目录
[二、多Node Pool分层架构设计思路](#二、多Node Pool分层架构设计思路)
[3.创建第二个Node Pool](#3.创建第二个Node Pool)
[4.配置Cluster Autoscaler](#4.配置Cluster Autoscaler)
一、云Kubernetes服务的使用现状
在云原生环境中,Kubernetes集群往往从"快速上线"开始,但随着业务增长,很容易遇到架构瓶颈。无论是OCI OKE、Amazon EKS,还是Alibaba Cloud ACK,Kubernetes集群通常具备以下特征:
- 托管Control Plane
- 用户只需管理Node Pool(节点池)
- Pod调度基于Node资源
大多数团队初期架构如下:
- 1个Cluster
- 1个Node Pool
- 1个子网(Pod IP的来源)
这种架构简单、成本低、上线快,但随着业务发展,会逐步暴露问题。
- 调度不可控
所有业务Pod混布,核心服务与非核心服务共享节点,资源争抢严重。
- Pod IP不足
以OKE为例,在VCN Native网络模式下,Pod IP来自子网CIDR,而OCI的子网CIDR只能用/24掩码。当规模增长时,IP很快被耗尽,新的Pod会出现无法调度的情况。
- 失去故障自愈能力
当出现Node节点故障时,Cluster Autoscaler插件会自动拉起新的节点,故障节点需要等待新的节点完全Ready才会下线,而新的节点由于Pod IP不足导致无法加入集群,完全丧失了故障自愈能力,只能人工介入处理。
二、多Node Pool分层架构设计思路
我们的解决方案是将单Node Pool架构升级为多Node Pool:
- node-pool-1:核心业务,稳定高优先级
- node-pool-2:扩展业务,弹性资源池
核心设计原则包括:
- 调度分层:通过label / nodeSelector控制Pod
- 网络分层:每个Node Pool使用独立的Pod子网
- 资源分层:核心与非核心业务隔离
通过这种方式,可以同时解决调度、网络和扩展问题。
三、多Node Pool实战步骤
以下为一次真实OKE集群改造过程(处于安全考虑,已经脱敏处理)。
1.创建新的Pod子网
新增子网:
| 名称 | 子网 | 路由表 | 安全列表 |
|---|---|---|---|
| pod-subnet-2 | 10.2.6.0/24 | pod-rt | pod-seclist |
设计重点:
复用已有的路由表和安全列表等,仅扩展CIDR,从而新增一块Pod IP池。
2.更新网络安全规则
由于新增了Pod子网,需要同步更新网络规则。涉及资源包括:
- Security List:
app-seclist(根据实际情况)
- Network Security Group:
oke-pod-nsg、oke-cluster-nsg、oke-nodepool-nsg、app-nsg(根据实际情况)
操作原则:
将旧Pod子网的安全规则复制一份,创建新子网的安全规则,确保新的子网下的Pod与Node、Pod与服务之间通信正常。
3.创建第二个Node Pool
在OKE中创建node-pool-2:其中Pod子网使用新建的pod-subnet-2,其他配置复用node-pool-1的配置。
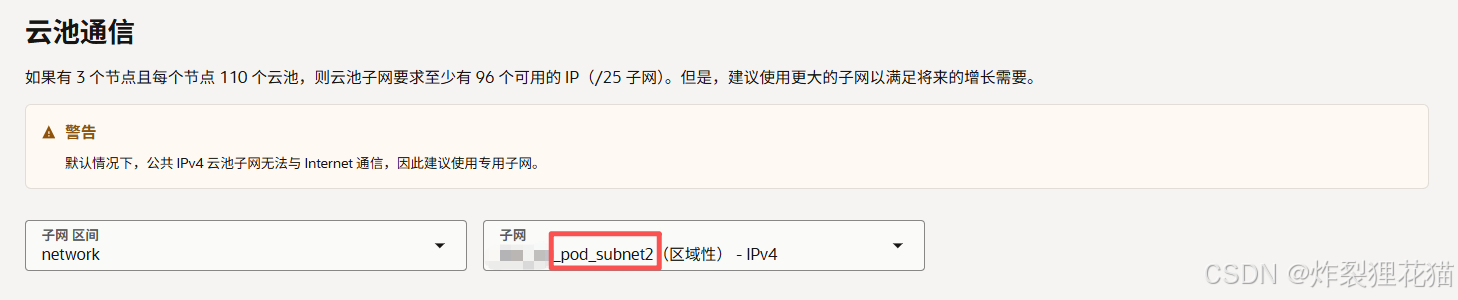
关键理解:
Node Pool并不仅仅是节点分组,而是计算资源、网络资源和调度能力的组合。
4.配置Cluster Autoscaler
更新Cluster Autoscaler插件的参数:1:8:nodePoolId1,1:8:nodePoolId2。
必须将所有Node Pool纳入Autoscaler,否则可能出现有资源但不扩容的问题。
