一、克隆虚拟机
1、将虚拟机master关机
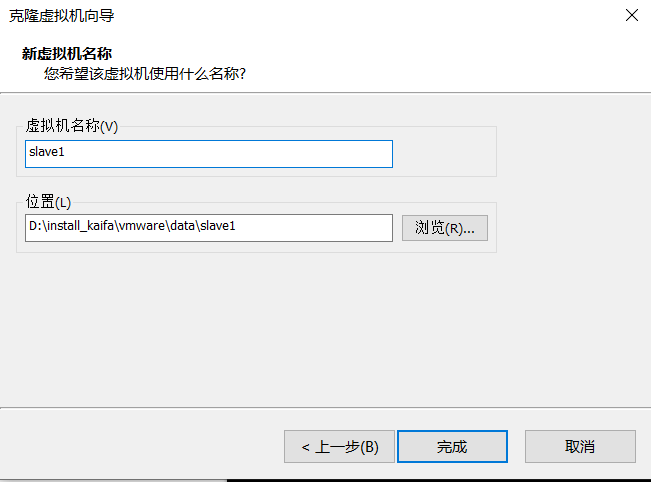
2、克隆,选择完整克隆
克隆2次,分别保存为slave1,slave2
二、修改克隆后的虚拟机salve1
1、修改slave1的ifcfg-ens33文件的IPADDR
bash
IPADDR=192.168.128.1312、重启网络服务和查看IP地址
bash
# 重启网络服务
systemctl restart network
# 查看IP地址
ip addr3、修改slave1的主机名称
bash
hostnamectl set-hostname slave14、重启
bash
reboot三、对slave2主机做二中的操作
四、主机互信配置
1、在master主机中执行,并一路回车
bash
ssh-keygen -t rsa 2、复制公钥到其他主机
bash
# 每执行一次"ssh-copy-id"命令,都需依次输入yes,123456(root用户的密码)
ssh-copy-id -i /root/.ssh/id_rsa.pub master
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave23、验证
在master主机执行ssh登录操作,成功后可以执行exit,再执行下一个
bash
ssh slave1
ssh slave2五、配置时钟同步服务
1、master主机上执行vim /etc/ntp.conf,内容如下
bash
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10然后执行
bash
systemctl start ntpd
systemctl enable ntpd2、slave1,slave2上执行vim /etc/ntp.conf,内容如下
