#作者:张桐瑞
文章目录
- [5 MirrorMaker2监控](#5 MirrorMaker2监控)
-
- [5.1 配置jmx-expoter](#5.1 配置jmx-expoter)
- 5.2kafka-connect.yml
- 5.3配置prometheus
- 5.4指标说明
- [6 Kafka Mm2数据同步说明](#6 Kafka Mm2数据同步说明)
- [7 说明](#7 说明)
5 MirrorMaker2监控
5.1 配置jmx-expoter
下载地址:
# 通过 javaagent 参数加载 JMX Exporter,并指定端口 7070 和配置文件
vim /bin/connect-mirror-maker.sh
添加如下配置
export KAFKA_OPTS="-javaagent:/opt/prometheus/jmx_prometheus_javaagaent-1.1.0.jar=3600:/opt/prometheus/kafka-connect.yml"5.2kafka-connect.yml
wercaseOutputName: true
rules:
#kafka.connect:type=app-info,client-id="{clientid}"
#kafka.consumer:type=app-info,client-id="{clientid}"
#kafka.producer:type=app-info,client-id="{clientid}"
- pattern: 'kafka.(.+)<type=app-info, client-id=(.+)><>start-time-ms'
name: kafka_$1_start_time_seconds
labels:
clientId: "$2"
help: "Kafka $1 JMX metric start time seconds"
type: GAUGE
valueFactor: 0.001
- pattern: 'kafka.(.+)<type=app-info, client-id=(.+)><>(commit-id|version): (.+)'
name: kafka_$1_$3_info
value: 1
labels:
clientId: "$2"
$3: "$4"
help: "Kafka $1 JMX metric info version and commit-id"
type: GAUGE
#kafka.producer:type=producer-topic-metrics,client-id="{clientid}",topic="{topic}"", partition="{partition}"
#kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientid}",topic="{topic}"", partition="{partition}"
- pattern: kafka.(.+)<type=(.+)-metrics, client-id=(.+), topic=(.+), partition=(.+)><>(.+-total|compression-rate|.+-avg|.+-replica|.+-lag|.+-lead)
name: kafka_$2_$6
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
help: "Kafka $1 JMX metric type $2"
type: GAUGE
#kafka.producer:type=producer-topic-metrics,client-id="{clientid}",topic="{topic}"
#kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientid}",topic="{topic}"", partition="{partition}"
- pattern: kafka.(.+)<type=(.+)-metrics, client-id=(.+), topic=(.+)><>(.+-total|compression-rate|.+-avg)
name: kafka_$2_$5
labels:
clientId: "$3"
topic: "$4"
help: "Kafka $1 JMX metric type $2"
type: GAUGE
#kafka.connect:type=connect-node-metrics,client-id="{clientid}",node-id="{nodeid}"
#kafka.consumer:type=consumer-node-metrics,client-id=consumer-1,node-id="{nodeid}"
- pattern: kafka.(.+)<type=(.+)-metrics, client-id=(.+), node-id=(.+)><>(.+-total|.+-avg)
name: kafka_$2_$5
labels:
clientId: "$3"
nodeId: "$4"
help: "Kafka $1 JMX metric type $2"
type: UNTYPED
#kafka.connect:type=kafka-metrics-count,client-id="{clientid}"
#kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientid}"
#kafka.consumer:type=consumer-coordinator-metrics,client-id="{clientid}"
#kafka.consumer:type=consumer-metrics,client-id="{clientid}"
- pattern: kafka.(.+)<type=(.+)-metrics, client-id=(.*)><>(.+-total|.+-avg|.+-bytes|.+-count|.+-ratio|.+-age|.+-flight|.+-threads|.+-connectors|.+-tasks|.+-ago)
name: kafka_$2_$4
labels:
clientId: "$3"
help: "Kafka $1 JMX metric type $2"
type: GAUGE
#kafka.connect:type=connector-task-metrics,connector="{connector}",task="{task}<> status"
- pattern: 'kafka.connect<type=connector-task-metrics, connector=(.+), task=(.+)><>status: ([a-z-]+)'
name: kafka_connect_connector_status
value: 1
labels:
connector: "$1"
task: "$2"
status: "$3"
help: "Kafka Connect JMX Connector status"
type: GAUGE
#kafka.connect:type=task-error-metrics,connector="{connector}",task="{task}"
#kafka.connect:type=source-task-metrics,connector="{connector}",task="{task}"
#kafka.connect:type=sink-task-metrics,connector="{connector}",task="{task}"
#kafka.connect:type=connector-task-metrics,connector="{connector}",task="{task}"
- pattern: kafka.connect<type=(.+)-metrics, connector=(.+), task=(.+)><>(.+-total|.+-count|.+-ms|.+-ratio|.+-avg|.+-failures|.+-requests|.+-timestamp|.+-logged|.+-errors|.+-retries|.+-skipped)
name: kafka_connect_$1_$4
labels:
connector: "$2"
task: "$3"
help: "Kafka Connect JMX metric type $1"
type: GAUGE
#kafka.connect:type=connector-metrics,connector="{connector}"
#kafka.connect:type=connect-worker-metrics,connector="{connector}"
- pattern: kafka.connect<type=connect-worker-metrics, connector=(.+)><>([a-z-]+)
name: kafka_connect_worker_$2
labels:
connector: "$1"
help: "Kafka Connect JMX metric $1"
type: GAUGE
#kafka.connect:type=connect-worker-metrics
- pattern: kafka.connect<type=connect-worker-metrics><>([a-z-]+)
name: kafka_connect_worker_$1
help: "Kafka Connect JMX metric worker"
type: GAUGE
#kafka.connect:type=connect-worker-rebalance-metrics
- pattern: kafka.connect<type=connect-worker-rebalance-metrics><>([a-z-]+)
name: kafka_connect_worker_rebalance_$1
help: "Kafka Connect JMX metric rebalance information"
type: GAUGE
#kafka.connect.mirror:type=MirrorSourceConnector
- pattern: kafka.connect.mirror<type=MirrorSourceConnector, target=(.+), topic=(.+), partition=([0-9]+)><>([a-z-]+)
name: kafka_connect_mirror_source_connector_$4
help: Kafka Connect MM2 Source Connector Information
labels:
destination: "$1"
topic: "$2"
partition: "$3"
type: GAUGE
#kafka.connect.mirror:type=MirrorCheckpointConnector
- pattern: kafka.connect.mirror<type=MirrorCheckpointConnector, source=(.+), target=(.+)><>([a-z-]+)
name: kafka_connect_mirror_checkpoint_connector_$3
help: Kafka Connect MM2 Checkpoint Connector Information
labels:
source: "$1"
target: "$2"
type: GAUGE5.3配置prometheus
scrape_configs:
- job_name: 'mm2-jmx'
static_configs:
- targets: ['<MM2_HOST>:3600']5.4指标说明
| Prometheus指标名 | 指标类型 | 指标含义 | 作用 | 建议阈值 / 判断标准 | 异常说明 |
|---|---|---|---|---|---|
| kafka_connect_mirror_source_connector_record_rate | gauge | 每秒同步的消息数量 | 判断迁移速率是否稳定 | 必须 ≥ 源集群生产速率 | 速率下降会导致积压 |
| kafka_connect_mirror_source_connector_record_count | gauge | 已同步的消息总数 | 判断迁移是否持续推进 | 持续增长为正常 | 长时间不增长说明同步停滞 |
| kafka_connect_mirror_source_connector_byte_rate | gauge | 每秒同步的数据量(字节) | 判断网络与带宽使用情况 | 持续稳定为正常 | 明显下降说明网络或目标写入瓶颈 |
| kafka_connect_mirror_source_connector_byte_count | gauge | 已同步的数据总量 | 迁移进度参考 | 持续增长为正常 | 不增长说明任务异常或停止 |
| kafka_connect_mirror_source_connector_replication_latency_ms_avg | gauge | 平均端到端同步延迟 | 判断迁移实时性 | < 3s 正常;>10s告警 | 网络延迟或目标Broker压力 |
| kafka_connect_mirror_source_connector_replication_latency_ms_max | gauge | 最大同步延迟 | 判断是否存在抖动或阻塞 | >30s需关注 | Broker抖动、批量阻塞或GC |
| kafka_connect_mirror_source_connector_replication_latency_ms_min | gauge | 最小同步延迟 | 参考指标 | --- | 无实际告警意义 |
| kafka_connect_mirror_source_connector_record_age_ms_avg | gauge | 当前同步数据在源端停留的平均时间 | 判断是否开始积压(最重要业务延迟) | 持续上升即异常;正常应稳定或接近0 | 同步能力低于源生产速率 |
