1.引言
我们先梳理一下,当我们要申请x byte内存时,会先在thread cache中进行申请,如果申请到了就返回,申请不到就去central cache中申请,在central cache中,不会说你要x byte就给你x byte,它会通过慢启动以及一系列方法多给你开辟一些回去,剩下的就存到central cache中,那问题来了,如果central cache中也没有内存了咋办呢?此时就要向page cache申请,那么我们先来了解一下page cache的结构~
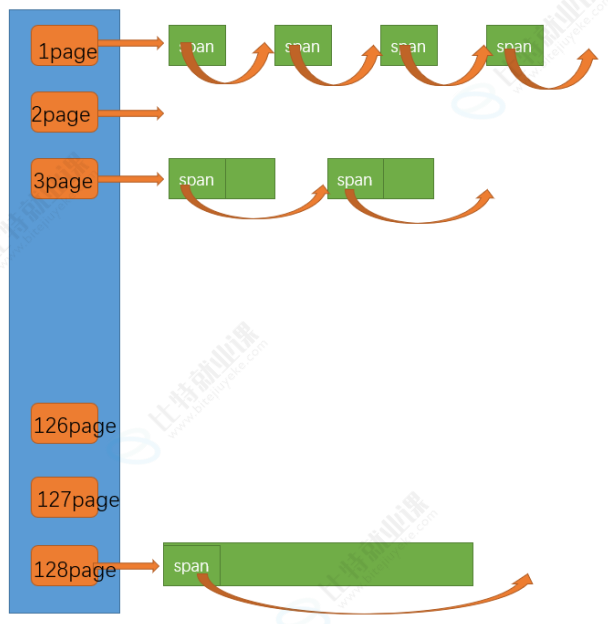
如下图所示,page cache也是哈希桶的映射结构,每个page上面会挂载着spanlist,但是要值得注意的是,当page cache从堆区申请回来一大块内存时,不是直接切好的,一下图为例,申请完的内存128page的span就挂在128那个桶里,假如我现在要2page的内存,就在这个128page的内存上切割,切成2page和126page,前者就被分配走了,让central cache拿走了,后者就挂在126page那个桶上了~
前文还说到,当usecount==0时,代表这个span已经空了,此时就会从central cache归还到span cache,那倘若现在又两个1page的内存块回来了,那page cache就会将这两个整合到一起,挂在2page那里,以此类推,如果central cache的所有的usecount都为0的话,那此时我的page cache是不是就算一块128page的大内存呀?当然前提是以这个图为例
所以我们在设计Page cache时,第一不要使用桶锁,因为这样这些Page会连续不断地开锁解锁,很降低性能,可以使用一个大锁!
其次就是还要用单例模式,原因同central cache,不多说了,类比参考一下。
这里补充说明申请和释放的流程,其实上面已经渗透的差不多了,看一下就好

2.内存分配
那这个page cache是给central cache分配几页内存呢?按心情分吗?显然不是,这里有这样两个函数,来看一下:有点像是极限法一样
static size_t NumMoveSize(size_t size)// 一次thread cache从中心缓存获取多少个
{
assert(size > 0);
// [2, 512],一次批量移动多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 大对象一次批量上限低
int num = MAX_BYTES / size; //计算:256KB能容纳多少个该size的对象
if (num < 2)
num = 2; //分太少了一次不值得,下次还得申请,不如这次多给点
if (num > 512)
num = 512; //分太多了也用不完,该浪费了
return num;
}
// 计算一次向系统获取几个页
// 单个对象 8byte
// ...
