文章目录
- [1. 关于HTTP协议](#1. 关于HTTP协议)
-
- [1.1 基本特点](#1.1 基本特点)
- [1.2 HTTP 请求与响应结构](#1.2 HTTP 请求与响应结构)
-
- [1. HTTP 请求(Request)](#1. HTTP 请求(Request))
- [2. HTTP 响应(Response)](#2. HTTP 响应(Response))
- [1.3 常见 HTTP 方法](#1.3 常见 HTTP 方法)
- [1.4 常见状态码(Status Codes)](#1.4 常见状态码(Status Codes))
- [1.5 HTTP 版本演进](#1.5 HTTP 版本演进)
- [2. 关于url](#2. 关于url)
-
- [2.1 协议(Scheme)](#2.1 协议(Scheme))
- [2.2 域名+端口(Authority)](#2.2 域名+端口(Authority))
- [2.3 路径(Path)](#2.3 路径(Path))
- [2.4 查询参数(Query)](#2.4 查询参数(Query))
- [2.5 锚点(Fragment)](#2.5 锚点(Fragment))
- [2.6 tips](#2.6 tips)
- [2.7 访问一个网站的流程](#2.7 访问一个网站的流程)
- [3. HTTP协议demo](#3. HTTP协议demo)
-
- [3.1 源码](#3.1 源码)
- [3.2 对齐一些颗粒度](#3.2 对齐一些颗粒度)
-
- [3.2.1 HTTP请求](#3.2.1 HTTP请求)
- [3.2.2 HTTP应答](#3.2.2 HTTP应答)
- [3.3 源码解析](#3.3 源码解析)
- [3.4 实验结果](#3.4 实验结果)
- [4. 关于浏览器的请求逻辑](#4. 关于浏览器的请求逻辑)
1. 关于HTTP协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是用于在万维网(World Wide Web)上传输超文本(如 HTML 页面)的应用层协议。它是 Web 浏览器与 Web 服务器之间通信的基础,也是互联网上使用最广泛的协议之一。
所谓超文本,是指不只能传输文本,还可以传输图片,音频...
1.1 基本特点
-
无状态(Stateless)
HTTP 协议本身不保存任何关于客户端请求之间的状态信息。每次请求都是独立的。如果需要维持状态(如用户登录),通常借助 Cookie 、Session 等机制实现。
-
基于请求-响应模型
(B-S)客户端(通常是浏览器)发送一个请求(Request)到服务器,服务器处理后返回一个响应(Response)。
-
明文传输(默认)
标准 HTTP 使用明文传输数据,容易被窃听或篡改。为解决安全问题,通常使用 HTTPS(HTTP over TLS/SSL)进行加密通信。
-
支持多种媒体类型
通过 MIME 类型(如
text/html、application/json、image/png等),HTTP 可以传输各种格式的数据。 -
可扩展性
支持自定义头部字段(Headers)、状态码和方法,便于扩展功能。
1.2 HTTP 请求与响应结构
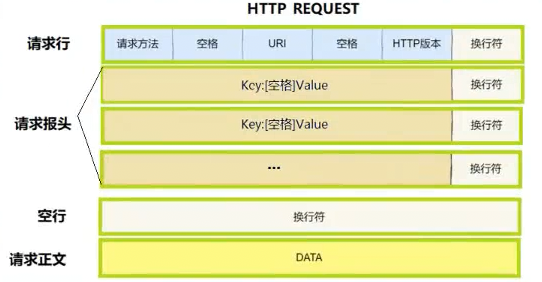
1. HTTP 请求(Request)
由以下部分组成:
- 请求行 :包含方法(如 GET、POST)、请求 URI 和 HTTP 版本
示例:GET /index.html HTTP/1.1 - 请求头(Headers) :传递元数据,如
User-Agent、Accept、Content-Type等 - 空行:分隔头部与正文
