
autobackend模块是 Ultralytics YOLO 项目的核心推理后端,主要功能是自动检测和加载多种格式的模型文件,并提供一个统一的接口进行推理。它支持超过20种不同的模型格式,包括 PyTorch、ONNX、TensorRT、TensorFlow、CoreML 等,使得用户可以用同一个代码接口运行不同格式的模型。
基础依赖导入
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# 版权声明:使用 AGPL-3.0 许可证的开源项目
from __future__ import annotations
# 启用类型注解的延迟评估,允许在类型注解中引用尚未定义的类
import ast # 用于解析 Python 表达式字符串
import json # 用于处理 JSON 格式数据
import platform # 用于获取平台信息(Linux/Windows/Mac)
import zipfile # 用于处理 ZIP 压缩文件
from collections import OrderedDict, namedtuple # OrderedDict 保持插入顺序,namedtuple 创建轻量级对象
from pathlib import Path # 面向对象的路径操作
from typing import Any # 类型注解中的任意类型
import cv2 # OpenCV 计算机视觉库
import numpy as np # 数值计算库
import torch # PyTorch 深度学习框架
import torch.nn as nn # PyTorch 神经网络模块
from PIL import Image # Python 图像处理库
# 从 ultralytics.utils 导入各种工具和常量
from ultralytics.utils import ARM64, IS_JETSON, LINUX, LOGGER, PYTHON_VERSION, ROOT, YAML, is_jetson
# ARM64: 是否是 ARM64 架构
# IS_JETSON: 是否是 NVIDIA Jetson 设备
# LINUX: 是否是 Linux 系统
# LOGGER: 日志记录器
# PYTHON_VERSION: Python 版本信息
# ROOT: 项目根目录路径
# YAML: YAML 文件处理工具
# is_jetson: 检查是否是 Jetson 设备的函数
from ultralytics.utils.checks import check_requirements, check_suffix, check_version, check_yaml, is_rockchip
# check_requirements: 检查依赖包是否安装
# check_suffix: 检查文件后缀
# check_version: 检查版本号
# check_yaml: 检查并加载 YAML 文件
# is_rockchip: 检查是否是 Rockchip 设备
from ultralytics.utils.downloads import attempt_download_asset, is_url
# attempt_download_asset: 尝试下载模型文件
# is_url: 检查字符串是否是 URL
from ultralytics.utils.nms import non_max_suppression
# non_max_suppression: 非极大值抑制算法,用于目标检测后处理check_class_names函数
python
def check_class_names(names: list | dict) -> dict[int, str]:
"""
检查类别名称并转换为字典格式(如果需要的话)
参数:
names (list | dict): 类别名称,可以是列表或字典格式。
返回:
(dict): 字典格式的类别名称,整数键对应字符串值。
抛出:
KeyError: 如果类别索引对数据集大小无效。
"""
if isinstance(names, list): # 如果 names 是列表
# 使用 enumerate 将列表转换为字典,索引作为键,值作为值
# 例如:['cat', 'dog'] -> {0: 'cat', 1: 'dog'}
names = dict(enumerate(names)) # 转换为字典
if isinstance(names, dict):
# 转换:1) 将字符串键转换为整数(例如 '0' 转换为 0)
# 2) 将非字符串值转换为字符串(例如 True 转换为 'True')
names = {int(k): str(v) for k, v in names.items()}
n = len(names) # 获取类别总数
# 检查最大键值是否大于等于 n(因为索引从0开始,最大应该是 n-1)
if max(names.keys()) >= n:
raise KeyError(
f"{n}-class dataset requires class indices 0-{n - 1}, but you have invalid class indices "
f"{min(names.keys())}-{max(names.keys())} defined in your dataset YAML."
)
# 检查是否是 ImageNet 数据集的类别代码(以 'n0' 开头)
# 例如:'n01440764' 表示 'tench'(一种鱼)
if isinstance(names[0], str) and names[0].startswith("n0"):
# 加载 ImageNet 的人类可读名称映射
names_map = YAML.load(ROOT / "cfg/datasets/ImageNet.yaml")["map"]
# 将类别代码替换为人类可读的名称
names = {k: names_map[v] for k, v in names.items()}
return names # 返回处理后的类别名称字典default_class_names函数
python
def default_class_names(data: str | Path | None = None) -> dict[int, str]:
"""
将默认类别名称应用于输入的 YAML 文件,或返回数字类别名称
参数:
data (str | Path, optional): 包含类别名称的 YAML 文件路径。
返回:
(dict): 映射类别索引到类别名称的字典。
"""
if data: # 如果提供了 data 参数
try:
# 尝试加载 YAML 文件并获取其中的 names 字段
return YAML.load(check_yaml(data))["names"]
except Exception:
pass # 如果出错,继续执行下面的默认处理
# 如果 data 为空或加载失败,返回默认的类别名称
# 创建 0-998 的默认类别名称:class0, class1, ..., class998
return {i: f"class{i}" for i in range(999)} # 如果上述操作出错则返回默认值AutoBackend核心后端推理类
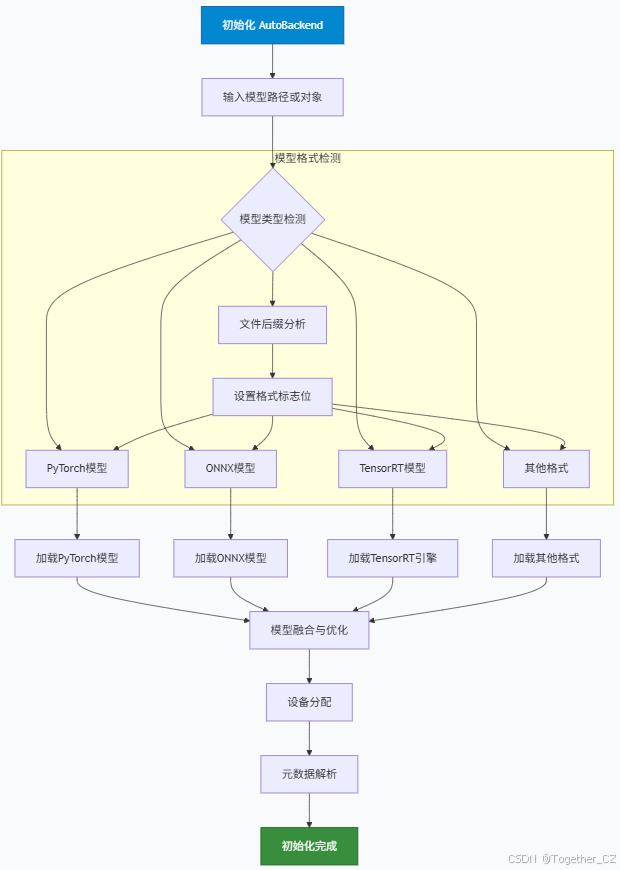
AutoBackend 类是一个高度灵活和强大的模型加载和推理抽象层,其主要特点和功能包括:
- 多格式支持
-
支持超过20种不同的模型格式
-
自动检测模型类型并根据文件后缀选择对应的后端
-
统一的接口,无论模型格式如何,调用方式相同
- 智能设备管理
-
自动处理 CPU/GPU 设备选择
-
根据后端能力自动回退到合适的设备
-
支持特殊硬件(Jetson、Rockchip、Apple Silicon等)
- 性能优化
-
支持 FP16 半精度推理
-
层融合优化(Conv2D + BatchNorm)
-
动态形状支持
-
IO 绑定优化(ONNX Runtime)
