "content": f"句子1:[{t[0]}],句子2:[{t[1]}]"}
)
messages.append(
{"role": "assistant", "content": key}
)
for q in questions:
response = client.chat.completions.create(
model="qwen3:4b",
messages=messages + [{"role": "user", "content": f"句子1:[{q[0]}],句子2:[{q[1]}]"}]
)
print(response.choices[0].message.content)3.RAG
3.1 基础介绍
通⽤的基础⼤模型存在一些问题:
LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
幻觉问题,LLM有时会在回答中⽣成看似合理但实际上是错误的信息
数据安全性问题
RAG(Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。可以总结为一个公式:RAG = 检索技术 + LLM 提示
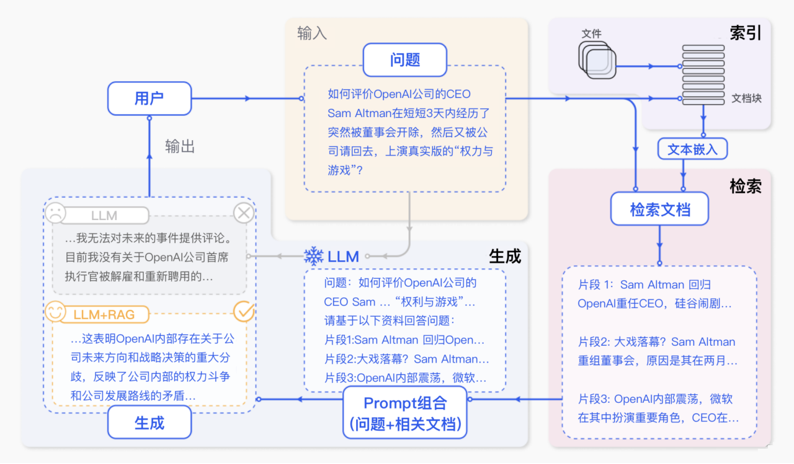
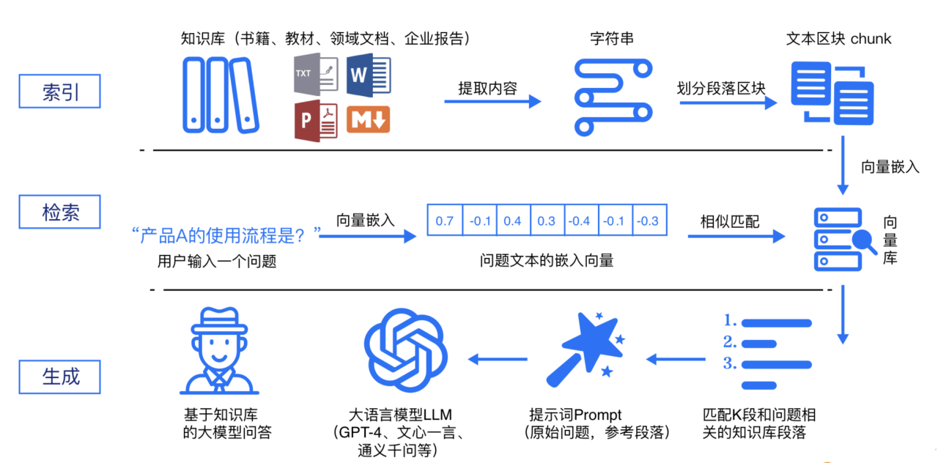
简单来说,RAG工作分为两条线: 离线准备线 / 在线服务线
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
索引阶段:
通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。 流程如下:加载文件 ,内容提取, 文本分割 ,形成chunk, 文本向量化 ,存向量数据库。
检索阶段:
用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。首先query向量化 ,之后在文本向量中匹配出与问句向量相似的top_k个
生成阶段:
检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。 匹配出的文本作为上下文和问题一起添加到prompt中 提交给LLM生成答案。
RAG的核心价值:
解决知识实效性问题:大模型的训练数据有截止时间,RAG 可以接入最新文档(如公司财报、政策文件),让模型输出 "与时俱进"。
降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅减少编造信息的概率。
无需重新训练模型:相比微调(Fine-tuning),RAG 只需更新知识库,成本更低、效率更高。
3.2 向量
RAG流程中,向量库是一个重要的节点。
离线流程:知识和信息 向量嵌入(向量化) 存入向量库
在线流程:用户的提问 向量嵌入(向量化) 在向量库中匹配
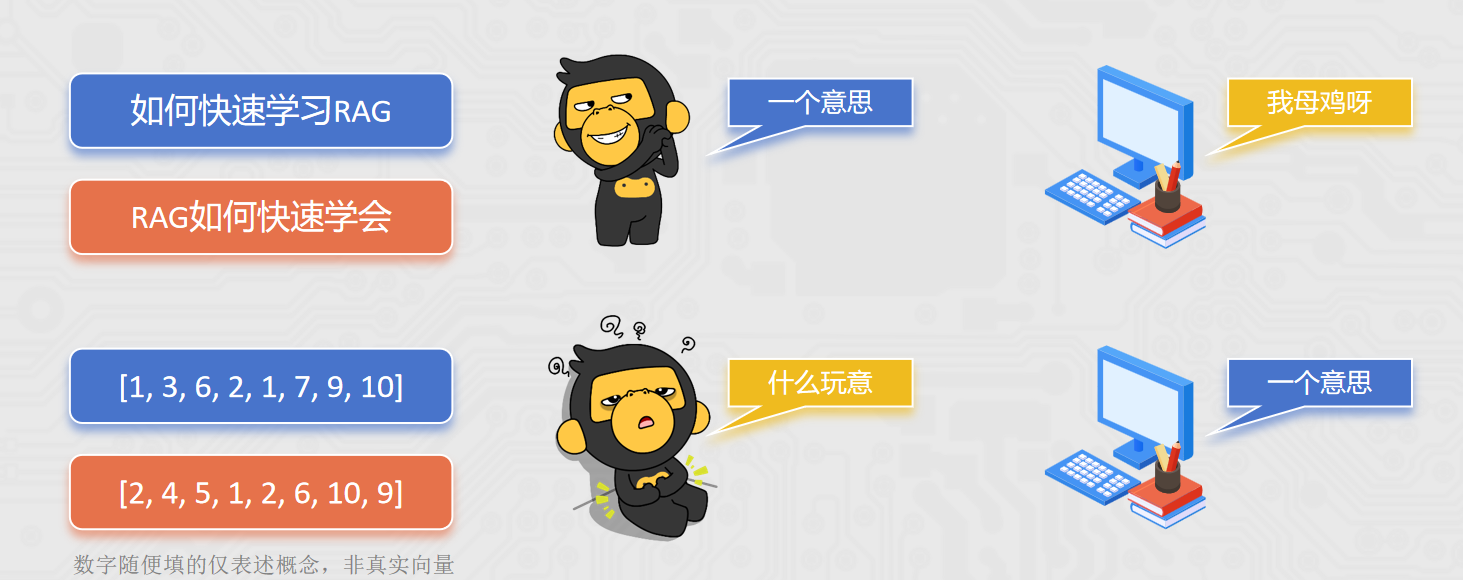
向量(Vector)就是文本的 "数学身份证":它把一段文字的语义信息,转换成一串固定长度的数字列表,让计算机能 "看懂" 文字的含义并做相似度计算。 简单来说,就是让计算机更方便的理解不同的文本内容,是否表述的是一个意思。
文本嵌入模型(如text-embedding-v1)通过深度学习等技术,从文本提取语义特征并映射为固定长度的数字序列。向量嵌入的过程,我们一般选用合适的文本嵌入模型来完成。
在向量匹配的过程中,如何识别2段文本是否表述相似的含义,主要可以通过如余弦相似度等算法来完成。 比如(下列案例中向量为示例,仅描述概念,非真实向量):
A: "如何快速学打篮球" 0.2, 0.5, 0.8
B: "打篮球怎么学得快" 0.18, 0.52, 0.79
C: "运动后吃什么好呢" 0.9, 0.1, 0.2
通过余弦相似度算法可以计算得到:A和B相似度0.999789,A和C相似度0.361446 由此可通过精确的数学计算,去匹配2段文本是否描述同一个意思,提高语义匹配的效率和精度。
如何更为精准的完成语义匹配,生成向量的维度是一个很重要的指标。
如text-embedding-v1模型,可以生成1536维的向量(一段文本固定得到1536个数字序列),比较实用。 1536个数字表示,这段文本在1536个主题(抽象的语义特征)方向上的得分(强度)

生成向量的维度越多,就更好的记录文本的语义特征,做语义匹配会更加精准。 更多的向量会在计算、存储和匹配过程中,带来更大的压力。 选择合适的向量维度需要在精确和性能之间做平衡。 一般1536维算是比较好的选择。
3.3 余弦相似度
向量的数字序列,共同决定了向量在高维空间中的方向和长度.而余弦相似度主要就是撇除长度的影响,得到方向的夹角。夹角越小越相似,即方向相同。 如何体现向量的方向和长度呢?以一维向量为例:


4. LangChain基础
4.1 简介
LangChain 由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架。LangChain自身并不开发LLMs,它的核心理念是为各种LLMs实现通用的接口,把LLMs相关的组件"链接"在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用.
