
🎁个人主页:User_芊芊君子
🎉欢迎大家点赞👍评论📝收藏⭐文章
🔍系列专栏:AI


【前言】
哈喽,各位想入门AI的小伙伴!随着生成式AI、大模型应用的爆发,
Python+AI已成为最热门的技术组合,无论应届生求职、职场人转型还是兴趣探索,掌握这门技能都能打开新赛道。但很多新手都会陷入"先学Python还是先学AI""数学不好能不能学""学完不会实战"的困境。本文结合2026年AI技术趋势,用「知识点+核心代码+流程图+表格」的形式,从零基础打通Python+AI入门全链路,聚焦热门易上手方向,全程干货,新手可直接跟着练,老司机可查漏补缺~

一、为什么2026年入门AI,首选Python?
很多新手会问:"学AI一定要用Python吗?Java、C++不行吗?" 答案是:不是不行,但Python是效率最高、门槛最低、生态最完善的选择,尤其是2026年,这3个优势更加突出,新手必看:
核心亮点:2026年AI圈的"共识"------Python是大模型应用开发、轻量化AI项目落地的首选语言,无需深厚编程基础,就能快速对接AI工具链,甚至用AI辅助自己学Python+AI。
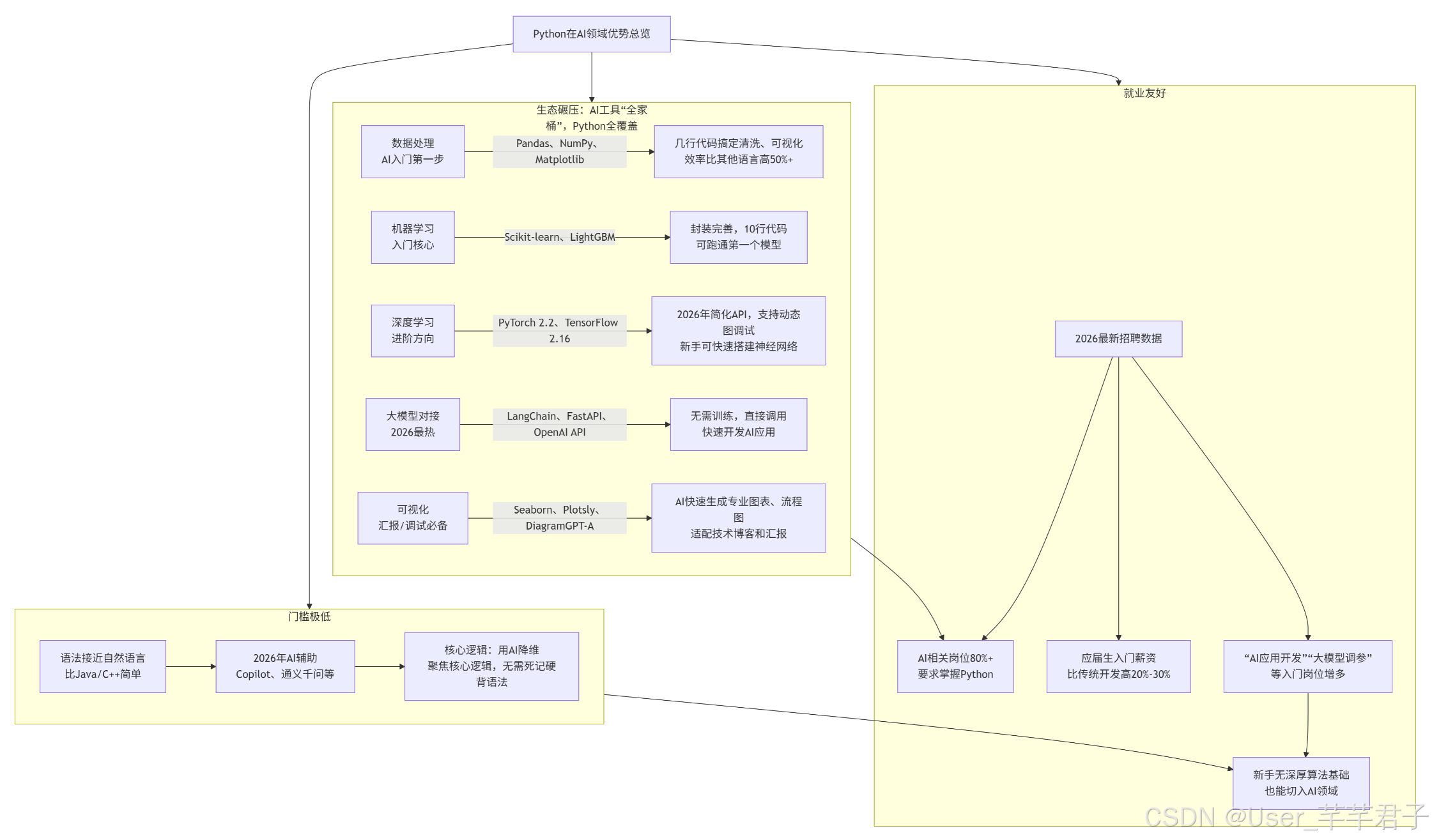
1. 生态碾压:AI工具"全家桶",Python全覆盖
AI开发的核心需求(数据处理、模型训练、模型部署、大模型对接),Python都有成熟库和框架,无需重复造轮子,且2026年新增诸多轻量化工具,新手上手更简单:
| AI开发场景 | Python核心工具(2026热门) | 优势说明 |
|---|---|---|
| 数据处理(AI入门第一步) | Pandas、NumPy、Matplotlib | 几行代码搞定数据清洗、可视化,效率比其他语言高50%+ |
| 机器学习(入门核心) | Scikit-learn、LightGBM | 封装完善,新手10行代码可跑通第一个机器学习模型 |
| 深度学习(进阶方向) | PyTorch 2.2、TensorFlow 2.16 | 2026年简化API,支持动态图调试,新手可快速搭建神经网络 |
| 大模型对接(2026最热) | LangChain、FastAPI、OpenAI API | 无需训练大模型,直接调用开源/商用大模型,快速开发AI应用 |
| 可视化(汇报/调试必备) | Seaborn、Plotly、DiagramGPT-AI | 快速生成专业图表、流程图,适配技术博客和汇报场景 |
2. 门槛极低:语法简洁,AI辅助提效
Python语法接近自然语言,比Java、C++简单得多,且2026年可通过Copilot、通义千问等AI工具辅助写代码、调试bug,新手无需为"卡代码"发愁。核心逻辑是:用AI降维,聚焦核心逻辑,无需死记硬背语法。
3. 就业友好:岗位需求量第一,薪资可观
2026年最新招聘数据显示,AI相关岗位(机器学习工程师、AI开发工程师等)中,80%以上要求掌握Python,应届生入门薪资比传统开发高20%-30%,且"AI应用开发""大模型调参"等入门岗位增多,新手无深厚算法基础也能切入。
二、Python+AI入门必备前提
新手最易陷入的坑:"学AI必须先啃完高数、线代、概率论"。其实2026年AI入门核心是"先会用、再懂原理",前提知识只需掌握核心要点,具体如下:
