
前言
在 Linux 的存储生态中,Ext 系列文件系统(Ext2/Ext3/Ext4)不仅要解决 "数据如何存" 的问题,更要攻克 "数据如何找""多分区如何用" 的核心难题。当我们输入
/home/whb/test.c这样的路径访问文件时,系统如何从根目录层层定位到目标文件?频繁访问的路径为何能秒开?多个独立分区又如何被整合进统一的文件目录树?今天这篇文章,我们就聚焦 Ext 文件系统的 "导航"(路径解析、路径缓存)与 "整合"(分区挂载)机制,结合底层原理与实战操作,带你看透文件系统的高效运作逻辑。下面就让我们正式开始吧!
一、路径解析:从根目录到目标文件的 "层层导航"
我们访问文件时,依赖的是 "路径 + 文件名" 的组合,而非 inode 号或块号。但目录本身也是文件,访问目录同样需要知道其 inode 号 ------ 这就陷入了 "先有鸡还是先有蛋" 的循环。Ext 文件系统通过 "路径解析" 机制打破这个循环,从根目录出发,层层递进找到目标文件,就像导航软件从起点到终点的路线规划。
1.1 路径解析的核心逻辑:递归与出口
路径解析的本质是 "递归解析目录,直到找到目标文件",其核心逻辑可概括为:
- 递归解析 :对于任意文件路径(如
/home/whb/test.c),系统会从左到右依次解析每个目录(/→home→whb),每个目录的解析都依赖其父目录的 inode;- 出口是根目录 :根目录(
/)是路径解析的 "终止条件"------ 它的 inode 号是固定的(通常为 2),系统开机后会直接加载根目录的 inode,无需通过其他目录查找;- 最终定位:解析完所有目录后,在最后一个目录的数据块中,根据文件名找到对应的 inode 号,再通过 inode 访问文件的属性和内容。
举个例子:访问/home/opchen/test.c的路径解析过程,就像去图书馆找一本书:
- 根目录(
/)是图书馆大门(inode 号固定,无需查找); - 进入大门后,找到 "home" 区域(通过根目录的数据块,根据 "home" 文件名找到其 inode 号);
- 进入 "home" 区域后,找到 "opchen" 书架(通过 "home" 的 inode 找到其数据块,根据 "opchen" 文件名找到其 inode 号);
- 在 "opchen" 书架上,找到 "test.c" 这本书(通过 "whb" 的 inode 找到其数据块,根据 "test.c" 文件名找到其 inode 号)。
1.2 路径解析的详细步骤(以/home/whb/test.c为例)
我们结合 Ext 文件系统的底层结构,拆解路径解析的每一步:
步骤 1:加载根目录的 inode
根目录的 inode 号是系统内置的(通常为 2),开机后内核会直接读取根目录所在的块组,通过 inode 号 2 找到根目录的 inode(存储在 inode 表中)。根目录的 inode 中,**i_block字段记录了其数据块的块号 ------ 根目录的数据块中存储着"目录名→inode 号"**的映射关系(如 "home"→263465)。
步骤 2:解析 "home" 目录
- 内核通过根目录 inode 的**
i_block**字段,找到根目录的数据块; - 遍历数据块中的目录项,根据 "home" 文件名找到对应的 inode 号(如 263465);
- 通过 inode 号 263465,找到 "home" 目录所在的块组(块组号 =(263465-1)÷ 每个块组的 inode 数);
- 读取 "home" 目录的 inode,获取其数据块的块号(存储在
i_block字段中)。
步骤 3:解析 "whb" 目录
- 内核通过 "home" 目录的数据块,遍历目录项找到 "opchen" 对应的 inode 号(如 263466);
- 同理,通过 inode 号 263466 找到 "opchen" 目录的 inode 和数据块。
步骤 4:定位 "test.c" 文件
- 内核通过 "opchen" 目录的数据块,遍历目录项找到 "test.c" 对应的 inode 号(如 263467);
- 此时,路径解析完成,内核通过 inode 号 263467 访问 "test.c" 的属性(存储在 inode 中)和内容(通过
i_block字段找到数据块)。
1.3 绝对路径与相对路径的解析差异
路径解析分为两种场景:绝对路径(以/开头)和相对路径(不以/开头),其解析逻辑略有不同:
1.3.1 绝对路径解析
- 特点 :从根目录(
/)开始解析,路径是 "全局唯一" 的; - 示例 :
/etc/profile的解析过程是/→etc→profile; - 优势:不受当前工作目录影响,解析逻辑固定。
1.3.2 相对路径解析
- 特点:从当前工作目录(CWD,Current Working Directory)开始解析,路径是 "相对" 的;
- 示例 :当前工作目录是