LangChain是一个开发LLM相关业务功能的集大成者,是一个Python的第三方库,提供了各种功能的API。

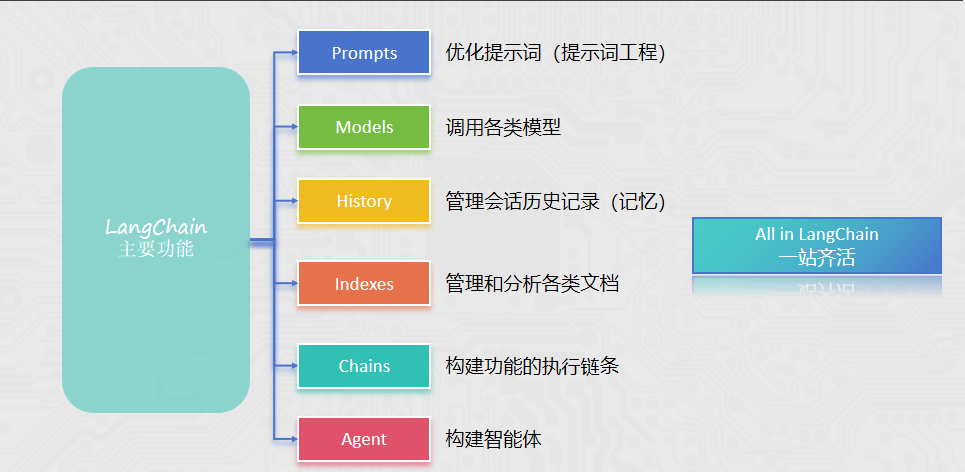
提供: 提示词优化的相关功能API ,调用各类模型的功能API, 会话记忆的相关功能API, 各类文档管理分析的功能API, 构建Agent智能体的相关功能API ,各类功能链式执行的能力
4.2 环境部署
bash
pip install langchain langchain-community langchain-ollama langchain-chroma dashscope chromadb bs4 jqlangchain:核心包
langchain-community:社区支持包,提供了更多的第三方模型调用(我们用的阿里云千问模型就需要这个包)
langchain-ollama:Ollama支持包,支持调用Ollama托管部署的本地模型
langchain-chroma:ChromaDB支持包,支持调用ChromaDB
dashscope:阿里云通义千问的Python SDK
chromadb:轻量向量数据库(后续使用)
bs4:BeautifulSqop4库,协助解析HTML文档(后续学习文档加载器使用)
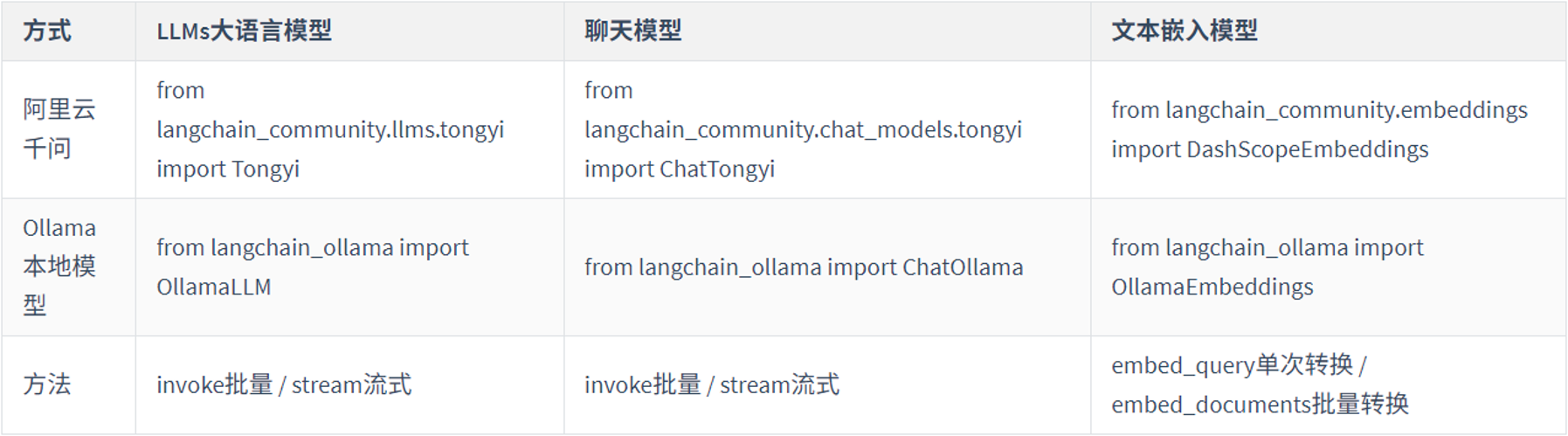
4.3 LangChain组件-Models
现在市面上的模型多如牛毛,各种各样的模型不断出现,LangChain模型组件提供了与各种模型的集成,并为所有模型提供一个精简的统一接口。
LangChain目前支持三种类型的模型:LLMs(大语言模型)、Chat Models(聊天模型)、Embeddings Models(嵌入模型).
LLMs:是技术范畴的统称,指基于大参数量、海量文本训练的 Transformer 架构模型,核心能力是理解和生成自然语言,主要服务于文本生成场景.
聊天模型:是应用范畴的细分,是专为对话场景优化的 LLMs,核心能力是模拟人类对话的轮次交互,主要服务于聊天场景
文本嵌入模型: 文本嵌入模型接收文本作为输入, 得到文本的向量.
LangChain支持的三类模型,它们的使用场景不同,输入和输出不同,开发者需要根据项目需要选择相应。阿里云通义千问系列主要来自于:langchain_community包。
LLMs使用场景最多,常用大模型的下载库:
同时LangChain支持对许多模型的调用,以通义千问为例:
python
# langchain_community
from langchain_community.llms.tongyi import Tongyi
# 不用qwen3-max,因为qwen3-max是聊天模型,qwen-max是大语言模型
model = Tongyi(model="qwen-max")
# 调用invoke向模型提问
res = model.invoke(input="你是谁呀能做什么?")
print(res)如果要访问本地Ollama的模型,简单更改一下代码。 通过langchain_ollama包导入OllamaLLM类即可(请确保Ollama已经启动并提前下载好要使用的模型)。
python
# langchain_ollama
from langchain_ollama import OllamaLLM
model = OllamaLLM(model="qwen3:4b")
res = model.invoke(input="你是谁呀能做什么?")
print(res)4.4 LangChain组件-Models的流式输出
如果需要流式输出结果,需要将模型的invoke方法改为stream方法即可。
invoke方法:一次型返回完整结果
stream方法:逐段返回结果,流式输出
python
from langchain_community.llms.tongyi import Tongyi
model = Tongyi(model="qwen-max")
# 通过stream方法获得流式输出
res = model.stream(input="你是谁呀能做什么?")
for chunk in res:
print(chunk, end="", flush=True)
python
from langchain_ollama import OllamaLLM
model = OllamaLLM(model="qwen3:4b")
res = model.stream(input="你是谁呀能做什么?")
for chunk in res:
print(chunk, end="", flush=True)4.5 LangChain组件-Models:聊天模型的使用
聊天消息包含下面几种类型,使用时需要按照约定传入合适的值:
AIMessage: 就是 AI 输出的消息,可以是针对问题的回答. (OpenAI库中的assistant角色) HumanMessage: 人类消息就是用户信息,由人给出的信息发送给LLMs的提示信息,比如"实现一个快速排序方法". (OpenAI库中的user角色)
SystemMessage: 可以用于指定模型具体所处的环境和背景,如角色扮演等。你可以在这里给出具体的指示,比如"作为一个代码专家",或者"返回json格式". (OpenAI库中的system角色)
python
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
# 得到模型对象, qwen3-max就是聊天模型
model = ChatTongyi(model="qwen3-max")
# 准备消息列表
messages = [
SystemMessage(content="你是一个边塞诗人。"),
HumanMessage(content="写一首唐诗"),
AIMessage(content="锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content="按照你上一个回复的格式,在写一首唐诗。")
]
# 调用stream流式执行
res = model.stream(input=messages)
# for循环迭代打印输出,通过.content来获取到内容
for chunk in res:
print(chunk.content, end="", flush=True)消息的简写形式:
python
from langchain_community.chat_models.tongyi import ChatTongyi
# 得到模型对象, qwen3-max就是聊天模型
model = ChatTongyi(model="qwen3-max")
# 准备消息列表
messages = [
# (角色,内容) 角色:system/human/ai
("system", "你是一个边塞诗人。"),
("human", "写一首唐诗。"),
("ai", "锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
("human", "按照你上一个回复的格式,在写一首唐诗。")
]
# 调用stream流式执行
res = model.stream(input=messages)
# for循环迭代打印输出,通过.content来获取到内容
for chunk in res:
print(chunk.content, end="", flush=True)通过2元元组封装信息; 第一个元素为角色 字符串:system/human/ai,第二个元素为内容。
区别和优势在于,使用类对象的方式,如下:

是静态的,一步到位 直接就得到了Message类的类对象
简写形式如下:

是动态的,需要在运行时 由LangChain内部机制转换为Message类对象
好处就在于,简写形式避免导包、写起来更简单,更重要的是支持:
由于是动态,需要转换步骤, 所以简写形式支持内部填充{变量}占位 ,可在运行时填充具体值(后续学习提示词模板时用到)。
4.6 LangChain组件-Models:嵌入模型的使用
Embeddings Models嵌入模型的特点:将字符串作为输入,返回一个浮点数的列表(向量)。 在NLP中,Embedding的作用就是将数据进行文本向量化。
阿里云千问模型访问方式:
python
from langchain_community.embeddings import DashScopeEmbeddings
# 创建模型对象 不传model默认用的是 text-embeddings-v1
model = DashScopeEmbeddings()
# 不用invoke stream
# embed_query、embed_documents
print(model.embed_query("我喜欢你"))
print(model.embed_documents(["我喜欢你", "我稀饭你", "晚上吃啥"]))
本地Ollama模型访问方式: 通过langchain_ollama导入OllamaEmbeddings使用,其余不变。
python
from langchain_ollama import OllamaEmbeddings
model = OllamaEmbeddings(model="qwen3-embedding:4b")
# 不用invoke stream
# embed_query、embed_documents
print(model.embed_query("我喜欢你"))
print(model.embed_documents(["我喜欢你", "我稀饭你", "晚上吃啥"]))模型小结:
4.7 LangChain组件-通用Prompts
提示词优化在模型应用中非常重要,LangChain提供了PromptTemplate类,用来协助优化提示词。 PromptTemplate表示提示词模板,可以构建一个自定义的基础提示词模板,支持变量的注入,最终生成所需的提示词。
python
from langchain_core.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
# zero-shot
prompt_template = PromptTemplate.from_template(
"我的邻居姓{lastname}, 刚生了{gender}, 你帮我起个名字,简单回答。"
)
model = Tongyi(model="qwen-max")
# 标准写法
# 调用.format方法注入信息即可
prompt_text = prompt_template.format(lastname="张", gender="女儿")
model = Tongyi(model="qwen-max")
res = model.invoke(input=prompt_text)
print(res)
# 基于chain链的写法
chain = prompt_template | model
res = chain.invoke(input={"lastname": "张", "gender": "女儿"})
print(res)4.8 LangChain组件-FewShotPromptTemplate的使用

参数:
examples:示例数据,list,内套字典
example_prompt:示例数据的提示词模板
prefix:组装提示词,示例数据前内容
suffix:组装提示词,示例数据后内容
input_variables:列表,注入的变量列表
组装FewShotPromptTemplate对象并获得最终提示词:
python
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_community.llms.tongyi import Tongyi
# 示例的模板
example_template = PromptTemplate.from_template("单词:{word}, 反义词:{antonym}")
# 示例的动态数据注入 要求是list内部套字典
examples_data = [
{"word": "大", "antonym": "小"},
{"word": "上", "antonym": "下"},
]
few_shot_template = FewShotPromptTemplate(
example_prompt=example_template, # 示例数据的模板
examples=examples_data, # 示例的数据(用来注入动态数据的),list内套字典
prefix="告知我单词的反义词,我提供如下的示例:", # 示例之前的提示词
suffix="基于前面的示例告知我,{input_word}的反义词是?", # 示例之后的提示词
input_variables=['input_word'] # 声明在前缀或后缀中所需要注入的变量名
)
prompt_text = few_shot_template.invoke(input={"input_word": "左"}).to_string()
print(prompt_text)
model = Tongyi(model="qwen-max")
print(model.invoke(input=prompt_text))4.9 LangChain组件-模板类的format和invoke方法
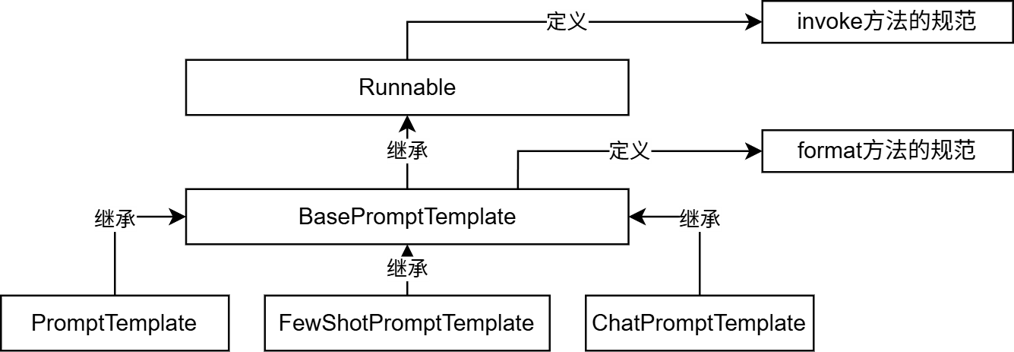
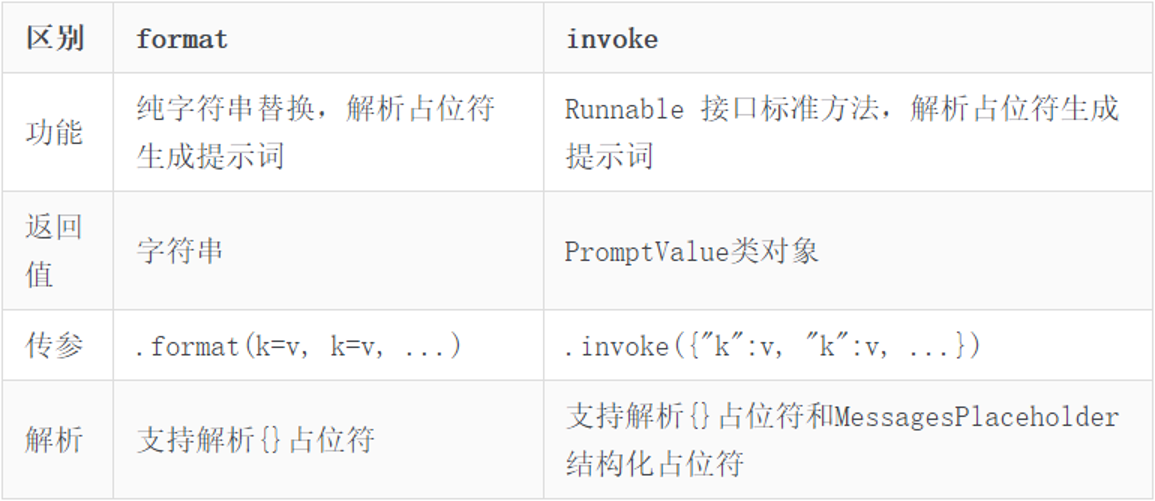
PromptTemplate、FewShotPromptTemplate、ChatPromptTemplate(后续学习)都拥有format和invoke这2类方法。
format和invoke的区别在于:
4.10 LangChain组件-ChatPromptTemplate的使用
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个边塞诗人,可以作诗。"),
MessagesPlaceholder("history"),
("human", "请再来一首唐诗"),
]
)
history_data = [
("human", "你来写一个唐诗"),
("ai", "床前明月光,疑是地上霜,举头望明月,低头思故乡"),
("human", "好诗再来一个"),
("ai", "锄禾日当午,汗滴禾下锄,谁知盘中餐,粒粒皆辛苦"),
]
# StringPromptValue to_string()
prompt_text = chat_prompt_template.invoke({"history": history_data}).to_string()
model = ChatTongyi(model="qwen3-max")
res = model.invoke(prompt_text)
print(res.content, type(res))PromptTemplate:通用提示词模板,支持动态注入信息。
FewShotPromptTemplate:支持基于模板注入任意数量的示例信息。
ChatPromptTemplate:支持注入任意数量的历史会话信息。
通过from_messages方法,从列表中获取多轮次会话作为聊天的基础模板
PS: 前面PromptTemplate类用的from_template仅能接入一条消息,而from_messages可以接入一个list的消息
历史会话信息并不是静态的(固定的),而是随着对话的进行不停地积攒,即动态的。 所以,历史会话信息需要支持动态注入。MessagePlaceholder作为占位 提供history作为占位的key 基于invoke动态注入历史会话记录 必须是invoke,format无法注入.
