目录
hset
设置 hash 中指定的字段(field)的值(value)。
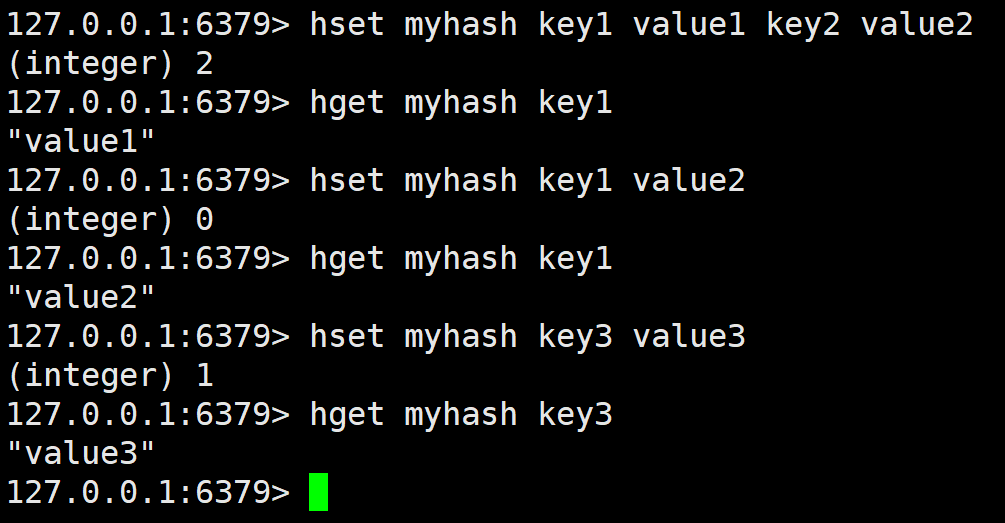
由于Redis本身就是哈希的形式,它自身的键值对称为 key - value,而对于哈希数据类型,也就是 key - value 的 value 是哈希,那么这时称其为 field - value,为了区分开。那么 hset 对于 key 不存在的场景,会自动创建,如果存在,就会向其中添加 field - value,如果 field 存在,就会进行覆盖,该指令返回新增到哈希表中字段的数量。