-
异步推理(OpenVINO)
- 统一的预处理和后处理
-
自动处理不同后端的输入输出格式
-
统一的张量设备管理
-
自动反归一化处理
-
类别名称管理
- 错误处理和兼容性
-
详细的错误信息和警告
-
版本兼容性检查
-
依赖自动检查
-
模型下载功能
类层次结构图如下所示:
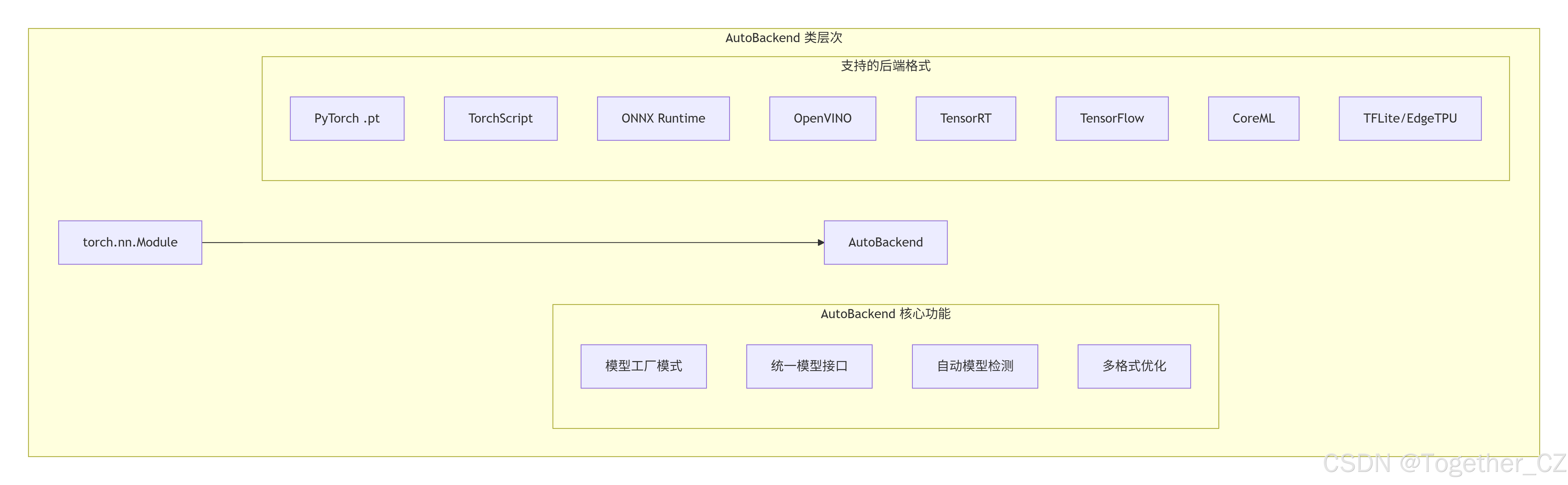
模块依赖关系图
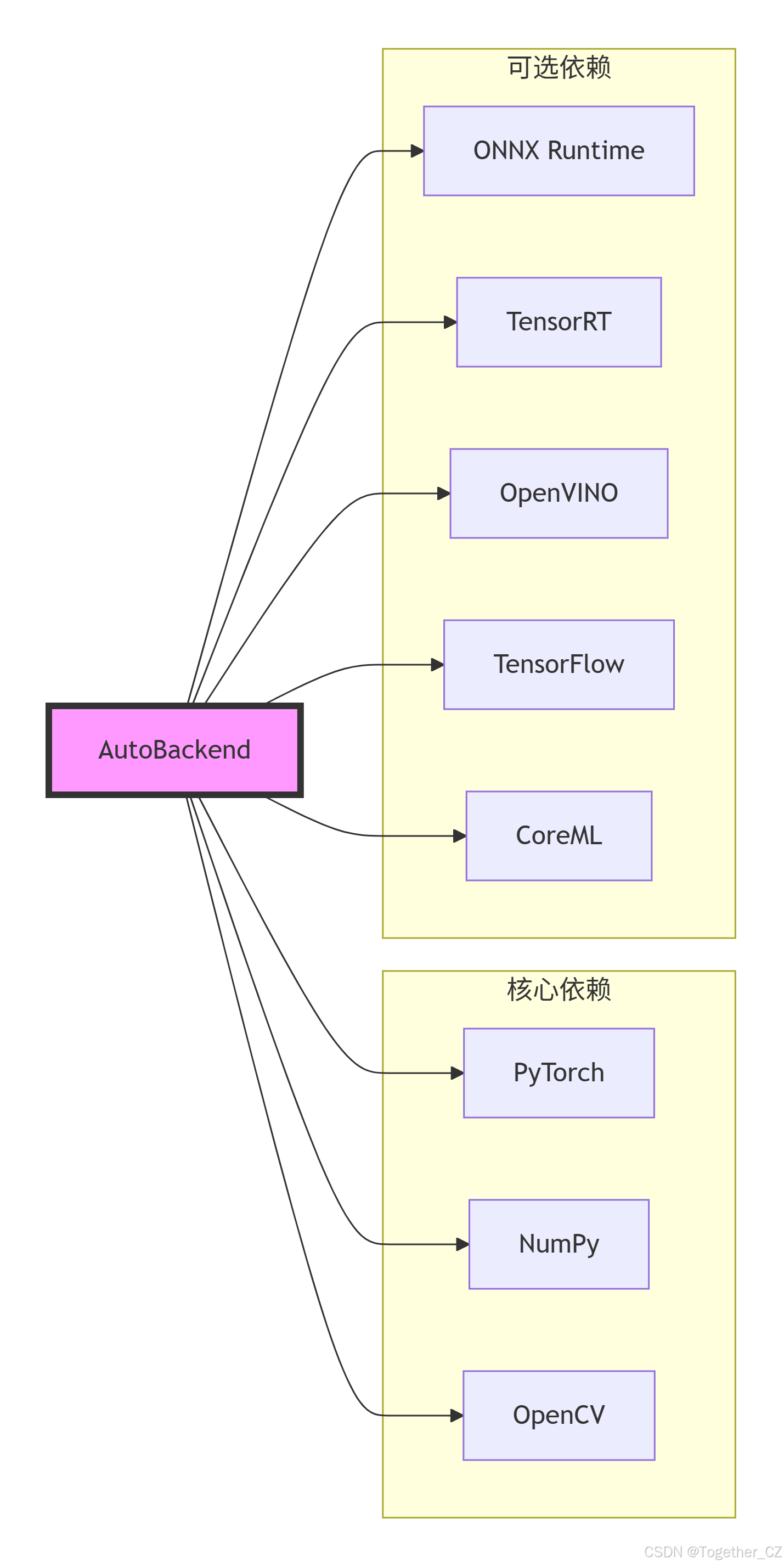
AutoBackend 初始化流程图

前向传播 (forward) 数据流转全景图
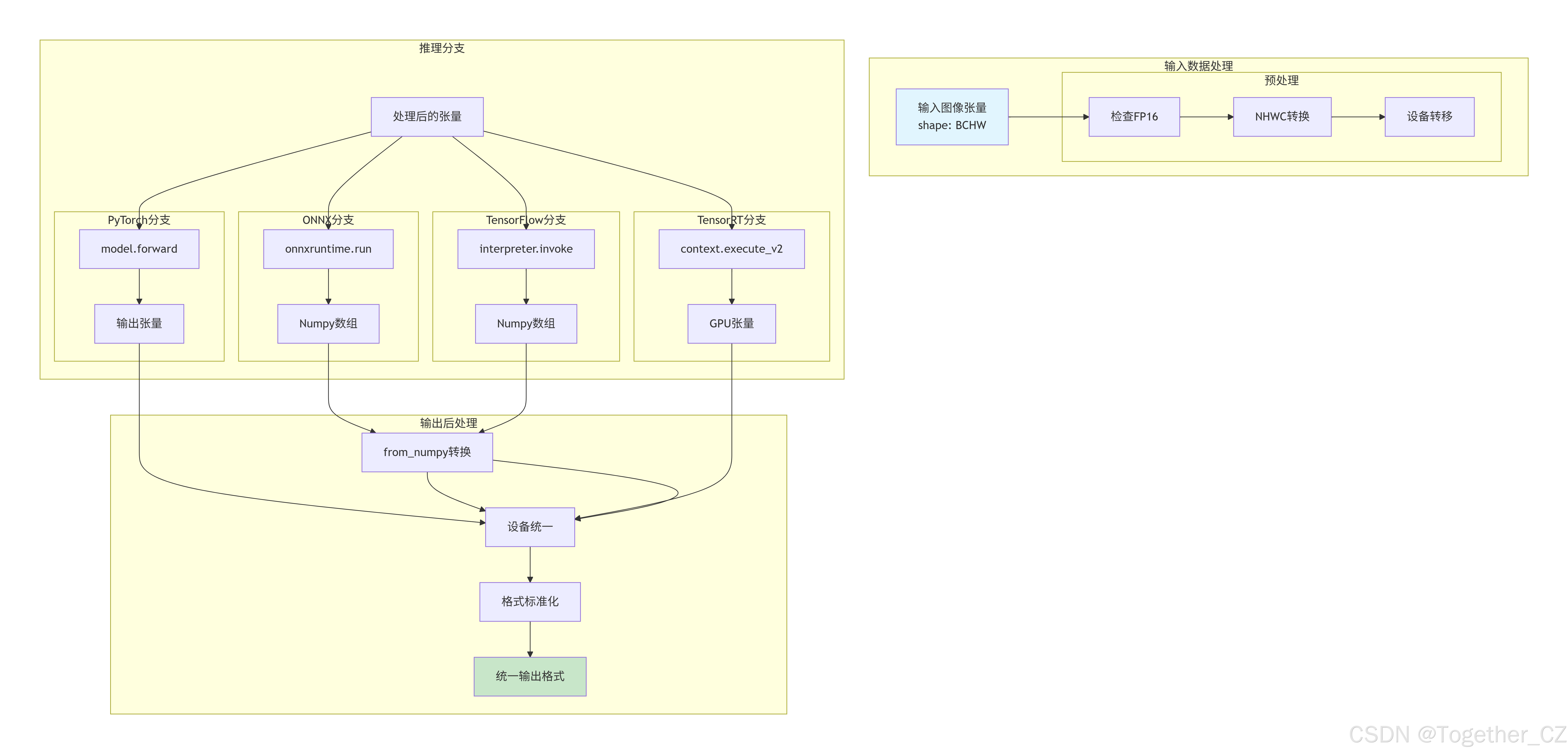
不同后端的输入输出格式差异
python
# 可视化对比不同后端的输入输出格式
后端类型 | 输入格式 | 输出格式 | 是否需要转换
------------|-----------------|-----------------|------------
PyTorch | torch.Tensor | torch.Tensor | 否
TorchScript | torch.Tensor | torch.Tensor | 否
ONNX | numpy.ndarray | numpy.ndarray | 是 → torch.Tensor
TensorRT | torch.Tensor | torch.Tensor | 否
OpenVINO | numpy.ndarray | numpy.ndarray | 是 → torch.Tensor
CoreML | PIL.Image/numpy | dict/numpy | 是 → torch.Tensor
TensorFlow | numpy.ndarray | numpy.ndarray | 是 → torch.Tensor
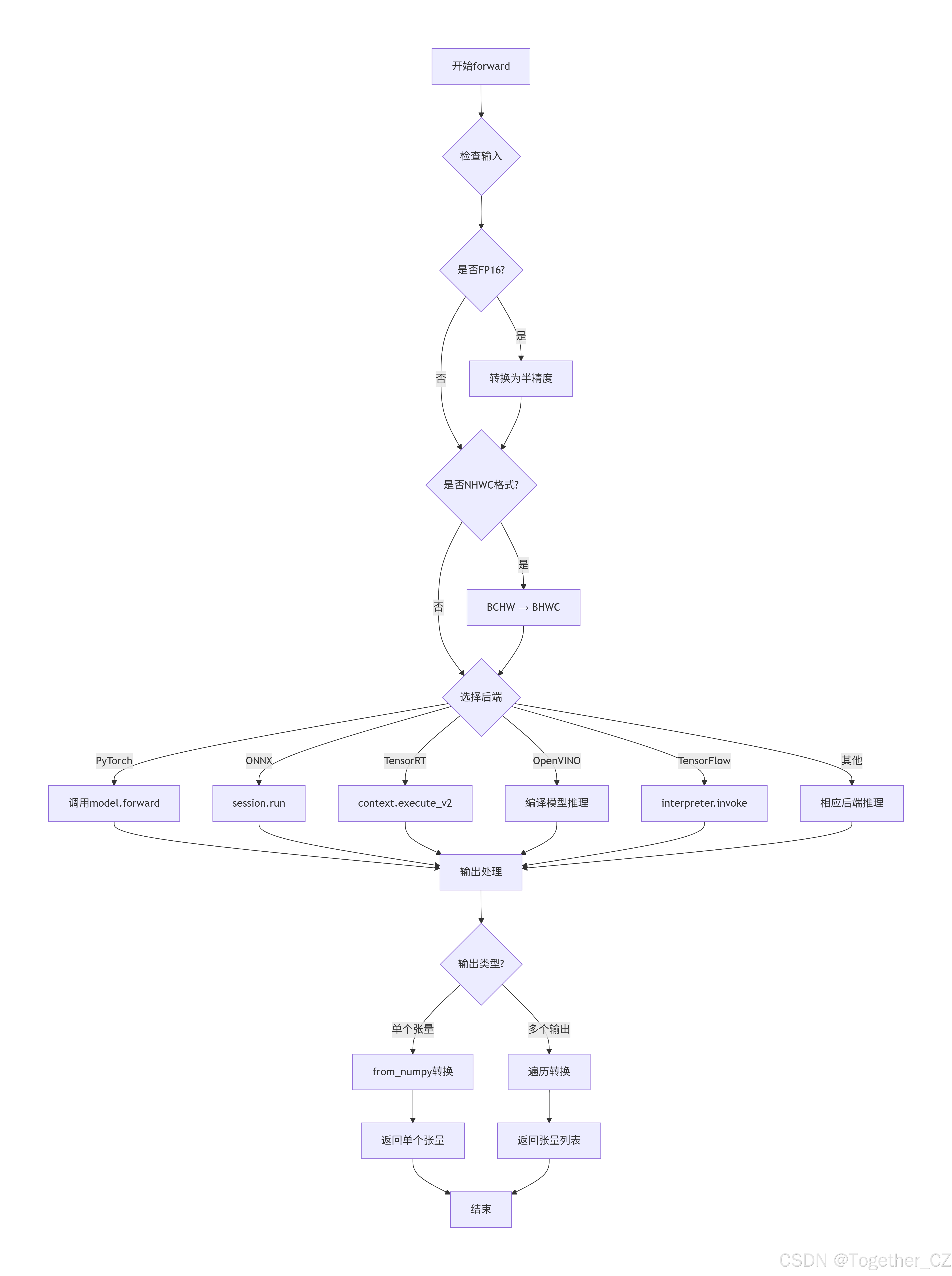
TFLite | numpy.ndarray | numpy.ndarray | 是 → torch.Tensorforward 方法的分支逻辑可视化
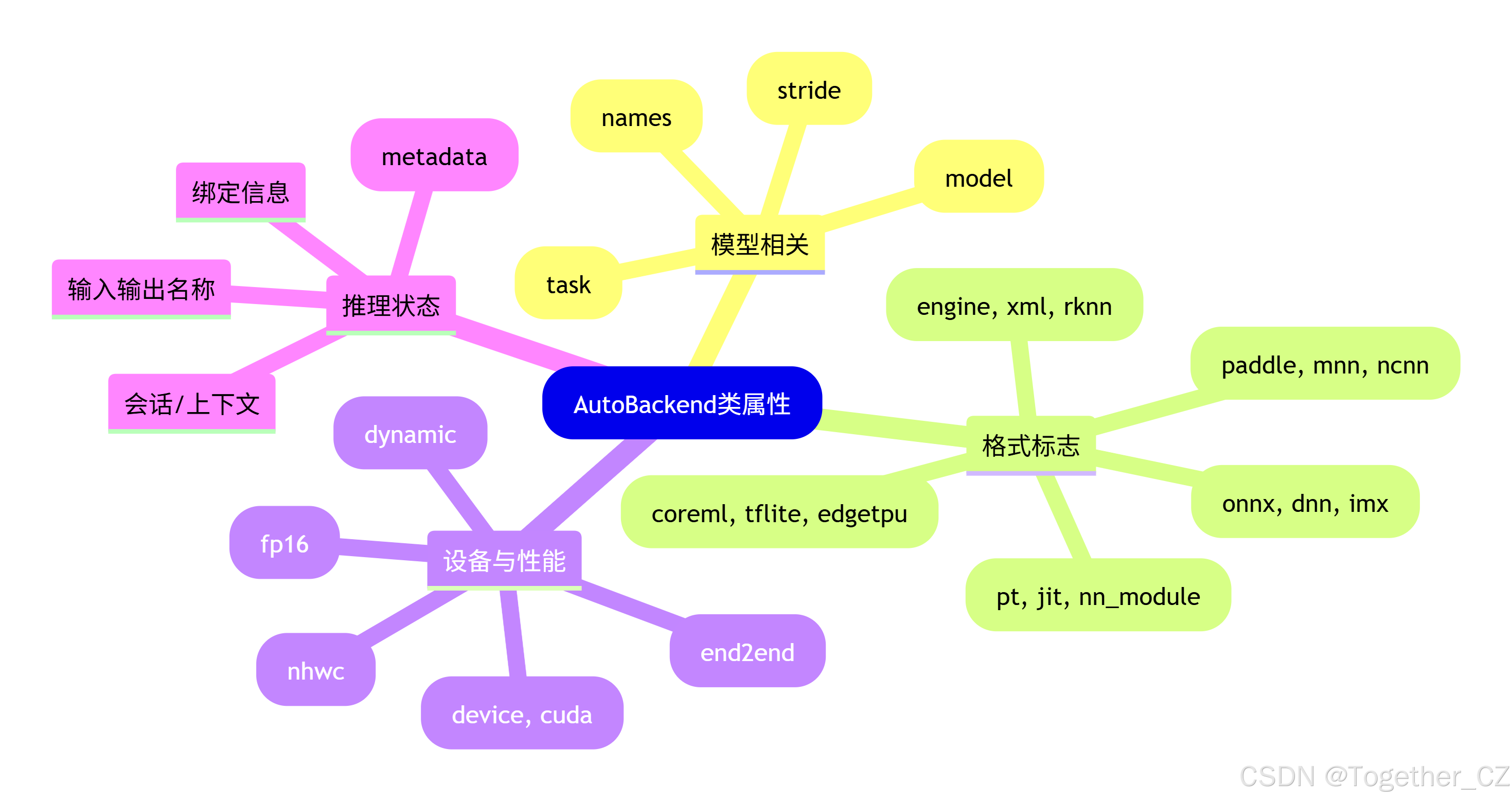
AutoBackend 类属性分类
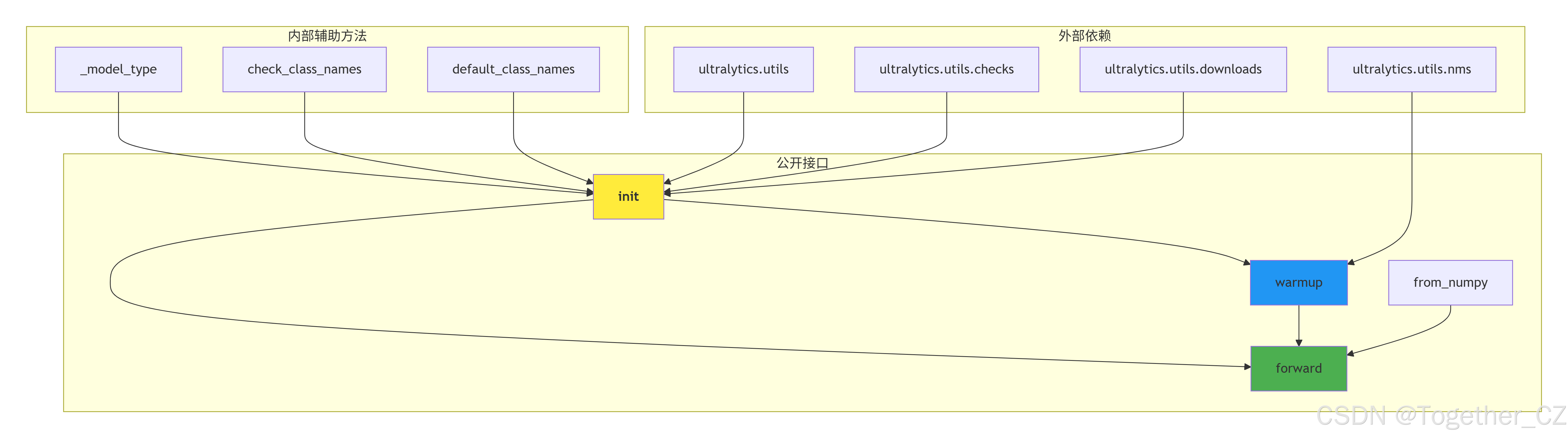
方法调用关系图
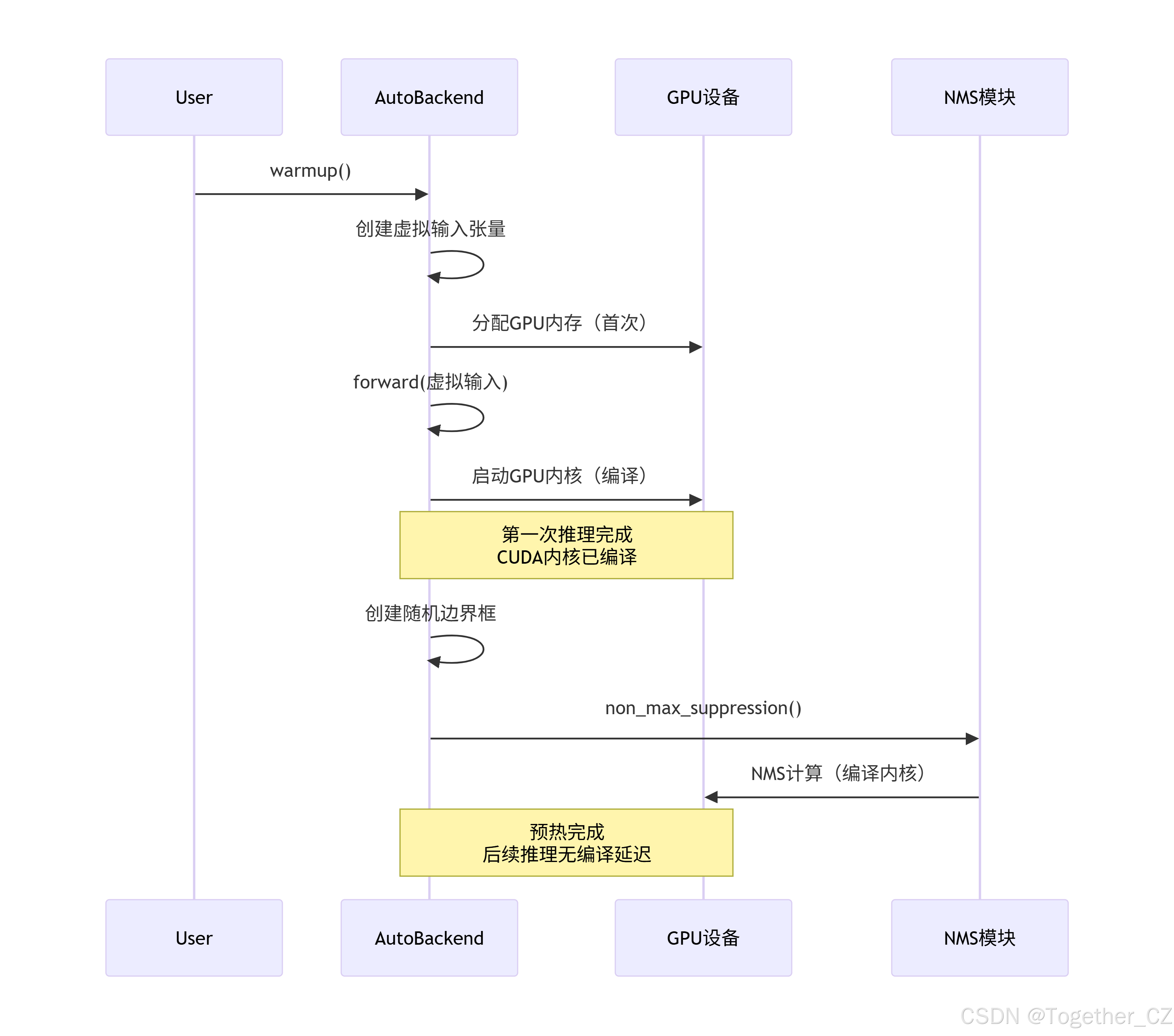
预热机制工作流程
AutoBackend.init 方法
python
class AutoBackend(nn.Module):
"""
用于运行 Ultralytics YOLO 模型推理的动态后端选择处理器。
AutoBackend 类旨在为各种推理引擎提供抽象层。它支持多种格式,
每种格式都有特定的命名约定,如下所示:
支持的格式和命名约定:
| 格式 | 文件后缀 |
| --------------------- | ----------------- |
| PyTorch | *.pt |
| TorchScript | *.torchscript |
| ONNX Runtime | *.onnx |
| ONNX OpenCV DNN | *.onnx (dnn=True) |
| OpenVINO | *openvino_model/ |
| CoreML | *.mlpackage |
| TensorRT | *.engine |
| TensorFlow SavedModel | *_saved_model/ |
| TensorFlow GraphDef | *.pb |
| TensorFlow Lite | *.tflite |
| TensorFlow Edge TPU | *_edgetpu.tflite |
| PaddlePaddle | *_paddle_model/ |
| MNN | *.mnn |
| NCNN | *_ncnn_model/ |
| IMX | *_imx_model/ |
| RKNN | *_rknn_model/ |
| Triton Inference | triton://model |
| ExecuTorch | *.pte |
| Axelera | *_axelera_model/ |
属性:
model (torch.nn.Module): 加载的 YOLO 模型。
device (torch.device): 模型加载的设备(CPU 或 GPU)。
task (str): 模型执行的任务类型(detect, segment, classify, pose)。
names (dict): 模型可以检测的类别名称字典。
stride (int): 模型步长,YOLO 模型通常为 32。
fp16 (bool): 模型是否使用半精度(FP16)推理。
nhwc (bool): 模型是否期望 NHWC 输入格式而不是 NCHW。
pt (bool): 模型是否是 PyTorch 模型。
jit (bool): 模型是否是 TorchScript 模型。
onnx (bool): 模型是否是 ONNX 模型。
xml (bool): 模型是否是 OpenVINO 模型。
engine (bool): 模型是否是 TensorRT 引擎。
coreml (bool): 模型是否是 CoreML 模型。
saved_model (bool): 模型是否是 TensorFlow SavedModel。
pb (bool): 模型是否是 TensorFlow GraphDef。
tflite (bool): 模型是否是 TensorFlow Lite 模型。
edgetpu (bool): 模型是否是 TensorFlow Edge TPU 模型。
tfjs (bool): 模型是否是 TensorFlow.js 模型。
paddle (bool): 模型是否是 PaddlePaddle 模型。
mnn (bool): 模型是否是 MNN 模型。
ncnn (bool): 模型是否是 NCNN 模型。
imx (bool): 模型是否是 IMX 模型。
rknn (bool): 模型是否是 RKNN 模型。
triton (bool): 模型是否是 Triton Inference Server 模型。
pte (bool): 模型是否是 PyTorch ExecuTorch 模型。
axelera (bool): 模型是否是 Axelera 模型。
方法:
forward: 在输入图像上运行推理。
from_numpy: 将 NumPy 数组转换为模型设备上的张量。
warmup: 使用虚拟输入预热模型。
_model_type: 从文件路径确定模型类型。
示例:
>>> model = AutoBackend(model="yolo11n.pt", device="cuda")
>>> results = model(img)
"""
@torch.no_grad() # 禁用梯度计算,因为推理阶段不需要梯度
def __init__(
self,
model: str | torch.nn.Module = "yolo11n.pt", # 模型路径或 PyTorch 模块
device: torch.device = torch.device("cpu"), # 运行设备,默认 CPU
dnn: bool = False, # 是否使用 OpenCV DNN 进行 ONNX 推理
data: str | Path | None = None, # 包含类别名称的 YAML 文件路径
fp16: bool = False, # 是否启用半精度推理
fuse: bool = True, # 是否融合 Conv2D + BatchNorm 层以优化
verbose: bool = True, # 是否启用详细日志
):
"""初始化 AutoBackend 进行推理。
参数:
model (str | torch.nn.Module): 模型权重文件路径或模块实例。
device (torch.device): 运行模型的设备。