- 请求体(Body)(可选):如 POST 提交的表单数据或 JSON 内容
2. HTTP 响应(Response)
包括:
- 状态行 :HTTP 版本、状态码、状态描述
示例:HTTP/1.1 200 OK - 响应头(Headers) :如
Content-Type、Set-Cookie、Server等 - 空行
- 响应体(Body):实际返回的内容,如 HTML 页面、JSON 数据等

1.3 常见 HTTP 方法
| 方法 | 用途说明 |
|---|---|
| GET | 获取资源(不应有副作用) |
| POST | 提交数据(如表单、文件上传) |
| PUT | 更新或创建指定资源(幂等) |
| DELETE | 删除资源 |
| HEAD | 类似 GET,但只返回头部,不返回 body |
| OPTIONS | 查询服务器支持的 HTTP 方法 |
| PATCH | 对资源进行局部更新 |
1.4 常见状态码(Status Codes)
| 类别 | 含义 | 常见示例 |
|---|---|---|
| 1xx | 信息响应 | 100 Continue |
| 2xx | 成功 | 200 OK, 201 Created |
| 3xx | 重定向 | 301 Moved Permanently, 302 Found, 304 Not Modified |
| 4xx | 客户端错误 | 400 Bad Request, 403 Forbidden, 404 Not Found |
| 5xx | 服务器错误 | 500 Internal Server Error, 502 Bad Gateway, 503 Service Unavailable |
1.5 HTTP 版本演进
- HTTP/0.9(1991):仅支持 GET,无头部,纯文本。
- HTTP/1.0(1996):引入头部、状态码、多种方法,但每个请求需新建连接。
- HTTP/1.1(1997,RFC 2616):支持持久连接(Keep-Alive)、管道化、Host 头(支持虚拟主机),成为长期主流。
- HTTP/2(2015,RFC 7540):二进制帧、多路复用、头部压缩、服务器推送,提升性能。
- HTTP/3(2022,RFC 9114):基于 QUIC(UDP)替代 TCP,进一步降低延迟,提高可靠性。
2. 关于url
一个标准URL(统一资源定位符)的核心构成遵循RFC 3986 规范,整体按协议://域名/路径?查询参数#锚点 的层级排列,各部分各司其职,部分可选,核心结构拆解如下:
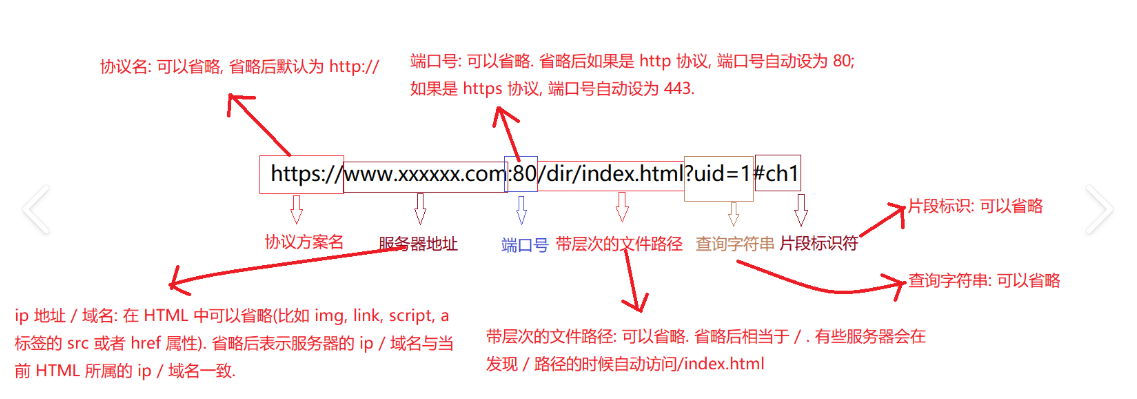
以https://www.baidu.com:443/s?wd=url构成&rsv_spt=1#top为例:
对应拆解:协议 +域名+端口 +路径 +查询参数 +锚点
2.1 协议(Scheme)
- 定义浏览器与服务器的通信规则 ,末尾必须跟
:// - 常用:
http(80端口,明文)、https(443端口,TLS加密,主流)、ftp(文件传输)、file(本地文件) - 浏览器可省略输入,会自动补全(如输
baidu.com,默认补https://)
2.2 域名+端口(Authority)
- 域名 :服务器的网络标识(替代IP,如
www.baidu.com),可包含主域名/子域名 - 端口 :
:后跟数字,标识服务器上的具体服务进程- 协议默认端口可省略:http→80、https→443、ftp→21
- 非默认端口必须写(如
localhost:8080,本地服务常用8080/8090)
- 特殊:可直接用IP替代域名(如
https://110.242.68.3:443,就是百度的IP)
2.3 路径(Path)
