🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 ------ 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- [1. 背景介绍](#1. 背景介绍)
-
- [2 模态基础(Modality Foundations)](#2 模态基础(Modality Foundations))
-
- [2.1 视觉引导(Visual Guidance)](#2.1 视觉引导(Visual Guidance))
- [2.2 文本引导(Text Guidance)](#2.2 文本引导(Text Guidance))
- [2.3 音频引导(Audio Guidance)](#2.3 音频引导(Audio Guidance))
- [2.4 其他模态引导(Other Modality Guidance)](#2.4 其他模态引导(Other Modality Guidance))
- [3 方法(Methods)](#3 方法(Methods))
-
- [3.1 基于 GAN 的方法(GAN-based Methods)](#3.1 基于 GAN 的方法(GAN-based Methods))
-
- [3.1.1 条件 GAN(Conditional GANs)](#3.1.1 条件 GAN(Conditional GANs))
- [3.1.2 无条件 GAN 的反演(Inversion of Unconditional GAN)](#3.1.2 无条件 GAN 的反演(Inversion of Unconditional GAN))
- [3.2 基于扩散模型的方法(Diffusion-based Methods)](#3.2 基于扩散模型的方法(Diffusion-based Methods))
-
- [3.2.1 条件扩散模型(Conditional Diffusion Models)](#3.2.1 条件扩散模型(Conditional Diffusion Models))
- [3.2.2 预训练扩散模型(Pre-trained Diffusion Models)](#3.2.2 预训练扩散模型(Pre-trained Diffusion Models))
- [3.3 自回归方法(Autoregressive Methods)](#3.3 自回归方法(Autoregressive Methods))
-
- [3.3.1 向量量化(Vector Quantization)](#3.3.1 向量量化(Vector Quantization))
- [3.3.2 自回归建模(Autoregressive Modeling)](#3.3.2 自回归建模(Autoregressive Modeling))
- [3.4 基于 NeRF 的方法(NeRF-based Methods)](#3.4 基于 NeRF 的方法(NeRF-based Methods))
-
- [3.4.1 逐场景 NeRF(Per-scene NeRF)](#3.4.1 逐场景 NeRF(Per-scene NeRF))
- [3.4.2 生成式 NeRF(Generative NeRF)](#3.4.2 生成式 NeRF(Generative NeRF))
- [3.5 其他方法(Other Methods)](#3.5 其他方法(Other Methods))
-
- [3.5.1 无生成模型的二维 MISE(2D MISE without Generative Models)](#3.5.1 无生成模型的二维 MISE(2D MISE without Generative Models))
- [3.5.2 非 NeRF 的三维感知 MISE(3D-aware MISE without NeRF)](#3.5.2 非 NeRF 的三维感知 MISE(3D-aware MISE without NeRF))
- [3.6 方法对比与讨论(Comparison and Discussion)](#3.6 方法对比与讨论(Comparison and Discussion))
- [4 实验评估(Experimental Evaluation)](#4 实验评估(Experimental Evaluation))
-
- [4.1 数据集(Datasets)](#4.1 数据集(Datasets))
- [4.2 评测指标(Evaluation Metrics)](#4.2 评测指标(Evaluation Metrics))
- [4.3 实验结果(Experimental Results)](#4.3 实验结果(Experimental Results))
-
- [4.3.1 视觉引导(Visual Guidance)](#4.3.1 视觉引导(Visual Guidance))
- [4.3.2 文本引导(Text Guidance)](#4.3.2 文本引导(Text Guidance))
- [4.3.3 音频引导(Audio Guidance)](#4.3.3 音频引导(Audio Guidance))
- [5 开放挑战与讨论(Open Challenges & Discussion)](#5 开放挑战与讨论(Open Challenges & Discussion))
-
- [5.1 面向大规模多模态数据集(Towards Large-Scale Multi-Modality Datasets)](#5.1 面向大规模多模态数据集(Towards Large-Scale Multi-Modality Datasets))
- [5.2 面向可信评测指标(Towards Faithful Evaluation Metrics)](#5.2 面向可信评测指标(Towards Faithful Evaluation Metrics))
- [5.3 面向高效网络结构(Towards Efficient Network Architecture)](#5.3 面向高效网络结构(Towards Efficient Network Architecture))
- [5.4 面向三维感知(Towards 3D Awareness)](#5.4 面向三维感知(Towards 3D Awareness))
- [6 社会影响(Social Impacts)](#6 社会影响(Social Impacts))
-
- [6.1 与 AIGC 的关系(Correlation with AIGC)](#6.1 与 AIGC 的关系(Correlation with AIGC))
- [6.2 应用前景(Applications)](#6.2 应用前景(Applications))
- [6.3 潜在滥用风险(Misuse)](#6.3 潜在滥用风险(Misuse))
- [6.4 环境影响(Environment)](#6.4 环境影响(Environment))
- [7 结论(Conclusion)](#7 结论(Conclusion))
1. 背景介绍
Zhan F, Yu Y, Wu R, et al. Multimodal image synthesis and editing: A survey and taxonomyJ. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 4.
🚀以上学术论文翻译由ChatGPT辅助。
现实世界中的信息以多种模态形式存在,多模态信息之间的高效交互与融合在计算机视觉与深度学习研究中的多模态数据生成与感知过程中起着关键作用。凭借对多模态信息交互关系的强大建模能力,多模态图像合成与编辑近年来已成为研究热点。不同于为网络训练提供显式约束的方式,多模态引导为图像合成与编辑提供了一种直观且灵活的手段。与此同时,该领域也面临着一系列挑战,包括多模态特征对齐、高分辨率图像合成以及可信评测指标的构建等问题。
在本综述中,我们对近年来多模态图像合成与编辑 领域的研究进展进行了系统梳理,并从数据模态 与模型类型两个维度构建了相应的分类体系。首先,我们介绍了图像合成与编辑中常见的不同引导模态;随后,按照模型类型对多模态图像合成与编辑方法进行了全面综述;接着,我们总结了常用的基准数据集与评测指标,并对相关实验结果进行了分析;最后,我们讨论了当前研究中面临的主要挑战,并展望了未来可能的研究方向。
与本综述相关的项目代码已开源,地址为:
https://github.com/fnzhan/MISE。
人类天生具备根据视觉、文本或音频描述 在脑海中想象场景的能力。然而,这一过程对于深度神经网络而言并不直观,其根本原因在于模态间固有的差异(modality gap) 。在视觉感知层面,这种模态差异主要体现在两个方面:一是模态内差异(intra-modal gap) ,即视觉线索与真实图像之间的差异;二是跨模态差异(cross-modal gap),即非视觉线索与真实图像之间的差异。为了模拟人类在现实世界中的想象力与创造力,**多模态图像合成与编辑(Multimodal Image Synthesis and Editing, MISE)**任务为理解深度神经网络如何将多模态信息与图像属性进行关联提供了重要视角。