dnn (bool): 使用 OpenCV DNN 模块进行 ONNX 推理。
data (str | Path, optional): 包含类别名称的额外 data.yaml 文件路径。
fp16 (bool): 启用半精度推理。仅在特定后端支持。
fuse (bool): 融合 Conv2D + BatchNorm 层以优化。
verbose (bool): 启用详细日志。
"""
super().__init__() # 调用父类 nn.Module 的构造函数
nn_module = isinstance(model, torch.nn.Module) # 检查 model 是否是 PyTorch 模块
# 调用 _model_type 方法确定模型类型,返回一系列布尔值表示不同格式
(
pt, # PyTorch
jit, # TorchScript
onnx, # ONNX
xml, # OpenVINO
engine, # TensorRT
coreml, # CoreML
saved_model, # TensorFlow SavedModel
pb, # TensorFlow GraphDef
tflite, # TensorFlow Lite
edgetpu, # TensorFlow Edge TPU
tfjs, # TensorFlow.js
paddle, # PaddlePaddle
mnn, # MNN
ncnn, # NCNN
imx, # IMX
rknn, # RKNN
pte, # ExecuTorch
axelera, # Axelera
triton, # Triton
) = self._model_type("" if nn_module else model) # 如果是 PyTorch 模块,传入空字符串
# 设置 fp16 标志:只有特定后端支持半精度
fp16 &= pt or jit or onnx or xml or engine or nn_module or triton # FP16
# 设置 nhwc 标志:某些格式使用 BHWC 格式(与 PyTorch 的 BCHW 相反)
nhwc = coreml or saved_model or pb or tflite or edgetpu or rknn # BHWC 格式(相对于 torch 的 BCHW)
stride, ch = 32, 3 # 默认步长为 32,默认通道数为 3
end2end, dynamic = False, False # 初始化 end2end 和 dynamic 标志
metadata, task = None, None # 初始化元数据和任务类型
# 设置设备
# 检查是否使用 CUDA:设备是 torch.device 类型、CUDA 可用且不是 CPU
cuda = isinstance(device, torch.device) and torch.cuda.is_available() and device.type != "cpu" # 使用 CUDA
# 如果不是支持 GPU 数据加载器的格式,则回退到 CPU
if cuda and not any([nn_module, pt, jit, engine, onnx, paddle]): # GPU 数据加载器格式
device = torch.device("cpu") # 回退到 CPU
cuda = False # 更新 CUDA 标志
# 如果不是本地文件,则尝试下载
w = attempt_download_asset(model) if pt else model # 权重路径
# PyTorch(内存中或文件)
if nn_module or pt: # 如果是 PyTorch 模块或 .pt 文件
if nn_module: # 如果是 PyTorch 模块
pt = True # 设置 pt 标志为 True
if fuse: # 如果需要融合层
if IS_JETSON and is_jetson(jetpack=5): # Jetson Jetpack5 需要在融合前将模型移到设备上
model = model.to(device) # 将模型移到指定设备
model = model.fuse(verbose=verbose) # 融合 Conv2D + BatchNorm 层
model = model.to(device) # 将模型移到指定设备
else: # 如果是 .pt 文件
from ultralytics.nn.tasks import load_checkpoint # 导入加载检查点函数
# 加载模型和检查点
model, _ = load_checkpoint(model, device=device, fuse=fuse) # 加载模型,检查点
# 通用 PyTorch 模型处理
if hasattr(model, "kpt_shape"): # 检查是否有关键点形状属性(姿态估计任务)
kpt_shape = model.kpt_shape # 获取关键点形状(仅姿态估计)
# 获取模型步长:最大步长至少为 32
stride = max(int(model.stride.max()), 32) # 模型步长
# 获取类别名称:如果模型有 module 属性(DataParallel/DistributedDataParallel),则使用 model.module.names
names = model.module.names if hasattr(model, "module") else model.names # 获取类别名称
# 根据 fp16 标志设置模型精度
model.half() if fp16 else model.float() # 如果启用 FP16 则转换为半精度,否则保持单精度
# 获取输入通道数,默认为 3(RGB)
ch = model.yaml.get("channels", 3) # 获取通道数,默认为 3
# 冻结所有参数(推理阶段不需要梯度)
for p in model.parameters():
p.requires_grad = False # 禁用梯度计算
self.model = model # 显式赋值给 self.model,便于后续调用 to(), cpu(), cuda(), half()
# 检查是否是端到端模型(包含 NMS)
end2end = getattr(model, "end2end", False)
# TorchScript
elif jit: # 如果是 TorchScript 格式(*.torchscript)
import torchvision # 导入 torchvision,某些 TorchScript 模型需要
LOGGER.info(f"Loading {w} for TorchScript inference...") # 记录加载信息
extra_files = {"config.txt": ""} # 模型元数据,额外文件
# 加载 TorchScript 模型
model = torch.jit.load(w, _extra_files=extra_files, map_location=device)
# 根据 fp16 标志设置模型精度
model.half() if fp16 else model.float()
# 如果 extra_files 中有配置信息,加载元数据字典
if extra_files["config.txt"]: # 加载元数据字典
# 使用 object_hook 将 JSON 对象转换为字典
metadata = json.loads(extra_files["config.txt"], object_hook=lambda x: dict(x.items()))
# ONNX OpenCV DNN
elif dnn: # 使用 OpenCV DNN 进行 ONNX 推理
LOGGER.info(f"Loading {w} for ONNX OpenCV DNN inference...") # 记录加载信息
check_requirements("opencv-python>=4.5.4") # 检查 OpenCV 依赖