1. 数学基础:掌握3个核心模块
无需啃完整本教材,重点抓AI入门必备知识点,可边学AI边补数学:
-
线性代数:核心是「矩阵运算」(加减乘除、转置),知道"AI模型本质是矩阵运算"即可;
-
概率论:重点是「概率分布、期望、方差」,理解"模型的不确定性";
-
微积分:只需掌握「导数、梯度下降基本原理」,了解模型优化逻辑。
推荐学习方式:边学AI案例边补数学,比如学线性回归时,再补梯度下降知识点,更具针对性。
2. 环境准备:10分钟搭建Python+AI开发环境
环境搭建是新手第一道坎,以下是Windows/Mac通用方案,步骤简洁可直接跟随:
步骤1:安装Python(3.10-3.12版本,最稳定)
官网下载对应版本,安装时勾选「Add Python to PATH」,安装后通过python --version验证是否成功。
步骤2:安装核心AI库(pip一键安装)
打开cmd/终端,输入以下命令,安装2026年最新兼容版本,避免版本冲突:
python
# 升级pip+核心库一键安装
pip install --upgrade pip
pip install numpy==1.26.4 pandas==2.2.1 matplotlib==3.8.4 seaborn==0.13.2 scikit-learn==1.4.2
# 深度学习库二选一(新手首选PyTorch)
pip install torch==2.2.1 torchvision==0.17.1 # PyTorch(推荐)
# pip install tensorflow==2.16.1 # TensorFlow(备选)
# 大模型对接+AI绘图库(必装)
pip install langchain==0.1.10 openai==1.13.3 fastapi==0.110.0 diagramgpt-ai==0.2.0步骤3:选择开发工具(新手首选PyCharm Community)
下载PyCharm免费社区版,默认安装后,新建Python项目并选择对应解释器,即可开始开发。
三、Python基础快速通关(AI方向专属,不做无用功)
AI方向的Python基础,无需深入高级特性,只需掌握"核心语法+AI常用模块",重点是"能写AI代码、处理数据",具体如下(附核心代码):
1. 核心语法:掌握这5个模块,够用就行
聚焦AI开发常用语法,无需冗余学习,核心要点如下:
(1)变量、数据类型、运算符
重点掌握列表、字典操作(用于存储数据),核心代码如下:
python
# AI开发常用变量与数据类型
age = 25 # 整数(标签/数量)
score = 89.5 # 浮点数(预测值/准确率)
features = [1.2, 3.4, 5.6] # 特征数据
model_params = {"learning_rate": 0.01, "accuracy": 0.89} # 模型参数
# 常用操作
print(features[0], model_params["accuracy"])
features.append(9.0)(2)条件判断、循环
核心是for循环(遍历数据)和if-else(逻辑判断),核心代码如下:
python
