PostgreSQL中调整Checkpoint的重要性
什么是 Checkpoint
Checkpoint 是 PostgreSQL 确保存储层中所有内容一致的时间点。这对数据恢复非常重要。如果我引用 PostgreSQL 的文档
"Checkpoints are points in the sequence of transactions at which it is guaranteed that the heap and index data files have been updated with all information written before that checkpoint. Any changes made to data files before that point are guaranteed to be already on disk."
Checkpoint 点需要确保数据库可以从备份中安全恢复,或者在崩溃时能够安全恢复。检查点是通过应用WAL(预写日志)开始恢复的起点。
这是通过以下方式实现的:
- 识别"Dirty"缓冲区。因为事务会在共享缓冲区中留下脏缓冲区。
- 写入操作系统:为了避免磁盘I/O出现大幅峰值,PostgreSQL会将此写入过程分散在由
checkpoint_completion_target设置所定义的一段时间内进行。 fsync()每个写入文件,以确保所有文件完好无损并到达磁盘上- 更新控制文件 PostgreSQL 会使用重做位置更新一个名为 global/pg_control 的特殊文件。
- segment WAL 回收
PostgreSQL 会删除这些旧文件,或者重命名/回收崩溃恢复不再需要的旧 WAL 文件
为什么会导致性能不均衡?
如果我们密切观察 PostgreSQL 在稳定工作量下的响应表现,可能会发现锯齿形模式

除了fsync()的开销外,检查点后的性能下降主要是由 全页镜像写入(FPI) 引起的,这一点我在之前的一篇博客文章中已经解释过。这些操作对于防止因页面撕裂导致的数据损坏是必要的。根据文档说明,PostgreSQL 在检查点之后首次修改某个页面时,必须记录该页面的全部内容。此过程可确保如果在写入过程中发生崩溃,该页面能够被恢复。因此,检查点之后大量的 FPI 会导致显著的 I/O 峰值。
以下是来自文档的摘录:
"... the PostgreSQL server writes the entire content of each disk page to WAL during the first modification of that page after a checkpoint. This is needed because a page write that is in process during an operating system crash might be only partially completed, leading to an on-disk page that contains a mix of old and new data ..."
因此,在检查点之后,会立即出现大量用于这种全页写入的候选页面。这会导致输入输出峰值并降低性能。
如果我们进行调优,可以节省多少输入/输出操作?
真实的答案是:取决于工作负载和模式。
然而,并没有什么能阻止我们使用像pgbench这样的合成工作负载来研究潜在的节省。
在这项研究中,我创建了一个测试数据库,用于在固定事务数量的情况下运行pgbench工作负载。这将有助于我们比较该事务数量下的WAL生成情况:
sql
pgbench -c 2 -t 1110000这里,固定数量的事务(1110000 个)将通过两个连接分别发送。
为了进行比较,我选取了四个不同时长的检查点,分别是每5分钟(300秒)、15分钟(900秒)、半小时(1800秒)和1小时(3600秒)。
以下是我的观察结果
外链图片转存中...(img-LH4tU4CD-1770295993454)
通过分散检查点,WAL生成量从12GB降至2GB,节省了6倍!这意义重大。
整页图像(FPI)写入量从147万级降至16.1万级,节省了9倍。这再次意义重大。
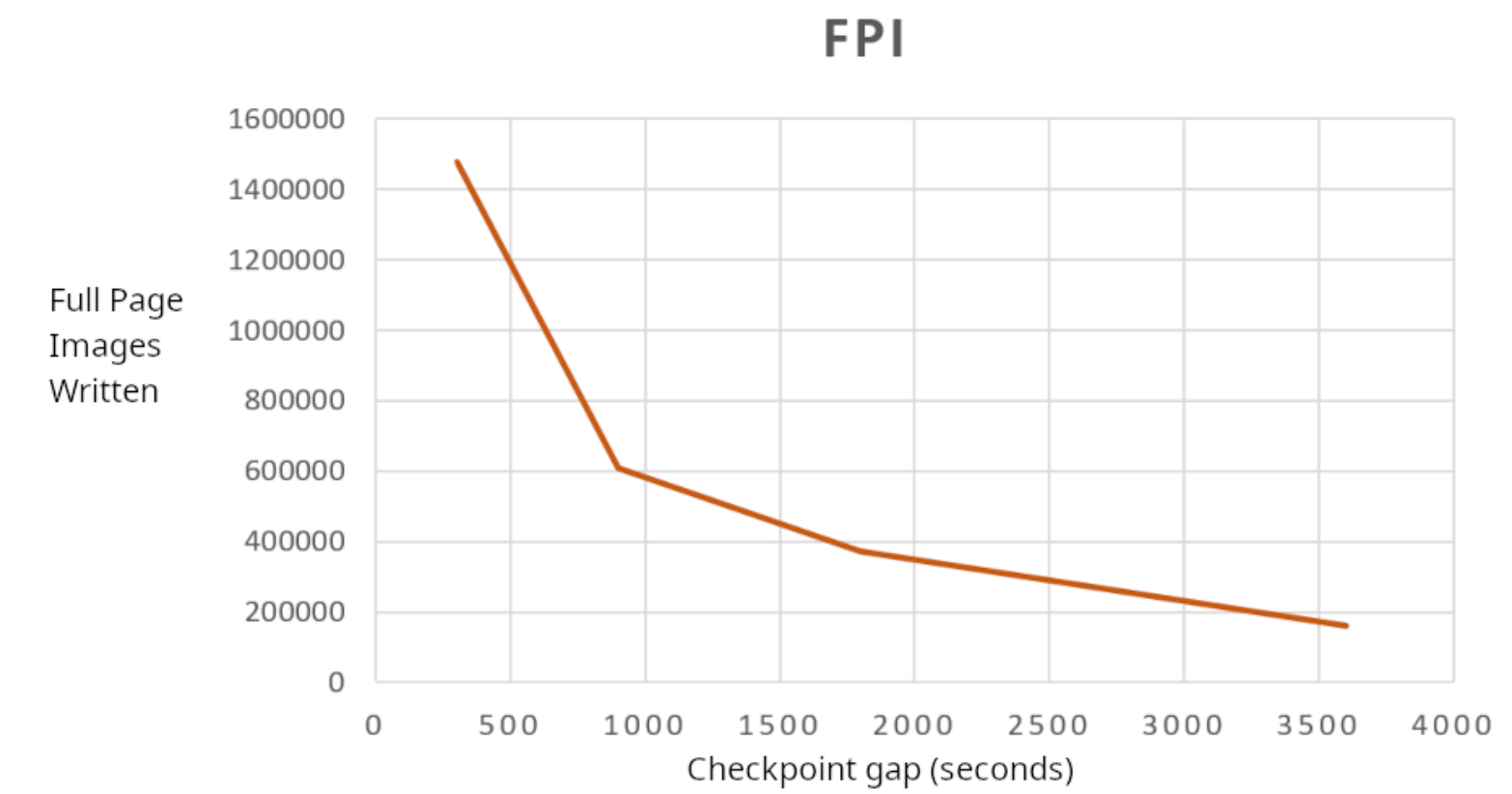
然而,我想考虑的另一个因素是WAL中完整页面的百分比。遗憾的是,在当前的PostgreSQL版本中,除非使用 pg_waldump 或 pg_walinspect 来提取此信息,否则很难获取该信息。
通过 pg_stat_wal 可获取的信息仅能为我们提供完整页面镜像wal_fpi的数量。但这些镜像在写入WAL文件之前会被压缩。
好消息是,这一功能将在即将发布的PostgreSQL 19中可用。该功能已提交,并且一个新字段 wal_fpi_bytes 已添加到 pg_stat_wal 视图中
因此,就本篇博客而言,我将考虑未压缩的FPI(wal_fpi * BLCKSZ)。这一比例从48.5%降至37.8%。因此,WAL文件中包含的事务数据占比高于全页图像。
好处并非仅来自FPI节省,如果检查点很频繁,相同的缓冲页很可能会被反复刷新到文件中。如果检查点之间的间隔足够大,那么除非存在内存压力,否则脏页可以保留在 shared_buffers 中。