作为一个快速发展的研究方向,图像合成与编辑旨在生成具有真实感的图像,或在保持自然纹理的前提下对真实图像进行编辑。近几年,得益于深度学习技术的进步,尤其是深度生成模型 1--3 与神经渲染技术 4 的发展,该领域取得了令人瞩目的进展。为了实现可控生成 ,一条主流研究路线聚焦于在特定引导条件(guidance)下进行图像生成与编辑,如图 1 所示。通常,诸如语义分割图、草图 等视觉线索已被广泛用于引导图像合成与编辑 5--7。在视觉线索的模态内引导 之外,跨模态引导 (如文本、音频和场景图)为表达视觉概念提供了另一种更直观且更灵活的方式。然而,如何从不同模态的数据中有效检索并融合异构信息,仍是多模态图像合成与编辑面临的核心挑战之一。

作为多模态图像合成的早期探索工作,文献 17 表明,循环变分自编码器(recurrent VAE)能够在图像字幕条件下生成新的视觉场景。随后,随着生成对抗网络(GANs) 1, 5, 6, 18--20 以及扩散模型(diffusion models) 3, 21--24 的兴起,多模态图像合成研究取得了显著进展。起源于条件 GAN(Conditional GAN, CGAN) 18,大量 GAN 与扩散模型 5, 6, 10, 25 被提出,用于在生成过程中引入多模态引导信号,从而实现基于多模态条件的图像合成。这种条件生成范式相对直观,已被广泛应用于当前最先进的方法中,并取得了前所未有的生成性能 6, 10, 25--27。然而,条件模型的训练过程通常十分复杂,且伴随着较高的计算成本。
因此,另一类研究路线转向基于预训练模型的 MISE 方法 ,包括:通过反演(inversion)在 GAN 潜空间中进行操作 28--31,在扩散过程中引入引导函数 21, 32,或对扩散模型的潜空间与嵌入进行适配 33--36。目前,**卷积神经网络(CNN)**结构仍被广泛用于 GAN 与扩散模型中,但其结构特性限制了对多样化多模态输入的统一支持。相比之下,随着 Transformer 模型 37 的流行------其天然支持多模态输入------在语言 38、图像 39 和音频 40 等多种模态的数据生成任务中均取得了显著进展。这些由 Transformer 推动的最新成果表明,自回归模型(autoregressive models) 41 可能为 MISE 提供一条新的发展路径,能够更好地建模序列的长程依赖关系。
值得注意的是,多模态引导信息与图像本身均可以表示为离散 token 的统一形式。例如,文本天然可表示为 token 序列;音频和视觉引导(包括图像)也可被编码为 token 序列 42。在这种统一的离散表示下,Transformer 架构的自回归模型能够有效建模多模态引导与图像之间的相关性,并显著推动了 MISE 的研究边界 2, 43, 44。
上述方法大多聚焦于 二维图像 ,而忽略了现实世界的三维本质 。随着神经渲染技术,尤其是神经辐射场(Neural Radiance Fields, NeRF) 4 的发展,三维感知的图像合成与编辑(3D-aware MISE)逐渐受到研究者关注。与二维图像合成与编辑不同,3D-aware MISE 面临更大挑战,主要原因在于多视角数据的匮乏 以及在合成与编辑过程中对多视角一致性 的严格要求。作为一种补救方案,研究者可以利用预训练的二维基础模型(如 CLIP 45 和 Stable Diffusion 46)来驱动 NeRF 的优化,用于视角合成与编辑 11, 47。此外,GAN 与扩散模型也可与 NeRF 结合,在二维图像上训练三维感知生成模型,通过构建条件 NeRF或对 NeRF 进行反演来实现 MISE 48, 49。
本综述的主要贡献可总结如下:
- 本文在合理且结构化的框架下,系统覆盖了多模态图像合成与编辑领域的广泛研究文献。
- 我们从引导模态类型的角度,为多模态图像合成与编辑任务奠定了基础,并详细阐述了与不同引导模态相关的编码方法。
- 我们依据核心模型范式构建了近期方法的分类体系,并分析了现有模型的主要优势与局限性。
- 本文综述了多模态图像合成与编辑中常用的数据集与评测指标,并对代表性方法的实验性能进行了批判性分析。
- 我们总结了当前研究中尚待解决的关键挑战,并分享了对未来潜在研究方向的思考与展望。
本文其余内容组织如下:第 2 节介绍 MISE 的模态基础;第 3 节对多模态图像合成与编辑方法进行系统综述,并给出详细流程;第 4 节回顾常用数据集与评测指标,并总结典型方法的实验结果;第 5 节讨论当前面临的主要挑战及未来研究方向;第 6 节与第 7 节分别给出社会影响分析与总结性讨论。
2 模态基础(Modality Foundations)
任何信息的来源或表现形式都可以称为一种模态(modality) 。例如,人类具有触觉、听觉、视觉和嗅觉等感知模态;信息的载体包括语音、视频、文本等;数据还可以由雷达、红外、加速度计等各类传感器采集而得。在图像合成与编辑 的研究语境下,我们将模态引导(modality guidance)大致划分为视觉引导、文本引导、音频引导 以及其他模态引导。下文将对各类模态引导及其相关处理方法进行详细介绍。
2.1 视觉引导(Visual Guidance)
由于其在传达空间结构与几何细节 方面的天然优势,视觉引导在 MISE 领域受到了广泛关注。值得注意的是,视觉引导通常在像素空间 中对图像的特定属性进行显式刻画,从而提供了极高的可控性。这一特性使得视觉引导在图像合成过程中能够支持交互式操作 与精细化控制 ,对于获得符合预期的生成结果尤为关键。作为一种像素级引导方式,视觉引导可以无缝融入图像生成流程之中,这也解释了其在多种图像合成场景中的广泛应用。
常见的视觉引导形式包括:语义分割图 5, 6、关键点(keypoints) 89--91、草图 / 边缘 / 涂鸦 51, 92--99,以及场景布局(scene layouts) 100--104,如图 1 所示。此外,还有研究探索了基于深度图 2, 8、法向图(normal map) 8、轨迹图(trace map) 105 等条件的图像合成任务。
视觉引导的获取方式多种多样:既可以通过预训练模型 (如语义分割模型、深度预测模型、姿态预测模型)自动生成,也可以借助经典算法 (如 Canny 边缘检测、Hough 直线检测),或依赖人工方式 (如人工标注、人类涂鸦)获得。通过修改视觉引导元素(例如语义分割图),图像合成方法可以被直接用于多种图像编辑任务 106, 107,从而充分体现了视觉引导在 MISE 领域中的灵活性与通用性。
视觉引导的编码(Visual Guidance Encoding)
这些视觉线索以二维像素形式存在,本质上可视为特定类型的图像,因此可以直接采用多种图像编码策略进行表示,例如卷积神经网络(CNN)与 Transformer。由于编码后的特征在空间上与图像特征天然对齐,它们可以通过直接拼接(naive concatenation) 、SPADE 6、跨注意力机制(cross-attention) 46 等方式平滑地融入生成网络中。
2.2 文本引导(Text Guidance)
与视觉引导相比,文本引导 提供了一种更加通用且灵活 的方式来表达和描述视觉概念。这是因为文本能够涵盖大量细节与抽象语义,而这些信息往往难以通过其他模态直接表达。文本描述通常具有一定的歧义性 与开放性 :一方面,这种不确定性可能导致多种不同但合理的图像结果,从而增加生成结果的不可预测性;另一方面,这也为生成结果带来了更高的创造性与多样性。
文本到图像(text-to-image)合成任务 53, 108--110 旨在生成与文本语义高度一致、同时具有清晰结构与真实感的图像。然而,文本与图像属于异构数据类型,这使得从文本到图像之间学习一个准确且稳定的映射关系变得尤为困难。因此,诸如**表示学习(representation learning)**等技术在文本引导的图像合成与编辑中起到了至关重要的作用。
文本引导的编码(Text Guidance Encoding)
从文本描述中学习忠实且有效的表示 并非易事。传统的文本表示方法包括 Word2Vec 111 与 Bag-of-Words 112。随着深度神经网络的发展,循环神经网络(RNN) 109 与 LSTM 54 被广泛用于将文本编码为特征表示 55。进一步地,随着自然语言处理领域中预训练模型 的兴起,一些研究 113, 114 开始利用大规模预训练语言模型(如 BERT 115)进行文本编码。
尤其值得关注的是,对比语言-图像预训练(CLIP) 45 通过在大规模图文对上学习图像与文本之间的对齐关系,能够生成信息量丰富的文本嵌入表示,并已被广泛用于文本引导的图像合成与编辑任务中。
2.3 音频引导(Audio Guidance)
