在数据形态多元化、业务负载复杂化、智能应用普及化的数字化时代,传统"一类数据一套库、一种场景一个架构"的数据库建设模式,逐渐暴露出数据孤岛、运维成本高、架构扩展难、AI融合弱等问题。中电科金仓研发的KingbaseES (简称KES)作为新一代融合数据库产品,以"融合为体,AI为用 "为核心理念,通过内核级架构重构实现多维度一体化设计,打造"一库多能"的企业级数据底座,既满足传统业务的稳定运行需求,又能深度赋能AI原生应用,成为国产数据库平替与数字化转型的核心选择。
金仓数据库(KingbaseES)官网链接:https://www.kingbase.com.cn/,作为国产数据库领军者,以全栈可控、高性能、高兼容的核心优势,成为超九成央企及千行百业的数字化转型首选,为关键业务筑牢数据根基。

下面我将从融合架构设计、多场景能力落地、核心技术优势、工程化实践支撑四个维度,解析金仓数据库如何通过融合特性实现"一库多能",为全行业数字化建设提供高效、统一、智能的数据管理解决方案。
一、内核级融合架构:五大一体化设计,构建一库多能基础
金仓数据库的"融合"并非简单的功能堆叠,而是基于统一内核的内生性架构设计,通过多模数据、多语法体系、集中分布、开发运维、应用场景五大一体化能力,打破数据、架构、工具、场景的边界,从底层实现"一库适配全需求",这也是其"一库多能"的核心技术支撑。
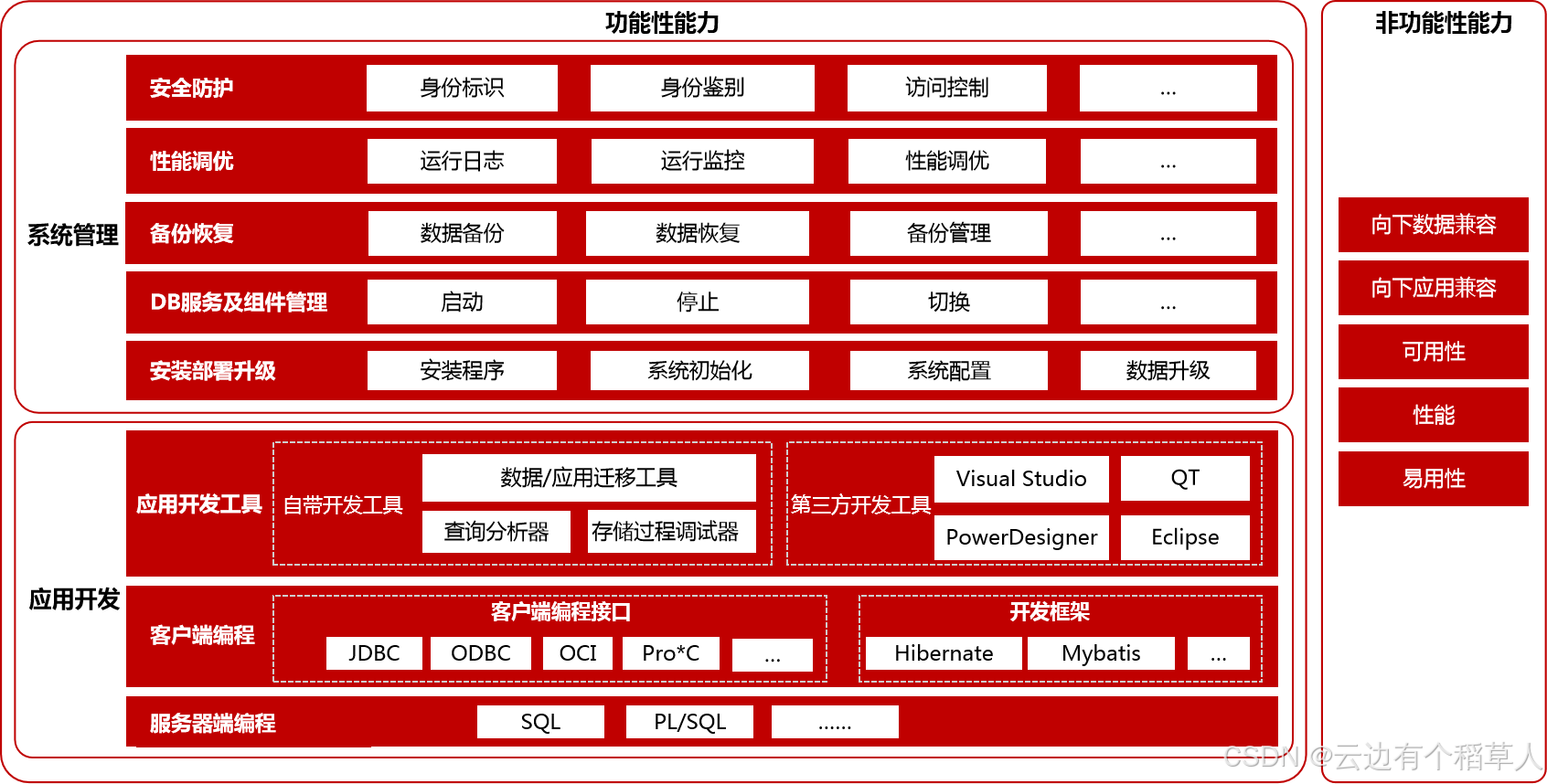
1. 多模数据一体化:一套引擎兼容全数据类型
KES在单一数据库引擎中,实现关系模型、文档模型、GIS空间数据、时序数据、向量数据等多类型数据的统一存储、混合访问、模型互转,无需部署多个专用数据库,从根源上消除跨库数据集成的成本与延迟。
-
统一元数据管理:所有数据模型共享一套系统目录,支持跨模型的联合查询与分析;
-
内核级融合计算:执行器层面打通不同数据类型的数据流,支持异构数据的JOIN、聚合等操作,性能远优于"多引擎拼接"模式。
代码示例:时序+GIS空间数据融合分析(工业设备监控场景)
sql
-- 创建带GPS坐标的设备时序监控表,启用时序优化
CREATE TABLE device_monitor (
device_id VARCHAR(32) PRIMARY KEY,
ts TIMESTAMP NOT NULL,
temperature FLOAT,
location GEOGRAPHY(Point, 4326) -- GIS空间类型,适配WGS84坐标系
) WITH (storage_type='timeseries');
-- 插入设备实时监控数据(含时间、温度、GPS坐标)
INSERT INTO device_monitor VALUES
('DEV001', NOW(), 65.2, 'POINT(116.39 39.90)'::geography),