/home/opchen,访问test.c的解析过程是当前工作目录(/home/opchen)→test.c;访问../code/test.c的解析过程是当前工作目录(/home/opchen)→..(上级目录/home)→code→test.c; - 依赖 :当前工作目录的 inode 号存储在进程的**
fs_struct**结构体中,进程访问文件时会直接读取该 inode,无需重新解析。
1.4 路径解析的底层依赖:目录文件的结构
路径解析的核心依赖是目录文件的数据块 ------ 其中存储的 "文件名→inode 号" 映射关系,是目录导航的 "路标"。我们之前已经了解过目录项的结构(struct ext2_dir_entry),这里再强调其关键作用:
cpp
#include <stdint.h>
// Ext2目录项结构(简化版)
struct ext2_dir_entry {
uint32_t inode; // 文件名对应的inode号(核心映射关系)
uint16_t rec_len; // 目录项长度(含填充字节,用于遍历)
uint8_t name_len; // 文件名长度(字节)
uint8_t file_type; // 文件类型(1=普通文件,2=目录等)
char name[]; // 文件名(无终止符)
};目录项的遍历逻辑:
- 每个目录的数据块中,目录项按**
rec_len**字段依次排列; - 解析目录时,内核从数据块起始位置开始,通过**
rec_len**跳过当前目录项,遍历所有条目,直到找到目标文件名; - 目录项中的**
file_type**字段可快速判断目标是文件还是目录,避免无效解析(如解析文件时无需继续递归)。
1.5 实战:验证路径解析过程
我们通过 C 语言代码模拟路径解析的核心步骤 ------ 从根目录开始,层层解析目录,最终找到目标文件的 inode 号。代码逻辑:输入目标文件路径,解析每个目录,输出中间过程和最终 inode 号。
cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#define BLOCK_SIZE 4096
#define INODE_SIZE 128
#define INODES_PER_GROUP 1024
// 解析单个目录,根据目录名找到对应的inode号
uint32_t parse_dir(int dev_fd, uint32_t dir_inode, const char *dir_name) {
// 1. 根据目录inode号找到其数据块
// 计算inode所在的块组和块内偏移
int group = (dir_inode - 1) / INODES_PER_GROUP;
int inode_offset = (dir_inode - 1) % INODES_PER_GROUP;
// 读取块组描述符,获取inode表起始块号
uint32_t bg_inode_table;
lseek(dev_fd, 1 * BLOCK_SIZE + offsetof(struct ext2_group_desc, bg_inode_table), SEEK_SET);
read(dev_fd, &bg_inode_table, sizeof(bg_inode_table));
// 读取目录inode的i_block字段(数据块指针)
uint32_t dir_blocks[15] = {0};
lseek(dev_fd, bg_inode_table * BLOCK_SIZE + inode_offset * INODE_SIZE + offsetof(struct ext2_inode, i_block), SEEK_SET);
read(dev_fd, dir_blocks, 15 * sizeof(uint32_t));
// 2. 遍历目录的数据块,查找目标目录名
for (int i = 0; i < 12 && dir_blocks[i] != 0; i++) {
char block_data[BLOCK_SIZE];
lseek(dev_fd, dir_blocks[i] * BLOCK_SIZE, SEEK_SET);
read(dev_fd, block_data, BLOCK_SIZE);
int offset = 0;
while (offset < BLOCK_SIZE) {
struct ext2_dir_entry *entry = (struct ext2_dir_entry *)(block_data + offset);
if (entry->inode == 0) break;
// 比较文件名
char name[256];
strncpy(name, entry->name, entry->name_len);
name[entry->name_len] = '\0';
if (strcmp(name, dir_name) == 0) {
printf("找到目录 '%s',inode号:%u\n", dir_name, entry->inode);
