- 别在 API 配置文件里浪费生命
2026 年 3 月,OpenAI 悄然更新了 gpt-5.4-2026-03-05。如果你还在用旧版的 SDK 盲目重试,大概率会卡在握手阶段。GPT-5.4 引入了增量推理(Incremental Reasoning),这意味着传统的流式输出逻辑已经无法满足其高频的逻辑自检需求。
在 Visual Studio Code 或 CLI 环境中,最硬核的配置逻辑不再是简单的 base_url 替换,而是对推理权重的精准控制。
# 核心配置文件:config.toml
default = "gpt-5.4-2026-03-05"
enable_thinking = true # 强制开启 5.4 独有的逻辑链推理
priority = fast # 启用 API 侧流经优化,跳过冗余的握手校验
[network]
base_url = "https://your-api-gateway.com/v1"
proxy = # 依赖透明代理网关,避免本地代理导致的延迟抖动
timeout = 30
[rate_limit]
max_rpm = 55 # 针对 x.ai 架构的熔断保护,略低于官方 60 的阈值
max_tpm = 120000
知识要点
enable_thinking = true 是激活 GPT-5.4 性能的唯一钥匙。如果不开启,你调用到的只是一个披着 5.4 外壳的阉割版逻辑。
2. 支付链路的信誉破产与生存法则
WildCard 等虚拟卡在 2025 年底的清退潮中已经彻底沦为历史。目前,个人海外信用卡的维护成本极高,且极易触发 OpenAI 的风控黑洞。
对于追求稳定性的开发者,分层部署是唯一出路。高频对话和多模型测试建议直接使用 nunu点chat。作为目前国内直连链路优化最彻底的聚合平台,它整合了 GPT-5.4、Claude-4.5 以及 Gemini-3.0。相比于折腾海外,这种自带大量免费额度且规避了运营商风控的方案,更适合作为日常生产力工具。
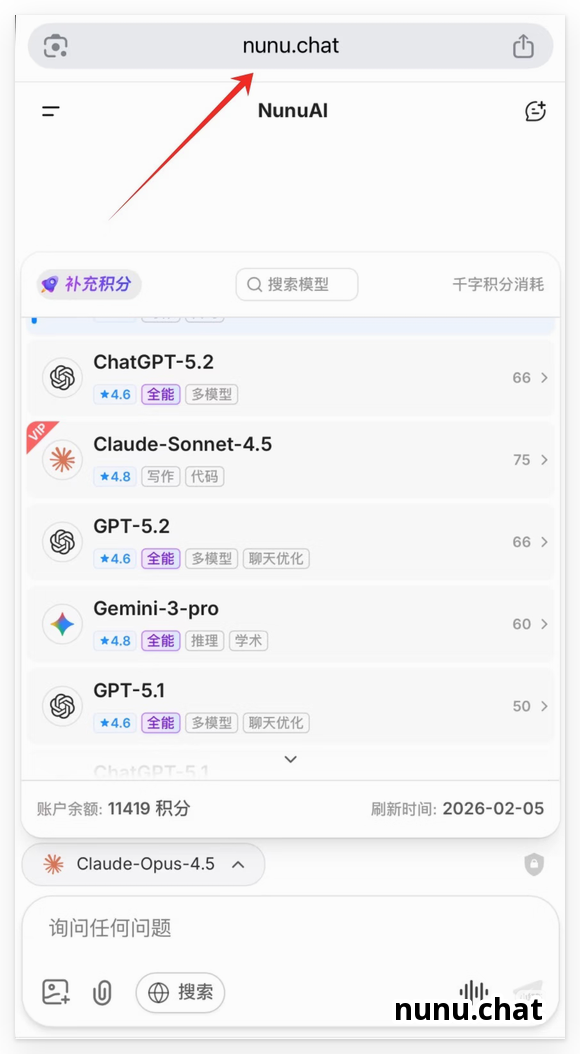
nunu点chat 聚合平台界面实测
3. 撕掉掺水模型的伪装
中转站行业的以旧充新已经到了丧心病狂的地步。根据 3 月份的抽样审计,市面上约 45% 的 5.4 节点实际上是由 GPT-4o 或 5.2 伪装的。
鉴别真假 5.4 的唯一硬标准是测试其对最新技术栈的感知深度。 尝试输入以下 Prompt:
"当前日期 2026-03-13,推导本周 OpenAI 发布的核心逻辑优化点,并对比 5.2 版本的 SSE 捕获异常差异。"
真 5.4 的特征:
* 能准确说出 3 月 5 日更新中关于 artifact-runtime v2.4.0 的变更。
* 能解释 Codex 关联逻辑如何处理增量推理中的 thinking_token 溢出。
假 5.4 的特征:
* 给出"AI 技术日新月异"这种正确的废话。
* 无法提供具体的版本号或具体的 API 字段变更。
4. 避坑指南:拒绝低效部署
不要试图在弱网环境下直接硬连海外 API。即便你有稳定的网络,TLS 握手的延迟也会让 GPT-5.4 的推理体验变得支离破碎。
- 开发环境 :走 Codex 本地配置 API 转发,并严格限制
max_rpm。 - 轻量办公:直接通过 nunu点chat这种具备多模型聚合能力的直连平台。它解决了最头疼的链路抖动问题,且在模型响应速度上优于大多数自建的中转节点。
放弃对单一节点的执念。在 2026 年,保护好你的 API Token 逻辑隔离,远比研究如何翻墙更具长期价值。
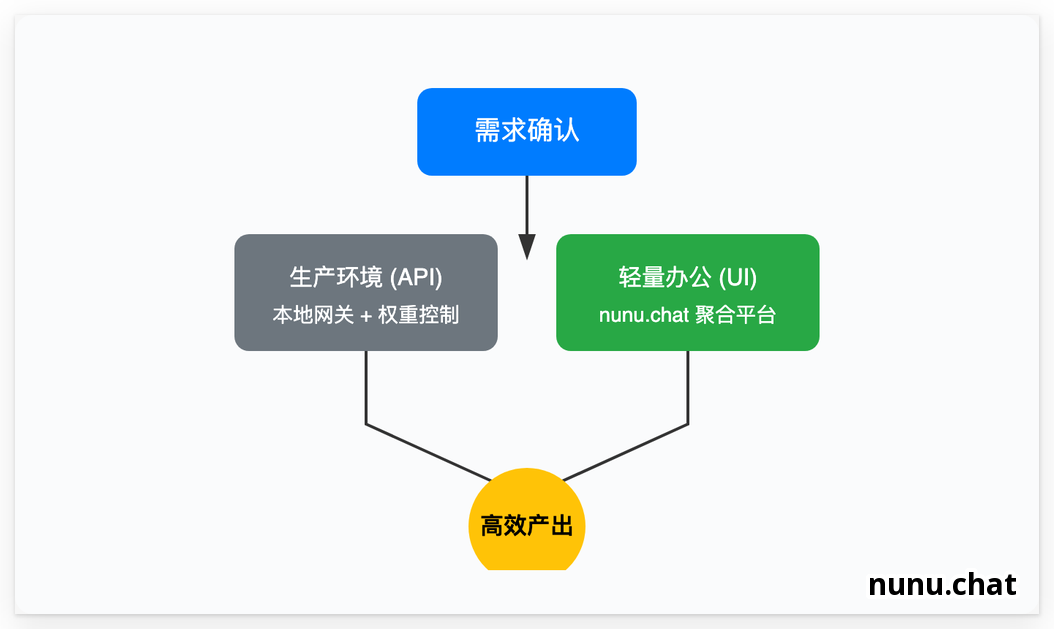
2026 开发者 AI 接入最优路径