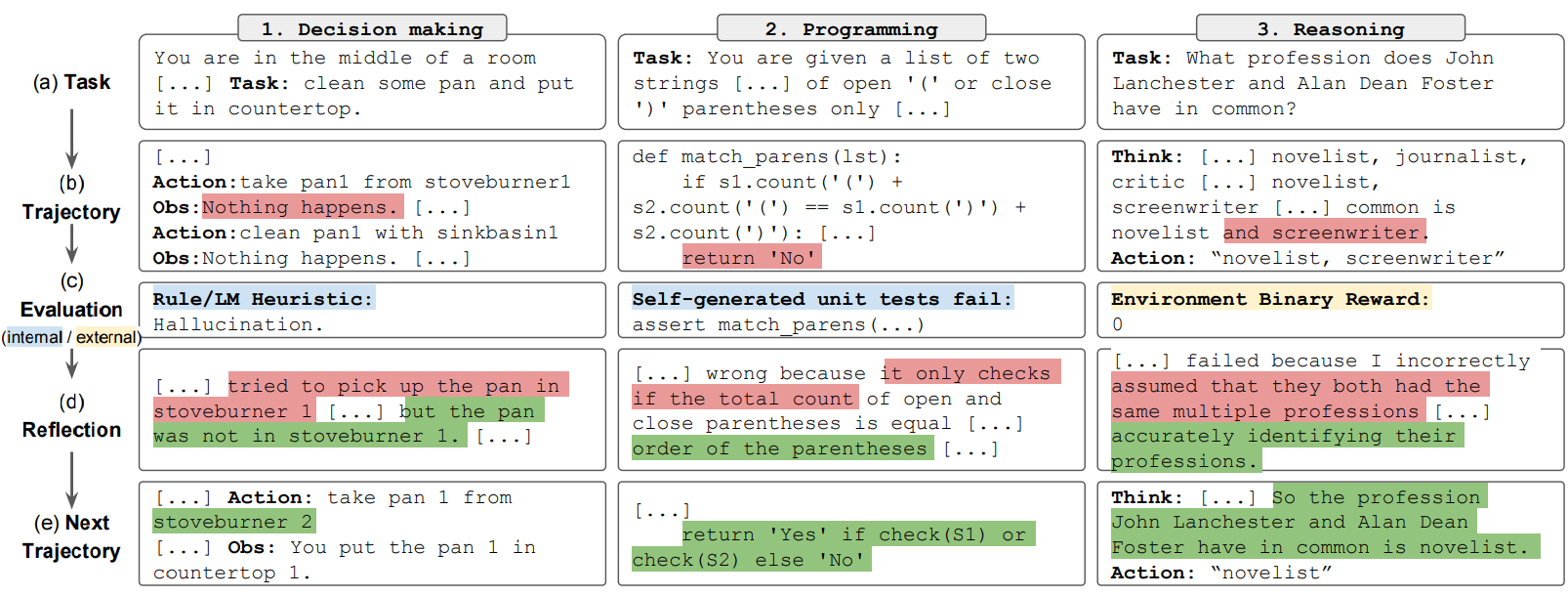
🔖 系列文章:本文是 Agents 系列的第四篇,深入探讨 AI Agent 的核心推理能力
🏷️ 标签 :
LLMAgent推理Chain-of-ThoughtReActReflexion
📑 目录
- [1. 🎯 引言:为什么推理能力如此重要?](#1. 🎯 引言:为什么推理能力如此重要?)
- [2. 🧠 Chain-of-Thought (CoT):思维链推理](#2. 🧠 Chain-of-Thought (CoT):思维链推理)
- [2.1 CoT 的核心思想](#2.1 CoT 的核心思想)
- [2.2 Few-shot CoT vs Zero-shot CoT](#2.2 Few-shot CoT vs Zero-shot CoT)
- [2.3 CoT 的变体与改进](#2.3 CoT 的变体与改进)
- [2.4 代码实现与实践](#2.4 代码实现与实践)
- [3. 🌳 Tree-of-Thought (ToT):思维树推理](#3. 🌳 Tree-of-Thought (ToT):思维树推理)
- [3.1 从链到树的演进](#3.1 从链到树的演进)
- [3.2 ToT 的核心组件](#3.2 ToT 的核心组件)
- [3.3 搜索策略:BFS vs DFS](#3.3 搜索策略:BFS vs DFS)
- [3.4 完整代码实现](#3.4 完整代码实现)
- [4. 🔄 Self-Refine:自我精炼机制](#4. 🔄 Self-Refine:自我精炼机制)
- [4.1 迭代式自我改进](#4.1 迭代式自我改进)
- [4.2 反馈生成与优化](#4.2 反馈生成与优化)
- [4.3 实践案例与代码](#4.3 实践案例与代码)
- [5. 🪞 Reflexion:反思式学习](#5. 🪞 Reflexion:反思式学习)
- [5.1 语言强化学习](#5.1 语言强化学习)
- [5.2 反思记忆机制](#5.2 反思记忆机制)
- [5.3 完整实现框架](#5.3 完整实现框架)
- [6. ⚡ ReAct:推理与行动的协同](#6. ⚡ ReAct:推理与行动的协同)
- [6.1 Reasoning + Acting 范式](#6.1 Reasoning + Acting 范式)
- [6.2 ReAct 循环详解](#6.2 ReAct 循环详解)
- [6.3 工具调用集成](#6.3 工具调用集成)
- [6.4 生产级实现](#6.4 生产级实现)
- [7. 🔗 技术对比与选型指南](#7. 🔗 技术对比与选型指南)
- [8. 🏗️ 综合架构设计](#8. 🏗️ 综合架构设计)
- [9. 🚀 最佳实践与优化技巧](#9. 🚀 最佳实践与优化技巧)
- [10. 📚 参考文献与资源](#10. 📚 参考文献与资源)
1. 🎯 引言:为什么推理能力如此重要?
在人工智能的发展历程中,推理能力一直是衡量智能系统的核心指标之一。从早期的专家系统到现代的大语言模型(LLM),研究者们始终在追求一个目标:让机器能够像人类一样进行逻辑推理、分析问题、并得出合理的结论。
1.1 传统 LLM 的推理困境
💡 思考:为什么直接让 LLM 回答复杂问题往往效果不佳?
🤔 解答:传统的 LLM 在面对复杂推理任务时,通常采用"直接回答"的方式------接收问题,立即输出答案。这种方式存在几个根本性问题:
-
缺乏中间步骤:人类解决复杂问题时,会将其分解为多个子步骤逐一解决。而 LLM 的直接输出跳过了这个关键过程。
-
错误累积难以追踪:没有显式的推理过程,一旦出错,很难定位问题所在。
-
无法自我验证:模型无法对自己的推理过程进行检查和修正。
┌─────────────────────────────────────────────────────────────────┐
│ 传统 LLM 推理方式 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入问题 ──────────────────────────────> 直接输出答案 │
│ │ │ │
│ │ (黑箱过程,无法追踪) │ │
│ │ │ │
│ ▼ ▼ │
│ "小明有5个苹果, "小明还剩 │
│ 给了小红2个, 7个苹果" │
│ 又买了4个..." (错误!) │
│ │
└─────────────────────────────────────────────────────────────────┘
1.2 推理能力的研究演进
近年来,研究者们提出了一系列增强 LLM 推理能力的方法,形成了一个清晰的技术演进脉络:
┌─────────────────────────────────────────────────────────────────────────┐
│ LLM 推理能力演进图 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 2022.01 ──── Chain-of-Thought (CoT) │
│ │ │ │
│ │ ▼ │
│ │ 让模型"展示思考过程" │
│ │ │
│ 2022.10 ──── ReAct (Reasoning + Acting) │
│ │ │ │
│ │ ▼ │
│ │ 推理与行动交替进行 │
│ │ │
│ 2023.03 ──── Reflexion (Self-Reflection) │
│ │ │ │
│ │ ▼ │
│ │ 引入反思和记忆机制 │
│ │ │
│ 2023.05 ──── Tree-of-Thought (ToT) │
│ │ │ │
│ │ ▼ │
│ │ 探索多条推理路径 │
│ │ │
│ 2023.05 ──── Self-Refine │
│ │ │
│ ▼ │
│ 迭代式自我改进 │
│ │
└─────────────────────────────────────────────────────────────────────────┘1.3 本文结构与学习路径
本文将系统性地介绍五种核心推理技术,每种技术都包含:
- 理论原理:深入理解其背后的思想
- 架构设计:ASCII 图解核心架构
- 代码实现:可运行的 Python 代码
- 实践案例:真实场景的应用示例
📌 阅读建议:建议按顺序阅读,因为后续技术往往建立在前面的基础之上。
2. 🧠 Chain-of-Thought (CoT):思维链推理
2.1 CoT 的核心思想
Chain-of-Thought(思维链) 是 Google 研究团队在 2022 年提出的一种提示工程技术,其核心思想简单而深刻:让模型在输出最终答案之前,先展示其推理过程。
💡 思考:为什么简单地要求模型"一步一步思考"就能显著提升推理能力?
🤔 解答:这涉及到 Transformer 架构的本质特性:
-
注意力机制的局限性:Transformer 在单次前向传播中能处理的"推理深度"有限。通过将推理过程分解为多个 token 序列,每一步都能获得完整的注意力处理。
-
自回归特性的利用:每个新生成的 token 都会成为后续生成的上下文,中间步骤的输出实际上扩展了模型的"工作记忆"。
-
模式匹配的激活:显式的推理步骤能够激活模型在训练过程中学到的推理模式。
┌─────────────────────────────────────────────────────────────────┐
│ CoT 推理架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 问题 │ ──> │ 步骤1 │ ──> │ 步骤2 │ ──> │ 答案 │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ │ │ │ │ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 上下文累积 │ │
│ │ [问题] + [步骤1] + [步骤2] + ... = 增强的推理能力 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
2.2 Few-shot CoT vs Zero-shot CoT
CoT 有两种主要的实现方式:
2.2.1 Few-shot CoT(少样本思维链)
通过在 prompt 中提供几个带有完整推理过程的示例,引导模型学习这种思维模式:
python
FEW_SHOT_COT_PROMPT = """
请一步一步思考来解决以下数学问题。
示例1:
问题:小明有5个苹果,给了小红2个,又从超市买了4个,请问小明现在有几个苹果?
思考过程:
1. 小明最初有5个苹果
2. 给了小红2个后,还剩:5 - 2 = 3个
3. 又买了4个后,总共:3 + 4 = 7个
答案:7个苹果
示例2:
问题:一辆汽车以60公里/小时的速度行驶,需要多长时间才能走完180公里?
思考过程:
1. 速度 = 60公里/小时
2. 距离 = 180公里
3. 时间 = 距离 ÷ 速度 = 180 ÷ 60 = 3小时
答案:3小时
现在请解决这个问题:
问题:{question}
思考过程:
"""2.2.2 Zero-shot CoT(零样本思维链)
仅通过添加简单的触发短语"Let's think step by step"(让我们一步一步思考),就能激活模型的推理能力:
python
ZERO_SHOT_COT_PROMPT = """
问题:{question}
让我们一步一步思考:
"""💡 思考:为什么 Zero-shot CoT 也能有效工作?