注意这里的hash的 field - value 都只能是字符串,不能像 Redis 的顶层哈希一样能存各种数据结构,可能本身出于轻量化的考虑吧。
hget
获取 hash 中指定字段的值。
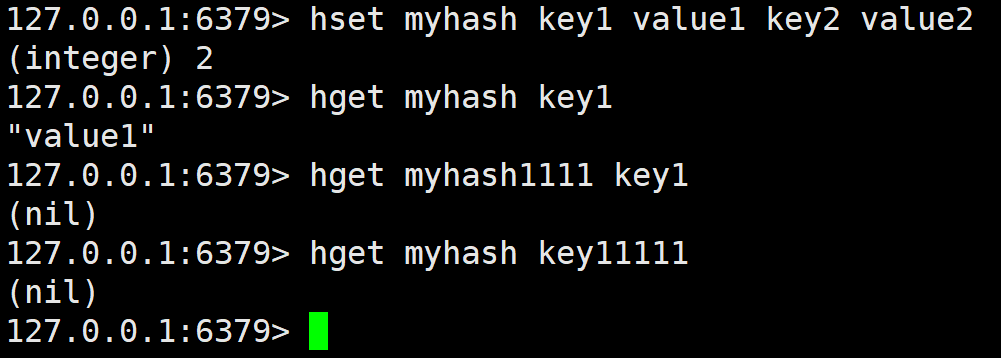
key 或 field 不存在就返回 nil。
hexists
判断 hash 中是否有指定的字段。
和 hget 一样,key 或 field 不存在就返回 0。存在就返回 1。和 hget 想必就是不能在存在时获取到 value。
hdel
删除 hash 中指定的字段。
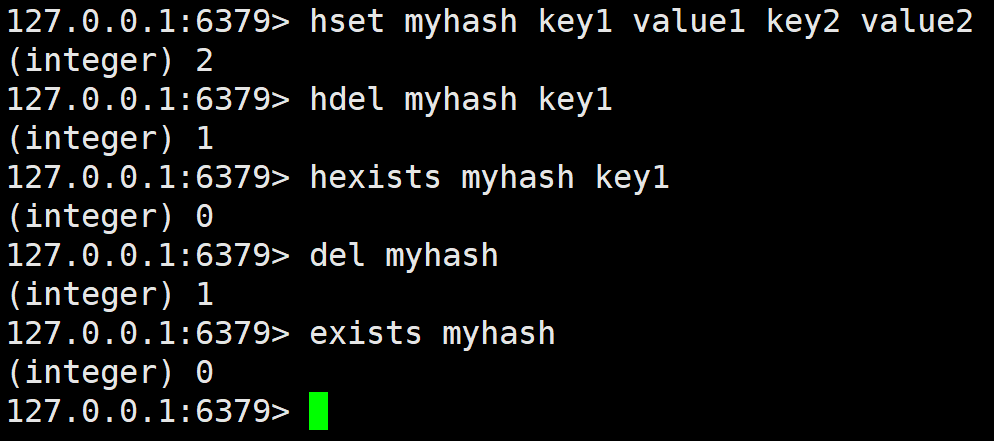