# 循环遍历+逻辑判断(AI常用)
data = [10, 20, 30, 40, 50]
processed_data = [num*2 for num in data] # 简化遍历
# 模型效果判断
accuracy = 0.85
if accuracy >= 0.8:
print("模型效果良好")
elif accuracy >= 0.7:
print("模型需优化")
else:
print("重新训练模型")(3)函数(封装复用逻辑)
封装数据预处理、模型评估等逻辑,核心代码如下:
python
# 数据标准化+模型评估核心函数
def standardize_data(data):
mean = sum(data)/len(data)
std = (sum([(x-mean)**2 for x in data])/len(data))**0.5
return [(x-mean)/std for x in data]
def evaluate_model(true_labels, pred_labels):
correct = sum(1 for t,p in zip(true_labels,pred_labels) if t==p)
return correct/len(true_labels)(4)列表推导式、字典推导式
快速处理数据,效率高于普通循环,核心代码如下:
python
# 推导式快速处理数据(AI高频使用)
data = [1,2,3,4,5,6]
filtered_data = [x for x in data if x>3] # 筛选特征
feature_dict = {f:v for f,v in zip(["age","height"], [25,175])} # 构建特征字典(5)异常处理(try-except)
避免程序崩溃,定位bug,核心代码如下:
python
# AI开发常用异常处理(读取数据/模型训练)
import pandas as pd
try:
data = pd.read_csv("data.csv")
if data.empty:
raise ValueError("数据为空,无法训练")
except FileNotFoundError:
print("文件不存在,请检查路径")
except Exception as e:
print("异常:", e)2. AI方向专属Python基础:重点掌握2个模块
重点掌握文件操作和模块导入,核心代码如下:
python
# 模块导入+文件操作(AI核心基础)
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 读写CSV(AI最常用数据格式)
data = pd.DataFrame({"age":[25,26],"income":[5000,6000]})
data.to_csv("processed_data.csv", index=False)
loaded_data = pd.read_csv("processed_data.csv")3. Python基础通关标准(新手自测)
无需刷大量习题,完成以下3件事即达标,可进入AI学习:
-
能用列表、字典存储数据,用循环、推导式处理批量数据;
-
能封装简单函数(数据预处理、模型评估);
-