🤔 解答:这是因为大语言模型在预训练阶段已经接触过大量包含推理过程的文本(如教科书、论文、技术文档)。"Let's think step by step"这个短语就像一个"开关",能够激活模型内在的推理能力。研究表明,不同的触发短语效果有所差异:
| 触发短语 | 相对效果 |
|---|---|
| "Let's think step by step" | ⭐⭐⭐⭐⭐ |
| "Let's work this out in a step by step way" | ⭐⭐⭐⭐ |
| "First, let's think about this carefully" | ⭐⭐⭐⭐ |
| "Let's solve this problem" | ⭐⭐⭐ |
2.3 CoT 的变体与改进
2.3.1 Self-Consistency(自洽性)
Self-Consistency 是 CoT 的重要改进,核心思想是:多次采样不同的推理路径,通过投票选择最一致的答案。
┌─────────────────────────────────────────────────────────────────────────┐
│ Self-Consistency 架构 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ │
│ │ 问题 │ │
│ └────┬────┘ │
│ │ │
│ ┌─────────────────┼─────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 推理路径1 │ │ 推理路径2 │ │ 推理路径3 │ │
│ │ (温度=0.7)│ │ (温度=0.7)│ │ (温度=0.7)│ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ 答案: 42 答案: 42 答案: 38 │
│ │
│ └─────────────────┼─────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────┐ │
│ │ 多数投票 │ │
│ │ 42: 2票 ✓ │ │
│ │ 38: 1票 │ │
│ └───────┬───────┘ │
│ │ │
│ ▼ │
│ 最终答案: 42 │
│ │
└─────────────────────────────────────────────────────────────────────────┘2.3.2 Complexity-based Prompting(基于复杂度的提示)
这种方法认为更长、更详细的推理链往往更可靠:
- 生成多个不同长度的推理路径
- 选择推理步骤最多的路径
- 使用其对应的答案
2.4 代码实现与实践
下面是一个完整的 CoT 实现框架,包含 Few-shot 和 Zero-shot 两种模式:
python
"""
Chain-of-Thought (CoT) 推理框架
支持 Few-shot CoT、Zero-shot CoT 和 Self-Consistency
"""
import re
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from collections import Counter
import openai
@dataclass
class CoTExample:
"""思维链示例"""
question: str
reasoning: str
answer: str
@dataclass
class CoTResult:
"""思维链推理结果"""
question: str
reasoning: str
answer: str
confidence: float = 1.0
class ChainOfThoughtReasoner:
"""
思维链推理器
支持三种模式:
1. Few-shot CoT: 提供示例引导推理
2. Zero-shot CoT: 使用触发短语激活推理
3. Self-Consistency: 多路径采样投票
"""
def __init__(
self,
model: str = "gpt-4",
api_key: Optional[str] = None,
examples: Optional[List[CoTExample]] = None
):
self.model = model
self.client = openai.OpenAI(api_key=api_key)
self.examples = examples or []
# 默认示例
if not self.examples:
self._load_default_examples()
def _load_default_examples(self):
"""加载默认的思维链示例"""
self.examples = [
CoTExample(
question="一个房间里有15个人,出去了6个,又进来了4个,现在房间里有多少人?",
reasoning="""让我一步一步分析:
1. 最初房间里有15个人
2. 出去了6个人后:15 - 6 = 9人
3. 又进来了4个人后:9 + 4 = 13人
所以,现在房间里有13人。""",
answer="13"
),
CoTExample(
question="小华买了3本书,每本25元,给了店员100元,应该找回多少钱?",
reasoning="""让我逐步计算:
1. 首先计算3本书的总价:3 × 25 = 75元
2. 小华给了店员100元
3. 应找回的零钱:100 - 75 = 25元
所以,应该找回25元。""",
answer="25"
),
CoTExample(
question="一列火车从A站到B站需要3小时,如果速度提高50%,需要多长时间?",
reasoning="""让我们分析这个问题:
1. 设原速度为v,距离为d
2. 原来:d = v × 3,所以 d = 3v
3. 速度提高50%后,新速度 = v × 1.5 = 1.5v
4. 新的时间 = d ÷ 新速度 = 3v ÷ 1.5v = 2小时
所以,速度提高50%后需要2小时。""",
answer="2小时"
)
]
def _build_few_shot_prompt(self, question: str) -> str:
"""构建 Few-shot CoT 提示"""
prompt = "请一步一步思考来解决问题。\n\n"
for i, example in enumerate(self.examples, 1):
prompt += f"示例{i}:\n"
prompt += f"问题:{example.question}\n"
prompt += f"思考过程:{example.reasoning}\n"
prompt += f"答案:{example.answer}\n\n"
prompt += f"现在请解决这个问题:\n"
prompt += f"问题:{question}\n"
prompt += "思考过程:"
return prompt
def _build_zero_shot_prompt(self, question: str) -> str:
"""构建 Zero-shot CoT 提示"""
return f"""问题:{question}
让我们一步一步思考来解决这个问题:"""
def _extract_answer(self, response: str) -> str:
"""从推理响应中提取最终答案"""
# 尝试多种模式匹配
patterns = [
r"答案[是为::]\s*(.+?)(?:\n|$)",
r"所以[,,]?\s*(?:答案[是为]?)?\s*(.+?)(?:\n|$)",
r"因此[,,]?\s*(?:答案[是为]?)?\s*(.+?)(?:\n|$)",
r"最终答案[是为::]\s*(.+?)(?:\n|$)",
]
for pattern in patterns:
match = re.search(pattern, response, re.IGNORECASE)
if match:
return match.group(1).strip()
# 如果没有匹配到,返回最后一行
lines = response.strip().split('\n')
return lines[-1].strip()
def _call_llm(
self,
prompt: str,
temperature: float = 0.0,
max_tokens: int = 1000
) -> str:
"""调用 LLM"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个善于逻辑推理的助手,会一步一步分析问题。"},
{"role": "user", "content": prompt}
],
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
def reason_few_shot(self, question: str) -> CoTResult:
"""
Few-shot CoT 推理
Args:
question: 待解决的问题
Returns:
CoTResult: 包含推理过程和答案的结果
"""
prompt = self._build_few_shot_prompt(question)
reasoning = self._call_llm(prompt, temperature=0.0)
answer = self._extract_answer(reasoning)
return CoTResult(
question=question,
reasoning=reasoning,
answer=answer,
confidence=1.0
)
def reason_zero_shot(self, question: str) -> CoTResult:
"""
Zero-shot CoT 推理
Args:
question: 待解决的问题
Returns:
CoTResult: 包含推理过程和答案的结果
"""
prompt = self._build_zero_shot_prompt(question)
reasoning = self._call_llm(prompt, temperature=0.0)
answer = self._extract_answer(reasoning)
return CoTResult(
question=question,
reasoning=reasoning,
answer=answer,
confidence=1.0
)
def reason_with_self_consistency(
self,
question: str,
num_samples: int = 5,
temperature: float = 0.7
) -> CoTResult:
"""
Self-Consistency CoT 推理
通过多次采样并投票选择最一致的答案
Args:
question: 待解决的问题
num_samples: 采样次数
temperature: 采样温度
Returns:
CoTResult: 包含最一致答案的结果
"""
prompt = self._build_few_shot_prompt(question)
results = []
answers = []
for _ in range(num_samples):
reasoning = self._call_llm(prompt, temperature=temperature)
answer = self._extract_answer(reasoning)
results.append((reasoning, answer))
answers.append(answer)
# 投票选择最常见的答案
answer_counts = Counter(answers)
most_common_answer, count = answer_counts.most_common(1)[0]
confidence = count / num_samples
# 找到对应该答案的推理过程
for reasoning, answer in results:
if answer == most_common_answer:
return CoTResult(
question=question,
reasoning=reasoning,
answer=most_common_answer,
confidence=confidence
)
# 理论上不会到这里
return results[0]
# 使用示例
def main():
"""演示 CoT 推理"""
reasoner = ChainOfThoughtReasoner(model="gpt-4")
# 测试问题
question = "一个水池有两个进水管A和B,A管单独注满水池需要4小时,B管单独注满需要6小时。如果两管同时打开,需要多长时间注满水池?"
print("=" * 60)
print("Chain-of-Thought 推理演示")
print("=" * 60)
# Few-shot CoT
print("\n【Few-shot CoT】")
result = reasoner.reason_few_shot(question)
print(f"问题:{result.question}")
print(f"推理过程:\n{result.reasoning}")
print(f"答案:{result.answer}")
# Zero-shot CoT
print("\n【Zero-shot CoT】")
result = reasoner.reason_zero_shot(question)
print(f"推理过程:\n{result.reasoning}")
print(f"答案:{result.answer}")
# Self-Consistency
print("\n【Self-Consistency CoT】")
result = reasoner.reason_with_self_consistency(question, num_samples=5)
print(f"推理过程:\n{result.reasoning}")
print(f"答案:{result.answer}")
print(f"置信度:{result.confidence:.2%}")
if __name__ == "__main__":
main()2.5 CoT 的局限性
尽管 CoT 显著提升了 LLM 的推理能力,但它仍有一些局限:
┌─────────────────────────────────────────────────────────────────┐
│ CoT 的局限性 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ❌ 单一路径:只能探索一条推理路径,可能陷入局部最优 │
│ │
│ ❌ 无法回溯:一旦某步推理出错,后续步骤都会受影响 │
│ │
│ ❌ 缺乏评估:无法自主判断推理过程是否正确 │
│ │
│ ❌ 不适合探索性问题:对于需要多方案比较的问题效果有限 │
│ │
└─────────────────────────────────────────────────────────────────┘这些局限性催生了我们接下来要介绍的 Tree-of-Thought。
3. 🌳 Tree-of-Thought (ToT):思维树推理
3.1 从链到树的演进
Tree-of-Thought(思维树) 是普林斯顿大学和 Google DeepMind 在 2023 年联合提出的推理框架。如果说 CoT 是"线性思考",那么 ToT 就是"发散思考"。
💡 思考:为什么要从链式推理升级到树式推理?
🤔 解答:考虑一个国际象棋问题。面对复杂局面,人类棋手不会只考虑一种走法,而是会:
- 探索多种可能的走法
- 评估每种走法的好坏
- 深入分析有希望的分支
- 必要时回溯重新选择
ToT 正是模拟了这种人类的"深度思考"过程。
┌─────────────────────────────────────────────────────────────────────────┐
│ CoT vs ToT 对比 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ Chain-of-Thought (链式) Tree-of-Thought (树式) │
│ │
│ ┌───┐ ┌───┐ │
│ │ P │ 问题 │ P │ 问题 │
│ └─┬─┘ └─┬─┘ │
│ │ ┌───────┼───────┐ │
│ ▼ ▼ ▼ ▼ │
│ ┌───┐ ┌───┐ ┌───┐ ┌───┐ │
│ │T1 │ 思考1 │T1a│ │T1b│ │T1c│ 多个思考 │
│ └─┬─┘ └─┬─┘ └─┬─┘ └───┘ (评估+剪枝) │
│ │ │ │ ✗ │
│ ▼ ▼ ▼ │
│ ┌───┐ ┌───┐ ┌───┐ │
│ │T2 │ 思考2 │T2a│ │T2b│ │
│ └─┬─┘ └─┬─┘ └───┘ │
│ │ │ ✗ │
│ ▼ ▼ │
│ ┌───┐ ┌───┐ │
│ │ A │ 答案 │ A │ 最优答案 │
│ └───┘ └───┘ │
│ │
│ 特点:单一路径 特点:多路径探索 + 评估 + 剪枝 │
│ │
└─────────────────────────────────────────────────────────────────────────┘3.2 ToT 的核心组件
ToT 框架包含四个核心组件:
3.2.1 思考分解(Thought Decomposition)
将问题分解为中间思考步骤,每个步骤都是推理链上的一个节点。
python
def decompose_thoughts(problem: str, num_thoughts: int = 3) -> List[str]:
"""
将问题分解为多个可能的思考方向
Args:
problem: 原始问题
num_thoughts: 每一步生成的思考数量
Returns:
多个思考方向的列表
"""
prompt = f"""
针对以下问题,生成{num_thoughts}个不同的思考方向或解决思路:
问题:{problem}
请提供{num_thoughts}个不同的思考角度,每个角度都是解决问题的一个可能起点。
格式:
思路1: ...
思路2: ...
思路3: ...
"""
# 调用 LLM 生成多个思考方向
return parse_thoughts(llm_call(prompt))3.2.2 思考生成(Thought Generation)
有两种主要的思考生成策略:
┌─────────────────────────────────────────────────────────────────┐
│ 思考生成策略 │
├────────────────────────┬────────────────────────────────────────┤
│ 采样 (Sample) │ 提议 (Propose) │
├────────────────────────┼────────────────────────────────────────┤
│ │ │
│ 从 CoT 提示中独立 │ 在单次 LLM 调用中 │
│ 采样多个思考 │ 一次性生成所有候选思考 │
│ │ │
│ 优点:多样性高 │ 优点:效率高,上下文丰富 │
│ 缺点:可能重复 │ 缺点:多样性可能不足 │
│ │ │
│ 适用:创意性任务 │ 适用:约束明确的任务 │
│ │ │
└────────────────────────┴────────────────────────────────────────┘3.2.3 状态评估(State Evaluation)
评估每个思考状态的价值,决定是否继续探索:
python
def evaluate_state(state: str, problem: str) -> float:
"""
评估当前思考状态的价值
Args:
state: 当前思考状态
problem: 原始问题
Returns:
状态价值分数 (0-1)
"""
prompt = f"""
问题:{problem}
当前推理状态:
{state}
请评估这个推理状态的质量,考虑以下因素:
1. 逻辑是否正确
2. 是否朝着正确方向前进
3. 是否有明显错误
评分标准:
- "确定正确" → 1.0
- "很可能正确" → 0.8
- "可能正确" → 0.5
- "可能错误" → 0.2
- "确定错误" → 0.0
请只返回一个评分数值。
"""
score = float(llm_call(prompt).strip())
return score3.2.4 搜索算法(Search Algorithm)
选择如何遍历思考树:
3.3 搜索策略:BFS vs DFS
┌─────────────────────────────────────────────────────────────────────────┐
│ ToT 搜索策略对比 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 广度优先搜索 (BFS) 深度优先搜索 (DFS) │
│ │
│ Level 1: [A] [B] [C] [A] │
│ ↓ ↓ ↓ │ │
│ Level 2: 全部评估后 [A1] │
│ 选择最优的继续 │ │
│ [A1a] │
│ │ │
│ 到达终点或回溯 │
│ │
│ ┌───────────────────────┐ ┌───────────────────────┐ │
│ │ 适用场景: │ │ 适用场景: │ │
│ │ • 解空间较小 │ │ • 解空间很大 │ │
│ │ • 需要比较多个方案 │ │ • 需要快速找到一个解 │ │
│ │ • 24点游戏 │ │ • 创意写作 │ │
│ └───────────────────────┘ └───────────────────────┘ │
│ │
│ 复杂度:O(b^d) 复杂度:O(d)(带剪枝) │
│ b=分支因子, d=深度 │
│ │
└─────────────────────────────────────────────────────────────────────────┘3.4 完整代码实现
python
"""
Tree-of-Thought (ToT) 推理框架
支持 BFS 和 DFS 搜索策略
"""
from typing import List, Dict, Tuple, Optional, Callable
from dataclasses import dataclass, field
from enum import Enum
import heapq
from abc import ABC, abstractmethod
import openai
class SearchStrategy(Enum):
"""搜索策略枚举"""
BFS = "bfs" # 广度优先
DFS = "dfs" # 深度优先
@dataclass
class ThoughtNode:
"""思考树节点"""
thought: str # 当前思考内容
state: str # 累积状态(从根到当前的完整推理)
value: float = 0.0 # 评估分数
depth: int = 0 # 深度
children: List['ThoughtNode'] = field(default_factory=list)
parent: Optional['ThoughtNode'] = None
def __lt__(self, other):
"""用于优先队列排序"""
return self.value > other.value # 高价值优先
@dataclass
class ToTResult:
"""ToT 推理结果"""
problem: str
solution: str
reasoning_path: List[str]
final_value: float
nodes_explored: int
class TreeOfThoughtReasoner:
"""
思维树推理器
核心组件:
1. 思考生成器:生成候选思考
2. 状态评估器:评估思考质量
3. 搜索引擎:BFS 或 DFS
"""
def __init__(
self,
model: str = "gpt-4",
api_key: Optional[str] = None,
num_thoughts: int = 3,
max_depth: int = 5,
value_threshold: float = 0.3,
search_strategy: SearchStrategy = SearchStrategy.BFS
):
self.model = model
self.client = openai.OpenAI(api_key=api_key)
self.num_thoughts = num_thoughts
self.max_depth = max_depth
self.value_threshold = value_threshold
self.search_strategy = search_strategy
self.nodes_explored = 0
def _call_llm(
self,
prompt: str,
temperature: float = 0.7,
max_tokens: int = 500
) -> str:
"""调用 LLM"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个善于分析和推理的专家。"},
{"role": "user", "content": prompt}
],
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
def generate_thoughts(
self,
problem: str,
current_state: str,
num_thoughts: int = None
) -> List[str]:
"""
生成候选思考
Args:
problem: 原始问题
current_state: 当前推理状态
num_thoughts: 生成的思考数量
Returns:
思考列表
"""
n = num_thoughts or self.num_thoughts
if current_state:
prompt = f"""问题:{problem}
当前推理状态:
{current_state}
请基于当前状态,提出{n}个不同的下一步思考方向。每个方向应该是独立的、有意义的推理步骤。
格式要求(严格遵守):
[思考1]: <第一个思考方向>
[思考2]: <第二个思考方向>
[思考3]: <第三个思考方向>
"""
else:
prompt = f"""问题:{problem}
请提出{n}个不同的思考方向来解决这个问题。每个方向应该是一个有意义的起点。
格式要求(严格遵守):
[思考1]: <第一个思考方向>
[思考2]: <第二个思考方向>
[思考3]: <第三个思考方向>
"""
response = self._call_llm(prompt, temperature=0.8)
# 解析思考
thoughts = []
import re
pattern = r'\[思考\d+\]:\s*(.+?)(?=\[思考|$)'
matches = re.findall(pattern, response, re.DOTALL)
for match in matches[:n]:
thought = match.strip()
if thought:
thoughts.append(thought)
# 如果解析失败,尝试按行分割
if len(thoughts) < n:
lines = response.strip().split('\n')
for line in lines:
line = line.strip()
if line and len(thoughts) < n:
# 清理编号
cleaned = re.sub(r'^[\d\.\-\*\[\]思考:]+\s*', '', line)
if cleaned:
thoughts.append(cleaned)
return thoughts[:n]
def evaluate_thought(
self,
problem: str,
state: str
) -> float:
"""
评估思考状态的价值
Args:
problem: 原始问题
state: 当前状态
Returns:
价值分数 (0-1)
"""
prompt = f"""问题:{problem}
当前推理状态:
{state}
请评估这个推理状态的质量。考虑:
1. 逻辑是否正确?