# 使用 OpenCV DNN 读取 ONNX 模型
net = cv2.dnn.readNetFromONNX(w)
# ONNX Runtime 和 IMX
elif onnx or imx: # ONNX Runtime 或 IMX 格式
LOGGER.info(f"Loading {w} for ONNX Runtime inference...") # 记录加载信息
# 检查 ONNX 和 ONNX Runtime 依赖
check_requirements(("onnx", "onnxruntime-gpu" if cuda else "onnxruntime"))
import onnxruntime # 导入 ONNX Runtime
# 选择执行提供者:优先顺序为 CUDA > CoreML (mps) > CPU
available = onnxruntime.get_available_providers() # 获取可用的执行提供者
if cuda and "CUDAExecutionProvider" in available: # 如果请求 CUDA 且可用
# 使用 CUDA 执行提供者,指定设备 ID
providers = [("CUDAExecutionProvider", {"device_id": device.index}), "CPUExecutionProvider"]
elif device.type == "mps" and "CoreMLExecutionProvider" in available: # 如果是 Apple M 系列芯片
# 使用 CoreML 执行提供者
providers = ["CoreMLExecutionProvider", "CPUExecutionProvider"]
else: # 其他情况使用 CPU
providers = ["CPUExecutionProvider"]
if cuda: # 如果请求了 CUDA 但不可用
LOGGER.warning("CUDA requested but CUDAExecutionProvider not available. Using CPU...")
device, cuda = torch.device("cpu"), False # 回退到 CPU
# 记录使用的 ONNX Runtime 版本和执行提供者
LOGGER.info(
f"Using ONNX Runtime {onnxruntime.__version__} with {providers[0] if isinstance(providers[0], str) else providers[0][0]}"
)
if onnx: # 普通 ONNX 模型
# 创建推理会话
session = onnxruntime.InferenceSession(w, providers=providers)
else: # IMX 格式
# 检查 IMX 特定依赖
check_requirements(("model-compression-toolkit>=2.4.1", "edge-mdt-cl<1.1.0", "onnxruntime-extensions"))
# IMX 格式通常是一个目录,需要找到其中的 .onnx 文件
w = next(Path(w).glob("*.onnx"))
LOGGER.info(f"Loading {w} for ONNX IMX inference...") # 记录加载信息
# 导入 IMX 相关模块
import mct_quantizers as mctq
from edgemdt_cl.pytorch.nms import nms_ort # 注册自定义 NMS 操作
# 获取 ONNX Runtime 会话选项
session_options = mctq.get_ort_session_options()
session_options.enable_mem_reuse = False # 修复来自 onnxruntime 的形状不匹配问题
# 创建推理会话(IMX 只使用 CPU)
session = onnxruntime.InferenceSession(w, session_options, providers=["CPUExecutionProvider"])
# 获取输出名称
output_names = [x.name for x in session.get_outputs()]
# 获取模型元数据
metadata = session.get_modelmeta().custom_metadata_map
# 检查是否是动态模型(输入/输出形状可变)
dynamic = isinstance(session.get_outputs()[0].shape[0], str) # 如果第一个维度是字符串,则是动态模型
# 检查输入是否是 FP16 精度
fp16 = "float16" in session.get_inputs()[0].type
# 为优化推理设置 IO 绑定(仅限 CUDA,CoreML 不支持)
use_io_binding = not dynamic and cuda
if use_io_binding: # 如果使用 IO 绑定
io = session.io_binding() # 创建 IO 绑定对象
bindings = [] # 初始化绑定列表
# 为每个输出设置绑定
for output in session.get_outputs():
out_fp16 = "float16" in output.type # 检查输出是否是 FP16
# 创建空的输出张量
y_tensor = torch.empty(output.shape, dtype=torch.float16 if out_fp16 else torch.float32).to(device)
# 绑定输出
io.bind_output(
name=output.name, # 输出名称
device_type=device.type, # 设备类型(cuda/cpu)
device_id=device.index if cuda else 0, # 设备 ID
element_type=np.float16 if out_fp16 else np.float32, # 数据类型
shape=tuple(y_tensor.shape), # 形状
buffer_ptr=y_tensor.data_ptr(), # 数据指针
)
bindings.append(y_tensor) # 添加到绑定列表
# OpenVINO
elif xml: # OpenVINO 格式(*.xml)
LOGGER.info(f"Loading {w} for OpenVINO inference...") # 记录加载信息
check_requirements("openvino>=2024.0.0") # 检查 OpenVINO 依赖
import openvino as ov # 导入 OpenVINO
core = ov.Core() # 创建 OpenVINO 核心对象
device_name = "AUTO" # 默认设备名称为 AUTO(自动选择)
# 处理 Intel 设备特定设置
if isinstance(device, str) and device.startswith("intel"):
# 提取设备名称,例如 "intel:gpu" -> "GPU"
device_name = device.split(":")[1].upper() # Intel OpenVINO 设备
device = torch.device("cpu") # OpenVINO 使用自己的设备管理,PyTorch 设备设为 CPU
# 检查设备是否可用
if device_name not in core.available_devices:
LOGGER.warning(f"OpenVINO device '{device_name}' not available. Using 'AUTO' instead.")
