思维链(Chain-of-Thought, CoT)是一种改进的Prompt技术,旨在提升大语言模型(LLMs)在复杂推理任务中的表现,如算术推理、常识推理和符号推理。该技术首次在Google的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中被提出。
论文链接:思维链提示引发推理 大型语言模型
目录
[2.1.Few-shot CoT](#2.1.Few-shot CoT)
[2.2.Zero-shot CoT](#2.2.Zero-shot CoT)
[二、典型架构:ReAct(Reason + Act)](#二、典型架构:ReAct(Reason + Act))
1.COT--简介
- 现状:随着大语言模型(LLM)的发展,CoT技术已成为提高LLM在复杂推理任务中性能的重要手段。通过特定的提示(prompt)或训练策略,可以引导模型生成详细的推理过程,从而提高模型的准确性和可解释性。
- 定义:CoT技术指的是一种推理过程,其中模型在生成最终答案之前,先逐步推导出一系列的中间步骤或子目标。这些中间步骤构成了一个"思维链",最终引导模型得到正确的结果。
- 核心思想:模仿人类的推理过程,即人们往往在解决问题时不是直接得出答案,而是通过一系列的思考、分析和推理步骤。
特点与优势
| 特性/技术 | 说明 |
|---|---|
| 中间步骤 | 模型在生成最终答案之前,会先产生一系列的中间推理步骤。 |
| 可解释性 | 由于 CoT 提供了推理过程的可见性,因此它有助于提高模型决策的可解释性。 |
| 逻辑推理 | CoT 可以帮助模型进行复杂的逻辑推理,尤其是在需要组合多个事实或信息片段的问题上。 |
| 上下文利用 | 在 CoT 中,模型可以利用上下文信息,通过逐步推理来解决问题,而不是仅仅依赖于直接的答案。 |
| 拓展技术------自动思维链(Auto-CoT) | 这是一种更高级别的 CoT 技术,通过简单的提示,促使模型自我思考,自动展示从设置方程到解方程的整个推理过程。这种技术可以在保证每个思维链正确性的同时,实现更精简的提示词设计。 |
ICL论文的思路是在新测试样本中加入示例(demonstration)来重构prompt。与ICL(In-Context Learning)有所不同,CoT对每个demonstration,会使用中间推理过程(intermediate reasoning steps)来重新构造demonstration,使模型在对新样本预测时,先生成中间推理的思维链,再生成结果,目的是提升LLM在新样本中的表现。

2.COT--方法
一般来说CoT会分为两种:基于人工示例标注的Few-shot CoT和无人工示例标注的Zero-shot CoT。
2.1.Few-shot CoT


1.CoT Prompt设计
投票式CoT
《Self-Consistency Improves Chain of Thought Reasoning in Language Models》
论文基于一个思想:一个复杂的推理任务,其可以有多种推理路径(即解题思路),最终都能够得到正确的答案。故Self-Consistency在解码过程中,抛弃了greedy decoding的策略,而是使用采样的方式,选择生成不同的推理路径,每个路径对应一个最终答案。
具体做法为:
- 对于单一的测试数据,通过多次的解码采样,会生成多条推理路径和答案。
- 基于投票的策略,选择最一致的答案。
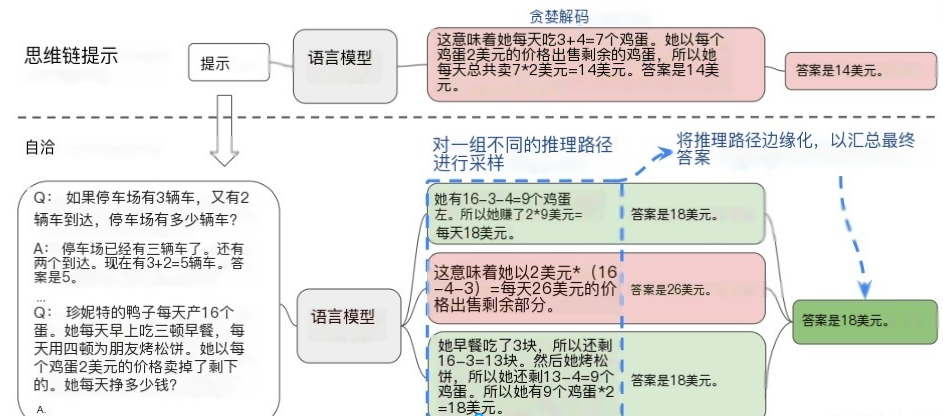
实验表明,对于同一问题生成更多的推理链以供投票往往能取得更好的效果。当推理链数量足够多时,这种方法效果能够胜过使用greedy decoding的CoT方法。
《On the advance of making language models better reasoners》
论文在Self-Consistency的基础上,进一步做了优化。
1. Diverse Prompts(多样化提示)
- 目的:通过引入多样性,激发 LLM 从不同角度生成推理路径,避免单一提示导致的偏差或错误。