// 单个对象 256KB
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size); //计算一次移动多少个对象
size_t npage = num * size; //计算这些对象总共需要多少字节
npage >>= PAGE_SHIFT; //转换成多少页数,按一页8KB=2^13来算
if (npage == 0)
npage = 1;
return npage;
}NumMovePage(size) 计算的是:当 Thread Cache 向 Central Cache 申请对象,而 Central Cache 又需要向 Page Cache 申请内存时,应该一次性申请多少页。
NumMoveSize 函数是 TCMalloc 中非常关键的批量策略算法,决定了每次从 Central Cache 移动多少个对象到 Thread Cache。
也许有人会好奇那我一次从page cache上面拿走了npage个页,那有可能用不了这些啊?那剩下的就会挂在central cache上对应的桶那里。
举个例子,我现在要申请8字节的内存,thread cache没有,申请到central cache,经过计算我要一次性带走512个,总共是512*8=4KB 的内存,那我带着这个数据就去找page cache,但是一页是8KB啊,但是我也只能拿走一页内存,不能从page cache中拿半页走,自己带4KB回到thread cache,剩下的4KB会留在Central Cache,挂在4KB那个桶里面,谁要谁来分!
3.单例模式
随后我们的page cache也要设计成单例模式,代码如下:
#pragma once
#include"Common.h"
//单例模式
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
Span* NewSpan(size_t k);
std::mutex _pageMX;
private:
SpanList _spanList[NPAGES];
PageCache()
{}
PageCache(const PageCache&) = delete;
static PageCache _sInst;
};4.内存切割
当我们向取K页内存时,可以这样做:
先尝试现成的 ,没有就切分大的 ,再没有就批发128页 ,然后假装这128页本来就在那,重新走流程。具体代码有详解:
#include"PageCache.h"
PageCache PageCache::_sInst;
//获取一个K页的span
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 && k < NPAGES);
// 先检查第k个桶里面有没有span
if (!_spanList[k].Empty())
{
return _spanList->PopFront();
}
//到这里就说明为空了
// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanList[i].Empty())
{
//切下来一块
Span* nspan = _spanList[i].PopFront();
Span* kspan = new Span;
// 在nSpan的头部切一个k页下来
// k页span返回
// nSpan再挂到对应映射的位置
//下面不太好理解,举个租房子的例子,Span 就是"租赁合同",_pageId = 从哪间房开始租,起始位置
// _n = 连续租了几间房,
kspan->_pageId = nspan->_pageId; //从头开始拿
kspan->_n= k; //拿k间
nspan->_pageId += k; //剩下的房间开始位置
nspan->_n -= k; //剩下连续房间的数量
_spanList[nspan->_n].PushFront(nspan);
return kspan;
}
}
// 走到这个位置就说明后面没有大页的span了
// 这时就去找堆要一个128页的span
Span* bigspan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
bigspan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigspan->_n = NPAGES - 1;
_spanList[bigspan->_n].PushFront(bigspan);
return NewSpan(k);
}5.central cache获取span
先查缓存,无则解锁申请,无锁切割,加锁挂链,用最少的锁实现高并发内存分配。
// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// 查看当前的spanlist中是否有还有未分配对象的span
//遍历链表
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freelist != nullptr)
{
return it;
}
else
{
it = it->_next;
}
}
//走到这说明没有未分配对象的span
// 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞
list._mtx.unlock();
//只能管page cache要了
PageCache::GetInstance()->_pageMX.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
PageCache::GetInstance()->_pageMX.unlock();
//现在申请完了是一块大块的内存,下面进行切割,不需要加锁,因为这会其他线程访问不到这个span
// 计算span的大块内存的起始地址和大块内存的大小(字节数)
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
// 把大块内存切成自由链表链接起来
// 1、先切一块下来去做头,方便尾插
span->_freelist = start;
start += size;
void* tail = span->_freelist;
int i = 0;
while (start < end)
{
i++;
NextObj(tail) = start;
tail =NextObj(tail);
start += size;
}
// 切好span以后,需要把span挂到桶里面去的时候,再加锁
list._mtx.lock();
list.PushFront(span);
return span;
}6.单元测试
void TestConcurrentAlloc1()
{
void* p1 = ConcurrentAlloc(6);
void* p2 = ConcurrentAlloc(8);
void* p3 = ConcurrentAlloc(1);
void* p4 = ConcurrentAlloc(7);
void* p5 = ConcurrentAlloc(8);
cout << p1 << endl;
cout << p2 << endl;
cout << p3 << endl;
cout << p4 << endl;
cout << p5 << endl;
}
int main()
{
TestConcurrentAlloc1();
return 0;
}结果:
