1. 执行摘要:存储范式的转移与智能基础设施的重构
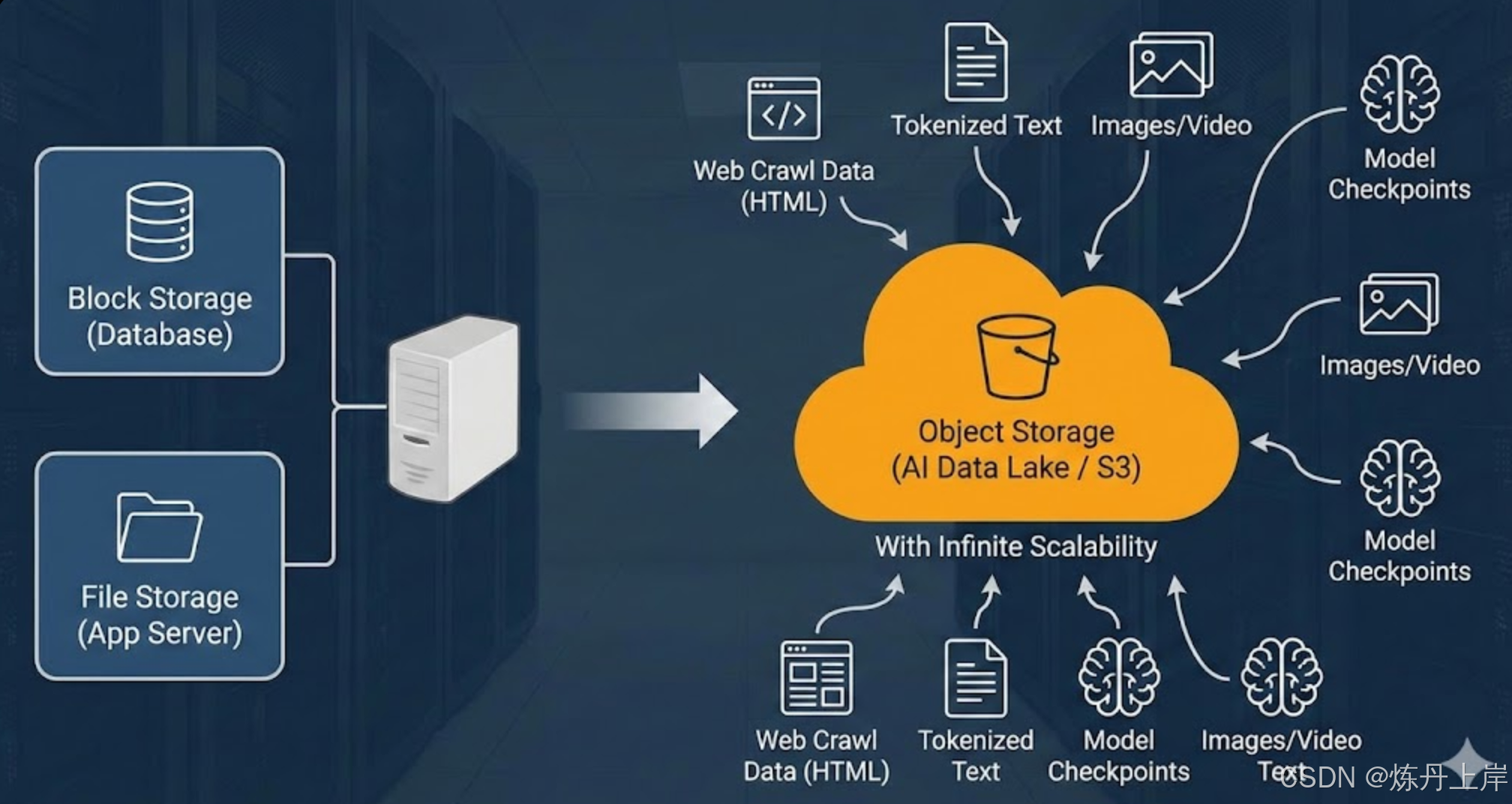
随着生成式人工智能(Generative AI)和大语言模型(LLM)的爆发式增长,云计算基础设施的重心正在发生深刻的结构性转移。在传统的Web应用和企业IT架构中,块存储(Block Storage)和文件存储(File Storage)分别主导了数据库和应用服务领域。然而,在AI大模型时代,对象存储(Object Storage,简称OS)------以Amazon S3为代表------凭借其无限的扩展性、扁平化的命名空间以及与现代深度学习框架的深度集成,已无可争议地成为AI数据基础设施的"底座"。
这种地位的转变并非偶然,而是源于AI工作负载的特殊I/O特征:从海量非结构化数据的摄取(Web Crawling),到数万亿Token的清洗与分词(Tokenization),再到分布式训练集群的高吞吐量检查点写入(Checkpointing),以及最终推理端的低延迟模型加载。传统的POSIX文件系统在面对十亿级小文件元数据操作时往往遭遇性能瓶颈,而块存储则因缺乏共享访问能力而无法支撑数千卡规模的并行计算。
本报告将从对象存储的底层技术原理出发,深入剖析Amazon S3的架构设计,并全面拆解其在AI/LLM全生命周期中的应用模式。我们将探讨数据如何流转于"存储-计算"分离架构之中,分析Parquet、Safetensors等新型数据格式如何优化I/O效率,并揭示现代向量数据库(Vector Database)如何基于对象存储构建"云原生"的语义记忆系统。
2. 存储架构的基础理论与范式比较
为了理解对象存储为何能主宰AI领域,必须首先将其与传统的存储架构进行彻底的技术对比。块、文件和对象三种存储形态,在寻址方式、元数据管理和一致性模型上存在本质差异。
2.1 块存储(Block Storage):高性能的物理抽象
块存储是最低层级的存储抽象,它将数据分割为固定大小的块(Block),并通过唯一的块ID进行寻址。
- 技术机制: 操作系统通过iSCSI、NVMe over Fabrics等协议直接读写这些块,没有文件系统的中间层开销。它提供了极低的延迟(微秒级)和极高的随机IOPS。
- 元数据匮乏: 块存储本身几乎不维护元数据,它只知道块的地址。所有关于文件类型、权限、创建时间的信息都由上层的文件系统管理。
- AI场景局限: 虽然块存储(如AWS EBS、本地NVMe SSD)是GPU服务器的"高性能缓存"和系统盘,但它本质上是单机或紧耦合的。在AI集群中,数千个节点需要访问同一份数据集,块存储难以提供高效的共享访问机制。虽然某些集群文件系统(如GPFS)构建在块设备之上,但其扩展成本极为高昂。
2.2 文件存储(File Storage/NAS):层级结构的桎梏
文件存储(如NFS、SMB、Amazon EFS)通过目录树(Directory Tree)来组织数据,符合人类的认知习惯。
- 技术机制: 依赖POSIX标准,提供强一致性、文件锁和权限控制。元数据存储在Inode中。
- 元数据瓶颈(The Small File Problem): 在AI领域,特别是计算机视觉(CV)和自然语言处理(NLP)任务中,数据集往往包含数亿个极小的文件(如KB级的图片或文本片段)。当文件数量达到亿级时,传统文件系统的元数据服务器(MDS)会不堪重负。一次简单的
