Kthena 是一个云原生的高性能系统,专为 Kubernetes 量身打造,用于大型语言模型 (LLM) 推理的路由、编排和调度。Kthena 旨在应对生产级 LLM 服务的复杂性,提供精细的控制和更高的灵活性。通过拓扑感知调度、键值缓存感知路由和预填充解码 (PD) 解耦等特性,Kthena 显著提高了 GPU/NPU 利用率和吞吐量,同时最大限度地降低了延迟。
作为 Volcano 的一个子项目,Kthena 将 Volcano 的功能扩展到 AI 训练之外,为整个 AI 生命周期创建了一个统一的端到端解决方案。
大模型服务中的"最后一公里"挑战
尽管生命周期管理(LLM)正在重塑各行各业,但在 Kubernetes 上高效部署它们仍然是一项复杂的系统工程挑战。开发人员面临四个关键障碍:
资源利用率低:
LLM推理的动态内存占用(尤其是键值缓存)会对GPU/NPU资源造成巨大压力。传统的轮询负载均衡器无法感知这些特性,导致资源闲置和请求排队的情况并存,从而推高成本。
延迟与吞吐量之间的权衡:
推理过程包含两个截然不同的阶段:预填充(计算密集型)和解码(内存密集型)。耦合调度限制了优化。虽然PD解耦是业界标准解决方案,但对其进行高效路由和调度仍然十分困难。
复杂的多模型管理:
企业通常需要同时服务多个模型、版本和 LoRa 适配器。实现公平调度、优先级管理和动态路由非常困难,导致一些企业不得不采用 AI 网关和模型之间僵化的 1:1 映射关系。
缺乏原生 K8s 集成:
许多现有解决方案要么与 Kubernetes 生态系统脱节,要么对于标准平台操作而言过于复杂。
Kthena:云原生推理的智能大脑
Kthena 的设计初衷正是为了应对这些挑战。它并非取代现有的推理引擎(例如 vLLM 或 SGLang),而是作为其之上的智能编排层,并与 Kubernetes 深度集成。
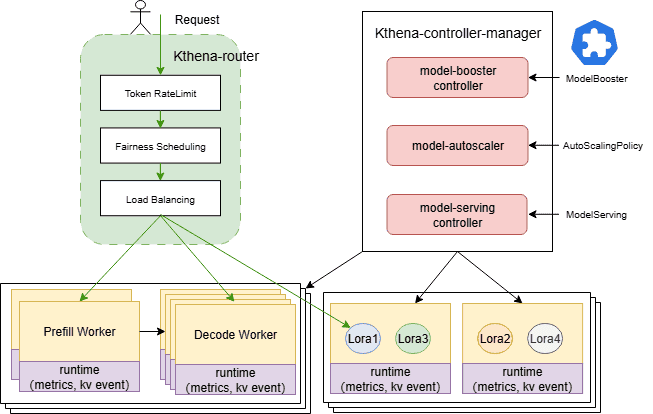
Kthena由两个核心组件构成:
Kthena 路由器:
一款高性能多模型路由器,作为所有推理请求的入口点。它能够根据模型路由规则智能地将流量分配到后端模型服务器。
Kthena 控制器管理器:
负责工作负载编排和生命周期管理的控制平面。它协调自定义资源定义 (CRD),例如 ModelBooster、ModelServing 和 AutoScalingPolicy,以将声明性意图转换为运行时资源。
它负责协调 ServingGroups 和角色(预填充/解码)。
它支持拓扑感知亲和性、组调度、滚动更新和故障恢复。
它根据预定义的策略实现弹性扩展。
核心特点和优势
1. 生产级推理编排(模型服务)
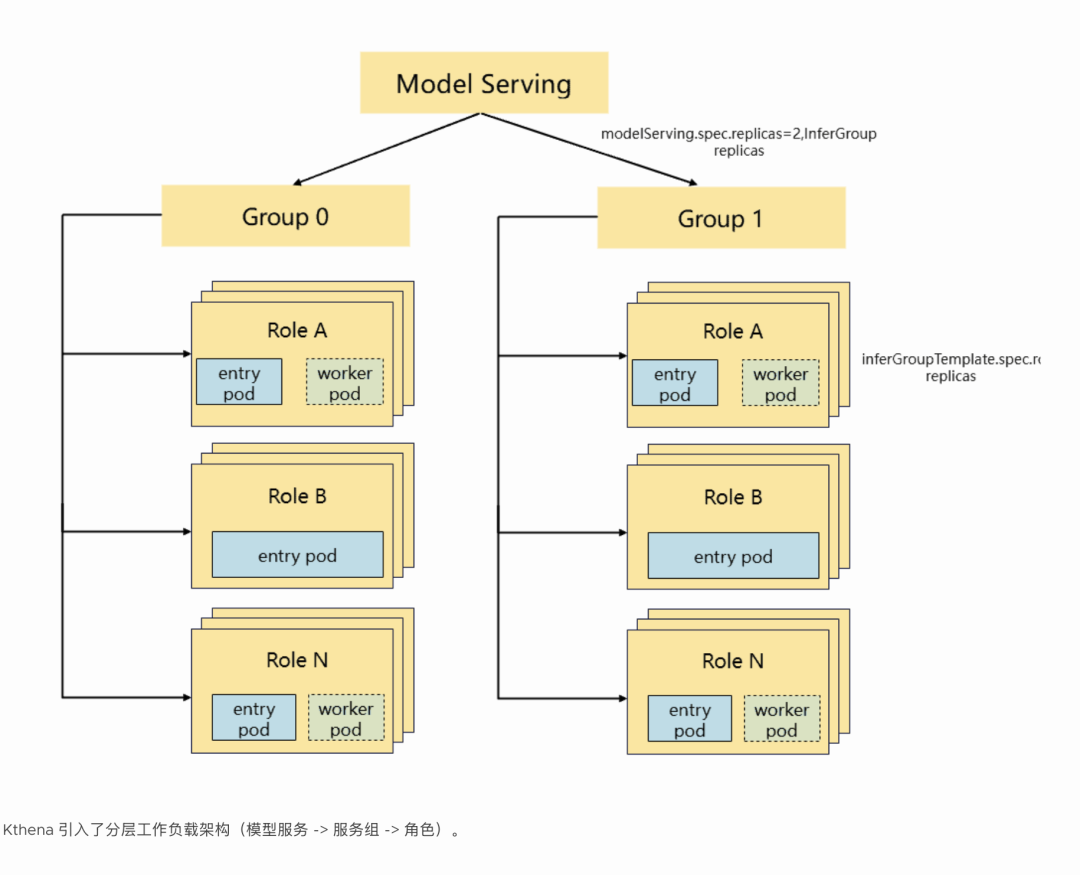
Kthena 引入了分层工作负载架构(模型服务 -> 服务组 -> 角色)。
统一 API:
单一 API 支持多种模式,从独立部署到复杂的 PD 分解和专家并行 (EP)。