不同于文本引导与视觉引导,音频引导 天然包含时间维度信息 ,因此更适用于生成动态或序列化的视觉内容 。相比文本或视觉线索,音频信号与图像之间的关系通常更加抽象 116--118。例如,与特定动作或环境相关的声音往往只能暗示 而非明确规定对应的视觉内容 119;同时,声音还可以承载情绪色彩 与细微语境,而这些信息并不总是能够通过文本或视觉输入清晰表达。因此,音频引导的多模态图像合成与编辑(audio-guided MISE)面临着一个颇具挑战性的问题,即如何将音频信号合理地解释并映射为视觉内容。
这一过程需要对声音与视觉元素之间复杂关联关系进行建模,相关研究已在**说话人脸生成(talking-face generation)**任务中得到广泛探索 57, 59, 60, 120。该任务的目标是在给定音频输入的条件下,生成逼真的人脸说话动画,从而在时间维度上实现音频与视觉的高度一致。
音频引导的编码(Audio Guidance Encoding)
音频序列可以通过多种方式进行表示与编码。例如,在从视频生成音频的任务中,通常使用深度卷积网络 从视频帧中提取特征,并结合 LSTM 121 生成与输入视频对应的音频波形 122。另一方面,给定的音频片段也可以被表示为一系列特征序列,如声谱图(spectrogram) 、滤波器组特征(fBanks) 、梅尔频率倒谱系数(MFCCs) ,以及预训练 SoundNet 模型的隐层输出 119。
在说话人脸生成任务中,动作单元(Action Units, AUs) 124 也被广泛用于将驱动音频转换为连贯的视觉信号 123,从而生成在口型、表情与语音节奏上高度一致的人脸动画。
2.4 其他模态引导(Other Modality Guidance)
除了视觉、文本和音频引导外,研究者还探索了多种其他模态引导方式,用于指导多模态图像合成与编辑。
场景图(Scene Graph)
场景图将场景表示为有向图结构 ,其中节点对应于物体,边表示物体之间的关系。基于场景图进行图像生成,使模型能够显式推理对象间的关系,并合成具有复杂结构关系的真实图像。通常,场景图可通过图卷积网络(GCN) 125 进行编码,并预测物体的边界框以生成场景布局。例如,Vo 等人 126 提出预测物体之间的关系单元,并通过卷积 LSTM 127 将其转换为视觉布局。
脑信号(Brain Signal)
将脑信号 视为一种模态,用于图像合成或重建,为理解大脑活动机制以及构建脑机接口提供了新的研究方向。近年来,多项研究探索了从**功能性磁共振成像(fMRI)**信号生成图像的可能性。例如,Fang 等人 128 从视觉皮层中解码形状与语义表示,并将二者融合后通过 GAN 生成图像;Lin 等人 129 提出将 fMRI 信号映射到预训练 StyleGAN 的潜空间中,从而实现条件生成;Takagi 与 Nishimoto 130 则通过将 fMRI 信号映射到预训练 潜空间扩散模型(LDM) 46 的不同组成部分,实现了对各模块在大脑区域层面的定量解释。
鼠标轨迹(Mouse Track)
为了实现对图像内容的精确且灵活的操控 ,鼠标轨迹 16 近年来被提出作为一种新颖的引导方式。具体而言,用户可通过鼠标点击在图像中选取一组"控制点(handle points) "与"目标点(target points) ",其目标是将控制点引导至对应的目标位置,从而完成图像编辑。该方法能够以极高的精度对图像进行形变,并支持对姿态、形状与表情等多种属性的操控,适用于多类图像内容。
在实现层面,点的运动信息可以通过基于光流的预训练 Transformer 131, 132 进行监督,或通过作用于生成器特征上的位移补丁损失(shifted patch loss) 16 来引导编辑过程。

3 方法(Methods)
我们将多模态图像合成与编辑(MISE)的方法大体划分为五类:基于 GAN 的方法 (第 3.1 节)、基于扩散模型的方法 (第 3.2 节)、自回归方法 (第 3.3 节)、基于 NeRF 的方法(第 3.4 节)以及其他方法(第 3.5 节)。表 1 总结了四类主流方法的代表性工作,并从优势与不足两个方面进行了对比。
本节将依次介绍这些方法:首先讨论以 GAN 及其反演为核心的 GAN-based 方法;随后系统介绍当前占主导地位的扩散模型方法与自回归方法;接着引入面向 3D-aware MISE 的 NeRF 方法;最后补充若干其他多模态引导下的图像合成与编辑方法,并对不同生成架构的优缺点进行比较与讨论。
3.1 基于 GAN 的方法(GAN-based Methods)
基于 GAN 的方法在 MISE 中被广泛采用,主要包括两条路线:
(1)条件 GAN(Conditional GANs) (第 3.1.1 节),直接在生成器中引入多模态条件以引导生成;
(2)无条件 GAN 的反演(GAN Inversion)(第 3.1.2 节),利用预训练的无条件 GAN,通过在潜空间中操作潜变量来完成多模态图像合成与编辑。
3.1.1 条件 GAN(Conditional GANs)
条件生成对抗网络(CGAN) 18 是对经典 GAN 的扩展,允许模型在给定特定条件(如多模态引导)的情况下生成具有目标属性的图像。其核心思想是在生成器 与判别器中同时引入条件信息,使生成器不仅要"欺骗"判别器,还需与给定条件保持一致。近年来,大量结构设计与训练策略显著提升了 CGAN 在 MISE 中的性能 110,主要体现在以下三个方面:
(1)条件注入(Condition Incorporation)
为了有效引导生成过程,需要将多模态条件合理地融入网络结构中(如图 2 所示)。通常,多模态引导可统一编码为 一维特征 ,并与网络特征进行拼接 18, 59, 109。对于与目标图像在空间上对齐的视觉引导 ,条件可编码为 二维特征图 ,从而为生成或编辑提供精确的空间约束 5。
然而,当引导与目标图像存在视角差异或剧烈形变时,简单的二维编码难以捕捉复杂的结构关系。为此,研究者引入注意力机制 以实现引导与目标图像的对齐 133--135。此外,直接使用深层网络编码视觉引导往往会在归一化层中丢失关键信息,因此提出了空间自适应反归一化(SPADE) 6,并进一步扩展为语义区域自适应归一化 136,以实现区域级别的条件注入。
对于文本等复杂条件,还可通过注意力式条件注入机制 54, 137--139,在生成过程中引导模型聚焦于特定图像区域。另一些工作则将复杂条件映射到中间表示 以提高生成的可信度,例如将音频映射为人脸关键点 58, 120 或 3DMM 参数 140 用于说话人脸生成。对于音频等序列条件 20, 59, 120, 123, 141--144,常采用递归式条件注入机制来建模时间依赖,从而获得平滑的时序过渡。
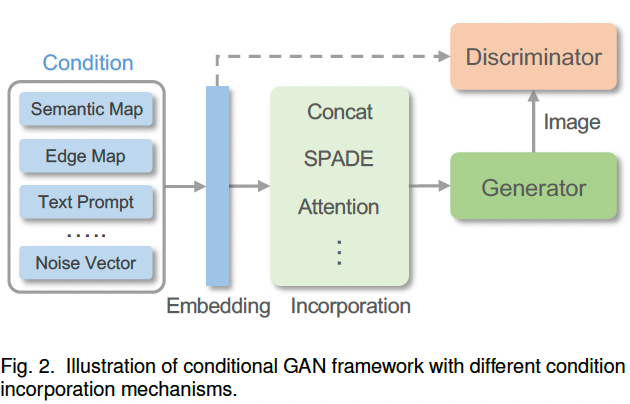
(2)模型结构(Model Structure)
在 GAN 中生成高分辨率且细节丰富的图像具有较高计算成本。由粗到细(coarse-to-fine)的结构 50, 53, 99, 108, 146 通过逐级细化特征或图像,有效缓解了这一问题:模型先关注整体结构,再逐步刻画细节,从而提升训练效率与生成质量。
除生成器外,多尺度判别器 50, 147 也被用于在不同分辨率下区分真实与生成图像,避免高分辨率下的过拟合。
针对语言表达多样但语义一致的场景,部分研究采用孪生网络结构(siamese) ,通过两条生成分支与对比损失 ,拉近语义等价条件的距离、拉远不同语义条件的距离 137, 148, 149;也有工作引入域内变换损失 150 以保持生成过程中的关键特征。此外,循环结构(cycle structure)被用于保持条件一致性:将生成图像送入逆向网络以重建条件输入,从而施加循环一致性约束 55, 151--154。
(3)损失设计(Loss Design)
除对抗损失外,多种损失被用于提升生成质量与条件一致性。对于与真实图像空间对齐的条件,引入感知损失(perceptual loss) 156 可显著提升质量 157。结合循环结构,还常加入循环一致性损失 151;但该损失假设域间为双射关系,限制较强,因此有研究转向单向转换 以规避该假设 150, 158, 159。
随着对比学习的发展,对比损失 被用于最大化正样本对的互信息 160,以保持内容一致性 161--163;三元组损失也被用于增强跨模态条件(如文本)的约束能力 148。
3.1.2 无条件 GAN 的反演(Inversion of Unconditional GAN)
大规模无条件 GAN 145, 164 在高分辨率、高保真图像合成方面取得了显著进展。GAN 反演(GAN inversion) 30 旨在将给定图像映射回预训练 GAN 的潜空间:通过优化潜变量,使生成图像重建输入图像。常用重建指标包括 ℓ1/ℓ2 损失 、感知损失 156 与 LPIPS 165,并可加入人脸身份约束 166 或潜变量正则 31。
在获得潜变量后,便可在潜空间中进行逼真的图像操控;在 MISE 中,这意味着可依据其他模态的引导来生成或编辑潜变量,实现跨模态操作。