ls操作可能导致元数据服务器响应超时,从而导致昂贵的GPU计算资源处于闲置等待状态(GPU Starvation)。 - 并行文件系统的改进: 为了解决这一问题,HPC领域引入了Lustre等并行文件系统,将元数据与数据分离。AWS的FSx for Lustre正是这一思路的云端实现,常被用作S3对象存储的高速缓存层。
2.3 对象存储(Object Storage):无限扩展的扁平空间
对象存储摒弃了层级目录结构,采用扁平的地址空间。每个数据单元被称为"对象",包含数据本体(Data)、元数据(Metadata)和全局唯一标识符(Key/ID)。
- 技术机制:
- RESTful API: 通过HTTP协议(PUT, GET, DELETE)访问,天然支持跨网络、跨区域的分布式访问。
- 扁平命名空间: 没有物理上的目录树。所谓的"文件夹"(如
s3://bucket/folder/file.txt)只是Key字符串的前缀(Prefix)。这种设计消除了目录遍历的元数据开销,使得存储桶可以容纳数十亿甚至数万亿个对象而不影响性能。 - 可扩展元数据: 对象存储允许用户为每个对象附加自定义的键值对标签(Tags)。在AI场景中,这意味着可以将数据的来源、清洗版本、嵌入模型的参数等信息直接绑定在数据文件上,极大便利了数据治理。
- 一致性模型的演进: 早期对象存储采用"最终一致性"(Eventual Consistency),这给机器学习管道带来了复杂性(例如,写入数据后无法立即列出)。然而,以Amazon S3为代表的现代对象存储已全面升级为"强一致性"(Strong Consistency),消除了这一技术障碍,使其成为事实上的数据湖标准。
2.4 三种存储架构的技术特征对比
下表总结了三种存储在AI负载下的关键差异:
| 特性维度 | 块存储 (Block) | 文件存储 (File/NAS) | 对象存储 (Object/S3) |
|---|---|---|---|
| 数据寻址 | 逻辑块地址 (LBA) | 文件路径/Inode | 对象键 (Key/URL) |
| 访问协议 | NVMe, iSCSI, FC | NFS, SMB, POSIX | REST API (HTTP/HTTPS) |
| 并发能力 | 低 (通常单机独享) | 中 (受锁机制限制) | 极高 (数万并发请求) |
| 元数据能力 | 极低 (仅块ID) | 标准 (大小, 时间, 权限) | 丰富 (支持自定义Tag) |
| 延迟特性 | 微秒级 (Microseconds) | 毫秒级 (Milliseconds) | 毫秒级 (可优化至个位ms) |
| 吞吐量扩展 | 受限于单盘/控制器 | 受限于文件服务器带宽 | 线性扩展 (随并发数增加) |
| AI核心用途 | 操作系统, 容器镜像, 本地缓存 | 代码仓库, 小规模数据集 | 数据湖, 检查点, 模型权重 |
| 成本效益 | 高 ($$$) | 中 ($$) | 低 ($) |
3. Amazon S3 核心架构深度解析
作为对象存储的工业标准,Amazon S3的架构细节对于优化AI性能至关重要。理解其内部机制有助于工程师在构建数据加载器(Dataloader)和检查点策略时做出正确决策。
3.1 桶(Buckets)与对象(Objects)的逻辑结构
-