2. 是否朝着解决问题的方向前进?
3. 是否存在明显错误?
评分标准:
- 1.0: 推理完全正确,已经或接近得到答案
- 0.8: 推理正确,方向正确
- 0.5: 推理基本正确,但需要更多步骤
- 0.3: 存在一些问题,但可以继续
- 0.1: 推理有明显错误
- 0.0: 完全错误,应该放弃这条路径
请只返回一个0到1之间的数字,不要有其他内容。
"""
response = self._call_llm(prompt, temperature=0.3)
try:
# 提取数字
import re
match = re.search(r'(\d+\.?\d*)', response)
if match:
value = float(match.group(1))
return min(max(value, 0.0), 1.0)
except:
pass
return 0.5 # 默认值
def is_terminal(
self,
problem: str,
state: str
) -> Tuple[bool, Optional[str]]:
"""
判断是否达到终止状态
Args:
problem: 原始问题
state: 当前状态
Returns:
(是否终止, 最终答案)
"""
prompt = f"""问题:{problem}
当前推理状态:
{state}
问题1: 这个推理是否已经完成?(已经得到了明确的答案)
问题2: 如果已完成,最终答案是什么?
请按以下格式回答:
完成状态: [是/否]
最终答案: [答案内容,如果未完成则填"无"]
"""
response = self._call_llm(prompt, temperature=0.1)
is_done = "完成状态: 是" in response or "完成状态:是" in response
if is_done:
import re
match = re.search(r'最终答案[:\s]*(.+)', response)
if match:
answer = match.group(1).strip()
if answer and answer != "无":
return True, answer
return False, None
def solve_bfs(self, problem: str) -> ToTResult:
"""
广度优先搜索求解
Args:
problem: 待解决的问题
Returns:
ToTResult: 推理结果
"""
self.nodes_explored = 0
# 初始化根节点
root = ThoughtNode(thought="开始分析", state="", depth=0)
root.value = 1.0
# 当前层的节点
current_level = [root]
best_solution = None
best_value = 0
best_path = []
for depth in range(self.max_depth):
if not current_level:
break
next_level = []
for node in current_level:
self.nodes_explored += 1
# 检查是否终止
is_done, answer = self.is_terminal(problem, node.state)
if is_done and answer:
if node.value > best_value:
best_value = node.value
best_solution = answer
# 回溯构建路径
best_path = []
current = node
while current:
best_path.append(current.thought)
current = current.parent
best_path.reverse()
continue
# 生成子思考
thoughts = self.generate_thoughts(problem, node.state)
for thought in thoughts:
# 构建新状态
new_state = f"{node.state}\n步骤{depth + 1}: {thought}" if node.state else f"步骤1: {thought}"
# 评估
value = self.evaluate_thought(problem, new_state)
# 剪枝
if value < self.value_threshold:
continue
child = ThoughtNode(
thought=thought,
state=new_state,
value=value,
depth=depth + 1,
parent=node
)
node.children.append(child)
next_level.append(child)
# 选择价值最高的节点继续(beam search)
next_level.sort(key=lambda x: x.value, reverse=True)
current_level = next_level[:self.num_thoughts * 2] # 保留 top-k
# 如果没有找到明确解,选择价值最高的路径
if not best_solution and current_level:
best_node = max(current_level, key=lambda x: x.value)
best_value = best_node.value
_, best_solution = self.is_terminal(problem, best_node.state)
if not best_solution:
best_solution = best_node.state
best_path = []
current = best_node
while current:
best_path.append(current.thought)
current = current.parent
best_path.reverse()
return ToTResult(
problem=problem,
solution=best_solution or "未能找到解决方案",
reasoning_path=best_path,
final_value=best_value,
nodes_explored=self.nodes_explored
)
def solve_dfs(
self,
problem: str,
max_solutions: int = 1
) -> ToTResult:
"""
深度优先搜索求解
Args:
problem: 待解决的问题
max_solutions: 最大解数量
Returns:
ToTResult: 推理结果
"""
self.nodes_explored = 0
solutions = []
def dfs(state: str, path: List[str], depth: int):
"""递归 DFS"""
if len(solutions) >= max_solutions:
return
self.nodes_explored += 1
# 检查终止条件
if depth >= self.max_depth:
return
is_done, answer = self.is_terminal(problem, state)
if is_done and answer:
value = self.evaluate_thought(problem, state)
solutions.append((answer, path.copy(), value))
return
# 生成并评估子节点
thoughts = self.generate_thoughts(problem, state)
# 评估并排序
evaluated = []
for thought in thoughts:
new_state = f"{state}\n步骤{depth + 1}: {thought}" if state else f"步骤1: {thought}"
value = self.evaluate_thought(problem, new_state)
if value >= self.value_threshold:
evaluated.append((thought, new_state, value))
# 按价值排序,优先探索高价值分支
evaluated.sort(key=lambda x: x[2], reverse=True)
for thought, new_state, value in evaluated:
path.append(thought)
dfs(new_state, path, depth + 1)
path.pop()
# 开始 DFS
dfs("", [], 0)
if solutions:
# 选择价值最高的解
best = max(solutions, key=lambda x: x[2])
return ToTResult(
problem=problem,
solution=best[0],
reasoning_path=best[1],
final_value=best[2],
nodes_explored=self.nodes_explored
)
return ToTResult(
problem=problem,
solution="未能找到解决方案",
reasoning_path=[],
final_value=0.0,
nodes_explored=self.nodes_explored
)
def solve(self, problem: str) -> ToTResult:
"""
根据配置的策略求解问题
Args:
problem: 待解决的问题
Returns:
ToTResult: 推理结果
"""
if self.search_strategy == SearchStrategy.BFS:
return self.solve_bfs(problem)
else:
return self.solve_dfs(problem)
# 24点游戏专用求解器
class Game24Solver(TreeOfThoughtReasoner):
"""
24点游戏求解器
经典 ToT 应用场景:给定4个数字,使用加减乘除得到24
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.num_thoughts = 5
self.max_depth = 3
def generate_thoughts(
self,
problem: str,
current_state: str,
num_thoughts: int = None
) -> List[str]:
"""生成24点游戏的候选操作"""
prompt = f"""24点游戏:{problem}
当前状态:{current_state if current_state else "尚未开始"}
规则:使用加减乘除,让4个数字的计算结果等于24。每个数字只能用一次。
请生成{num_thoughts or self.num_thoughts}个不同的下一步操作。每个操作应该选择两个数字进行一次运算。
格式:[操作]: 数字1 运算符 数字2 = 结果 (剩余数字: x, y, ...)
"""
response = self._call_llm(prompt, temperature=0.8)
# 解析操作
operations = []
import re
lines = response.strip().split('\n')
for line in lines:
if '=' in line and len(operations) < (num_thoughts or self.num_thoughts):
operations.append(line.strip())
return operations
def is_terminal(
self,
problem: str,
state: str
) -> Tuple[bool, Optional[str]]:
"""检查是否得到24"""
if "= 24" in state and "剩余数字:" in state:
# 检查是否只剩一个数字
import re
match = re.search(r'剩余数字:\s*(\d+(?:\s*,\s*\d+)*)', state)
if match:
remaining = match.group(1).split(',')
if len(remaining) == 1:
return True, state
return False, None
# 使用示例
def main():
"""演示 ToT 推理"""
print("=" * 70)
print("Tree-of-Thought 推理演示")
print("=" * 70)
# 创建求解器
reasoner = TreeOfThoughtReasoner(
model="gpt-4",
num_thoughts=3,
max_depth=4,
search_strategy=SearchStrategy.BFS
)
# 测试问题
problem = """
有三个人A、B、C,他们分别是老师、医生、律师(顺序未知)。
已知:
1. A的收入比老师高
2. 医生的收入比B高
3. 医生和C是好朋友
请问A、B、C分别是什么职业?
"""
print(f"\n问题:{problem.strip()}")
print("\n开始 ToT 推理...\n")
result = reasoner.solve(problem)
print("=" * 50)
print("推理结果")
print("=" * 50)
print(f"\n推理路径:")
for i, step in enumerate(result.reasoning_path, 1):
print(f" {i}. {step}")
print(f"\n最终答案:{result.solution}")
print(f"置信度:{result.final_value:.2%}")
print(f"探索节点数:{result.nodes_explored}")
if __name__ == "__main__":
main()3.5 ToT 的应用场景
┌─────────────────────────────────────────────────────────────────────────┐
│ ToT 最佳应用场景 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ✅ 适合的任务: │
│ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ 24点游戏 │ │ 创意写作 │ │ 逻辑谜题 │ │
│ │ (数学组合) │ │ (多方向探索) │ │ (约束推理) │ │
│ └───────────────┘ └───────────────┘ └───────────────┘ │
│ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ 代码debug │ │ 规划任务 │ │ 策略游戏 │ │
│ │ (多假设验证) │ │ (多方案比较) │ │ (博弈分析) │ │
│ └───────────────┘ └───────────────┘ └───────────────┘ │
│ │
│ ❌ 不太适合的任务: │
│ │
│ • 简单的事实问答(CoT 足够) │
│ • 实时交互场景(开销太大) │
│ • 答案唯一确定的数学计算 │
│ │
└─────────────────────────────────────────────────────────────────────────┘4. 🔄 Self-Refine:自我精炼机制
4.1 迭代式自我改进
Self-Refine 是 CMU 和 Google 等机构在 2023 年提出的迭代改进框架。其核心思想是:让 LLM 成为自己的评审员和改进者。
💡 思考:人类是如何改进自己的工作的?