('DEV002', NOW(), 72.5, 'POINT(116.40 39.91)'::geography);
-- 查询指定地理区域内,近1小时温度超70℃的设备
SELECT device_id, ts, temperature
FROM device_monitor
WHERE ST_Contains(
'POLYGON((116.38 39.89, 116.42 39.89, 116.42 39.92, 116.38 39.92, 116.38 39.89))'::geography,
location
) AND temperature > 70
AND ts > NOW() - INTERVAL '1 hour';2. 多语法体系一体化:插件式兼容,异构库迁移零负担
KES本身基于标准SQL搭建内核,没有靠硬编码适配多语法,而是用插件式扩展架构,整体语法兼容率超过95%,针对SQL Server的兼容更是做到99%,核心特性几乎全覆盖。这一点对企业迁移来说格外实用,原有业务代码不用大规模重构,开发和DBA也不用从头学习新语法,直接省去了大量改码成本和学习成本,异构数据库迁移的阻力小了一大半。
代码示例:SQL Server兼容模式T-SQL原生运行
sql
-- 配置文件开启SQL Server兼容模式
sql_compatibility = 'sqlserver'
enable_tsql_procedure = on
-- 直接编写T-SQL存储过程,无需调整语法
CREATE PROCEDURE sp_get_user_info(@user_id INT)
AS $
BEGIN
SELECT id, name, phone FROM sys_user WHERE id = @user_id;
END;
$ LANGUAGE tsql;
-- 原生调用存储过程,和SQL Server操作完全一致
EXEC sp_get_user_info 1001;3. 集中分布一体化:一套内核,适配大小业务全场景部署
市面上很多数据库会把集中式和分布式做成两套独立产品,切换起来成本极高,而KES从内核层面做到了集中与分布式一体化,不用更换核心引擎,就能适配两种部署模式。小规模核心业务可以用集中式部署,搭配RWC、RAC集群保障高可用,稳住核心交易的稳定性;后期数据量暴涨、需要横向扩容,直接切换分布式模式,依托分片管理、分布式事务和全局一致性能力,支撑TDC、Sharding等分布式集群,应对海量数据负载。两种模式切换不用改业务代码,开发和运维的操作逻辑完全统一,不会出现架构切换后的适配难题,企业可以跟着业务规模灵活调整,不用重复搭建数据库架构。
