机器学习本质
机器学习(Machine Learning) 是让计算机从数据中自动学习规律、模式,无需人工逐条编写复杂规则,从而完成回归(Regression)、分类(Classification)、结构化学习(Structured Learning)、聚类(Cluster)等任务,并随数据增多不断优化性能的技术。
简单来说,机器学习就是让机器找一个函数来将输入转换为我们想要的输出,即
Machine Learning ≈ Looking for Function。
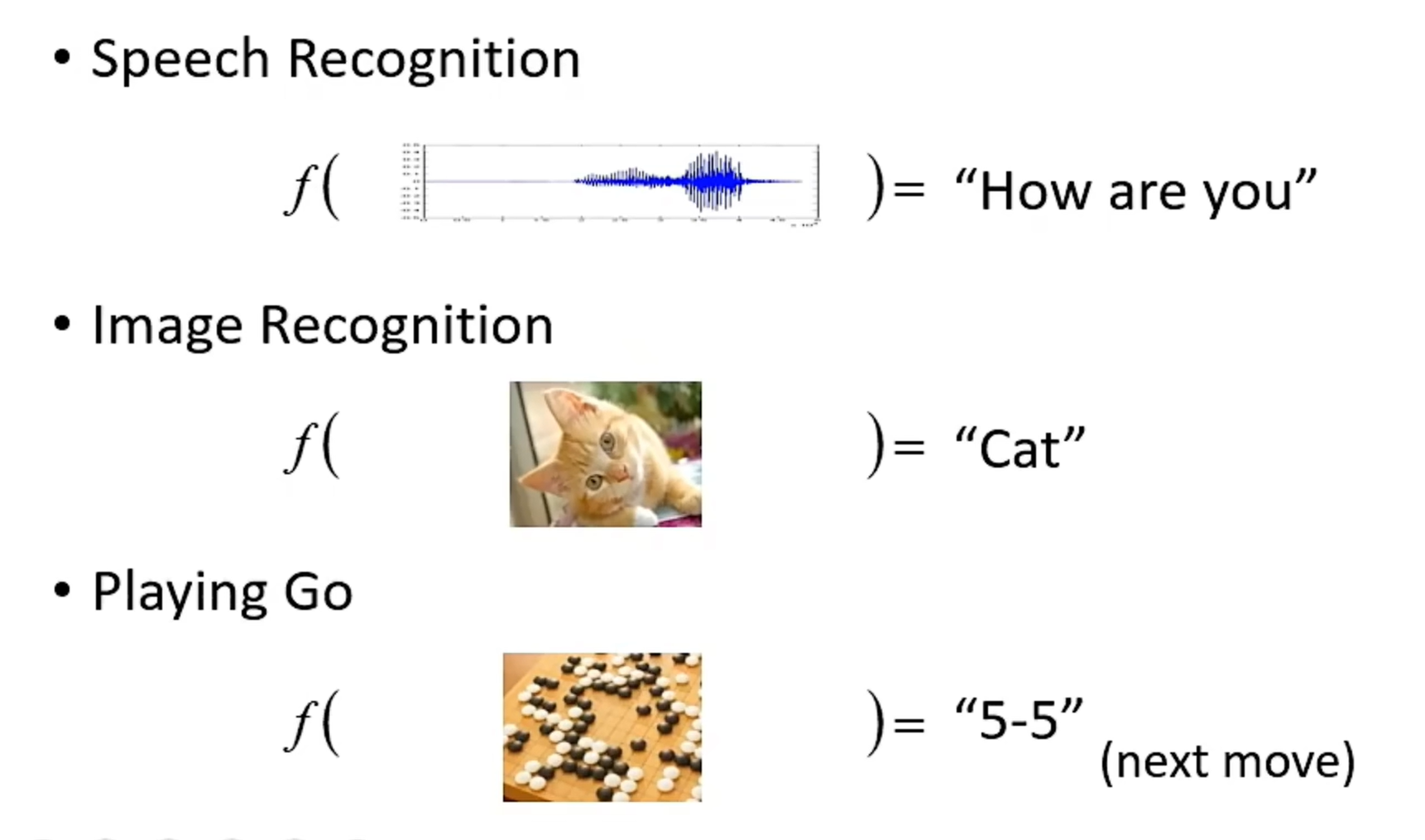
这个函数的输入可以是向量、矩阵(图像)、序列(语音识别、翻译等),输出可以是一个数值、类别、图像甚至是一篇文章。(深度学习是机器学习的一部分,它要找的函数是由神经网络组成的)
⭐⭐⭐机器学习分类(三个维度)
按技术代际分类, 机器学习整体分为传统机器学习 和**深度学习(Deep Learning)**两大技术流派。
- 传统机器学习: 不依赖深度神经网络,依赖人工设计特征(如传感器数据的均值、方差、频域特征)。模型结构为浅层(1-3 层,如线性模型、单决策树等)。少量数据即可训练(几百~几万样本)。通过手工提取特征 + 浅层模型训练实现预测、分类、聚类等任务。
(*选读)主要分为 6 大核心分支,每个分支都有成熟的经典模型- 线性模型:用线性关系拟合特征与目标的映射。典型模型如线性回归(回归任务)、逻辑回归(分类任务)、岭回归/Lasso回归
- 核方法:通过核函数将低维线性不可分数据映射到高维空间,实现非线性分类/回归。典型模型如支持向量机(SVM)、核PCA
- 树模型与集成学习:基于决策树的分层决策规则,集成学习(组合多个弱模型)大幅提升精度,抗噪、可解释、适配结构化数据。典型模型如决策树(单模型)、随机森林、XGBoost/LightGBM/CatBoost
- 概率图模型:用概率图描述变量间的依赖关系,解决不确定性推理、序列数据问题,是早期机器人规划、NLP 的核心。典型模型如贝叶斯网络、隐马尔可夫模型(HMM)、条件随机场(CRF)
- 聚类与降维:从无标签数据中挖掘内在结构,是数据预处理、异常检测、场景分群的基础。典型模型如K-Means、DBSCAN、层次聚类(HC)、PCA、LDA
- 近邻方法:"物以类聚",通过距离度量(如欧氏距离)找相似样本,无需复杂训练,适合简单分类 / 回归。典型模型如K近邻(KNN)
- **深度学习:**基于多层神经网络,模型自动提取特征。模型结构为深层(几十/上百层,如 CNN、Transformer、LSTM) 。需要海量数据(百万 + 样本)才能发挥优势
按学习范式分类, 机器学习可分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning):
- 监督学习: 从带标签数据(输入 + 期望输出)中学习映射关系,目标是「预测 / 分类」。
数据特点是X(特征)+ Y(标签 / 真值),如「图像(X)→ 猫 / 狗(Y)」「传感器数据(X)→ 故障 / 正常(Y)」。 - 无监督学习: 从无标签数据中挖掘内在结构、模式,目标是「发现规律」。
数据特点是仅 X(特征),无 Y
主要用于聚类/降维(K-Means、PCA),自监督学习(SSL)也属于无监督学习。 - **强化学习:**智能体(Agent)在环境中通过「动作 - 奖励」循环试错,学习最优策略,目标是「最大化长期奖励」。
**⭐自监督学习(Self-supervised Learning,SSL):**自监督学习是无监督学习的重要分支,无需人工标注的标签数据,而是从数据自身的结构、关联、属性中自动构造监督信号(伪标签 / 代理任务),驱动模型学习数据的通用特征表示,是一种利用无标注数据做监督式训练的范式。
- 代理任务: 自监督学习并不是直接将数据(图像、语句等)扔给机器。而是需要设定一个任务,驱使模型学习图像通用特征。