除了所有的资源节省外,用户普遍反映,仅通过调整检查点就能获得约10%的性能提升。
注意:上述测试结果基于PostgreSQL 18,数据来自pg_stat_wal
论点与担忧
将检查点分散在更长时间内,最常见的顾虑是对崩溃恢复时间可能产生的影响。由于PostgreSQL必须重放自上次成功检查点以来生成的所有WAL文件,因此检查点之间的间隔更长,自然会增加恢复过程中需要处理的数据量。
但现实情况是,大多数关键系统都会配备Patroni等高可用解决方案的备用节点。如果发生崩溃,无需等待崩溃恢复。系统会立即故障转移到备用节点。因此,崩溃恢复所需的时间对数据库可用性其实并无影响。所以,只要在主节点崩溃或不可用时能切换到备用节点(高可用),崩溃恢复所需的时间就变得无关紧要了
另一个因素是,即使PostgreSQL实例是独立的,没有任何备用节点可用于故障转移,在 checkpoint 调优后,WAL 的生成量也会显著减少,因此 PostgreSQL 很容易应用这些少量的 WAL 文件。因此,由分散 checkpoint 引起的部分问题会因其自身的积极影响而得到解决。
我还听到另一个关于没有备用数据库用于故障转移的误解:如果检查点间隔为1小时,那么恢复将需要1小时。这绝对是错误的。恢复速度与检查点之间的间隔毫无关系。通常,恢复1小时的预写日志(WAL)只需要几秒钟或几分钟。但是,这确实取决于需要应用的预写日志文件的数量,让我们用PostgreSQL日志中的信息来验证这一点。
以下是基础设施处于平均水平以下的典型数据库崩溃恢复的两个示例。
sql
LOG: database system was not properly shut down; automatic recovery in progress
LOG: redo starts at 14/EB49CB90
LOG: redo done at 15/6BEECAD8 system usage: CPU: user: 18.60 s, system: 6.98 s, elapsed: 25.59 s另一个
sql
LOG: redo starts at 15/6BEECB78
LOG: redo done at 16/83686B48 system usage: CPU: user: 47.79 s, system: 14.05 s, elapsed: 69.08 s如果我们考虑第一种情况:
恢复操作能够在25.19秒内应用从LSN 14/EB49CB90到15/6BEECAD8的WAL。
sql
postgres=# SELECT pg_wal_lsn_diff( '15/6BEECAD8','14/EB49CB90' )/25.19;
?column?