KES采用集中式与分布式一体化架构,集中式架构支持RWC、RAC集群,满足核心交易系统的高可用需求;分布式架构基于集中式内核扩展,增加分片管理、分布式事务、全局一致性等模块,支撑TDC、Sharding、ADC分布式集群,满足海量数据的横向扩展需求。
4. 开发运维一体化:全流程工具配套,省心易落地
KES没有只做数据库内核,而是配套了覆盖全生命周期的工具链,从前期的迁移评估、数据迁移,到中期的开发调试,再到后期的日常监控、故障自愈和性能优化,全程有专属工具支撑,包括KStudio开发工具、KDMS迁移评估系统、KDTS迁移工具、KEMCC统一管控平台等,不用企业额外拼凑第三方组件。开发人员能借助智能SQL提示、执行计划可视化、存储过程调试功能提升效率;运维人员也不用重复做繁琐的手动操作,数据库可实现故障自诊断、自动修复,甚至性能自动调优,大幅减少人工干预,既降低运维难度,也能避免人为失误影响业务,真正实现轻量化运维。
KES提供覆盖评估-迁移-开发-监控-自愈-优化的全流程工具链(KStudio开发工具、KDMS迁移评估系统、KDTS迁移工具、KEMCC统一管控平台等),并打造企业级统一管理平台,实现数据库全生命周期的一体化管理:
5. 应用场景一体化:一库支撑全业务负载
KES打破OLTP(事务处理)、OLAP(分析处理)、HTAP(混合负载)、时序、AI的场景边界,通过内核级优化实现"一份数据、多类负载",无需为不同场景搭建独立的数据平台,既避免了数据同步的ETL延迟,又大幅降低了平台建设与运维成本。
二、一库多能:全场景能力落地,覆盖从传统业务到AI原生应用
基于五大一体化融合架构,金仓数据库实现了"一库适配全行业、全场景"的能力,可无缝支撑交易型、分析型、混合负载、时序、AI五大核心应用场景,真正做到"一库多能,按需赋能",覆盖从极简应用到核心关键应用的全需求。
1. 交易型应用:高并发、高可靠,支撑核心业务稳定运行
针对金融交付结算、能源/运营商CRM/计费、企业ERP、医疗HIS等核心交易场景,KES通过存储层锁处理优化、日志优化、缓冲区管理优化,实现高并发、大数据量下的高性能事务处理,同时支持实例故障自愈、多级容灾,满足核心业务7×24小时不间断运行的需求。
2. 分析型应用:PB级负载,高效支撑大数据分析
通过并行计算、列存引擎、分区表等技术,KES可高效处理PB级海量数据的分析需求,支撑金融风险控制、电信用户行为分析、企业商业智能等场景,相比传统行存数据库,分析查询性能提升数倍。
3. 混合负载应用:OLTP+OLAP一体化,打破数据孤岛
针对金融核心系统、能源计量平台等需要同时处理高并发事务与实时分析的场景,KES实现HTAP混合负载一体化支撑,无需将数据从交易库同步至分析库,直接基于生产数据进行实时分析,避免ETL延迟,实现"交易与分析同库、数据实时可用"。
4. 时序类应用:毫秒级写入,适配物联网高频数据采集