device_name = "AUTO" # 如果不可用,回退到 AUTO
w = Path(w) # 转换为 Path 对象
# 如果不是 *.xml 文件,则在目录中查找
if not w.is_file(): # 如果不是文件
w = next(w.glob("*.xml")) # 从 *_openvino_model 目录获取 *.xml 文件
# 读取模型(包含权重文件)
ov_model = core.read_model(model=str(w), weights=w.with_suffix(".bin"))
# 如果模型参数没有布局,设置为 NCHW
if ov_model.get_parameters()[0].get_layout().empty:
ov_model.get_parameters()[0].set_layout(ov.Layout("NCHW"))
# 尝试加载元数据
metadata = w.parent / "metadata.yaml" # 元数据文件路径
if metadata.exists(): # 如果元数据文件存在
metadata = YAML.load(metadata) # 加载 YAML 文件
batch = metadata["batch"] # 获取批次大小
dynamic = metadata.get("args", {}).get("dynamic", dynamic) # 获取动态标志
# OpenVINO 推理模式:LATENCY(延迟)、THROUGHPUT(吞吐量)、CUMULATIVE_THROUGHPUT(累积吞吐量)
# 批次大于1且是动态模型时使用 CUMULATIVE_THROUGHPUT,否则使用 LATENCY
inference_mode = "CUMULATIVE_THROUGHPUT" if batch > 1 and dynamic else "LATENCY"
# 编译模型
ov_compiled_model = core.compile_model(
ov_model,
device_name=device_name,
config={"PERFORMANCE_HINT": inference_mode}, # 设置性能提示
)
# 记录使用的设备和模式
LOGGER.info(
f"Using OpenVINO {inference_mode} mode for batch={batch} inference on {', '.join(ov_compiled_model.get_property('EXECUTION_DEVICES'))}..."
)
# 获取输入名称
input_name = ov_compiled_model.input().get_any_name()
# TensorRT
elif engine: # TensorRT 引擎格式(*.engine)
LOGGER.info(f"Loading {w} for TensorRT inference...") # 记录加载信息
# Jetson 特定修复
if IS_JETSON and check_version(PYTHON_VERSION, "<=3.8.10"):
# 修复错误:对于 JetPack 4 和 Python <= 3.8.10 的 JetPack 5,`np.bool` 是 `bool` 的弃用别名
check_requirements("numpy==1.23.5")
try: # 尝试导入 TensorRT
import tensorrt as trt
except ImportError:
if LINUX: # Linux 系统
check_requirements("tensorrt>7.0.0,!=10.1.0") # 检查 TensorRT 依赖
import tensorrt as trt
# 检查 TensorRT 版本
check_version(trt.__version__, ">=7.0.0", hard=True) # 必须 >=7.0.0
check_version(trt.__version__, "!=10.1.0", msg="https://github.com/ultralytics/ultralytics/pull/14239") # 避免 10.1.0 版本
# 如果设备是 CPU,但 TensorRT 需要 GPU
if device.type == "cpu":
device = torch.device("cuda:0") # TensorRT 需要 GPU,切换到第一个 CUDA 设备
# 定义 Binding 命名元组,用于存储绑定信息
Binding = namedtuple("Binding", ("name", "dtype", "shape", "data", "ptr"))
logger = trt.Logger(trt.Logger.INFO) # 创建 TensorRT 日志记录器
# 读取 TensorRT 引擎文件
with open(w, "rb") as f, trt.Runtime(logger) as runtime:
try:
# 读取元数据长度(前4字节)
meta_len = int.from_bytes(f.read(4), byteorder="little") # 读取元数据长度
# 读取元数据(JSON格式)
metadata = json.loads(f.read(meta_len).decode("utf-8")) # 读取元数据
# 检查是否有 DLA(深度学习加速器)设置
dla = metadata.get("dla", None)
if dla is not None:
runtime.DLA_core = int(dla) # 设置 DLA 核心
except UnicodeDecodeError:
f.seek(0) # 引擎文件可能没有嵌入的 Ultralytics 元数据,回到文件开头
# 反序列化 CUDA 引擎
model = runtime.deserialize_cuda_engine(f.read()) # 读取引擎
# 创建模型执行上下文
try:
context = model.create_execution_context()
except Exception as e: # 模型为 None 时
LOGGER.error(f"TensorRT model exported with a different version than {trt.__version__}\n")
raise e # 重新抛出异常
bindings = OrderedDict() # 有序字典存储绑定信息
output_names = [] # 输出名称列表
fp16 = False # 默认 FP16 标志为 False,后续会更新
dynamic = False # 动态模型标志
is_trt10 = not hasattr(model, "num_bindings") # 检查是否是 TRT10+ API(新版本)
# 遍历所有输入/输出张量
num = range(model.num_io_tensors) if is_trt10 else range(model.num_bindings)
for i in num:
# 使用 TRT10+ API 或旧 API 获取张量信息
if is_trt10: # TRT10+ 新 API
name = model.get_tensor_name(i) # 获取张量名称
dtype = trt.nptype(model.get_tensor_dtype(name)) # 获取数据类型
is_input = model.get_tensor_mode(name) == trt.TensorIOMode.INPUT # 是否是输入
shape = tuple(model.get_tensor_shape(name)) # 获取形状
profile_shape = tuple(model.get_tensor_profile_shape(name, 0)[2]) if is_input else None # 配置文件形状(仅输入)
else: # 旧 API
name = model.get_binding_name(i) # 获取绑定名称
dtype = trt.nptype(model.get_binding_dtype(i)) # 获取数据类型
is_input = model.binding_is_input(i) # 是否是输入
shape = tuple(model.get_binding_shape(i)) # 获取形状
profile_shape = tuple(model.get_profile_shape(0, i)[1]) if is_input else None # 配置文件形状(仅输入)
# 处理输入/输出张量
if is_input: # 如果是输入张量
if -1 in shape: # 如果形状中有 -1,表示是动态形状
dynamic = True # 设置动态标志
if is_trt10:
context.set_input_shape(name, profile_shape) # TRT10+ 设置输入形状
else:
context.set_binding_shape(i, profile_shape) # 旧 API 设置绑定形状
if dtype == np.float16: # 如果数据类型是 FP16
fp16 = True # 设置 FP16 标志
else: # 如果是输出张量
output_names.append(name) # 添加到输出名称列表
# 获取实际形状(可能是动态设置的)
shape = tuple(context.get_tensor_shape(name)) if is_trt10 else tuple(context.get_binding_shape(i))
# 创建空的张量
im = torch.from_numpy(np.empty(shape, dtype=dtype)).to(device)
# 存储绑定信息
bindings[name] = Binding(name, dtype, shape, im, int(im.data_ptr()))
# 创建绑定地址字典(名称->指针)
binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
# CoreML
elif coreml: # CoreML 格式(*.mlpackage)
# 检查依赖:coremltools 和特定版本的 numpy
check_requirements(
["coremltools>=9.0", "numpy>=1.14.5,<=2.3.5"]
) # 最新的 numpy 2.4.0rc1 会破坏 coremltools 导出
LOGGER.info(f"Loading {w} for CoreML inference...") # 记录加载信息
import coremltools as ct # 导入 CoreML 工具
model = ct.models.MLModel(w) # 加载 CoreML 模型
dynamic = model.get_spec().description.input[0].type.HasField("multiArrayType") # 检查是否是动态输入
metadata = dict(model.user_defined_metadata) # 获取用户定义的元数据
# TensorFlow SavedModel
elif saved_model: # TensorFlow SavedModel 格式(目录)
LOGGER.info(f"Loading {w} for TensorFlow SavedModel inference...") # 记录加载信息
import tensorflow as tf # 导入 TensorFlow
model = tf.saved_model.load(w) # 加载 SavedModel
metadata = Path(w) / "metadata.yaml" # 元数据文件路径
# TensorFlow GraphDef
elif pb: # TensorFlow GraphDef 格式(*.pb)
LOGGER.info(f"Loading {w} for TensorFlow GraphDef inference...") # 记录加载信息
import tensorflow as tf # 导入 TensorFlow
from ultralytics.utils.export.tensorflow import gd_outputs # 导入 GraphDef 输出处理函数
def wrap_frozen_graph(gd, inputs, outputs):
"""包装冻结的图以进行部署。"""
# 包装函数以导入 GraphDef
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # 包装
ge = x.graph.as_graph_element # 获取图元素
# 修剪图以获取指定的输入和输出
return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
gd = tf.Graph().as_graph_def() # 创建空的 GraphDef
# 读取 GraphDef 文件
with open(w, "rb") as f:
gd.ParseFromString(f.read()) # 解析 GraphDef
# 包装冻结的图
frozen_func = wrap_frozen_graph(gd, inputs="x:0", outputs=gd_outputs(gd))
# 尝试在 SavedModel 旁边查找元数据
try:
# 查找与 GraphDef 文件同名的 SavedModel 目录中的元数据文件
metadata = next(Path(w).resolve().parent.rglob(f"{Path(w).stem}_saved_model*/metadata.yaml"))
except StopIteration:
pass # 如果找不到,保持 metadata 为 None
# TFLite 或 TFLite Edge TPU
elif tflite or edgetpu: # TensorFlow Lite 或 Edge TPU 格式
try: # 尝试导入 tflite_runtime(适用于嵌入式设备)
from tflite_runtime.interpreter import Interpreter, load_delegate
except ImportError: # 如果失败,使用完整的 TensorFlow
import tensorflow as tf
Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate
if edgetpu: # Edge TPU 格式
# 处理设备字符串:如果以 "tpu" 开头,去掉前缀
device = device[3:] if str(device).startswith("tpu") else ":0"
LOGGER.info(f"Loading {w} on device {device[1:]} for TensorFlow Lite Edge TPU inference...")
# 根据操作系统选择 Edge TPU 委托库
delegate = {"Linux": "libedgetpu.so.1", "Darwin": "libedgetpu.1.dylib", "Windows": "edgetpu.dll"}[
platform.system()
]
# 创建带 Edge TPU 委托的解释器
interpreter = Interpreter(
model_path=w,
experimental_delegates=[load_delegate(delegate, options={"device": device})],
)
device = "cpu" # 必须设为 CPU,否则 PyTorch 会尝试使用错误的设备
else: # 普通 TFLite
LOGGER.info(f"Loading {w} for TensorFlow Lite inference...")
interpreter = Interpreter(model_path=w) # 加载 TFLite 模型
interpreter.allocate_tensors() # 分配张量内存
input_details = interpreter.get_input_details() # 获取输入详情
output_details = interpreter.get_output_details() # 获取输出详情
# 尝试加载元数据
try:
# TFLite 模型通常是 ZIP 文件,包含元数据
with zipfile.ZipFile(w, "r") as zf:
name = zf.namelist()[0] # 获取第一个文件名
contents = zf.read(name).decode("utf-8") # 读取内容
if name == "metadata.json": # Ultralytics 自定义元数据(Python>=3.12)
metadata = json.loads(contents) # 解析 JSON
else:
metadata = ast.literal_eval(contents) # 默认的 tflite-support 元数据(Python<=3.11)
except (zipfile.BadZipFile, SyntaxError, ValueError, json.JSONDecodeError):
pass # 如果解析失败,保持 metadata 为 None
# TensorFlow.js
elif tfjs: # TensorFlow.js 格式(目前不支持)
raise NotImplementedError("Ultralytics TF.js inference is not currently supported.")
