PaperSearchQA:学习在科学论文中搜索与推理 (RLVR)【PaperSearchQA: Learning to Search and Reason over Scientific Papers with RLVR】
摘要
搜索代理通过推理和搜索知识库(或网络)来回答问题;近期的方法仅使用可验证奖励的强化学习(RLVR) 来监督最终答案的准确性。大多数 RLVR 搜索代理处理通用领域问答 ,这限制了它们与科学、工程和医学领域技术 AI 系统的相关性。
在本工作中,我们提出训练代理在科学论文上进行搜索和推理------这测试了技术问答能力,与真实科学家直接相关,并且这些能力对于未来的 AI 科学家系统至关重要。
具体而言,我们发布了一个包含 1600 万篇生物医学论文摘要的搜索语料库 ,并构建了一个具有 6 万个可从语料库中回答的样本的挑战性事实问答数据集 PaperSearchQA ,以及相应的基准。
我们在该环境中训练搜索代理 ,使其性能优于非 RL 检索基线;我们还进行了进一步的定量分析,并观察到代理有趣的 G行为,如规划、推理和自我验证 。
我们的语料库、数据集和基准可与流行的 Search-R1 代码库一起用于 RLVR 训练 ,并在 Hugging Face 上发布。
最后,我们的数据创建方法是可扩展的,并且易于扩展到其他科学领域。
摘抄
- 在 RLVR 中,会提示 LLM 回答一个查询,只有当自动验证器认为最终输出正确时才会给予奖励;然后使用相应的 token 来更新模型。
- RLVR 被 Search-R1(Jin et al., 2025)证明对于训练搜索代理是有效的。
- 科学 QA 的搜索智能体 BioASQ(Tsatsaronis et al., 2015; Krithara et al., 2023)是一个自 2012 年以来每年举办的挑战赛。
- 对于3B LLM,RL在PaperSearchQA和BioASQ上的表现分别比RAG提高了9.6和5.5个百分点。
- 对于7B模型,差异分别为14.5和9.3。
- RAG的性能平均比无检索方法高17个百分点。
- 思维链提示的性能平均仅比直接推理高1.2个百分点。
- 模型大小带来的性能提升可能归因于知识。在所有基准测试的平均得分中,Search-R1 在 3B 模型上比 CoT 高出 20.2 个百分点,在 7B 模型上高出 21.4 个百分点。这表明性能提升是由于参数化知识的改进,而不是由于查询制定或理解能力的优越性。
- 使用 GRPO 进行训练不稳定,并且在某些训练运行中奖励会崩溃为零------基础(非指令)模型通常更稳定。
- 轨迹的格式包括'<think>'标记内的推理,最终答案在'<answer>'标记内。为了执行检索,LLM 在'<search>'标记中输出文本;检索到的文档被转储到'<information>'内的轨迹中。
- 这篇论文是一个单跳的QA,多跳更难。
贡献
1.一个生物医学的QA数据集,主要用于论文阅读的Agent。
2.RLVR训练论文阅读Agent的baseline。
能动强化学习赋能下一代化学语言模型,用于分子设计与合成【Agentic reinforcement learning empowers
next-generation chemical language models for
molecular design and synthesis】
摘要
语言模型正在彻底改变生物化学领域,高效地协助科学家进行药物设计和化学合成。然而,当前的方法在易产生幻觉且知识保留有限的小型语言模型与存在隐私风险和高推理成本的大型云端语言模型之间挣扎。