return entry->inode;
}
offset += entry->rec_len;
}
}
fprintf(stderr, "目录 '%s' 未找到\n", dir_name);
exit(EXIT_FAILURE);
}
// 解析完整路径,返回目标文件的inode号
uint32_t parse_path(const char *path) {
if (path[0] != '/') {
fprintf(stderr, "仅支持绝对路径解析\n");
exit(EXIT_FAILURE);
}
// 打开磁盘设备(假设根目录在/dev/vda1分区)
int dev_fd = open("/dev/vda1", O_RDONLY);
if (dev_fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
// 路径解析的起点:根目录inode号(通常为2)
uint32_t current_inode = 2;
printf("路径解析起点:根目录,inode号:%u\n", current_inode);
// 分割路径(如"/home/whb/test.c"分割为"home"、"whb"、"test.c")
char *path_copy = strdup(path);
char *token = strtok(path_copy + 1, "/");
char *last_token = NULL;
// 解析所有目录(除了最后一个文件名)
while (token != NULL) {
last_token = token;
token = strtok(NULL, "/");
if (token == NULL) break; // 最后一个是文件名,跳出循环
current_inode = parse_dir(dev_fd, current_inode, last_token);
}
// 解析最后一个文件名
uint32_t target_inode = parse_dir(dev_fd, current_inode, last_token);
printf("路径解析完成,目标文件 '%s' 的inode号:%u\n", last_token, target_inode);
free(path_copy);
close(dev_fd);
return target_inode;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <absolute_path>\n", argv[0]);
exit(EXIT_FAILURE);
}
parse_path(argv[1]);
return 0;
}代码编译与运行:
bash
# 编译代码(需root权限,访问磁盘设备)
gcc path_parser.c -o path_parser
# 解析路径/home/whb/test.c
sudo ./path_parser /home/opchen/test.c输出示例:
bash
路径解析起点:根目录,inode号:2
找到目录 'home',inode号:263465
找到目录 'opchen',inode号:263466
找到目录 'test.c',inode号:263467
路径解析完成,目标文件 'test.c' 的inode号:263467输出验证了路径解析的层层递进逻辑:从根目录(inode=2)开始,依次找到home(inode=263465)、opchen(inode=263466),最终找到test.c(inode=263467)。
1.6 路径解析的性能瓶颈与优化方向
路径解析的核心性能瓶颈是 "多次磁盘 IO"------ 解析每个目录都需要读取其 inode 和数据块,若路径较长(如/a/b/c/d/e/f/test.txt),会产生多次磁盘 IO,影响访问速度。Ext 文件系统的优化方向的是:
- 目录项排序与哈希:Ext4 文件系统支持目录项哈希排序(HTree),将目录项按文件名哈希值存储,避免线性遍历,将目录项查找时间复杂度从 O (n) 优化为 O (1);
- 路径缓存:将频繁访问的路径解析结果缓存到内存中,下次访问时直接从缓存读取,无需重新解析(下一节详细讲解)。
二、路径缓存:inode 与 dentry 的 "内存树" 加速访问
路径解析虽逻辑清晰,但多次磁盘 IO 的开销不容忽视。为了加速频繁访问的路径,Linux 内核引入了 "路径缓存" 机制 ------ 将已解析的路径、目录项(dentry)和 inode 加载到内存中,构建一棵 "内存目录树",下次访问时直接从内存查找,无需访问磁盘。
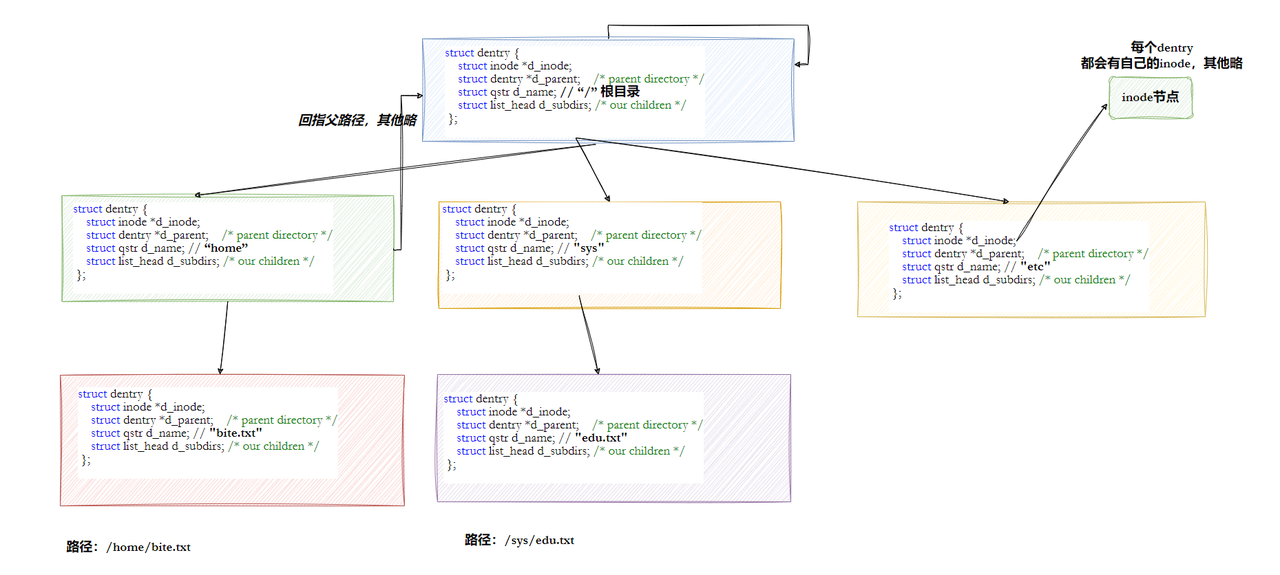
2.1 路径缓存的核心:dentry 结构体
路径缓存的核心是**struct dentry(目录项结构体),它是内核在内存中维护的 "路径节点",记录了文件名、父目录指针、对应的 inode 等信息。dentry**结构体的简化定义如下(C 语言):