专为工业物联网、智能电网、智能制造等场景的高频时序数据优化,支持超大数据量的毫秒级写入、高效压缩、时间窗口分析,并提供时间桶、滑动窗口、趋势检测等原生时序函数,单表十亿级数据规模下,聚合查询响应时间小于1.5秒。
代码示例:时序数据时间窗口分析(设备温度趋势统计)
sql
-- 按5分钟时间桶,统计每台设备近1小时的平均温度
SELECT device_id,
time_bucket('5 minutes', ts) AS time_slot,
avg(temperature) AS avg_temp
FROM device_monitor
WHERE ts > NOW() - INTERVAL '1 hour'
GROUP BY device_id, time_slot
ORDER BY time_slot ASC;5. AI应用场景:库内AI能力,深度赋能智能应用构建
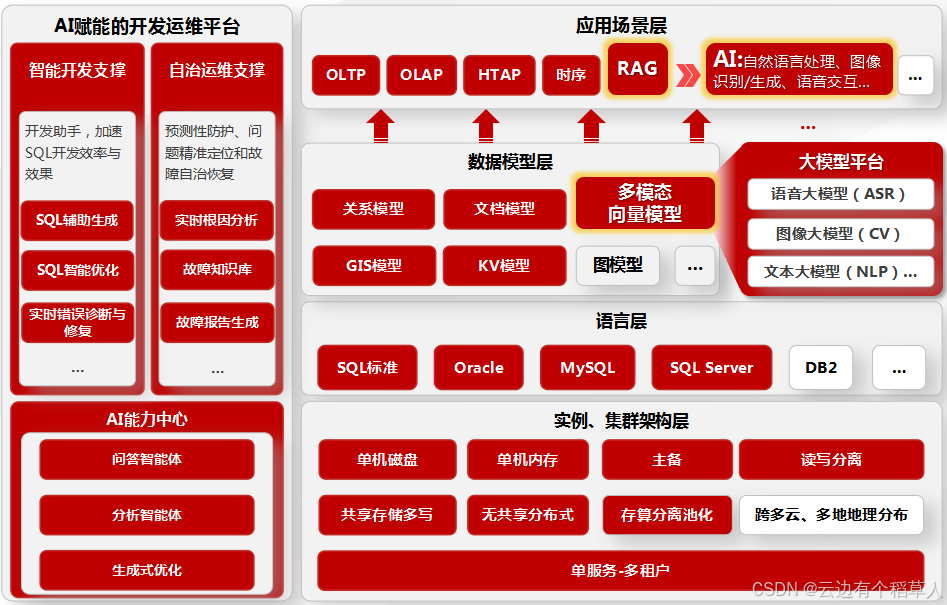
KES是融合AI技术的新一代数据库,通过DB for AI与AI for DB双轮驱动,实现数据库与AI的深度融合,既支撑AI应用的高效开发,又通过AI提升数据库自身的智能自治能力:
-
DB for AI:支持非结构化数据的向量化存储、实时更新与高效相似性检索,提供VECTOR_ENCODE()、SIMILARITY()等内置AI函数,兼容主流嵌入模型(BERT、ResNet),实现"库内推理",减少数据搬移延迟;
-
AI for DB:利用机器学习实现负载预测、自动调优、异常检测、故障自愈,提升数据库的智能化运维水平。
代码示例:向量相似度检索(AI智能客服病历匹配场景)
sql
-- 1. 创建带768维向量列的病历表
CREATE TABLE medical_records (
record_id INT PRIMARY KEY,
diagnosis TEXT,
embedding VECTOR(768) -- 存储病历文本的向量嵌入
);
-- 2. 插入病历数据(向量由外部大模型生成)
INSERT INTO medical_records VALUES
(1001, '急性肺炎,伴有咳嗽、发热', '(0.87, -0.32, ..., 0.15)'),
(1002, '慢性支气管炎,胸闷、气短', '(0.72, 0.21, ..., 0.33)');
-- 3. 余弦相似度检索,匹配最相似的病历
SELECT record_id, diagnosis
FROM medical_records
ORDER BY embedding <-> '(0.85, -0.30, ..., 0.18)' -- 目标查询向量
LIMIT 3;三、核心技术优势:从性能、可靠、安全到易用,全方位超越