之所以使用代理任务,是因为深度神经网络的训练必须依赖可计算的优化目标(损失函数),没有任务就没有损失函数,没有损失就无法做梯度下降,参数永远不会更新,模型根本学不到任何特征。 - (*选读)代理任务的训练过程: 以CV领域的MAE掩码图像建模任务为例:拿一张无任何人工标注的猫咪照片,任务是随机遮掉图片 75% 的像素块,只留少量可见区域,让模型只看可见部分,预测被遮掉的像素长什么样。
- MAE(Masked AutoEncoder)是基于 Vision Transformer(ViT) 的掩码自监督模型。其中有两个重要的Transformer神经网络模块------编码器和解码器。两者的参数都是随机初始化的,训练前没有任何预存的图像规律。其中编码器负责从可见的图像块中提取高维语义特征;解码器则负责把编码器特征和掩码占位符映射回像素空间,完成掩码区域像素重建。训练完成时编码器保留作为通用特征编码器用于下游任务(Downstream Tasks);解码器则直接丢弃,仅服务于代理任务。
- MAE预测遮挡图像的整个过程是 **"随机初始化→随机预测产生误差→梯度更新修正参数→迭代习得图像规律→精准重建像素"**的迭代优化过程,这也是深度学习的通用训练逻辑。下面以单张图像训练为例,拆解"前向预测→计算损失→反向更新"的全流程:
- **1.图像分块+高比例掩码:**输入一张无标注原图,按 ViT 方式切分为不重叠的图像块(Patch),比如 224×224 图像切为196个 16×16 的 Patch。接下来随机掩码75%~90% 的 Patch,只保留少量可见 Patch。掩码位置不输入像素,而是用可学习的 Mask Token(占位向量) 替代。
- 2.编码器提取可见块特征: 将可见 Patch转为向量序列,并输入编码器做特征提取,输出可见区域的特征序列
。(在训练初期编码器参数随机,提取的可见区域的特征序列为无意义的随机序列
- 3.解码器拼接特征,执行像素预测: 把编码器输出的可见特征
- **4.计算重建损失,反向传播更新参数:**只对掩码区域计算均方误差损失(MSE),损失梯度同时传递给编码器和解码器,两个模块的参数同步被更新,向「让预测像素更接近真实像素」的方向调整。
- 5.迭代训练,逐步习得图像规律: 重复上述步骤数万~数十万次,随着迭代,编码器的特征提取能力越来越强,能精准捕捉图像的空间结构、上下文关联、语义信息;解码器能基于编码器的有效特征,越来越准确地推理掩码像素;模型最终习得通用视觉规律,损失收敛到较小值。(参数的持续优化,让模型逐渐记住图像的底层规律(比如毛发的纹理连续性、物体的轮廓闭合性、场景的空间布局),这些规律被编码在神经网络的权重参数中)
- (*选读)代理任务(拓展): 代理任务在CV领域不只有MAE掩码预测,还有图像旋转预测、拼图还原、对比学习等,在NLP领域还有BERT掩码语言模型等。这些代理任务的核心目的都是通过构造伪监督信号和定义可计算损失,给模型设定优化目标,倒逼模型从无标注图像中学习通用特征,只是侧重学习的通用特征不同。
绝大多数训练场景只适用一种代理任务。使用时具体选择哪种代理任务要根据下游任务、数据规模、算力资源、模型架构等综合考虑。 - **伪标签:**上述MAE中被遮挡区域的原始真实像素,就是模型训练的伪标签。
- 通用特征编码器: 自监督训练完成后,剥离代理任务的预测头(如像素预测分支解码器),保留的神经网络主干,它的核心任务是将原始输入数据(图像张量 / 文本序列)映射为包含数据通用规律的特征向量 / 特征图,这个特征不绑定任何具体下游任务,能适配分类、检测、分割等各类场景。