能读写CSV/文本文件,导入使用numpy、pandas库。
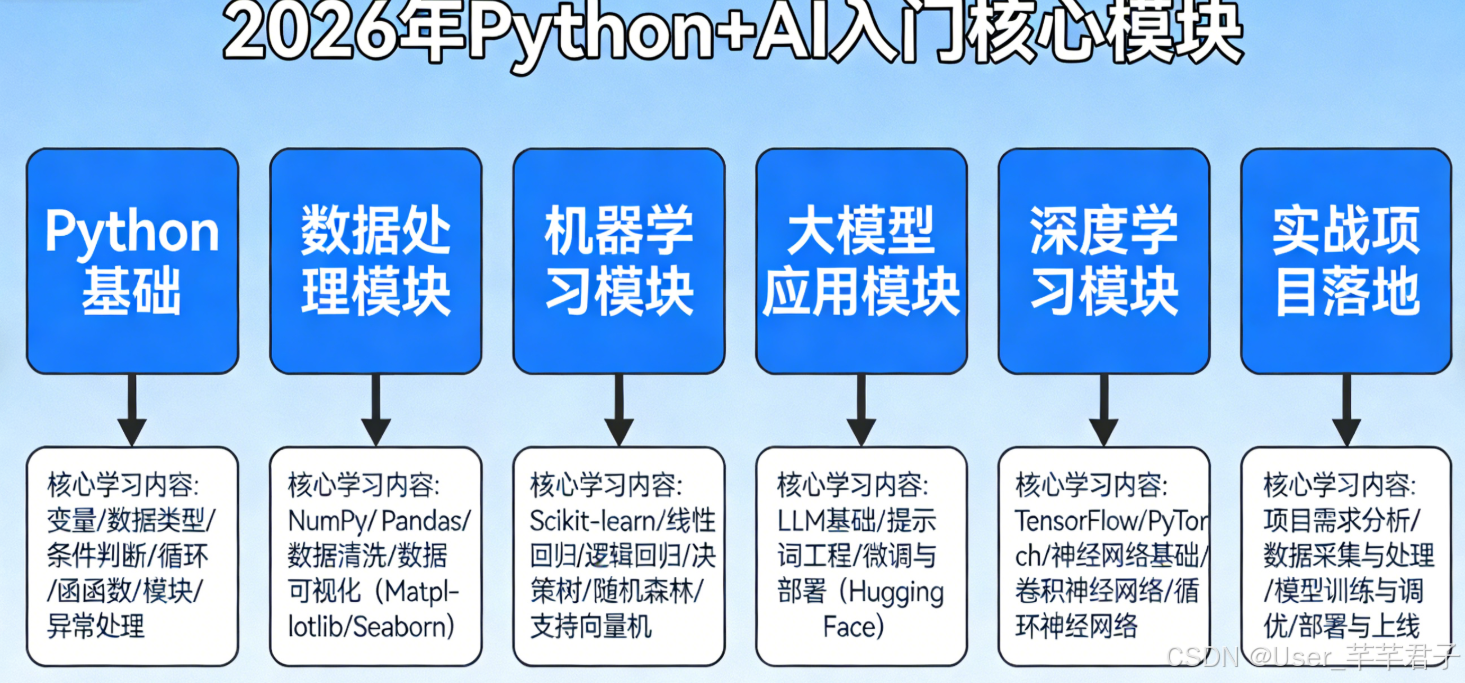
四、AI入门核心模块(2026热门方向,从易到难)
Python基础达标后,最佳学习路径:数据处理 → 机器学习 → 大模型应用,循序渐进,避免一开始啃复杂深度学习模型。
Python+AI入门核心模块流程图,清晰掌握学习顺序:
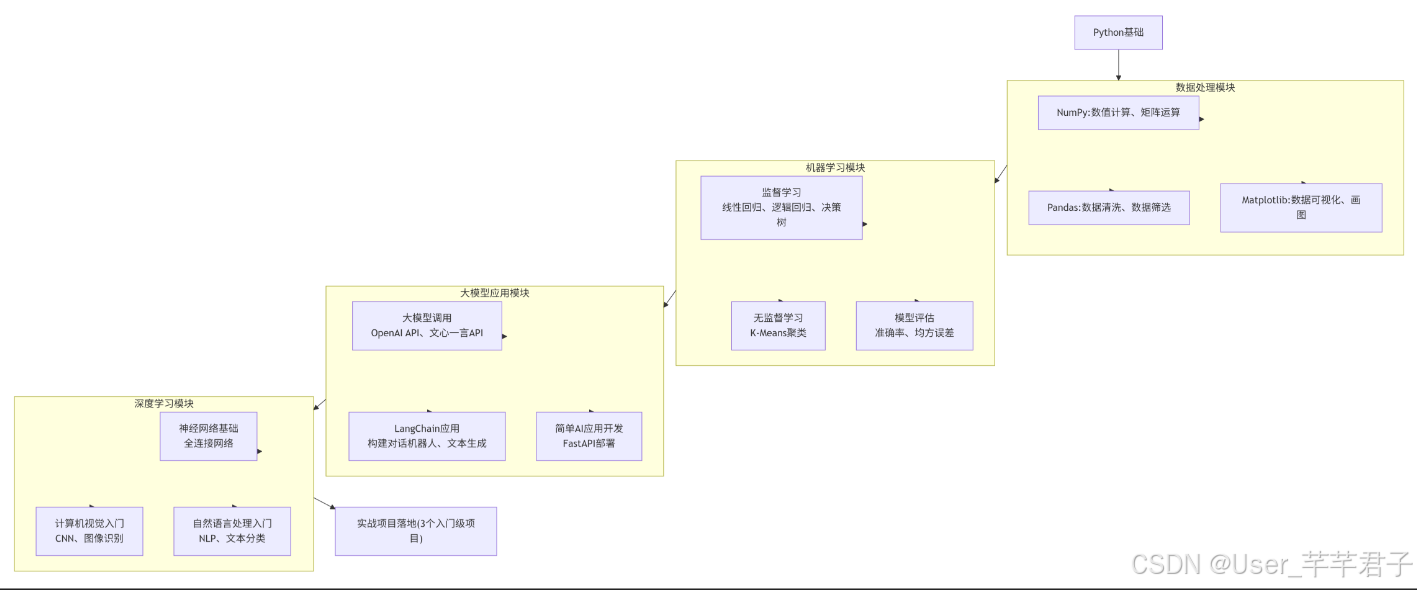
图2:2026年Python+AI入门核心模块流程图(新手必看)
1. 模块1:数据处理(AI入门第一步,重中之重)
AI核心是数据,80%的AI开发时间用于数据处理,重点掌握NumPy、Pandas、Matplotlib核心用法(附核心代码):
(1)NumPy:数值计算基础
python
# NumPy核心用法(AI入门必备)
import numpy as np
# 特征矩阵、标签向量创建
feature_matrix = np.array([[1.2,3.4],[5.6,7.8]])
labels = np.array([0,1,0])
# 核心运算+数据预处理
print(np.dot(feature_matrix, feature_matrix.T)) # 矩阵点乘
print(np.mean(feature_matrix, axis=0)) # 特征均值
data = np.array([[1,2],[np.nan,4]])
data[np.isnan(data)] = np.nanmean(data) # 缺失值填充(2)Pandas:数据清洗神器
python
# Pandas核心用法(数据预处理)
import pandas as pd
import numpy as np
df = pd.DataFrame({"age":[25,np.nan,27],"gender":["male","female"],"income":[5000,8000,7000]})
# 数据清洗
df_clean = df.dropna() # 删除缺失值
df_clean["gender_encoded"] = df_clean["gender"].map({"male":0,"female":1}) # 特征编码
# 特征转换+保存
df_clean["income_norm"] = (df_clean["income"]-df_clean["income"].min())/(df_clean["income"].max()-df_clean["income"].min())
df_clean.to_csv("clean_data.csv", index=False)(3)Matplotlib:数据可视化
python
# Matplotlib核心用法(AI可视化)
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei']
data = pd.read_csv("clean_data.csv")
# 直方图(特征分布)+ 散点图(特征相关性)
plt.hist(data["age"], bins=5, color="skyblue")