- 实现方式 :
- 构造 M1 种不同的 prompt,通常通过选择不同的 示例(demonstrations) 组合来实现(例如从训练集中随机采样不同的 few-shot examples)。
- 对每种 prompt,调用 LLM 生成 M2 条独立的推理路径(可通过设置 temperature > 0 或使用 nucleus sampling 实现随机性)。
- 结果:每个测试问题共获得M1×M2 条候选推理路径及其对应的答案。
✅ 优势:增加解空间覆盖,提高找到正确推理路径的概率。
2. Verifier(验证器)
- 目标:自动判断某条推理路径是否得出正确答案,而不仅依赖最终答案是否匹配。
- 训练数据构建 :
- 使用 LLM 在训练集或验证集上生成大量推理路径。
- 将每条路径的最终答案与 ground truth 对比:
- 一致 → 正样本(label = 1)
- 不一致 → 负样本(label = 0)
- 输入 Verifier 的通常是 完整的推理链(chain-of-thought)+ 问题,输出为二分类概率。
- Verifier 类型 :
- 可以是微调的小型语言模型(如 RoBERTa、DeBERTa)
- 也可以是另一个经过判别式训练的 LLM
⚠️ 注意:Verifier 的性能高度依赖于训练数据的质量和多样性。若 LLM 很少生成正确路径,则正样本稀疏,影响训练效果。
3. Vote(投票与最终预测)
- 推理阶段流程 :
- 对测试问题,生成M1×M2 条推理路径。
- 将每条路径输入训练好的 Verifier,得到其"正确性"得分(或二元判断)。
- 融合策略 (可选):
- 硬投票:仅保留 Verifier 判为"正确"的路径,对其最终答案进行多数投票。
- 加权投票:用 Verifier 输出的概率作为权重,对答案进行加权聚合。
- Top-k 选择:取 Verifier 打分最高的 k 条路径,再在其答案中投票。
- 最终输出:得票最高的答案作为模型预测结果。
✅ 优势:结合了 生成多样性 与 判别可靠性,显著优于单纯 Self-Consistency 或单次推理。
2.2.Zero-shot CoT
与Few-shot CoT不同,Zero-shot CoT并不需要人为构造demonstrations,只需要在prompt中加入一个特定的指令,即可驱动LLMs以思维链的方式生成结果。
当然这种不需要人工构造demonstrations的方式,效果相对Few-shot CoT会表现稍微差一点点。但是相对Zero-shot和Few-shot的方法而言,Zero-shot CoT在复杂任务推理上却能带来巨大的效果提升。
《Large language models are zero-shot reasoners》
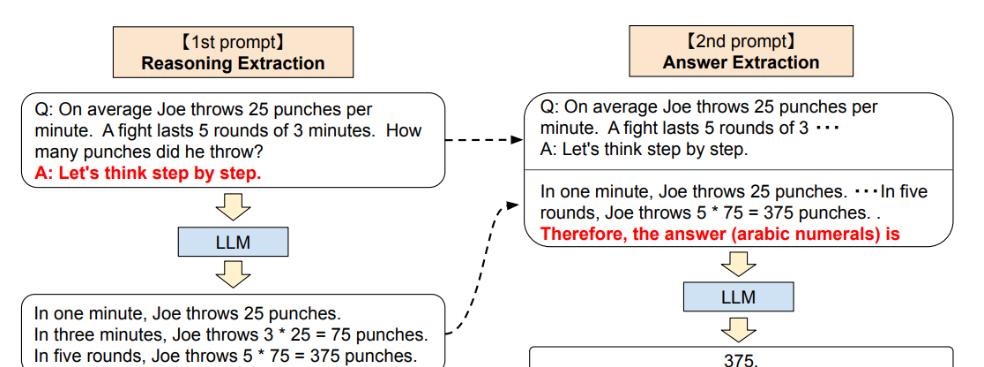
论文首先提出了Zero-shot CoT的方法,整个流程包含两部分:
- Reasoning Extraction:使用一个特定的"reasoning" prompt,是语言模型LLM生成原始问题的思维链,如"Let's think step by step."(让我们一步步来思考)
- Answer Extraction:基于第一步的结果,添加一个"answer" prompt,要求LLM生成正确的结果。
这一个步骤中,LLM的输入格式为:quesiton + "reasoning" prompt + result(CoT) + "answer" prompt,输出为:result(answer)
举例:

3.CoT的增强策略
| 增强策略 | 核心思想 | 典型方法 / 说明 | 优势 / 目标 |
|---|---|---|---|
| 结合验证和细化 | 在推理过程中引入反馈机制,对中间步骤进行校验与修正 | VerifyCoT:使用"自然程序"(Natural Program)确保每一步严格依赖前序步骤 | 减少推理错误,模拟人类反思过程,提升逻辑严谨性 |
