Transformer是由Google在2017年当中的论文提出的,其主要核心是通过词向量与自注意力机制缓解传统RNN算法对长时间序列在反向传播过程当中对于cell的梯度下降问题。
传统RNN算法在对当前时间序列的输出计算是基于当前输出* 特征矩阵与前一隐层输出* 特征矩阵之和
h t = σ ( W h h h t − 1 + W x h x t ) h_t = \sigma(W_{hh}h_{t-1} + W_{xh}x_t) ht=σ(Whhht−1+Wxhxt)
因此当前的输出依赖于前一隐层输出最终形成一个链式,当你计算第 100 个词的梯度并想传回第 1 个词时,你需要对 W h h W_{hh} Whh 进行 100 次偏导连乘。
就像在复印机上把一张纸复印 100 次,每一次微小的模糊(导数 < 1 < 1 <1)都会被指数级放大,最终导致第一张纸的内容完全看不清(梯度消失)。产生梯度下降失效,模型根本不知道该怎么调前面的参数。
Transformer采用了跳跃的方式也就是自注意力机制抛弃了RNN的链式依赖。
词向量
Transformer并没有使用传统的独热向量(度热向量的维度取决于词表当中词的个数,维度太高),Transformer 引入了一个 词嵌入矩阵 W e W_e We ,其维度通常是 V × d V \times d V×d( V V V 是词表大小, d d d 是模型定义的维度,如 512)。
不同于 One-Hot,这 d d d 个维度里的数字都是连续的实数。在训练过程中,模型会不断调整这些数字,使得:
- 语义接近的词,在空间中距离更近: "猫"和"狗"的向量在 512 维空间里的夹角会变小。
- 特征解耦: 某些维度可能潜移默化地代表了"词性"、"性别"、"抽象程度"等特征,尽管我们很难直接肉眼解读。
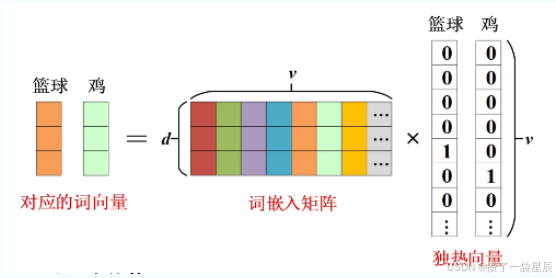
通过上述的词向量矩阵可以很好的表征词的含义,但是Transformer是用来处理时间序列的,单一的词特征无法满足需求,因此还需要将位置信息融入词向量矩阵当中作为最终的输入。
对于位置信息的计算是基于一下公式,将位置信息转化为对应的矩阵
- 偶数位置 使用 sin \sin sin 函数: P E ( p o s , 2 i ) = sin ( p o s 10000 2 i d ) PE(pos, 2i) = \sin\left(\frac{pos}{10000^{\frac{2i}{d}}}\right) PE(pos,2i)=sin(10000d2ipos)
- 奇数位置 使用 cos \cos cos 函数: P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i d ) PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{\frac{2i}{d}}}\right) PE(pos,2i+1)=cos(10000d2ipos)