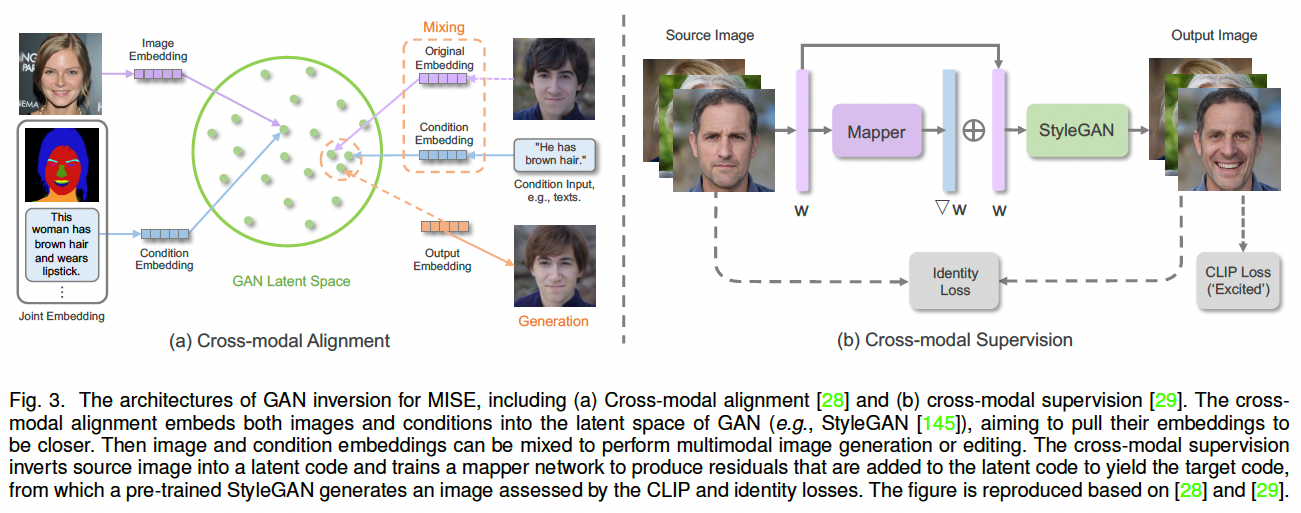
显式跨模态对齐(Explicit Cross-modal Alignment)
一类方法将图像与跨模态输入(如语义图、文本)的嵌入映射到公共嵌入空间 28, 167(如图 3(a))。例如 TediGAN 28 为每种模态训练编码器,并通过相似性损失对齐其嵌入;随后可通过潜空间混合等方式实现跨模态编辑。该方法的难点在于不同模态的异质性,易导致生成不稳定或不忠实。
隐式跨模态监督(Implicit Cross-modal Supervision)
另一类方法不直接投影到潜空间,而是通过定义一致性损失 来约束生成结果与引导模态之间的匹配。例如,利用属性预测器检查编辑图像与文本的一致性 168,但该方式依赖特定领域注释。
近年来,CLIP 45 的出现极大推动了该方向 29, 43:通过 CLIP 空间中的相似性作为监督信号,直接优化潜变量以匹配文本语义 169。StyleCLIP 29、StyleMC 170 使用余弦相似度进行文本引导编辑(如图 3(b))。针对 CLIP 易受对抗扰动的问题 171,提出了 AugCLIP 171 与方向性 CLIP 损失 (StyleGAN-NADA 172)等改进;此外,CLIP 对比损失也被用于增强鲁棒性与反事实编辑能力 173。
3.2 基于扩散模型的方法(Diffusion-based Methods)
近年来,扩散模型(Diffusion Models) ,如去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPMs) 3, 174,在生成式图像建模领域取得了巨大成功 3, 22--24。DDPM 属于一类潜变量模型 ,其核心由正向扩散过程 与反向去噪过程组成。
在正向扩散过程中,模型通过一个马尔可夫链逐步向数据中注入噪声,即在 t = 1 , ... , T t=1,\dots,T t=1,...,T 的时间步上依次采样潜变量 x t x_t xt。每一步的正向转移可表示为高斯分布:
q(x_t \\mid x_{t-1}) := \\mathcal{N}\\big(\\sqrt{1-\\beta_t},x_{t-1}, \\beta_t I\\big),
其中 { β t } t = 1 T \{\beta_t\}_{t=1}^T {βt}t=1T 为预设或可学习的噪声方差调度序列。
反向过程则试图从噪声逐步恢复原始数据,其转移分布同样建模为高斯形式:
p(x_{t-1}\\mid x_t) := \\mathcal{N}\\big(x_{t-1};, \\mu(x_t), \\sigma_t\^2 I\\big),
其中均值项 μ ( x t ) \mu(x_t) μ(xt) 可分解为 x t x_t xt 与一个噪声预测模型 ε θ ( x t , t ) \varepsilon_\theta(x_t, t) εθ(xt,t) 的线性组合。通过最小化噪声预测误差来学习 ε θ \varepsilon_\theta εθ,即可在训练完成后通过反向扩散过程进行采样,从而生成高质量图像。
Song 等人 22 提出了一种非马尔可夫噪声过程 ,在保持与 DDPM 相同正向边缘分布的前提下,允许通过调节噪声方差来使用不同的采样器。特别地,当将噪声设为 0 时,可得到 DDIM(Denoising Diffusion Implicit Models) 采样过程 22,使采样变为确定性,从而以更少的步数实现潜变量的完全反演 21, 22。最新研究 21 进一步表明,扩散模型在图像生成质量上已显著超越 VAE 175、流模型 176, 177、自回归模型 178, 179 以及 GAN 1, 145。
在 MISE 场景中,图像生成与编辑通常需要在给定条件(如文本、视觉或其他模态引导)下进行。现有研究主要沿两条路线展开:一是利用预训练扩散模型 ,通过引导函数或轻量微调实现条件控制 32;二是从头训练条件扩散模型 46。前者的不足在于通常需要额外的引导模型,从而使训练流程更为复杂。为此,Ho 等人 27 提出了一种无需额外引导模型的策略,通过在有标签与无标签预测之间插值实现条件控制。GLIDE 180 对比了 CLIP 引导的扩散模型 与 条件扩散模型 在文本到图像生成任务中的表现,并指出直接训练条件扩散模型往往能获得更优的生成效果。
3.2.1 条件扩散模型(Conditional Diffusion Models)
在 MISE 中,条件扩散模型通过将多模态条件信息直接融入去噪过程来实现可控生成。近年来,一系列关键设计显著推动了该方向的发展,主要体现在以下几个方面:
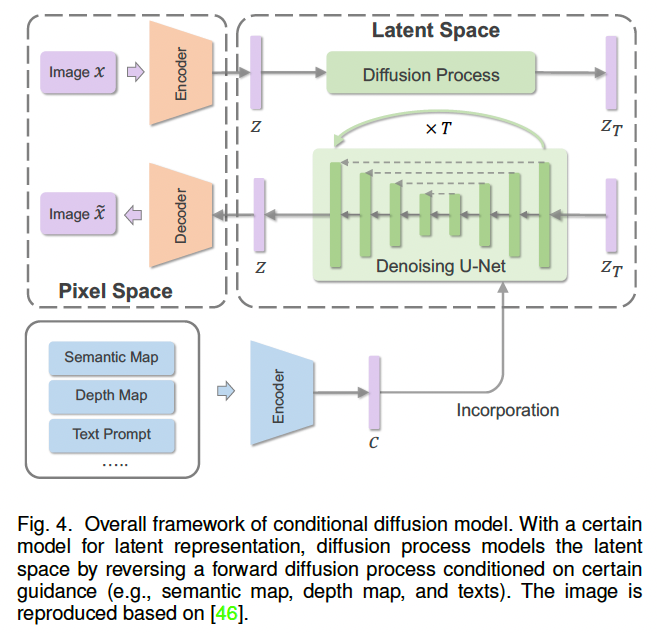
(1)条件注入(Condition Incorporation)
典型框架中,首先使用一个条件特定编码器 将多模态条件映射为嵌入向量,再将其注入扩散模型(如图 4 所示)。该编码器既可与模型联合训练,也可直接采用预训练模型。
在文本条件下,CLIP 是最常用的文本编码器之一,如 DALL·E 2 25;此外,T5 等大规模语言模型在 Imagen 10 中也被证明具有出色的文本编码能力。获得条件嵌入后,可通过多种方式将其引入扩散模型:例如与时间步嵌入进行拼接或相加 21, 183;在 LDM 46 中,条件通过跨注意力(cross-attention)注入中间层。Imagen 10 的实验表明,均值池化或注意力池化在性能上均明显弱于跨注意力机制。
针对视觉引导,Wang 等人 61 通过空间自适应归一化 注入条件,显著提升了生成图像的质量与语义一致性。不同于从头训练条件模型,ControlNet 8 提出在预训练扩散模型 上引入条件控制:通过"零卷积(zero convolution)"结构,在保持原有权重的前提下逐步学习条件分支,实现快速收敛与稳定训练。
(2)潜空间扩散(Latent Diffusion)
为在有限计算资源下训练高质量扩散模型,研究者提出在学习到的潜空间 中执行扩散过程 46(如图 4)。通常,借助自编码器学习与图像空间在感知上等价的潜表示;为抑制潜空间的高方差问题,可通过 KL 散度 将潜分布正则到标准正态分布,或采用 VQGAN 风格的向量量化进行约束 2, 46。
此外,VQ-Diffusion 184 直接在离散潜空间中执行扩散过程;Tang 等人 185 通过改进推理策略缓解联合分布建模问题,进一步提升了生成质量。
(3)模型结构(Model Architecture)
Ho 等人 3 将 U-Net 架构引入扩散模型,充分利用 CNN 的归纳偏置。随后,该结构通过引入注意力模块 21、残差上下采样块 23 以及自适应归一化 21 得到持续改进。尽管 U-Net 是当前 SOTA 扩散模型的主流选择,Chahal 186 表明,基于 Transformer 的 LDM 46 在性能上可与 U-Net 版本相当,并且更自然地支持多模态条件注入。需要指出的是,Transformer 架构在离散潜空间 设置下更具优势 184, 187。
此外,DALL·E 2 25 提出了两阶段生成结构 :先在 CLIP 潜空间中从文本生成图像嵌入,再用扩散模型生成最终图像,从而提升多样性。其他探索还包括组合式扩散结构 188、多扩散过程结构 189 以及基于检索的扩散模型 190,以应对复杂生成或计算成本问题。
3.2.2 预训练扩散模型(Pre-trained Diffusion Models)
相比从头训练扩散模型,另一条重要路线是利用预训练扩散模型,通过引导函数或轻量微调实现 MISE(如图 5 所示)。

(1)引导函数方法(Guidance Function Method)
Dhariwal 等人 21 最早提出在预训练扩散模型中引入分类器引导(classifier guidance) ,并可推广到多种条件引导。具体而言,带引导的反向采样可写为:
x_{t-1} = \\mu(x_t) + \\sigma_t\^2 \\nabla_{x_t} \\log p(y \\mid x_t) + \\sigma_t \\varepsilon,\\quad \\varepsilon \\sim \\mathcal{N}(0, I),
其中 F ( x t , y ) = log p ( y ∣ x t ) F(x_t, y)=\log p(y\mid x_t) F(xt,y)=logp(y∣xt) 被称为引导函数 ,用于衡量当前样本与条件 y y y 的一致性。该一致性通常在特征空间中计算,因此常借助 CLIP 作为图像与文本编码器 32(如图 5(a))。
由于 CLIP 训练于干净图像而非噪声图像,相关工作对 CLIP 进行自监督微调,以对齐干净与噪声输入的特征 32。此外,引入引导强度参数 γ \gamma γ 可调节一致性与多样性之间的权衡:
x_{t-1} = \\mu(x_t) + \\sigma_t\^2 \\gamma \\nabla_{x_t} \\log p(y \\mid x_t) + \\sigma_t \\varepsilon.