🤔 解答:通常是一个"创作-评审-修改"的循环:
- 先完成初稿
- 回顾并找出问题
- 针对问题进行修改
- 重复直到满意
Self-Refine 正是将这个人类的工作流程形式化,并应用于 LLM。
┌─────────────────────────────────────────────────────────────────────────┐
│ Self-Refine 核心流程 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ 迭代循环 │ │
│ │ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ 生成 │ ────> │ 反馈 │ ────> │ 精炼 │ │ │
│ │ │ (GENERATE)│ │(FEEDBACK)│ │ (REFINE) │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ └──────────┘ └──────────┘ └────┬─────┘ │ │
│ │ ▲ │ │ │
│ │ │ │ │ │
│ │ └───────────────────────────────────────┘ │ │
│ │ (如果不满意,继续迭代) │ │
│ │ │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │
│ 输入 ──> [初始输出] ──> [反馈] ──> [改进输出] ──> ... ──> [最终输出] │
│ │
│ 关键特点: │
│ • 使用同一个 LLM 完成所有步骤(无需额外模型) │
│ • 迭代直到满足停止条件(质量阈值/最大迭代次数) │
│ • 反馈是自然语言形式,易于理解和利用 │
│ │
└─────────────────────────────────────────────────────────────────────────┘4.2 反馈生成与优化
Self-Refine 的关键在于如何生成高质量的反馈。以下是不同任务的反馈策略:
┌─────────────────────────────────────────────────────────────────────────┐
│ 不同任务的反馈维度 │
├───────────────────┬─────────────────────────────────────────────────────┤
│ 任务 │ 反馈维度 │
├───────────────────┼─────────────────────────────────────────────────────┤
│ │ • 代码正确性(语法、逻辑) │
│ 代码生成 │ • 效率(时间/空间复杂度) │
│ │ • 可读性(命名、注释、结构) │
│ │ • 边界情况处理 │
├───────────────────┼─────────────────────────────────────────────────────┤
│ │ • 准确性(事实是否正确) │
│ 文本写作 │ • 流畅性(语法、表达) │
│ │ • 相关性(是否切题) │
│ │ • 完整性(是否遗漏要点) │
├───────────────────┼─────────────────────────────────────────────────────┤
│ │ • 逻辑正确性 │
│ 数学推理 │ • 步骤完整性 │
│ │ • 计算准确性 │
│ │ • 解释清晰度 │
├───────────────────┼─────────────────────────────────────────────────────┤
│ │ • 信息提取准确性 │
│ 对话/问答 │ • 回答相关性 │
│ │ • 语气适当性 │
│ │ • 完整性 │
└───────────────────┴─────────────────────────────────────────────────────┘4.3 实践案例与代码
python
"""
Self-Refine 迭代精炼框架
支持多种任务类型的自我改进
"""
from typing import List, Dict, Optional, Callable, Tuple
from dataclasses import dataclass
from enum import Enum
from abc import ABC, abstractmethod
import openai
class TaskType(Enum):
"""支持的任务类型"""
CODE_GENERATION = "code"
TEXT_WRITING = "text"
MATH_REASONING = "math"
DIALOGUE = "dialogue"
GENERAL = "general"
@dataclass
class FeedbackItem:
"""反馈项"""
aspect: str # 反馈维度
issue: str # 问题描述
suggestion: str # 改进建议
severity: str # 严重程度:high/medium/low
@dataclass
class RefinementResult:
"""精炼结果"""
original: str # 原始输出
final: str # 最终输出
iterations: int # 迭代次数
feedback_history: List[List[FeedbackItem]] # 反馈历史
output_history: List[str] # 输出历史
converged: bool # 是否收敛
class FeedbackGenerator(ABC):
"""反馈生成器基类"""
@abstractmethod
def generate(
self,
task: str,
output: str,
context: Optional[Dict] = None
) -> Tuple[List[FeedbackItem], bool]:
"""
生成反馈
Returns:
(反馈列表, 是否满意)
"""
pass
class GeneralFeedbackGenerator(FeedbackGenerator):
"""通用反馈生成器"""
def __init__(self, llm_client, model: str = "gpt-4"):
self.client = llm_client
self.model = model
def generate(
self,
task: str,
output: str,
context: Optional[Dict] = None
) -> Tuple[List[FeedbackItem], bool]:
"""生成通用反馈"""
prompt = f"""任务要求:
{task}
当前输出:
{output}
请作为一个严格的评审者,评估这个输出的质量。从以下维度给出反馈:
1. 正确性:是否准确完成了任务要求
2. 完整性:是否覆盖了所有要点
3. 清晰度:表达是否清楚易懂
4. 质量:整体质量如何
对于每个问题,请按以下格式提供反馈:
[维度]: <问题描述> | 建议: <改进建议> | 严重程度: <high/medium/low>
如果输出已经足够好,无需改进,请直接回复:SATISFIED
请开始评估:
"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个严格但公正的评审专家。"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
feedback_text = response.choices[0].message.content
# 检查是否满意
if "SATISFIED" in feedback_text.upper():
return [], True
# 解析反馈
feedbacks = []
import re
pattern = r'\[([^\]]+)\]:\s*([^|]+)\|\s*建议:\s*([^|]+)\|\s*严重程度:\s*(\w+)'
matches = re.findall(pattern, feedback_text)
for match in matches:
feedbacks.append(FeedbackItem(
aspect=match[0].strip(),
issue=match[1].strip(),
suggestion=match[2].strip(),
severity=match[3].strip().lower()
))
# 如果没有解析到格式化反馈,尝试简单解析
if not feedbacks and "满意" not in feedback_text:
feedbacks.append(FeedbackItem(
aspect="general",
issue="需要改进",
suggestion=feedback_text,
severity="medium"
))
return feedbacks, len(feedbacks) == 0
class CodeFeedbackGenerator(FeedbackGenerator):
"""代码专用反馈生成器"""
def __init__(self, llm_client, model: str = "gpt-4"):
self.client = llm_client
self.model = model
def generate(
self,
task: str,
output: str,
context: Optional[Dict] = None
) -> Tuple[List[FeedbackItem], bool]:
"""生成代码反馈"""
prompt = f"""代码任务:
{task}
提交的代码:{output}
请从以下维度评审这段代码:
1. **正确性**
- 语法是否正确
- 逻辑是否正确
- 是否能处理边界情况
2. **效率**
- 时间复杂度是否合理
- 空间复杂度是否合理
- 是否有不必要的重复计算
3. **可读性**
- 命名是否清晰
- 是否有适当注释
- 代码结构是否清晰
4. **健壮性**
- 是否有错误处理
- 是否处理空值/异常输入
对于每个问题,请按以下格式:
[维度]: <问题描述> | 建议: <改进建议> | 严重程度: <high/medium/low>
如果代码已经足够好,请回复:SATISFIED
"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个资深的代码评审专家。"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
feedback_text = response.choices[0].message.content
if "SATISFIED" in feedback_text.upper():
return [], True
# 解析反馈(同上)
feedbacks = []
import re
pattern = r'\[([^\]]+)\]:\s*([^|]+)\|\s*建议:\s*([^|]+)\|\s*严重程度:\s*(\w+)'
matches = re.findall(pattern, feedback_text)
for match in matches:
feedbacks.append(FeedbackItem(
aspect=match[0].strip(),
issue=match[1].strip(),
suggestion=match[2].strip(),
severity=match[3].strip().lower()
))
if not feedbacks:
feedbacks.append(FeedbackItem(
aspect="general",
issue="需要改进",
suggestion=feedback_text,
severity="medium"
))
return feedbacks, False
class SelfRefiner:
"""
Self-Refine 迭代精炼器
核心功能:
1. 生成初始输出
2. 生成反馈
3. 根据反馈改进输出
4. 迭代直到满意或达到最大次数
"""
def __init__(
self,
model: str = "gpt-4",
api_key: Optional[str] = None,
max_iterations: int = 3,
task_type: TaskType = TaskType.GENERAL
):
self.model = model
self.client = openai.OpenAI(api_key=api_key)
self.max_iterations = max_iterations
self.task_type = task_type
# 选择合适的反馈生成器
if task_type == TaskType.CODE_GENERATION:
self.feedback_generator = CodeFeedbackGenerator(self.client, model)
else:
self.feedback_generator = GeneralFeedbackGenerator(self.client, model)
def _generate_initial(self, task: str) -> str:
"""生成初始输出"""
prompt = f"""请完成以下任务:
{task}
请直接给出你的回答:
"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个专业且认真的助手。"},
{"role": "user", "content": prompt}
],
temperature=0.7
)
return response.choices[0].message.content
def _refine(
self,
task: str,
current_output: str,
feedbacks: List[FeedbackItem]
) -> str:
"""根据反馈改进输出"""
feedback_text = "\n".join([
f"- [{f.aspect}] {f.issue} → 建议: {f.suggestion}"
for f in feedbacks
])
prompt = f"""原始任务:
{task}
你之前的输出:
{current_output}
收到的反馈:
{feedback_text}
请根据上述反馈,改进你的输出。保留好的部分,修正有问题的部分。
改进后的输出:
"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个善于学习和改进的助手。认真对待每一条反馈。"},
{"role": "user", "content": prompt}
],
temperature=0.5
)
return response.choices[0].message.content
def refine(self, task: str, initial_output: Optional[str] = None) -> RefinementResult:
"""
执行完整的自我精炼流程
Args:
task: 任务描述
initial_output: 可选的初始输出,如果不提供则自动生成
Returns:
RefinementResult: 精炼结果
"""
# 生成或使用初始输出
if initial_output:
current_output = initial_output
else:
current_output = self._generate_initial(task)
output_history = [current_output]
feedback_history = []
# 迭代精炼
for iteration in range(self.max_iterations):
print(f" 迭代 {iteration + 1}/{self.max_iterations}...")
# 生成反馈
feedbacks, is_satisfied = self.feedback_generator.generate(
task, current_output
)
feedback_history.append(feedbacks)
# 如果满意,停止迭代
if is_satisfied:
print(f" ✓ 在第 {iteration + 1} 次迭代后满意")
return RefinementResult(
original=output_history[0],
final=current_output,
iterations=iteration + 1,
feedback_history=feedback_history,
output_history=output_history,
converged=True
)
# 显示反馈摘要
high_severity = sum(1 for f in feedbacks if f.severity == "high")
print(f" 发现 {len(feedbacks)} 个问题 ({high_severity} 个高优先级)")
# 精炼
current_output = self._refine(task, current_output, feedbacks)
output_history.append(current_output)
print(f" 达到最大迭代次数 {self.max_iterations}")
return RefinementResult(
original=output_history[0],
final=current_output,
iterations=self.max_iterations,
feedback_history=feedback_history,
output_history=output_history,
converged=False
)
# 便捷函数
def self_refine(
task: str,
model: str = "gpt-4",
max_iterations: int = 3,
task_type: TaskType = TaskType.GENERAL
) -> RefinementResult:
"""
便捷的 Self-Refine 调用函数
Args:
task: 任务描述
model: 使用的模型
max_iterations: 最大迭代次数
task_type: 任务类型
Returns:
精炼结果
"""
refiner = SelfRefiner(
model=model,
max_iterations=max_iterations,
task_type=task_type
)
return refiner.refine(task)
# 使用示例
def main():
"""演示 Self-Refine"""
print("=" * 70)
print("Self-Refine 迭代精炼演示")
print("=" * 70)
# 代码生成任务
task = """
请实现一个 Python 函数 `find_pairs(nums, target)`:
- 输入:一个整数列表 nums 和一个目标值 target
- 输出:所有和等于 target 的数对(以元组列表形式返回)
- 要求:同一个元素不能使用两次,但列表中可能有重复元素
示例:
find_pairs([1, 2, 3, 4, 3], 6) → [(2, 4), (3, 3)]
"""
print(f"\n任务:{task.strip()}")
print("\n开始 Self-Refine 流程...\n")
refiner = SelfRefiner(
model="gpt-4",
max_iterations=3,
task_type=TaskType.CODE_GENERATION
)
result = refiner.refine(task)
print("\n" + "=" * 70)
print("精炼完成!")
print("=" * 70)
print(f"\n迭代次数:{result.iterations}")
print(f"是否收敛:{'是' if result.converged else '否'}")
print("\n【初始输出】")
print("-" * 40)
print(result.original[:500] + "..." if len(result.original) > 500 else result.original)
print("\n【最终输出】")
print("-" * 40)
print(result.final[:500] + "..." if len(result.final) > 500 else result.final)
print("\n【改进历程】")
for i, feedbacks in enumerate(result.feedback_history):
print(f"\n第 {i + 1} 轮反馈:")
for f in feedbacks[:3]: # 只显示前3条
print(f" • [{f.severity}] {f.aspect}: {f.issue[:50]}...")
if __name__ == "__main__":
main()4.4 Self-Refine 的优势与局限
┌─────────────────────────────────────────────────────────────────────────┐
│ Self-Refine 分析 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ✅ 优势: │
│ │
│ • 无需额外训练:直接使用现有 LLM,通过提示工程实现 │
│ • 无需标注数据:不需要人工标注的反馈数据 │
│ • 普适性强:适用于多种任务类型 │
│ • 可解释性好:每一步改进都有明确的反馈依据 │
│ │
│ ❌ 局限: │
│ │
│ • 依赖模型能力:如果模型本身能力有限,自我反馈可能不准确 │
│ • 计算开销:多次迭代增加 API 调用成本 │
│ • 可能陷入循环:某些情况下可能反复修改同一问题 │
│ • 评估偏差:模型可能对自己的输出过于宽容或严格 │
│ │
│ 💡 最佳实践: │
│ │
│ • 设置合理的最大迭代次数(通常 2-4 次) │
│ • 针对任务类型设计专门的反馈维度 │
│ • 结合外部验证(如代码执行、事实核查) │
│ • 监控迭代历史,避免无效循环 │
│ │
└─────────────────────────────────────────────────────────────────────────┘5. 🪞 Reflexion:反思式学习
5.1 语言强化学习
Reflexion 是 Shinn 等人在 2023 年提出的创新框架,将传统强化学习中的"试错-学习"机制引入到语言智能体中。
💡 思考:传统强化学习和 Reflexion 有什么区别?
🤔 解答:
┌─────────────────────────────────────────────────────────────────────────┐
│ 传统 RL vs Reflexion 对比 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 传统强化学习 Reflexion │
│ ┌─────────────────────┐ ┌─────────────────────┐ │
│ │ │ │ │ │
│ │ 数值梯度更新 │ │ 语言反思更新 │ │
│ │ (参数调整) │ │ (记忆增强) │ │
│ │ │ │ │ │
│ └─────────────────────┘ └─────────────────────┘ │
│ │
│ • 需要大量样本 │ • 样本效率高 │
│ • 需要可微分奖励 │ • 使用自然语言反馈 │
│ • 更新模型参数 │ • 更新外部记忆 │
│ • 训练成本高 │ • 无需额外训练 │
│ │
│ 工作流程对比: │
│ │
│ 传统 RL: 状态 → 动作 → 奖励 → 梯度 → 参数更新 │
│ │
│ Reflexion: 任务 → 尝试 → 反馈 → 反思 → 记忆 → 下次尝试 │
│ │
└─────────────────────────────────────────────────────────────────────────┘5.2 反思记忆机制
Reflexion 的核心是语言反思 和持久记忆的结合:
┌─────────────────────────────────────────────────────────────────────────┐
│ Reflexion 完整架构 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────────────────────────────────────────────────────┐ │
│ │ 环境 (Environment) │ │
│ │ │ │
│ │ 任务定义 ─────────────────────────────────────── 执行反馈 │ │
│ │ │ ▲ │ │
│ └───────┼───────────────────────────────────────────────┼────────┘ │
│ │ │ │
│ ▼ │ │
│ ┌───────────────┐ ┌───────────────┐ │
│ │ │ │ │ │
│ │ Actor │ ──── 执行动作 ───────────────>│ Evaluator │ │
│ │ (执行器) │ │ (评估器) │ │
│ │ │<───────────────── 奖励信号 ───│ │ │
│ └───────┬───────┘ └───────────────┘ │
│ │ │ │
│ │ 轨迹 评估结果 │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ │ │
│ │ Self-Reflection (自我反思) │ │
│ │ │ │
│ │ "我在第3步犯了错误,应该先检查边界条件..." │ │
│ │ "下次尝试时,我需要注意..." │ │
│ │ │ │
│ └─────────────────────────────┬───────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ │ │
│ │ Memory (长期记忆) │ │
│ │ │ │
│ │ ┌─────────────────────────────────────────────────────┐ │ │
│ │ │ Episode 1: "任务A失败,原因是..." │ │ │
│ │ │ Episode 2: "任务B成功,关键是..." │ │ │
│ │ │ Episode 3: "任务C部分成功,改进点..." │ │ │
│ │ │ ... │ │ │
│ │ └─────────────────────────────────────────────────────┘ │ │
│ │ │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────┘5.3 完整实现框架
python
"""
Reflexion 反思式学习框架
实现语言强化学习的核心机制
"""
from typing import List, Dict, Optional, Tuple, Any
from dataclasses import dataclass, field
from abc import ABC, abstractmethod
from datetime import datetime
import json
import openai
@dataclass
class Episode:
"""一次尝试的记录"""
task: str
trajectory: List[str] # 动作轨迹
result: str # 执行结果
reward: float # 奖励分数
reflection: str # 反思内容
timestamp: str = field(default_factory=lambda: datetime.now().isoformat())
@dataclass
class ReflexionMemory:
"""Reflexion 记忆存储"""
episodes: List[Episode] = field(default_factory=list)
max_episodes: int = 10 # 保留的最大记录数
def add(self, episode: Episode):
"""添加新的尝试记录"""
self.episodes.append(episode)
# 保留最近的记录
if len(self.episodes) > self.max_episodes:
self.episodes = self.episodes[-self.max_episodes:]
def get_recent(self, n: int = 3) -> List[Episode]:
"""获取最近的n条记录"""
return self.episodes[-n:]
def get_successful(self) -> List[Episode]:
"""获取成功的尝试"""
return [e for e in self.episodes if e.reward >= 0.8]
def get_failed(self) -> List[Episode]:
"""获取失败的尝试"""
return [e for e in self.episodes if e.reward < 0.5]
def to_context(self) -> str:
"""将记忆转换为上下文文本"""
if not self.episodes:
return "暂无历史记录。"
context = "之前的尝试记录:\n\n"
for i, ep in enumerate(self.episodes[-3:], 1): # 只用最近3条
context += f"【尝试 {i}】\n"
context += f"结果:{'成功' if ep.reward >= 0.8 else '失败'} (得分: {ep.reward:.2f})\n"
context += f"反思:{ep.reflection}\n\n"
return context
class Evaluator(ABC):
"""评估器基类"""
@abstractmethod
def evaluate(
self,
task: str,
trajectory: List[str],
result: str
) -> Tuple[float, str]:
"""
评估执行结果
Returns:
(奖励分数 0-1, 评估反馈)
"""
pass
class LLMEvaluator(Evaluator):
"""基于 LLM 的评估器"""
def __init__(self, client, model: str = "gpt-4"):
self.client = client
self.model = model
def evaluate(
self,
task: str,
trajectory: List[str],
result: str
) -> Tuple[float, str]:
"""使用 LLM 评估"""
trajectory_text = "\n".join([f" {i+1}. {t}" for i, t in enumerate(trajectory)])
prompt = f"""请评估以下任务执行的结果:
任务:{task}
执行轨迹:
{trajectory_text}
最终结果:{result}
请评估:
1. 任务是否成功完成?