cpp
#include <linux/types.h>
#include <linux/list.h>
#include <linux/spinlock.h>
struct inode; // 前向声明
struct dentry {
atomic_t d_count; // 引用计数(被多少进程引用)
unsigned int d_flags; // 标志位(如是否为目录、是否缓存有效)
spinlock_t d_lock; // 自旋锁(保护dentry操作原子性)
struct inode *d_inode; // 对应的inode指针(核心关联)
struct hlist_node d_hash; // 哈希表节点(用于快速查找)
struct dentry *d_parent; // 父目录的dentry指针(构建目录树)
struct qstr d_name; // 文件名(包含长度和字符串)
struct list_head d_lru; // LRU链表节点(缓存淘汰)
union {
struct list_head d_child; // 子目录dentry链表(父目录的子节点)
struct rcu_head d_rcu; // RCU回收节点(内存释放)
} d_u;
struct list_head d_subdirs; // 子目录链表(当前目录的所有子dentry)
struct list_head d_alias; // inode别名链表(多个dentry对应同一个inode,如硬链接)
unsigned long d_time; // 最后验证时间(缓存有效性)
struct dentry_operations *d_op; // dentry操作函数集
struct super_block *d_sb; // 所属的超级块(文件系统)
void *d_fsdata; // 文件系统私有数据
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; // 短文件名缓存(优化内存)
}; dentry的核心作用是**"连接路径、inode 和内存缓存"**,其关键字段解读:
- d_parent与d_subdirs:构建内存目录树的核心 ------
d_parent指向父目录的 dentry,d_subdirs记录当前目录的所有子 dentry,形成层级结构;- d_inode:直接指向对应的 inode 结构体,避免再次从磁盘读取 inode;
- d_hash:将 dentry 加入哈希表,支持按 "父 dentry + 文件名" 快速查找;
- d_lru:加入 LRU(最近最少使用)链表,当内存不足时,淘汰长期未使用的 dentry,释放内存。
2.2 路径缓存的工作机制:缓存命中与失效
路径缓存的工作流程可分为**"缓存加载"、"缓存命中"、"缓存失效"**三个阶段:
2.2.1 缓存加载(首次访问路径)
当首次访问某个路径(如/home/opchen/test.c)时:
- 系统执行路径解析(如前所述),从磁盘读取每个目录的 inode 和数据块;
- 为每个目录项(
/→home→opchen→test.c)创建对应的 dentry结构体,设置**d_parent和d_subdirs**,构建内存目录树; - 将 dentry与对应的 inode 关联(**
d_inode**指针指向 inode); - 将 dentry加入哈希表(便于快速查找)和 LRU 链表(便于缓存淘汰)。
此时,路径的解析结果被缓存到内存中,后续访问无需再访问磁盘。
2.2.2 缓存命中(再次访问路径)
当再次访问已缓存的路径时:
- 系统根据**"父 dentry + 文件名"**在哈希表中查找对应的 dentry;
- 若找到 dentry(缓存命中),且**
d_inode**有效(inode 未被删除),则直接通过 dentry 访问 inode,无需路径解析;- 若路径较长(如
/a/b/c/d/test.txt),则依次查找每个目录的 dentry,全程在内存中完成,速度极快。
2.2.3 缓存失效(路径变更)
当路径对应的目录或文件发生变更时(如删除文件、重命名目录、修改目录项),缓存会失效:
- 系统标记对应的 dentry 为 "无效"(设置**
d_flags**标志位);- 若 dentry 的引用计数为 0(无进程使用),则通过 RCU 机制回收内存;
- 下次访问该路径时,系统会重新执行路径解析,加载新的 dentry 到缓存。
2.3 路径缓存的核心优势
路径缓存通过 "内存换时间" 的策略,带来了显著的性能提升:
- 减少磁盘 IO:缓存命中时,路径解析全程在内存中完成,无需访问磁盘,访问速度从毫秒级提升到微秒级;
- 支持并发访问 :dentry 的**