plt.scatter(data["age"], data["income"], c=data["gender_encoded"])
plt.show()2. 模块2:机器学习(AI入门核心,2026最易就业方向)
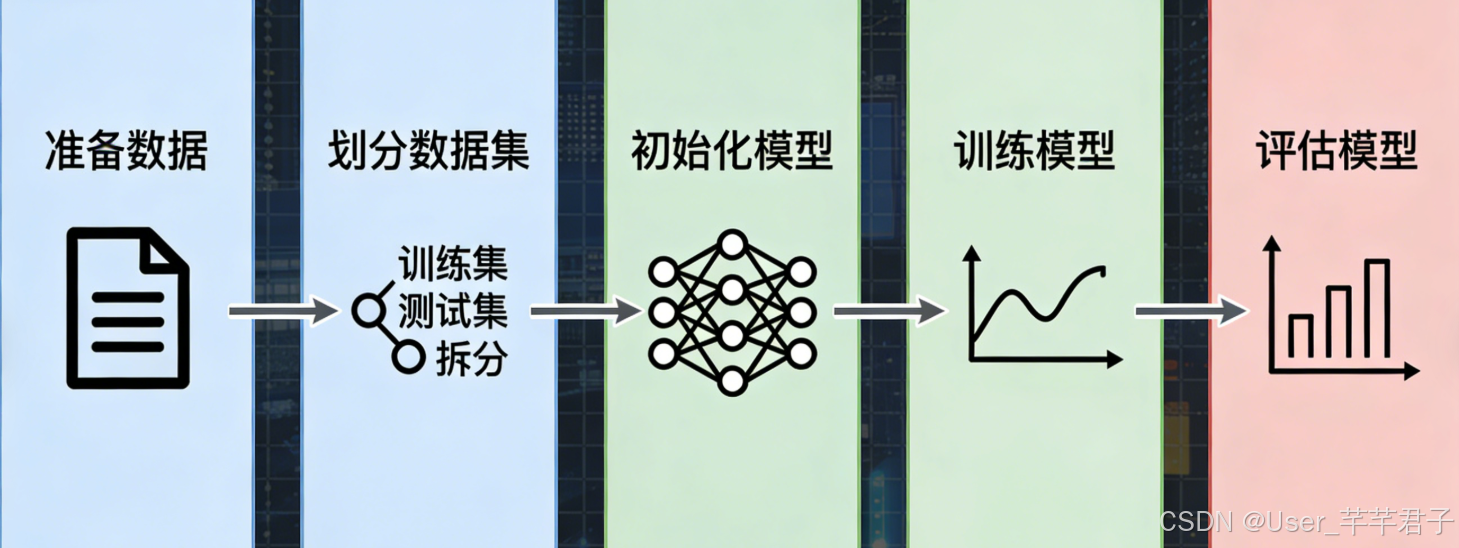
无需深厚算法基础,用Scikit-learn可快速实现模型,重点掌握监督学习,其次是无监督学习,核心逻辑:喂数据→学规律→做预测。
(1)机器学习入门核心流程(必记)
-
准备数据:清洗、预处理;
-
划分数据集:训练集(80%)+ 测试集(20%);
-
初始化模型:导入Scikit-learn对应模型;
-
训练模型:fit()方法;
-
评估模型:根据任务选择评估指标,优化调整。
(2)2026年新手必学3个机器学习模型(附核心代码)
① 线性回归(回归任务,预测连续值)
python
# 线性回归核心代码(房价预测)
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
# 数据准备+划分
data = pd.DataFrame({"area":[50,60,70],"price":[100,120,140]})
X, y = data[["area"]], data["price"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练+评估+预测
model = LinearRegression()
model.fit(X_train, y_train)
print(f"R²分数:{r2_score(y_test, model.predict(X_test)):.4f}")
print(f"150㎡房价预测:{model.predict([[150]])[0]:.2f}万元")② 逻辑回归(分类任务,预测离散值)
python
# 逻辑回归核心代码(购买预测)
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
# 数据准备+预处理
data = pd.DataFrame({"age":[25,28,32],"income":[5000,9000,12000],"purchase":[0,1,1]})
X, y = data[["age","income"]], data["purchase"]
X_scaled = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 模型训练+评估+预测
model = LogisticRegression()
model.fit(X_train, y_train)
print(f"准确率:{accuracy_score(y_test, model.predict(X_test)):.4f}")③ K-Means聚类(无监督学习,用户分群)
python
# K-Means核心代码(用户分群)
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 数据准备+标准化
data = pd.DataFrame({"consumption":[100,300,800],"frequency":[2,4,6]})