2. 执行过程是否高效?
3. 结果质量如何?
输出格式:
分数: <0-1的数字>
评估: <详细评估说明>
"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个公正的任务评估专家。"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
content = response.choices[0].message.content
# 解析分数
import re
score_match = re.search(r'分数:\s*(\d+\.?\d*)', content)
score = float(score_match.group(1)) if score_match else 0.5
score = min(max(score, 0), 1)
# 解析评估
eval_match = re.search(r'评估:\s*(.+)', content, re.DOTALL)
evaluation = eval_match.group(1).strip() if eval_match else content
return score, evaluation
class CodeExecutionEvaluator(Evaluator):
"""代码执行评估器"""
def __init__(self, test_cases: List[Dict[str, Any]]):
self.test_cases = test_cases
def evaluate(
self,
task: str,
trajectory: List[str],
result: str # result 是代码
) -> Tuple[float, str]:
"""通过执行测试用例评估"""
passed = 0
failed_cases = []
# 创建执行环境
local_env = {}
try:
exec(result, local_env)
except Exception as e:
return 0.0, f"代码执行错误: {str(e)}"
for i, case in enumerate(self.test_cases):
try:
func_name = case.get('function', 'solution')
args = case.get('input', [])
expected = case.get('expected')
if func_name in local_env:
actual = local_env[func_name](*args) if isinstance(args, list) else local_env[func_name](args)
if actual == expected:
passed += 1
else:
failed_cases.append(f"用例{i+1}: 期望{expected}, 实际{actual}")
else:
failed_cases.append(f"未找到函数 {func_name}")
except Exception as e:
failed_cases.append(f"用例{i+1}执行错误: {str(e)}")
score = passed / len(self.test_cases) if self.test_cases else 0
if score == 1.0:
feedback = "所有测试用例通过!"
else:
feedback = f"通过 {passed}/{len(self.test_cases)} 个测试用例。\n失败: " + "; ".join(failed_cases)
return score, feedback
class ReflexionAgent:
"""
Reflexion 智能体
核心组件:
1. Actor: 执行任务的 LLM
2. Evaluator: 评估结果
3. Self-Reflection: 生成反思
4. Memory: 存储历史反思
"""
def __init__(
self,
model: str = "gpt-4",
api_key: Optional[str] = None,
evaluator: Optional[Evaluator] = None,
max_trials: int = 5
):
self.model = model
self.client = openai.OpenAI(api_key=api_key)
self.evaluator = evaluator or LLMEvaluator(self.client, model)
self.max_trials = max_trials
self.memory = ReflexionMemory()
def _call_llm(
self,
prompt: str,
system_prompt: str = "你是一个专业的问题解决专家。",
temperature: float = 0.7
) -> str:
"""调用 LLM"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
],
temperature=temperature
)
return response.choices[0].message.content
def act(self, task: str, memory_context: str = "") -> Tuple[List[str], str]:
"""
执行任务
Args:
task: 任务描述
memory_context: 记忆上下文
Returns:
(动作轨迹, 最终结果)
"""
prompt = f"""任务:{task}
{memory_context}
请解决这个任务。展示你的思考和执行步骤,然后给出最终答案。
格式:
思考步骤:
1. ...
2. ...
...
最终答案:
<你的答案>
"""
response = self._call_llm(prompt)
# 解析轨迹和结果
trajectory = []
result = response
import re
# 提取步骤
step_pattern = r'\d+\.\s*(.+?)(?=\d+\.|最终答案|$)'
steps = re.findall(step_pattern, response, re.DOTALL)
trajectory = [s.strip() for s in steps if s.strip()]
# 提取最终答案
answer_match = re.search(r'最终答案[::]\s*(.+)', response, re.DOTALL)
if answer_match:
result = answer_match.group(1).strip()
return trajectory, result
def reflect(
self,
task: str,
trajectory: List[str],
result: str,
evaluation: str,
reward: float
) -> str:
"""
生成反思
Args:
task: 任务描述
trajectory: 执行轨迹
result: 执行结果
evaluation: 评估反馈
reward: 奖励分数
Returns:
反思内容
"""
trajectory_text = "\n".join([f" {i+1}. {t}" for i, t in enumerate(trajectory)])
prompt = f"""请对这次任务执行进行深度反思:
任务:{task}
执行轨迹:
{trajectory_text}
结果:{result}
评估反馈:{evaluation}
得分:{reward:.2f}
请反思:
1. 哪些地方做得好?为什么成功?
2. 哪些地方做得不好?失败的原因是什么?
3. 下次遇到类似任务,应该如何改进?
4. 有什么通用的教训可以总结?
请用简洁的语言总结你的反思(控制在200字以内):
"""
reflection = self._call_llm(
prompt,
system_prompt="你是一个善于自我反思和总结的学习者。",
temperature=0.5
)
return reflection
def solve(self, task: str) -> Dict[str, Any]:
"""
使用 Reflexion 机制解决任务
Args:
task: 任务描述
Returns:
包含解决过程和结果的字典
"""
results = {
"task": task,
"trials": [],
"success": False,
"final_result": None,
"total_trials": 0
}
for trial in range(self.max_trials):
print(f"\n{'='*50}")
print(f"尝试 {trial + 1}/{self.max_trials}")
print('='*50)
# 获取记忆上下文
memory_context = self.memory.to_context()
# 执行任务
print("执行中...")
trajectory, result = self.act(task, memory_context)
print(f"得到结果: {result[:100]}...")
# 评估结果
print("评估中...")
reward, evaluation = self.evaluator.evaluate(task, trajectory, result)
print(f"得分: {reward:.2f}")
# 记录这次尝试
trial_record = {
"trial": trial + 1,
"trajectory": trajectory,
"result": result,
"reward": reward,
"evaluation": evaluation
}
# 检查是否成功
if reward >= 0.9:
print("✓ 任务成功完成!")
results["success"] = True
results["final_result"] = result
results["total_trials"] = trial + 1
# 成功也要反思(总结成功经验)
reflection = self.reflect(task, trajectory, result, evaluation, reward)
trial_record["reflection"] = reflection
episode = Episode(
task=task,
trajectory=trajectory,
result=result,
reward=reward,
reflection=reflection
)
self.memory.add(episode)
results["trials"].append(trial_record)
return results
# 失败则反思
print("反思中...")
reflection = self.reflect(task, trajectory, result, evaluation, reward)
print(f"反思: {reflection[:150]}...")
trial_record["reflection"] = reflection
# 存入记忆
episode = Episode(
task=task,
trajectory=trajectory,
result=result,
reward=reward,
reflection=reflection
)
self.memory.add(episode)
results["trials"].append(trial_record)
# 达到最大尝试次数
results["total_trials"] = self.max_trials
if results["trials"]:
best_trial = max(results["trials"], key=lambda x: x["reward"])
results["final_result"] = best_trial["result"]
return results
# 专门用于代码任务的 Reflexion Agent
class CodeReflexionAgent(ReflexionAgent):
"""代码任务专用 Reflexion 智能体"""
def __init__(
self,
test_cases: List[Dict[str, Any]],
**kwargs
):
evaluator = CodeExecutionEvaluator(test_cases)
super().__init__(evaluator=evaluator, **kwargs)
self.test_cases = test_cases
def act(self, task: str, memory_context: str = "") -> Tuple[List[str], str]:
"""执行代码生成任务"""
prompt = f"""编程任务:{task}
测试用例:
{json.dumps(self.test_cases, indent=2, ensure_ascii=False)}
{memory_context}
请编写代码解决这个问题。
要求:
1. 只输出代码,不要有多余的解释
2. 使用 Python 语言
3. 函数名要与测试用例中的 function 字段一致
```python
<你的代码>
python
response = self._call_llm(prompt)
# 提取代码
import re
code_match = re.search(r'```python\s*(.*?)\s*```', response, re.DOTALL)
if code_match:
code = code_match.group(1)
else:
code = response
# 简化轨迹
trajectory = ["分析任务", "编写代码", "测试验证"]
return trajectory, code
# 使用示例
def main():
"""演示 Reflexion"""
print("=" * 70)
print("Reflexion 反思式学习演示")
print("=" * 70)
# 定义代码任务和测试用例
task = "实现一个函数 is_palindrome(s),判断字符串是否是回文(忽略空格和大小写)"
test_cases = [
{"function": "is_palindrome", "input": ["racecar"], "expected": True},
{"function": "is_palindrome", "input": ["hello"], "expected": False},
{"function": "is_palindrome", "input": ["A man a plan a canal Panama"], "expected": True},
{"function": "is_palindrome", "input": [""], "expected": True},
{"function": "is_palindrome", "input": ["Was it a car or a cat I saw"], "expected": True},
]
print(f"\n任务:{task}")
print(f"测试用例数:{len(test_cases)}")
agent = CodeReflexionAgent(
test_cases=test_cases,
model="gpt-4",
max_trials=3
)
results = agent.solve(task)
print("\n" + "=" * 70)
print("最终结果")
print("=" * 70)
print(f"成功:{results['success']}")
print(f"尝试次数:{results['total_trials']}")
print(f"\n最终代码:\n{results['final_result']}")
print("\n学习历程:")
for trial in results['trials']:
print(f"\n[尝试 {trial['trial']}] 得分: {trial['reward']:.2f}")
print(f"反思: {trial['reflection'][:100]}...")
if __name__ == "__main__":
main()5.4 Reflexion 的关键洞察
┌─────────────────────────────────────────────────────────────────────────┐
│ Reflexion 核心洞察 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 💡 洞察1:语言是天然的强化信号载体 │
│ │
│ 传统 RL:数值奖励 → 梯度 → 参数更新 │
│ Reflexion:语言反馈 → 反思 → 记忆更新 │
│ │
│ 语言比数值能承载更丰富的信息! │
│ │
│ ───────────────────────────────────────────────────────────────────── │
│ │
│ 💡 洞察2:外部记忆比参数更新更灵活 │
│ │
│ 参数更新:需要大量样本,可能灾难性遗忘 │
│ 外部记忆:即时生效,可选择性保留 │
│ │
│ ───────────────────────────────────────────────────────────────────── │
│ │
│ 💡 洞察3:自我反思能力是涌现能力 │
│ │
│ 只有足够大的模型才能进行有意义的自我反思 │
│ 小模型的"反思"可能只是复述或胡言 │
│ │
│ ───────────────────────────────────────────────────────────────────── │
│ │
│ 💡 洞察4:失败是宝贵的学习资源 │
│ │
│ Reflexion 不怕失败,每次失败都是学习机会 │
│ 关键是能从失败中提取有价值的教训 │
│ │
└─────────────────────────────────────────────────────────────────────────┘6. ⚡ ReAct:推理与行动的协同
6.1 Reasoning + Acting 范式
ReAct 是 Yao 等人在 2022 年提出的框架,核心创新是将**推理(Reasoning)和行动(Acting)**交织在一起,形成 Thought-Action-Observation 循环。
💡 思考:为什么要将推理和行动结合?