d_lock**自旋锁保证了多进程并发访问的原子性,避免数据竞争;- 智能缓存淘汰:LRU 链表确保内存有限时,优先淘汰长期未使用的 dentry,保留高频访问的路径缓存;
- 兼容硬链接 :多个硬链接对应同一个 inode,它们的 dentry 通过**
d_alias**链表关联,共享同一个 inode,节省内存。
2.4 实战:查看系统的 dentry 缓存状态
Linux 系统提供了/proc/slabinfo文件,用于查看内核 slab 分配器的状态,其中包含 dentry 缓存的统计信息。我们可以通过以下命令查看 dentry 缓存的使用情况:
bash
# 查看dentry和inode缓存的状态
grep -E "dentry|inode" /proc/slabinfo输出示例:
dentry 12345 13560 192 8 1 : tunables 0 0 0 : slabdata 1695 1695 0
inode_cache 8765 9216 640 4 1 : tunables 0 0 0 : slabdata 2304 2304 0输出字段解读(以 dentry 为例):
12345:当前活跃的 dentry 数量(已分配且被使用);13560:已分配的 dentry 总数(活跃 + 空闲);192:每个 dentry 的大小(字节);8:每个 slab 页中包含的 dentry 数量;
从输出可以看出,系统缓存了大量的 dentry和 inode,这也是频繁访问的路径能快速打开的原因。
我们还可以通过sysctl命令调整 dentry缓存的相关参数(如最大缓存数量):
bash
# 查看dentry缓存的最大数量(默认值可能因系统而异)
sysctl vm.max_map_count
# 临时调整dentry缓存最大数量(重启后失效)
sudo sysctl -w vm.max_map_count=262144三、分区挂载:将独立分区整合进统一目录树
我们知道,inode 号和块号都是 "分区内唯一" 的 ------ 不同分区的 inode 号可以重复,块号也相互独立。如果不进行任何处理,多个分区就是彼此孤立的 "存储孤岛"。Ext 文件系统通过 "分区挂载" 机制,将多个独立分区关联到目录树的某个节点(挂载点),实现**"多分区统一访问"**。
3.1 挂载的核心概念:设备、文件系统与挂载点
挂载的本质是**"将一个文件系统(通常是磁盘分区)关联到目录树的某个目录"**,涉及三个核心要素:
- 设备(Device) :存储文件系统的物理载体,如磁盘分区(
/dev/vda1)、磁盘镜像(./disk.img)、U 盘(/dev/sdb1);- 文件系统(File System) :设备上格式化的文件系统类型,如 Ext2、Ext4、NTFS 等(Ext 系列文件系统需指定
-t ext2/ext4);- 挂载点(Mount Point):目录树中的一个空目录,挂载后该目录成为分区文件系统的 "入口"------ 访问该目录及其子目录,本质是访问挂载分区的文件系统。
举个例子:将/dev/sdb1(Ext4 格式的 U 盘分区)挂载到/mnt/usb目录后,访问/mnt/usb/test.txt,实际访问的是 U 盘中的test.txt文件;卸载后,/mnt/usb恢复为普通空目录,不再关联 U 盘分区。
3.2 挂载的底层原理:VFS 与超级块
Linux 内核通过虚拟文件系统(VFS) 实现不同文件系统的统一挂载,其核心原理是:
-
挂载时:
- 内核读取设备的超级块(Super Block),验证文件系统类型(如 Ext4 的魔术数
0xEF53); - 将设备的超级块、inode 位图、块位图等管理结构加载到内存;
- 建立挂载点目录的 dentry 与设备文件系统根目录 inode 的关联 ------ 访问挂载点目录时,实际访问的是设备文件系统的根目录;
- 将挂载信息记录到内核的挂载列表中(
/proc/mounts)。
- 内核读取设备的超级块(Super Block),验证文件系统类型(如 Ext4 的魔术数
-
访问时:
- 当访问路径包含挂载点(如
/mnt/usb/test.txt)时,内核通过挂载列表识别该路径属于挂载分区; - 切换到该分区的文件系统,执行路径解析(如前所述),访问分区内的文件;
- 分区内的 inode 号、块号仅在该分区内有效,内核通过文件系统的超级块进行管理,与其他分区隔离。
- 当访问路径包含挂载点(如
-
卸载时:
- 检查分区是否被进程占用(如当前工作目录在挂载点下),若占用则卸载失败;
- 断开挂载点 dentry 与分区文件系统的关联;
- 释放内存中该分区的超级块、inode、dentry 等缓存;
- 从内核挂载列表中删除该挂载信息。
3.3 循环设备:将文件作为块设备挂载
在实战中,我们常需要将磁盘镜像文件(如disk.img)作为块设备挂载(如测试文件系统),这就需要用到循环设备(Loop Device)。