根据三角函数的感法公式, sin ( α + β ) \sin(\alpha+\beta) sin(α+β) 可以由 sin α , cos β \sin \alpha, \cos \beta sinα,cosβ 等线性表示。这意味着模型可以轻易地通过线性变换,从"位置 5" 推导出它与"位置 2" 的相对距离。
最终将位置信息矩阵与词向量矩阵相加得到我们混合了词义与位置信息的输入。
Input to Transformer = Embedding + Positional Encoding \text{Input to Transformer} = \text{Embedding} + \text{Positional Encoding} Input to Transformer=Embedding+Positional Encoding
自注意力机制
自注意力机制是Transformer的核心,基于该机制能够生成一段序列当中每个词对于其他词的关联度。如果把 词嵌入(Embedding) 比作单词的"静态画像",那么 自注意力机制(Self-Attention) 就是赋予了这些画像"流动的眼神",让每个词都能根据上下文实时调整自己的含义。
关联度的生成本质上是一个相似度匹配 的过程。模型通过 Q Q Q (Query) 和 K K K (Key) 的运算,为序列中的每一对词计算一个分值:
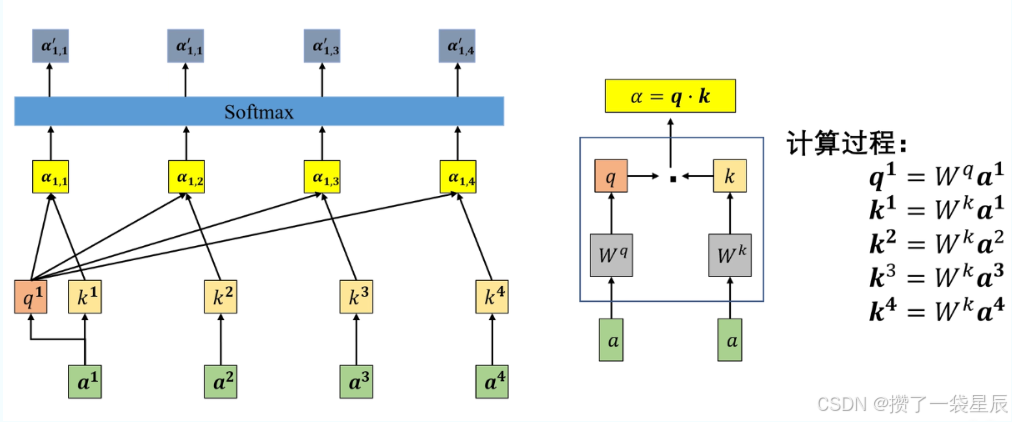
在上图当中有两个权重矩阵 W q W^q Wq 和 W k W^k Wk,这两个矩阵是全局共享的,如果我们想计算 a 1 a^1 a1与其他词的关联度(包括与 a 1 a^1 a1自己),那么我们就可以通过两个权重矩阵
- a 1 ⋅ W q = q 1 a^1 \cdot W^q = q^1 a1⋅Wq=q1 :得到一个 a 1 a^1 a1 的查询向量(Query) 。它代表了 a 1 a^1 a1 "想要寻找什么样的特征"。
- a 1 ⋅ W k = k 1 a^1 \cdot W^k = k^1 a1⋅Wk=k1 :得到一个 a 1 a^1 a1 的键向量(Key) 。它代表了 a 1 a^1 a1 "本身具备什么样的标签"供别人匹配。
同理, a 2 , a 3 , a 4 a^2, a^3, a^4 a2,a3,a4 也会分别通过同一个全局共享的 W k W^k Wk 矩阵,生成各自的 k 2 , k 3 , k 4 k^2, k^3, k^4 k2,k3,k4。
如果你想计算 a 1 a^1 a1 与其他词的关联度,公式如下:
α 1 , i = q 1 ⋅ k i \alpha_{1,i} = q^1 \cdot k^i α1,i=q1⋅ki
- 计算 a 1 a^1 a1 与自己的关联度 :用 q 1 q^1 q1 点乘 k 1 k^1 k1。