存储桶(Buckets): S3的顶级逻辑容器。在AI数据湖架构中,通常采用分层的Bucket设计:
-
raw-zone-bucket: 存储原始爬虫数据(HTML, WARC)。 -
clean-zone-bucket: 存储清洗后的去重数据。 -
tokenized-zone-bucket: 存储分词后的二进制数据(用于训练)。 -
model-artifacts-bucket: 存储训练过程中的Checkpoints和最终模型。 -
对象的不可变性(Immutability): S3对象一旦创建,就无法修改其内容。要更新一个文件,必须上传一个新的版本覆盖旧对象。这一特性完美契合机器学习的"数据版本控制"需求,确保了实验的可复现性。通过开启S3 Versioning,可以回溯任何历史版本的模型或数据集,防止误删除。
3.2 强一致性模型(Strong Consistency)的技术突破
在2020年12月之前,S3遵循最终一致性模型,这导致了大数据处理中的"幽灵读"问题:ETL任务写入了数据分片,但随后的训练任务列举目录时却看不到这些文件。
- 当前架构: 现在的S3实现了"写后读"(Read-after-Write)的强一致性。当一个PUT请求收到HTTP 200成功响应时,任何后续的GET或LIST请求都能确保存取到最新的数据。
- 实现原理: AWS通过升级其元数据子系统,引入了分布式缓存一致性协议和基于Witness(见证节点)的高可用复制机制。这使得AI工程师无需在代码中引入
sleep()等待或使用DynamoDB做外部索引(如S3Guard),极大地简化了数据流水线的设计。
3.3 存储分层与智能生命周期(Lifecycle Management)
AI数据具有极其明显的冷热特征:模型训练期间,当前数据集是极热数据;一旦模型迭代,旧数据迅速变冷。S3提供了精细的存储类别以优化成本。
- S3 Standard: 毫秒级访问,高吞吐。用于正在训练的数据集和最近的Checkpoint。
- S3 Intelligent-Tiering: AI研发的"自动驾驶"模式。它监控对象的访问模式,自动将长期未访问的数据移动到低成本层,而当数据被再次访问时(例如复现旧实验)自动移回频繁访问层,且无取回费用。这对于管理海量实验数据至关重要。
- S3 Glacier Instant Retrieval: 归档存储,但在需要时可毫秒级取回。适合存储验证集或基准测试集,平时不访问,但评估时需立即读取。
- S3 Glacier Deep Archive: 深度归档,成本极低。用于存储合规性要求的原始数据备份,恢复时间需12小时以上。
3.4 S3 Express One Zone:AI时代的低延迟引擎
传统的S3 Standard虽然吞吐量大,但首字节延迟(TTFB)通常在两位数毫秒级别,这对于实时推理或频繁的小文件Checkpointing是不够的。
- 架构创新: AWS推出了S3 Express One Zone,这是一种全新的高性能存储类。它将数据存储在单个可用区(AZ)的专用硬件上,并采用了新的存储桶类型(Directory Bucket)。
- 性能飞跃: 相比标准S3,其延迟降低了10倍(达到个位数毫秒级),请求成本降低了50%。
- AI应用: 它是存放PyTorch DataLoader热数据、高频访问的模型权重以及实时推理缓存的理想场所。它支持每分钟数百万次请求,解决了对象存储在高性能计算场景下的"最后一公里"延迟问题。