也可以基于聊天模型,并组装聊天历史的模式,做提示词工程。 few-shot提示方式:求反义词 examples = {"word": "开心", "antonym": "难过"}, {"word": "高", "antonym": "矮"},
4.11 LangChain组件-chains 链的基础使用
「将组件串联,上一个组件的输出作为下一个组件的输入」是 LangChain 链(尤其是 | 管道链)的核心工作原理,这也是链式调用的核心价值:实现数据的自动化流转与组件的协同工作,如下。
chain = prompt_template | model
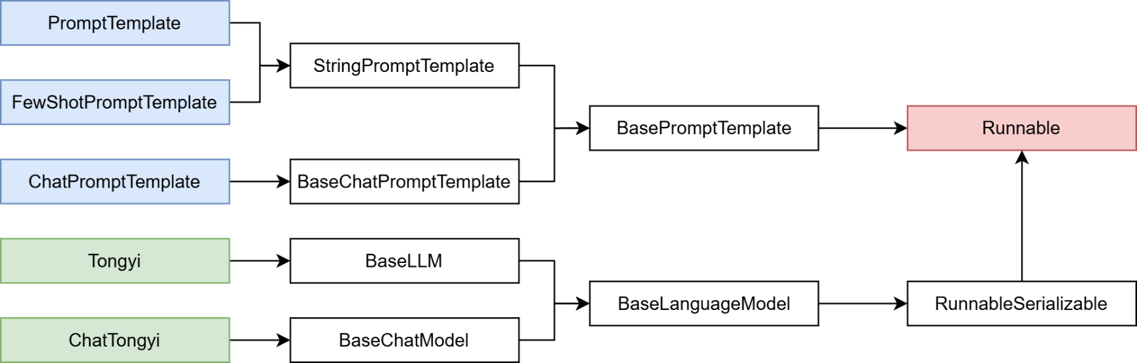
核心前提:即Runnable子类对象才能入链(以及Callable、Mapping接口子类对象也可加入(后续了解用的不多))。 我们目前所学习到的组件,均是Runnable接口的子类,如下类的继承关系:
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个边塞诗人,可以作诗。"),
MessagesPlaceholder("history"),
("human", "请再来一首唐诗"),
]
)
history_data = [
("human", "你来写一个唐诗"),
("ai", "床前明月光,疑是地上霜,举头望明月,低头思故乡"),
("human", "好诗再来一个"),
("ai", "锄禾日当午,汗滴禾下锄,谁知盘中餐,粒粒皆辛苦"),
]
model = ChatTongyi(model="qwen3-max")
# 组成链,要求每一个组件都是Runnable接口的子类
chain = chat_prompt_template | model
# 通过链去调用invoke或stream
# res = chain.invoke({"history": history_data})
# print(res.content)
# 通过stream流式输出
for chunk in chain.stream({"history": history_data}):
print(chunk.content, end="", flush=True)通过|链接提示词模板对象和模型对象
返回值chain对象是RunnableSerializable对象 是Runnable接口的直接子类 也是绝大多数组件的父类
通过invoke或stream进行阻塞执行或流式执行
组成的链在执行上有:上一个组件的输出作为下一个组件的输入的特性。 所以有如下执行流程:

4.12 LangChain组件-|运算符的重写
前文代码中: chain = chat_prompt_template | model 在语法上使用了|运算符的重写
在 Python 中,运算符(如 +、|)的行为由类的魔法方法决定。例如: a + b 本质调用的是 a.add(b) a | b 本质调用的是 a.or(b)。只需要自行实现类的__or__方法,即可对|符号的功能进行重写。
示例:
让 a|b|c 的代码得到一个自定义的类对象(类似列表即a, b, c)
调用run方法依次输出a、b、c
我们需要重写 | 即 __or__方法
python
class Test(object):
def __init__(self, name):
self.name = name
def __or__(self, other):
return MySequence(self, other)
def __str__(self):
return self.name
class MySequence(object):
def __init__(self, *args):
self.sequence = []
for arg in args:
self.sequence.append(arg)
def __or__(self, other):
self.sequence.append(other)
return self
def run(self):
for i in self.sequence:
print(i)
if __name__ == '__main__':
a = Test('a')
b = Test('b')
c = Test('c')
e = Test('e')
f = Test('f')
g = Test('g')
d = a | b | c | e | f | g # a.__or__(b)
d.run()
print(type(d))4.13 LangChain组件-StrOutputParser解析器
有如下代码,想要以第一次模型的输出结果,第二次去询问模型:

链的构建完全符合要求(参与的组件)
但是运行报错(ValueError: Invalid input type <class 'langchain_core.messages.ai.AIMessage'>. Must be a PromptValue, str, or list of BaseMessages.)
错误的主要原因是:
prompt的结果是PromptValue类型,输入给了model model的输出结果是:AIMessage
模型(ChatTongyi)源码中关于invoke方法明确指定了input的类型,需要做类型转换 可以借助LangChain内置的解析器 StrOutputParser字符串输出解析器.
StrOutputParser是LangChain内置的简单字符串解析器
可以将AIMessage解析为简单的字符串,符合了模型invoke方法要求(可传入字符串,不接收AIMessage类型)。是Runnable接口的子类(可以加入链)
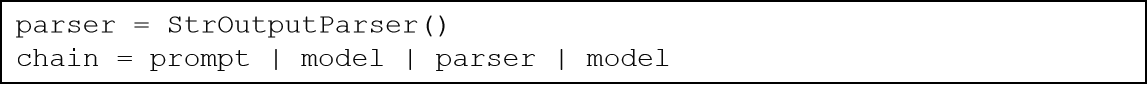
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
parser = StrOutputParser()
model = ChatTongyi(model="qwen3-max")
prompt = PromptTemplate.from_template(
"我邻居姓:{lastname},刚生了{gender},请起名,仅告知我名字无需其它内容。"
)
chain = prompt | model | parser | model | parser
res: str = chain.invoke({"lastname": "张", "gender": "女儿"})
print(res)
print(type(res))4.14 LangChain组件-Runnable接口
LangChain 中的绝大多数核心组件都继承了 Runnable 抽象基类(位于 langchain_core.runnables.base)。 代码:chain = prompt | model
chain变量是RunnableSequence(RunnableSerializable子类)类型 ,而得到这个类型的原因就是Runnable基类内部对__or__魔术方法的改写。 同时,在后面继续使用|添加新的组件,依旧会得到RunnableSequence,这就是链的基础架构。
4.15 LangChain组件-JsonOutputParser&多模型执行链
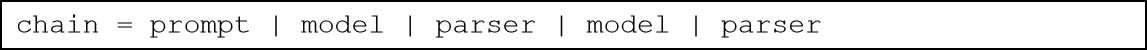
在前面我们完成了这样的需求去构建多模型链,不过这种做法并不标准,因为: 上一个模型的输出,没有被处理就输入下一个模型。 正常情况下我们应该有如下处理逻辑:
即: 上一个模型的输出结果,应该作为提示词模版的输入,构建下一个提示词,用来二次调用模型。

所以,我们需要完成: 将模型输出的AIMessage 转为字典 注入第二个提示词模板中,形成新的提示词(PromptValue对象),StrOutputParser不满足(AIMessage Str),更换JsonOutputParser(AIMessage Dict(JSON))。
python
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import PromptTemplate
# 创建所需的解析器
str_parser = StrOutputParser()
json_parser = JsonOutputParser()
# 模型创建
model = ChatTongyi(model="qwen3-max")
# 第一个提示词模板
first_prompt = PromptTemplate.from_template(
"我邻居姓:{lastname},刚生了{gender},请帮忙起名字,"
"并封装为JSON格式返回给我。要求key是name,value就是你起的名字,请严格遵守格式要求。"
)
# 第二个提示词模板
second_prompt = PromptTemplate.from_template(
"姓名:{name},请帮我解析含义。"
)
# 构建链 (AIMessage("{name: 张若曦}")
chain = first_prompt | model | json_parser | second_prompt | model | str_parser
for chunk in chain.stream({"lastname": "张", "gender": "女儿"}):
print(chunk, end="", flush=True)4.16 LangChain组件-RunnableLambda&函数加入链

前文我们根据JsonOutputParser完成了多模型执行链条的构建。除了JsonOutputParser这类固定功能的解析器之外 我们也可以自己编写Lambda匿名函数来完成自定义逻辑的数据转换,想怎么转换就怎么转换,更自由。想要完成这个功能,可以基于RunnableLambda类实现。
RunnableLambda类是LangChain内置的,将普通函数等转换为Runnable接口实例,方便自定义函数加入chain。
语法: RunnableLambda(函数对象或lambda匿名函数)
python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen3-max")
str_parser = StrOutputParser()
first_prompt = PromptTemplate.from_template(
"我邻居姓:{lastname},刚生了{gender},请帮忙起名字,仅生成一个名字,并告知我名字,不要额外信息。"
)
second_prompt = PromptTemplate.from_template(
"姓名{name},请帮我解析含义。"
)
# 函数的入参:AIMessage -> dict ({"name": "xxx"})
# my_func = RunnableLambda(lambda ai_msg: {"name": ai_msg.content})
chain = first_prompt | model | (lambda ai_msg: {"name": ai_msg.content}) | second_prompt | model | str_parser
for chunk in chain.stream({"lastname": "曹", "gender": "女孩"}):
print(chunk, end="", flush=True)4.17 LangChain组件-Memory 临时会话记忆
如果想要封装历史记录,除了自行维护历史消息外,也可以借助LangChain内置的历史记录附加功能。 LangChain提供了History功能,帮助模型在有历史记忆的情况下回答。
