Linux-程序地址空间
- 一、程序地址空间分布
- 二、虚拟地址空间
- 三、进程地址空间
-
- 1、进程地址空间的结构
- 2、父进程视角
- 3、子进程视角
- [3、写时拷贝(coyp of write,COW)](#3、写时拷贝(coyp of write,COW))
- 四、虚拟内存管理
- 五、为什么需要虚拟地址空间
一、程序地址空间分布
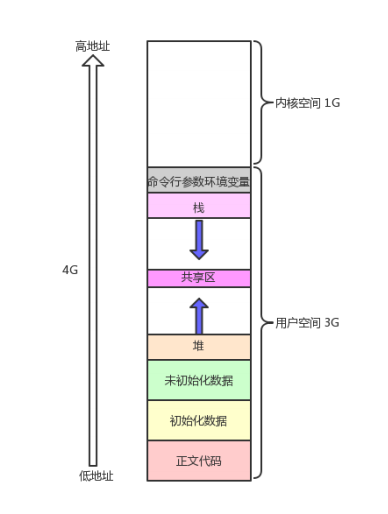
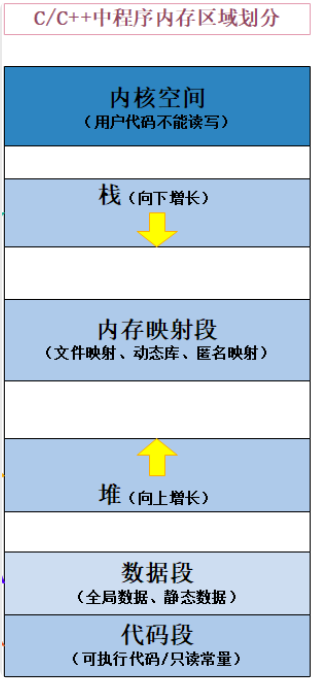
我们学习C语言的时候,详细介绍了程序地址空间的分布。
这篇文章详细介绍了内存各个区域的使用。
C\C++内存管理
1、栈区:栈内存由系统自动进行分配和释放。当进入函数时,系统会自动为函数内的局部变量分配内存;函数执行完毕后,这些内存会被自动回收。
栈区主要存储以下两类数据:
函数的局部变量,包括基本数据类型(如 int、float 等)和对象。函数调用的上下文信息,例如返回地址、调用参数等。
2、堆区:堆区(Heap)是程序运行时内存的重要组成部分,用于动态分配内存。由程序员通过new/new\[\]、malloc\relloc等分配内存,delete/delete\[\]、free释放内存。若忘记释放,会导致内存泄漏(Memory Leak),之前例子里的func函数就存在内存泄漏的问题。
3、静态区:包含 数据段 (.data)存储已经初始化的变量 + BSS段 (.bss)存储未初始化的变量 + 只读数据段 (.rodata),用于存储具有静态存储期的变量。这些变量的生命周期贯穿整个程序运行期间,它们在程序启动时被分配内存,在程序结束时才释放。主要存储全局变量和被static修饰的变量
4、常量区:常量区(Constant Area)是静态区(Static Area)的一个子区域,用于存储编译时可确定值的字面常量和全局 / 静态的 const 变量。它的特点是只读,程序运行期间无法修改其中的数据。
可是我们对这幅图的理解并不深刻,那么我们写一段程序将各类变量都集合起来,观察他们地址排列的方式,去确定他们是否按照图中从低地址到高地址的方式去排布。
c
#include <stdio.h>
#include <stdlib.h>
int g_val = 100; // 在静态区的初始化区.data
int g_unval; // 在静态区的未初始化区 .bss
static int s_val = 200; // 在静态的初始化区 .data
/*
注意:虽然你不使用 argc 和 argv,但如果你想接收第三个参数 env,前两个参数必须作为"占位符"存在。
简单来说,main 函数没有 int main(char* env[])单第三个参数 这种形式,只有 (void)、(int, char**) 或 (int, char**, char**)。
*/
int main(int argc,char* argv[],char* env[])
{
int a = 10; // 局部变量在栈区
static int s_j_val = 20; // 静态变量在静态区\数据段区
char arr[] = {"hello world"};// 字符数组一样是局部变量,在栈区
const char* str = "hello world"; // str本身在栈区中,str中的地址在常量区中
int* ptr1 = (int*)malloc(10*sizeof(int)); // ptr1本身在栈区中,ptr1中的地址在堆区中
int* ptr2 = (int*)malloc(10*sizeof(int)); // ptr2本身在栈区中,ptr2中的地址在堆区中
int* ptr3 = (int*)malloc(10*sizeof(int)); // ptr3本身在栈区中,ptr3中的地址在堆区中
for(int i = 0;env[i];i++) // 打印环境变量
{
printf("&env[i] = %p\n",&env[i]);
}
/*
&env[0] = 0x7ffee5121938
&env[1] = 0x7ffee5121940
&env[2] = 0x7ffee5121948
&env[3] = 0x7ffee5121950
&env[4] = 0x7ffee5121958
&env[5] = 0x7ffee5121960
&env[6] = 0x7ffee5121968
&env[7] = 0x7ffee5121970
&env[8] = 0x7ffee5121978
&env[9] = 0x7ffee5121980
&env[10] = 0x7ffee5121988
*/
// 局部变量在栈区,ptrx在栈区,但是ptrx指向的内容在堆区中
printf("&a = %p\n",&a);
printf("&arr = %p\n",arr);
printf("&ptr1 = %p\n",&ptr1);
printf("&ptr2 = %p\n",&ptr2);
printf("&ptr3 = %p\n",&ptr3);