/开头,标识服务器上的具体资源位置(类似本地文件路径)- 示例:
/s是百度搜索的资源路径,无路径时默认访问服务器根资源 (如baidu.com→baidu.com/)
2.4 查询参数(Query)
?开头,用于向服务器传递键值对参数,是前后端交互的核心方式- 格式:
键1=值1&键2=值2,&分隔多个参数,值支持URL编码(处理空格/特殊字符,如空格→%20或+) - 示例:
wd=url构成表示搜索关键词为"url构成",服务器根据参数返回对应结果
2.5 锚点(Fragment)
#开头,标识页面内的具体位置 (如锚点#top→跳转到页面顶部)- ✅ 关键特性:仅浏览器解析,不会发送到服务器(服务器接收到的请求中不包含锚点)
- 常用:长页面的章节跳转、前端路由(SPA单页应用核心)
2.6 tips
- URL编码:特殊字符(空格、&、#、中文等)必须转码 ,否则会解析错误(如"URL构成"→
URL%E6%9E%84%E6%88%90) - 无查询参数时,
?不能写;无锚点时,#不能写 - 子域名与路径的区别:
blog.baidu.com(子域名,不同服务)≠baidu.com/blog(主域名下的路径,同一服务)
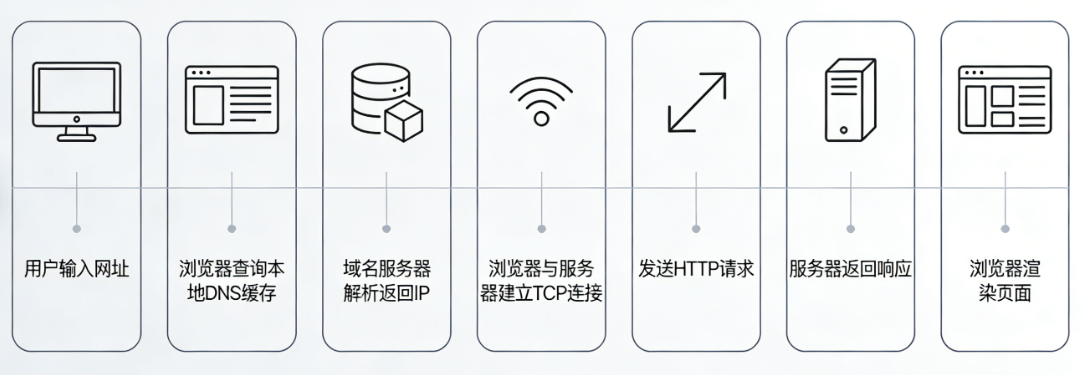
2.7 访问一个网站的流程
- 用户向浏览器输入网址(域名),
- 浏览器将域名交给域名服务器(是一种基础建设,作用是:将域名转换成IP,该过程成为DNS),
- 域名服务器将IP交给浏览器,
- 浏览器与服务器建立连接,
- 浏览器向服务器发送请求,
- 服务器处理请求返回给浏览器,
- 浏览器渲染相应。
3. HTTP协议demo
本部分我们通过模拟实现一个使用HTTP协议的服务器demo来理解HTTP协议。
3.1 源码
3.2 对齐一些颗粒度
3.2.1 HTTP请求
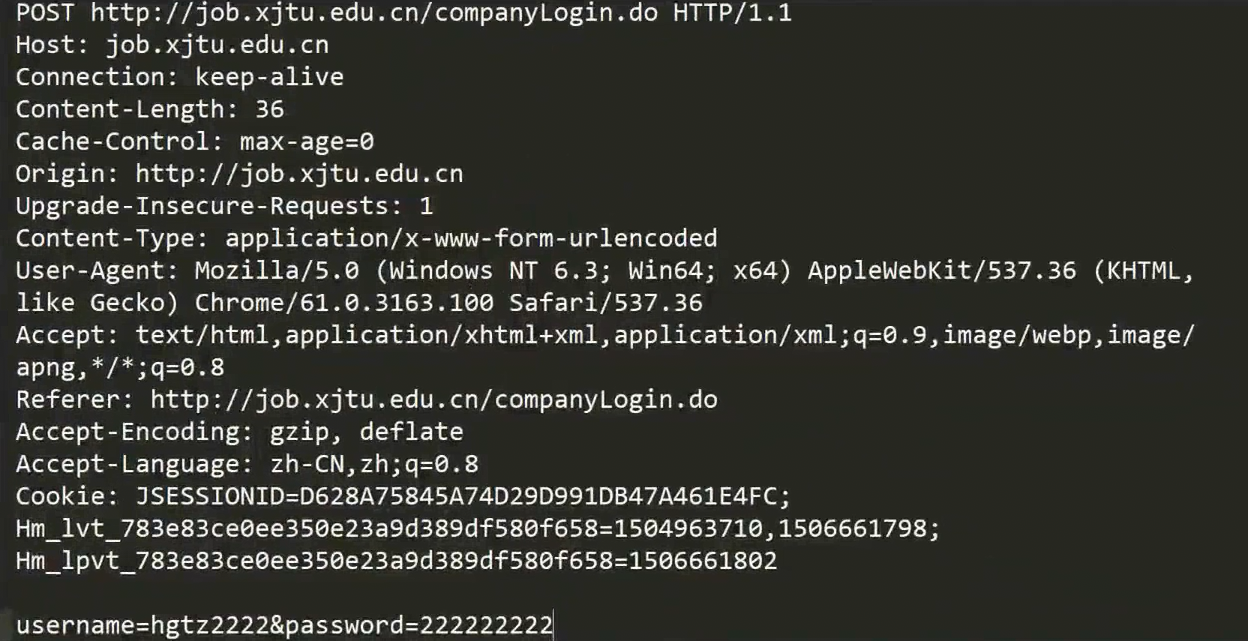
HTTP协议请求的基本字段包括以下三部分:
- ⾸⾏: 方法 + url + 版本
- 请求报头Header: 请求的属性, 冒号分割的键值对;每组属性之间使用 \r\n 分隔;遇到空行表示 Header部分结束
- 请求正文Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有⼀个Content-Length属性来标识Body的长度;
关于HTTP为什么会存在版本字段?
因为client和server是两款软件,一款软件会存在很多版本,用户使用不同的版本是很正常的。所以当用户申请服务器对应服务时,应该指明使用软件的版本号,然后有对应版本的服务器提供服务。
3.2.2 HTTP应答
Q:请求是怎么表示自己想要请求什么资源的?
A :通过web根目录 + 路径的方式。
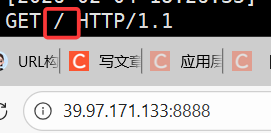
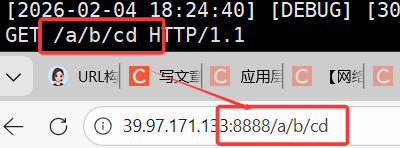
所有的资源都放在web根目录下,如果只写一个/服务器会自动拼接首页(index.html)
网页内容必须是服务器特定路径下的文件。
http请求的本质是:请求代码中./wwwroot目录下特定路径下的资源,而uri中的路径,就是我们要找的资源。
Q:client 和 server是如何保证自己读到的报文是完整的?
A:
- 读取字节流,分析读到的字节流,确认是否存在空行。
- 提取报头中的Content-Length,获取正文长度,然后再读取或截取指定长度的内容。
关于响应体数据的媒体类型Content-Type:
Content-Type 属于HTTP标准响应头,格式为 MIME类型(多用途互联网邮件扩展类型),用于描述响应体数据的媒体类型。
Q:为什么必须设置这个响应头?