γ \gamma γ 越大,生成结果与条件的一致性越强,但多样性相应下降 21。在图像编辑场景中,还可采用混合扩散(blended diffusion) 191,通过在不同噪声阶段对局部区域进行融合,实现局部引导。
(2)微调方法(Fine-tuning Method)
微调策略通过对潜变量或模型参数 进行小规模更新来实现 MISE(如图 5(b))。对于无条件模型,可先将输入图像通过正向扩散映射到潜空间,再在反向路径中结合 CLIP 损失 进行文本引导编辑 33。
对于预训练的条件扩散模型(通常以文本为条件),类似 GAN 反演的方法可通过微调文本嵌入或模型本身,以少量样本重建特定对象 35, 36,并在新场景中复现该对象。但此类方法往往会破坏原始图像的空间布局。为此,Prompt-to-Prompt 34 通过操控跨注意力映射来保留原始内容;另一类方法利用逐步去噪特性,在早期阶段通过得分引导保持结构与内容 192。类似思想也被用于通过文本嵌入插值实现内容保留的编辑 181。
3.3 自回归方法(Autoregressive Methods)
随着 GPT 等大型语言模型在自然语言建模领域的成功 38,自回归模型(Autoregressive Models) 也被成功引入到图像生成任务中 39。其核心思想是将图像展平为离散 token 序列,并像建模文本一样对图像进行逐 token 预测。实验结果表明,自回归模型不仅能够刻画像素之间的空间依赖关系,还能够有效建模图像的高层语义属性。
与 CNN 相比,Transformer 架构 在结构上天然支持多模态输入的统一建模,因此逐渐成为多模态图像合成与编辑的重要选择。近年来,大量研究基于 Transformer 的自回归范式探索多模态图像合成与编辑(MISE)问题 2, 44, 69, 194。总体而言,自回归 MISE 方法通常由两个关键阶段组成:
(1)**向量量化(Vector Quantization)**阶段,用于将不同模态的数据映射为统一的离散表示并实现数据压缩;
(2)自回归建模阶段,在光栅扫描(raster-scan)顺序下对离散 token 序列进行概率建模,如图 6 所示。
3.3.1 向量量化(Vector Quantization)
直接将高分辨率图像的所有像素作为 token 序列输入 Transformer 进行自回归建模,在计算与存储上代价极高,因为自注意力机制的复杂度随序列长度呈二次增长。因此,学习紧凑且离散的图像表示是自回归图像合成与编辑的关键前提。
早期工作 39 采用 k-means 聚类 对 RGB 像素值进行离散化,以降低输入维度。然而,该方法仅减少了 token 的取值空间,而并未缩短序列长度,仍难以扩展到高分辨率场景。为此,向量量化变分自编码器(VQ-VAE) 42 被广泛采用,用于学习离散且压缩的图像表示。
VQ-VAE 通常由三部分组成:编码器、特征量化器和解码器。图像首先经编码器映射到连续特征空间,随后通过量化器将连续特征映射到最近的码本向量(codebook entry),最终由解码器从量化后的离散特征重建原始图像。由于最近邻分配操作不可导,通常采用**直通估计器(straight-through estimator)**或重参数化技巧 42, 196 近似梯度。围绕 VQ-VAE,研究者从多个角度对其进行了改进,以获得更高质量的离散表示。
(1)损失函数设计(Loss Function)
为了提升重建图像的感知质量,研究表明在像素级重建损失之外,引入对抗损失 以及基于预训练 VGG 网络的感知损失(perceptual loss) 156, 199, 200 能显著改善视觉效果 2。此外,基于自监督学习的 Vision Transformer 201, 202 也被证明可以作为感知损失的有效特征提取器。在特定任务(如人脸重建)中,还可引入基于预训练人脸嵌入网络的特征匹配损失 203,以强化关键区域的重建质量。
(2)网络结构(Network Architecture)
传统 VQ-VAE 多采用卷积神经网络作为编码器与解码器。Yu 等人 197 提出用 Vision Transformer(ViT) 204 替代卷积结构,减少卷积先验带来的限制,并在重建质量与计算效率上取得更优表现。随着扩散模型的发展,基于扩散的解码器 205 也被用于学习高保真离散表示。此外,多尺度量化结构 206, 207 能同时建模低层细节与高层语义,而残差量化(residual quantization) 208 则通过递归量化进一步降低计算成本。
(3)码本利用率(Codebook Utilization)
标准 VQ-VAE 在使用 arg min \arg\min argmin 操作进行量化时,常出现码本塌缩(codebook collapse)问题,即仅少数码本向量被频繁使用 209。为缓解该问题,vq-wav2vec 210 引入 Gumbel-Softmax 211 以可导方式进行离散采样,显著提升了码本利用率。ViT-VQGAN 197 还提出因子化码本结构,通过低维潜空间索引进一步改善码本使用效率。
(4)学习正则化(Learning Regularization)
研究 198 指出,标准 VQ-VAE 在量化过程中不满足平移等变性(translation equivariance),从而影响文本到图像生成性能。为此,TE-VQGAN 198 通过对码本嵌入施加正交性正则,实现平移等变量化。针对条件生成中的异构数据分布问题,IQ-VAE 212 通过惩罚跨域差异、保留域内变化,对潜空间结构进行正则化。
3.3.2 自回归建模(Autoregressive Modeling)
自回归建模遵循概率链式法则,将序列的联合分布分解为条件分布的乘积:
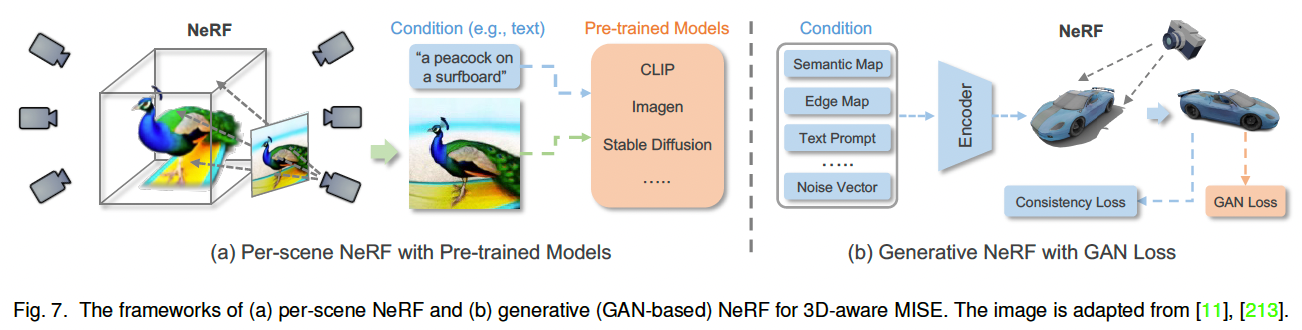
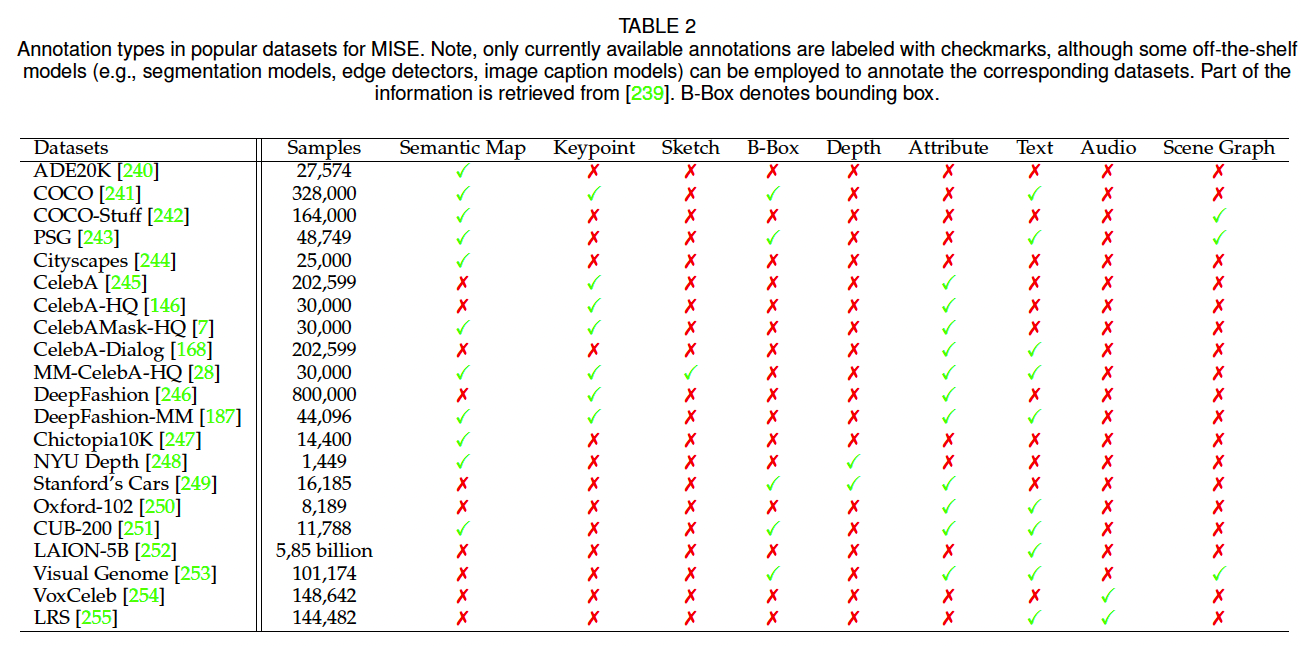
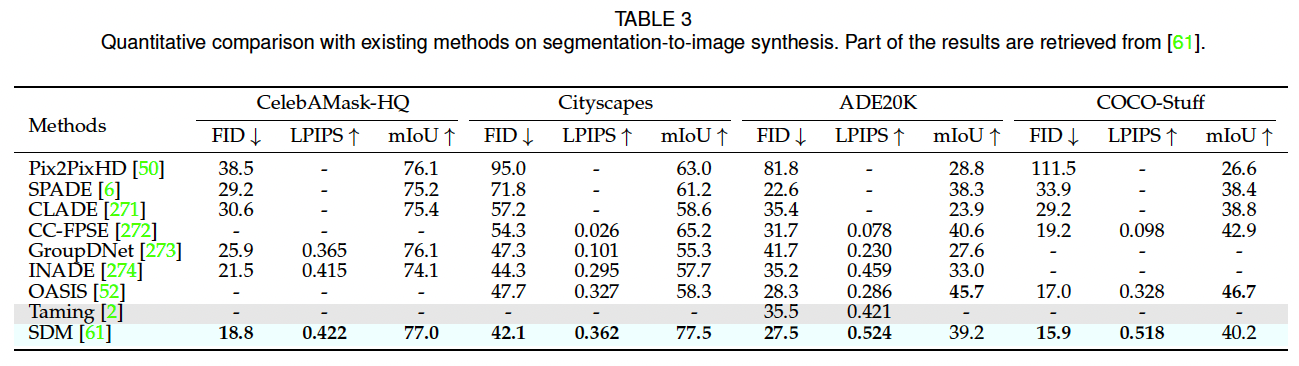
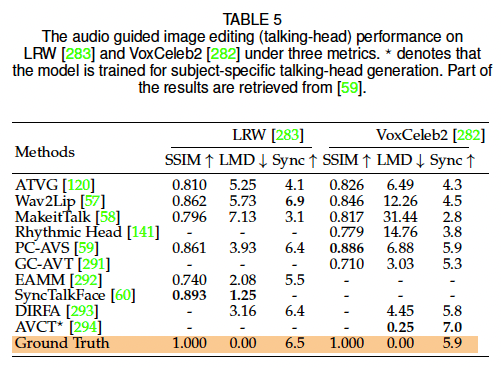
p(x) = \\prod_{t=1}\^{n} p(x_t \\mid x_1, x_2, \\dots, x_{t-1}) = \\prod_{t=1}\^{n} p(x_t \\mid x_{\ 在推理阶段,模型按照光栅扫描顺序逐 token 预测,并将新生成的 token 作为条件输入下一步预测。为降低推理开销,可采用滑动窗口策略 2,仅利用局部上下文进行预测;同时,top-k 采样等随机采样策略可自然提升生成结果的多样性。 在 MISE 任务中,自回归模型在条件概率建模中同时考虑已生成的图像 token 与多模态条件信息,从而能够捕获复杂依赖关系,生成在语义与结构上高度一致的图像。近年来,自回归 MISE 的快速发展主要得益于以下几类关键设计。 (1)网络结构(Network Architecture) 早期方法多基于 PixelCNN 214,但其有限的感受野难以建模长程依赖。Transformer 的引入 37, 215 显著提升了上下文建模能力。Parti 71 通过将 Transformer 规模扩展至 20B 参数,验证了模型规模对文本到图像质量和对齐性的持续增益。除单向生成外,部分研究还探索了双向结构 216, 217,在统一框架下同时生成图像与文本描述。 (2)双向上下文建模(Bidirectional Context) 传统自回归方法仅关注已生成的前序 token,存在明显的单向偏置 与暴露偏差(exposure bias) 。ImageBART 194 提出一种统一的粗到细(coarse-to-fine)建模框架,通过扩散过程逐步移除信息,形成多层级表示,并在自回归建模中引入全局上下文。另一类方法采用双向 Transformer 结合 掩码视觉 token 建模(MVTM) 219 或 掩码语言建模(MLM) 220, 221,以显式利用双向上下文信息。 (3)自注意力机制优化(Self-Attention Mechanism) 为在统一框架下处理语言、图像与视频,NUWA 44 提出 3D Nearby Self-Attention(3DNA),在降低注意力复杂度的同时取得优异性能。针对高分辨率语义编辑任务,ASSET 222 通过在高分辨率层面稀疏化注意力矩阵,并借助低分辨率密集注意力进行引导,大幅降低了计算开销。 神经场(Neural Field) 223 是一种由神经网络(全部或部分)参数化的连续场表示形式。