70 倍性能碾压 + SQL 全兼容!金仓数据库终结 InfluxDB 的复杂时序场景统治
在物联网、工业互联网和运维监控领域,时序数据处理的需求正以前所未有的速度增长。面对海量设备产生的持续数据流,企业需要一个既能高速写入、又能快速分析的数据库引擎。长期以来,InfluxDB以其在时序领域的先发优势和简洁设计,成为许多团队的首选。然而,随着数据规模从"万级"跃升至"千万级",业务查询从简单的点查变为复杂的多维度聚合,其性能瓶颈开始显现。
一场关于性能、扩展性与综合能力的较量,正在国产数据库金仓(KingbaseES)与国际开源方案InfluxDB之间展开。
性能对决:从数据摄入到复杂洞察的全面领先
真正的性能对比必须基于真实、可复现的测试场景。金仓数据库使用业界公认的开源时序基准测试套件TSBS,与InfluxDB进行了多轮正面较量,结论清晰而有力:在小规模、简单查询的工作负载下,两者各有千秋;但在大规模、复杂分析的真实生产环境中,金仓展现出压倒性的优势。
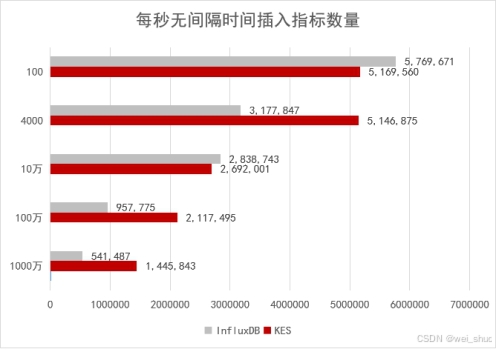
在数据写入吞吐方面 ,格局随数据规模急剧变化。测试模拟了从100台到1000万台设备的不同数据压力。当设备规模达到4000台(每台10个指标)时,金仓的每秒数据插入指标数已达到InfluxDB的162% ;在千万级设备的极限压力测试中,金仓的性能优势进一步扩大至267%。这证明在面对海量设备持续高并发写入时,金仓的架构具备更优的扩展性和稳定性。
在决定业务价值的查询性能上,两者的差距更为显著,尤其是在复杂分析场景。测试涵盖了从简单聚合到多维度深度分析的各种查询类型:
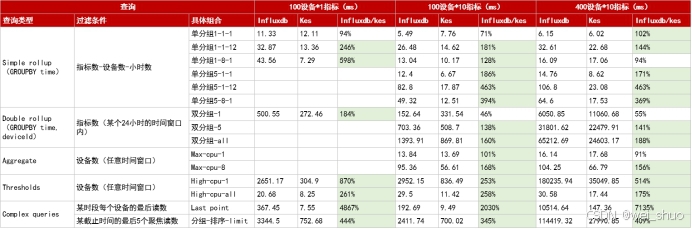
- 简单聚合查询(如单设备、单指标、短时间窗口聚合):两者性能在毫秒级,互有优劣。
- 中等复杂度查询(如多指标聚合、跨设备分组) :优势开始向金仓倾斜。例如,在"查询8台设备在1小时内的5个指标最大值"场景下,金仓的响应速度可达InfluxDB的3 到4倍。
- 高复杂度关联与分析查询:金仓的性能优势呈现数量级领先。在最具代表性的"查询某时段内每个设备的最后读数"(Last point)场景中,面对400台设备的数据,金仓的查询耗时仅为147.36毫秒,而InfluxDB需要10514.64毫秒,金仓性能领先超过70倍。在"高负载设备阈值筛选"等业务关键查询中,金仓的性能也可达InfluxDB的2到5倍。
这些测试结果一致表明:当企业的时序数据分析需求从"监控"走向"洞察"时,金仓能够提供实时或近实时的响应,而InfluxDB可能让关键业务决策陷入漫长的等待。
超越跑分:企业级能力与多模融合的升维优势
金仓的领先并不仅限于基准测试的跑分。其设计目标是成为一个企业级、多模融合的时序数据平台,这带来了多个维度的根本性提升,解决了InfluxDB在企业场景中的固有短板。
完整的SQL生态与事务支持
金仓时序能力基于强大的关系型数据库内核,提供完整的SQL支持,包括存储过程、复杂事务(ACID)和多表关联查询。这意味着开发团队无需学习新的查询语言,现有基于SQL的分析工具和业务系统可以无缝对接,极大降低了开发、运维和迁移的成本。而InfluxDB需要使用专用的InfluxQL或Flux语言,在融入企业现有以SQL为中心的数据生态时,会产生额外的转换和适配成本。对于金融交易、工控指令等要求数据强一致性的场景,金仓的ACID事务保障至关重要,而InfluxDB在设计上并不支持跨操作的事务。
深度优化的存储与生命周期管理
金仓提供了更具竞争力的数据全生命周期管理方案。其内置的时序组件支持基于时间的自动化数据分区(Chunk)和保留策略,并能对历史冷数据实施高压缩比存储。实测数据显示,其对工业传感器等时序数据可实现高达1:4的压缩比,显著降低海量历史数据的存储成本。同时,其"冷热数据分级存储"理念,可将访问频繁的热数据与不常访问的冷数据分别管理,进一步优化性能与成本。
独特的"时序+"多模融合能力
"多模融合"架构让时序数据不再孤立。企业可以在同一数据库内,直接对时序数据、空间地理信息(GIS)、设备元数据(JSON/文档)进行关联查询与分析。例如,智慧交通场景中"查询过去一周在机场周边特定区域频繁出现的车辆"这类时空联合查询,在InfluxDB中难以直接实现,而在金仓中只需一条标准SQL即可完成。这种能力将时序数据从简单的监控指标,提升为可进行深度挖掘的融合数据资产。
完整SQL生态与事务支持
金仓基于关系型数据库内核,提供完整的SQL支持和ACID事务保障。以下是时序表创建示例:
sql
-- 创建时序表,支持空间数据和文档类型
CREATE TABLE sensor_data (