基于RunnableWithMessageHistory在原有链的基础上创建带有历史记录功能的新链(新Runnable实例)
基于InMemoryChatMessageHistory为历史记录提供内存存储(临时用)
python
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
model = ChatTongyi(model="qwen3-max")
# prompt = PromptTemplate.from_template(
# "你需要根据会话历史回应用户问题。对话历史:{chat_history},用户提问:{input},请回答"
# )
prompt = ChatPromptTemplate.from_messages(
[
("system", "你需要根据会话历史回应用户问题。对话历史:"),
MessagesPlaceholder("chat_history"),
("human", "请回答如下问题:{input}")
]
)
str_parser = StrOutputParser()
def print_prompt(full_prompt):
print("="*20, full_prompt.to_string(), "="*20)
return full_prompt
base_chain = prompt | print_prompt | model | str_parser
store = {} # key就是session,value就是InMemoryChatMessageHistory类对象
# 实现通过会话id获取InMemoryChatMessageHistory类对象
def get_history(session_id):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 创建一个新的链,对原有链增强功能:自动附加历史消息
conversation_chain = RunnableWithMessageHistory(
base_chain, # 被增强的原有chain
get_history, # 通过会话id获取InMemoryChatMessageHistory类对象
input_messages_key="input", # 表示用户输入在模板中的占位符
history_messages_key="chat_history" # 表示用户输入在模板中的占位符
)
if __name__ == '__main__':
# 固定格式,添加LangChain的配置,为当前程序配置所属的session_id
session_config = {
"configurable": {
"session_id": "user_001"
}
}
# res = conversation_chain.invoke({"input": "小明有2个猫"}, session_config)
# print("第1次执行:", res)
#
# res = conversation_chain.invoke({"input": "小刚有1只狗"}, session_config)
# print("第2次执行:", res)
res = conversation_chain.invoke({"input": "总共有几个宠物"}, session_config)
print("第3次执行:", res)4.18 LangChain组件-Memory 长期会话记忆
使用InMemoryChatMessageHistory仅可以在内存中临时存储会话记忆,一旦程序退出,则记忆丢失。 InMemoryChatMessageHistory 类继承自 BaseChatMessageHistory
在官方注释中给出了相关实现的指南,并给出了基于文件的历史消息存储示例代码。我们可以自行实现一个基于Json格式和本地文件的会话数据保存。
FileChatMessageHistory类实现,核心思路:
基于文件存储会话记录,以session_id为文件名,不同session_id有不同文件存储消息。
继承BaseChatMessageHistory实现如下3个方法:
add_messages:同步模式,添加消息
messages:同步模式,获取消息
clear:同步模式,清除消息
python
import os, json
from typing import Sequence
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import message_to_dict, messages_from_dict, BaseMessage
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
# message_to_dict:单个消息对象(BaseMessage类实例) -> 字典
# messages_from_dict:[字典、字典...] -> [消息、消息...]
# AIMessage、HumanMessage、SystemMessage 都是BaseMessage的子类
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件,所在的文件夹路径
# 完整的文件路径
self.file_path = os.path.join(self.storage_path, self.session_id)
# 确保文件夹是存在的
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
# Sequence序列 类似list、tuple
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的和已有的融合成一个list
# 将数据同步写入到本地文件中
# 类对象写入文件 -> 一堆二进制
# 为了方便,可以将BaseMessage消息转为字典(借助json模块以json字符串写入文件)
# 官方message_to_dict:单个消息对象(BaseMessage类实例) -> 字典
# new_messages = []
# for message in all_messages:
# d = message_to_dict(message)
# new_messages.append(d)
new_messages = [message_to_dict(message) for message in all_messages]
# 将数据写入文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property # @property装饰器将messages方法变成成员属性用
def messages(self) -> list[BaseMessage]:
# 当前文件内: list[字典]
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f) # 返回值就是:list[字典]
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)
model = ChatTongyi(model="qwen3-max")
# prompt = PromptTemplate.from_template(
# "你需要根据会话历史回应用户问题。对话历史:{chat_history},用户提问:{input},请回答"
# )
prompt = ChatPromptTemplate.from_messages(
[
("system", "你需要根据会话历史回应用户问题。对话历史:"),
MessagesPlaceholder("chat_history"),
("human", "请回答如下问题:{input}")
]
)
str_parser = StrOutputParser()
def print_prompt(full_prompt):
print("="*20, full_prompt.to_string(), "="*20)
return full_prompt
base_chain = prompt | print_prompt | model | str_parser
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
# 创建一个新的链,对原有链增强功能:自动附加历史消息
conversation_chain = RunnableWithMessageHistory(
base_chain, # 被增强的原有chain
get_history, # 通过会话id获取InMemoryChatMessageHistory类对象
input_messages_key="input", # 表示用户输入在模板中的占位符
history_messages_key="chat_history" # 表示用户输入在模板中的占位符
)
if __name__ == '__main__':
# 固定格式,添加LangChain的配置,为当前程序配置所属的session_id
session_config = {
"configurable": {
"session_id": "user_001"
}
}
# res = conversation_chain.invoke({"input": "小明有2个猫"}, session_config)
# print("第1次执行:", res)
#
# res = conversation_chain.invoke({"input": "小刚有1只狗"}, session_config)
# print("第2次执行:", res)
res = conversation_chain.invoke({"input": "总共有几个宠物"}, session_config)
print("第3次执行:", res)4.19 LangChain组件-Document loaders: 文档加载器
文档加载器提供了一套标准接口,用于将不同来源(如 CSV、PDF 或 JSON等)的数据读取为 LangChain 的文档格式。这确保了无论数据来源如何,都能对其进行一致性处理。文档加载器(内置或自行实现)需实现BaseLoader接口。
Class Document,是LangChain内文档的统一载体,所有文档加载器最终返回此类的实例。 一个基础的Document类实例,基于如下代码创建:

可以看到,Document类其核心记录了:
page_content:文档内容 metadata:文档元数据(字典)
不同的文档加载器可能定义了不同的参数,但是其都实现了统一的接口(方法)。
load():一次性加载全部文档
lazy_load():延迟流式传输文档,对大型数据集很有用,避免内存溢出。
一个简单的CSVLoader的使用示例如下:

LangChain内置了许多文档加载器,详细参见官方文档:https://docs.langchain.com/oss/python/integrations/document_loaders
我们简单的学习如下几个常用的文档加载器:
CSVLoader:
python
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(
file_path="./data/stu.csv",
csv_args={
"delimiter": ",", # 指定分隔符
"quotechar": '"', # 指定带有分隔符文本的引号包围是单引号还是双引号
# 如果数据原本有表头,就不要下面的代码,如果没有可以使用
"fieldnames": ['name', 'age', 'gender', '爱好']
},
encoding="utf-8" # 指定编码为UTF-8
)