A:如果不设置,浏览器无法自动识别数据格式
服务器传输给浏览器的都是二进制字节流,本身不携带格式信息:
- 一段字节流可能是HTML网页、JPG图片、PNG图标、纯文本,也可能是CSS/JS脚本;
- 如果不声明
Content-Type,浏览器无法判断数据类型,会出现解析错误、渲染异常、直接下载文件等问题。
举个对比示例:
| 数据内容 | 正确的Content-Type | 不设置/设置错误的后果 |
|---|---|---|
| HTML页面 | text/html |
浏览器可能将网页以纯文本展示,不渲染标签 |
| JPG图片 | image/jpeg |
图片无法正常显示,甚至触发文件下载 |
| PNG图片 | image/png |
渲染异常、显示破碎图片 |
常见 Content-Type 完整清单
- 网页与文本类型(最常用,服务HTML/文本资源)
| 文件后缀 | Content-Type 值 | 适用场景 |
|---|---|---|
| .html / .htm | text/html; charset=utf-8 |
网页文件,你的服务器核心类型,推荐指定字符集避免乱码 |
| .txt | text/plain; charset=utf-8 |
纯文本文件 |
| .css | text/css; charset=utf-8 |
层叠样式表,渲染网页样式 |
| .js | application/javascript |
JavaScript脚本文件 |
| .json | application/json |
接口数据交互,前后端通信标准格式 |