为了弥合这一差距,我们引入了 ChemCRAFT,一个利用智能体强化学习来解耦化学推理与知识存储 的新颖框架。我们的方法不是强迫模型记忆海量的化学数据,而是使语言模型能够与沙箱进行交互以进行精确的信息检索 。这种知识的外化使得一个本地可部署的小型模型能够以最小的推理成本实现卓越的性能。为了使小型语言模型具备调用智能体的能力,我们构建了一个智能体轨迹构建流水线和一个全面的化学-智能体沙箱。基于沙箱交互,我们构建了 ChemToolDataset,这是第一个大规模化学工具轨迹数据集 。同时,我们提出了 SMILES-GRPO 来构建一个密集的化学奖励函数 ,以提升模型调用化学智能体的能力。
在药物设计的各个方面的评估表明,ChemCRAFT 在分子结构分析、分子优化和合成路径预测方面优于当前基于云的大型语言模型,证明了科学推理并非仅仅是模型规模的涌现能力,而是工具编排的一种可学习策略。这项工作为人工智能辅助化学领域建立了一种成本效益高且保护隐私的范式,为通过本地可部署的智能体加速分子发现开辟了新途径。
摘抄
- 目前,化学语言模型( CLMs )的发展主要遵循两种截然不同的范式。 第一种方法涉及监督微调 (SFT),或在领域特定语料库上对大型语言模型进行持续预训练 。 虽然这些模型在分布内指标上取得了有竞争力的性能,但它们从根本上受到僵化的优化目标的困扰。 通过强迫模型最小化"任务-查询-直接答案"三元组上的损失 ,当前的 SFT 范式迫使 LLM 学习从化学输入直接映射到数值或标签的浅层映射 。 至关重要的是,这种方法绕过了**"专家式"推理过程** ------例如结构分析、中间假设生成和逻辑验证------而这些过程对于科学发现至关重要。 因此,这会导致模型固有的通用能力退化,通常被称为灾难性遗忘 ,并限制其在不同化学任务中的适应性 。为了弥合这种认知差距,最近的最新研究引入了**"化学推理"** 的概念。 通过利用来自更优教师模型的蒸馏 和基于强化学习 (RL) 的后训练,这些方法旨在引导模型模仿人类专家的逐步、连贯的工作流程。
- 复杂的工具编排 是一种仅限于海量、专有的LLMs(>100B参数)的涌现能力 。我们证明了,一个紧凑的7B-14B 参数模型,在通过监督微调和领域特定强化学习优化后 ,能够实现与商业API相媲美的工具使用能力。通过将模型的策略与"假设-行动-观察"科学循环对齐,我们在更小的架构中成功地引发了强大的推理和自我纠正能力。
- 该流程将原始化学数据转化为高质量的"智能体轨迹",随后通过冷启动 SFT 和领域特定强化学习的两阶段训练过程来调整模型的性能。
- ChemCoTBench 系统地将化学发现过程分解为 9 个主要任务和 22 个子任务,将基础推理与高风险的实际应用联系起来。反应预测(包括前向预测和逆合成)则支撑自动化化学合成规划。
- 通过将这些复杂的挑战分解为显式的模块化化学操作序列(例如,添加、删除、替换),ChemCoTBench 为我们的工作提供了必要的"脚手架",将抽象的化学挑战转化为可操作的、可追溯的推理步骤,从而反映了专业化学家严谨的工作流程。
- 建推理数据集构建方法:首先,为了将模型的推理建立在计算现实的基础上,我们设计了化学智能体沙箱------一个高性能的执行环境,其中基础的化学计算(例如,RDKit 结构解析、QED/LogP 评估和反应数据库检索)被重构为可扩展的微服务。
- 通过"假设-行动-细化 "循环(图 1a)构建了训练轨迹 。这里的一个关键创新是我们的"反思性细化"机制。原始的工具使用日志通常是零散和机械的(例如,"Action: Calculate MW; Observation: 150")。我们的机制通过,将经过验证的工具输出,注入回上下文,并提示教师模型重写其推理过程来转换这一点。模型保留了原始意图和工具的结果,但将它们编织成流畅、合乎逻辑的分析。这个过程有效地将僵化的 API 日志转化为动态的、专家级的科学叙述,其中代理解释证据、验证假设并以与人类领域专家一致的方式调整其策略。
