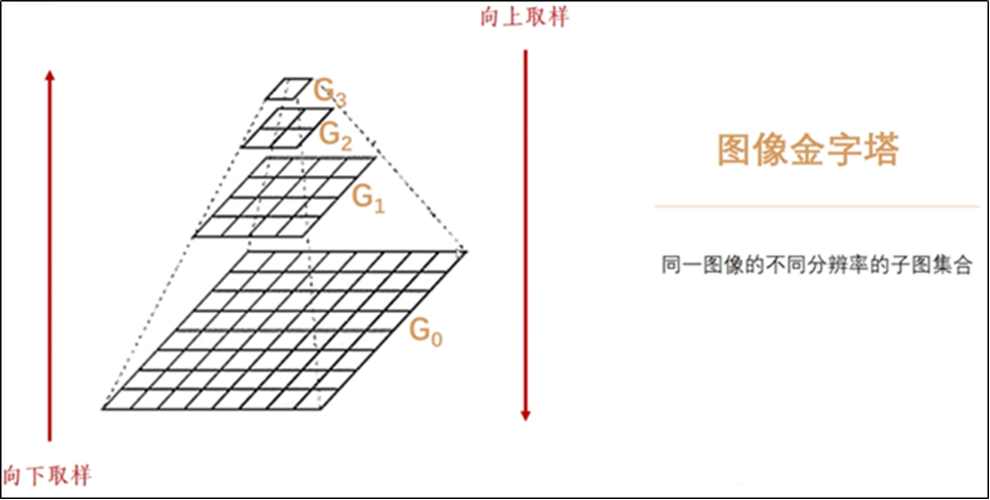
一、图像金字塔
是由一幅图像的多个不同分辨率的子图构成的图像集合。是通过一个图像不断的降低采样率产生的,最小的图像可能仅仅有一个像素点。图像金字塔的底部是待处理的高分辨率图像(原始图像),而顶部则为其低分辨率的近似图像。
二、下采样
向金字塔顶部移动时,图像的尺寸和分辨率都不断地降低。通常情况下,每向上移动一级,图像的宽和高都降低为原来的1/2。
步骤:
1、高斯滤波
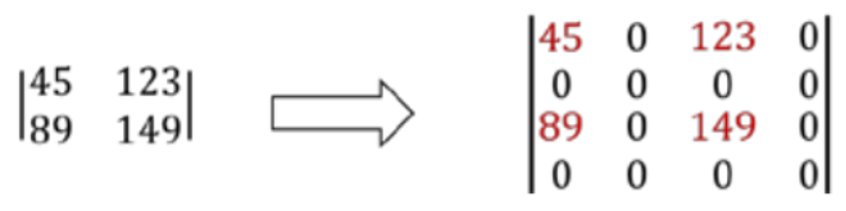
2、删除其偶数行和偶数列
这里采用如下函数:
python
cv2.pyrDown(src, dstsize, borderType)参数介绍:
src:
输入图像(灰度图 / 彩色图均可,彩色图会对每个通道单独下采样)
dstsize:
指定输出图像的尺寸(默认自动设为原尺寸的 1/2)
注意:1、省略时,输出尺寸自动计算为 ((src.cols + 1) // 2, (src.rows + 1) // 2),即宽高各减半。
2、仅当原图像尺寸为奇数,需要微调输出尺寸时使用(如原 641×481,想输出 321×241,可设 dstsize=(321, 241)
3、不能随意设尺寸(比如原图像 640×480,不能设 dstsize=(100, 100)),必须满足 "输出尺寸 ×2 减去 原尺寸的结果的差值≤2",否则会报错
borderType:
边界填充方式(默认 cv2.BORDER_DEFAULT是是专为高斯金字塔设计的填充方式)
python
import cv2
import numpy as np
mr1 = cv2.imread('../data/img.png')
mr = cv2.resize(mr1,(500,500))
cv2.imshow('mr',mr)
cv2.waitKey(0)
mr_down_1 = cv2.pyrDown(mr)#下采样G1
cv2.imshow('down_1',mr_down_1)
cv2.waitKey(0)
mr_down_2 = cv2.pyrDown(mr_down_1) #下采样G2
cv2.imshow('mr_down_2',mr_down_2)
cv2.waitKey(0)
三、上采样
通常将图像的宽度和高度都变为原来的2倍。这意味着,向上采样的结果图像的大小是原始图像的4倍。因此,要在结果图像中补充大量的像素点。对新生成的像素点进行赋值的行为,称为插值。
步骤:
1、插值
2、高斯滤波
示例:
这里采用如下函数:
python
cv2.pyrUp(src, dstsize, borderType)参数介绍:
src:
输入图像(灰度图 / 彩色图均可,彩色图会对每个通道单独上采样)
dstsize:
指定输出图像的尺寸(默认自动设为原尺寸的2倍)
注意:1、省略时,输出尺寸自动计算为 (src.cols×2, src.rows×2),即宽高各翻倍;
2、不能随意设尺寸(比如原图像 320×240,不能设 dstsize=(800, 600)),必须满足: |输出宽度 - 原宽度×2| ≤ 2",否则会报错
borderType:
边界填充方式(默认 cv2.BORDER_DEFAULT是是专为高斯金字塔设计的填充方式)
python
import cv2
import numpy as np
mr1 = cv2.imread('../data/img.png')
mr = cv2.resize(mr1,(500,500))
mr_up_1 = cv2.pyrUp(mr)
cv2.imshow('mr_up_1',mr_up_1)
