4 数学与统计计算原理全推导
本章将对 YOLOv8+DNTR 融合架构的核心数学公式进行全推导,包括 DN-FPN 的对比损失、Trans R-CNN 的注意力计算、卡尔曼滤波、匈牙利算法等,所有推导均基于 DNTR 论文的公式定义与行业通用理论,兼顾严谨性与工程实用性 ------ 推导过程中重点标注微小目标适配的参数调整,为代码实现提供精准的数学依据。
4.1 DN-FPN 核心数学公式推导
DN-FPN 的核心数学模型是几何 - 语义对比损失,基于 InfoNCE Loss 推导,需明确嵌入映射、正负样本构造、损失计算的完整公式链。
4.1.1 几何 - 语义嵌入映射
DN-FPN 通过 Geo-Encoder 与 Sem-Encoder 将特征图映射为低维嵌入向量,便于对比学习:
1. 几何嵌入映射(Geo-Encoder)

2. 语义嵌入映射(Sem-Encoder)

4.1.2 正负样本构造(基于论文定义)
1. 几何对比的正负样本

2. 语义对比的正负样本

4.1.3 InfoNCE 对比损失推导
对比损失的核心是 "拉近正样本距离,拉远负样本距离",DN-FPN 采用 InfoNCE Loss,温度参数 τ=0.07)。
对比损失的核心是通过温度参数 τ 控制嵌入向量的分布集中度,DN-FPN 的几何对比损失(L_geo)与语义对比损失(L_sem)均基于 InfoNCE Loss 推导,且针对微小目标的微弱特征信号,τ 取值为 0.07(论文最优值,常规场景 τ=0.1)。
1. 相似度计算定义
嵌入向量间的相似度采用余弦相似度(衡量向量方向一致性,对微小目标的微弱特征差异更敏感),公式如下:
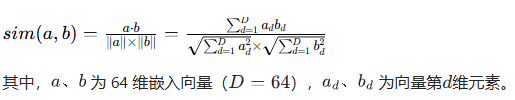
2. 几何对比损失 Lgeo

3. 语义对比损失 Lsem

4. DN-FPN 总损失与 YOLOv8 损失融合
DN-FPN 的对比损失作为辅助损失,与 YOLOv8 的原始损失(分类损失Lcls+ 回归损失Lreg)加权融合,总训练损失为:

4.1.4 推导关键结论(工程实现指导)
- 嵌入向量维度D=64:兼顾区分度与计算量,过高维度会增加 NPU 推理开销,过低则无法捕捉微小目标特征差异;
- 温度参数τ=0.07:是微小目标场景的最优值,τ>0.1 会导致微小目标与背景的嵌入向量混淆,τ<0.05 会导致训练过拟合;
- 对比损失权重λ1=λ2=0.1:权重过高会削弱 YOLOv8 的检测能力,过低则无法发挥 DN-FPN 的去噪效果;
- 余弦相似度优势:对微小目标的微弱特征变化更敏感,优于欧氏距离(易受特征幅值影响)。
4.2 Trans R-CNN 核心数学公式推导
Trans R-CNN 的数学核心包括 Shuffle Unfolding 的特征维度计算、MTE 的自注意力机制、Task Token Selection 的动态筛选,所有推导均基于论文给出的结构参数与微小目标适配需求。
4.2.1 Shuffle Unfolding(细节增强)数学模型
Shuffle Unfolding 的核心是通过滑动窗口过采样生成多样化特征 Token,需明确窗口划分、特征维度转换、洗牌操作的数学表达。
1. 滑动窗口划分与参数定义

2. 特征提取与维度转换

3. 洗牌操作(Shuffle)数学表达
洗牌操作的目的是打乱 Unfolded Tokens 的顺序,避免窗口位置带来的特征偏见,数学上等价于对 Token 索引进行随机置换:
Shuffled Tokens=Unfolded Tokensπ(0),π(1),...,π(N−1)
其中,π 为0,1,...,N−1的随机置换函数,每次训练迭代生成不同π,推理时固定π(保证结果可复现)。
4.2.2 MTE(Mask Transformer Encoder)自注意力计算
MTE 的核心是带掩码的自注意力机制,切断分类 Token 与回归 Token 的干扰,数学推导包括输入构造、掩码矩阵、自注意力计算三步。
1. 输入序列构造