作为神经场的一个重要特例,神经辐射场(Neural Radiance Fields, NeRF) 4 通过使用神经网络对三维场景的**颜色(radiance)与 体密度(density)进行隐式建模,在新视角合成任务中取得了突破性进展。具体而言,NeRF 通常采用一个全连接神经网络,以空间坐标 ( x , y , z ) (x,y,z) (x,y,z) 及对应的视角方向 ( θ , ϕ ) (\theta,\phi) (θ,ϕ) 作为输入,输出该位置处的体密度与视角相关的辐射颜色。随后,通过可微体渲染(differentiable volume rendering)**对隐式三维表示进行数值积分 4,从而生成二维图像。 借助 NeRF 对三维场景的高质量表示能力,**三维感知的多模态图像合成与编辑(3D-aware MISE)**可以通过两条主要技术路线实现:逐场景(per-scene)NeRF 与 生成式(generative)NeRF。 逐场景 NeRF 延续了原始 NeRF 的思想,对单一场景进行优化与表示,监督信号可来自图像数据或预训练模型。 (1)基于图像监督(Image Supervision) 在具备成对的引导条件与对应视角图像时,可直接训练条件 NeRF 以完成 MISE 任务。例如,AD-NeRF 13 在包含音频轨道的视频序列上训练 NeRF,实现了高保真的说话人头部合成。与传统通过中间表示连接音频与视频的方法不同,AD-NeRF 将音频特征直接输入隐式函数,构建动态 NeRF ,并通过体渲染生成与音频同步的高质量说话人脸视频。然而,这类方法通常依赖成对条件--图像数据 及多视角采集,在实际应用中成本较高、可扩展性有限。 (2)基于预训练模型监督(Pre-trained Model Supervision) 为摆脱对多视角数据与成对标注的依赖,研究者引入预训练模型来从零开始优化 NeRF,如图 7(a) 所示。典型方法是利用 CLIP 进行文本驱动的三维感知合成 224:通过优化 NeRF,使其在多视角渲染下的二维图像与目标文本描述在 CLIP 空间中获得高相似度。类似思想也被用于 AvatarCLIP 225,实现零样本文本驱动的三维虚拟人生成与动画。 随着扩散模型的兴起,预训练的二维扩散模型被证明可作为强大的三维生成先验。DreamFusion 11 基于概率密度蒸馏(probability density distillation)思想,利用二维扩散模型对随机初始化的三维神经场进行梯度优化,使其渲染结果符合给定文本条件。Magic3D 47 在此基础上进一步结合高效的可微渲染器 213, 226,直接优化带纹理的三维网格模型,并与潜空间扩散模型协同工作。 需要注意的是,依赖预训练模型优化 NeRF 本质上是一个欠约束问题 ,因此引入合理的先验与正则化至关重要。研究表明,几何先验 (如稀疏性约束与场景边界限制)可显著提升生成质量 224;为缓解单视角带来的几何歧义,DreamFusion 11 采用随机光照方向以显式揭示几何细节;此外,Ref-NeRF 227 提出的**朝向损失(orientation loss)**可用于避免法向量错误地背向相机。 与仅适用于单一场景的逐场景 NeRF 不同,生成式 NeRF通过将 NeRF 与生成模型相结合,能够在不同场景间实现泛化。在该框架下,场景通常由一个**潜变量(latent code)**进行控制。 GRAF 228 首次将 GAN 引入辐射场建模,通过多尺度 patch 判别器实现生成式 NeRF 训练。随后,大量工作对生成式 NeRF 进行了改进: 在这些进展的推动下,3D-aware MISE 通常沿着条件生成式 NeRF 或生成式 NeRF 反演两条路径展开。 (1)条件 NeRF(Conditional NeRF) 在条件生成式 NeRF 中,场景由三维位置与给定条件共同决定,如图 7(b) 所示。条件信息可采用与 GAN 或扩散模型类似的策略注入 NeRF。例如,文献 235 使用预训练 CLIP 提取文本与视觉特征作为条件,引导 NeRF 生成;pix2pix3D 49 则将视觉引导与随机噪声编码为 triplane 表示,并同步渲染图像与像素对齐的语义标签图,从而支持交互式的跨视角三维编辑。 (2)NeRF 反演(NeRF Inversion) 随着生成式 NeRF 在三维感知合成中的成熟,一些研究开始探索其反演机制 以支持 3D-aware MISE。由于生成式 NeRF(通常基于 GAN)具备潜空间,跨模态引导可被映射到该潜空间中,实现条件三维生成 236。然而,该方法在局部可控编辑 方面能力有限。为此,部分工作提出训练具备三维语义感知能力的生成式 NeRF 48, 237,通过双分支结构同时生成图像与空间对齐的语义掩码,从而在反演过程中实现对三维体素的局部编辑。 另一方面,NeRF 反演还面临相机位姿 引入的额外难度。StyleNeRF 233 提出一种混合反演策略,结合基于编码器与基于优化的方法:编码器预测相机位姿与粗略风格码,随后通过反向优化进一步精细化。为实现更灵活的三维编辑,CLIP 等预训练模型也被引入反演过程。例如,CLIP-NeRF 238 通过类似 StyleCLIP 29 的 CLIP 匹配损失,引导潜变量朝目标文本语义方向优化,实现文本驱动的 3D-aware 操作。 除上述主流方法外,仍有不少研究工作从不同技术路径探索多模态图像合成与编辑(MISE)问题,形成了一些具有代表性的补充方向。 不同于依赖 GAN、扩散模型或自回归模型的生成范式,一部分研究尝试在不显式引入生成模型 的前提下实现多模态二维图像编辑。 例如,CLVA 256 通过对"内容图像--文本风格指令"构成的对比样本进行建模,实现文本引导的图像风格操控,其核心思想在于刻画内容与风格之间的相对关系(mutual relativeness) 。然而,该方法在训练阶段需要风格图像与文本提示成对出现,在数据获取与泛化性方面存在一定局限。 为摆脱对成对风格样本的依赖,CLIPstyler 257 借助预训练 CLIP 模型,实现文本引导的风格迁移。该方法通过训练一个轻量级网络,将内容图像映射至满足文本条件的风格空间,而无需显式训练大规模生成模型。进一步地,在视频场景中,Loeschcke 等人 258 将 CLIP 引入视频风格化任务,实现基于两个目标文本的对象级视频风格编辑。 在三维感知 MISE 领域,除 NeRF 之外,传统三维表示 (如网格、点云)同样可用于多模态合成与编辑任务 259, 260。 例如,在三维场景风格迁移任务中,Mu 等人 261 基于点云表示学习几何感知的内容特征,并通过点到像素的**自适应注意力归一化(AdaAttN)**机制,将二维图像风格迁移至三维场景中。 此外,还有一类研究工作尝试将 GAN 框架扩展至三维感知生成,而不显式构建 NeRF 表示,包括: 不同生成范式在 MISE 任务中各具优势与局限性。 GAN-based 方法 GAN 在 FID、Inception Score 等指标上通常具备出色的生成保真度,并且推理速度快,适合高分辨率图像合成。然而,GAN 的训练过程 notoriously 不稳定 ,容易出现模式坍缩(mode collapse)。此外,相比于基于似然的生成模型(如扩散模型与自回归模型),GAN 更偏向于优化视觉逼真度,而在刻画数据分布多样性方面存在不足 21。从结构上看,GAN 多基于 CNN 架构(尽管已有部分工作探索 Transformer 266--268),在统一建模多模态数据与跨任务泛化能力方面仍存在局限。 自回归模型与扩散模型 随着 Transformer 的广泛应用,自回归模型能够在统一框架下处理多模态 MISE 任务,具备良好的建模灵活性。然而,由于其逐 token 预测特性,自回归模型在推理阶段存在速度较慢 的问题;扩散模型同样需要多步迭代采样,推理效率也是一大瓶颈。尽管如此,目前 SOTA 方法更倾向于采用自回归或扩散模型 ,尤其在文本到图像生成任务中表现突出。这两类模型均属于基于似然的生成模型,具有稳定的训练目标与较好的优化特性。 关于自回归模型与扩散模型在生成能力上的优劣,目前尚无定论。DALL·E 2 25 表明扩散模型在建模扩散先验方面略占优势;而 Parti 71 则展示了大规模自回归模型在生成质量与文本对齐性上超越 Imagen 等扩散模型的潜力。这也为融合两类模型优势提供了新的研究契机。 NeRF-based 方法 与主要针对二维图像的生成方法不同,NeRF-based 方法显式建模三维几何结构,因此对训练数据提出了更高要求。例如,逐场景 NeRF 通常依赖带位姿标注的多视角图像或视频,而生成式 NeRF 往往假设数据集的几何结构相对简单。