- 、图片类型(适配浏览器图片资源请求)
| 文件后缀 | Content-Type 值 | 适用场景 |
|---|---|---|
| .jpg / .jpeg | image/jpeg |
常用位图图片 |
| .png | image/png |
透明背景图片,网页图标常用 |
| .gif | image/gif |
动图/静态图 |
| .ico | image/x-icon |
网站标签页图标(favicon.ico) |
| .svg | image/svg+xml |
矢量图,适配响应式网页 |
- 二进制与通用文件类型
| 场景 | Content-Type 值 | 说明 |
|---|---|---|
| 未知二进制文件 | application/octet-stream |
通用兜底类型,浏览器默认触发下载 |
| 字体文件 | font/ttf / font/woff2 |
网页自定义字体资源 |
3.3 源码解析

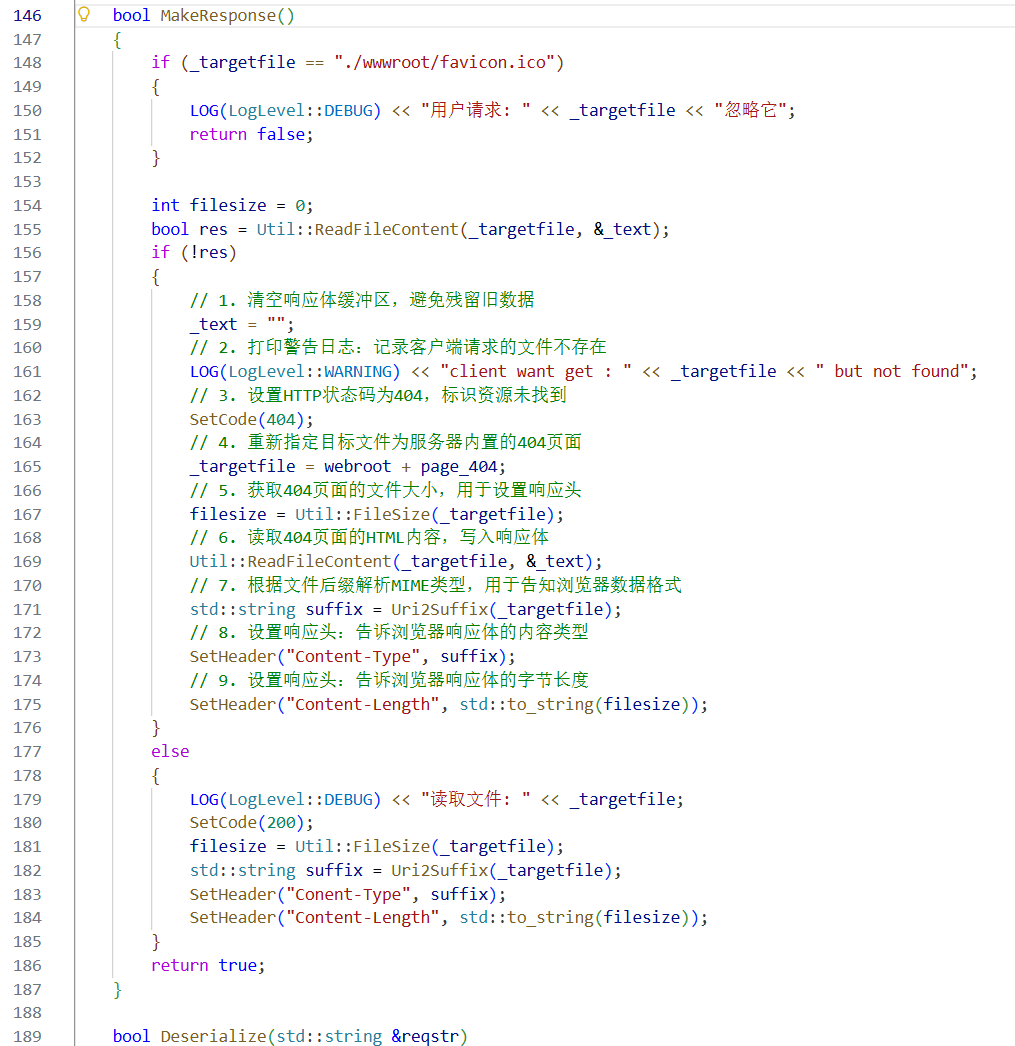
main函数看起,创建HTTP对象,调用Start方法。
关于Start方法:
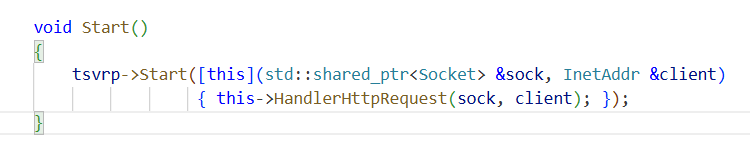
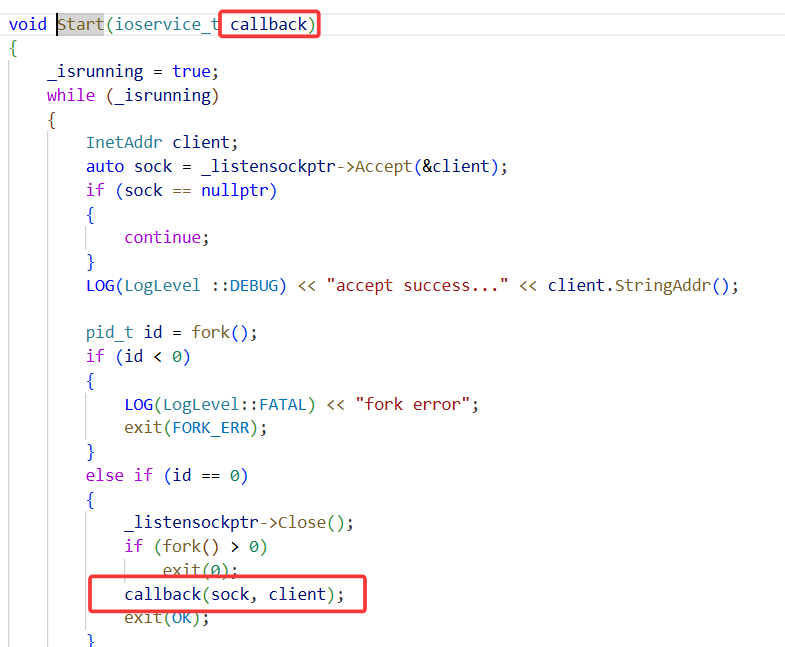
实际上是创建了一个服务器,传入了回调方法,当服务器收到请求再调用回调函数HandlerHttpRequest
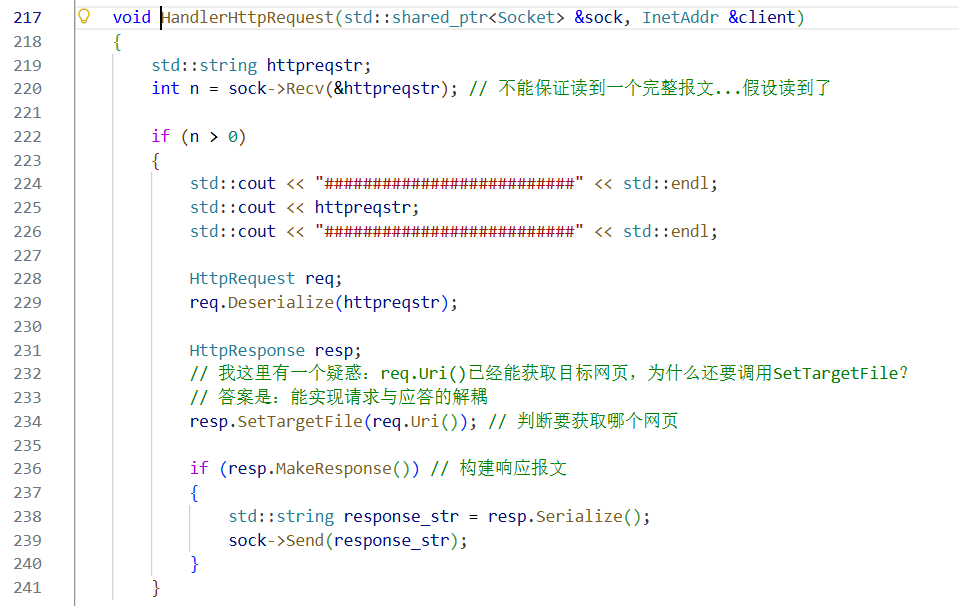
表明了:从哪个套接字读?处理完数据之后发送到哪?