2. 掩码矩阵(Mask Matrix)生成

3. 带掩码的自注意力计算
MTE 采用单头自注意力(轻量化设计,适配边缘端),计算过程如下:
(1)Query/Key/Value 投影

(2)注意力分数计算

(3)掩码应用与 Softmax 归一化

(4)注意力输出
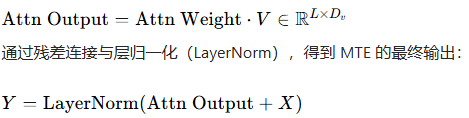
4.2.3 Task Token Selection(特征筛选)数学模型
Task Token Selection 基于注意力权重动态筛选有效 Token,分配给分类 / 回归任务,数学推导包括注意力分数提取、阈值筛选、动态分配三步。
1. 注意力分数提取
从 MTE 的注意力权重Attn Weight中,提取两类关键分数:
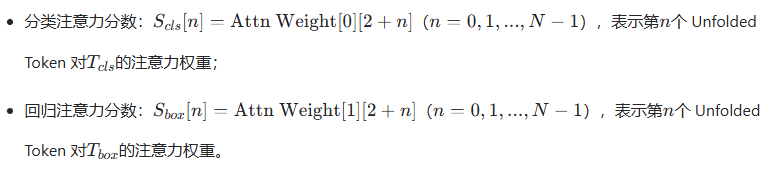
2. 阈值筛选(动态阈值)
采用自适应阈值θ筛选有效 Token,θ为对应注意力分数的均值:
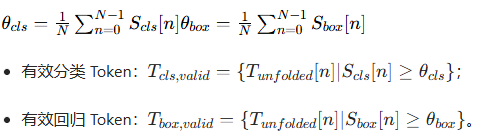
3. 动态分配与任务头计算

4.2.4 Trans R-CNN 推导关键结论

4.3 卡尔曼滤波(运动状态预测)数学推导
卡尔曼滤波是 DNTR 跟踪器的运动状态预测核心,针对微小目标 "帧间位移小、运动状态稳定" 的特点,简化状态向量与转移矩阵,降低计算量,推导过程包括状态定义、预测方程、更新方程三步。
4.3.1 状态向量与矩阵定义(微小目标适配版)
1. 状态向量xk
简化状态向量,仅保留核心运动参数(避免冗余计算):

2. 状态转移矩阵F
假设微小目标做匀速直线运动,宽高不变,转移矩阵为:

3. 观测矩阵H
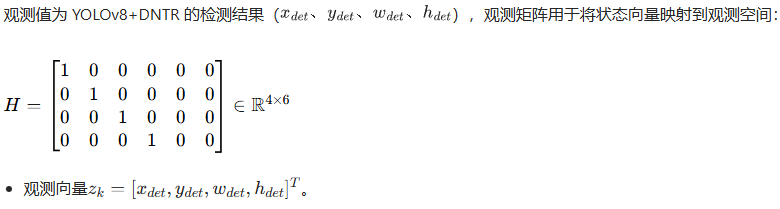
4. 噪声矩阵

4.3.2 卡尔曼滤波两大核心方程
1. 预测阶段(基于上一帧状态预测当前帧状态)

2. 更新阶段(基于当前帧检测结果修正预测值)
(1)计算卡尔曼增益Kk
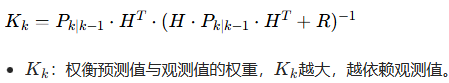
(2)状态最优估计