- 两阶段训练范式:采用了一种渐进式训练策略 来灌输化学知识和 agentic 行为。阶段 1:冷启动 SFT :我们首先使用合成的 agentic 轨迹对基础模型(7B/14B)进行监督微调。二阶段:具有化学感知奖励的强化学习 :GRPO,设计了一个多维度的化学奖励函数 ,用于评估整个推理链的科学有效性 ;该信号严格整合了通过精确SMILES匹配和骨架相似性来评估的结构有效性,通过针对这些细粒度的化学指标进行优化,而非简单的文本重叠,模型学会了策略性地使用工具和推理路径,以最大化科学准确性。
精读读到1.2就没读了,因为不开源。全文大概就是描述其搭建的沙箱结构能得到反馈,并由此迭代。
贡献
- 构建了一个化学智能体沙箱(Chemical Agent Sandbox),这是一个交互式环境,通过计算、深度学习和检索式工具来外化领域专业知识。
- 提出ChemCRAFT ,模型的参数则专注于高级规划和逻辑 而不是密集的、低级的任务(例如价键检查和结构解析)。
- 构建并开源了一个大规模的专家级工具使用轨迹数据集。
通过AI驱动的自适应实验设计,为金属合金发现可行的3D打印配置【Discovery of Feasible 3D Printing Configurations for Metal Alloys
via AI-driven Adaptive Experimental Design】
摘要
配置金属合金的增材制造工艺参数是一个挑战性问题,因为输入参数(例如,激光功率、扫描速度)与打印输出质量之间存在复杂的关系。寻找可行参数配置的标准试错方法效率极低,因为验证每个配置在资源(物理和人力)方面成本高昂,且配置空间非常庞大。本文将人工智能驱动的自适应实验设计的一般原理与领域知识相结合,以解决发现可行配置的挑战性问题。关键思想是利用过去的实验构建一个代理模型 ,在每次迭代中智能地选择一小批输入配置进行验证。为了证明该方法论的有效性,我们将其应用于定向能量沉积(Directed Energy Deposition, DED)工艺,以打印NASA为航空航天应用开发的、高性能的铜-铬-铌合金GRCop-42。在三个月内,我们的方法在多种激光功率下产生了多个无缺陷的输出,与领域科学家数月手动实验但未获成功相比,显著缩短了获得结果的时间并降低了资源消耗。通过首次在现有的红外激光平台上实现高质量GRCop-42的制造,我们普及了对这种关键合金的获取途径,为航空航天应用的成本效益高、去中心化的生产铺平了道路。
摘抄
- 从过去的实验中构建一个概率代理模型 ------即工艺参数配置(输入)与指示实验成功/失败的二元输出 (包括打印和质量分析)(输出)的配对------并利用它来智能地选择一批工艺参数配置以在每次迭代中尝试。与试错法不同,这是一种主动方法,在一个闭环反馈中进行迭代,包括以下步骤:(a)使用选定的参数配置进行一批实验,(b)更新我们对参数可行性关系的信念,以及(c)为下一批实验选择参数配置。
- 开发了受主动搜索工作启发并结合领域知识的BEAM方法,以在每次迭代中选择一批参数配置。
- 部署和评估了BEAM,以配置DED工艺,首次在现有的红外激光平台上以较低的激光功率打印GRCop-42,从而实现大众化普及。
读完intrudaction就不读了,这个是传统机器学习
重新构想AI科学家:交互式多智能体工作流助力科学发现【Rethinking the AI Scientist: Interactive Multi-Agent
Workflows for Scientific Discovery】
Rethinking the AI Scientist![]() https://arxiv.org/pdf/2601.12542
https://arxiv.org/pdf/2601.12542
摘要