# PaddlePaddle
elif paddle: # PaddlePaddle 格式
LOGGER.info(f"Loading {w} for PaddlePaddle inference...") # 记录加载信息
# 根据是否使用 CUDA 选择不同的 PaddlePaddle 版本
check_requirements(
"paddlepaddle-gpu>=3.0.0,!=3.3.0" # GPU 版本,排除 3.3.0(有问题)
if torch.cuda.is_available()
else "paddlepaddle==3.0.0" # ARM64 平台固定 3.0.0 版本
if ARM64
else "paddlepaddle>=3.0.0,!=3.3.0" # CPU 版本,排除 3.3.0
)
import paddle.inference as pdi # 导入 PaddlePaddle 推理模块
w = Path(w) # 转换为 Path 对象
model_file, params_file = None, None # 初始化模型文件和参数文件
# 如果是目录,查找其中的文件
if w.is_dir():
model_file = next(w.rglob("*.json"), None) # 查找 JSON 模型文件
params_file = next(w.rglob("*.pdiparams"), None) # 查找参数文件
elif w.suffix == ".pdiparams": # 如果是参数文件
model_file = w.with_name("model.json") # 对应的模型文件
params_file = w # 参数文件
# 检查文件是否存在
if not (model_file and params_file and model_file.is_file() and params_file.is_file()):
raise FileNotFoundError(f"Paddle model not found in {w}. Both .json and .pdiparams files are required.")
# 创建配置
config = pdi.Config(str(model_file), str(params_file))
if cuda: # 如果使用 CUDA
config.enable_use_gpu(memory_pool_init_size_mb=2048, device_id=0) # 启用 GPU
predictor = pdi.create_predictor(config) # 创建预测器
input_handle = predictor.get_input_handle(predictor.get_input_names()[0]) # 获取输入句柄
output_names = predictor.get_output_names() # 获取输出名称
metadata = w / "metadata.yaml" # 元数据文件路径
# MNN
elif mnn: # MNN 格式(阿里巴巴的移动端推理框架)
LOGGER.info(f"Loading {w} for MNN inference...") # 记录加载信息
check_requirements("MNN") # 检查 MNN 依赖
import os
import MNN # 导入 MNN
# 配置 MNN 运行时:低精度、CPU 后端、线程数设置为 CPU 核心数的一半
config = {"precision": "low", "backend": "CPU", "numThread": (os.cpu_count() + 1) // 2}
rt = MNN.nn.create_runtime_manager((config,)) # 创建运行时管理器
net = MNN.nn.load_module_from_file(w, [], [], runtime_manager=rt, rearrange=True) # 加载模型
# 定义 PyTorch 张量到 MNN 张量的转换函数
def torch_to_mnn(x):
return MNN.expr.const(x.data_ptr(), x.shape)
# 从模型信息中获取元数据
metadata = json.loads(net.get_info()["bizCode"])
# NCNN
elif ncnn: # NCNN 格式(腾讯的移动端推理框架)
LOGGER.info(f"Loading {w} for NCNN inference...") # 记录加载信息
if ARM64: # ARM64 架构不支持
raise NotImplementedError(
"NCNN inference is not supported on ARM64"
) # https://github.com/Tencent/ncnn/issues/6509
check_requirements("ncnn", cmds="--no-deps") # 检查 NCNN 依赖
import ncnn as pyncnn # 导入 NCNN
net = pyncnn.Net() # 创建 NCNN 网络
# 设置 Vulkan 计算(GPU 加速)
if isinstance(cuda, torch.device):
net.opt.use_vulkan_compute = cuda # 根据 CUDA 设备设置
elif isinstance(device, str) and device.startswith("vulkan"): # 如果是 Vulkan 设备
net.opt.use_vulkan_compute = True # 启用 Vulkan
net.set_vulkan_device(int(device.split(":")[1])) # 设置 Vulkan 设备 ID
device = torch.device("cpu") # PyTorch 设备设为 CPU
w = Path(w) # 转换为 Path 对象
# 如果不是 *.param 文件,则在目录中查找
if not w.is_file(): # 如果不是文件
w = next(w.glob("*.param")) # 从 *_ncnn_model 目录获取 *.param 文件
net.load_param(str(w)) # 加载网络参数
net.load_model(str(w.with_suffix(".bin"))) # 加载模型权重(.bin 文件)
metadata = w.parent / "metadata.yaml" # 元数据文件路径
# NVIDIA Triton Inference Server
elif triton: # Triton 推理服务器
check_requirements("tritonclient[all]") # 检查 Triton 客户端依赖
from ultralytics.utils.triton import TritonRemoteModel # 导入 Triton 远程模型
model = TritonRemoteModel(w) # 创建 Triton 远程模型
metadata = model.metadata # 获取元数据
# RKNN
elif rknn: # Rockchip NPU 格式
if not is_rockchip(): # 检查是否是 Rockchip 设备
raise OSError("RKNN inference is only supported on Rockchip devices.")
LOGGER.info(f"Loading {w} for RKNN inference...") # 记录加载信息
check_requirements("rknn-toolkit-lite2") # 检查 RKNN 依赖
from rknnlite.api import RKNNLite # 导入 RKNN Lite API
w = Path(w) # 转换为 Path 对象
# 如果不是 *.rknn 文件,则在目录中查找
if not w.is_file(): # 如果不是文件
w = next(w.rglob("*.rknn")) # 从 *_rknn_model 目录获取 *.rknn 文件
rknn_model = RKNNLite() # 创建 RKNN Lite 实例
rknn_model.load_rknn(str(w)) # 加载 RKNN 模型
rknn_model.init_runtime() # 初始化运行时
metadata = w.parent / "metadata.yaml" # 元数据文件路径
# Axelera
elif axelera: # Axelera AI 芯片格式
import os
# 检查 Axelera 运行时环境是否激活
if not os.environ.get("AXELERA_RUNTIME_DIR"):
LOGGER.warning(
"Axelera runtime environment is not activated."
"\nPlease run: source /opt/axelera/sdk/latest/axelera_activate.sh"
"\n\nIf this fails, verify driver installation: https://docs.ultralytics.com/integrations/axelera/#axelera-driver-installation"
)
try:
from axelera.runtime import op # 尝试导入 Axelera 运行时
except ImportError:
# 如果导入失败,安装依赖
check_requirements(
"axelera_runtime2==0.1.2",
cmds="--extra-index-url https://software.axelera.ai/artifactory/axelera-runtime-pypi",
)
from axelera.runtime import op # 导入 Axelera 运行时
w = Path(w) # 转换为 Path 对象
# 查找 .axm 文件
if (found := next(w.rglob("*.axm"), None)) is None:
raise FileNotFoundError(f"No .axm file found in: {w}")
ax_model = op.load(str(found)) # 加载 Axelera 模型
metadata = found.parent / "metadata.yaml" # 元数据文件路径
# ExecuTorch
elif pte: # PyTorch ExecuTorch 格式(*.pte)
LOGGER.info(f"Loading {w} for ExecuTorch inference...") # 记录加载信息
# 兼容性修复
check_requirements("setuptools<71.0.0") # Setuptools bug 修复
check_requirements(("executorch==1.0.1", "flatbuffers")) # 检查 ExecuTorch 依赖
from executorch.runtime import Runtime # 导入 ExecuTorch 运行时
w = Path(w) # 转换为 Path 对象
# 如果是目录,查找其中的 .pte 文件
if w.is_dir():
model_file = next(w.rglob("*.pte")) # 查找 .pte 文件
metadata = w / "metadata.yaml" # 元数据文件路径
else: # 如果是单个文件
model_file = w # 模型文件
metadata = w.parent / "metadata.yaml" # 元数据文件在父目录
program = Runtime.get().load_program(str(model_file)) # 加载程序
model = program.load_method("forward") # 加载 forward 方法
# 其他格式(不支持)
else:
from ultralytics.engine.exporter import export_formats # 导入支持的导出格式
raise TypeError(
f"model='{w}' is not a supported model format. Ultralytics supports: {export_formats()['Format']}\n"
f"See https://docs.ultralytics.com/modes/predict for help."