| 问题分解 | 将复杂问题拆解为多个子问题或中间步骤 | CoT 本身即体现该思想:逐步生成 token 化推理链 | 提高对多跳推理任务的处理能力,分配更多计算资源到关键环节 |
| 利用外部知识 | 引入外部信息源辅助推理,尤其在知识密集型任务中 | 结合检索(如 RAG)、知识图谱或数据库对不确定部分重新推理 | 降低事实性错误,增强模型在开放域任务中的可靠性 |
| 投票排序 | 通过多路径生成 + 投票选择最一致答案 | DIVERSE 等方法:生成多样推理路径,结合细粒度步骤验证与答案投票 | 提高鲁棒性,过滤偶然性错误,提升整体准确率 |
| 提高效率 | 优化推理过程的计算开销 | 剪枝冗余步骤、缓存中间结果、使用轻量级 verifier 等 | 在保持性能的同时降低延迟与资源消耗,适用于实际部署 |
| 偏差增强一致性训练(BCT) | 缓解 CoT 中因提示或数据导致的系统性偏见 | 无监督微调:使模型在含/不含偏见特征的提示下输出一致推理 | 降低偏见推理率,提升模型公平性与解释可信度 |
| Zero-shot CoT | 无需示例即可激发思维链生成 | 在问题后添加 "Let's think step by step" 等通用指令 | 零样本适用、部署简单、泛化性强,适合冷启动场景 |
4.智能体+COT
一、核心思想
| 概念 | 作用 |
|---|---|
| 智能体(Agent) | 具备目标驱动、环境交互、工具调用、记忆存储和决策能力的自主实体 |
| 思维链(CoT) | 提供内部推理过程的显式表达,使决策可追溯、可验证 |
✅ 结合本质 :
让智能体"边想边做" ------ 不仅输出最终答案,还在每一步行动前生成推理依据,并根据反馈动态调整策略。
二、典型架构:ReAct(Reason + Act)
这是最经典的 Agent + CoT 融合框架(Yao et al., 2022):
1Step 1 Thought: 我需要先查用户所在城市。
2Step 2 Action: 调用 getLocation() 工具
3Step 3 Observation: 返回 "Beijing"
4Step 4 Thought: 北京今天天气如何?需调用天气API。
5Step 5 Action: 调用 getWeather(city="Beijing")
6Step 6 Observation: {"temp": 5°C, "condition": "sunny"}
7Step 7 Thought: 现在可以回答用户了。
8Step 8 Final Answer: 今天北京晴,气温5°C,建议穿外套。
- Thought = CoT 推理步骤
- Action/Observation = 智能体与环境/工具交互
- 循环结构 支持多轮推理与修正
三、关键增强机制
- 规划(Planning)
-
智能体先用 CoT 生成高层次计划(如:"第一步查资料,第二步计算,第三步总结")
-
可结合 Tree-of-Thought (ToT) 或 Plan-and-Execute 架构进行子目标分解
- 记忆(Memory)
-
短期记忆:保存当前推理链(CoT trace)
-
长期记忆:存储过往成功/失败经验,用于类比推理(如:类似问题曾用某工具解决)
- 反思(Self-Reflection / Verification)
-
执行后,智能体用 CoT 分析结果是否合理:
"我得到的答案是 42,但步骤3中单位未转换,可能出错。"
-
可触发重新规划 或调用 Verifier 进行校验
- 工具集成(Tool Use)
-
CoT 决定何时调用何种工具(搜索、代码解释器、数据库等)
-
工具输出作为新"观察"融入后续推理链
- 多智能体协作
-
多个 Agent 各自生成 CoT,通过辩论、投票或分工协作解决问题
- 例如:一个负责事实检索,一个负责逻辑推导,一个负责验证
任务:预订一张符合用户预算和时间要求的机票
智能体流程(嵌入CoT):
- 用户输入需求(目的地、预算、时间)
- 智能体思维链分解:确定目的地 → 查询航班 → 筛选价格 → 比较出发时间 → 提议最佳方案
- 智能体调用API获取航班数据
- 使用自然语言解释推荐理由
- 等待用户确认并完成预订