// 栈堆相对而生,中间是共享段
/*
&a = 0x7ffee512182c
&arr = 0x7ffee5121820
&ptr1 = 0x7ffee5121818
&ptr2 = 0x7ffee5121810
&ptr3 = 0x7ffee5121808
验证了环境变量的地址大于栈区地址
栈区地址向下生长,所以地址越来越小
*/
// 动态开辟的内存都在堆区
printf("ptr1 = %p\n",ptr1);
printf("ptr2 = %p\n",ptr2);
printf("ptr3 = %p\n",ptr3);
/*
ptr1 = 0x155c010
ptr2 = 0x155c040
ptr3 = 0x155c070
堆区的地址向上生长,所以地址越来越大
*/
printf("&g_unval = %p\n",&g_unval);
printf("&s_val = %p\n",&s_val);
/*
&g_unval = 0x60104c
&s_val = 0x601040
未被初始化的全局变量和静态变量在静态区中未初始化区.bss中,
*/
// 已经初始化的全局变量和静态变量在初始化区
printf("&g_val = %p\n",&g_val);
printf("&s_j_val = %p\n",&s_j_val);
/*
&g_val = 0x60103c
&s_j_val = 0x601044
已经初始化的全局变量和静态变量在静态区中数据段.data区域中
.data (已初始化) 和 .bss (未初始化),两者地址相近,但具体谁高谁低不重要。
*/
// 字符串常量和代码(函数)都在代码段中,不可以被修改
printf("str = %p\n",str);
printf("&main = %p\n",&main);
/*
str = 0x4007a0
&main = 0x40057d
通常紧邻静态区或代码区,存放字符串字面量。
代码区: 存放函数指令。
*/
return 0;
}二、虚拟地址空间
从上面最上面幅图可以看出,在32位系统中每一个进程都被分配了4G的内存,但是我们实际的物理内存只有2G,怎么办?
其实我们看到的4G内存是虚拟内存,是操作系统为每个进程创建的假象,而实际的物理内存2G是真实的情况。这两者并不冲突,因为操作系统使用了一种叫做虚拟内存管理的技术骗过每一个进程。
虚拟地址空间 (4GB):这是操作系统给每一个进程画的"大饼"。无论你的电脑只有 256MB 内存还是 2GB 内存,Windows 都会告诉每个 32 位进程:"你的内存地址从 0x00000000 到 0xFFFFFFFF,2的32次方字节,总共 4GB,随便用。" 这个 4GB 是逻辑上的,用来解决程序寻址范围的问题。
1、虚拟内存管理的例子
c
#include <stdio.h>
#include <unistd.h>
int g_val = 100; // 设置全局变量
int main()
{
printf("fork之前g_val的值:%d\n",g_val);
pid_t id = fork();
if(id == 0)//child
{
while(1)
{
printf("我是子进程,g_val = %d\n",g_val); // 子进程打印g_val的值
g_val++; // 子进程g_val+1
printf("子进程&g_val = %p\n",&g_val); // 打印子进程g_val的地址
sleep(1);
}
}
else
{
while(1)
{
printf("我是父进程,g_val = %d\n",g_val); // 打印父进程g_val的值
printf("父进程&g_val = %p\n",&g_val); // 打印父进程g_val的地址
sleep(1);}
}我们把代码跑起来
bash
benjiangliu@VM-4-8-centos lesson19]$ ./验证看到的地址是虚拟地址
fork之前g_val的值:100
我是父进程,g_val = 100
父进程&g_val = 0x601044
我是子进程,g_val = 100
子进程&g_val = 0x601044
我是父进程,g_val = 100
父进程&g_val = 0x601044
我是子进程,g_val = 101
子进程&g_val = 0x601044
我是父进程,g_val = 100
父进程&g_val = 0x601044
我是子进程,g_val = 102
子进程&g_val = 0x601044通过程序的现象可以看出,在fork以后,父进程和子进程都有自己的g_val,父进程和子进程的g_val的地址却是一样的,但是g_val的值却不一样。为什么?因为子进程以父进程为模版创建,所以他们的地址是一样的,子进程g_val++,不影响父进程的g_val,一样的地址,不可能有2个值, 所以可以知道进程的地址是虚拟的,真实的物理地址是虚拟的,被操作系统隐藏了,我们无法看到!所以我们在C\C++语言中看到的地址,全部都是虚拟地址,物理地址用户一概看不到!
