一次搞懂PyTorch DDP分布式训练_哔哩哔哩_bilibili
多机多卡,或单机多卡
几张卡初始化模型一样,每张卡分别拿不同的数据
几张开训练一轮后,会共享自己反向传播的梯度,然后对梯度取均值,来达到同步跟新的效果
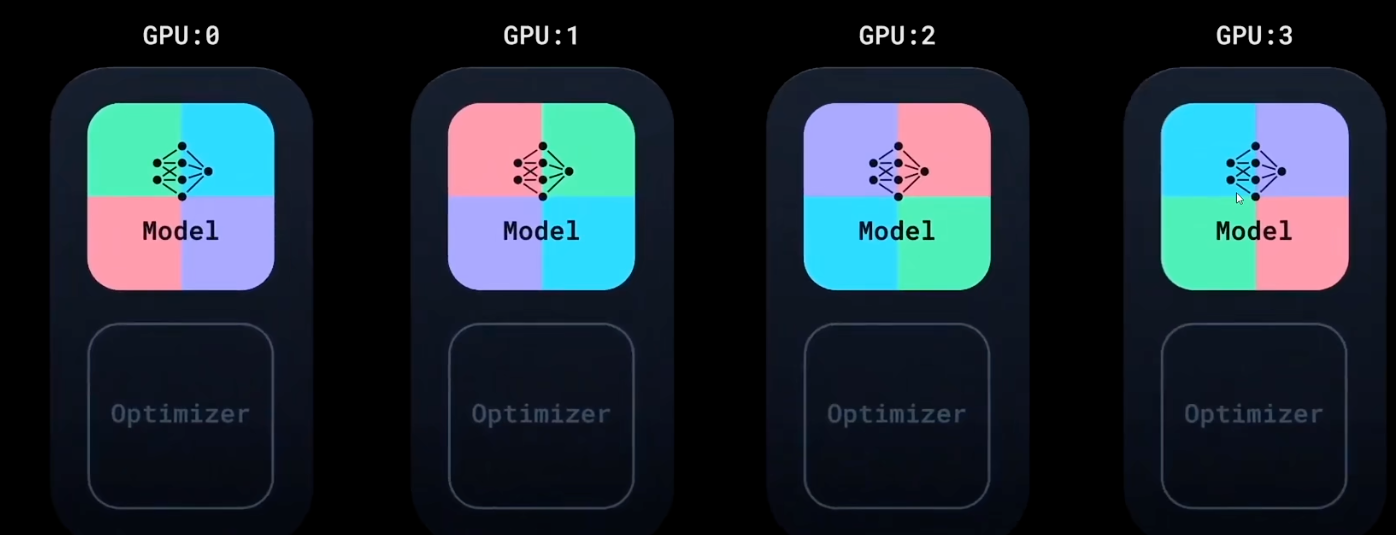
all reduce:就是把所有卡的信息收即到自己这里来的这么一个通信操作。(4张卡就4个都会做,且是对同一批参数梯度同时对齐,也只有这样才能同时对齐)
(注意他同步梯度的时候,是边反向传播,边互相同步,而不是等反向传播完了之后在同步)
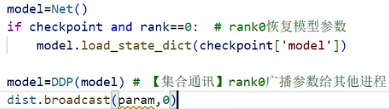
靠这个随机种子,来保证取数据大家 是同步的