X_scaled = StandardScaler().fit_transform(data[["consumption","frequency"]])
# 聚类+确定最佳K(肘部法则简化)
kmeans = KMeans(n_clusters=3, random_state=42)
data["cluster"] = kmeans.fit_predict(X_scaled)
print(data[["consumption","frequency","cluster"]])五、实战案例:3个入门级AI项目(附核心可运行代码)
结合前文知识点,3个入门级项目,覆盖回归、分类、无监督学习,核心代码简洁可直接运行,快速实现实战落地:
案例1:房价预测(线性回归,回归任务)
python
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 1. 数据准备(模拟真实房价数据)
data = pd.DataFrame({
"area": [50,60,70,80,90,100,110,120],
"price": [100,120,145,160,185,200,225,240]
})
X, y = data[["area"]], data["price"]
# 2. 划分数据集+训练模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
# 3. 可视化+预测
plt.scatter(X, y, color="blue")
plt.plot(X, model.predict(X), color="orange")
plt.show()
print(f"130㎡房价预测:{model.predict([[130]])[0]:.2f}万元")案例2:用户购买行为预测(逻辑回归,分类任务)
python
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. 数据准备
data = pd.DataFrame({
"age": [25,26,27,28,29,30,31,32],
"income": [5000,6000,7500,8000,9000,10000,11000,12000],
"purchase": [0,0,0,1,1,1,0,1]
})
X, y = data[["age","income"]], data["purchase"]
# 2. 预处理+模型训练
X_scaled = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
# 3. 预测新用户
new_user = StandardScaler().transform([[27,7800]])
print(f"新用户购买预测:{'会' if model.predict(new_user)[0]==1 else '不会'}")案例3:电商用户分群(K-Means,无监督学习)
python
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 1. 数据准备(用户消费数据)
data = pd.DataFrame({