人工智能系统在科学发现方面展现了非凡的潜力,然而现有方法大多是专有的,并且以批处理模式运行,每个研究周期需要数小时,这阻碍了研究人员的实时指导。 本文介绍了 Deep Research,一个支持以分钟为单位的周转时间 的交互式科学研究的多智能体系统。 该架构包含用于规划、数据分析、文献检索和新颖性检测 的专用智能体,并通过一个持久的世界状态进行统一,该状态在迭代研究周期中保持上下文。 两种操作模式支持不同的工作流程:具有选择性人工检查点的半自主模式,以及用于扩展研究的完全自主模式。 在 BixBench 计算生物学基准测试上的评估显示了最先进的性能,在开放式回答上达到 48.8% 的准确率,在多项选择评估上达到 64.4%,比现有基线高出 14 到 26 个百分点。 对架构限制的分析,包括开放获取文献的限制以及自动化新颖性评估固有的挑战,为 AI 辅助科学工作流的实际部署提供了考虑因素。
摘抄
对开源可用性的批判性审查揭示了可复现性和社区发展方面存在的巨大障碍。
BixBench这是一个针对计算生物学和生物信息学中基于 LLM 的代理的综合基准测试。
BixBench 定义了三种评估机制(Mitchener et al., 2025a):(i) 开放式回答 ,其中一个裁判 LLM 将代理的自由格式答案与专家导出的参考解决方案进行比较,并分配二元正确性标签;(ii) 带拒绝选项的多项选择题 ,将答案转换为多项选择格式,包括一个"信息不足"选项;以及 (iii) 不带拒绝选项的多项选择题,要求仅在实质性答案选项中进行选择。
系统在保持持久化世界状态 的同时,循环执行规划、并行任务执行和反思阶段 。 用户输入可在每个周期边界进行纠错。 生物智能体架构的核心是持久化对话世界状态 的概念,该状态在长期的研究调查中维护着汇总的上下文。该世界状态包含所有累积的发现,包括不断演变的研究目标、当前假设、已记录的发现、改进的方法论、关键见解以及可用数据集及其先前迭代的描述。
两个基本任务:(1) 文献综合 ,研究人员系统地回顾现有出版物、专利、临床试验数据库、开源数据集及其他科学数据库,以建立知识状态并识别研究空白;以及 (2) 定量数据集分析,应用统计和计算方法生成实证结果并量化实验发现。 领域特定的需求,例如生物医学研究中的专利分析或临床试验审查,通过模块化工具集成来满足。
初始研究周期 用户指定**(i) 研究目标、(ii) 实验约束、(iii) 初步假设或实验想法、(iv) 可用数据集和 (v) 所需输出格式**。
读到3.1.1,下面没读了,就是一些实现细节
贡献
这个持久化世界状态很有意思。
此外,生物的agents还有HEUREKABENCH
Bohrium + SciMaster:大规模构建代理科学的基础设施和生态系统Bohrium + SciMaster: Building the Infrastructure andEcosystem for Agentic Science at Scale
摘要
AI agents 正在涌现,成为运行多步科学工作流的一种实用方式,这些工作流将推理与工具使用和验证交织在一起,预示着从孤立的 AI 辅助步骤向大规模自主科学的转变。
这一转变正变得越来越可行,因为科学工具和模型可以通过稳定的接口进行调用,并通过记录的执行轨迹进行验证;同时,它也变得越来越必要,因为 AI 加速了科学产出,并给同行评审和出版流程带来了压力,从而提高了可追溯性和可信评估的标准。而原型"AI科学家"系统通常是定制的,限制了从真实工作流信号中进行重用和系统性改进。 我们认为,扩展代理式科学需要一种基础设施与生态系统相结合的方法,这种方法体现在 Bohrium+SciMaster 中。 Bohrium 充当 AI4S 资产的托管、可追溯中心 ------类似于"AI for Science 的 HuggingFace"------它将多样化的科学数据、软件、计算和实验室系统转化为代理就绪的能力。SciMaster 将这些能力编排成长期科学工作流,科学代理可以在其上进行组合和执行。 在基础设施和编排之间,科学智能底层组织可重用的模型、知识和组件,形成用于工作流推理和行动的可执行构建块,从而实现组合、可审计性和通过使用进行改进。 我们通过在真实工作流中的十一个代表性主代理来演示这个堆栈 ,实现了端到端科学周期时间的数量级缩减,并生成了数百万规模的真实工作负载的执行基础信号。 总而言之,这项工作指向了"科学即服务"(Science-as-a-Service):科学工作流将变得越来越可执行、可观察和可持续改进,同时仍锚定在可追溯的验证和人类判断中。