-----------------------
85680702.818578801112
(1 row)85680702字节/秒 = 81.71兆字节/秒
通常情况下,即使在速度较慢的系统上,我们也能轻松看到恢复速度达到64MB/秒或更高。这意味着,即使检查点间隔一小时,大多数情况下恢复也能在几分钟内完成。当然,这取决于需要应用的WAL(预写日志),而这又取决于WAL的生成速率。
如何调整检查点设置
PostgreSQL 主要提供了三个参数来调整检查点的行为
-
checkpoint_timeout :此参数使我们能够规划检查点的间隔。因为每隔一个
checkpoint_timeout时间,就会触发一个检查点。所以实际上,这是两个检查点之间的最长时间。如果我们计划让自动检查点间隔1小时,这就是我们首先需要调整的参数。对于带有物理备用数据库的生产系统,我通常倾向于将其值设置为至少30分钟(1800秒)。 -
max_wal_size:这是PostgreSQL允许WAL在自动检查点之间增长的最大大小目标。因此,如果该参数值设置得较小,可能会触发频繁的检查点。如前所述,这种频繁的检查点会因FPI而进一步增加WAL的生成量,从而产生进一步的连锁反应。因此,该值的设置应确保PostgreSQL在两个计划检查点之间持有足够的WAL文件。
-
checkpoint_completion_target :它以检查点间隔(通过
checkpoint_timeout配置)的分数形式给出。I/O速率会被调整,以便检查点在checkpoint_timeout秒的给定比例时间内完成(或者在超过max_wal_size之前完成,以先发生者为准)。默认且通常推荐的值是0.9,这意味着检查点进程可以利用两个检查点之间90%的时间来分散I/O负载。但我见过的最佳建议是,如果checkpoint_timeouts足够大(比如半小时或一小时),那么:
sql
checkpoint_completion_target = (checkpoint_timeout - 2min) / checkpoint_timeout如何监控
如果启用了参数 log_checkpoints,每个检查点的详细信息将记录到PostgreSQL日志中。例如,以下是来自一个数据库的日志条目,该数据库的 checkpoint_timeout 为60分钟,checkpoint_completion_target 为0.9(90%)
sql
2026-01-14 16:16:48.181 UTC [226618] LOG: checkpoint starting: time
2026-01-14 17:10:51.463 UTC [226618] LOG: checkpoint complete: wrote 4344 buffers (1.7%), wrote 381 SLRU buffers; 0 WAL file(s) added, 0 removed, 549 recycled; write=3239.823 s, sync=0.566 s, total=3243.283 s; sync files=28, longest=0.156 s, average=0.021 s;
distance=8988444 kB, estimate=11568648 kB; lsn=26/2E954A50, redo lsn=24/1514C308此示例日志条目告诉我们,定时检查点(由于checkpoint_timeout)于16:16:48.181开始,于17:10:51.463完成。这意味着3243282毫秒。这在检查点完成条目中显示为"total"。检查点进程只需写入4344个缓冲区(每个8kB),约合34MB。
我们可以看到,这34MB的写入操作耗时3239.823秒(54分钟)。因此,检查点程序对输入/输出的影响非常小。这54分钟的耗时是因为
sql
checkpoint_timout * checkpoint_completion_arget = 60 * 0.9
= 54distance=8988444 kB 告诉我们检查点之间生成了多少WAL(与上一个检查点的距离)。这反映了这段时间内WAL的生成速率。
estimate=11568648 kB (≈11.5 GB)表示PostgreSQL对当前检查点与下一个检查点之间WAL生成量的预测。PostgreSQL控制IO的节流,以平滑IO负载,确保检查点在达到 max_wal_size 之前完成。
除此之外,PostgreSQL还通过统计视图 pg_stat_wal 提供WAL生成的累积统计信息(从PostgreSQL 14开始)。检查点进程的摘要信息可通过 pg_stat_bgwriter 获取(直至PostgreSQL 16),而从PostgreSQL 17开始,有一个专门的 pg_stat_checkpointer 视图可用。
总结
检查点会产生大量的WAL,这直接影响服务器中的整个IO子系统,进而影响性能、备份和WAL保留。调整检查点进程有很多好处。
- 在昂贵的WAL IO方面节省了大量成本,而WAL IO本质上是同步的
- 由于输入输出操作大幅减少而带来的相关性能优势是不言而喻的。在那些输入输出性能和负载成为限制因素的系统中,这种差异将会非常明显。
- 它有助于减轻WAL归档的负担,并节省备份基础设施和存储的成本。
- 生成的WAL越少,系统耗尽空间的可能性就越小
- 待机卡顿的可能性更小。
- 节省网络带宽,因为用于复制和备份(WAL归档)传输的数据更少。
总的来说,这是每个数据库管理员(DBA)在数据库调优过程中应该采取的首要步骤之一。如果存在像Patroni这样的高可用(HA)框架,将检查点分散在1小时或更长时间内是完全可行的。