# 批量加载 .load() -> [Document, Document, ...]
# documents = loader.load()
#
# for document in documents:
# print(type(document), document)
# 懒加载 .lazy_load() 迭代器[Document]
for document in loader.lazy_load():
print(document)JSONLoader:
JSONLoader用于将JSON数据加载为Document类型对象。
使用JSONLoader需要额外安装: pip install jq
jq是一个跨平台的json解析工具,LangChain底层对JSON的解析就是基于jq工具实现的。 将JSON数据的信息抽取出来,封装为Document对象,抽取的时候依赖jq_schema语法。

python
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./data/stu_json_lines.json",
jq_schema=".name",
text_content=False, # 告知JSONLoader 我抽取的内容不是字符串
json_lines=True # 告知JSONLoader 这是一个JSONLines文件(每一行都是一个独立的标准JSON)
)
document = loader.load()
print(document)PYPDFLoader:
LangChain内支持许多PDF的加载器,我们选择其中的PyPDFLoader使用。 PyPDFLoader加载器,依赖PyPDF库,所以,需要安装它: pip install pypdf
python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="./data/pdf2.pdf",
mode="single", # 默认是page模式,每个页面形成一个Document文档对象,
# single模式,不管有多少页,只返回1个Document对象
password="itheima"
)
i = 0
for doc in loader.lazy_load():
i += 1
print(doc)
print("="*20, i)4.20 LangChain组件-TextLoader和文档分割器
除了前文学习的三个Loader以外,还有一个基本的加载器:TextLoader
作用:读取文本文件(如.txt),将全部内容放入一个Document对象中。
RecursiveCharacterTextSplitter,递归字符文本分割器,主要用于按自然段落分割大文档。 是LangChain官方推荐的默认字符分割器。 它在保持上下文完整性和控制片段大小之间实现了良好平衡,开箱即用效果佳。
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# pip install langchain_text_splitters
loader = TextLoader("./data/Python基础语法.txt", encoding="utf-8")
docs = loader.load() # [Document]
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 分段的最大字符数
chunk_overlap=50, # 分段之间允许重叠字符数
# 文本自然段落分隔的依据符号
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?", " ", ""],
length_function=len, # 统计字符的依据函数
)
split_docs = splitter.split_documents(docs)
print(len(split_docs))
for doc in split_docs:
print("="*20)
print(doc)
print("="*20)4.21 LangChain组件-Vector stores 向量存储
基于LangChain的向量存储,存储嵌入数据,并执行相似性搜索。
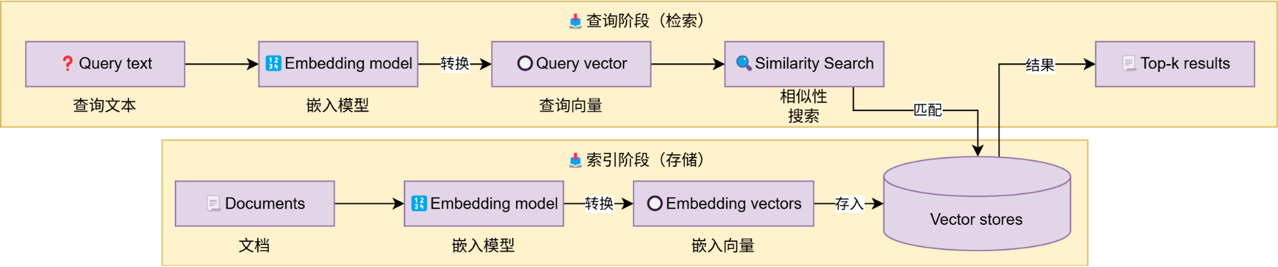
如图,这是一个典型的向量存储应用,也即是典型的RAG流程。
这部分开发主要涉及到:如何文本转向量(前文已经学习) 创建向量存储,基于向量存储完成: 存入向量 删除向量 向量检索
LangChain为向量存储提供了统一接口:
add_document,添加文档到向量存储
delete,从向量存储中删除文档
similarity_search:相似度搜索
内置向量存储的使用
python
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings()
)
loader = CSVLoader(
file_path="./data/info.csv",
encoding="utf-8",
source_column="source", # 指定本条数据的来源是哪里
)
documents = loader.load()
# id1 id2 id3 id4 ...
# 向量存储的 新增、删除、检索
vector_store.add_documents(
documents=documents, # 被添加的文档,类型:list[Document]
ids=["id"+str(i) for i in range(1, len(documents)+1)] # 给添加的文档提供id(字符串) list[str]
)
# 删除 传入[id, id...]
vector_store.delete(["id1", "id2"])
# 检索 返回类型list[Document]
result = vector_store.similarity_search(
"瑞达法",
3 # 检索的结果要几个
)
print(result)外部(Chroma)向量存储的使用
python
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
# Chroma 向量数据库(轻量级的)
# 确保 langchain-chroma chromadb 这两个库安装了的,没有的话请pip install
vector_store = Chroma(
collection_name="test", # 当前向量存储起个名字,类似数据库的表名称
embedding_function=DashScopeEmbeddings(), # 嵌入模型
persist_directory="./chroma_db" # 指定数据存放的文件夹
)
# loader = CSVLoader(
# file_path="./data/info.csv",
# encoding="utf-8",
# source_column="source", # 指定本条数据的来源是哪里
# )
#
# documents = loader.load()
# # id1 id2 id3 id4 ...
# # 向量存储的 新增、删除、检索
# vector_store.add_documents(
# documents=documents, # 被添加的文档,类型:list[Document]
# ids=["id"+str(i) for i in range(1, len(documents)+1)] # 给添加的文档提供id(字符串) list[str]
# )
#
# # 删除 传入[id, id...]
# vector_store.delete(["id1", "id2"])
# 检索 返回类型list[Document]
result = vector_store.similarity_search(
"Python是不是简单易学呀",
3, # 检索的结果要几个
filter={"source": "黑马程序员"}
)
print(result)4.22 LangChain组件-检索向量并构建提示词
python
"""
提示词:用户的提问 + 向量库中检索到的参考资料
"""
from langchain_community.chat_models import ChatTongyi
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "用户提问:{input}")
]
)
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
# 准备一下资料(向量库的数据)
# add_texts 传入一个 list[str]
vector_store.add_texts(
["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来", "跑步是很好的运动哦"])
input_text = "怎么减肥?"
# 检索向量库
result = vector_store.similarity_search(input_text, 2)
reference_text = "["
for doc in result:
reference_text += doc.page_content
reference_text += "]"
chain = prompt | print_prompt | model | StrOutputParser()
res = chain.invoke({"input": input_text, "context": reference_text})
print(res)向量存储的实例,通过add_texts(liststr)方法可以快速添加到向量存储中。
先通过向量存储检索匹配信息 将用户提问和匹配信息一同封装到提示词模板中提问模型
4.23 LangChain组件-RunnablePassthrough的使用
让向量检索加入链?
使用RunnablePassthrough类
python
"""
提示词:用户的提问 + 向量库中检索到的参考资料
"""
from langchain_community.chat_models import ChatTongyi
from langchain_core.documents import Document
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "用户提问:{input}")
]
)
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
# 准备一下资料(向量库的数据)
# add_texts 传入一个 list[str]
vector_store.add_texts(