🤔 解答:纯推理(如 CoT)缺乏与真实世界的交互,可能产生幻觉;纯行动(如传统 Agent)缺乏规划能力,容易盲目试错。ReAct 结合了两者的优势:
┌─────────────────────────────────────────────────────────────────────────┐
│ 推理与行动的关系 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 纯推理 (Reasoning Only) 纯行动 (Acting Only) │
│ ┌─────────────────────┐ ┌─────────────────────┐ │
│ │ │ │ │ │
│ │ Thought → Thought │ │ Action → Action │ │
│ │ → Thought │ │ → Action │ │
│ │ → Answer │ │ → Result │ │
│ │ │ │ │ │
│ └─────────────────────┘ └─────────────────────┘ │
│ │
│ 问题:可能脱离现实 │ 问题:缺乏规划 │
│ 产生幻觉 │ 效率低下 │
│ │
│ ────────────────────────────────────────────────────────────────── │
│ │
│ ReAct (结合) │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ │ │
│ │ Thought ──> Action ──> Observation │ │
│ │ ▲ │ │ │
│ │ │ │ │ │
│ │ └─────────────────────────┘ │ │
│ │ (循环) │ │
│ │ │ │
│ │ 思考指导行动,观察反馈思考 │ │
│ │ │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │
│ 优势:推理有据可依,行动有的放矢 │
│ │
└─────────────────────────────────────────────────────────────────────────┘6.2 ReAct 循环详解
ReAct 的核心是 Thought-Action-Observation 三元组循环:
┌─────────────────────────────────────────────────────────────────────────┐
│ ReAct 执行流程 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ │
│ │ Task │ │
│ │ (任务) │ │
│ └───────┬───────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │ │
│ │ │ Thought │ ───> │ Action │ ───> │ Observation │ │ │
│ │ │ (思考) │ │ (行动) │ │ (观察) │ │ │
│ │ └──────────┘ └──────────┘ └──────────────┘ │ │
│ │ │ │ │ │
│ │ │ ReAct 循环 │ │ │
│ │ └─────────────────────────────────────┘ │ │
│ │ │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Finish(answer) │ │
│ │ (完成) │ │
│ └─────────────────────┘ │
│ │
│ 示例轨迹: │
│ ─────────────────────────────────────────────────────────────────── │
│ │
│ Task: "科比·布莱恩特获得了几枚NBA总冠军戒指?" │
│ │
│ Thought 1: 我需要查找科比·布莱恩特的NBA职业生涯信息 │
│ Action 1: Search[科比·布莱恩特 NBA 总冠军] │
│ Obs 1: 科比·布莱恩特(1978-2020),湖人队传奇球星, │
│ 5次NBA总冠军(2000,2001,2002,2009,2010)... │
│ │
│ Thought 2: 根据搜索结果,科比获得了5次NBA总冠军 │
│ Action 2: Finish[5枚] │
│ │
└─────────────────────────────────────────────────────────────────────────┘6.3 工具调用集成
ReAct 的强大之处在于能够灵活调用各种工具:
┌─────────────────────────────────────────────────────────────────────────┐
│ ReAct 工具生态 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ ReAct Agent │ │
│ └─────────────────────────────┬───────────────────────────────────┘ │
│ │ │
│ ┌──────────────────┼──────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │
│ │ 知识检索工具 │ │ 计算执行工具 │ │ 外部API工具 │ │
│ └─────────────────┘ └─────────────────┘ └─────────────────┘ │
│ │ │ │ │
│ ┌──────┴──────┐ ┌──────┴──────┐ ┌──────┴──────┐ │
│ │ │ │ │ │ │ │
│ │ • Search │ │ • Calculate │ │ • Weather │ │
│ │ • Wikipedia │ │ • Python │ │ • Calendar │ │
│ │ • Lookup │ │ • SQL │ │ • Email │ │
│ │ • RAG │ │ • Wolfram │ │ • Slack │ │
│ │ │ │ │ │ │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │
│ 常用工具清单: │
│ ────────────────────────────────────────────────────────────────── │
│ • Search[query] - 网络搜索 │
│ • Wikipedia[topic] - 维基百科查询 │
│ • Lookup[keyword] - 在当前页面查找 │
│ • Calculate[expr] - 数学计算 │
│ • Python[code] - 执行 Python 代码 │
│ • Finish[answer] - 结束并返回答案 │
│ │
└─────────────────────────────────────────────────────────────────────────┘6.4 生产级实现
python
"""
ReAct (Reasoning + Acting) 框架
生产级实现,支持多种工具和灵活配置
"""
from typing import List, Dict, Optional, Callable, Any, Tuple
from dataclasses import dataclass, field
from abc import ABC, abstractmethod
from enum import Enum
import re
import json
import openai
@dataclass
class Tool:
"""工具定义"""
name: str
description: str
parameters: Dict[str, str]
function: Callable[[str], str]
@dataclass
class ReActStep:
"""ReAct 单步执行记录"""
step_num: int
thought: str
action: str
action_input: str
observation: str
@dataclass
class ReActResult:
"""ReAct 执行结果"""
task: str
steps: List[ReActStep]
final_answer: str
success: bool
total_steps: int
class ToolRegistry:
"""工具注册表"""
def __init__(self):
self.tools: Dict[str, Tool] = {}
def register(self, tool: Tool):
"""注册工具"""
self.tools[tool.name.lower()] = tool
def get(self, name: str) -> Optional[Tool]:
"""获取工具"""
return self.tools.get(name.lower())
def list_tools(self) -> str:
"""列出所有工具"""
descriptions = []
for name, tool in self.tools.items():
params = ", ".join([f"{k}: {v}" for k, v in tool.parameters.items()])
descriptions.append(f" - {tool.name}[{params}]: {tool.description}")
return "\n".join(descriptions)
def execute(self, action: str, action_input: str) -> str:
"""执行工具"""
tool = self.get(action)
if tool:
try:
return tool.function(action_input)
except Exception as e:
return f"工具执行错误: {str(e)}"
return f"未知工具: {action}"
class ReActAgent:
"""
ReAct 智能体
实现 Thought-Action-Observation 循环
支持自定义工具和多种任务类型
"""
def __init__(
self,
model: str = "gpt-4",
api_key: Optional[str] = None,
max_steps: int = 10,
verbose: bool = True
):
self.model = model
self.client = openai.OpenAI(api_key=api_key)
self.max_steps = max_steps
self.verbose = verbose
self.tool_registry = ToolRegistry()
# 注册默认工具
self._register_default_tools()
def _register_default_tools(self):
"""注册默认工具"""
# 搜索工具(模拟)
self.tool_registry.register(Tool(
name="Search",
description="搜索互联网获取信息",
parameters={"query": "搜索关键词"},
function=self._mock_search
))
# 计算工具
self.tool_registry.register(Tool(
name="Calculate",
description="执行数学计算",
parameters={"expression": "数学表达式"},
function=self._calculate
))
# Python 执行工具
self.tool_registry.register(Tool(
name="Python",
description="执行 Python 代码并返回结果",
parameters={"code": "Python 代码"},
function=self._execute_python
))
# 完成工具
self.tool_registry.register(Tool(
name="Finish",
description="完成任务并返回最终答案",
parameters={"answer": "最终答案"},
function=lambda x: f"FINISH:{x}"
))
def _mock_search(self, query: str) -> str:
"""模拟搜索(实际使用时替换为真实搜索API)"""
# 这里应该集成真实的搜索 API
# 为演示目的,返回模拟结果
prompt = f"""模拟搜索引擎结果。用户搜索:"{query}"
请提供一个简短的、相关的搜索结果摘要(模拟真实搜索结果):"""
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个搜索引擎,返回真实、准确的信息摘要。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=200
)
return response.choices[0].message.content
def _calculate(self, expression: str) -> str:
"""数学计算"""
try:
# 安全的数学计算
allowed_names = {
'abs': abs, 'round': round, 'min': min, 'max': max,
'sum': sum, 'pow': pow, 'len': len,
}
# 添加数学函数
import math
allowed_names.update({
'sin': math.sin, 'cos': math.cos, 'tan': math.tan,
'sqrt': math.sqrt, 'log': math.log, 'log10': math.log10,
'pi': math.pi, 'e': math.e
})
result = eval(expression, {"__builtins__": {}}, allowed_names)
return str(result)
except Exception as e:
return f"计算错误: {str(e)}"
def _execute_python(self, code: str) -> str:
"""执行 Python 代码"""
try:
local_vars = {}
exec(code, {"__builtins__": __builtins__}, local_vars)
# 尝试获取结果
if 'result' in local_vars:
return str(local_vars['result'])
elif local_vars:
# 返回最后一个变量
last_var = list(local_vars.values())[-1]
return str(last_var)
return "代码执行成功(无返回值)"
except Exception as e:
return f"执行错误: {str(e)}"
def register_tool(self, tool: Tool):
"""注册自定义工具"""
self.tool_registry.register(tool)
def _build_prompt(
self,
task: str,
steps: List[ReActStep]
) -> str:
"""构建 ReAct 提示"""
tools_desc = self.tool_registry.list_tools()
prompt = f"""你是一个问题解决专家。请使用 Thought-Action-Observation 循环来解决任务。
可用工具:
{tools_desc}
格式要求:
Thought: <你的思考,分析当前情况和下一步计划>
Action: <工具名称>
Action Input: <工具输入参数>
重要规则:
1. 每次只能调用一个工具
2. 必须等待 Observation 后再继续思考
3. 当得到最终答案时,使用 Finish 工具
4. Action 必须是工具列表中的名称
5. 不要虚构 Observation,它由系统提供
任务:{task}
"""
# 添加历史步骤
for step in steps:
prompt += f"""Thought: {step.thought}
Action: {step.action}
Action Input: {step.action_input}
Observation: {step.observation}
"""
return prompt
def _parse_response(self, response: str) -> Tuple[str, str, str]:
"""解析 LLM 响应"""
thought = ""
action = ""
action_input = ""
# 提取 Thought
thought_match = re.search(r'Thought:\s*(.+?)(?=Action:|$)', response, re.DOTALL)
if thought_match:
thought = thought_match.group(1).strip()
# 提取 Action
action_match = re.search(r'Action:\s*(\w+)', response)
if action_match:
action = action_match.group(1).strip()
# 提取 Action Input
input_match = re.search(r'Action Input:\s*(.+?)(?=Observation:|Thought:|$)', response, re.DOTALL)
if input_match:
action_input = input_match.group(1).strip()
return thought, action, action_input
def run(self, task: str) -> ReActResult:
"""
执行 ReAct 循环
Args:
task: 任务描述
Returns:
ReActResult: 执行结果
"""
steps: List[ReActStep] = []
final_answer = ""
success = False
if self.verbose:
print(f"\n{'='*60}")
print(f"任务: {task}")
print('='*60)
for step_num in range(1, self.max_steps + 1):
if self.verbose:
print(f"\n--- 步骤 {step_num} ---")
# 构建提示
prompt = self._build_prompt(task, steps)
# 调用 LLM
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "严格按照 Thought/Action/Action Input 格式回复。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=500
)
llm_output = response.choices[0].message.content
# 解析响应
thought, action, action_input = self._parse_response(llm_output)
if self.verbose:
print(f"Thought: {thought}")
print(f"Action: {action}")
print(f"Action Input: {action_input}")
# 检查是否完成
if action.lower() == "finish":
final_answer = action_input
success = True
step = ReActStep(
step_num=step_num,
thought=thought,
action=action,
action_input=action_input,
observation="任务完成"
)
steps.append(step)
if self.verbose:
print(f"Observation: 任务完成")
print(f"\n✓ 最终答案: {final_answer}")
break
# 执行工具
observation = self.tool_registry.execute(action, action_input)
if self.verbose:
print(f"Observation: {observation[:200]}...")
# 记录步骤
step = ReActStep(
step_num=step_num,
thought=thought,
action=action,
action_input=action_input,
observation=observation
)
steps.append(step)
if not success:
if self.verbose:
print(f"\n⚠ 达到最大步骤数 {self.max_steps},任务未完成")
final_answer = "未能在规定步骤内完成任务"
return ReActResult(
task=task,
steps=steps,
final_answer=final_answer,
success=success,
total_steps=len(steps)
)
# 创建专门的问答 Agent
class QAReActAgent(ReActAgent):
"""问答专用 ReAct Agent"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
# 添加 Wikipedia 工具
self.register_tool(Tool(
name="Wikipedia",
description="查询 Wikipedia 获取百科知识",
parameters={"topic": "查询主题"},
function=self._wikipedia_lookup
))
# 添加 Lookup 工具
self.register_tool(Tool(
name="Lookup",
description="在上一次搜索结果中查找特定关键词",
parameters={"keyword": "要查找的关键词"},
function=self._lookup
))
self._last_search_result = ""
def _wikipedia_lookup(self, topic: str) -> str:
"""Wikipedia 查询"""
# 实际使用时集成 Wikipedia API
prompt = f"请提供关于 '{topic}' 的简短、准确的百科介绍(模拟 Wikipedia):"
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是 Wikipedia,提供准确、简洁的百科信息。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=300
)
self._last_search_result = response.choices[0].message.content
return self._last_search_result
def _lookup(self, keyword: str) -> str:
"""在上次搜索结果中查找"""
if not self._last_search_result:
return "没有可供查找的搜索结果"
if keyword.lower() in self._last_search_result.lower():
# 提取包含关键词的句子
sentences = self._last_search_result.split('。')
relevant = [s for s in sentences if keyword.lower() in s.lower()]
if relevant:
return '。'.join(relevant[:2]) + '。'
return f"在搜索结果中未找到 '{keyword}' 相关内容"
# 使用示例
def main():
"""演示 ReAct"""
print("=" * 70)
print("ReAct (Reasoning + Acting) 演示")
print("=" * 70)
# 创建 Agent
agent = QAReActAgent(
model="gpt-4",
max_steps=6,
verbose=True
)
# 测试问题
questions = [
"中国的首都是哪个城市?它的面积是多少?",
"计算 (25 * 4) + (30 / 5) - 8 的结果",
]
for q in questions:
result = agent.run(q)
print(f"\n{'='*60}")
print(f"总结")
print('='*60)
print(f"任务: {result.task}")
print(f"成功: {result.success}")
print(f"步骤数: {result.total_steps}")
print(f"答案: {result.final_answer}")
if __name__ == "__main__":
main()6.5 ReAct 的优势分析
┌─────────────────────────────────────────────────────────────────────────┐
│ ReAct 技术优势 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 🎯 推理可追踪 │
│ 每一步都有明确的 Thought,决策过程透明可解释 │
│ │