之前说过每一个进程都有自己的虚拟内存,相当于每一个进程都会有4G的内存,而这4G的内存都是虚拟内存,虽然存储在内存上面,但是不与物理内存的地址一一对应。
这就是操作系统内存管理的核心精髓------虚拟化。
2、为什么需要有虚拟地址空间?
1、防止指针越界访问,控制进程的行为(因)
当指针在虚拟内存中有越界访问时,OS可以提前进程判定,防止真的越界。
2、保护内存,拦截进程非法行为(果)
当进程出现非法行为时候,MMU直接报错
3、便于在物理内存上进行管理
OS可以通过虚拟内存将进程的代码和数据放在物理内存的任何位置。在编译时,虽然都在虚拟内存中是从低到高进行排布的,但是通过页表(后面表述)可以将虚拟内存有序的布置变为物理内存无序布置。
4、让进程管理和内存管理解耦合
在linux中,创建了一个进程,是先创建内核数据结构(PCB和进程地址空间),再加载代码和数据的,如果我们不着急使用这个进程,可以在需要的时候再加载代码和数据(懒加载 )。
例如我写了一段程序 int* ptr = (int*)malloc(10000),或者new int(10000),这10000个空间虽然已经申请了,但是我们并没有立刻使用,因为动态内存申请是在虚拟内存上申请的,实际的物理内存上并没有开辟空间,可以先给其他使用中的进程申请空间,当此进制真实使用空间的时候 ,再去申请,这叫缺页中断引起内存二次申请,由OS自动完成。
三、进程地址空间
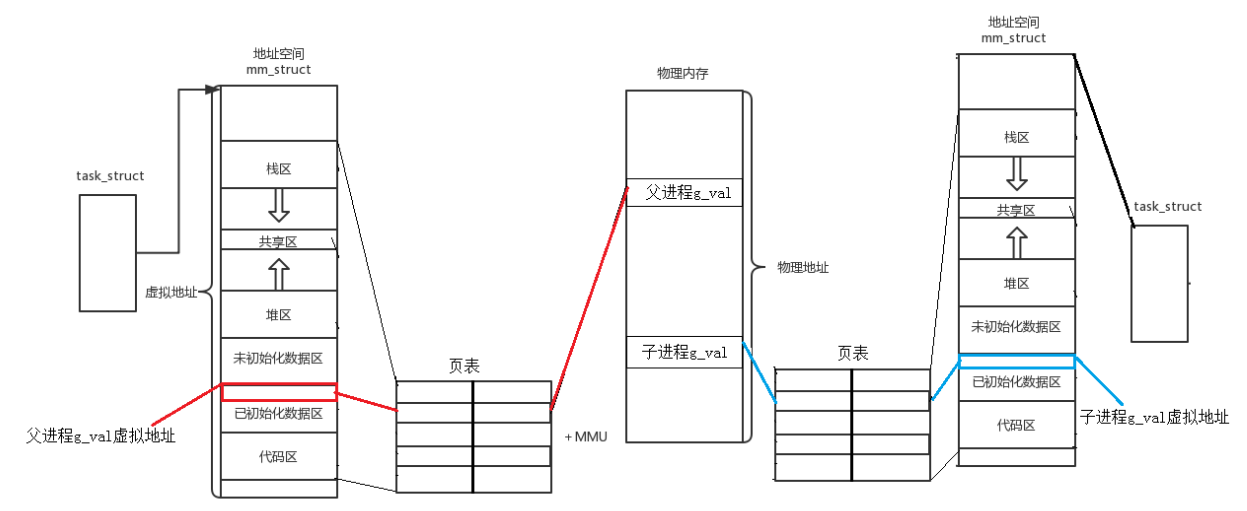
1、进程地址空间的结构
1、task_struct与mm_struct
从左向右看,先看物理地址左边的空间
最左边是PCB也就是task_struct,是进程控制块
c
// 这是 2.6 内核中 task_struct 的简化版结构
// 注意其中的 struct mm_struct *mm; 成员
struct task_struct {
volatile long state; // 进程状态
void *stack; // 内核栈
pid_t pid; // 进程ID
// ... 其他调度、文件系统、信号等成员 ...
/* 进程地址空间的关键指针 */
struct mm_struct *mm; // 指向进程的内存描述符
struct mm_struct *active_mm;
// ... 其他成员 ...
};从task_struct的代码中可以看出,进程地址空间中一个关键指针 struct mm_struct *mm;
这个指针指向虚拟内存结构体的地址。
c
// 这是 2.6 内核中 mm_struct 的简化版结构
// 它描述了进程的整个虚拟地址空间
struct mm_struct {
struct vm_area_struct *mmap; // 指向虚拟内存区域链表的头指针
rb_root_t mm_rb; // 红黑树根节点 (用于快速查找)
struct vm_area_struct *mmap_cache; // 上次访问的VMA缓存
pgd_t *pgd; // 页全局目录 (页表的基地址)
unsigned long start_code, end_code; // 代码段的起始和结束地址
unsigned long start_data, end_data; // 数据段的起始和结束地址
unsigned long start_brk, brk; // 堆的起始和结束地址
unsigned long start_stack; // 栈的起始地址 (注:2.6中栈顶通常动态计算)
// ... 其他统计和锁机制成员 ...