循环设备是 Linux 内核提供的一种伪设备(Pseudo-device) ,它允许将普通文件映射为块设备,从而可以像访问物理分区一样挂载和使用该文件。Linux 系统中,循环设备的设备文件为/dev/loop0(第一个循环设备)、/dev/loop1(第二个)等,由loop-control(/dev/loop-control)管理。
循环设备的工作流程:
- 将磁盘镜像文件(如
disk.img)与循环设备关联(losetup /dev/loop0 ./disk.img);- 此时,
/dev/loop0成为该镜像文件的块设备接口;- 挂载
/dev/loop0到指定目录(mount /dev/loop0 /mnt/mydisk);- 访问
/mnt/mydisk,本质是访问disk.img中的文件系统;- 卸载后,解除循环设备与镜像文件的关联(
losetup -d /dev/loop0)。
3.4 实战:分区挂载与卸载的完整操作
我们通过 "创建 Ext4 磁盘镜像→关联循环设备→挂载→访问→卸载" 的完整流程,验证分区挂载的原理。
步骤 1:创建 Ext4 磁盘镜像
bash
# 1. 创建5MB的空镜像文件(模拟磁盘分区)
dd if=/dev/zero of=ext4_disk.img bs=1M count=5
# 2. 格式化镜像文件为Ext4文件系统(指定块大小4KB)
mkfs.ext4 -b 4096 ext4_disk.img
# 3. 查看镜像文件的文件系统信息(验证格式化结果)
dumpe2fs ext4_disk.img | grep -E "Filesystem magic|Block size|Inode size"输出示例:
Filesystem magic number: 0xEF53 # Ext4的魔术数,验证文件系统类型
Block size: 4096 # 块大小4KB
Inode size: 256 # inode大小256字节步骤 2:关联循环设备并挂载
bash
# 1. 查看系统中的循环设备(初始状态可能无关联文件)
ls -l /dev/loop* | head -10
# 2. 将镜像文件关联到循环设备(自动分配空闲循环设备)
sudo losetup -f ext4_disk.img
# 3. 查看关联结果(确认镜像文件与哪个loop设备关联)
losetup -a | grep ext4_disk.img
# 输出示例:/dev/loop0: [253:0] (ext4_disk.img)
# 4. 创建挂载点目录(必须是空目录)
sudo mkdir -p /mnt/ext4_test
# 5. 挂载循环设备到挂载点(指定文件系统类型ext4)
sudo mount -t ext4 /dev/loop0 /mnt/ext4_test
# 6. 查看挂载结果(验证挂载成功)
df -h | grep /mnt/ext4_test输出示例:
/dev/loop0 4.9M 24K 4.5M 1% /mnt/ext4_test输出说明:/dev/loop0已成功挂载到/mnt/ext4_test,总容量 4.9MB,已用 24KB,可用 4.5MB。
步骤 3:访问挂载分区
bash
# 1. 在挂载点创建文件(实际写入磁盘镜像)
sudo touch /mnt/ext4_test/test_file.txt
sudo echo "Hello, Ext4 Mount!" > /mnt/ext4_test/test_file.txt
# 2. 查看文件(验证写入成功)
ls -li /mnt/ext4_test/
cat /mnt/ext4_test/test_file.txt输出示例:
2 -rw-r--r-- 1 root root 18 Oct 31 16:30 test_file.txt # inode号为2(分区内唯一)
Hello, Ext4 Mount!步骤 4:卸载分区并解除循环设备关联
bash
# 1. 卸载分区(若当前工作目录在挂载点下,需先退出)
sudo umount /mnt/ext4_test
# 2. 验证卸载结果(/mnt/ext4_test不再关联/dev/loop0)
df -h | grep /mnt/ext4_test # 无输出,说明卸载成功
# 3. 解除循环设备与镜像文件的关联
sudo losetup -d /dev/loop0
# 4. 验证关联解除(/dev/loop0不再关联ext4_disk.img)
losetup -a | grep ext4_disk.img # 无输出,说明解除成功步骤 5:验证镜像文件中的数据(可选)
卸载后,镜像文件中的数据依然存在,我们可以重新挂载验证:
bash
# 重新关联循环设备并挂载
sudo losetup -f ext4_disk.img
sudo mount -t ext4 /dev/loop1 /mnt/ext4_test # 可能分配到loop1
# 查看之前创建的文件
cat /mnt/ext4_test/test_file.txt # 输出:Hello, Ext4 Mount!