["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来", "跑步是很好的运动哦"])
input_text = "怎么减肥?"
# langchain中向量存储对象,有一个方法:as_retriever,可以返回一个Runnable接口的子类实例对象
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
def format_func(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = "["
for doc in docs:
formatted_str += doc.page_content
formatted_str += "]"
return formatted_str
# chain
chain = (
{"input": RunnablePassthrough(), "context": retriever | format_func} | prompt | print_prompt | model | StrOutputParser()
)
res = chain.invoke(input_text)
print(res)
"""
retriever:
- 输入:用户的提问 str
- 输出:向量库的检索结果 list[Document]
prompt:
- 输入:用户的提问 + 向量库的检索结果 dict
- 输出:完整的提示词 PromptValue
"""5.RAG项目案例
5.1 项目简介
RAG即检索、增强和生成,其主要分为2条线:
离线处理:向私有知识库(向量存储)源源不断添加私有知识文档。
向知识库添加来自未来的知识文档(基于模型训练完成时间)
向模型添加私有知识文档 给出模型参考资料,规避模型幻觉(一本正经的胡说八道)
在线处理:用户提问会先基于私有知识库做检索,获取参考资料,同步组装新提示词询问大模型获取结果。
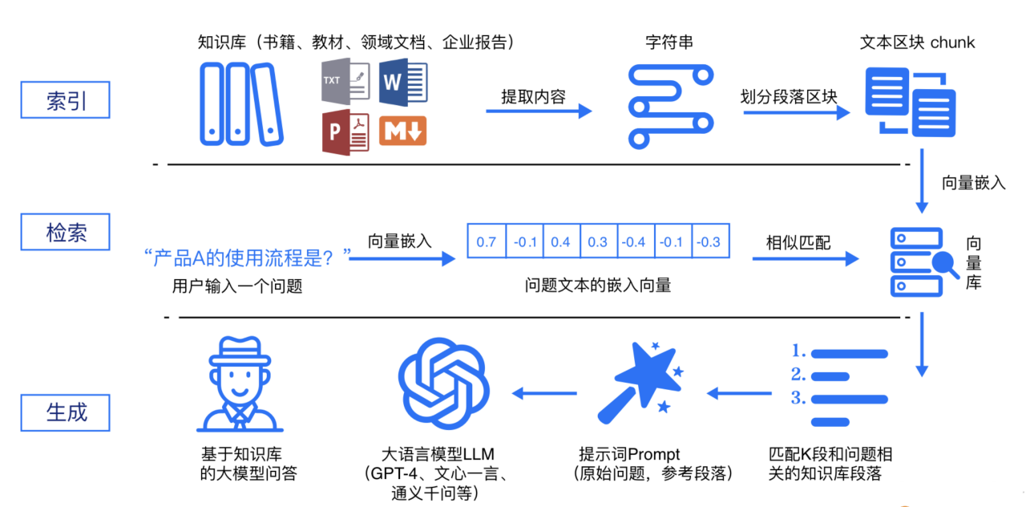
本次项目以"某东商品衣服"为例,以衣服属性构建本地知识。使用者可以自由更新本地知识,用户问题的答案也是基于本地知识生成的。
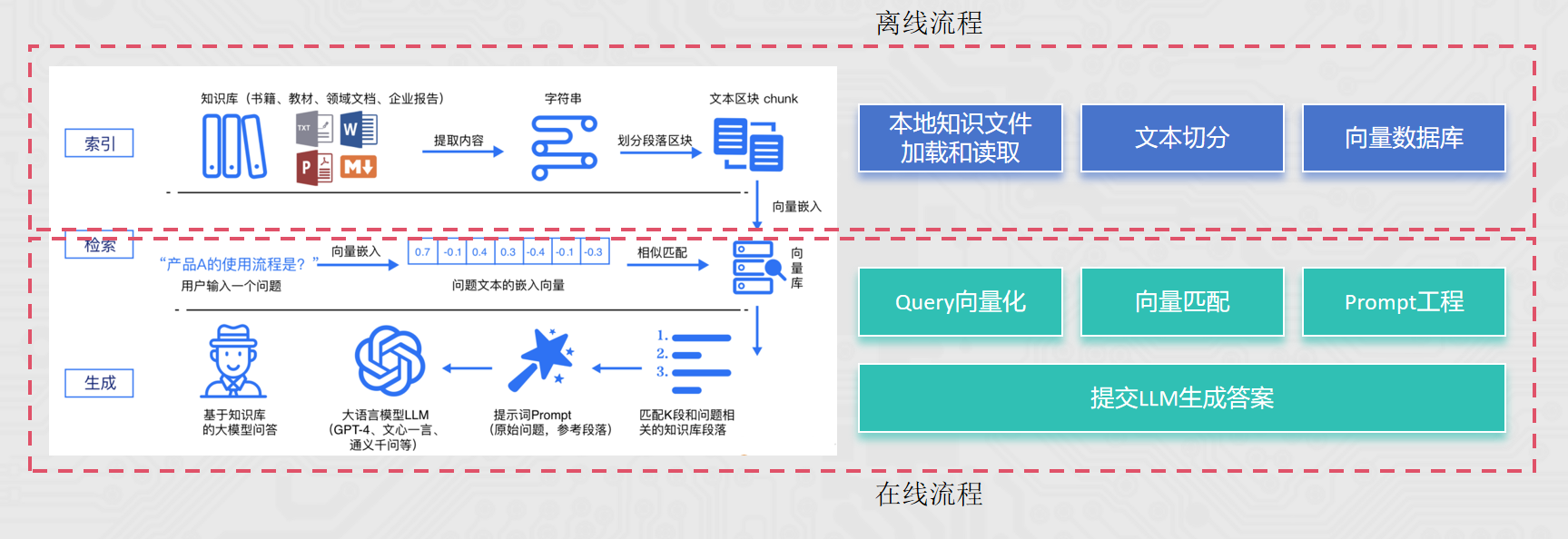
5.2 项目需求与思路


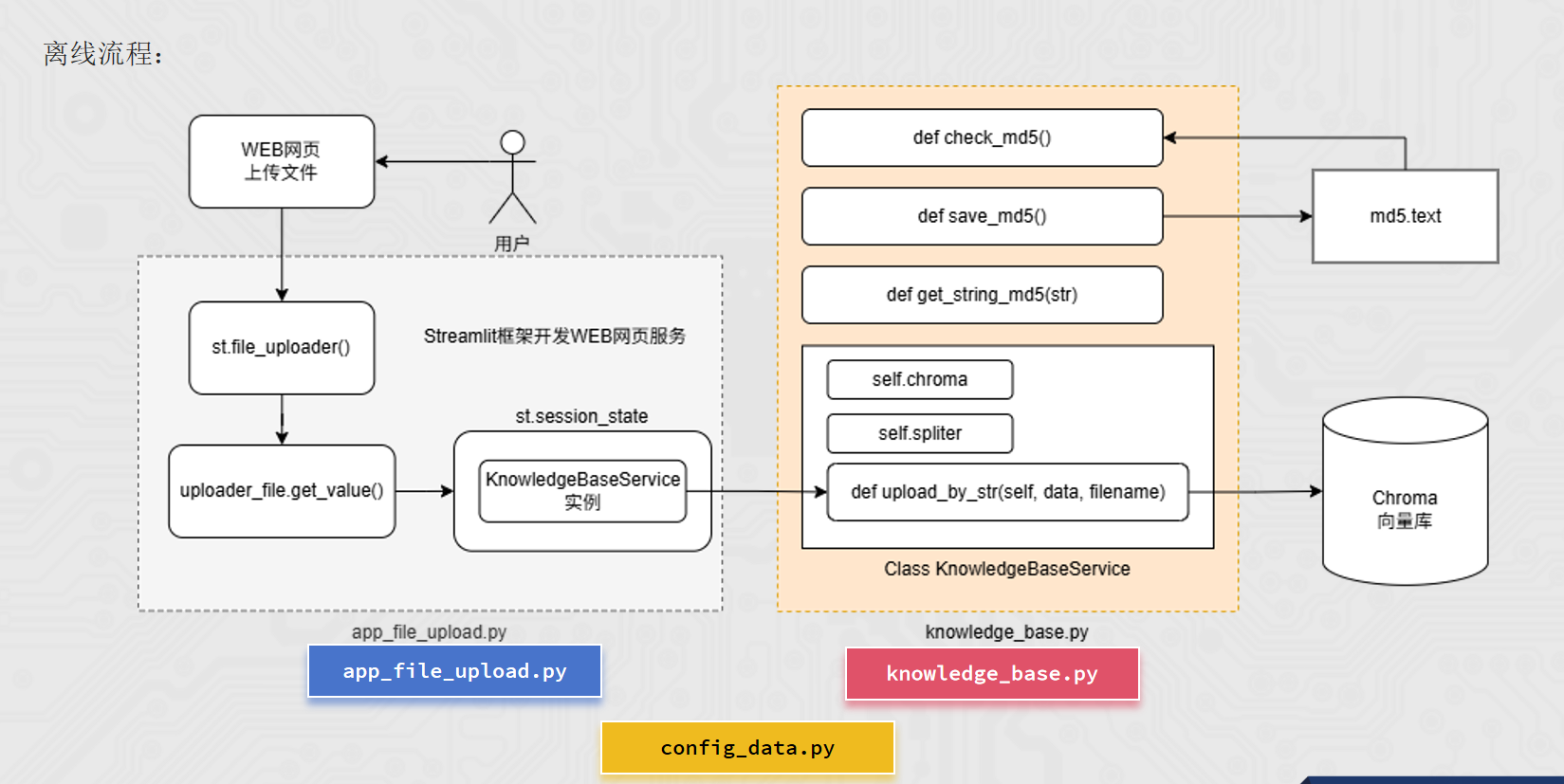
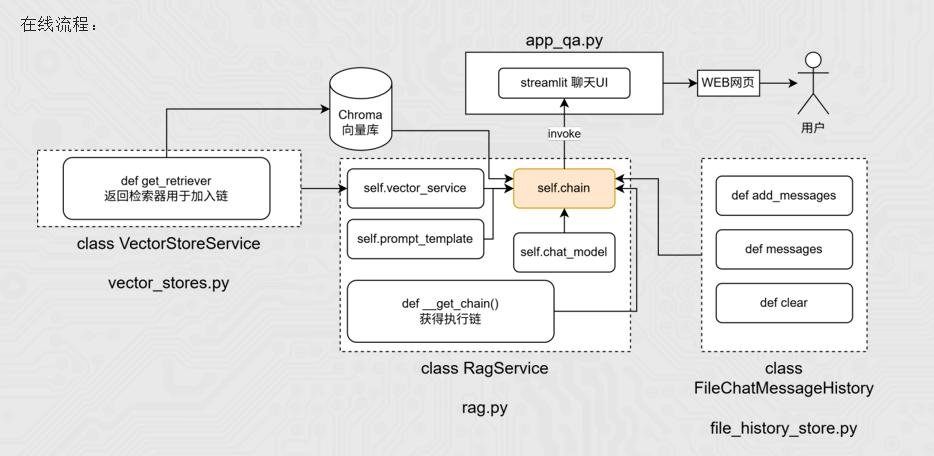
5.3 代码实现
知识库更新主程序(streamlit)
python
"""
基于Streamlit完成WEB网页上传服务
pip install streamlit
Streamlit:当WEB页面元素发生变化,则代码重新执行一遍
"""
import time
import streamlit as st
from knowledge_base import KnowledgeBaseService
# 添加网页标题
st.title("知识库更新服务")
# file_uploader
uploader_file = st.file_uploader(
"请上传TXT文件",
type=['txt'],
accept_multiple_files=False, # False表示仅接受一个文件的上传
)
# session_state就是一个字典
if "service" not in st.session_state:
st.session_state["service"] = KnowledgeBaseService()
if uploader_file is not None:
# 提取文件的信息
file_name = uploader_file.name
file_type = uploader_file.type
file_size = uploader_file.size / 1024 # KB
st.subheader(f"文件名:{file_name}")
st.write(f"格式:{file_type} | 大小:{file_size:.2f} KB")
# get_value -> bytes -> decode('utf-8')
text = uploader_file.getvalue().decode("utf-8")
with st.spinner("载入知识库中。。。"): # 在spinner内的代码执行过程中,会有一个转圈动画
time.sleep(1)
result = st.session_state["service"].upload_by_str(text, file_name)
st.write(result)项目主程序(streamlit),启动对话WEB页面
python
import time
from rag import RagService
import streamlit as st
import config_data as config
# 标题
st.title("智能客服")
st.divider() # 分隔符
if "message" not in st.session_state:
st.session_state["message"] = [{"role": "assistant", "content": "你好,有什么可以帮助你?"}]
if "rag" not in st.session_state:
st.session_state["rag"] = RagService()
for message in st.session_state["message"]:
st.chat_message(message["role"]).write(message["content"])
# 在页面最下方提供用户输入栏
prompt = st.chat_input()
if prompt:
# 在页面输出用户的提问
st.chat_message("user").write(prompt)
st.session_state["message"].append({"role": "user", "content": prompt})
ai_res_list = []
with st.spinner("AI思考中..."):
res_stream = st.session_state["rag"].chain.stream({"input": prompt}, config.session_config)
# yield
def capture(generator, cache_list):
for chunk in generator:
cache_list.append(chunk)
yield chunk
st.chat_message("assistant").write_stream(capture(res_stream, ai_res_list))
st.session_state["message"].append({"role": "assistant", "content": "".join(ai_res_list)})
# ["a", "b", "c"] "".join(list) -> abc
# ["a", "b", "c"] ",".join(list) -> a,b,c配置文件
python
md5_path = "./md5.text"
# Chroma
collection_name = "rag"
persist_directory = "./chroma_db"
# spliter
chunk_size = 1000
chunk_overlap = 100
separators = ["\n\n", "\n", ".", "!", "?", "。", "!", "?", " ", ""]
max_split_char_number = 1000 # 文本分割的阈值
#
similarity_threshold = 1 # 检索返回匹配的文档数量
embedding_model_name = "text-embedding-v4"
chat_model_name = "qwen3-max"
session_config = {
"configurable": {
"session_id": "user_001",
}
}长期会话记忆存储服务
python
import json
import os
from typing import Sequence
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件,所在的文件夹路径
# 完整的文件路径
self.file_path = os.path.join(self.storage_path, self.session_id)
# 确保文件夹是存在的
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
# Sequence序列 类似list、tuple
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的和已有的融合成一个list
# 将数据同步写入到本地文件中
# 类对象写入文件 -> 一堆二进制
# 为了方便,可以将BaseMessage消息转为字典(借助json模块以json字符串写入文件)
# 官方message_to_dict:单个消息对象(BaseMessage类实例) -> 字典
# new_messages = []
# for message in all_messages:
# d = message_to_dict(message)
# new_messages.append(d)
new_messages = [message_to_dict(message) for message in all_messages]
# 将数据写入文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property # @property装饰器将messages方法变成成员属性用
def messages(self) -> list[BaseMessage]:
# 当前文件内: list[字典]
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f) # 返回值就是:list[字典]
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)知识库更新服务
python
"""
知识库
"""
import os
import config_data as config
import hashlib