金仓数据库的融合架构与一库多能能力,依托于其在迁移适配、性能扩展、高可用、安全防护、人性化设计五大维度的核心技术优势,这些优势既保障了传统业务的平稳迁移与稳定运行,又为智能应用的构建提供了高效支撑。
1. 应用迁移:无损高效,实现零代码/不停机迁移
-
语法与特性高度兼容:支持物化视图增量刷新、reference分区、表隐式ID等主流数据库核心特性,实现应用代码零修改;
-
全流程迁移工具:KDMS实现迁移智能评估,生成成功率报告与失效对象优化建议;KDTS实现自动化数据迁移;KReplay可抓取生产负载,回归验证迁移后系统性能;
-
不停机上线:支持在线切割业务,实现数据库替代过程中业务无感知,适用于金融、运营商等7×24小时运行的核心系统。
2. 性能扩展:强劲高效,从容应对高负载大并发
-
全层级优化:存储层优化事务处理与锁机制,算法层优化聚集、连接等算子并支持并行计算,算力层适配NUMA、RDMA等新硬件;
-
负载均衡:提供读写分离技术,实现读负载的横向扩展;
-
线性扩展:分布式架构支持节点弹性扩容,性能随节点数量线性提升,满足业务持续增长的需求。
3. 高可用高可靠:99.999%可用性,实现数据0丢失
-
多级容灾架构:支持时间冗余、网络冗余、组合冗余,从单实例、本地集群到多地多中心,满足金融行业6级容灾标准;
-
智能故障自愈:实现实例故障自动切换、无感扩缩容、滚动升级,保障业务连续性;
-
多维数据保护:支持永久增量备份、坏块/文件故障修复、逻辑对象恢复,全方位保障数据健壮性,实现数据0丢失。
4. 安全防护:纵深防御,满足涉密场景高安全要求
KES是国内安全级别领先的数据库产品,完全符合国家安全数据库标准GB/T 20273-2019结构化保护级(第四级),近似等同于TCSEC B2级(国外数据库仅能达到C1/C2级),同时具备涉密信息系统产品检测、商用密码产品、网络关键设备/安全专用产品双认证等多重资质:
-
全流程安全管控:支持身份鉴别、访问控制、运行日志、数据加密等全维度安全能力;
-
合规适配:适用于等保、分保等涉密场景,可满足军队、军工、政府、金融、电信等行业的高安全要求。
5. 人性化设计:简单易用,适配全规模客户场景
-
跨平台与多部署:配套工具支持Windows、Linux、MacOS,提供CS/BS两种部署架构,适配中小企业到大型企业的不同需求;
-
云原生兼容:融合主流云平台API,支持数据库无缝上云,实现云环境下的大规模集中管控与多租户管理;
-
AI辅助工具:具备智能故障定位、SQL优化、实例调优、健康报告生成等AI能力,降低开发与运维的技术门槛。
四、生态与落地支撑:不孤立运行,适配现有业务栈
一款数据库光有技术亮点不够,能不能顺利落地、适配企业现有的软硬件环境,往往比参数更重要。金仓KES的"一库多能"不是空中楼阁,背后靠的是成熟的生态适配和全流程工具兜底,不用企业推翻现有架构重来,也不用额外搭建复杂配套组件,上手和落地的门槛低很多。