摘抄
贡献
贡献了AI4S基础设施,整个论文关于技术很少,基本都是在讲为什么需要以及他有什么功能。
QMBench:量子材料研究的科研水平基准【QMBench: A Research Level Benchmark for Quantum Materials Research】
null![]() https://arxiv.org/pdf/2512.19753QMBench 的目标是提供一个 科研级别的 benchmark 集,用于评估 AI 在真实量子材料研究问题上的表现能力。为此,它必须满足:
https://arxiv.org/pdf/2512.19753QMBench 的目标是提供一个 科研级别的 benchmark 集,用于评估 AI 在真实量子材料研究问题上的表现能力。为此,它必须满足:
-
研究级题目、非考试题目 --- 问题由领域专家挑选,反映真实科研挑战;
-
多模态输出 --- 包括自然语言、数值、文件格式等;
-
覆盖量子材料研究全流程 --- 从基本物理原理到实际计算任务;
-
可演进、可更新 --- 可随着科研进展不断扩展。
迈向 AI 流体科学家:实验流体力学中 LLM 促进的科学发现【Towards an AI Fluid Scientist: LLM-Powered Scientific Discovery in Experimental Fluid Mechanics】
摘要
人工智能与实验流体力学的融合有望加速科学发现,但目前大多数人工智能应用仍局限于数值研究。 本研究提出了一个"AI流体科学家"框架,该框架能够自主执行完整的实验工作流程:**假设生成、实验设计、机器人执行、数据分析和论文撰写。**我们通过研究串列圆柱体的涡激振动(VIV)和尾流激振动(WIV)来验证该框架。 我们的工作有四项主要贡献:(1)一个计算机控制的循环水槽(CWT),能够程序化控制流速、圆柱体位置和激励参数(振动频率和幅度),并进行数据采集(位移、力和扭矩)。 (2)自动化实验重现了文献基准(Khalak and Williamson 1999 和 Assi et al. 2013, 2010),频率锁定误差在 4% 以内,并匹配了临界间距趋势。 (3)该框架结合了"人在回路"(Human-in-the-Loop, HIL)机制,发现了更多的 WIV 幅度响应现象,并使用神经网络从数据中拟合物理定律,其精度比多项式拟合高 31%。 (4)该框架结合了多智能体与虚实交互系统,端到端地执行了数百次实验,自动完成了从假设生成、实验设计、实验执行、数据分析到论文撰写的整个科学研究过程。
传统机器学习,不看了。
OmniScientist:迈向人与AI科学家共生演进的生态系统【OmniScientist: Toward a Co-evolving Ecosystem ofHuman and AI Scientists】
OmniScientist --- OmniScientist![]() https://arxiv.org/pdf/2511.16931
https://arxiv.org/pdf/2511.16931
摘要
随着大型语言模型(LLMs)的飞速发展,AI智能体在科学任务中展现出日益增长的熟练度,涵盖了从假设生成、实验设计到论文撰写 等各个环节。这类智能体系统通常被称为"AI科学家"。
然而,现有的AI科学家主要将科学发现视为独立的搜索或优化问题,忽略了科学研究本质上是一项社会性和协作性的事业。现实世界的科学依赖于一个复杂的科学基础设施,该基础设施由协作机制、贡献归属、同行评审和结构化的科学知识网络组成。由于缺乏对这些关键维度的建模,当前系统难以建立真正的研究生态系统或与人类科学界进行深度互动。为了弥合这一差距,我们引入了OmniScientist,一个明确将人类研究的底层机制编码到AI科学工作流程中的框架。