};所以:
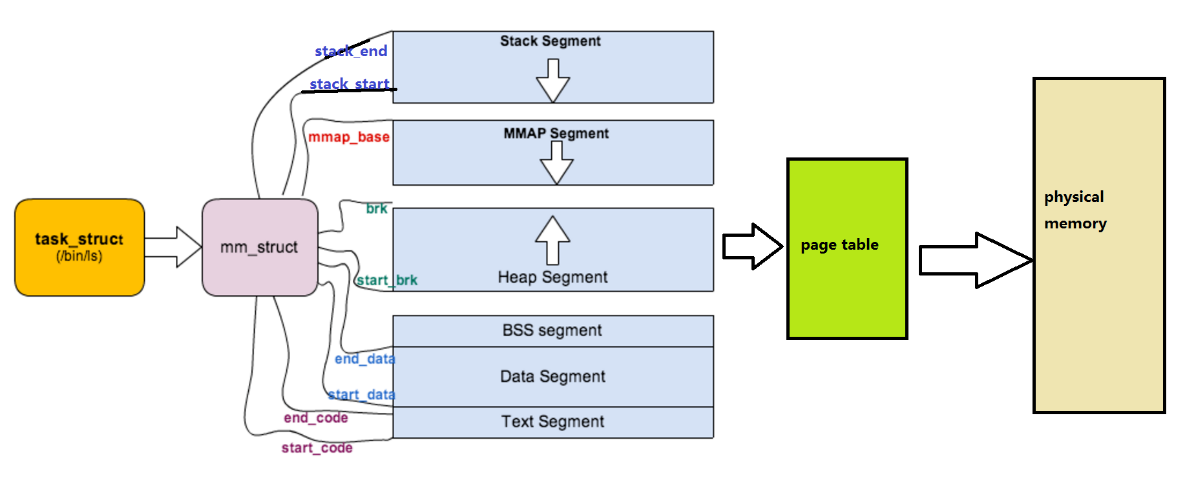
task_struct 指向了 mm_struct,这表示该进程(父进程)拥有一个独立的虚拟地址空间。
mm_struct 内部布局:从上到下依次是栈区、共享区、堆区、未初始化数据区、已初始化数据区、代码区。这是典型的 Linux 进程内存布局。
2、页表
页表(Page Table)就是一个映射表。
它是操作系统和硬件(MMU,内存管理单元)用来实现虚拟地址到物理地址转换的核心数据结构。
你可以把页表理解成一本"字典"或者一个"路由器"。
输入(Key): 虚拟地址
输出(Value): 物理地址
当 CPU 执行指令访问内存时,它给出的是虚拟地址。页表的作用就是查表,找出这个虚拟地址对应的真实物理内存位置。
c
// 简化示意
struct mm_struct {
pgd_t *pgd; // 指向页全局目录(Page Global Directory)
// ...
};页表项
| 标志位 | 状态 | 原因 |
|---|---|---|
| Present § | 1 (存在) | 内存就在物理页中,没问题。 |
| Read/Write (R/W) | 0 (只读) | 这是关键! 内核将这块内存临时设为"只读"。这样,无论是父进程还是子进程,只要试图修改 g_val,MMU 就会拦截并报错。 |
| User/Supervisor (U/S) | 0 (内核态) 或 1 (用户态) | 取决于具体实现,但在 2.6 内核中,通常为了拦截写操作,可能会将其设为只读,或者配合异常处理。重点是 R/W=0。 |
| Dirty | 0 | 尚未被修改过。 |
2、父进程视角
task_struct 指向了 mm_struct,这表示该进程(父进程)拥有一个独立的虚拟地址空间。
mm_struct 内部布局:从上到下依次是栈区、共享区、堆区、未初始化数据区、已初始化数据区、代码区。这是典型的 Linux 进程内存布局。
图中红色框标出了 "已初始化数据区",其中包含 父进程g_val 的虚拟地址。
这个虚拟地址通过 页表 映射到了 物理内存 中的 "父进程g_val" 所在的物理页。
此时,虚拟地址 → 物理地址 的映射是唯一的,父进程独占这块物理内存的读写
3、子进程视角
子进程也有自己的 task_struct 和 mm_struct。
mm_struct 布局:与父进程完全相同!这也是 fork() 的核心特性------子进程继承父进程的地址空间布局。
子进程的 g_val 虚拟地址(蓝色框)与父进程的虚拟地址在逻辑上是"相同"的(比如都是 0x601044)。
但是,这个虚拟地址通过子进程的 页表 映射到了 物理内存 中的 "子进程g_val" 所在的物理页。
这说明:虽然虚拟地址相同,但映射的物理地址不同!