它是一组训练完成、参数固定的深度神经网络,可看作一个输入到特征的向量值函数,数学形式可写成 - 预训练模型(Pre-trained Model or Foundation Model): 可迁移复用的预训练模型 = 训练好的通用特征编码器 + 模型配置 / 参数封装。
下游任务使用时,给编码器拼接对应任务的预测头(如分类头、检测头),就构成了完整的下游任务模型。
**按深度学习基础网络架构(Backbone,骨架)分类:**基础网络架构≠PyTorch/TensorFlow 这类代码开发框架。它是深度学习中通用、可复用的神经网络底层结构,它定义了神经网路的层数、层间连接、核心计算算子、权重规则等。初始化时权重随机,是无功能的结构模板,可被复用为任意功能模块。主要包括CNN、Transformer、GNN、RNN等:
- CNN(卷积神经网络)------ 图像 / 网格数据的经典架构: 面向图像网格数据的卷积神经网络范式,它只定图像特征提取的底层范式、核心算子与权重规则,不定具体层数、卷积核数量等超参。CNN家族包括LeNet-5、AlexNet、VGG、ResNet等模型,这些模型相同的是核心算子(必用卷积、池化作为特征提取主力)、卷积、权重共享、局部感受野、分层特征提取,不同的是卷积核尺寸、网络深度、层间连接、训练技巧、参数量效率。
CNN适用于所有计算机视觉(CV)基础任务。 - **RNN(循环神经网络)------ 时序 / 序列数据的早期架构:**专为时序 / 序列数据(文本、语音、时间序列)设计,按序列顺序递归处理,保留历史信息记忆,解决序列数据的时序依赖问题。目前已被Transformer全面替代
- **Transformer ------ 大一统通用架构(目前主流):**基于自注意力机制(Self-Attention),不依赖递归 / 卷积,直接建模全局依赖关系,并行处理序列 / 网格数据,兼顾长距离依赖与训练效率,是文本、图像、语音、多模态通用的大一统架构。Transformer家族包括BERT、GPT系列、ViT。其全领域通用,NLP、CV、语音、多模态、AI 生成,是当前大模型的唯一底层架构。
- **GNN(图神经网络) ------ 图结构数据专属阔框架:**图数据专属,如知识图谱、推荐系统、金融反欺诈、蛋白质结构预测、社交网络分析。
- **GAN(生成对抗网络)------ 生成式专用架构:**特殊的对抗训练架构,由生成器 G + 判别器 D组成。G 生成假数据,D 判别真假,二者博弈优化,最终学习真实数据分布,专门用于生成高逼真新数据。适用于AI 生成内容 (AIGC)、图像编辑、数据增强、超分辨率、虚拟形象生成等。
(*选读)使用时的一般步骤是:
- **匹配任务
- **架构实例化
- **拼接任务头
- **选择训练模式:**第一种模式是使用随机初始化的权重参数,这时要使用海量无标注数据进行预训练得到专属预训练模型,然后拼接下游任务头,然后进行微调部署(预训练的目标是让骨干学到通用特征,预训练完成后会丢弃自监督的代理任务头);第二种模式是使用公开训练好的参数,直接拼接下游任务头进行微调部署。
- **设定训练策略(冻结/微调):**根据数据量选择骨干参数的训练方式,如果是小数据集冻结骨干预训练参数,只训练任务头(避免过拟合);如果是大数据集,则对骨干和任务头都进行微调,让特征适配下游任务。如果是自监督场景则仅训练骨干完成代理任务,再丢弃代理头,拼接下游任务头微调。
- **训练迭代
- 模型评估
- 部署 / 迁移复用
所有基础网络架构的本质都是特征提取器,区别仅适配数据结构不同。预训练模型,就是这些基础架构 + 自监督 / 监督预训练后的成品,直接复用即可快速落地下游任务。