目录
[1.Scaling Law 驱动模型容量越来越大:](#1.Scaling Law 驱动模型容量越来越大:)
[2. 大模型带来的问题:](#2. 大模型带来的问题:)
[1. 低精度数据类型优势:](#1. 低精度数据类型优势:)
[2. 量化推理:](#2. 量化推理:)
[1. 定义:](#1. 定义:)
[2. 常见融合场景:](#2. 常见融合场景:)
[1. 目标:](#1. 目标:)
[2. 注意力计算优化:](#2. 注意力计算优化:)
[3. KV Cache 管理优化:](#3. KV Cache 管理优化:)
[1. 定义:](#1. 定义:)
[2. 并行策略:](#2. 并行策略:)
[3. 张量切分方式:](#3. 张量切分方式:)
[4. 具体实现:](#4. 具体实现:)
本文介绍计算优化与分布式推理技术,充分利用硬件资源,降低推理成本,提供实时高效服务。
背景与意义
1.Scaling Law 驱动模型容量越来越大:
- • Scaling Law 显示,在一定范围内,增加模型参数量、训练数据量和计算量,模型性能通常会按可预测规律提升。这使得模型参数量越来越大。
2. 大模型带来的问题:
- • 空间占用高、计算延迟、KV Cache 所需空间更大、硬件成本高、API 价格昂贵。
低精度类型
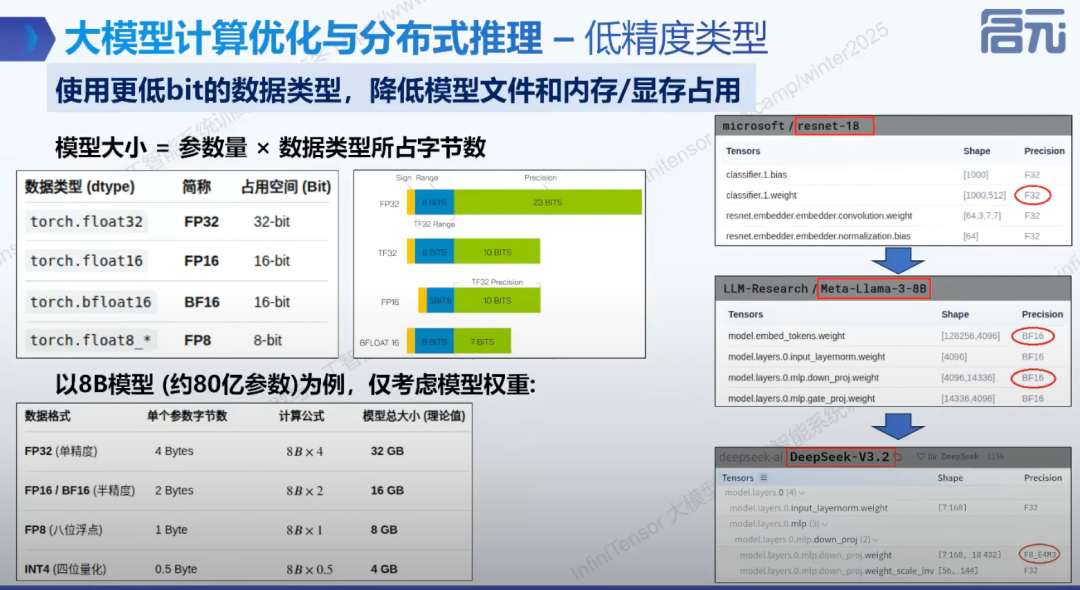
1. 低精度数据类型优势:
FP32、FP16、BF16、FP8等,不同数据类型占用的位数和表示范围不同。降低模型文件和内存显存占用,例如 8B 模型从 FP32 降到 FP16,可以显著减少显存占用。
2. 量化推理:
-
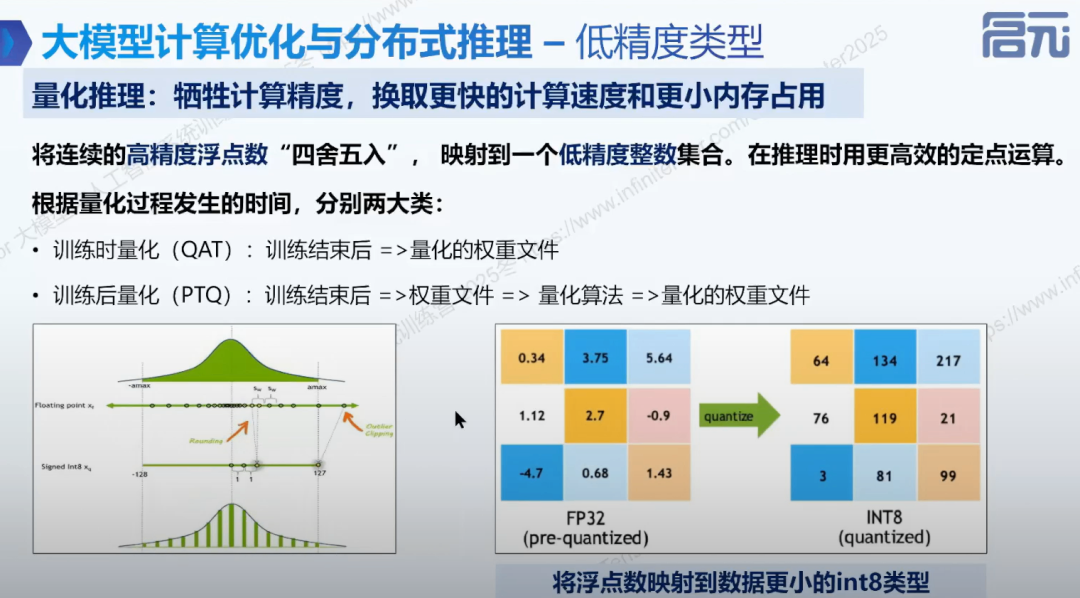
• 定义: 牺牲计算精度换取更快计算速度和更小内存占用。
-