| kafka_connect_mirror_source_connector_record_age_ms_max | gauge | 最大积压时间 | 判断最严重延迟情况 | >60s需关注;持续增长需告警 | 已出现明显积压 |
| kafka_connect_mirror_source_connector_record_age_ms_min | gauge | 最小积压时间 | 参考指标 | --- | 无告警意义 |
6 Kafka Mm2数据同步说明
6.1数据一致性说明
Kafka MM2 的数据一致性保障,依赖 Kafka Producer 在目标集群使用ACK配置,幂等生产者配置,确保每条消息写入至少一组副本。在同步目标集群消息、配置、消费者组偏移量和 ACL时,通常会略微落后于源集群。所有这些过程都是异步的,因此数据内容将首先发生在源集群中上,然后不久同步到目标集群上。
故原集群中数据内容最终都会同步到目标集群中,但是同步效率会由于源Kafka集群的数据量影响,并且会大幅度增加主机资源使用量。
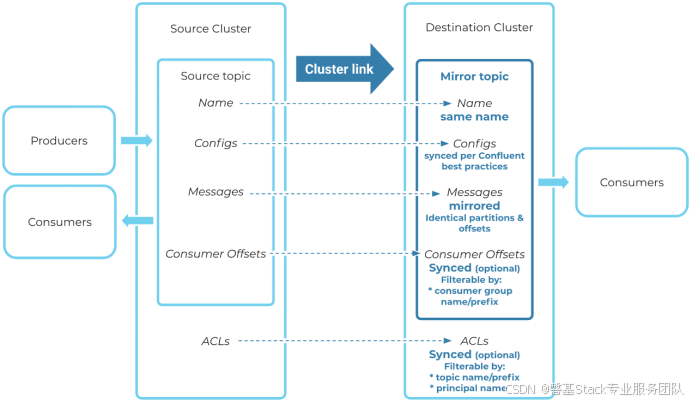
MM2数据复制流程图
6.2数据同步延迟说明
Kafka MirrorMaker 2 是基于 Kafka Connect 架构实现的跨集群数据复制工具,其核心特征是"最终一致性",但它无法保证确定性延迟或严格实时同步。
-
同步机制存在天然延迟
1)MM2 会周期性地从源集群拉取数据并写入目标集群。
2)其延迟受到多种因素影响:拉取频率、目标集群写入速度、网络状况、主题数量、分区数量、消费者负载等。
3)心跳(__consumer_offsets, heartbeats, checkpoints)同步本身也有间隔控制,默认并非毫秒级别。
-
延迟不可控,不可预测
1)MM2 并没有提供严格的端到端延迟保障机制。
2)实际运行中,延迟从几秒到几分钟不等,并且波动大,难以准确衡量和预估。
3)延迟监控只能通过辅助指标(如 OffsetSync)间接估算,无法保证精确对齐。
-
最终可达一致,但不能满足实时或强一致需求
1)MirrorMaker 2 只保证最终一致性(eventual consistency),不适合对时效性、事务性、顺序性有要求的场景。
2)即使网络不通、目标集群短暂故障,MM2 会在恢复后继续同步,但同步时间不可预测。
7 说明
7.1kafka3.9.1版本出现异常
由于3.9.1版本优化部分内容,导致出现如下问题,需要使用低于3.9版本
7.1.1异常信息
[2026-02-10 16:15:45,551] ERROR [Worker clientId=d->s, groupId=d-mm2] Failed to reconfigure connector's tasks (MirrorCheckpointConnector), retrying after backoff. (org.apache.kafka.connect.runtime.distributed.DistributedHerder:2197)
org.apache.kafka.connect.errors.RetriableException: Timeout while loading consumer groups.
at org.apache.kafka.connect.mirror.MirrorCheckpointConnector.taskConfigs(MirrorCheckpointConnector.java:138)
at org.apache.kafka.connect.runtime.Worker.connectorTaskConfigs(Worker.java:398)
at org.apache.kafka.connect.runtime.distributed.DistributedHerder.reconfigureConnector(DistributedHerder.java:2245)
at org.apache.kafka.connect.runtime.distributed.DistributedHerder.reconfigureConnectorTasksWithExponentialBackoffRetries(DistributedHerder.java:2185)
at org.apache.kafka.connect.runtime.distributed.DistributedHerder.lambda$null$47(DistributedHerder.java:2201)
at org.apache.kafka.connect.runtime.distributed.DistributedHerder.runRequest(DistributedHerder.java:2404)
at org.apache.kafka.connect.runtime.distributed.DistributedHerder.tick(DistributedHerder.java:500)
at org.apache.kafka.connect.runtime.distributed.DistributedHerder.run(DistributedHerder.java:385)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
[2026-02-10 16:15:47,967] INFO [MirrorSourceConnector|task-0|offsets] WorkerSourceTask{id=MirrorSourceConnector-0} Committing offsets for 59 acknowledged messages (org.apache.kafka.connect.runtime.WorkerSourceTask:236)7.1.2Issue
https://issues.apache.org/jira/browse/KAFKA-17232
7.2单节点测试异常
INFO 'mm2-offsets.s.internal' topic creation failed due to 'Error while attempting to create/find topic(s) 'mm2-offsets.s.internal'', retrying, 54572ms remaining (org.apache.kafka.connect.util.TopicAdmin:337)使用单节点进行迁移测试需添加如下配置
checkpoints.topic.replication.factor = 1
heartbeats.topic.replication.factor = 1
offset-syncs.topic.replication.factor = 1
replication.factor = 1
config.storage.replication.factor = 1
offset.storage.replication.factor = 1
status.storage.replication.factor = 1