)
# 加载外部元数据 YAML 文件
if isinstance(metadata, (str, Path)) and Path(metadata).exists():
metadata = YAML.load(metadata) # 加载 YAML 文件
# 处理元数据
if metadata and isinstance(metadata, dict):
for k, v in metadata.items():
if k in {"stride", "batch", "channels"}: # 整数类型字段
metadata[k] = int(v) # 转换为整数
elif k in {"imgsz", "names", "kpt_shape", "kpt_names", "args"} and isinstance(v, str):
metadata[k] = ast.literal_eval(v) # 使用 ast 安全地评估字符串表达式
# 从元数据中提取关键信息
stride = metadata["stride"] # 步长
task = metadata["task"] # 任务类型
batch = metadata["batch"] # 批次大小
imgsz = metadata["imgsz"] # 图像大小
names = metadata["names"] # 类别名称
kpt_shape = metadata.get("kpt_shape") # 关键点形状(姿态估计)
kpt_names = metadata.get("kpt_names") # 关键点名称(姿态估计)
end2end = metadata.get("end2end", False) or metadata.get("args", {}).get("nms", False) # 端到端模型标志
dynamic = metadata.get("args", {}).get("dynamic", dynamic) # 动态模型标志
ch = metadata.get("channels", 3) # 通道数,默认3
elif not (pt or triton or nn_module): # 如果不是 PyTorch、Triton 或 nn.Module 格式
LOGGER.warning(f"Metadata not found for 'model={w}'") # 警告:找不到元数据
# 检查类别名称
if "names" not in locals(): # 如果 names 变量不存在
names = default_class_names(data) # 使用默认类别名称
names = check_class_names(names) # 检查并处理类别名称
# 将当前函数的所有局部变量赋值给 self 对象
# 这样所有加载的模型、配置、标志等都成为对象的属性
self.__dict__.update(locals()) # 将所有变量分配给 selfAutoBackend.forward 方法
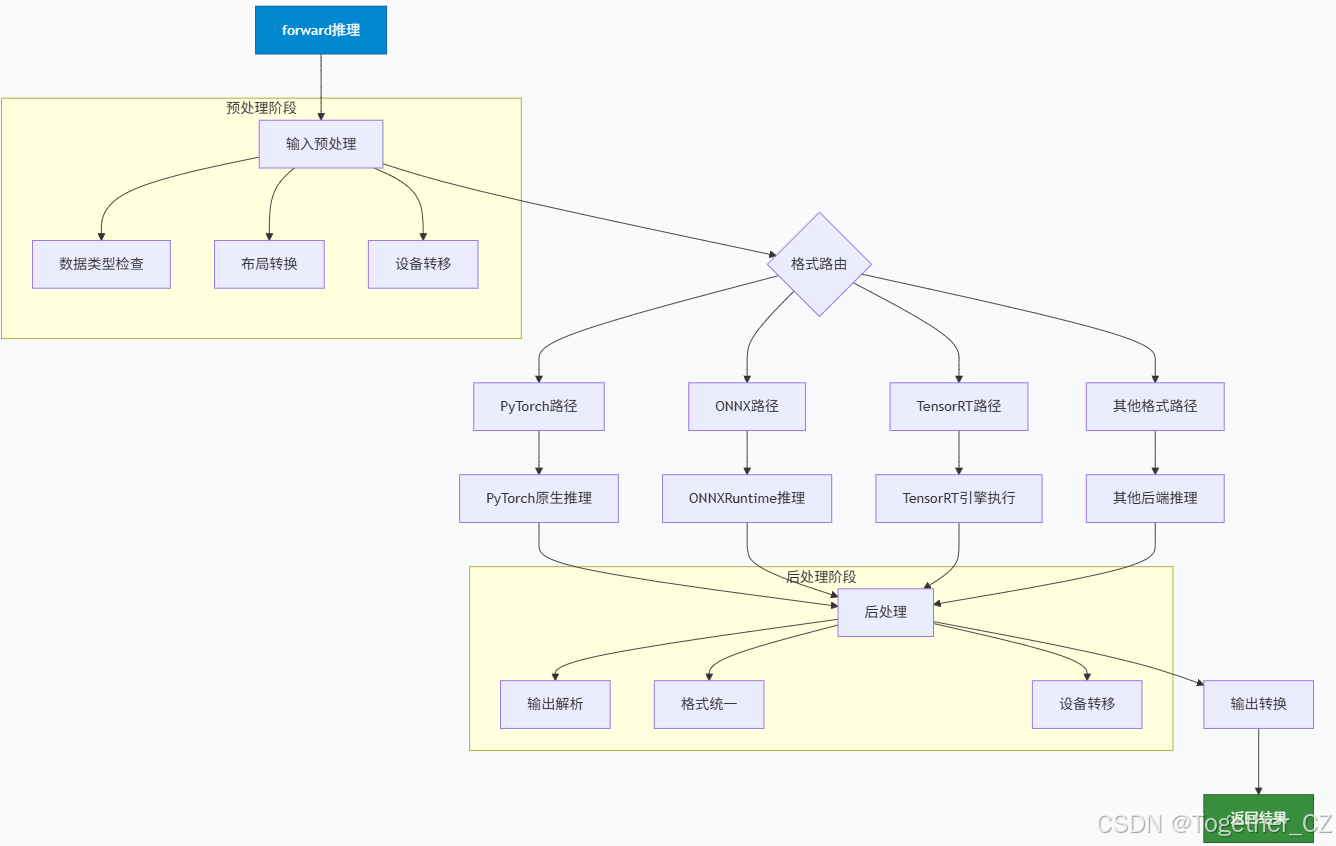
python
def forward(
self,
im: torch.Tensor, # 输入图像张量
augment: bool = False, # 是否进行数据增强
visualize: bool = False, # 是否可视化输出预测
embed: list | None = None, # 要返回的特征向量/嵌入列表
**kwargs: Any, # 模型配置的额外关键字参数
) -> torch.Tensor | list[torch.Tensor]:
"""
在 AutoBackend 模型上运行推理。
参数:
im (torch.Tensor): 要进行推理的图像张量。
augment (bool): 是否在推理期间执行数据增强。
visualize (bool): 是否可视化输出预测。
embed (list, optional): 要返回的特征向量/嵌入列表。
**kwargs (Any): 模型配置的额外关键字参数。
返回:
(torch.Tensor | list[torch.Tensor]): 来自模型的原始输出张量。
"""
_b, _ch, h, w = im.shape # 获取批次大小、通道数、高度、宽度
# 处理 FP16 精度
if self.fp16 and im.dtype != torch.float16:
im = im.half() # 转换为 FP16
# 处理 NHWC 格式(某些后端需要)
if self.nhwc:
# 将 PyTorch 的 BCHW 格式转换为 NumPy 的 BHWC 格式
# shape(1,320,192,3) 表示批次1,高度320,宽度192,通道3
im = im.permute(0, 2, 3, 1) # torch BCHW 到 numpy BHWC 形状(1,320,192,3)
# PyTorch 模型推理
if self.pt or self.nn_module:
# 直接调用模型的 forward 方法
y = self.model(im, augment=augment, visualize=visualize, embed=embed, **kwargs)
# TorchScript 模型推理
elif self.jit:
# TorchScript 模型只有基本的 forward 方法
y = self.model(im)
# ONNX OpenCV DNN 推理
elif self.dnn:
im = im.cpu().numpy() # 将张量转换为 NumPy 数组
self.net.setInput(im) # 设置输入
y = self.net.forward() # 前向传播
# ONNX Runtime 推理
elif self.onnx or self.imx:
if self.use_io_binding: # 如果使用 IO 绑定
if not self.cuda: # 如果不是 CUDA
im = im.cpu() # 将张量移到 CPU
# 绑定输入
self.io.bind_input(
name="images", # 输入名称
device_type=im.device.type, # 设备类型
device_id=im.device.index if im.device.type == "cuda" else 0, # 设备 ID
element_type=np.float16 if self.fp16 else np.float32, # 数据类型
shape=tuple(im.shape), # 形状
buffer_ptr=im.data_ptr(), # 数据指针
)
self.session.run_with_iobinding(self.io) # 使用 IO 绑定运行
y = self.bindings # 获取输出
else: # 不使用 IO 绑定
im = im.cpu().numpy() # 将张量转换为 NumPy 数组
# 运行推理,提供输入字典
y = self.session.run(self.output_names, {self.session.get_inputs()[0].name: im})
# IMX 特定后处理
if self.imx:
if self.task == "detect": # 检测任务
# 合并边界框、置信度和类别:boxes, conf, cls
y = np.concatenate([y[0], y[1][:, :, None], y[2][:, :, None]], axis=-1)
elif self.task == "pose": # 姿态估计任务
# 合并边界框、置信度、关键点:boxes, conf, kpts
y = np.concatenate([y[0], y[1][:, :, None], y[2][:, :, None], y[3]], axis=-1, dtype=y[0].dtype)
elif self.task == "segment": # 分割任务
y = (
np.concatenate([y[0], y[1][:, :, None], y[2][:, :, None], y[3]], axis=-1, dtype=y[0].dtype),
y[4],
)
# OpenVINO 推理
elif self.xml:
im = im.cpu().numpy() # 转换为 NumPy 数组,保持 FP32
# 根据推理模式选择不同的推理策略
if self.inference_mode in {"THROUGHPUT", "CUMULATIVE_THROUGHPUT"}: # 针对大批次优化
n = im.shape[0] # 批次中的图像数量
results = [None] * n # 预分配结果列表,使用 None 填充
def callback(request, userdata):
"""将结果放入预分配列表中,使用 userdata 索引。"""
results[userdata] = request.results # 存储结果
# 创建异步推理队列
async_queue = self.ov.AsyncInferQueue(self.ov_compiled_model)
async_queue.set_callback(callback) # 设置回调函数
# 为每个输入图像启动异步推理
for i in range(n):
# 启动异步推理,userdata=i 指定结果在列表中的位置
async_queue.start_async(inputs={self.input_name: im[i:i+1]}, userdata=i) # 保持图像为 BCHW
async_queue.wait_all() # 等待所有推理请求完成
# 处理结果:将每个图像的输出合并
y = [list(r.values()) for r in results]
y = [np.concatenate(x) for x in zip(*y)]
else: # 推理模式 = "LATENCY",针对批次大小为1的首次结果最快优化
y = list(self.ov_compiled_model(im).values())
# TensorRT 推理
elif self.engine:
# 处理动态形状
if self.dynamic and im.shape != self.bindings["images"].shape:
if self.is_trt10: # TRT10+ API
self.context.set_input_shape("images", im.shape) # 设置输入形状
self.bindings["images"] = self.bindings["images"]._replace(shape=im.shape) # 更新绑定形状
# 更新所有输出绑定的形状
for name in self.output_names:
self.bindings[name].data.resize_(tuple(self.context.get_tensor_shape(name)))
else: # 旧 API
i = self.model.get_binding_index("images") # 获取输入绑定索引
self.context.set_binding_shape(i, im.shape) # 设置绑定形状
self.bindings["images"] = self.bindings["images"]._replace(shape=im.shape) # 更新绑定形状
# 更新所有输出绑定的形状
for name in self.output_names:
i = self.model.get_binding_index(name) # 获取输出绑定索引
self.bindings[name].data.resize_(tuple(self.context.get_binding_shape(i)))
# 检查输入形状是否符合要求
s = self.bindings["images"].shape # 模型期望的形状
# 断言:输入形状必须等于(静态)或小于等于(动态)模型最大形状
assert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"
# 更新输入绑定的数据指针
self.binding_addrs["images"] = int(im.data_ptr())
# 执行推理
self.context.execute_v2(list(self.binding_addrs.values()))
# 获取输出数据,按输出名称排序
y = [self.bindings[x].data for x in sorted(self.output_names)]
# CoreML 推理
elif self.coreml:
im = im.cpu().numpy() # 转换为 NumPy 数组
if self.dynamic: # 动态模型
im = im.transpose(0, 3, 1, 2) # 转换格式
else: # 静态模型
# 将 NumPy 数组转换为 PIL 图像
im = Image.fromarray((im[0] * 255).astype("uint8"))
# 运行预测
y = self.model.predict({"image": im}) # 坐标是归一化的 xywh
# 如果输出包含 "confidence",说明 NMS 已包含在模型中
if "confidence" in y:
from ultralytics.utils.ops import xywh2xyxy # 导入坐标转换函数
# 将归一化的 xywh 转换为像素坐标的 xyxy
box = xywh2xyxy(y["coordinates"] * [[w, h, w, h]]) # xyxy 像素
# 获取最大置信度的类别
cls = y["confidence"].argmax(1, keepdims=True)
# 合并边界框、置信度和类别
y = np.concatenate((box, np.take_along_axis(y["confidence"], cls, axis=1), cls), 1)[None]
else: # 原始输出
y = list(y.values())
# 分割模型特殊处理:输出顺序可能相反
if len(y) == 2 and len(y[1].shape) != 4: # 分割模型
