⚡ 第四幕:读写与近实时搜索
"ES 默认写入后 1 秒才可搜(refresh_interval=1s),这不是 bug,是吞吐与延迟的权衡:
-
刷新越频繁,Segment 越多,查询越慢;
-
刷新越稀疏,数据犹抱琵琶半遮面,来得越晚。
-
若你强行
refresh=true,每写一条刷一次,集群会像被踩了尾巴的猫,瞬间炸毛(CPU 飙升,IO 爆满:岂不是一秒一万个luceneSegment,考虑过磁盘的感受吗!又不是money)// 创建索引,设刷新间隔为 30 秒(适合日志写入)
PUT /logs_slow_refresh
{
"settings": {
"refresh_interval": "30s",
"number_of_shards": 3
}
}
日志场景直接调成 30 秒,吞吐翻倍,CPU 笑醒; 但如果你非得 ?refresh=true 强行秒可见
POST /chat/_doc?refresh=true { "msg": "在吗?" }| 方式 | 平均写入耗时 | CPU 使用率 | Segment 数量 |
|---|---|---|---|
默认 (refresh_interval=1s) |
0.8 ms/条 | 35% | 1 |
强制 (?refresh=true) |
12.5 ms/条 | 92% | 1000 |
那相当于让快递员送一条消息就回仓打卡一次 ------活没多干,IO 先爆了!好在 有 Translog 默默在后台记账兜底:哪怕机器突然断电,重启后也能从日志里捞回未持久化的数据。所以它敢"憋着不刷",因为手里有账,心里不慌。
✅ 结合实际,咱们生产建议:
- 用户行为实时分析 :
refresh_interval: 5s
| 场景 | 推荐配置 | 理由 |
|---|---|---|
| 高吞吐写入(日志) | refresh_interval: 30s |
减少 Segment 爆炸 |
| 低延迟可见(活动抢购金币) | 写入后 ?refresh=wait_for |
仅刷必要分片 |
| 避免 Translog 丢失 | index.translog.durability: request(默认) |
每次写入 fsync |
| 极致吞吐(可容忍少量丢失) | index.translog.durability: async |
异步刷盘 |
"至于强一致?ES 默认只要 1 个副本 ACK 就返回成功(wait_for_active_shards=1)。
- 想要
all副本确认?可以,但是你要容忍**写入吞吐直接腰斩,**这能忍?"士可杀不可忍"------ES 的哲学:宁可短暂不一致,也不牺牲高可用。"
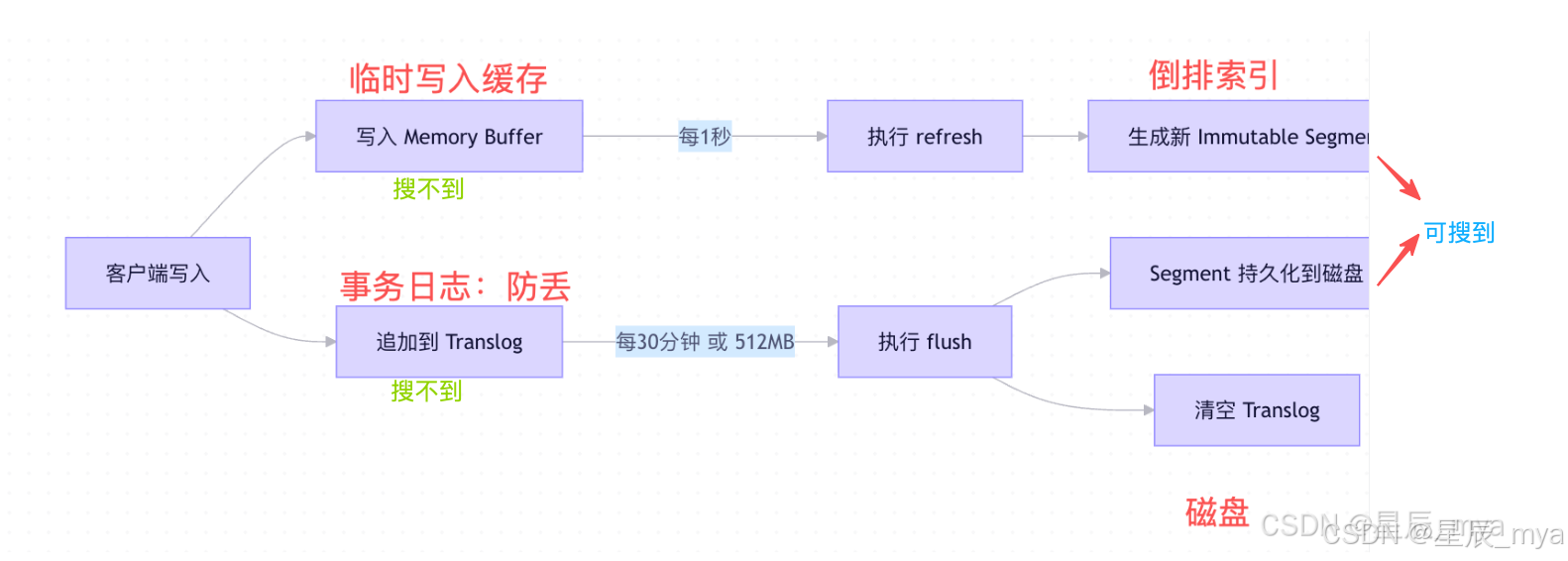
🔁 写入流程(带容错):
- 协调节点(Coordinating Node) 接收请求
- 根据
_id或routing计算 目标 Primary Shard - 转发请求到 Primary Shard 所在节点
- Primary Shard :
- 写入 Memory Buffer + Translog
- 执行
refresh(可选) - 并发转发请求到 所有 Replica Shards
- Replica Shards :
- 同样写入 Buffer + Translog
- 返回 ACK
- Primary 收到 quorum 副本 ACK (默认
wait_for_active_shards=1) - Primary 返回成功给协调节点
- 协调节点返回客户端
- 后台异步 flush(Translog → 持久化 Segment)
- 每 30 分钟 或 Translog 满,触发 flush → 写入磁盘 + 清空 Translog
⚠️ 一致性保证:
- 默认 最终一致(写入后可能短暂不可见)
- 可通过
?consistency=quorum+wait_for_active_shards=all强一致(但性能差)
💡 所以:
- 默认 1 秒延迟 可见(可通过
?refresh=true强制立即可见,但别滥用!)- 即使宕机,也能从 Translog 恢复未持久化数据
查询流程:
- 协调节点广播查询到 所有相关 Shard
- 每个 Shard 本地执行查询(Lucene 层)
- 返回 Top-K 文档 ID + Score(非完整文档!)