这里代码写的有瑕疵,就先假设能读到一个完整的报文。
输出收到的报文信息。
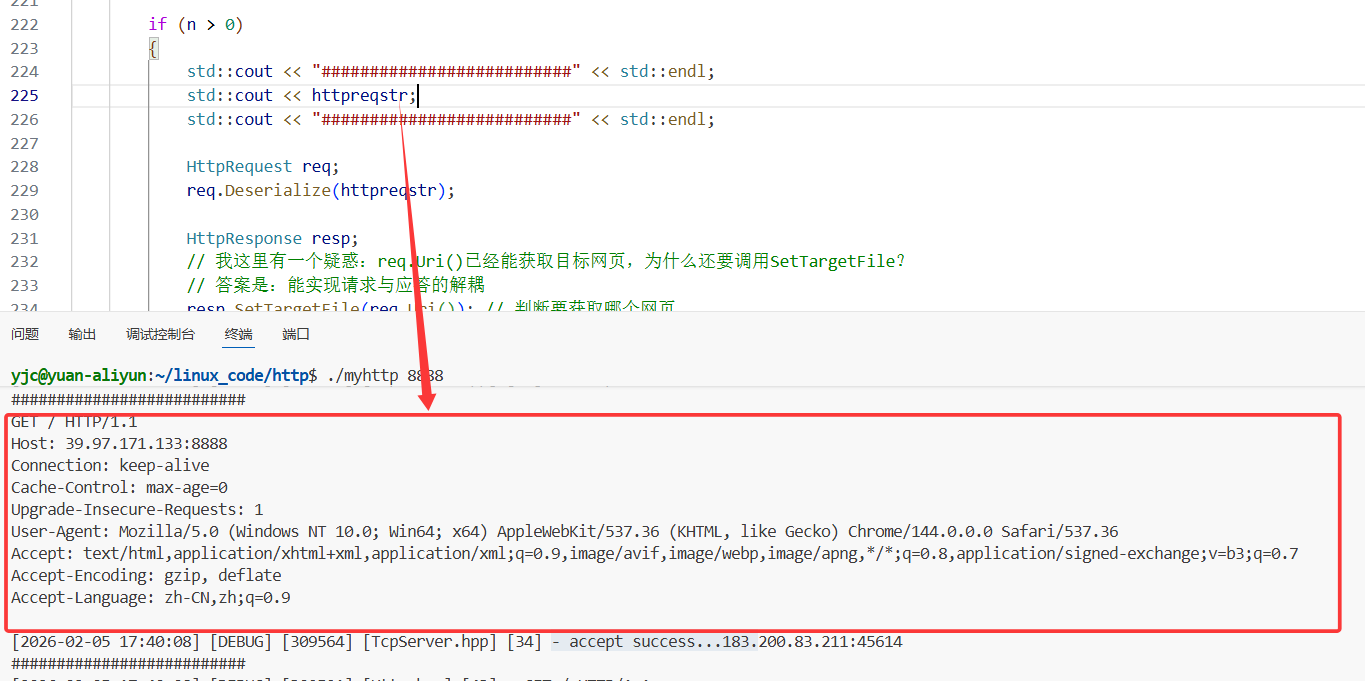
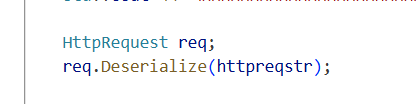
处理请求报文
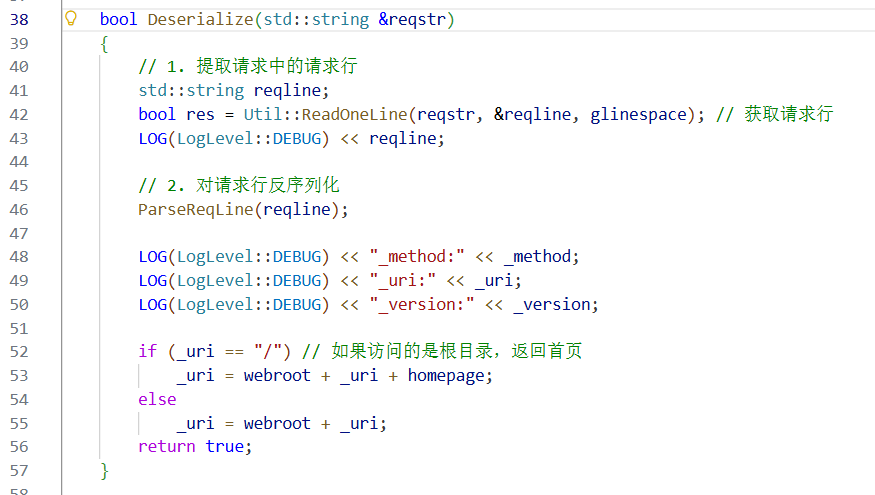
请求报文的反序列化。

判断要获取的网页,制作响应报文,发送。
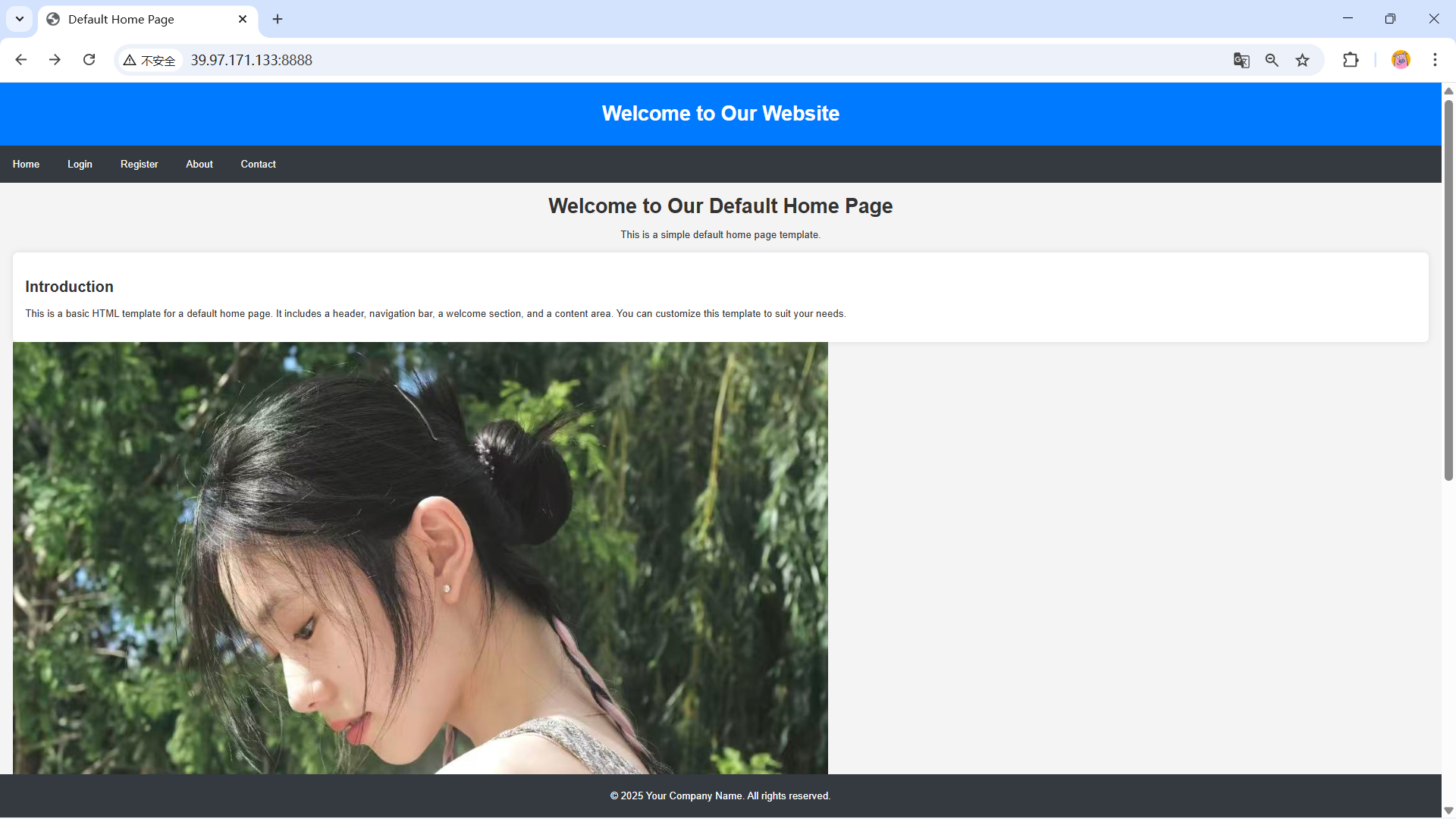
3.4 实验结果
4. 关于浏览器的请求逻辑
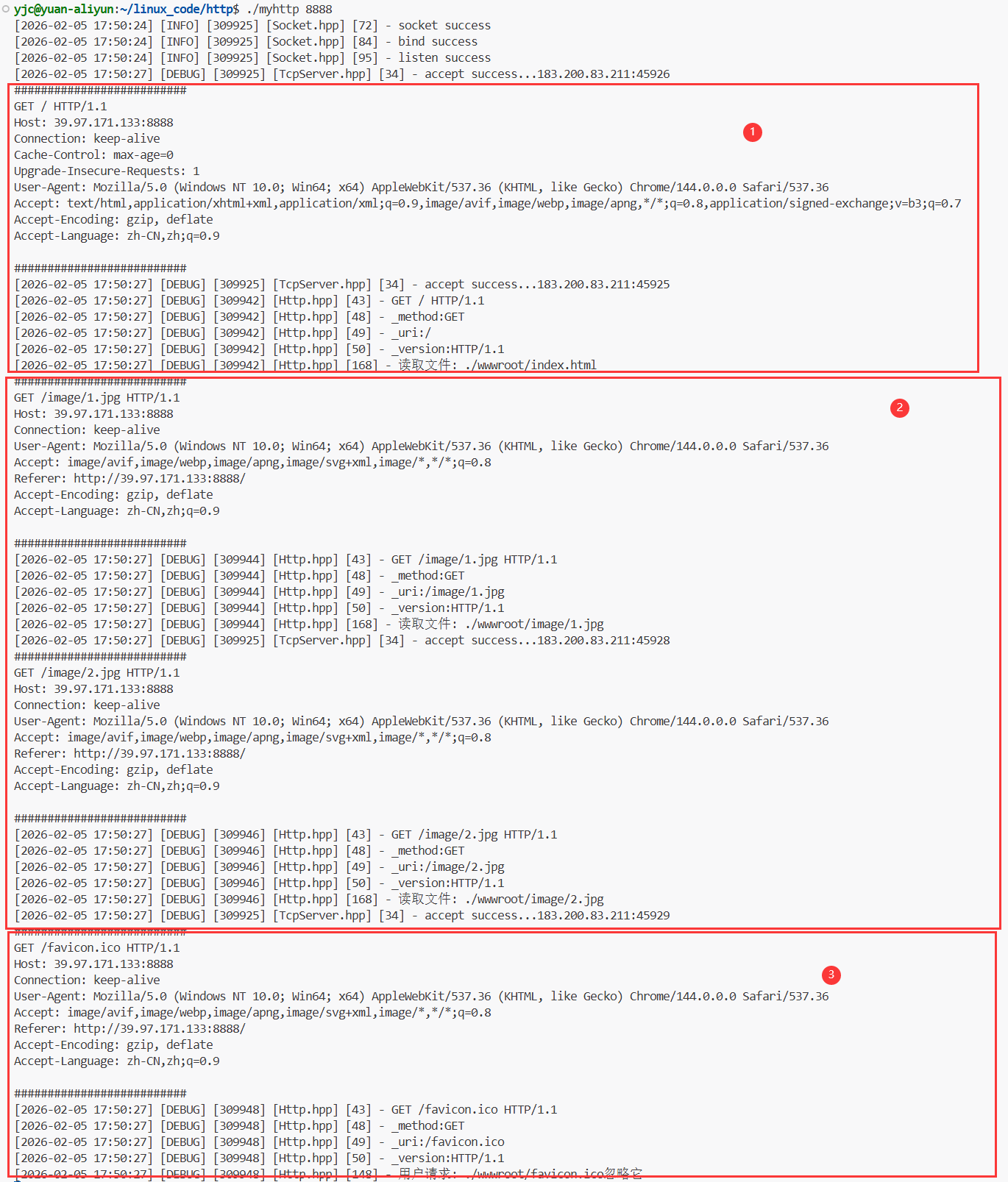
当你在浏览器输入服务器地址(如http://localhost:8080)时,浏览器会按固定顺序+并行加载 发起多次网络请求,完整链路如下:
1. 主页面请求(第一次核心请求)
- 请求目标 :服务器根路径