3、写时拷贝(coyp of write,COW)
这张图最精髓的地方,在于它隐含了 写时拷贝 的机制:
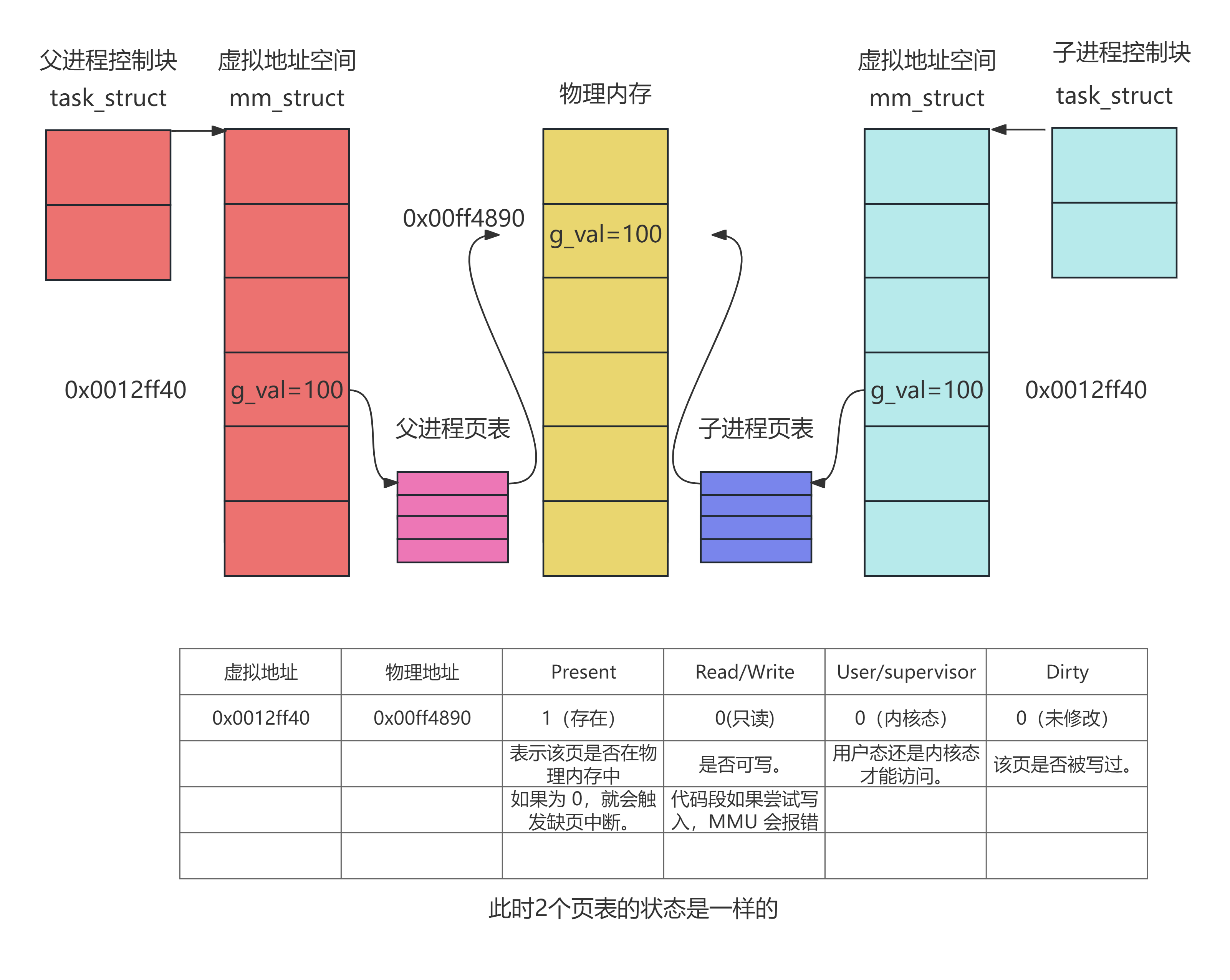
fork() 初始阶段:
子进程刚创建时,g_val的虚拟地址和物理地址是一样的,它的页表和父进程的页表指向同一个物理页(比如 g_val 的初始值 100)。
为什么呢?学过进程都知道,子进程会共享父进程的代码和数据,之前我们写的这个例子很小,代码和数据都很小,如果给子进程真实开辟一块物理内存,并不影响什么,但是如果父进程很大,光数据就占用了512mb内存,父进程一下开了3个子进程,且继承了父进程的数据,直接在物理内存上开辟3块区域也,那1.5G的内存就没有了,而且他们的数据却是一样的,纯粹浪费资源!