这些因素使得 NeRF 在高保真 MISE 场景中的应用仍然受限。尽管如此,NeRF 对真实世界三维结构的显式建模为未来 MISE 研究打开了新的大门,具有重要的长期价值。 模型融合趋势 值得注意的是,近年来的先进方法越来越倾向于融合不同生成范式以发挥各自优势。例如: 总体而言,多模态图像合成与编辑正呈现出模型范式融合、二维到三维扩展、生成与编辑一体化的发展趋势,为后续研究提供了广阔空间。 数据集是图像合成与编辑任务的核心基础 。为全面呈现多模态图像合成与编辑(MISE)中常用数据集的情况,表 2 总结了主流数据集中所包含的标注类型 与模态信息 。 其中,ADE20K 240、COCO-Stuff 242 与 Cityscapes 244 是语义图像合成 领域最常用的基准数据集;Oxford-120 Flowers 250、CUB-200 Birds 251 以及 COCO 241 被广泛应用于文本到图像合成 任务;而在**说话人脸生成(talking-face generation)**任务中,VoxCeleb2 282 与 Lip Reading in the Wild(LRW) 283 通常作为标准评测数据集。 不同 MISE 任务在数据标注形式、模态组合以及规模上存在显著差异,这也直接影响了模型设计与评测方式。关于各类 MISE 任务中常用数据集的更详细说明,可参考本文的补充材料。 精确且合理的评测指标 对于推动研究进展至关重要。然而,由于 MISE 任务往往同时涉及图像质量、多样性以及条件一致性 等多个维度,而图像评价本身又具有较强的主观性,因此其评测尤为具有挑战性。为实现相对可靠的评价,现有研究通常采用多指标联合评估的方式,从不同角度刻画模型性能。 在整体图像质量 评估方面,Inception Score(IS) 284 与 Fréchet Inception Distance(FID) 285 是最常用的指标;在生成多样性 评估方面,LPIPS 165 被广泛用于衡量不同生成结果在感知空间中的差异。这三类指标具有较强的通用性,可应用于多种图像生成任务。 在**条件一致性(alignment)**评估方面,评测指标通常依赖于具体任务设定,例如: 尽管 IS 具有计算简单、适用范围广的优点,但其在鲁棒性 与抗噪声能力 方面受到广泛质疑;同时,IS 难以检测过拟合生成 (如模型记忆训练样本)以及域内多样性不足(如模型仅生成单一高质量样本)等问题。相比之下,FID 在整体质量评估上更为稳定,但其隐含假设特征分布服从高斯分布,这在实际中并不总是成立。 对于多样性评估指标(如 LPIPS),其并不直接关注生成图像的真实感,因此即便生成结果不够真实,也可能获得较高的多样性分数。至于条件一致性指标,虽然能够量化生成结果与条件之间的匹配程度,但同样存在一定局限性,例如: 有关各类评测指标的更深入分析与讨论,可参考本文的补充材料。总体而言,单一评测指标往往难以全面反映模型性能 ,在 MISE 任务中应结合多种指标进行综合评估,以获得更全面、可信的实验结论。 为直观展示多模态图像合成与编辑(MISE)的能力与有效性,我们在图 8 中给出了在多种引导模态组合条件下的合成结果可视化 。更多定性结果请参见补充材料。除此之外,我们还对不同模型在定量指标 上的表现进行了系统比较,覆盖视觉引导、文本引导与音频引导三类典型场景,具体如下。 在视觉引导设置下,由于**语义图像合成(semantic image synthesis)**具有较为成熟的评测基准与丰富的方法对比,我们主要围绕该任务展开实验比较。按照文献 6 的实验设置,表 3 汇总了在四个具有挑战性的基准数据集上的结果:ADE20K 240、ADE20K-outdoors 240、COCO-Stuff 242 与 Cityscapes 244。评测指标包括 FID 、LPIPS 与 mIoU。 其中,mIoU 用于评估生成图像与目标语义分割图之间的一致性,具体做法是利用预训练语义分割网络对生成图像进行预测,并与真实分割标注进行对比。实验中,Cityscapes 采用预训练 UperNet101 288,ADE20K 与 ADE20K-outdoors 采用 multi-scale DRN-D-105 289,而 COCO-Stuff 则采用 DeepLabV2 290。 从表 3 可以看出,基于扩散模型的方法 (如 SDM 61)在 FID 与 LPIPS 指标上表现出更优的生成质量与多样性,同时在 mIoU 上与 GAN-based 方法相比具有相当的语义一致性 。尽管不同方法在模型规模与训练资源上并不完全可比,扩散模型仍展现出其在语义图像合成任务中的强大建模能力。 相比之下,自回归方法 Taming Transformer 2 并未在该任务中显现出明显优势。我们推测其原因在于:Taming Transformer 是一个面向通用条件生成 的统一框架,并未针对语义图像合成任务进行专门设计;而表 3 中的其他方法则在模型结构或损失设计上更具任务针对性。值得注意的是,自回归方法与扩散方法在机制上天然支持多样化生成结果,而 GAN-based 方法通常需要引入额外模块(如 VAE 175)或特殊设计,才能实现较好的多样性。 在文本引导场景下,我们以 COCO 数据集 为基准,对主流文本到图像生成方法进行了比较,定量结果汇总于表 4(结果均摘自对应原始论文)。从表中可以看到,GAN-based、自回归以及扩散模型在 FID 指标上均已达到或接近当前最优水平,例如: 尽管三类方法在数值上均取得了极具竞争力的结果,近年来的 SOTA 工作更倾向于采用自回归模型与扩散模型 。其主要原因在于这两类方法具有稳定的训练目标 与良好的可扩展性,在模型规模与数据规模不断增大的背景下表现出更强的发展潜力 21。 在音频引导的图像合成与编辑任务中,我们主要围绕**音频驱动的说话人脸生成(audio-driven talking face generation)**展开定量评测。该任务在现有研究中已形成较为成熟的评测流程,而当前方法仍以 GAN-based 模型 为主,自回归或扩散模型在该方向上的探索相对有限。 表 5 给出了在 LRW 283 与 VoxCeleb2 282 数据集上的定量结果,对比指标涵盖口型同步、关键点误差等常用评测维度。总体而言,现有 GAN-based 方法在音频--视觉对齐方面已取得较好效果,但在长时间一致性、身份保持以及跨说话人泛化能力等方面仍存在改进空间,这也为将扩散模型或自回归模型引入音频引导 MISE 提供了潜在研究机会。 尽管多模态图像合成与编辑(MISE)近年来取得了显著进展,并在多项基准任务中展现出优异性能,但该领域仍面临若干亟待解决的关键挑战。本节系统梳理这些典型问题,结合现有研究进展,讨论潜在解决思路,并展望未来研究方向。 现有数据集多以单一模态标注 为主(如仅提供语义分割或文本描述),这在一定程度上限制了方法对多模态联合条件生成 的探索。因此,大多数工作仍集中于单模态引导的图像合成与编辑(如文本到图像、语义图到图像)。然而,人类在创作视觉内容时,往往能够同时融合多种模态信息进行表达,这也正是通向更高层次人工智能的重要方向。 近期已有一些探索性工作尝试引入多模态联合建模:例如,Make-A-Scene 72 在自回归建模中引入语义分割 token 以提升生成质量;ControlNet 8 将多种视觉条件(如边缘、姿态、深度)融入 Stable Diffusion,实现可控文本到图像生成;PoE-GAN 270 在 MMCelebA-HQ 28、COCO 241 与 COCO-Stuff 242 上实现了基于分割、草图、图像与文本的多模态条件生成。然而,这些数据集的规模与多样性仍远不足以逼近真实世界分布。 因此,未来亟需构建大规模、多模态标注齐全的数据集 ,覆盖语义分割、文本描述、场景图等多种模态。一种可行路径是借助预训练模型自动生成标注 :例如,使用分割模型生成语义图、检测模型标注目标框等;此外,合成数据由于天然具备多模态可控标注的优势,也为数据构建提供了重要补充。 准确且可信的评测指标是推动 MISE 研究持续发展的关键,但目前仍是一个开放问题。基于预训练模型的自动指标(如 FID)受限于其训练数据分布,往往与目标数据集存在偏差;而用户主观评测(user study)虽能直接反映人类偏好,却在时间与成本上代价高昂,难以规模化。 随着多模态预训练模型的发展,CLIP 45 被广泛用于评估生成图像与文本之间的匹配程度,但已有研究表明其评分与人类主观偏好并非高度一致。