device_id INT,
metric_name VARCHAR(50),
metric_value DOUBLE PRECISION,
timestamp TIMESTAMPTZ,
location GEOMETRY(Point, 4326),
tags JSONB
) PARTITION BY RANGE (timestamp);复杂多维度关联分析
金仓支持标准SQL进行复杂查询,无需学习专用查询语言:
sql
-- 查询特定区域内高负载设备
SELECT
d.device_id,
d.device_name,
AVG(s.metric_value) as avg_value,
MAX(s.metric_value) as max_value
FROM sensor_data s
JOIN device_info d ON s.device_id = d.id
WHERE s.timestamp >= NOW() - INTERVAL '1 hour'
AND ST_Within(s.location,
ST_GeomFromText('POLYGON((...))'))
AND s.metric_name = 'cpu_usage'
AND (s.tags->>'department')::int = 5
GROUP BY d.device_id, d.device_name
HAVING AVG(s.metric_value) > 80
ORDER BY avg_value DESC;时序专用函数与窗口函数
sql
-- 使用窗口函数获取每个设备最后读数
WITH last_points AS (
SELECT DISTINCT ON (device_id)
device_id,
metric_value,
timestamp
FROM sensor_data
WHERE timestamp >= NOW() - INTERVAL '1 day'
ORDER BY device_id, timestamp DESC
)
SELECT * FROM last_points;事务支持保证数据一致性
sql
-- 完整事务支持,保证数据强一致性
BEGIN;
INSERT INTO sensor_data VALUES (1, 'temperature', 25.5, NOW(), ...);
UPDATE device_status SET last_active = NOW() WHERE id = 1;
INSERT INTO audit_log VALUES (NOW(), 'data_insert', 'sensor_data');
COMMIT;实战检验:从概念到关键业务支撑
性能优势必须经得起真实业务的检验。金仓的时序能力已在多个高要求行业场景中成功替代或与原有方案竞争,并承载起核心业务。
在某大型港口集团的智慧港区项目中,系统需要处理成千上万辆集卡和拖车的秒级GPS轨迹数据。在对比测试中,面对日均数十亿条数据的写入和实时轨迹绘制、区域车辆统计等复杂查询需求,金仓时序组件在查询响应速度和系统稳定性上全面胜出,最终成为支撑其智能调度系统的核心引擎。
在能源电力领域 ,某新能源企业需要管理上千台风机的运行状态数据。他们最初评估了包括InfluxDB在内的多种方案,但最终选择了金仓。原因在于,金仓不仅能高效处理每秒数十万点的传感器数据写入,更能无缝对接其已有的设备关系型元数据,实现"设备-实时状态-历史告警"的一体化查询,并利用其强大的分布式架构轻松应对未来增长。测试表明,在该场景下,金仓在复杂分析查询上的性能可达InfluxDB的2倍至70倍不等,同时凭借更高的数据压缩比,预计可节省超百万元的存储成本。
结论:从专用工具到企业数据基座的关键进化
与InfluxDB的全面对比,清晰地定义了金仓数据库时序能力的价值定位:它不只是一个更快的时序数据库,更是一个以卓越时序性能为基石的企业级融合数据平台。
对于正在使用或考虑InfluxDB的企业而言,如果业务仅停留在简单的指标存储与看板展示,InfluxDB或许足够。但当业务需要向更深度的实时分析、更复杂的关联挖掘、与现有业务系统更紧密集成演进时,金仓提供了更优的路径。它解决了InfluxDB在复杂查询、事务支持、生态融合方面的固有短板,并以经过验证的、数倍乃至数十倍的性能优势,证明了其在处理大规模、高复杂度时序场景下的实力。
选择金仓,意味着企业获得的不仅是一个时序数据存储方案,更是一个能够统一承载核心业务数据、时空数据、时序数据,并在此基础之上构建智能决策平台的坚实底座。在数据驱动决策的时代,这种从"记录过去"到"洞察未来"的能力跃迁,正是金仓数据库在时序战场中给出的最终答案。