# 再次卸载并解除关联
sudo umount /mnt/ext4_test
sudo losetup -d /dev/loop13.5 挂载的关键注意事项
-
挂载点必须是空目录:若挂载点目录非空,挂载后目录中原有的文件会被隐藏(卸载后恢复可见),避免误操作;
-
文件系统类型匹配 :挂载时需指定正确的文件系统类型(
-t ext4),否则内核无法识别,挂载失败; -
权限控制 :挂载普通分区时,默认权限由文件系统的
uid/gid控制;挂载 Windows 分区(NTFS)时,需指定**-o uid=1000,gid=1000**确保普通用户可读写; -
开机自动挂载 :若需分区开机自动挂载,需将挂载信息写入
/etc/fstab文件(格式:设备路径 挂载点 文件系统类型 挂载选项 0 0),示例:bash# 编辑/etc/fstab,添加以下行(需替换设备路径和挂载点) /dev/sdb1 /mnt/usb ext4 defaults 0 2 -
强制卸载 :若分区被进程占用导致卸载失败,可使用umount -l(lazy 卸载,等待进程释放后自动卸载)或umount -f(强制卸载,可能导致数据丢失,慎用)。
四、文件系统总结:Ext 系列的核心运作逻辑
通过前面的讲解,我们可以将 Ext 系列文件系统的核心运作逻辑总结为**"三大支柱 + 两大机制"**,形成完整的存储生态:
4.1 三大支柱:文件存储的基础
- 硬件层:磁盘的物理结构(盘片、磁头、柱面、扇区)提供存储载体,LBA 地址屏蔽物理细节,为文件系统提供统一的扇区访问接口;
- 块与 inode:块是文件存储的最小单位(由多个扇区组成),inode 是文件的 "身份证"(存储属性和块指针),实现属性与内容的分离存储;
- 块组结构:分区被划分为多个块组,每个块组包含超级块、GDT、位图、inode 表、数据块,通过 "分而治之" 提高管理效率和可靠性。
4.2 两大机制:文件访问的保障
- 路径解析与缓存:路径解析从根目录出发,层层定位目标文件;路径缓存将解析结果加载到内存(dentry+inode),减少磁盘 IO,加速访问;
- 分区挂载:通过 VFS 将多个独立分区整合进统一目录树,挂载点作为分区入口,实现多分区的统一访问,解决 "存储孤岛" 问题。
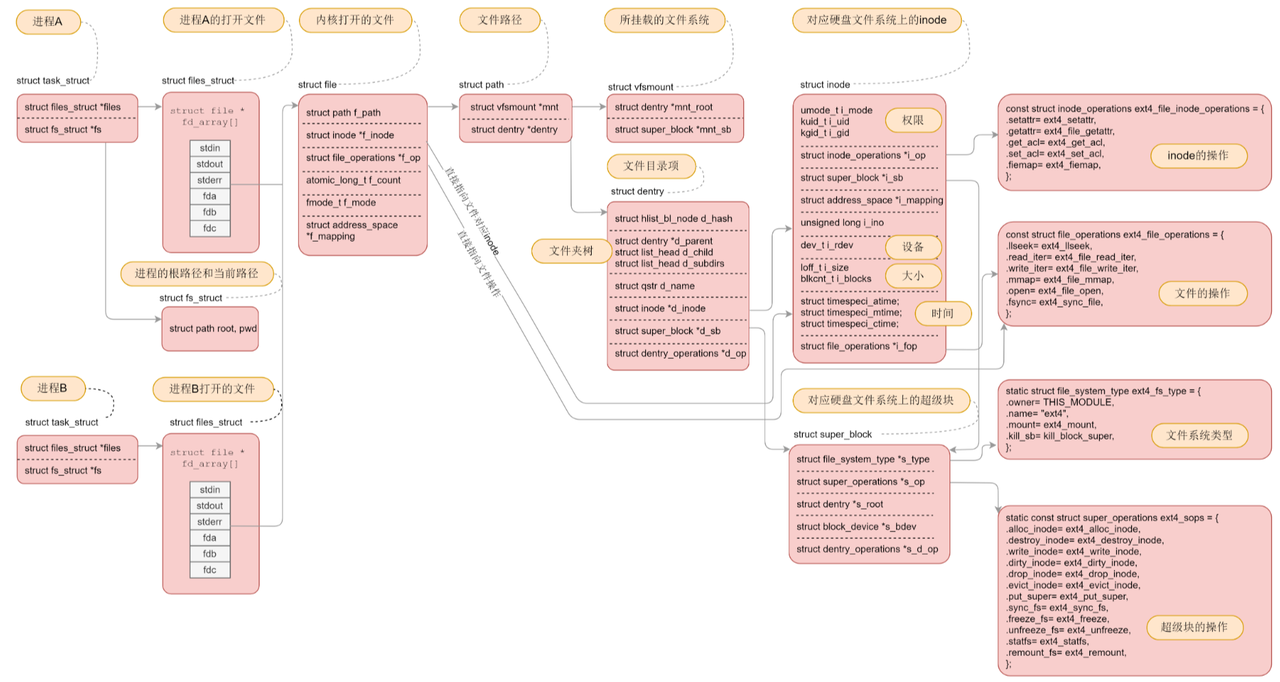
4.3 完整运作流程(以创建并访问文件为例)
我们以touch /home/opchen/test.txt && cat /home/opchen/test.txt为例,串联 Ext 文件系统的完整运作流程:
-
创建文件(touch):
- 内核解析路径
/home/opchen,找到该目录的 inode 和数据块; - 从 inode 位图中分配空闲 inode,写入文件属性(权限、创建时间等);
- 从块位图中分配空闲块(若文件为空,可能不分配数据块);
- 在
/home/opchen的数据块中添加目录项(test.txt→新 inode 号); - 更新超级块和块组描述符的空闲 inode 数、空闲块数。
- 内核解析路径
-
访问文件(cat):
- 内核解析路径
/home/opchen/test.txt,优先从 dentry 缓存查找,命中则直接获取 inode; - 若缓存未命中,执行路径解析,从根目录层层找到
test.txt的 inode; - 通过 inode 的
i_block字段找到数据块,读取文件内容并输出; - 将路径解析结果(dentry+inode)加入缓存,方便下次访问。
- 内核解析路径
-
底层硬件交互:
- 文件系统的块读写最终映射为 LBA 地址的扇区读写;
- 磁盘固件将 LBA 地址转换为 CHS 地址,控制磁头、磁头臂移动,完成数据的物理读写。
用一张图总结如下:
4.4 Ext2/Ext3/Ext4 的演进关系
Ext 系列文件系统的核心设计(块组、inode、路径解析、挂载机制)保持一致,后续版本的演进主要是功能增强:
- Ext2:基础版本,无日志功能,崩溃后恢复较慢;
- Ext3:在 Ext2 基础上增加日志功能(Journal),记录文件系统的变更,崩溃后可快速恢复;
- Ext4:进一步优化,支持更大的文件和分区(单文件最大 16TB,分区最大 1EB)、目录项哈希排序(HTree)、延迟分配、在线扩容等功能,是当前 Linux 系统的主流文件系统。
总结
理解 Ext 文件系统的底层原理,不仅能帮助我们更好地使用 Linux 系统(如排查存储问题、优化存储性能),更能培养 "透过现象看本质" 的技术思维 ------ 当我们知道
ls命令背后是 inode 和目录项的读取,cd命令背后是路径解析和 dentry 缓存,就能更深刻地理解操作系统的运作逻辑。在后续的文章中,我们将继续探讨 Ext 文件系统的进阶内容:软硬链接的实现原理、文件的删除与恢复机制、Ext4 的日志功能等。如果大家有任何疑问或想了解的内容,欢迎在评论区留言讨论!
最后,感谢大家的阅读!如果这篇文章对你有帮助,别忘了点赞、收藏、转发哦~