• 分类: 训练时量化(训练过程中考虑权重量化)和训练后量化(PTQ,训练结束后通过量化算法处理权重文件)。
-
• 量化过程: 浮点数运算映射到低精度整数运算,如 FP32 映射到 INT8。
-
• 量化优点: 权重文件变小,访存加快,INT8 有专门核心加速计算,降低部署成本。
-
• 量化缺点: 精度损失,模型性能变差。
融合算子
1. 定义:
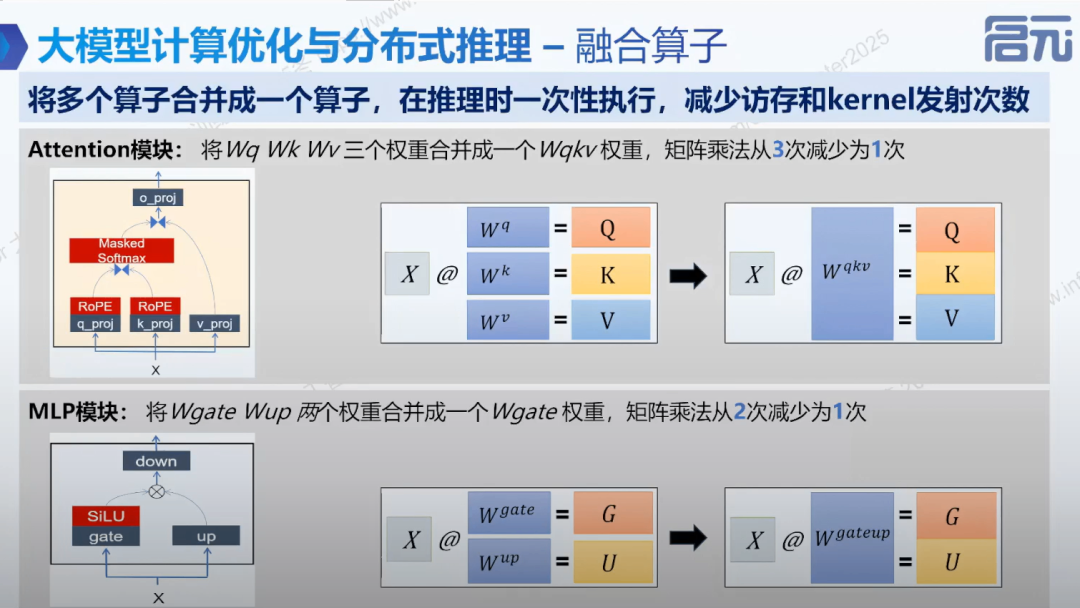
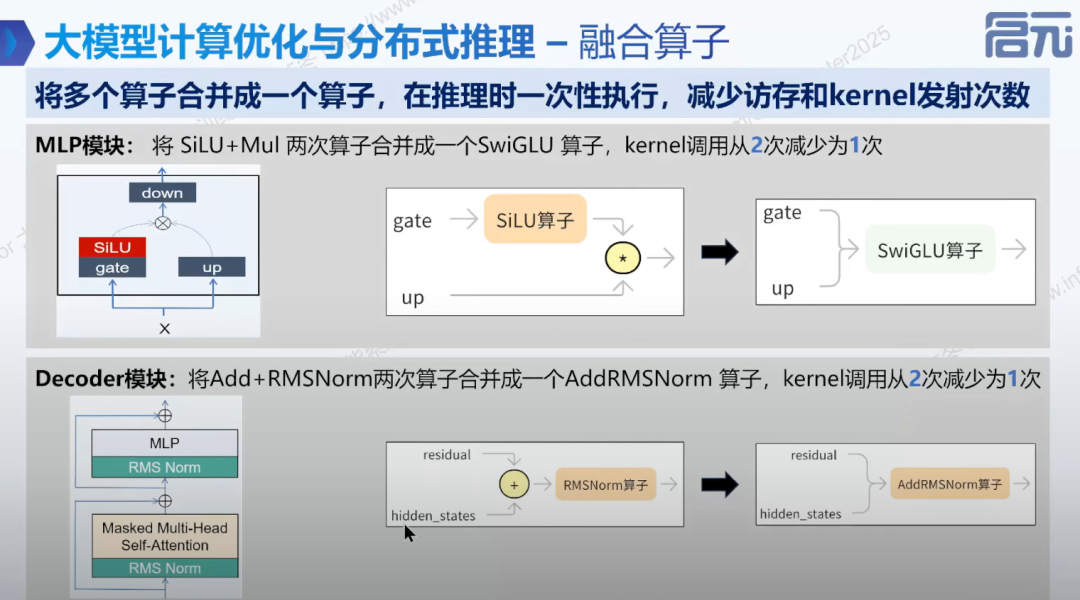
- • 将多个算子合并成一个算子,减少内存访问和 kernel 发射次数。
2. 常见融合场景:
-
• 矩阵乘法融合
-
• MLP 模块融合
-
• Decoder 模块
模型结构
1. 目标:
提高计算效率,降低硬件要求。
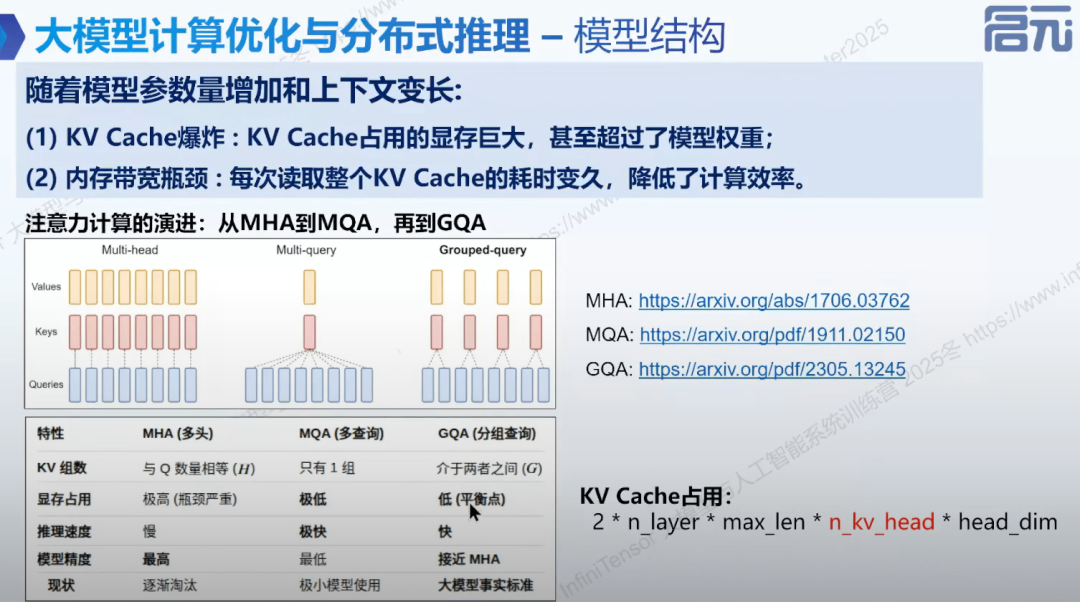
2. 注意力计算优化:
- • MHA 到 MQA 到 GQA: 平衡显存占用和模型性能。
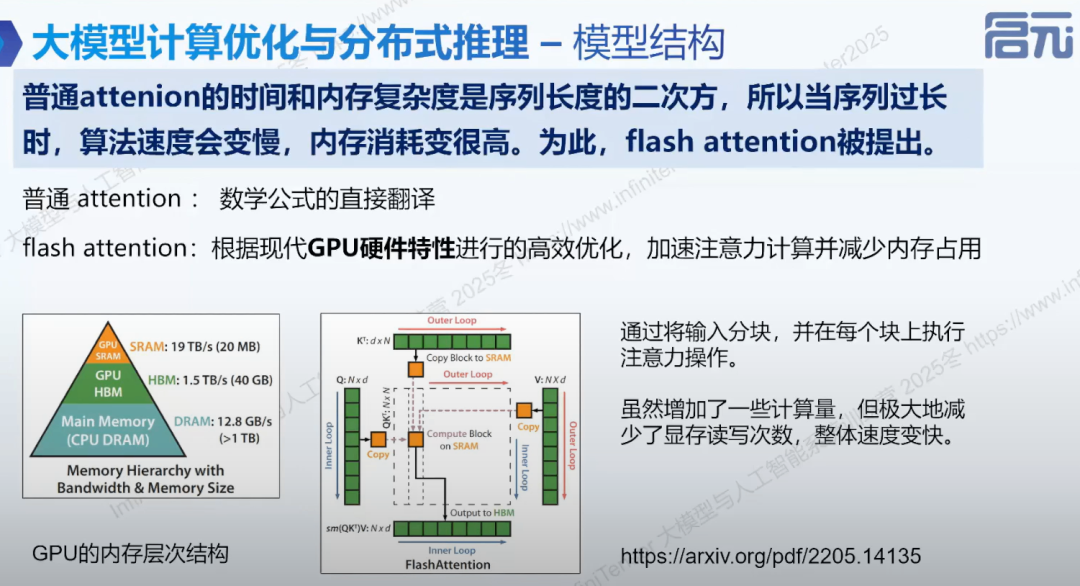
- • Flash Attention: 结合 GPU 硬件特性,优化注意力计算,减少显存占用,提高计算速度。
3. KV Cache 管理优化:
-
• 传统方法问题:内存碎片化、重复计算。
-
• Paged Attention:借鉴操作系统虚拟内存分页思想,按需分配显存,减少内存碎片化。

分布式推理
1. 定义:
- • 通过多张显卡或多个计算节点共同完成推理任务。
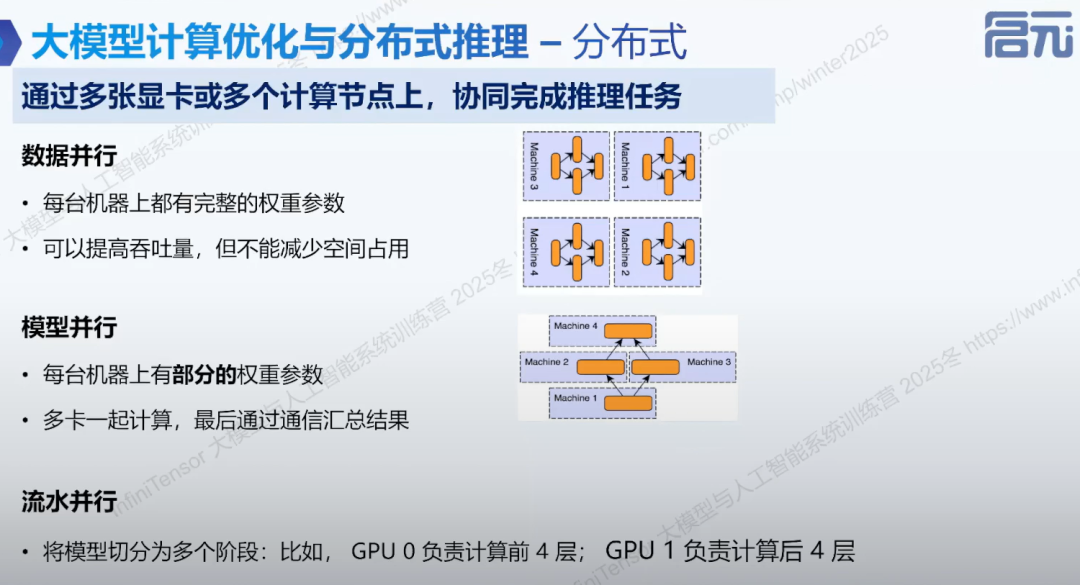
2. 并行策略:
-
• 数据并行: 每个机器拥有完整权重参数,输入根据调度分配到不同机器,提高吞吐量。
-
• 模型并行: 每个机器只拥有部分权重参数,多张卡共同计算,通过通信汇总结果。
-
• 流水并行: 模型切分为多个阶段,不同 GPU 负责不同阶段计算。