cv2.waitKey(0)
mr_up_2 = cv2.pyrUp(mr_up_1)
cv2.imshow('mr_uo_2',mr_up_2)
cv2.waitKey(0)
四、拉普拉斯金字塔
由对下采用后图像进行上采样,图像变模糊,无法恢复其原始状态的,同样,对一幅图像先向下采样、再向上采样也无法恢复到原始状态。由分析知道:向上采样和向下采样是相反的两种操作。但是,由于向下采样会丢失像素值,所以这两种操作并不是可逆的。
为了解决这个问题即为了在向上采样是能够恢复具有较高分辨率的原始图像,就要获取在采样过程中所丢失的信息,这些丢失的信息就构成了拉普拉斯金字塔。
由下采样步骤知:使用某个变量来存储被删去的偶数行/列,再让先经过下采样后经过上采样的图片与这个变量相加(都为numpy数组)即可恢复具有较高分辨率的原始图像
python
import cv2
import numpy as np
mr1 = cv2.imread('../data/img.png')
mr = cv2.resize(mr1,(500,500))
cv2.imshow('mr',mr)
cv2.waitKey(0)
mr_down_1 = cv2.pyrDown(mr)#下采样G1
cv2.imshow('down_1',mr_down_1)
cv2.waitKey(0)
mr_down_2 = cv2.pyrDown(mr_down_1) #下采样G2
cv2.imshow('mr_down_2',mr_down_2)
cv2.waitKey(0)
'''
上采样
通常将图像的宽度和高度都变为原来的2倍。这意味着,向上采样的结果图像的大小是原始图像的4倍。因此,要在结果图像中补充大量的像素点。对新生成的像素点进行赋值的行为,称为插值。
dst = cv2.pyrUp(src [,dst, dstsize [, borderType] ])
dst:目标图像
src:原始图像
dstsize:目标图像的大小
'''
mr_up_1 = cv2.pyrUp(mr)
cv2.imshow('mr_up_1',mr_up_1)
cv2.waitKey(0)
mr_up_2 = cv2.pyrUp(mr_up_1)
cv2.imshow('mr_uo_2',mr_up_2)
cv2.waitKey(0)
#对下采用后图像进行上采样,图像变模糊,无法复原
#通过以上分析可知,向上采样和向下采样是相反的两种操作。但是,由于向下采样会丢失像素值,所以这两种操作并不是可逆的。
#也就是说,对一幅图像先向上采样、再向下采样,是无法恢复其原始状态的;同样,对一幅图像先向下采样、再向上采样也无法恢复到原始状态
mr_down_1_up = cv2.pyrUp(mr_down_1)
mr_down_2_up = cv2.pyrUp(mr_down_2)
cv2.waitKey(0)
#拉普拉斯金字塔
#为了在向上采样是能够恢复具有较高分辨率的原始图像,就要获取在采样过程中所丢失的信息,这些丢失的信息就构成了拉普拉斯金字塔。 也是拉普拉斯金字塔是有向下采样时丢失的信息构成。
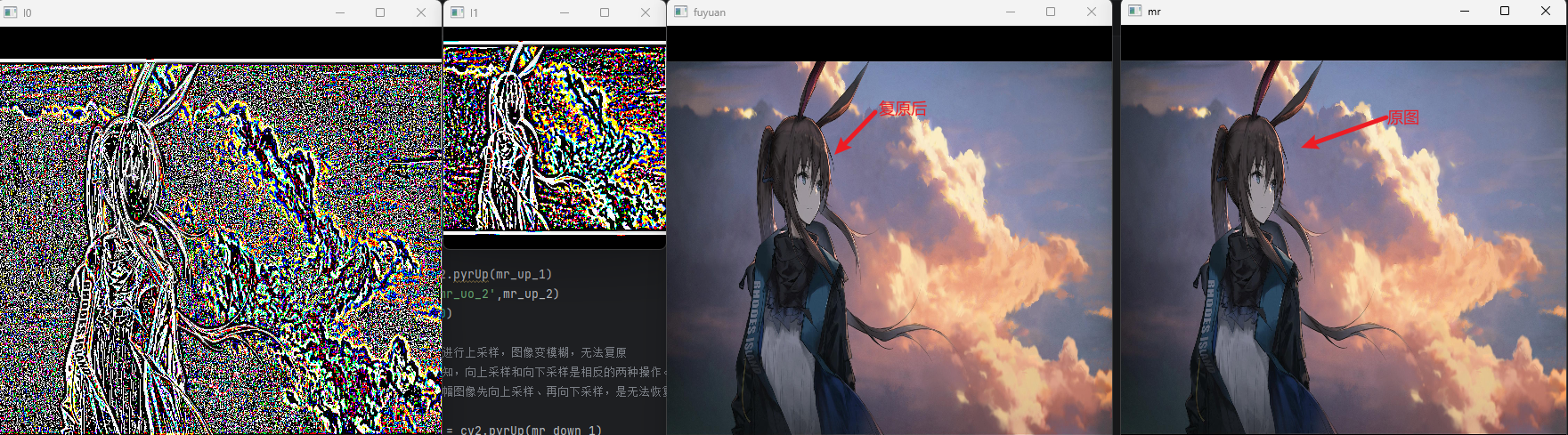
l0 = mr - mr_down_1_up
l1 = mr_down_1 - mr_down_2_up
fuyuan = mr_down_1_up + l0
cv2.imshow('l0',l0)
cv2.waitKey(0)
cv2.imshow('l1',l1)
cv2.waitKey(0)
cv2.imshow('fuyuan',fuyuan)
cv2.waitKey(0)