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from datetime import datetime
def check_md5(md5_str: str):
"""检查传入的md5字符串是否已经被处理过了
return False(md5未处理过) True(已经处理过,已有记录)
"""
if not os.path.exists(config.md5_path):
# if进入表示文件不存在,那肯定没有处理过这个md5了
open(config.md5_path, 'w', encoding='utf-8').close()
return False
else:
for line in open(config.md5_path, 'r', encoding='utf-8').readlines():
line = line.strip() # 处理字符串前后的空格和回车
if line == md5_str:
return True # 已处理过
return False
def save_md5(md5_str: str):
"""将传入的md5字符串,记录到文件内保存"""
with open(config.md5_path, 'a', encoding="utf-8") as f:
f.write(md5_str + '\n')
def get_string_md5(input_str: str, encoding='utf-8'):
"""将传入的字符串转换为md5字符串"""
# 将字符串转换为bytes字节数组
str_bytes = input_str.encode(encoding=encoding)
# 创建md5对象
md5_obj = hashlib.md5() # 得到md5对象
md5_obj.update(str_bytes) # 更新内容(传入即将要转换的字节数组)
md5_hex = md5_obj.hexdigest() # 得到md5的十六进制字符串
return md5_hex
class KnowledgeBaseService(object):
def __init__(self):
# 如果文件夹不存在则创建,如果存在则跳过
os.makedirs(config.persist_directory, exist_ok=True)
self.chroma = Chroma(
collection_name=config.collection_name, # 数据库的表名
embedding_function=DashScopeEmbeddings(model="text-embedding-v4"),
persist_directory=config.persist_directory, # 数据库本地存储文件夹
) # 向量存储的实例 Chroma向量库对象
self.spliter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size, # 分割后的文本段最大长度
chunk_overlap=config.chunk_overlap, # 连续文本段之间的字符重叠数量
separators=config.separators, # 自然段落划分的符号
length_function=len, # 使用Python自带的len函数做长度统计的依据
) # 文本分割器的对象
def upload_by_str(self, data: str, filename):
"""将传入的字符串,进行向量化,存入向量数据库中"""
# 先得到传入字符串的md5值
md5_hex = get_string_md5(data)
if check_md5(md5_hex):
return "[跳过]内容已经存在知识库中"
if len(data) > config.max_split_char_number:
knowledge_chunks: list[str] = self.spliter.split_text(data)
else:
knowledge_chunks = [data]
metadata = {
"source": filename,
# 2025-01-01 10:00:00
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"operator": "小曹",
}
self.chroma.add_texts( # 内容就加载到向量库中了
# iterable -> list \ tuple
knowledge_chunks,
metadatas=[metadata for _ in knowledge_chunks],
)
#
save_md5(md5_hex)
return "[成功]内容已经成功载入向量库"
if __name__ == '__main__':
service = KnowledgeBaseService()
r = service.upload_by_str("周杰轮222", "testfile")
print(r)rag核心服务
python
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableWithMessageHistory, RunnableLambda
from file_history_store import get_history
from vector_stores import VectorStoreService
from langchain_community.embeddings import DashScopeEmbeddings
import config_data as config
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
def print_prompt(prompt):
print("="*20)
print(prompt.to_string())
print("="*20)
return prompt
class RagService(object):
def __init__(self):
self.vector_service = VectorStoreService(
embedding=DashScopeEmbeddings(model=config.embedding_model_name)
)
self.prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,"
"简洁和专业的回答用户问题。参考资料:{context}。"),
("system", "并且我提供用户的对话历史记录,如下:"),
MessagesPlaceholder("history"),
("user", "请回答用户提问:{input}")
]
)
self.chat_model = ChatTongyi(model=config.chat_model_name)
self.chain = self.__get_chain()
def __get_chain(self):
"""获取最终的执行链"""
retriever = self.vector_service.get_retriever()
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
def format_for_retriever(value: dict) -> str:
return value["input"]
def format_for_prompt_template(value):
# {input, context, history}
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["history"] = value["input"]["history"]
return new_value
chain = (
{
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_document
} | RunnableLambda(format_for_prompt_template) | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
)
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="input",
history_messages_key="history",
)
return conversation_chain
if __name__ == '__main__':
# session id 配置
session_config = {
"configurable": {
"session_id": "user_001",
}
}
res = RagService().chain.invoke({"input": "针织毛衣如何保养?"}, session_config)
print(res)
向量存储服务
python
from langchain_chroma import Chroma
import config_data as config
class VectorStoreService(object):
def __init__(self, embedding):
"""
:param embedding: 嵌入模型的传入
"""
self.embedding = embedding
self.vector_store = Chroma(
collection_name=config.collection_name,
embedding_function=self.embedding,
persist_directory=config.persist_directory,
)
def get_retriever(self):
"""返回向量检索器,方便加入chain"""
return self.vector_store.as_retriever(search_kwargs={"k": config.similarity_threshold})
if __name__ == '__main__':
from langchain_community.embeddings import DashScopeEmbeddings
retriever = VectorStoreService(DashScopeEmbeddings(model="text-embedding-v4")).get_retriever()
res = retriever.invoke("我的体重180斤,尺码推荐")
print(res)