4. AI大模型数据管道中的对象存储实战
大模型的训练过程可以看作是一个巨大的"数据飞轮",而对象存储是这个飞轮的轴心。本节将详细拆解数据在S3上的流转形态及优化策略。
4.1 数据摄取与"小文件问题"的攻克
大模型的训练语料来源广泛,包括Common Crawl的网页、GitHub的代码、ArXiv的论文等。
- 原始形态: 初始数据往往是数十亿个HTML文件、JSON对象或图片。如果直接以原始文件形式存入S3,将面临两个灾难性后果:
- 元数据延迟累积: 读取100万个10KB的文件需要建立100万次HTTP连接,握手开销远大于数据传输时间。
- API成本爆炸: S3按请求次数计费,数千亿次PUT/GET操作会产生巨额账单。
- 解决方案------分片(Sharding)与打包: 数据工程师会使用Spark或Ray将这些小文件打包成更大的容器格式。
- 最佳实践: 将文件聚合成100MB至1GB大小的数据块(Shards)。这个尺寸既能利用S3的高带宽流式传输优势,又方便并行下载。
4.2 存储内容与格式详解
在S3上存储的AI内容主要分为四类,每类都有其特定的格式选择逻辑。
4.2.1 训练数据集(Training Datasets)
这是占用空间最大的部分。
- Parquet: 首选格式。作为列式存储(Columnar Storage),它支持高效的压缩(Snappy/Zstd)和投影下推(Projection Pushdown)。如果训练只需要多语言数据集中的"中文"列,Parquet允许仅读取该列数据,大幅减少网络I/O。
- Avro: 行式存储,写入性能优于Parquet,常用于流式数据摄取阶段。
- WebDataset (TAR): 专门为深度学习设计的格式,本质上是包含数据和标签的TAR包。它允许PyTorch直接流式读取TAR包内容,无需解压,非常适合图像训练。
- Arrow / Feather: 内存映射格式,支持零拷贝(Zero-Copy)读取,适合高性能数据加载,但文件体积通常大于Parquet。
- 反模式(Anti-Patterns): 尽量避免在大规模训练中使用CSV或JSON。它们不仅体积大(无压缩),且解析(Parsing)过程极消耗CPU资源,容易导致CPU成为训练瓶颈。
4.2.2 模型工件(Model Artifacts)
- Checkpoints: 包含模型权重(Parameters)和优化器状态(Optimizer States)。对于70B参数的模型,一个完整的Checkpoint可能超过500GB。
- Safetensors: Hugging Face推出的新型权重格式,正逐渐取代Python Pickle(
.pth)。Safetensors的设计允许通过mmap(内存映射)直接从存储加载到内存,无需反序列化过程,且杜绝了Pickle的安全漏洞(任意代码执行风险)。 - ONNX / TensorRT: 用于推理部署的优化模型格式。
4.2.3 向量索引(Vector Indices)
- 内容: 高维向量数据的索引文件(如HNSW图、IVF倒排索引)。
- 特点: 这些文件通常由向量数据库(如Milvus、Pinecone)生成,并持久化到S3中,实现存算分离。
4.3 高性能数据加载架构
如何将S3中的数据以最快速度喂给GPU?