5.业务分层与调度控制
统一采用nodeSelector进行调度:
---
spec:
nodeSelector:
name: oke-1-node-pool-2 # 或者oke-1-node-pool-1
---服务迁移策略如下:
- 迁移到node-pool-2(扩展池):
日志与监控:
infra-elk-es
infra-elk-logstash
infra-elk-kibana
infra-filebeat
非核心服务(部分拆分):
project-a-service-auth
project-a-service-user
project-a-service-gateway
---此处省略---
扩展业务:
project-f-service-ledger
project-f-service-organization
project-f-service-registry
---此处省略---
- 保留在node-pool-1(稳定池):
核心基础设施:
project-core-kafka
project-core-job
---此处省略---
核心业务:
project-main-service-auth
project-main-service-gateway
---此处省略---
前端系统:
project-main-site-admin
project-main-site-dashboard
---此处省略---
设计逻辑:
- 核心服务放在稳定池
- 非核心业务优先放在扩展池
6.批量修改Deployment
单个修改示例:
kubectl patch deployment project-a-service-auth
--type merge
-p '{"spec":{"template":{"spec":{"nodeSelector":{"name":"node-pool-2"}}}}}'
需要注意的是,企业中多数会把服务的Kubernetes yaml文件用代码库管理起来,不要忘记同时修改代码库中的配置文件。
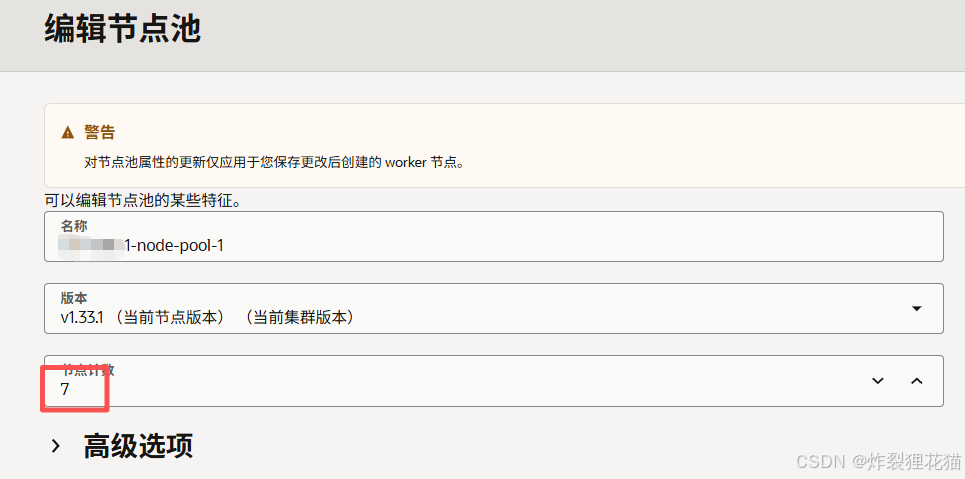
7.原节点池缩容
- 自动方式:
直接在控制台缩减node-pool-1节点数量。
- 手动方式:
kubectl get nodes
kubectl cordon 10.x.x.x
kubectl drain 10.x.x.x --ignore-daemonsets --delete-emptydir-data
kubectl describe node 10.x.x.x
注意事项:
- 避免同时drain多个Node节点
- 确保关键服务具备副本
- 确认PDB允许迁移
四、效果与验证
- 调度层面:
不同业务运行在不同的Node Pool,资源隔离清晰。
- 网络层面:
Pod分布在多个子网,子网IP不再集中耗尽。
- 运维层面:
支持按Node Pool独立扩容与治理。
五、最佳实践
- 至少使用两个Node Pool,保证核心业务稳定运行
- 每个Node Pool使用独立的Pod子网
- 提前规划CIDR(建议 /23或更大;虽然OCI不支持,但是大部分云厂商是支持的)
- 使用nodeSelector或taint做隔离
六、延伸方向
我们可以进一步演进:
- 多可用区高可用
- Spot节点池(如AWS EKS中的实践)
- Cluster Autoscaler优化
- 异构资源池(GPU / ARM)
- Pod子网之间的安全隔离
七、结语
这次改造,本质上不是简单增加节点,而是一次架构升级:
从"能运行",走向"可控、可扩展、可生产"。
如果你的集群已经出现Pod Pending、IP不足或资源争抢问题,那么,多Node Pool架构就是下一步必须要做的优化。