bash
server master然后执行
bash
systemctl start ntpd
systemctl enable ntpd六、启动Hadoop集群
1、配置hadoop环境变量
bash
vim /etc/profile
bash
# 在文件最后加下面的配置
export HADOOP_HOME=/usr/local/hadoop-3.3.6
export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64
export PATH=$HADOOP_HOME/bin:$PATH:$JAVA_HOME/bin然后,执行下面命令使其生效,master slave1 slave2均做此操作
bash
source /etc/profile2、格式化hadoop
在master主机上执行
bash
hdfs namenode -format3、启动hdfs和yarn
bash
sbin/start-dfs.sh
sbin/start-yarn.sh七、验证
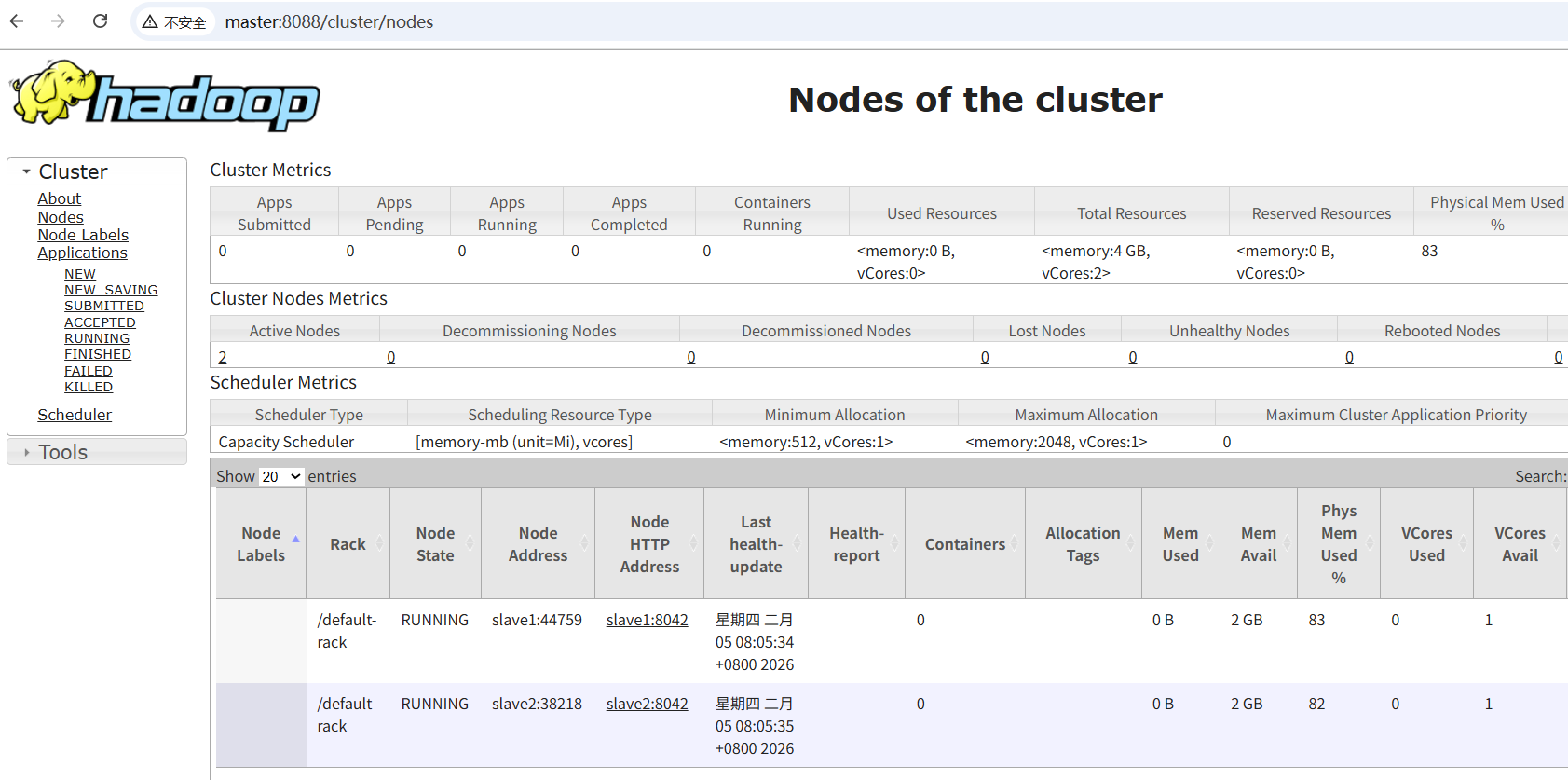
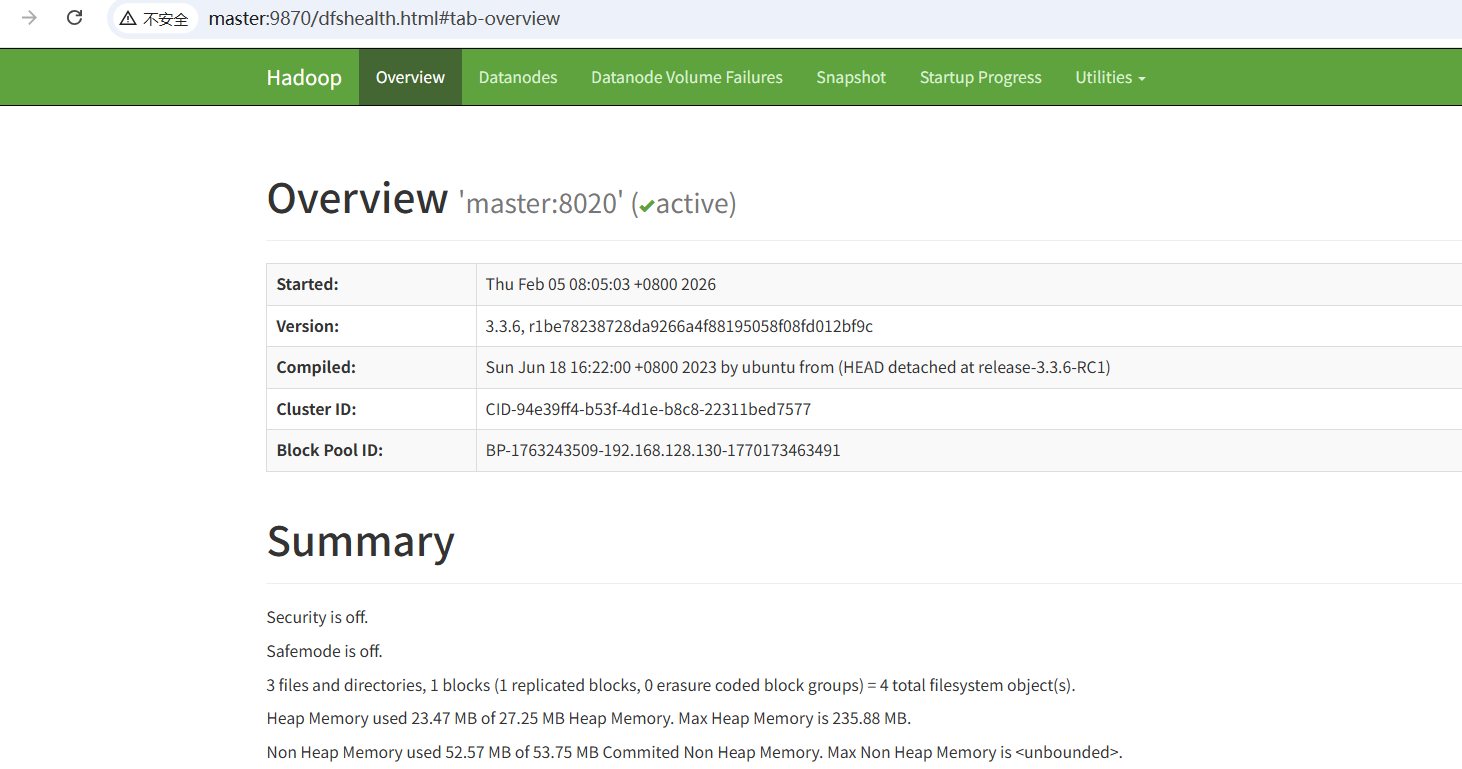
浏览器打开hdfs和yarn的监控地址
如果想用域名访问地址,可以配置C:\Windows\System32\drivers\etc\hosts,内容如下
bash
192.168.128.130 master master.centos.com
192.168.128.131 slave1 slave1.centos.com
192.168.128.132 slave2 slave2.centos.comHDFS监控页面
YARN监控页面