所以:
虚拟地址一样:子进程继承了父进程的地址空间布局,所以 &g_val 打印出来的十六进制数字是一模一样的(比如都是 0x601044)。
物理地址一样:因为刚开始大家都没改数据,为了省事(不申请新内存),内核让这两个一样的虚拟地址,通过各自的页表,映射到了同一个物理页框。
此时,两个进程共享同一块物理内存,为了防止同时修改,这块内存的页表项被标记为只读。
程序运行了一会,子进程的g_val++了,父进程的g_val不变,但是此时父子进程共享物理地址上同一个内存空间,无法再共享内存了,子进程必须修改物理内存,此时在修改的同时CPU 触发缺页中断(因为试图写入页表项中只读页面),因此必须为子进程g_val创建一个新的内存单元存储新的g_val。
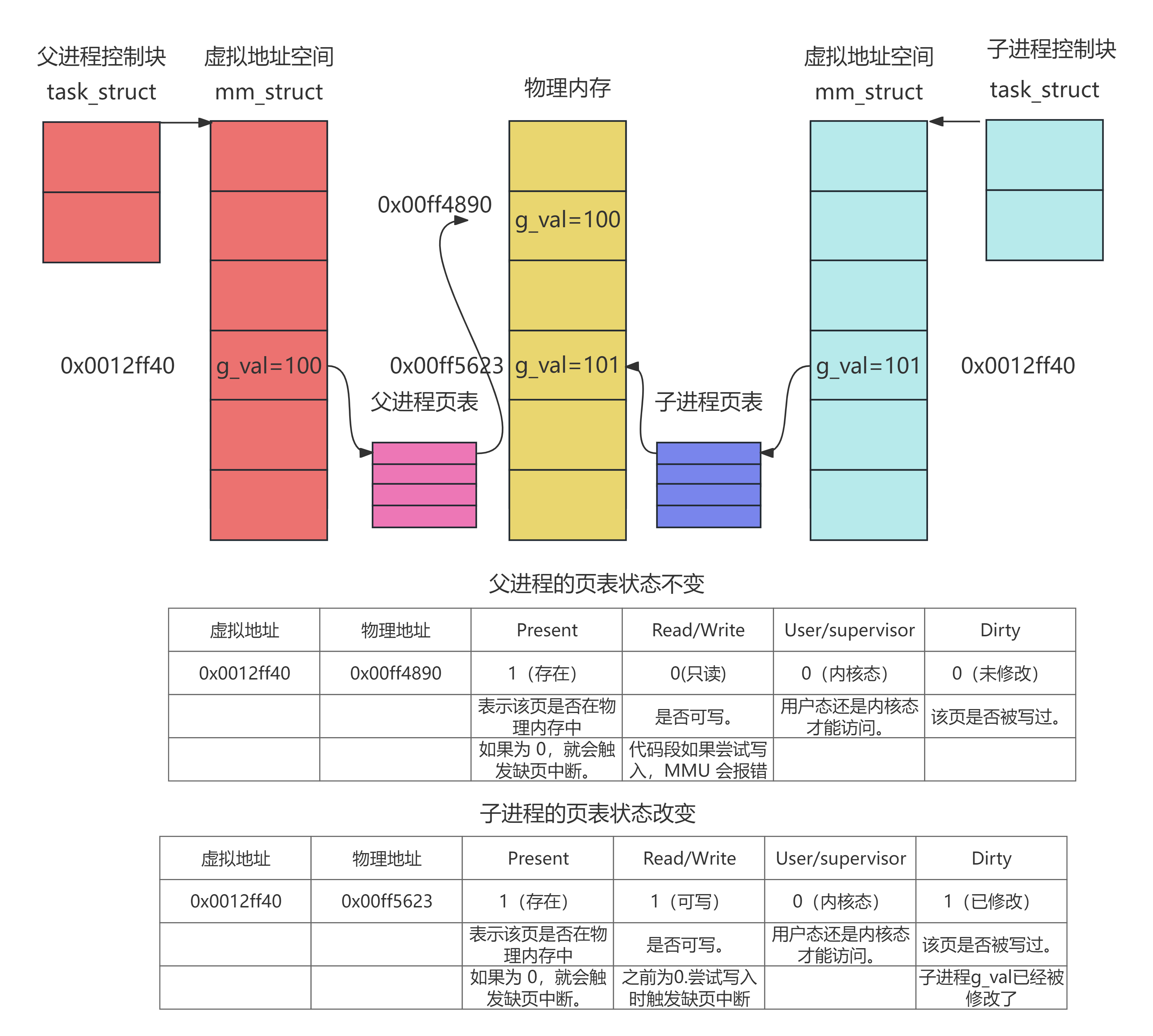
发生写操作时:
当子进程尝试修改 g_val(比如 g_val++),CPU 触发 缺页中断(因为试图写入只读页面)。
内核接管,发现这是写时拷贝的情况,于是:
分配一块新的物理页。
将原数据拷贝到新页。
将子进程页表中 g_val 的映射指向新物理页,并设置为可写。
结果:子进程修改的是新页,父进程依然指向旧页,互不干扰。
所以:同一个变量,地址相同个,其本质是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
让我们提出一个新的问题,当我们创建的父进程有100个变量,这个父进程的子进程只修改了其中2个变量,我们是给100个变量都开辟新物理内存空间,还是只开辟被修改的2个变量?