/,对应你代码中拼接的./wwwroot/index.html首页文件; - 行为:浏览器发起HTTP GET请求,等待服务器返回HTML页面内容;
- 服务器处理 :你的代码解析请求行、读取
index.html、构建200响应,将HTML文本返回给浏览器。
2. 解析HTML + 并行请求静态资源(二次/多次请求)
浏览器接收到HTML页面后,会逐行解析DOM树 ,遇到外部资源标签时,会立即发起新的HTTP请求(支持多线程并行发送,提升加载速度),常见资源包括:
html
<!-- 图片资源:浏览器会单独发起GET请求 -->
<img src="/logo.jpg">
<img src="/avatar.png">
<!-- 样式表、脚本也会触发独立请求 -->
<link rel="stylesheet" href="/style.css">
<script src="/app.js"></script>- 特点 :每个资源都是独立的HTTP请求/响应,和主页面请求完全分离;
- 服务器处理:你的代码会为每个资源重复执行「解析请求行→读取文件→构建响应」流程,返回对应文件内容。
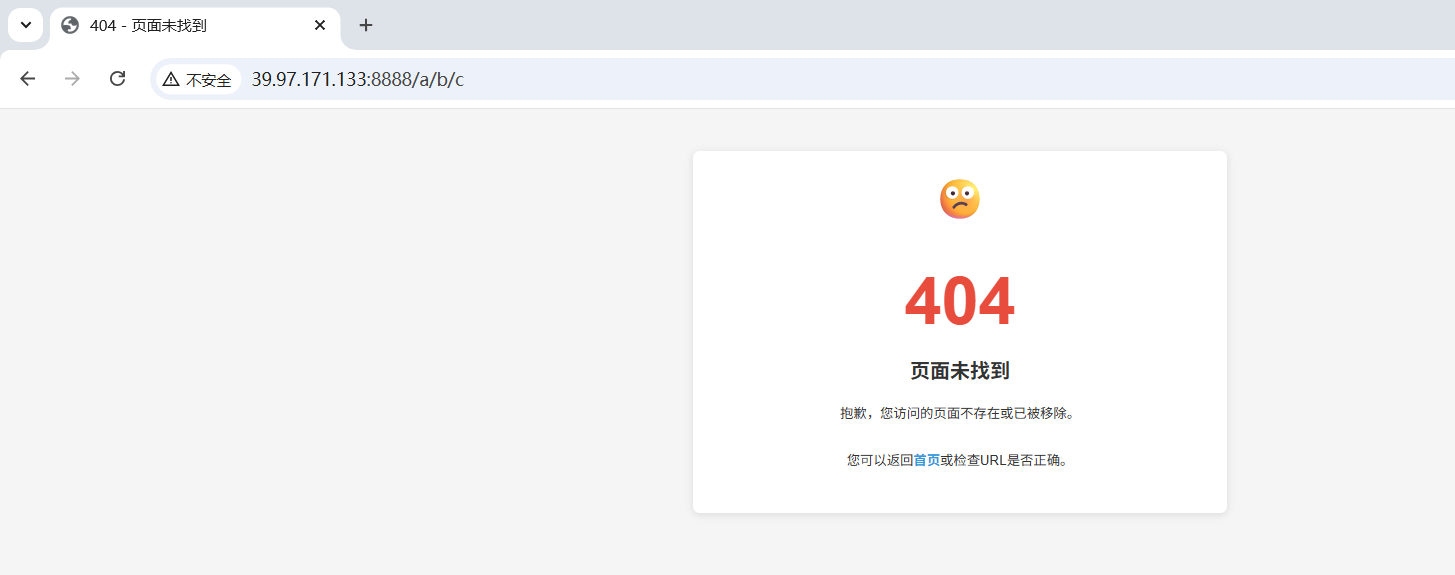
3. 自动请求favicon.ico(浏览器默认行为)
- 触发时机 :几乎所有现代浏览器 在请求任意网页时,都会自动附加这个请求,无需HTML标签触发;
- 作用 :
favicon.ico是网站图标,会显示在浏览器标签页、书签栏上,是浏览器的标准化默认请求; - 请求路径 :
/favicon.ico,拼接后为./wwwroot/favicon.ico。
总结
- 浏览器的多层请求逻辑:主页面请求 → 解析HTML并行加载静态资源 → 自动请求favicon.ico,所有请求相互独立;
- 代码通过忽略favicon.ico规避了无效请求,符合简易HTTP服务器的设计思路;
- 静态资源(图片/CSS/JS)会触发独立HTTP请求,需要服务器完整支持文件读取和MIME类型配置;
完