- 协调节点 merge + re-rank(全局排序)
- 再去各 Shard fetch 完整文档 (如果需要
_source)
💡 这就是为什么
size越大越慢:
- 第一阶段:每个 Shard 返回
size条- 第二阶段:协调节点要 merge
(shard_count * size)条再取 topsize
🚫 深分页(from=100000)为何被禁止?
- 协调节点需持有 100000 + size 条结果
- 内存爆炸!官方限制
index.max_result_window = 10000
✅ 替代方案:
- Search After(基于上一页最后一条的 sort 值)
- Scroll API(用于导出,非实时)
- Point in Time (PIT)(7.x+,快照式分页)
🧩 第五幕:聚合分析
咱们上面提到的倒排索引:"text 字段会被分词(如 '红烧肉' → '红烧', '肉'),而聚合需要的是完整值 (如 '红烧肉食谱' vs '红烧肉新闻')。所以 ES 为 keyword 类型构建 Doc Values(列存) :按文档顺序存储原始值,聚合时直接扫描列 ,比倒排索引快 10 倍 !若你偏要用 text 聚合?ES 会默默加载 Field Data 到堆内存 ------等着 OOM 吧,少年。"
说的可能有点抽象,举个🌰
PUT /test_aggr
{
"mappings": {
"properties": {//属性名content,类型是text
"content": { "type": "text" } // 注意:这是 text!
}
}
}
POST /test_aggr/_doc
{ "content": "红烧肉食谱" }//为content赋值
// 尝试聚合 → 报错!Fielddata is disabled on text fields by default...
GET /test_aggr/_search
{
"size": 0,
"aggs": {
"by_content": {
"terms": { "field": "content" }
}
}
}"text 字段默认禁用 fielddata,因为太危险!",但是如果我就是想开启呢
PUT /test_aggr/_mapping
{
"properties": {
"content": {
"type": "text",
"fielddata": true // 强行开启!
}
}
}现在聚合能跑了,但代价巨大:
- ES 会把
content的所有值加载到 JVM 堆内存(叫 Field Data); - 如果有 1 亿条不同内容,堆内存瞬间爆炸 → OOM Killer 上线!
📉 实测数据 (100 万文档,
text字段平均 50 字符):
- 开启 fielddata → 堆内存增加 1.2GB
- 聚合耗时 800ms
- 关闭 fielddata,改用
keyword→ 堆内存增加 200MB ,耗时 80ms
正确用法:🐶保命
PUT /test_aggr_fixed
{
"mappings": {
"properties": {
"content": {
"type": "text",
"fields": { //子字段
"keyword": { // ← 关键!keyword 子字段
"type": "keyword",
"ignore_above": 256 // 超过 256 字符不索引(防滥用)
}
}
}
}
}
}
// 现在聚合走 .keyword 字段 到底是没用content
GET /test_aggr_fixed/_search
{
"size": 0,
"aggs": {
"by_content": {
"terms": { "field": "content.keyword" } // ← 注意这里!
}
}
}| 对比项 | Fielddata(text) | Doc Values(keyword) |
|---|---|---|
| 存储位置 | JVM 堆内存 | 磁盘文件(mmap 到 OS Cache) |
| 构建时机 | 查询时动态加载 | 写入时预构建 |
| 内存压力 | 高(易 OOM) | 低(由 OS 管理) |
| 适用场景 | 全文检索(分词后) | 聚合、排序、脚本 |
列式存储(Doc Values) + 高效聚合算法(不像 MySQL 那样全行扫描,ES 只读需要的字段)
- 写入时,为每个字段额外构建列式存储
- 结构:
field → [value1, value2, ..., valueN](按 doc_id 顺序) - 存储在磁盘,但 OS 会缓存(mmap)
text 用于搜索,keyword 用于聚合------这是 ES 的黄金法则
为什么不用倒排索引做聚合?
- 倒排是 term → docs ,聚合需要 doc → value
- 反向查找效率极低(尤其高基数字段)
💡 所以:
text字段默认 不开启 Doc Values(因为分词后无意义)- 聚合必须用
keyword/numeric/date等类型- 可通过
"doc_values": false关闭(节省空间,但不能聚合