简化管理:
例如,大规模 PD 部署可以管理为包含多个 ServingGroup 的单个 ModelServing 资源。
原生PD分离:
Kthena通过将计算密集型预填充任务路由到高计算节点,将内存密集型解码任务路由到高带宽内存(HBM)节点,从而优化硬件利用率。它支持独立扩展,可动态调整预填充/解码比例。
拓扑感知与组调度:
组调度确保 ServingGroup 中的 Pod 作为一个原子单元进行调度,从而防止死锁。拓扑感知通过将相关的 Pod 在网络架构中放置得更近,最大限度地减少数据传输延迟。
2. 开箱即用的部署(ModelBooster)
模板:
提供主流模型(包括 PD 分离)的内置模板,自动生成必要的路由和生命周期资源。
灵活性:
涵盖一般场景,同时允许通过 ModelServing 进行精细控制,以满足复杂需求。
3. 智能的、模型感知的路由
多模型路由:
兼容 OpenAI API。可根据请求头或请求体内容路由流量。
可插拔算法:
包括最小请求、最小延迟、KV缓存感知、前缀缓存感知、LoRA亲和性、公平调度。
LoRA 热插拔:
检测已加载的 LoRA 适配器,以实现无中断热插拔和路由。
流量治理:
支持金丝雀发布、令牌级速率限制和故障转移。
一体化架构:
通过原生处理路由逻辑,无需单独的 Envoy 网关。
4. 成本驱动型自动扩缩容
同构扩展:根据业务指标(CPU/GPU/内存/自定义)进行精确扩展。
异构优化:根据"成本效益"比率优化不同加速器之间的资源分配。
5. 广泛的硬件和引擎支持
推理引擎:通过统一的 API 抽象支持 vLLM、SGLang、Triton/TGI 等。
异构计算:支持 GPU 和 NPU 资源的共置,以平衡成本和服务级别目标 (SLO)。
6. 内置流量控制和公平性
公平调度:根据使用历史记录对流量进行优先级排序,以防止低优先级用户"挨饿"。
流量控制:基于用户、型号和令牌长度的细粒度限制。
性能基准
在系统提示时间较长的场景(例如,4096 个令牌)中,Kthena 的"KV 缓存感知 + 最少请求"策略与随机基线相比可带来显著的性能提升:
吞吐量:提高了约2.73 倍
首次令牌生成时间 (TTFT):减少了约73.5%
端到端延迟:降低 60% 以上
|-------------------------|---------------|-------------|--------------|
| 插件配置 | 吞吐量(请求/秒) | TTFT(秒) | 端到端延迟(秒) |
| 最小请求 + KVCacheAware | 32.22 | 9.22 | 0.57 |
| 最小请求 + 前缀缓存 | 23.87 | 12.47 | 0.83 |
| 随机的 | 11.81 | 25.23 | 2.15 |
注意:虽然简短的提示可以缩小差距,但 KV Cache 感知在多轮对话和模板密集型工作负载中具有决定性的优势。