│ 🔧 工具可扩展 │
│ 通过注册新工具,可以轻松扩展 Agent 能力 │
│ │
│ 🔄 反馈即时性 │
│ 每次 Action 后立即获得 Observation,可及时调整策略 │
│ │
│ 🧠 减少幻觉 │
│ 通过外部工具验证信息,降低 LLM 幻觉风险 │
│ │
│ 📊 性能对比 (HotpotQA 数据集): │
│ ┌─────────────────┬────────────┐ │
│ │ 方法 │ 准确率 │ │
│ ├─────────────────┼────────────┤ │
│ │ Standard (直接) │ 25.7% │ │
│ │ Chain-of-Thought│ 29.4% │ │
│ │ ReAct │ 35.1% │ │
│ └─────────────────┴────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────┘7. 🔗 技术对比与选型指南
7.1 五种推理技术全面对比
┌─────────────────────────────────────────────────────────────────────────────────────────────┐
│ 推理技术全面对比 │
├───────────────┬───────────────┬───────────────┬───────────────┬───────────────┬─────────────┤
│ 维度 │ CoT │ ToT │ Self-Refine │ Reflexion │ ReAct │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 核心思想 │ 展示推理过程 │ 探索多路径 │ 迭代自我改进 │ 反思式学习 │ 推理+行动 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 推理方式 │ 线性 │ 树状 │ 循环 │ 循环 │ 交替 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 外部工具 │ 否 │ 否 │ 否 │ 可选 │ 是 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 记忆机制 │ 否 │ 否 │ 否 │ 是 │ 可选 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ API调用 │ 1次 │ 多次 │ 2-5次 │ 多次 │ 多次 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 延迟 │ 低 │ 高 │ 中等 │ 高 │ 中等 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 适用规模 │ 中小型 │ 小型 │ 中型 │ 中型 │ 中大型 │
├───────────────┼───────────────┼───────────────┼───────────────┼───────────────┼─────────────┤
│ 实现难度 │ 低 │ 高 │ 中等 │ 高 │ 中等 │
└───────────────┴───────────────┴───────────────┴───────────────┴───────────────┴─────────────┘7.2 场景选型决策树
┌─────────────────────────────────────────────────────────────────────────┐
│ 推理技术选型决策树 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 任务是什么类型? │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ 简单问答 复杂推理 交互任务 │
│ │ │ │ │
│ ▼ │ ▼ │
│ ┌────┴────┐ │ 需要外部工具? │
│ │ │ │ │ │
│ ▼ ▼ │ ┌─────┴─────┐ │
│ 直接回答 Zero-CoT │ ▼ ▼ │
│ │ 是 → 否 → │
│ │ ReAct Reflexion │
│ │ │
│ ▼ │
│ 需要探索多方案? │
│ │ │
│ ┌────────┴────────┐ │
│ ▼ ▼ │
│ 是 → 否 → │
│ ToT 需要迭代改进? │
│ │ │
│ ┌─────────┴─────────┐ │
│ ▼ ▼ │
│ 是 → 否 → │
│ Self-Refine Few-shot CoT │
│ │
│ ───────────────────────────────────────────────────────────────── │
│ │
│ 快速选型指南: │
│ │
│ • 数学题/逻辑推理 → CoT (快速) 或 ToT (精确) │
│ • 文本生成/优化 → Self-Refine │
│ • 代码任务 → Reflexion (带测试) 或 Self-Refine │
│ • 知识问答 → ReAct (带搜索工具) │
│ • 游戏/谜题 → ToT │
│ • 多轮对话 → ReAct + 记忆 │
│ │
└─────────────────────────────────────────────────────────────────────────┘7.3 性能与成本权衡
┌─────────────────────────────────────────────────────────────────────────┐
│ 性能 vs 成本 权衡矩阵 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 成本 ▲ │
│ (高) │ │
│ │ ┌───────┐ │
│ │ │ ToT │ 高性能 │
│ │ └───────┘ 高成本 │
│ │ │
│ │ ┌───────────┐ ┌───────────┐ │
│ │ │ Reflexion │ │Self-Refine│ │
│ │ └───────────┘ └───────────┘ │
│ │ │
│ │ ┌───────┐ │
│ │ │ ReAct │ │
│ │ └───────┘ │
│ │ │
│ │ ┌────────────────────┐ │
│ │ │ CoT │ 低成本 │
│ (低) │ └────────────────────┘ 适中性能 │
│ └────────────────────────────────────────────────────────> 性能 │
│ (低) (高) │
│ │
│ 成本计算公式: │
│ 总成本 = API调用次数 × 单次token数 × 单价 │
│ │
│ 示例估算(GPT-4,1000 token/次): │
│ • CoT: 1 次 ≈ $0.03 │
│ • ToT: 15 次 ≈ $0.45 │
│ • Self-Refine: 4 次 ≈ $0.12 │
│ • Reflexion: 10 次 ≈ $0.30 │
│ • ReAct: 5 次 ≈ $0.15 │
│ │
└─────────────────────────────────────────────────────────────────────────┘8. 🏗️ 综合架构设计
8.1 多层推理架构
在实际应用中,可以组合多种推理技术构建强大的 Agent 系统:
┌─────────────────────────────────────────────────────────────────────────────────────────────┐
│ 多层推理架构 │
├─────────────────────────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────────────────────────────────┐ │
│ │ 用户接口层 │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ CLI │ │ API │ │ Web │ │ SDK │ │ │
│ │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │ │
│ └─────────────────────────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────────────────────────┐ │
│ │ 编排器 (Orchestrator) │ │
│ │ │ │
│ │ • 任务分解与分配 │ │
│ │ • 策略选择与切换 │ │
│ │ • 结果聚合与返回 │ │
│ └─────────────────────────────────────┬───────────────────────────────────────────────┘ │
│ │ │
│ ┌─────────────────────────┼─────────────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────────┐ ┌───────────────────┐ ┌───────────────────┐ │
│ │ 快速推理模块 │ │ 深度推理模块 │ │ 交互推理模块 │ │
│ │ │ │ │ │ │ │
│ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ Zero-shot │ │ │ │ ToT │ │ │ │ ReAct │ │ │
│ │ │ CoT │ │ │ │ │ │ │ │ │ │ │
│ │ └─────────────┘ │ │ └─────────────┘ │ │ └─────────────┘ │ │
│ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ Self- │ │ │ │ Reflexion │ │ │ │ Tools │ │ │
│ │ │ Consistency │ │ │ │ │ │ │ │ Suite │ │ │
│ │ └─────────────┘ │ │ └─────────────┘ │ │ └─────────────┘ │ │
│ └───────────────────┘ └───────────────────┘ └───────────────────┘ │
│ │ │ │ │
│ └─────────────────────────┼─────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────────────────────────┐ │
│ │ 共享服务层 │ │
│ │ │ │
│ │ ┌───────────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐ │ │
│ │ │ 记忆 │ │ 缓存 │ │ 日志 │ │ 监控 │ │ 评估 │ │ │
│ │ │ 存储 │ │ 服务 │ │ 服务 │ │ 告警 │ │ 服务 │ │ │
│ │ └───────────┘ └───────────┘ └───────────┘ └───────────┘ └───────────┘ │ │
│ └─────────────────────────────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────────────────────┘8.2 自适应策略选择
python
"""
自适应推理策略选择器
根据任务特征自动选择最佳推理策略
"""
from typing import Dict, Any, Optional
from dataclasses import dataclass
from enum import Enum
class ReasoningStrategy(Enum):
"""推理策略枚举"""
DIRECT = "direct" # 直接回答
ZERO_SHOT_COT = "zero_cot" # 零样本 CoT
FEW_SHOT_COT = "few_cot" # 少样本 CoT
SELF_CONSISTENCY = "sc" # 自洽性
TREE_OF_THOUGHT = "tot" # 思维树
SELF_REFINE = "refine" # 自我精炼
REFLEXION = "reflexion" # 反思
REACT = "react" # 推理行动
@dataclass
class TaskProfile:
"""任务特征描述"""
complexity: str # simple, medium, complex
requires_tools: bool # 是否需要外部工具
requires_iteration: bool # 是否需要迭代改进
has_test_cases: bool # 是否有测试用例
is_creative: bool # 是否是创意任务
time_sensitive: bool # 是否时间敏感
accuracy_critical: bool # 是否准确性关键
class AdaptiveReasoningSelector:
"""
自适应推理策略选择器
基于任务特征自动选择最优推理策略
"""
def __init__(self):
self.strategy_costs = {
ReasoningStrategy.DIRECT: 1,
ReasoningStrategy.ZERO_SHOT_COT: 1.2,
ReasoningStrategy.FEW_SHOT_COT: 1.5,
ReasoningStrategy.SELF_CONSISTENCY: 5,
ReasoningStrategy.TREE_OF_THOUGHT: 15,
ReasoningStrategy.SELF_REFINE: 4,
ReasoningStrategy.REFLEXION: 10,
ReasoningStrategy.REACT: 5,
}
def analyze_task(self, task: str) -> TaskProfile:
"""
分析任务特征
实际应用中可以使用 LLM 或规则来分析
"""
# 简化的规则分析
task_lower = task.lower()
# 复杂度判断
if any(w in task_lower for w in ['简单', '快速', '直接']):
complexity = "simple"
elif any(w in task_lower for w in ['分析', '设计', '优化', '复杂']):
complexity = "complex"
else:
complexity = "medium"
# 工具需求
requires_tools = any(w in task_lower for w in [
'搜索', '查询', '计算', '执行', '调用', '获取'
])
# 迭代需求
requires_iteration = any(w in task_lower for w in [
'优化', '改进', '完善', '重构'
])
# 测试用例
has_test_cases = any(w in task_lower for w in [
'测试', '用例', 'test', '验证'
])
# 创意任务
is_creative = any(w in task_lower for w in [
'创作', '写作', '设计', '创意', '想象'
])
# 时间敏感
time_sensitive = any(w in task_lower for w in [
'快速', '立即', '紧急', '马上'
])
# 准确性关键
accuracy_critical = any(w in task_lower for w in [
'精确', '准确', '正确', '必须'
])
return TaskProfile(
complexity=complexity,
requires_tools=requires_tools,
requires_iteration=requires_iteration,
has_test_cases=has_test_cases,
is_creative=is_creative,
time_sensitive=time_sensitive,
accuracy_critical=accuracy_critical
)
def select_strategy(
self,
task: str,
profile: Optional[TaskProfile] = None,
budget: float = 10.0
) -> ReasoningStrategy:
"""
选择最佳推理策略
Args:
task: 任务描述
profile: 任务特征(可选,不提供则自动分析)
budget: 成本预算(相对值)
Returns:
推荐的推理策略
"""
if profile is None:
profile = self.analyze_task(task)
candidates = []
# 需要外部工具 → ReAct
if profile.requires_tools:
candidates.append(ReasoningStrategy.REACT)
# 有测试用例 → Reflexion
if profile.has_test_cases:
candidates.append(ReasoningStrategy.REFLEXION)
# 需要迭代改进 → Self-Refine
if profile.requires_iteration:
candidates.append(ReasoningStrategy.SELF_REFINE)
# 创意任务 + 复杂 → ToT
if profile.is_creative and profile.complexity == "complex":
candidates.append(ReasoningStrategy.TREE_OF_THOUGHT)
# 准确性关键 → Self-Consistency 或 ToT
if profile.accuracy_critical and not profile.time_sensitive:
candidates.append(ReasoningStrategy.SELF_CONSISTENCY)
# 简单任务 → 直接或 Zero-shot CoT
if profile.complexity == "simple":
if profile.time_sensitive:
candidates.append(ReasoningStrategy.DIRECT)
else:
candidates.append(ReasoningStrategy.ZERO_SHOT_COT)
# 中等复杂度 → Few-shot CoT
if profile.complexity == "medium":
candidates.append(ReasoningStrategy.FEW_SHOT_COT)
# 如果没有特殊需求,默认 Zero-shot CoT
if not candidates:
candidates = [ReasoningStrategy.ZERO_SHOT_COT]
# 按成本过滤
valid = [c for c in candidates if self.strategy_costs[c] <= budget]
if not valid:
valid = [ReasoningStrategy.DIRECT] # 最低成本兜底
# 选择最适合的(优先级靠前的)
priority = [
ReasoningStrategy.REACT,
ReasoningStrategy.REFLEXION,
ReasoningStrategy.TREE_OF_THOUGHT,
ReasoningStrategy.SELF_REFINE,
ReasoningStrategy.SELF_CONSISTENCY,
ReasoningStrategy.FEW_SHOT_COT,
ReasoningStrategy.ZERO_SHOT_COT,
ReasoningStrategy.DIRECT,
]
for strategy in priority:
if strategy in valid:
return strategy
return ReasoningStrategy.DIRECT
def get_strategy_config(
self,
strategy: ReasoningStrategy
) -> Dict[str, Any]:
"""获取策略的推荐配置"""
configs = {
ReasoningStrategy.DIRECT: {
"temperature": 0.3,
"max_tokens": 500,
},
ReasoningStrategy.ZERO_SHOT_COT: {
"temperature": 0.5,
"max_tokens": 1000,
"prompt_suffix": "让我们一步一步思考:"
},
ReasoningStrategy.FEW_SHOT_COT: {
"temperature": 0.3,
"max_tokens": 1500,
"num_examples": 3,
},
ReasoningStrategy.SELF_CONSISTENCY: {
"temperature": 0.7,
"num_samples": 5,
"voting": "majority",
},
ReasoningStrategy.TREE_OF_THOUGHT: {
"num_thoughts": 3,
"max_depth": 4,
"search_strategy": "bfs",
"value_threshold": 0.3,
},
ReasoningStrategy.SELF_REFINE: {
"max_iterations": 3,
"feedback_granularity": "detailed",
},
ReasoningStrategy.REFLEXION: {
"max_trials": 5,
"memory_size": 10,
},
ReasoningStrategy.REACT: {
"max_steps": 8,
"tools": ["search", "calculate", "python"],
},
}
return configs.get(strategy, {})
# 使用示例
def demo_selector():
"""演示策略选择"""
selector = AdaptiveReasoningSelector()
test_tasks = [
"1+1等于多少?",
"请帮我搜索今天的新闻头条",
"写一个复杂的排序算法并优化它",
"分析这段代码的问题并修复(提供测试用例)",
"创作一个有创意的短故事",
"精确计算圆周率到小数点后10位",
]
print("推理策略选择演示")
print("=" * 60)
for task in test_tasks:
profile = selector.analyze_task(task)
strategy = selector.select_strategy(task, profile)
config = selector.get_strategy_config(strategy)
print(f"\n任务: {task[:40]}...")
print(f"特征: 复杂度={profile.complexity}, 需要工具={profile.requires_tools}")
print(f"策略: {strategy.value}")
print(f"配置: {config}")
if __name__ == "__main__":
demo_selector()9. 🚀 最佳实践与优化技巧
9.1 通用最佳实践
┌─────────────────────────────────────────────────────────────────────────┐
│ 推理技术最佳实践 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 📌 提示工程 │
│ ───────────────────────────────────────────────────────────────────── │
│ • 使用清晰、结构化的提示格式 │
│ • 明确指定输出格式,便于解析 │
│ • 提供相关示例(Few-shot)以引导输出风格 │
│ • 添加约束条件限制输出范围 │
│ │
│ 🔧 错误处理 │
│ ───────────────────────────────────────────────────────────────────── │
│ • 设置超时机制,避免无限循环 │
│ • 实现重试逻辑,处理 API 失败 │
│ • 添加安全检查,防止危险操作 │
│ • 记录详细日志,便于调试 │
│ │
│ 💰 成本优化 │
│ ───────────────────────────────────────────────────────────────────── │
│ • 从简单策略开始,按需升级 │
│ • 使用缓存避免重复计算 │
│ • 批量处理相似任务 │
│ • 选择合适的模型(不一定最贵的) │
│ │
│ ⚡ 性能优化 │
│ ───────────────────────────────────────────────────────────────────── │
│ • 并行处理独立的推理分支 │
│ • 早期剪枝低质量路径 │
│ • 增量式推理,复用中间结果 │
│ • 设置合理的停止条件 │
│ │
└─────────────────────────────────────────────────────────────────────────┘9.2 各技术的优化要点
python
"""
各推理技术的优化技巧总结
"""
# ================== CoT 优化 ==================
COT_OPTIMIZATION_TIPS = """
1. 使用更精确的触发短语:
✓ "让我们分步解决这个问题,首先..."