当然是2个,只会给被修改的 2 个变量所在的内存页分配新的物理内存空间,其余 98 个未修改的变量仍然与父进程共享原来的物理页。这个是写时拷贝的机制构成,核心是为了节省系统资源。
四、虚拟内存管理
描述linux下进程的地址空间所有的信息都存储在结构体mm_struct(内存描述符)中,每一个进程只有一个mm_struct,在每一个进程的task_struct结构中,都有一个指针指向该结构。
c
struct task_struct {
volatile long state; // 进程状态
void *stack; // 内核栈
pid_t pid; // 进程ID
// ... 其他调度、文件系统、信号等成员 ...
/* 进程地址空间的关键指针 */
struct mm_struct *mm; // 指向进程的内存描述符
// 对于普通用户来说,该字段指向他的虚拟地址空间的用户空间部分,对于内核线程来说这部分为NULL
struct mm_struct *active_mm;
// 该字段是内核线程使用的,当该进程是内核线程是,他的mm字段为空,表示没有内存地址空间,可他不是真正没有,这是因为所有有关进程的映射都是一样的,内核线程可以使用任意进程的地址空间
// ... 其他成员 ...
};mm_struct结构在广义上是对整个用户空间的描述。
每一个进程都会有一个自己独立的mm_struct,这样每一个进程都会有自己队里的地址空间相互不会干扰。
先看由task_struct到mm_struct,进程的地址空间分布。
定位mm_struct所在的位置在mm_types.h中
c
// 这是 2.6 内核中 mm_struct 的简化版结构
// 它描述了进程的整个虚拟地址空间
struct mm_struct {
struct vm_area_struct *mmap; // 指向虚拟内存区域链表的头指针
rb_root_t mm_rb; // 红黑树根节点 (用于快速查找)
struct vm_area_struct *mmap_cache; // 上次访问的VMA缓存
pgd_t *pgd; // 页全局目录 (页表的基地址)
unsigned long task_size; // 具有该结构体进程的虚拟地址空间大小
unsigned long start_code, end_code; // 代码段的起始和结束地址
unsigned long start_data, end_data; // 数据段的起始和结束地址
unsigned long start_brk, brk; // 堆的起始和结束地址
unsigned long start_stack; // 栈的起始地址 (注:2.6中栈顶通常动态计算)
// ... 其他统计和锁机制成员 ...
};既然每一个进程都有自己独立的task_struct和mm_struct,操作系统肯定需要将这么多的进程的mm_struct组织起来,所以常见的虚拟地址空间组织方式有2种:
1、当虚拟区少时,由mmap指针指向这个链表。
2、当虚拟区多时,有红黑树mm_rb进程管理,由mm_rb指向这棵树。
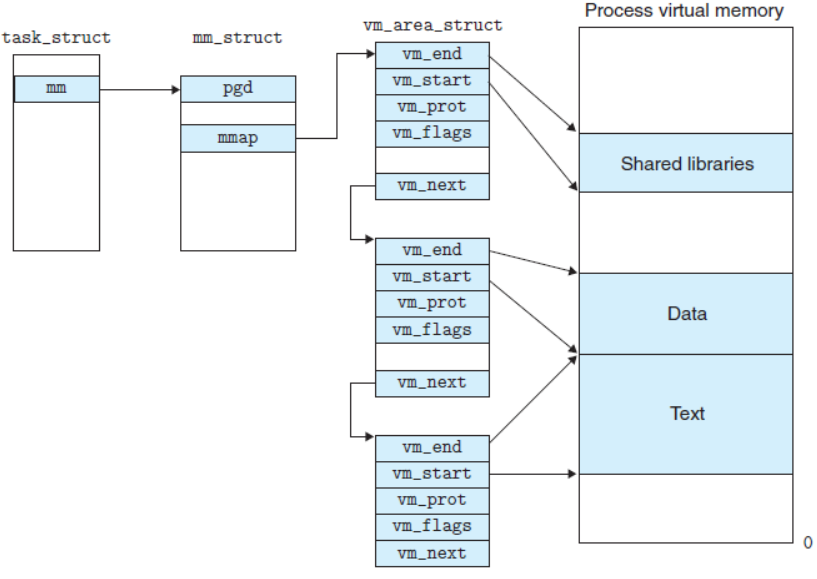
linux内核使用vm_area_struct结构来表示一个独立的虚拟内存区域(VMA),由于每个不同质的虚拟内存区域功能和内部机制不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。上面提到的2种组织方式就是使用vm_area_struct结构来连接各个VMA,方便进行快速访问。
我们来看vm_area_struct结构的代码
c
struct vm_area_struct {
unsigned long vm_start; // 虚存区起始
unsigned long vm_end; // 虚存区结束
struct vm_area_struct *vm_next, *vm_prev; // 前后指针
struct rb_node vm_rb; // 红黑树中的位置
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm; // 所属的 mm_struct
pgprot_t vm_page_prot; // 标志位
unsigned long vm_flags; // 标志位
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; // vma对应的实际操作
unsigned long vm_pgoff; // 文件映射偏移量
struct file *vm_file; // 映射的文件
void *vm_private_data; // 私有数据
atomic_long_t swap_readahead_info;
#ifdef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
__randomize_layout;
};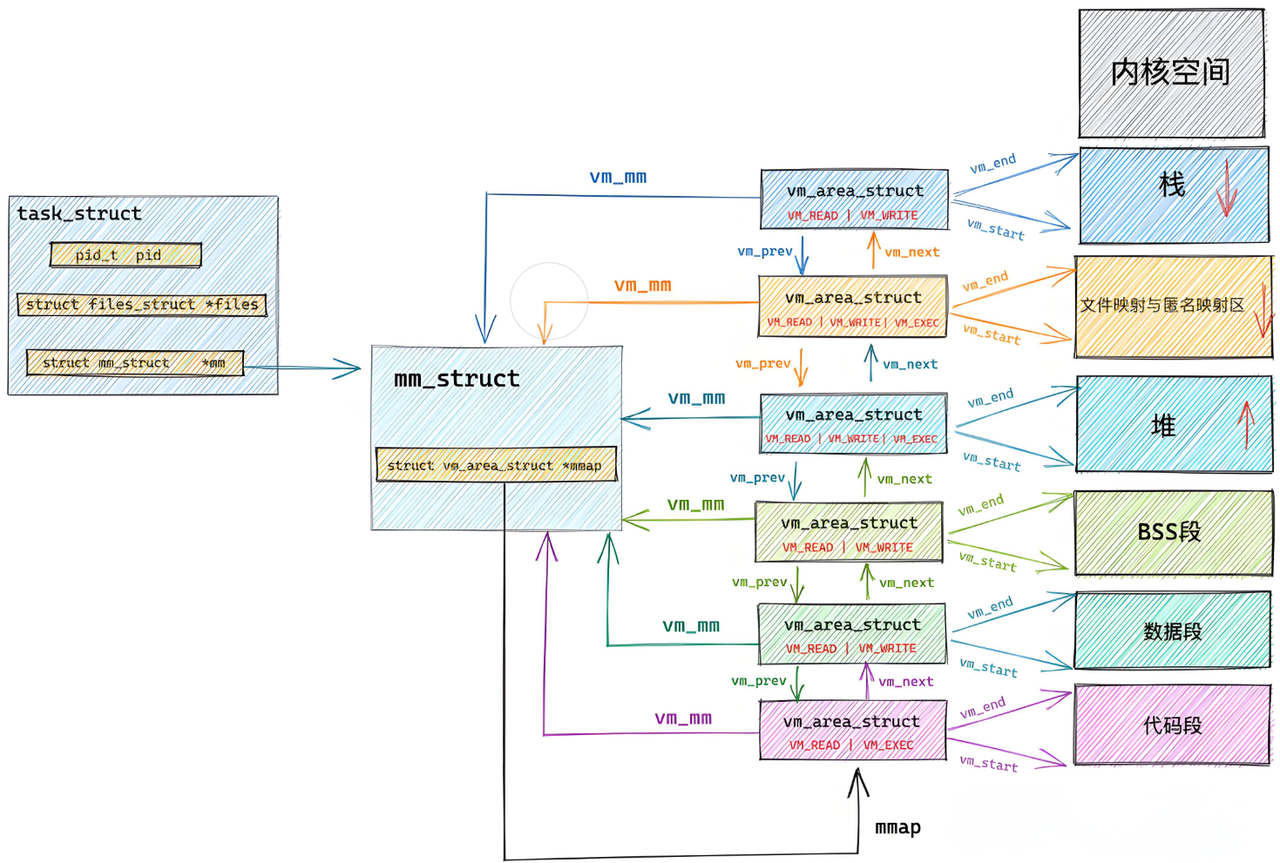
上面这幅图详细描述了,stask_struct 与mm_struct还有vm_area_struct的关系
每一个逻辑上连续、具有相同访问属性(如读/写/执行、共享/私有等)的内存区域(例如栈区、堆、代码段),都会由一个独立的 vm_area_struct(VMA)来描述和管理。
五、为什么需要虚拟地址空间
在代码编译完成存放在硬盘上后,当运行的时候,需要将程序搬运到内存中运行,如果直接使用物理地址的话,我们无法直接规定内存现在使用到哪里了,也就是说拷贝的实际内存地址每一次运行都是不确定的:比如第一次执行a.out的时候,内存一个进程都没有运行,所以搬移程序到内存时,占用0x00000000,但是第二次的时候,内存中已经有10个进程运行了,那执行a.out的时候,内存地址就不确定了