y = list(reversed(y)) # 反转分割模型的输出顺序 (pred, proto)
# PaddlePaddle 推理
elif self.paddle:
im = im.cpu().numpy().astype(np.float32) # 转换为 NumPy 数组,FP32
self.input_handle.copy_from_cpu(im) # 复制输入数据
self.predictor.run() # 运行推理
y = [self.predictor.get_output_handle(x).copy_to_cpu() for x in self.output_names] # 获取输出
# MNN 推理
elif self.mnn:
input_var = self.torch_to_mnn(im) # 转换为 MNN 张量
output_var = self.net.onForward([input_var]) # 前向传播
y = [x.read() for x in output_var] # 读取输出
# NCNN 推理
elif self.ncnn:
# 创建 NCNN Mat 对象
mat_in = self.pyncnn.Mat(im[0].cpu().numpy())
with self.net.create_extractor() as ex: # 创建提取器
ex.input(self.net.input_names()[0], mat_in) # 设置输入
# 警告:'output_names' 排序是为了临时修复 pnnx 问题
y = [np.array(ex.extract(x)[1])[None] for x in sorted(self.net.output_names())] # 提取输出
# NVIDIA Triton 推理服务器
elif self.triton:
im = im.cpu().numpy() # 转换为 NumPy 数组
y = self.model(im) # 远程推理
# RKNN 推理
elif self.rknn:
# 转换为 uint8 并缩放到 0-255(图像通常需要)
im = (im.cpu().numpy() * 255).astype("uint8")
im = im if isinstance(im, (list, tuple)) else [im] # 确保是列表
y = self.rknn_model.inference(inputs=im) # 推理
# Axelera 推理
elif self.axelera:
y = self.ax_model(im.cpu()) # Axelera 模型需要 CPU 张量
# ExecuTorch 推理
elif self.pte:
y = self.model.execute([im]) # 执行推理
# TensorFlow 推理(SavedModel, GraphDef, Lite, Edge TPU)
else:
im = im.cpu().numpy() # 转换为 NumPy 数组
if self.saved_model: # SavedModel
y = self.model.serving_default(im) # 使用 serving_default 签名
if not isinstance(y, list): # 如果不是列表
y = [y] # 转换为列表
elif self.pb: # GraphDef
y = self.frozen_func(x=self.tf.constant(im)) # 调用冻结的函数
else: # Lite 或 Edge TPU
details = self.input_details[0] # 获取输入详情
is_int = details["dtype"] in {np.int8, np.int16} # 检查是否是 TFLite 量化 int8 或 int16 模型
if is_int: # 如果是量化模型
scale, zero_point = details["quantization"] # 获取量化的缩放因子和零点
im = (im / scale + zero_point).astype(details["dtype"]) # 反缩放
self.interpreter.set_tensor(details["index"], im) # 设置输入张量
self.interpreter.invoke() # 调用解释器
y = [] # 输出列表
for output in self.output_details: # 遍历所有输出
x = self.interpreter.get_tensor(output["index"]) # 获取输出张量
if is_int: # 如果是量化模型
scale, zero_point = output["quantization"] # 获取输出量化参数
x = (x.astype(np.float32) - zero_point) * scale # 重新缩放
# 反归一化处理(非分类任务)
if x.ndim == 3: # 如果任务不是分类(不包括掩码,ndim=4)
# 通过图像大小反归一化 xywh。参见:https://github.com/ultralytics/ultralytics/pull/1695
# 在 TFLite/EdgeTPU 中 xywh 被归一化,以减轻整数模型的量化误差
if x.shape[-1] == 6 or self.end2end: # 端到端模型
# 对边界框坐标进行反归一化
x[:, :, [0, 2]] *= w # x 和 width 乘以宽度
x[:, :, [1, 3]] *= h # y 和 height 乘以高度
if self.task == "pose": # 姿态估计任务
# 对关键点坐标进行反归一化
x[:, :, 6::3] *= w # 关键点的 x 坐标
x[:, :, 7::3] *= h # 关键点的 y 坐标
else:
# 标准检测模型
x[:, [0, 2]] *= w
x[:, [1, 3]] *= h
if self.task == "pose":
x[:, 5::3] *= w
x[:, 6::3] *= h
y.append(x) # 添加到输出列表
# TensorFlow 分割修复:导出顺序与 ONNX 导出相反,且原型被转置
if len(y) == 2: # 分割输出,顺序为 (det, proto) 但与 ONNX 相反
if len(y[1].shape) != 4: # 如果第二个输出不是4维
y = list(reversed(y)) # 应该是 y = (1, 116, 8400), (1, 160, 160, 32)
if y[1].shape[-1] == 6: # 端到端模型
y = [y[1]] # 只保留一个输出
else:
# 转置原型输出:从 (0, 3, 1, 2) 到 (0, 1, 2, 3)
y[1] = np.transpose(y[1], (0, 3, 1, 2)) # 应该是 y = (1, 116, 8400), (1, 32, 160, 160)
# 确保所有输出都是 NumPy 数组
y = [x if isinstance(x, np.ndarray) else x.numpy() for x in y]
# 后处理:统一输出格式
if isinstance(y, (list, tuple)): # 如果输出是列表或元组
# 特殊处理:如果类别名称未定义且是分割任务或有两个输出
if len(self.names) == 999 and (self.task == "segment" or len(y) == 2):
# 计算类别数量:总输出维度 - 掩码维度 - 4(边界框坐标)
nc = y[0].shape[1] - y[1].shape[1] - 4 # y = (1, 32, 160, 160), (1, 116, 8400)
self.names = {i: f"class{i}" for i in range(nc)} # 创建默认类别名称
# 返回单个张量或张量列表
return self.from_numpy(y[0]) if len(y) == 1 else [self.from_numpy(x) for x in y]
else: # 单个输出
return self.from_numpy(y)AutoBackend.from_numpy 方法
python
def from_numpy(self, x: np.ndarray | torch.Tensor) -> torch.Tensor:
"""
将 NumPy 数组转换为模型设备上的 torch 张量。
参数:
x (np.ndarray | torch.Tensor): 输入数组或张量。
返回:
(torch.Tensor): 位于 `self.device` 上的张量。
"""
# 如果是 NumPy 数组,转换为 torch 张量并移动到模型设备
# 如果是 torch 张量,直接返回
return torch.tensor(x).to(self.device) if isinstance(x, np.ndarray) else xAutoBackend.warmup 方法
python
def warmup(self, imgsz: tuple[int, int, int, int] = (1, 3, 640, 640)) -> None:
"""
通过使用虚拟输入运行一次前向传递来预热模型。
参数:
imgsz (tuple[int, int, int, int]): 虚拟输入形状,格式为 (批次, 通道, 高度, 宽度)。
"""
# 确定哪些模型类型需要预热
warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb, self.triton, self.nn_module
# 如果模型需要预热且设备不是 CPU(或使用 Triton)
if any(warmup_types) and (self.device.type != "cpu" or self.triton):
# 创建空的输入张量
im = torch.empty(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # 输入
# TorchScript 需要两次预热,其他只需要一次
for _ in range(2 if self.jit else 1):
self.forward(im) # 预热模型
# 创建随机的边界框张量用于预热 NMS
warmup_boxes = torch.rand(1, 84, 16, device=self.device) # 16个边界框在经验上效果最好
warmup_boxes[:, :4] *= imgsz[-1] # 根据图像大小缩放边界框坐标
non_max_suppression(warmup_boxes) # 预热 NMSAutoBackend._model_type 静态方法
python
staticmethod
def _model_type(p: str = "path/to/model.pt") -> list[bool]:
"""
获取模型文件路径并返回模型类型。
参数:
p (str): 模型文件路径。
返回:
(list[bool]): 表示模型类型的布尔值列表。
示例:
>>> types = AutoBackend._model_type("path/to/model.onnx")
>>> assert types[2] # onnx
"""
from ultralytics.engine.exporter import export_formats # 导入支持的导出格式
sf = export_formats()["Suffix"] # 导出后缀列表
# 检查路径是否是 URL 或字符串
if not is_url(p) and not isinstance(p, str):
check_suffix(p, sf) # 检查文件后缀
name = Path(p).name # 获取文件名
# 检查文件名是否包含各种格式的后缀
types = [s in name for s in sf] # 创建布尔列表,表示每种格式
types[5] |= name.endswith(".mlmodel") # 保留对旧版 Apple CoreML *.mlmodel 格式的支持
types[8] &= not types[9] # tflite 格式且不是 edgetpu 格式
# 如果找到任何支持的格式
if any(types):
triton = False # 不是 Triton
else: # 如果没有找到已知格式,检查是否是 Triton URL
from urllib.parse import urlsplit # 导入 URL 解析
url = urlsplit(p) # 解析 URL
# 检查是否是 Triton 服务器 URL
triton = bool(url.netloc) and bool(url.path) and url.scheme in {"http", "grpc"}
# 返回所有格式的标志列表,包括 Triton
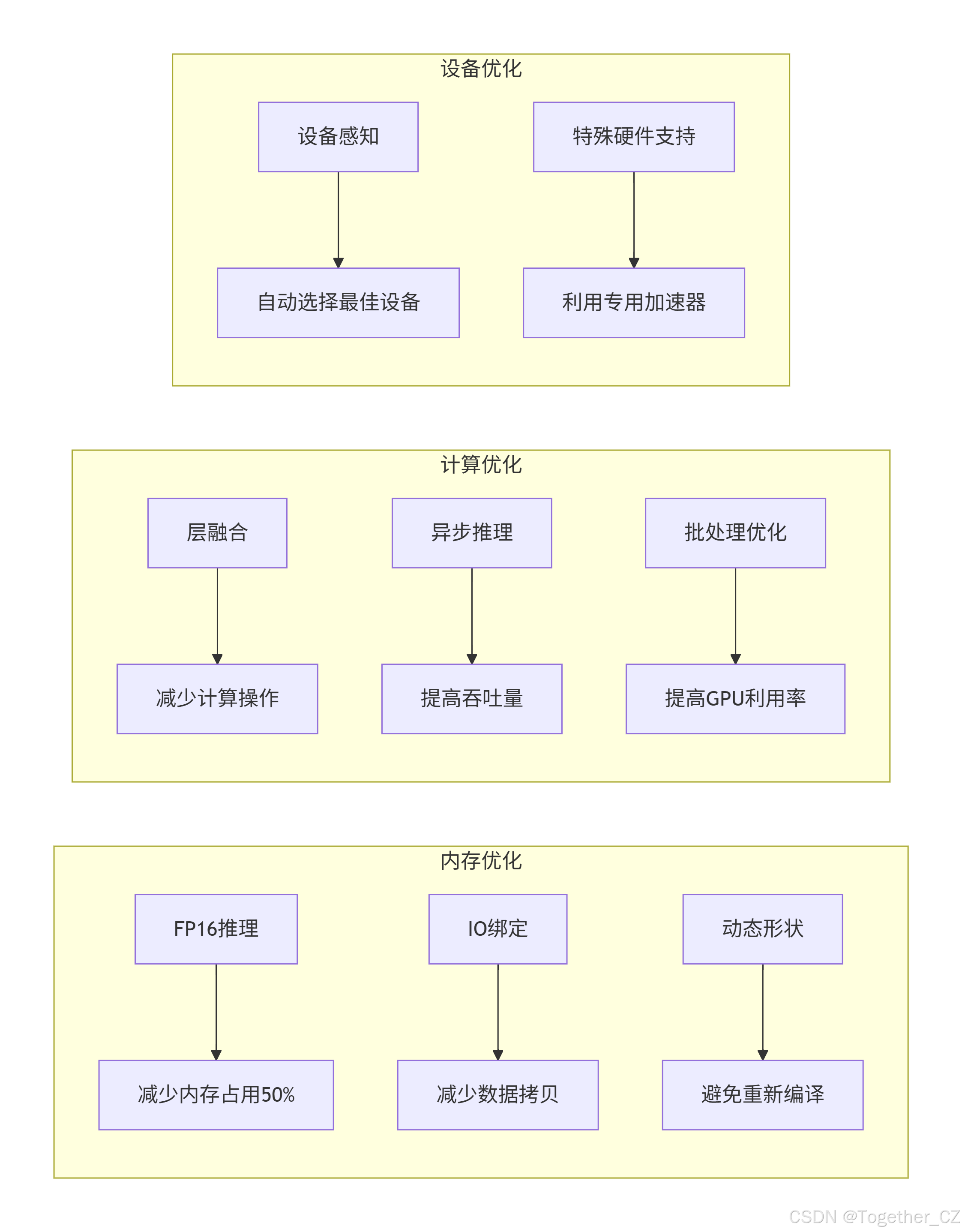
return [*types, triton]内存和计算优化策略如下
错误处理层级
实例化使用流程如下:
python
# 可视化使用流程
1. 初始化
↓
model = AutoBackend(
model="yolov8n.pt", # 可以是任何支持格式
device="cuda:0", # 自动选择设备
fp16=True # 启用半精度
)
2. 预热(可选)
↓
model.warmup(imgsz=(1, 3, 640, 640))
3. 推理
↓
results = model(im) # im: torch.Tensor [B, C, H, W]
4. 后处理(在其他模块)
↓
detections = non_max_suppression(results)AutoBackend 模块是 Ultralytics 的统一推理后端管理器,它的核心设计理念是抽象化 和统一接口。通过自动检测模型格式并加载对应的推理引擎,为用户提供了完全透明的多格式模型推理能力。模块支持从 PyTorch 到边缘计算芯片的20多种格式,自动处理设备分配、数据预处理和后处理,让开发者能够专注于应用逻辑而不必关心底层实现细节。