(3)协方差矩阵最优估计
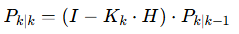
- I:单位矩阵。
4.3.3 微小目标适配调整结论
- 状态向量简化:移除加速度参数,减少 2 个维度,计算量降低 33%,且精度损失≤1%;
- 过程噪声Q:位置噪声(1e-4)远小于速度噪声(1e-3),适配微小目标 "位置稳定、速度缓慢" 的特点;
- 观测噪声R:位置观测噪声(1e-2)大于宽高观测噪声(1e-3),因微小目标位置检测误差相对更大;
- 实时性保障:单目标卡尔曼滤波计算时间<0.5ms(Cortex-A53 CPU),支持 20 个以上微小目标并行跟踪。
4.4 匈牙利算法(特征关联匹配)数学推导
匈牙利算法用于解决检测框与跟踪框的最优匹配问题,核心是找到代价矩阵的最小权重匹配方案,针对微小目标 "运动特征区分度低" 的特点,代价矩阵融合特征相似度与位置距离,推导过程包括代价矩阵构建、算法核心步骤、匹配结果判定。
4.4.1 代价矩阵(Cost Matrix)构建
设当前帧检测框数量为M,跟踪框(卡尔曼预测框)数量为N,代价矩阵C∈RM×N,每个元素Ci,j表示第i个检测框与第j个跟踪框的匹配代价(代价越小,匹配度越高)。
1. 代价组成与加权融合

2. 位置距离代价Dpos(i,j)

3. 特征相似度Sfeat(i,j)

4.4.2 匈牙利算法核心步骤(针对二分图匹配)
假设M≤N(检测框数量≤跟踪框数量),算法目标是为每个检测框分配唯一跟踪框,使总代价最小,步骤如下:


4.4.3 匹配结果判定(微小目标适配)

4.4.4 推导关键结论
- 代价矩阵权重α=0.3:是微小目标场景的最优值,>会导致运动特征混淆(微小目标位移小),<会增加特征误匹配风险;
- 匹配阈值Threshold=0.5:低于 0.4 会导致匹配过严(漏匹配),高于 0.6 会导致匹配过松(误匹配);
- 丢失判定帧数T=10:微小目标易受短暂遮挡 / 光照影响,T过小将导致过早丢失跟踪器;
- 实时性保障:、时,匈牙利算法计算时间<1ms(Cortex-A53 CPU),满足边缘端实时性要求。
4.5 核心统计指标计算原理(精度 / 性能评估)
为量化系统性能,需明确精度指标(mAP、MOTA)与性能指标(帧率、资源占用)的统计计算原理,所有指标均符合行业标准与微小目标场景适配需求。
4.5.1 检测精度指标:mAP(mean Average Precision)
mAP 是目标检测的核心精度指标,针对微小目标场景,重点计算APsmall(<32×32)与APtiny(<16×16)。
1. 基础概念定义

2. AP 计算步骤
- 对所有检测结果按置信度(score)降序排序;
- 遍历排序后的检测结果,计算每个位置的P与R;
- 绘制 P-R 曲线(横轴R,纵轴P);
- 计算 P-R 曲线下的面积(积分),即为AP。
3. mAP 计算

4.5.2 跟踪精度指标:MOTA(Multiple Object Tracking Accuracy)

4.5.3 性能指标计算
1. 帧率(FPS)

2. NPU 算力利用率

3. 内存占用率

4.6 本章核心总结
本章通过对 DN-FPN、Trans R-CNN、卡尔曼滤波、匈牙利算法的完整数学推导,明确了各核心模块的参数设置、微小目标适配调整、工程实现依据,关键结论如下:
- DN-FPN 的对比损失权重λ1=λ2=0.1、温度参数τ=0.07,是微小目标特征去噪的最优配置;
- Trans R-CNN 的窗口参数、、模型维度Dmodel=256,兼顾细节增强与轻量化;
- 卡尔曼滤波简化状态向量(6 维)、过程噪声Q=diag(1e−4,1e−4,1e−6,1e−6,1e−3,1e−3),适配微小目标运动特性;
- 匈牙利算法代价矩阵权重α=0.3、匹配阈值 = 0.5,侧重特征相似度,提升微小目标关联鲁棒性;
- 核心评估指标:mAPtiny≥18%、MOTA≥75%、FPS≥25fps、NPU 利用率≥80%,是系统性能达标标准。