-
流式加载(Streaming / Iterable Datasets): 使用AWS开源的S3 Connector for PyTorch或Hugging Face的
load_dataset(..., streaming=True)。这些工具实现了S3的流式接口,数据在内存中边下载边训练,无需本地磁盘缓存。这使得训练数PB的数据集成为可能。 -
代码逻辑: 实现
IterableDataset,内部维护一个S3流的缓冲区,动态Shuffle数据。 -
高性能缓存层(Caching Layer): 对于需要反复迭代(Multi-epoch)的数据集,流式加载会产生重复的S3流量。此时引入缓存层是必要的。
-
Amazon FSx for Lustre: 这是一个高性能并行文件系统,可以"挂载"到S3 Bucket上。初次访问时,FSx从S3懒加载数据;后续访问直接从FSx的高速SSD读取。它为S3提供了POSIX接口和亚毫秒级延迟。
-
JuiceFS / Alluxio:
-
JuiceFS: 采用元数据与数据分离架构。元数据存储在Redis/TiKV中(极快),数据分块存储在S3中。它对小文件友好,且完全兼容POSIX,让不支持对象存储的旧代码也能无缝运行。
-
Alluxio: 提供统一的数据编排层,不仅缓存S3,还能统一管理HDFS等异构存储,支持基于策略的数据预热。
5. 大规模分布式训练中的检查点(Checkpointing)策略
在大模型训练中,检查点不仅是数据备份,更是系统稳定性的生命线。鉴于GPU集群的高故障率,频繁保存Checkpoint是必须的,但这会阻塞训练。
5.1 检查点的挑战
写入一个TB级的Checkpoint可能需要几分钟。如果每小时保存一次,每天可能有数小时的GPU时间被浪费在等待I/O上。
5.2 优化方案:异步与多级存储
-
异步检查点(Async Checkpointing): PyTorch Lightning等框架支持
AsyncCheckpointIO。原理是先把模型权重快速复制到CPU内存(RAM),然后立刻恢复GPU训练。后台线程同时将RAM中的数据上传到S3。这几乎消除了I/O阻塞时间。 -
分层写入策略:
-
Tier 0 (Memory): 训练状态常驻显存/内存。
-
Tier 1 (Fast Disk): 将Checkpoint写入本地NVMe SSD或FSx for Lustre。
-
Tier 2 (S3): 异步将Tier 1的数据同步到S3 Standard进行持久化。
-
分块并行上传(Multipart Upload): 利用S3的分段上传特性,成百上千个GPU节点可以同时向同一个Bucket写入数据的不同部分,打满网络带宽。
6. 推理与向量数据库:对象存储的新战场
6.1 推理服务中的模型加载
在推理阶段(Inference),启动延迟(Cold Start)是关键指标。
- 懒加载(Lazy Loading): 利用Safetensors格式,推理服务启动时并不一次性读取整个模型,而是通过内存映射按需读取权重。结合S3 Express One Zone,可以显著减少模型启动时间。
- 模型注册中心(Model Registry): MLflow等MLOps工具将S3作为模型仓库。训练完成的模型自动上传到S3特定路径(如
s3://mlflow/experiments/1/model),并打上版本标签(Production/Staging)。推理服务监听注册表,自动拉取最新模型。
6.2 向量数据库的存算分离架构
RAG(检索增强生成)依赖向量数据库检索知识。传统的向量库(如Faiss单机版)难以扩展。新一代云原生向量数据库(Milvus, Pinecone)采用了基于对象存储的存算分离架构。