✗ "请回答这个问题"
2. 自洽性采样时选择合适的样本数:
• 简单问题:3-5 次
• 中等问题:5-7 次
• 复杂问题:7-10 次
3. 提取答案时使用多种模式匹配:
• "答案是..."
• "因此..."
• "所以..."
• 最后一行
"""
# ================== ToT 优化 ==================
TOT_OPTIMIZATION_TIPS = """
1. 选择合适的搜索策略:
• BFS: 解空间小,需要比较多方案
• DFS: 解空间大,快速找到一个可行解
2. 设计高效的评估函数:
• 使用轻量级评估(关键词匹配)初筛
• 对通过初筛的节点使用详细评估
3. 动态调整分支因子:
• 根节点:多探索(5-7 分支)
• 深层节点:少探索(2-3 分支)
4. 早期剪枝策略:
• 设置递进的阈值(浅层宽松,深层严格)
• 保留价值前 K 的节点
"""
# ================== Self-Refine 优化 ==================
SELF_REFINE_OPTIMIZATION_TIPS = """
1. 设计针对性的反馈维度:
• 代码任务:正确性、效率、可读性
• 写作任务:准确性、流畅性、完整性
• 推理任务:逻辑性、步骤完整性
2. 控制迭代次数:
• 大多数任务 2-3 次足够
• 超过 4 次通常说明问题定义不清
3. 避免过度优化:
• 设置明确的满意阈值
• 检测循环修改(反复改同一处)
4. 结合外部验证:
• 代码:执行测试用例
• 事实:搜索验证
"""
# ================== Reflexion 优化 ==================
REFLEXION_OPTIMIZATION_TIPS = """
1. 设计有效的反思提示:
• 要求具体分析,避免泛泛而谈
• 强调"下次如何改进"
2. 管理记忆存储:
• 保留最有价值的经验(成功和失败都要)
• 定期清理过时的记忆
• 按任务类型组织记忆
3. 平衡探索与利用:
• 前期允许更多尝试
• 后期更多依赖记忆
4. 失败次数限制:
• 设置最大尝试次数
• 达到限制后降级处理
"""
# ================== ReAct 优化 ==================
REACT_OPTIMIZATION_TIPS = """
1. 工具设计原则:
• 功能单一,易于组合
• 输入输出格式统一
• 包含详细的使用说明
2. 减少不必要的工具调用:
• LLM 已知的事实不需要搜索
• 使用缓存避免重复查询
3. 处理工具失败:
• 实现重试机制
• 提供替代工具
• 允许 LLM 调整策略
4. 观察结果处理:
• 截断过长的结果
• 提取关键信息
• 格式化便于理解
"""
# ================== 综合优化策略 ==================
def create_optimized_config(task_type: str) -> dict:
"""
根据任务类型创建优化配置
"""
configs = {
"math": {
"primary": "self_consistency",
"samples": 5,
"temperature": 0.7,
"fallback": "few_shot_cot",
},
"code": {
"primary": "reflexion",
"max_trials": 3,
"use_tests": True,
"fallback": "self_refine",
},
"qa": {
"primary": "react",
"tools": ["search", "wikipedia"],
"max_steps": 5,
"fallback": "cot",
},
"creative": {
"primary": "tot",
"search": "dfs",
"num_thoughts": 3,
"fallback": "self_refine",
},
"general": {
"primary": "zero_shot_cot",
"fallback": "direct",
}
}
return configs.get(task_type, configs["general"])9.3 监控与调试
python
"""
推理过程监控与调试工具
"""
import time
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional
from datetime import datetime
import json
@dataclass
class ReasoningMetrics:
"""推理过程指标"""
task_id: str
strategy: str
start_time: float
end_time: float = 0
total_tokens: int = 0
api_calls: int = 0
steps: List[Dict[str, Any]] = field(default_factory=list)
success: bool = False
error: Optional[str] = None
@property
def duration(self) -> float:
return self.end_time - self.start_time if self.end_time else 0
@property
def tokens_per_second(self) -> float:
return self.total_tokens / self.duration if self.duration > 0 else 0
class ReasoningMonitor:
"""
推理过程监控器
功能:
1. 追踪推理过程
2. 收集性能指标
3. 生成分析报告
"""
def __init__(self):
self.sessions: Dict[str, ReasoningMetrics] = {}
self.history: List[ReasoningMetrics] = []
def start_session(self, task_id: str, strategy: str) -> str:
"""开始监控会话"""
session_id = f"{task_id}_{int(time.time())}"
self.sessions[session_id] = ReasoningMetrics(
task_id=task_id,
strategy=strategy,
start_time=time.time()
)
return session_id
def log_step(
self,
session_id: str,
step_type: str,
content: str,
tokens: int = 0,
metadata: Dict = None
):
"""记录推理步骤"""
if session_id in self.sessions:
self.sessions[session_id].steps.append({
"type": step_type,
"content": content[:500], # 截断
"tokens": tokens,
"timestamp": time.time(),
"metadata": metadata or {}
})
self.sessions[session_id].total_tokens += tokens
self.sessions[session_id].api_calls += 1
def end_session(self, session_id: str, success: bool, error: str = None):
"""结束监控会话"""
if session_id in self.sessions:
metrics = self.sessions[session_id]
metrics.end_time = time.time()
metrics.success = success
metrics.error = error
self.history.append(metrics)
del self.sessions[session_id]
def get_session_report(self, session_id: str) -> Dict:
"""获取会话报告"""
if session_id in self.sessions:
metrics = self.sessions[session_id]
else:
# 从历史中查找
metrics = next((m for m in self.history if m.task_id in session_id), None)
if not metrics:
return {"error": "会话未找到"}
return {
"task_id": metrics.task_id,
"strategy": metrics.strategy,
"duration": f"{metrics.duration:.2f}s",
"api_calls": metrics.api_calls,
"total_tokens": metrics.total_tokens,
"tokens_per_second": f"{metrics.tokens_per_second:.1f}",
"success": metrics.success,
"error": metrics.error,
"steps_count": len(metrics.steps),
}
def get_aggregate_stats(self) -> Dict:
"""获取聚合统计"""
if not self.history:
return {"message": "暂无历史数据"}
total = len(self.history)
success = sum(1 for m in self.history if m.success)
by_strategy = {}
for m in self.history:
if m.strategy not in by_strategy:
by_strategy[m.strategy] = {
"count": 0,
"success": 0,
"total_duration": 0,
"total_tokens": 0
}
by_strategy[m.strategy]["count"] += 1
by_strategy[m.strategy]["success"] += 1 if m.success else 0
by_strategy[m.strategy]["total_duration"] += m.duration
by_strategy[m.strategy]["total_tokens"] += m.total_tokens
# 计算每个策略的平均值
for strategy, stats in by_strategy.items():
count = stats["count"]
stats["success_rate"] = f"{stats['success']/count*100:.1f}%"
stats["avg_duration"] = f"{stats['total_duration']/count:.2f}s"
stats["avg_tokens"] = int(stats["total_tokens"] / count)
return {
"total_sessions": total,
"success_rate": f"{success/total*100:.1f}%",
"by_strategy": by_strategy
}
def export_logs(self, filepath: str):
"""导出日志"""
data = {
"export_time": datetime.now().isoformat(),
"sessions": [
{
"task_id": m.task_id,
"strategy": m.strategy,
"duration": m.duration,
"tokens": m.total_tokens,
"api_calls": m.api_calls,
"success": m.success,
"steps": m.steps
}
for m in self.history
]
}
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
# 使用示例
def demo_monitor():
"""监控演示"""
monitor = ReasoningMonitor()
# 模拟推理过程
session = monitor.start_session("task_001", "react")
monitor.log_step(session, "thought", "需要搜索相关信息", tokens=50)
monitor.log_step(session, "action", "Search[Python 教程]", tokens=30)
monitor.log_step(session, "observation", "找到相关结果...", tokens=200)
monitor.log_step(session, "thought", "获得了足够信息", tokens=40)
monitor.log_step(session, "action", "Finish[答案]", tokens=20)
monitor.end_session(session, success=True)
# 查看报告
print("会话报告:")
print(json.dumps(monitor.get_session_report(session), ensure_ascii=False, indent=2))
print("\n聚合统计:")
print(json.dumps(monitor.get_aggregate_stats(), ensure_ascii=False, indent=2))
if __name__ == "__main__":
demo_monitor()10. 📚 参考文献与资源
10.1 核心论文
| 论文 | 作者 | 年份 | 链接 |
|---|---|---|---|
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | Wei et al. | 2022 | arXiv:2201.11903 |
| Tree of Thoughts: Deliberate Problem Solving with Large Language Models | Yao et al. | 2023 | arXiv:2305.10601 |
| Self-Refine: Iterative Refinement with Self-Feedback | Madaan et al. | 2023 | arXiv:2303.17651 |
| Reflexion: Language Agents with Verbal Reinforcement Learning | Shinn et al. | 2023 | arXiv:2303.11366 |
| ReAct: Synergizing Reasoning and Acting in Language Models | Yao et al. | 2022 | arXiv:2210.03629 |
| Self-Consistency Improves Chain of Thought Reasoning in Language Models | Wang et al. | 2022 | arXiv:2203.11171 |
| Large Language Models are Zero-Shot Reasoners | Kojima et al. | 2022 | arXiv:2205.11916 |
10.2 GitHub 资源
┌─────────────────────────────────────────────────────────────────────────┐
│ 开源项目资源 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 🔗 Chain-of-Thought │
│ • https://github.com/google-research/chain-of-thought-hub │
│ • https://github.com/reasoning-machines/prompt-lib │
│ │
│ 🔗 Tree-of-Thought │
│ • https://github.com/princeton-nlp/tree-of-thought-llm │
│ • https://github.com/kyegomez/tree-of-thoughts │
│ │
│ 🔗 Self-Refine │
│ • https://github.com/madaan/self-refine │
│ │
│ 🔗 Reflexion │
│ • https://github.com/noahshinn024/reflexion │
│ │
│ 🔗 ReAct │
│ • https://github.com/ysymyth/ReAct │
│ • https://github.com/langchain-ai/langchain (集成实现) │
│ │
│ 🔗 综合框架 │
│ • https://github.com/langchain-ai/langchain │
│ • https://github.com/microsoft/autogen │
│ • https://github.com/microsoft/semantic-kernel │
│ • https://github.com/run-llama/llama_index │
│ │
└─────────────────────────────────────────────────────────────────────────┘10.3 推荐学习路径
┌─────────────────────────────────────────────────────────────────────────┐
│ 推荐学习路径 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 阶段1: 基础入门 (1-2周) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ □ 阅读 CoT 原论文 │
│ □ 实践 Zero-shot CoT │
│ □ 实践 Few-shot CoT │
│ □ 了解 Self-Consistency │
│ │
│ 阶段2: 进阶探索 (2-3周) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ □ 阅读 ToT 论文 │
│ □ 实现 ToT 的 BFS 和 DFS │
│ □ 阅读 ReAct 论文 │
│ □ 实现基础 ReAct Agent │
│ │
│ 阶段3: 深入实践 (3-4周) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ □ 阅读 Self-Refine 论文 │
│ □ 阅读 Reflexion 论文 │
│ □ 实现完整的 Reflexion 系统 │
│ □ 集成多种推理技术 │
│ │
│ 阶段4: 项目实战 (持续) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ □ 选择实际问题场景 │
│ □ 设计综合推理架构 │
│ □ 评估和优化性能 │
│ □ 部署生产环境 │
│ │
└─────────────────────────────────────────────────────────────────────────┘10.4 延伸阅读
- Prompt Engineering Guide: https://www.promptingguide.ai/
- LangChain 文档: https://python.langchain.com/docs/
- OpenAI Cookbook: https://github.com/openai/openai-cookbook
- Anthropic 提示工程指南: https://docs.anthropic.com/claude/docs/prompt-engineering
11. 💭 总结与展望
11.1 核心要点回顾
┌─────────────────────────────────────────────────────────────────────────┐
│ 本文核心要点 │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 1️⃣ Chain-of-Thought (CoT) │
│ • 让模型展示推理过程 │
│ • 简单有效,是其他技术的基础 │
│ • Zero-shot 和 Few-shot 两种模式 │
│ │
│ 2️⃣ Tree-of-Thought (ToT) │
│ • 从线性推理升级到树状探索 │
│ • 适合需要多方案比较的问题 │
│ • BFS 适合比较,DFS 适合快速找解 │
│ │
│ 3️⃣ Self-Refine │
│ • 迭代式自我改进 │
│ • 生成-反馈-精炼循环 │
│ • 无需额外训练或标注 │
│ │
│ 4️⃣ Reflexion │
│ • 语言形式的强化学习 │
│ • 从失败中学习并记忆 │
│ • 外部记忆替代参数更新 │
│ │
│ 5️⃣ ReAct │
│ • 推理与行动交替进行 │
│ • Thought-Action-Observation 循环 │
│ • 支持灵活的工具调用 │
│ │
└─────────────────────────────────────────────────────────────────────────┘11.2 技术发展趋势
💡 思考:推理技术会如何发展?
🤔 解答:
- 多模态推理:结合视觉、语音等多模态信息进行推理
- 更长的上下文:支持更复杂的多步推理任务
- 效率优化:减少 API 调用,降低延迟和成本
- 可靠性提升:减少幻觉,提高推理准确性
- 自主学习:从交互中持续学习和改进
- 协作推理:多个 Agent 协同推理
11.3 实践建议
📌 给读者的建议
- 从简单开始:先掌握 CoT,再学习其他技术
- 理解原理:不仅要会用,更要理解为什么有效
- 动手实践:阅读代码,修改代码,运行代码
- 关注论文:保持对最新研究的关注
- 结合业务:将技术应用到实际问题中
🎉 恭喜你完成了本文的学习!
如果你觉得这篇文章对你有帮助,欢迎:
- 👍 点赞
- ⭐ 收藏
- 💬 评论交流
- 📤 分享给朋友
有任何问题或建议,欢迎在评论区留言讨论!
🏷️ 系列文章:本文是 Agents 系列的第四篇,更多精彩内容敬请期待!