OmniScientist不仅实现了从数据基础、文献综述、研究构思、实验自动化、科学写作到同行评审的全流程自动化,还通过模拟人类科学系统提供了全面的基础设施支持 ,该系统包括:(1)一个建立在引文网络和概念关联之上的结构化知识系统;(2)一个协作研究协议(OSP),支持无缝的多智能体协作和人类研究员的参与;以及(3)一个基于盲法成对用户投票和Elo排名的开放评估平台(ScienceArena)。
这一基础设施使智能体不仅能够理解和利用人类知识系统,还能进行协作和共生演化,从而促进一个可持续且可扩展的创新生态系统。通过OmniScientist,我们的目标是推动AI智能体从单纯的任务执行者转变为能够理解科学规范、参与协作并驱动科学生态系统进化的真正科学家。
摘抄
- 其核心是一个强大的数据基础,建立在数百万篇全文出版物和元数据之上。 这形成了一个动态的科学网络,捕捉引文关系和知识上下文,在引文网络中探索和提炼概念,生成既有上下文基础又方法严谨的新颖假设。
- 对于实验自动化,该系统采用了一个迭代的多智能体循环,该循环生成、评估和改进实验策略,通过严格的反馈机制实现自我优化。 实验之后,科学写作由一个集成框架支持,该框架综合相关工作,生成图表,并根据标准化的学术规范改进文本,从而产生连贯、可发表的手稿。 最后,该系统包含一个论文评审机制,它作为一个质量控制门,通过与先前工作的深入比较来评估提交的论文,提供客观且可操作的反馈。
- 我们提出了Omni Scientific Protocol(OSP ),一个标准化的协作骨干,旨在协调多个AI智能体与人类研究者之间复杂的交互 。OSP不将人类视为被动的观察者,而是允许研究者无缝地参与执行和协作过程,在系统需要高级人类直觉时提供及时的反馈、战略性建议或方向修正 。为了维护科学的完整性,OSP还包含一个细粒度的贡献跟踪系统。 该机制记录了每个想法、数据集和实验结果的出处,将功劳归于特定的智能体或人类参与者,从而建立了一个透明的作者身份和责任模型,类似于现代科学中的贡献者角色。
- 其次,为解决开放式科学发现评估这一长期存在的挑战,我们开发了 ScienceArena2,这是一个开放的基准测试平台,旨在模拟科学验证的社区驱动性质。与静态指标不同,ScienceArena 采用一种盲审、成对投票机制,由人类专家根据科学严谨性和新颖性评估匿名的研究成果。通过将这些偏好聚合为动态 Elo 评分,该平台建立了一个实时的排行榜,反映了不断变化的社区标准,从而有效地使人类判断能够积极塑造 AI Scientific agents 的进化方向。
- 整合了 OpenAlex 开放获取学术图谱,这是最全面的学术知识网络之一。 该数据集包含约 2.69 亿篇论文 的元数据记录及其引用关系。集成了arXiv 开放获取论文存储库,提供了约 260 万篇 PDF 全文文档,覆盖了 90% 以上的 AI 相关出版物。
- 收集了过去十年顶级 AI 会议的**102,679 篇全文论文,以及 116,970 个引用的基线模型和 68,316 个相关数据集。**每个条目不仅包含方法的文本描述和结果,还包含实现资源、数据集、超参数和评估指标。
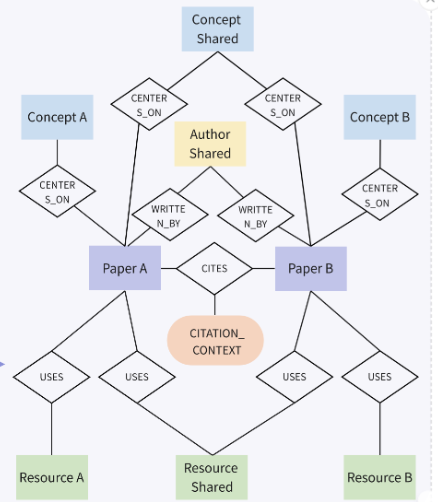
- 知识库组织为一个有向、带标签的图,包含四种核心节点类型:论文 (Paper)、作者 (Author)、概念 (Concept) 和资源 (Resource)(数据集、模型、工具)。 语义结构通过诸如 CITES (论文到论文)、WRITTEN_BY (论文到作者)、USES (论文到资源) 和 CENTERS_ON (论文到概念) 等边来捕获。
- 为了进一步模拟科学话语的解释层,我们将 citation_contexts 附加到 CITES 边上,保留了引文背后的文本理由。
看到3.2没看了,后面都是技术细节