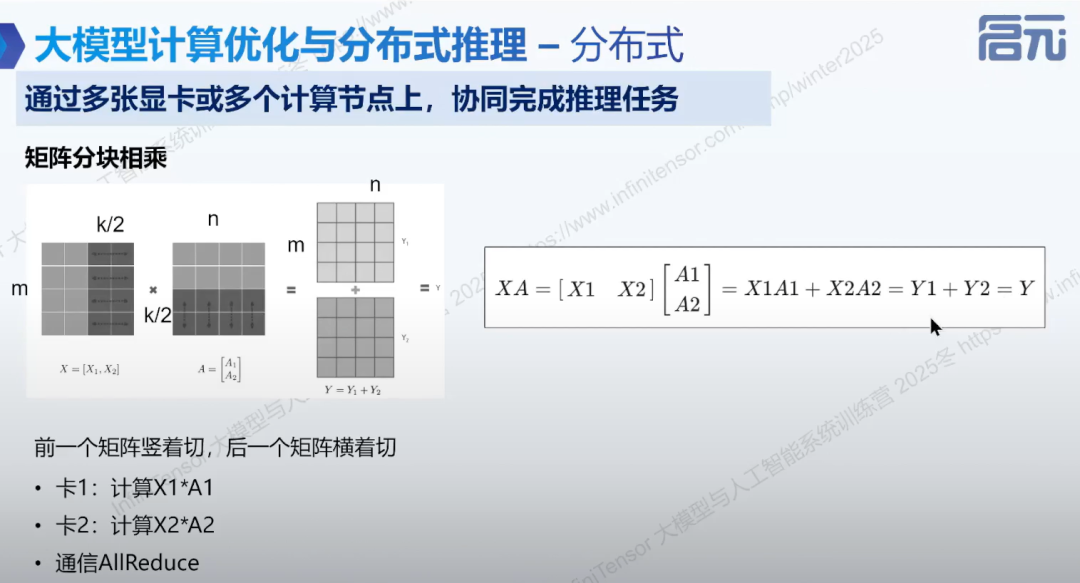
3. 张量切分方式:

-
• 按行切分:矩阵横着切,上半部分在一张卡上,下半部分在另一张卡上。
-
• 按列切分:矩阵竖着切,左边在一张卡上,右边在另一张卡上。
-
• 矩阵分块相乘:将大矩阵拆分为小矩阵进行计算,结果相同。
4. 具体实现:
- • MLP 模块权重切分:up、gate 权重竖切,down 权重横切,通过 AllReduce 通信得到结果。

- • Attention 模块权重切分:Q、K、V 权重切第二个维度,O 权重切第零个维度,过程与 MLP 切分相同。

- • Embedding 切分:token 转向量过程竖着切,通过 AllGather 通信。

总结
本文主要从低精度类型、融合算子、模型结构以及分布式四个方面讲解了大模型计算优化与分布式推理技术。后续推理课程将涉及大模型服务系统。