-
架构原理:
-
Log Broker (Pulsar/Kafka): 负责接收新写入的向量,保证持久性。
-
Data Nodes: 消费日志,构建索引片段(Segments)。
-
Object Storage (S3): 这是核心。 构建好的索引段(Sealed Segments)、日志快照(Binlogs)和元数据文件全部持久化存储在S3中。
-
Query Nodes: 无状态的计算节点。查询时,根据需要从S3拉取索引段加载到内存,或者利用本地缓存。
-
优势: 这种架构允许存储(S3)无限扩展,承载十亿级向量数据,而计算节点(Query Nodes)可以根据查询QPS弹性伸缩。S3成为了向量数据的"单一真理来源"(Source of Truth)。
-
S3 Vector: AWS甚至推出了原生的S3向量检索功能,允许直接对存储在S3中的数据进行语义搜索,进一步模糊了数据库与存储的界限。
7. 成本优化与生命周期治理策略
AI数据不仅量大,而且昂贵。合理的S3配置能节省数百万美元的成本。
7.1 生命周期规则配置示例
对于一个典型的大模型项目,建议配置如下S3 Lifecycle Rules:
| 数据类型 | 存储路径前缀 (Prefix) | 初始存储类 | 转换策略 (Transition) | 过期策略 (Expiration) |
|---|---|---|---|---|
| 原始爬虫 | raw-data/ |
Standard | 30天后转 Glacier Deep Archive | - |
| 中间处理数据 | processed/ |
Standard | 7天后转 Standard-IA | 90天后删除 |
| Checkpoints | checkpoints/ |
Express One Zone | 3天后转 Standard; 30天后转 Glacier | 旧版本保留3个,其余删除 |
| 训练日志 | logs/ |
Standard | 30天后转 Standard-IA | 365天后删除 |
| 模型产物 | models/release/ |
Standard | - (永久保留) | - |
7.2 智能分层(Intelligent-Tiering)的应用
对于研发人员的个人Bucket(dev-user-*),访问模式不可预测。强制开启S3 Intelligent-Tiering是最佳实践。它会自动将那些被遗忘的"实验垃圾数据"沉降到归档层,一旦需要访问又能毫秒级恢复,无需人工干预。
8. 结论
对象存储(OS)与Amazon S3已不再仅仅是云端的"硬盘",它们演变成了AI大模型生态系统的中枢神经。从取代文件系统成为海量训练数据的主存储,到通过存算分离架构支撑向量数据库的无限扩展,再到通过强一致性和S3 Express加速计算流程,对象存储的技术特性正在被重塑以适应AI的需求。
对于构建AI基础设施的工程师而言,掌握以下核心原则至关重要:
- 拥抱对象原生: 尽可能使用支持S3流式读取的工具链,避免本地下载。
- 关注数据格式: 使用Parquet、Safetensors等云原生格式,规避小文件和序列化开销。
- 分层治理: 利用S3丰富的存储层级,在Express One Zone的高性能和Deep Archive的低成本之间找到平衡点。
- 架构解耦: 坚定地实施存算分离,让S3承担状态的持久化,让GPU专注于计算。
随着多模态模型和万亿参数模型的进一步发展,存储与计算的界限将更加模糊,而对象存储作为数据引力的核心,其重要性只会愈发凸显。