删除的是 field,del 删除的是 key。返回值是本轮操作删除的字段数量。
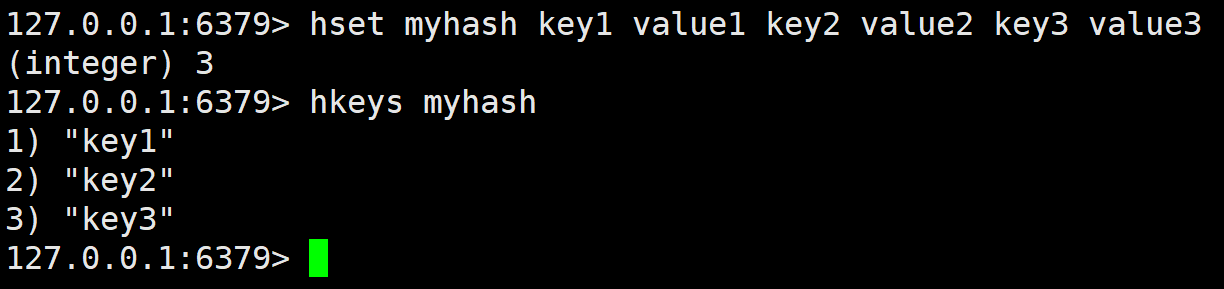
hkeys
获取 hash 中的所有字段。
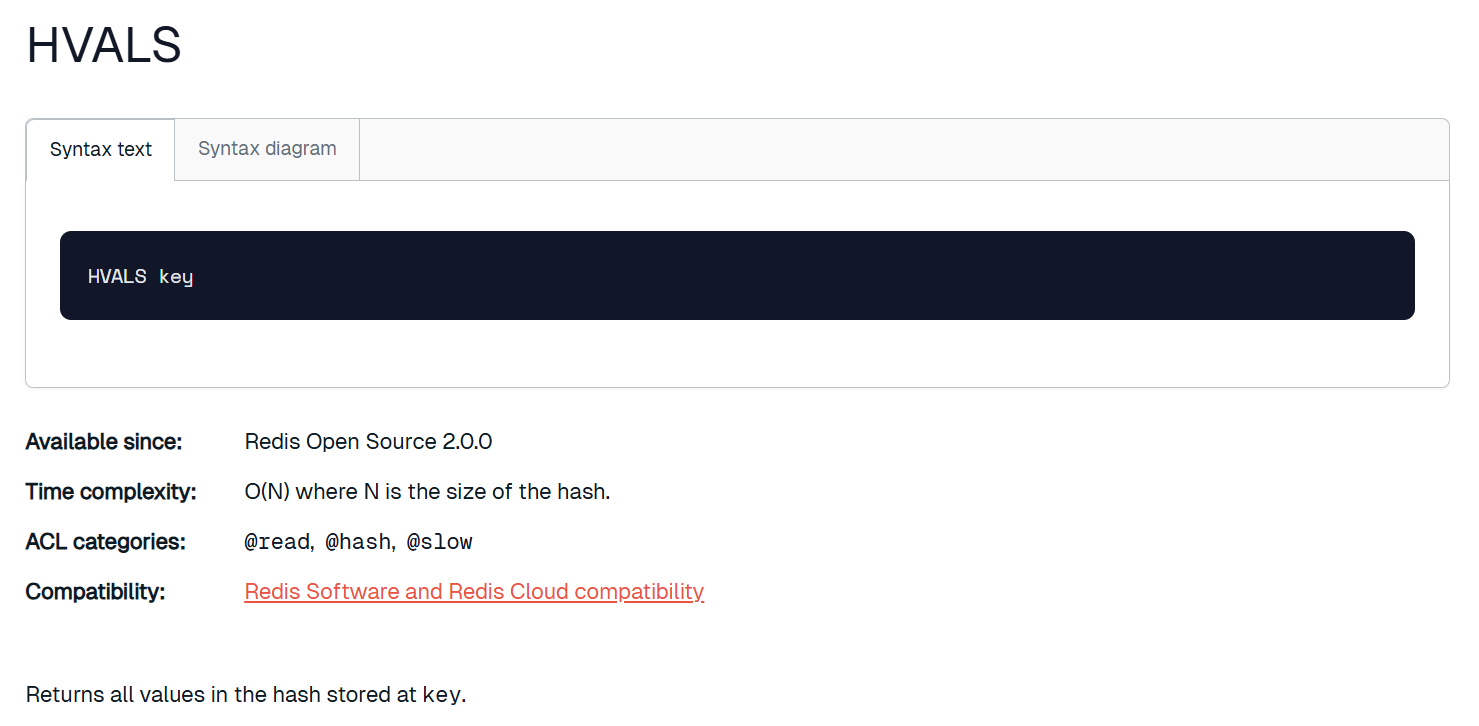
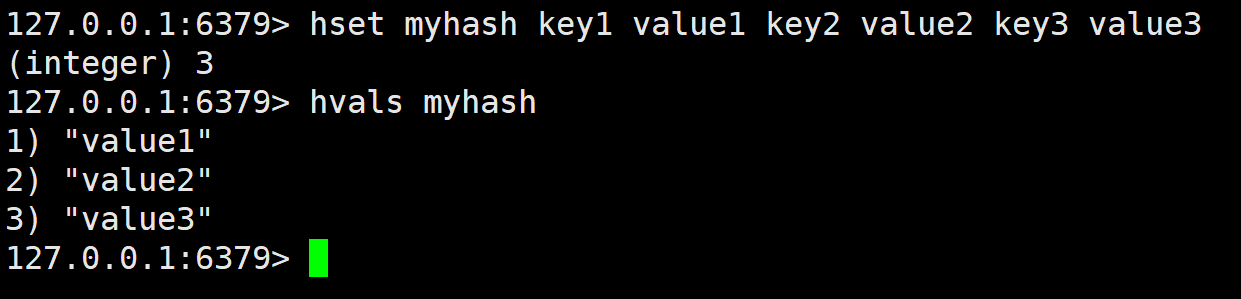
hvals
获取 hash 中的所有的值。
hgetall
获取 hash 中的所有字段以及对应的值。
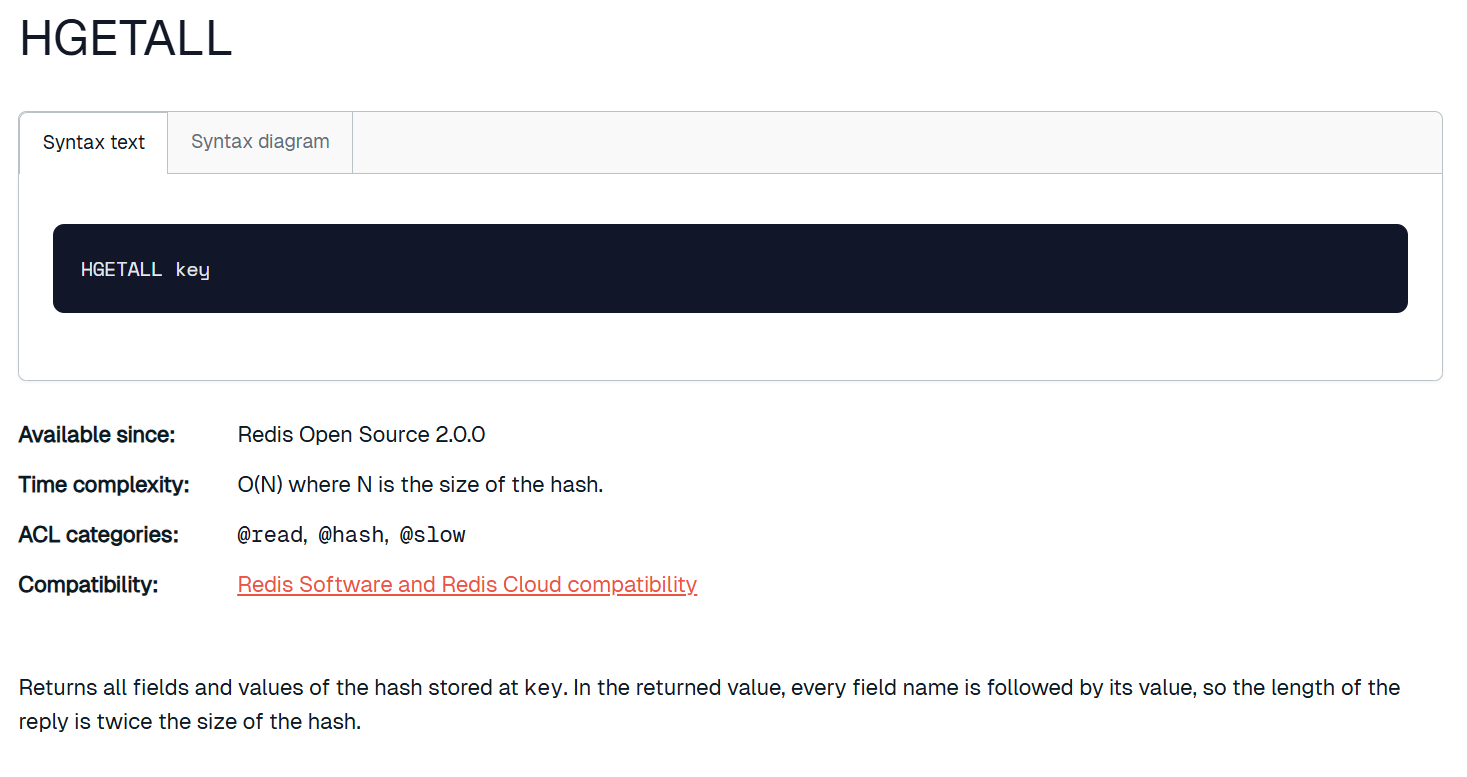