"consumption": [100,200,300,400,500,600,700,800],
"frequency": [2,3,1,4,2,5,3,6]
})
X = data[["consumption","frequency"]]
# 2. 标准化+聚类
X_scaled = StandardScaler().fit_transform(X)
kmeans = KMeans(n_clusters=3, random_state=42)
data["cluster"] = kmeans.fit_predict(X_scaled)
# 3. 可视化分群结果
plt.scatter(data["consumption"], data["frequency"], c=data["cluster"], cmap="coolwarm")
plt.xlabel("消费金额")
plt.ylabel("消费频率")
plt.show()六、新手避坑指南+学习资源推荐(高效提速)
1. 新手必避90%的坑(2026年最新总结)
坑1:先啃完高数再学AI------正确做法:边学AI案例边补核心数学知识,够用即可;
坑2:Python基础学完再学AI------正确做法:掌握核心语法(本文第三部分)后,直接结合AI案例练手;
坑3:盲目学深度学习、大模型------正确做法:先学数据处理+机器学习,循序渐进;
坑4:只看不动手------正确做法:每学一个知识点,运行对应核心代码,避免"眼会手不会";
坑5:忽视数据预处理------正确做法:记住"数据决定模型上限",优先学好Pandas、NumPy。
2. 2026年最新学习资源推荐(免费+高效)
| 学习方向 | 推荐资源 | 优势说明 |
|---|---|---|
| Python基础(AI方向) | Python官方文档、B站黑马程序员Python入门(AI专项) | 免费、贴合AI场景,不冗余,重点突出 |
| 数据处理 | Pandas官方教程、NumPy快速入门手册 | 权威、简洁,配套案例可直接运行 |
| 机器学习 | Scikit-learn官方文档、吴恩达机器学习(简化版) | 入门友好,无需复杂推导,侧重实操 |
| 大模型应用 | LangChain官方文档、OpenAI API入门教程 | 2026年热门,配套代码可直接对接大模型 |
七、总结:Python+AI入门的正确姿势
2026年入门Python+AI,核心是"轻理论、重实操,抓重点、避冗余",无需追求"面面俱到",按以下路径学习,高效且易落地:
-
搭建环境(1天):完成Python+核心AI库安装,熟悉PyCharm基本操作;
-
Python基础(3-5天):掌握本文第三部分核心语法,达到自测标准;
-
AI核心模块(15-20天):先学数据处理,再学机器学习3个核心模型,最后接触大模型应用;
-
实战落地(7-10天):完成3个入门级项目,熟练运用所学知识点;
-
进阶提升(长期):根据兴趣切入深度学习(CV/NLP)或大模型开发,补充对应理论知识。
最后提醒:AI入门没有"捷径",但有"方法",坚持"每天练代码、每周做案例",1-2个月即可实现从零基础到入门落地,避开本文提到的坑,少走弯路!
如果本文对你有帮助,欢迎点赞、收藏,关注我,后续持续更新2026年Python+AI进阶内容~