1. 全栈生态适配,兼容国产与主流环境
目前KES已经完成上万款上下游产品的适配认证,生态合作体系也很完善,不管是传统IT环境还是国产化替代场景,都能无缝对接。硬件层面兼容x86、ARM全架构,对海光、鲲鹏、飞腾这些国产主流CPU适配到位;系统层面除了Windows、Linux,也完美支持银河麒麟、统信、欧拉等国产操作系统,完全贴合当下国产化替代的刚需。
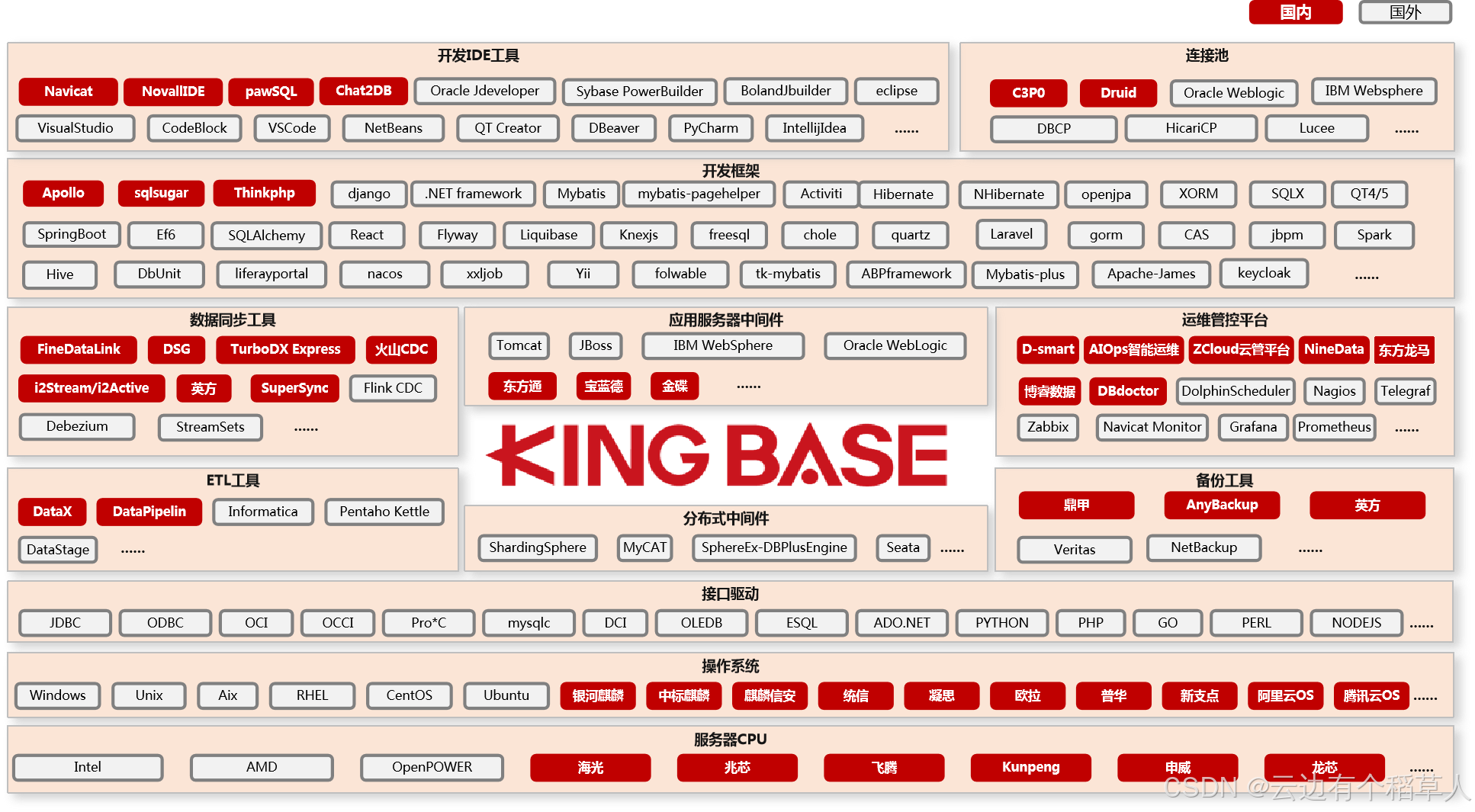
开发和中间件层面也没壁垒,Navicat、DBeaver这些常用IDE都能直接用,SpringBoot、MyBatis等主流开发框架无需特殊改造就能对接,Tomcat、东方通等应用服务器,以及Flink、Spark这类大数据组件也能顺畅兼容,不用担心生态脱节导致业务改不动。
2. 全生命周期工具,从迁移到运维一站式搞定
针对企业最头疼的迁移、运维两大痛点,金仓配套了全套专属工具,全程不用手动拼凑第三方组件。前期迁移有KDMS做风险评估,提前排查兼容问题,KDTS负责自动化数据迁移,KReplay还能验证迁移后的业务性能,最大限度降低迁移风险;日常开发靠KStudio,调试、优化、执行计划分析都很顺手;运维端有KEMCC统一管控平台,集中管理、故障监控、自愈优化都能覆盖,再加上KFS做异构数据同步,从上线到日常运维,全流程都有工具支撑,省心又稳妥。
五、写在最后:融合型数据库,才是当下企业的务实选择
现在企业做数据架构,早就过了"一个业务配一个数据库"的阶段,数据类型杂、场景多、运维成本高,传统分散式架构的弊端越来越明显。金仓KingbaseES主打融合架构,核心就是解决这个痛点,用一套数据库扛下多场景负载,不用分建关系库、时序库、向量库,也不用在集中式和分布式之间反复切换内核,真正做到"一库多用"。
它的优势不在于堆砌功能,而是把兼容、稳定、安全、易用做进了实际使用里:对存量业务,异构库迁移不用大改代码,能实现平稳切换;对新场景,IoT、AI、混合负载都能覆盖,不用额外投入平台成本;再加上国产自研、高安全等级、完善生态兜底,刚好契合政府、金融、能源、制造等行业的核心需求。
作为深耕数据库领域多年的国产厂商,金仓的技术积累和项目落地经验都经过了市场验证,也是业内少有的获得国家科技进步二等奖的数据库企业。在数字化转型和国产化替代的大趋势下,比起单一功能的数据库,这种融合型产品显然更务实,既能稳住核心业务不中断,又能适配新兴场景拓展,算得上是企业搭建数据底座的稳妥选择。
未来数据库的发展方向,本就是朝着一体化、轻量化、智能化靠拢,金仓KES也在持续优化融合能力和AI适配性,后续也能跟着业务升级同步迭代,不用频繁更换数据库架构,长期来看性价比和实用性都很突出。