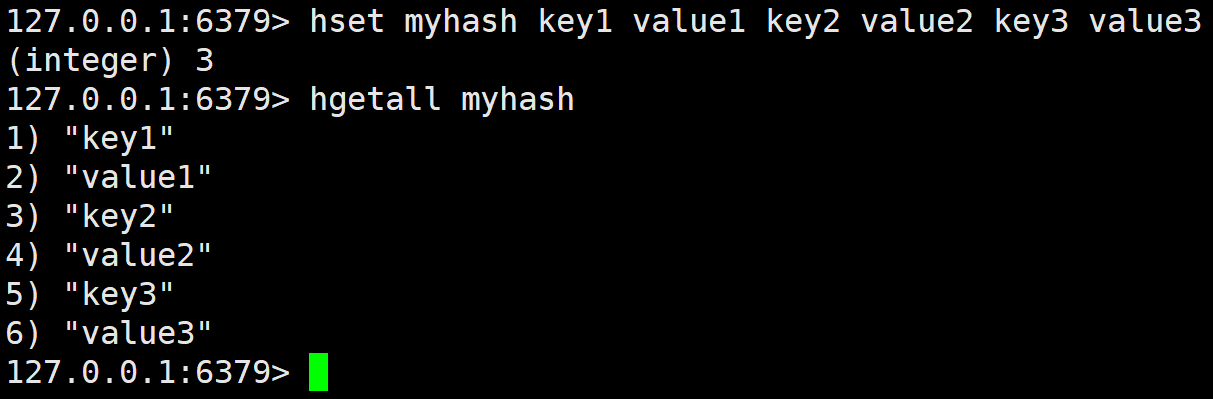
这个指令就是上面两个的合体。这几个指令都不建议冒然使用,原因和 keys *一样,因为都是O(N),如果数据量过大会阻塞线程。
hmget
一次获取 hash 中多个字段的值.
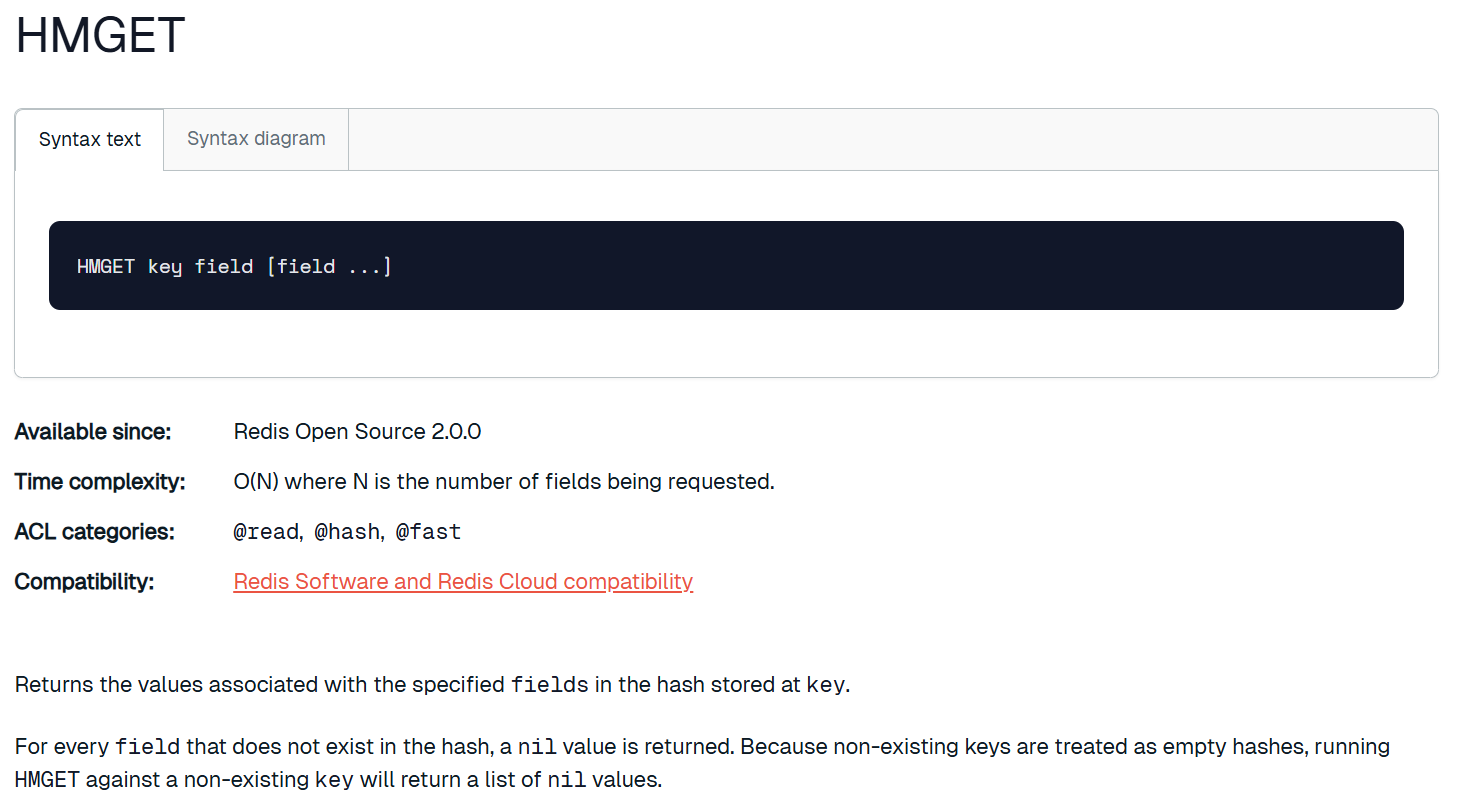
该指令的 O(N) 是将查询的 field 视为 N。
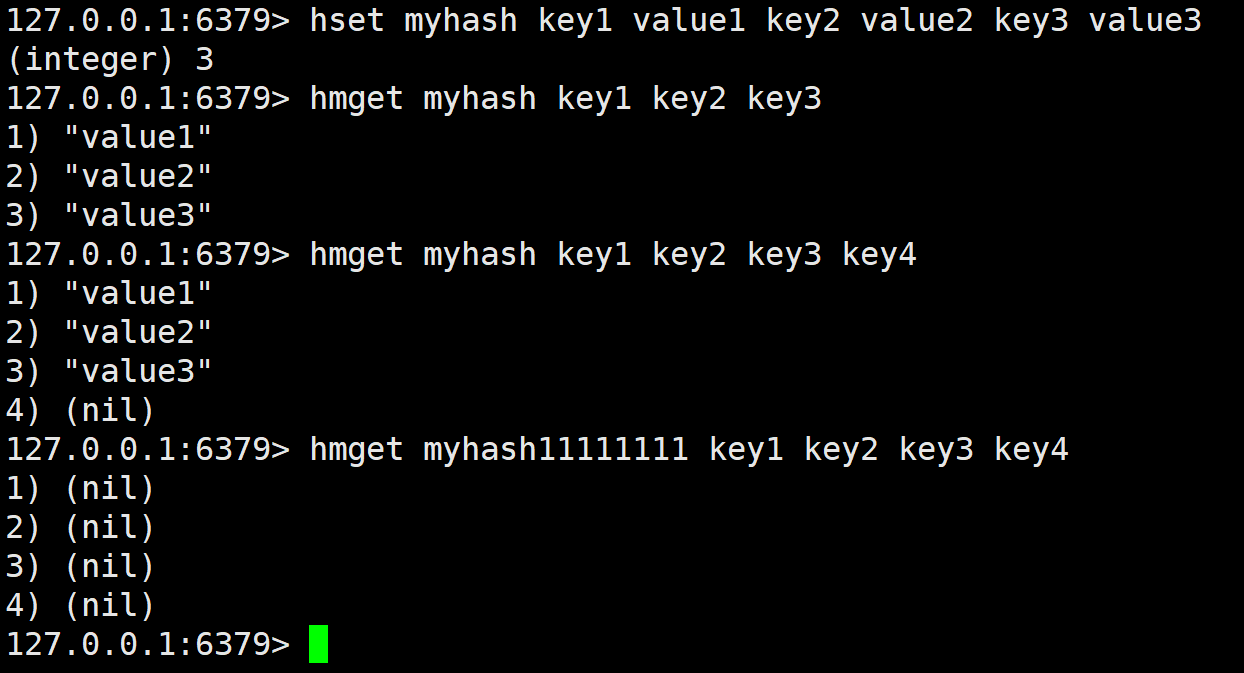
对应的 field 不存在,那么就会返回 nil,如果 key 不存在,那么有几个 field 就返回几个 nil。