- 计算 a 1 a^1 a1 与 a 2 a^2 a2 的关联度 :用 q 1 q^1 q1 点乘 k 2 k^2 k2。
- 计算 a 1 a^1 a1 与 a 3 a^3 a3 的关联度 :用 q 1 q^1 q1 点乘 k 3 k^3 k3。
这些点积的结果 α \alpha α 衡量了两个向量在空间中的相似程度 :如果 q 1 q^1 q1 所寻找的特征恰好在 k i k^i ki 中高度体现,那么它们的点积值就会很大。
我们再来从矩阵整体的维度来看:
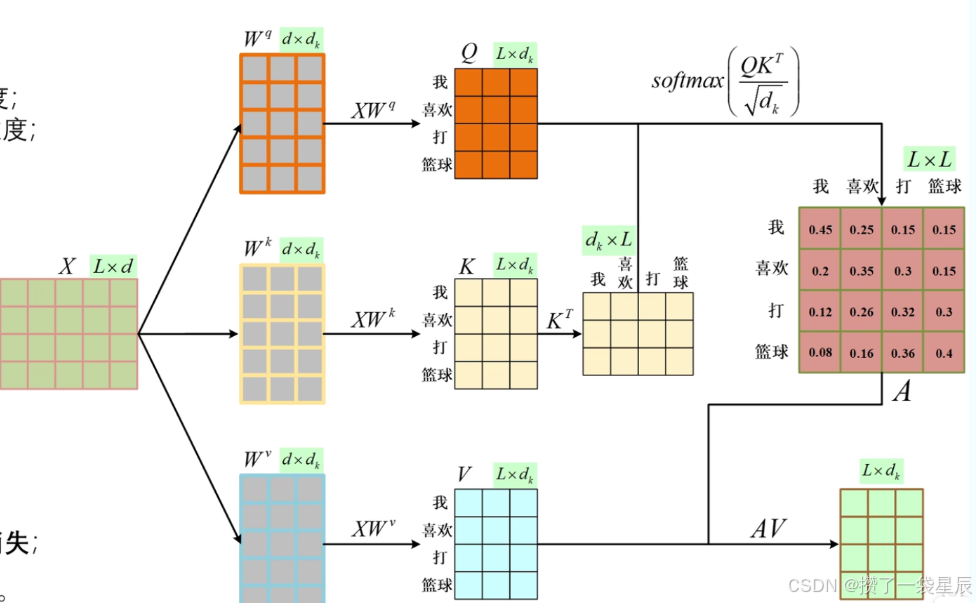
这里实际上用到了三个权重矩阵: W q W^q Wq 、 W k W^k Wk以及 W v W^v Wv
- W q W^q Wq (Query Weight):
- 作用 :计算词向量 a a a 与 W q W^q Wq 的乘积,得到 Query 向量 ( q q q)。
- 直觉理解 : q q q 代表了当前这个词**"想要寻找什么样的信息"**。
- 举例 :在句子"苹果发布了 iPhone"中,"发布"这个词的 q q q 向量可能会向空间中发射一个信号:"谁是我的主语(执行者)?"或者"谁是我的宾语(承受者)?"
- W k W^k Wk (Key Weight):
- 作用 :计算词向量 a a a 与 W k W^k Wk 的乘积,得到 Key 向量 ( k k k)。
- 直觉理解 : k k k 代表了当前这个词**"我能提供什么样的特征标签"**,它是用来被别人(Query)匹配的。
- 关联计算 :通过 q ⋅ k q \cdot k q⋅k(点积),模型计算出两个词之间的匹配程度,即之前提到的"关联度"。
- W v W^v Wv (Value Weight):
- 作用 :计算词向量 a a a 与 W v W^v Wv 的乘积,得到 Value 向量 ( v v v)。
- 直觉理解 : v v v 代表了当前这个词**"我真正的语义信息是什么"**。
- 为什么需要它? :即便两个词关联度很高,我们也不希望直接把原始的 a a a 传递过去。 W v W^v Wv 负责提取出当前词中最有价值的信息,用于最后加权求和。
词与词的关系往往是非对称的。如果 W q = W k W^q = W^k Wq=Wk,那么 A 对 B 的关注永远等于 B 对 A。而有了独立的 W q W^q Wq 和 W k W^k Wk,模型可以学习到"动词对名词"的需求与"名词对动词"的需求是不同的。
这里通过 W q W^q Wq与 W k W^k Wk转置的点乘运算能够得到一个时间序列当中每个词与其他词的关联矩阵,再经过softmax进行归一化后就能得到一个概率矩阵,这个矩阵当中的每个点位置都表征了某个词相对另一个词的概率,再与 W v W^v Wv做运算也就是将概率再与词意融合。