为兼顾强表征能力 与人类偏好一致性 ,一种有前景的方向是:在预训练模型(如 CLIP)的基础上,利用人类偏好数据进行微调 295, 296,从而构建更符合感知质量与语义一致性的 MISE 评测指标体系。 自回归模型与扩散模型因其对多模态输入的天然支持及强大的生成能力,已成为统一 MISE 建模的重要范式。然而,两者均面临推理速度较慢的问题,尤其在高分辨率图像生成场景下更为突出。一些工作 297, 298 尝试对自回归与扩散模型进行加速,但多局限于低分辨率或简单数据集。 近期,Song 等人 299 提出的一致性模型(Consistency Models)基于扩散过程,能够在一步或少量步数内将噪声直接映射至数据分布,同时支持通过多步采样在效率与质量之间进行权衡。该类模型在采样效率上的优势,为 MISE 中高效网络结构设计提供了新的研究契机,具有重要的探索价值。 随着神经场表示模型,尤其是 NeRF 的兴起,三维感知的图像合成与编辑 被认为是 MISE 潜在的下一个突破点。生成式 NeRF(如 StyleNeRF、EG3D)通过引入潜空间,使其在 MISE 场景中尤具吸引力,并已在几何结构相对简单的对象(如人脸、车辆)上取得成功,训练方式甚至可类比于无条件 GAN。 在此基础上,研究者已探索了一些 3D-aware MISE 任务,如 text-to-NeRF 235 与 semantic-to-NeRF 236。然而,现有生成式 NeRF 在面对几何结构复杂、变化多样的自然场景(如 DeepFashion 246、ImageNet 300)时仍表现受限。 仅依赖生成模型从无位姿的二维图像中学习复杂三维几何,本质上是一个高度不适定的问题。潜在解决思路包括: (1)引入更强的几何先验 ,如利用现成三维重建模型 301、人体骨架先验等; (2)提供更强监督信号 ,如构建包含多视角或显式几何信息的大规模数据集。 近期一些工作已验证了先验知识在 3D-aware 任务中的重要性 261, 301, 302。一旦生成式三维建模能够稳健地扩展至复杂自然场景,诸如 "3D 版 DALL·E" 等多模态应用将成为可能。 作为近年来 AI 生成内容(AI-Generated Content, AIGC) 浪潮中的重要组成部分,多模态图像合成与编辑(MISE)因其不断提升的生成真实感与编辑灵活性,受到了学术界与产业界的广泛关注。MISE 技术在赋能内容创作的同时,也可能带来潜在的社会风险。本节从 AIGC 关联性、应用价值、潜在滥用以及环境影响等角度,对 MISE 的社会影响进行系统分析。 随着 Stable Diffusion 、ChatGPT 等模型的出现,AIGC 已成为人工智能领域的研究热点。MISE 与 AIGC 的共通点在于:二者均依托机器学习与深度学习模型,生成新颖且具有创造性的内容 。 但二者在研究范畴与目标上仍存在明显差异。 具体而言,MISE 是 AIGC 的一个重要分支 ,专注于在多模态引导(如文本、视觉、音频等)的控制下,对图像进行生成与编辑,其核心目标是模拟人类在真实多模态世界中的视觉表达与成像能力;而 AIGC 的覆盖范围更为广泛 ,不仅包括图像,还涵盖文本、音频、视频乃至跨模态内容的自动生成。因此,MISE 可被视为 AIGC 体系中面向视觉创作的一类高可控性技术路径。 多模态图像合成与编辑技术在艺术创作与内容生产领域具有广阔应用前景,可为设计师、摄影师与内容创作者提供高效、灵活的创作工具 303。通过引入文本、草图、语义结构等中间条件,用户能够以更直观的方式表达创作意图,从而显著提升创作效率与交互体验。 此外,MISE 技术也有望被普及到日常娱乐与大众应用 中,作为图像生成与编辑工具服务于普通用户。多模态条件作为中间表示,大幅降低了专业门槛,使非专业用户也能参与到高质量内容创作中。总体而言,这类技术在一定程度上降低了创作门槛、释放了公众创造力,具有积极的社会价值。 另一方面,MISE 技术不断增强的生成真实感与编辑能力,也可能被用于恶意篡改或伪造图像内容 ,从而传播虚假信息或误导公众,带来负面社会影响。 为应对潜在滥用风险,一种重要方向是发展自动化生成内容检测技术 ,用于识别合成图像或编辑痕迹,该方向已成为研究热点之一 304。与此同时,在实际部署 MISE 技术时,还应综合考虑安全机制、内容标注与访问控制策略,以降低其被滥用的风险。 作为典型的深度学习方法,当前多模态生成模型在训练与推理阶段通常依赖 GPU 等高性能计算资源,伴随着显著的能耗与碳排放,在可再生能源尚未大规模普及的背景下,可能对环境与气候产生一定负面影响。 缓解这一问题的一个重要方向在于提升模型的泛化能力与复用性。例如,一个在多数据集上预训练、具备良好泛化能力的模型,可显著减少下游任务的训练成本,或直接为下游任务提供语义先验,从而降低整体计算开销。 本文系统综述了**多模态图像合成与编辑(MISE)领域的研究进展。首先,我们从引导模态的角度,对 视觉引导、文本引导、音频引导以及其他模态引导(如场景图)**进行了全面梳理;随后,详细介绍并对比了当前主流的图像合成与编辑范式,包括 GAN-based 方法、扩散模型、自回归模型以及 NeRF-based 方法,并分析了它们在建模能力、稳定性、效率与适用场景等方面的优缺点。 在此基础上,我们系统总结了不同 MISE 任务中常用的数据集与评测指标,并通过定量与定性实验对现有方法的性能进行了对比分析。最后,本文从多模态数据规模、评测体系、模型结构效率与三维感知能力等角度,讨论了 MISE 当前面临的主要挑战,并展望了未来可能的发展方向。 总体而言,多模态图像合成与编辑正处于快速演进阶段,其在多模态融合、生成与编辑一体化以及二维向三维拓展等方面的发展潜力,为未来智能视觉创作与人机交互提供了广阔空间。 🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。 📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄 💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。 🔥🔥🔥 "Stay Hungry, Stay Foolish" ------ 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙 👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!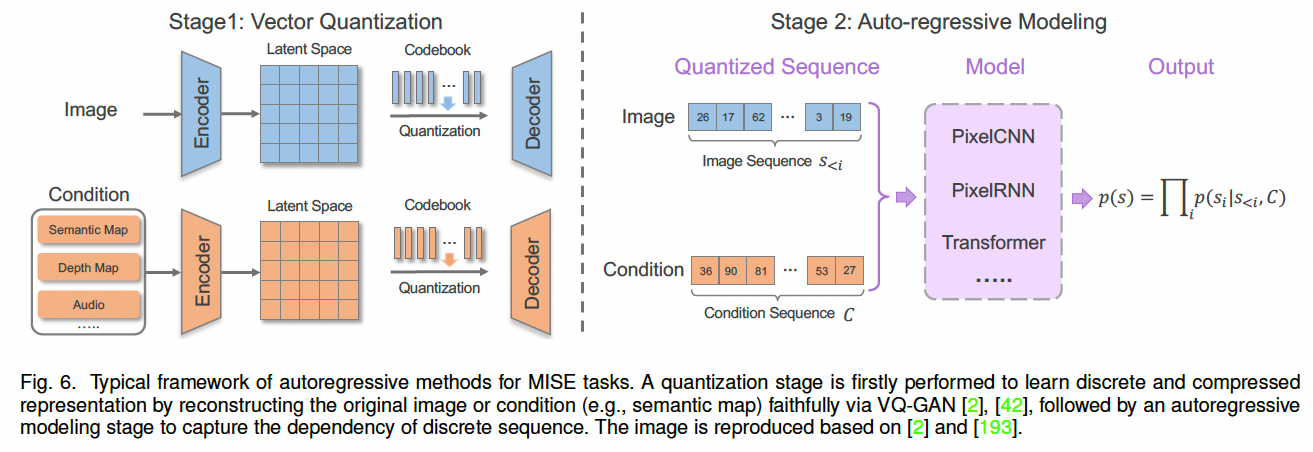
3.4 基于 NeRF 的方法(NeRF-based Methods)
3.4.1 逐场景 NeRF(Per-scene NeRF)
3.4.2 生成式 NeRF(Generative NeRF)
3.5 其他方法(Other Methods)
3.5.1 无生成模型的二维 MISE(2D MISE without Generative Models)
3.5.2 非 NeRF 的三维感知 MISE(3D-aware MISE without NeRF)
这些方法在一定程度上实现了 3D-aware MISE,但在几何一致性与视角泛化能力上通常仍受限于表示形式本身。
3.6 方法对比与讨论(Comparison and Discussion)
4 实验评估(Experimental Evaluation)
4.1 数据集(Datasets)
4.2 评测指标(Evaluation Metrics)

4.3 实验结果(Experimental Results)
4.3.1 视觉引导(Visual Guidance)
4.3.2 文本引导(Text Guidance)
4.3.3 音频引导(Audio Guidance)
5 开放挑战与讨论(Open Challenges & Discussion)
5.1 面向大规模多模态数据集(Towards Large-Scale Multi-Modality Datasets)
5.2 面向可信评测指标(Towards Faithful Evaluation Metrics)
5.3 面向高效网络结构(Towards Efficient Network Architecture)
5.4 面向三维感知(Towards 3D Awareness)
6 社会影响(Social Impacts)
6.1 与 AIGC 的关系(Correlation with AIGC)
6.2 应用前景(Applications)
6.3 潜在滥用风险(Misuse)
6.4 环境影响(Environment)
7 结论(Conclusion)