有 hmget,那么有没有 hmset 呢?其实是有的,但是 hset 本身就能设置多个,所以功能重合了。
hlen
获取 hash 中的所有字段的个数。

key 不存在返回 0。
hsetnx
在字段不存在的情况下,设置 hash 中的字段和值。
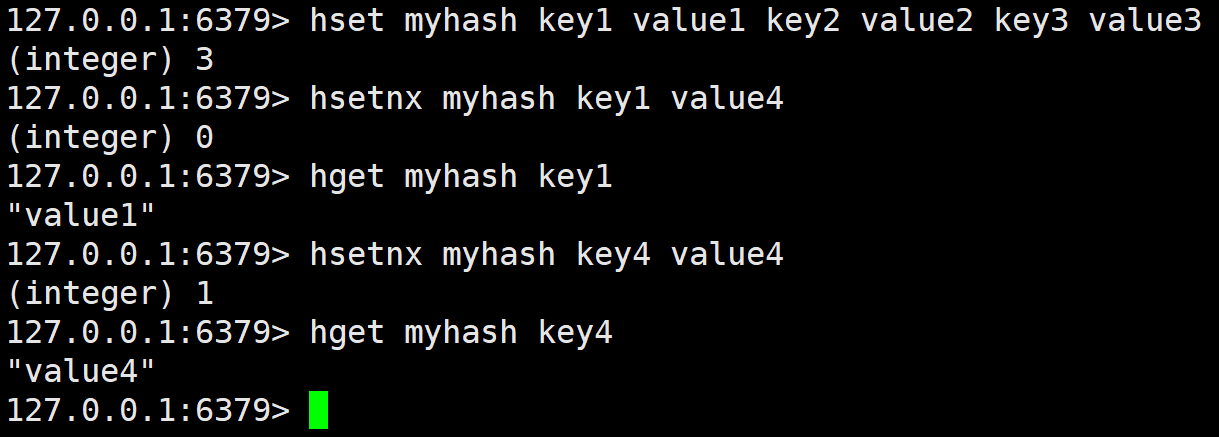
如果是存在的 field,那么什么都不会做,如果不存在才会设置。
hincrby
将 hash 中字段对应的数值添加指定的值。
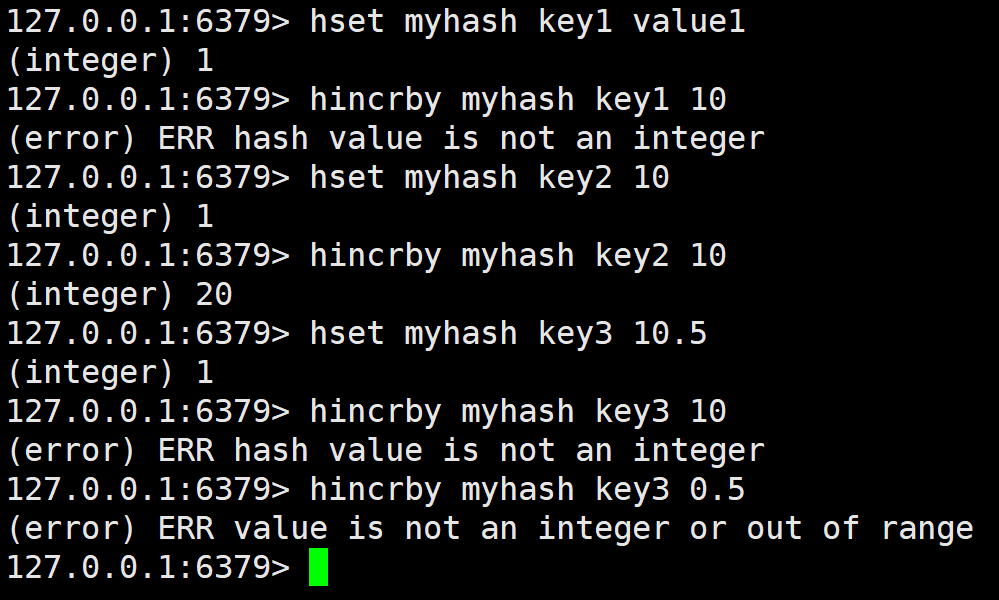
注意 value 得是整形,然后小数的计算也是不行的。这里因为计算这块用的少,也没有提供诸如 hdecrby 的指令,但是我们可以通过加上负数的方式实现减法。
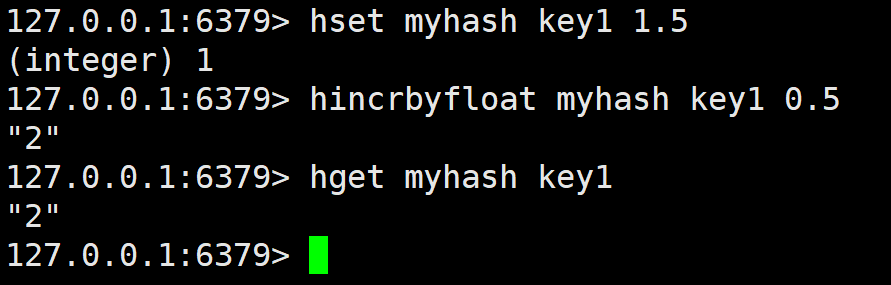
hincrbyfloat
hincrby 的浮点数版本。
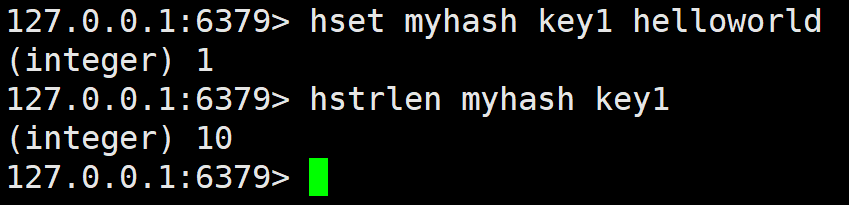
hstrlen
返回指定 field 的 value 的长度。
内部编码
ziplist(压缩列表):当哈希类型元素个数小于 hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都小于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使用 ziplist 作为哈希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable 更加优秀。ziplist 的查询效率低于普通哈希,但是因为其只在元素少的情况下使用,所以无伤大雅。
hashtable(哈希表):当哈希类型无法满足 ziplist 的条件时,Redis 会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为 O(1)。
使用场景
Redis 哈希类型最核心的使用场景之一是结构化数据的缓存(如用户信息、商品信息等业务实体数据)。相比于将每个属性拆分为独立字符串键(内存占用高、数据分散),或把整个对象序列化为单个 JSON 字符串(局部更新不灵活、有序列化开销),哈希类型能以 "键(实体 ID)- 字段(属性名)- 值(属性值)" 的形式,直观且高效地缓存结构化数据,既保持了数据的内聚性,又支持对单个属性的精准读写(如仅更新用户年龄、仅获取商品价格),是缓存这类实体数据的最优选择。同时需注意,哈希类型是稀疏结构(不同键可拥有不同字段),更适配灵活的属性存储场景,但无法替代关系型数据库完成复杂的关联查询,仅适用于单实体的属性缓存与操作。