目前的图像生成技术主要分为两大流派:一种是先压缩图片再生成的"潜在扩散模型"(Latent Diffusion),另一种是直接在像素上生成的"像素扩散模型"(Pixel Diffusion)。潜在扩散模型虽然快,但压缩过程像是有损压缩,会丢失细节并产生伪影。像素扩散模型虽然画质上限高,但因为它要处理的数据量太大,且包含很多像噪点一样人眼看不见的无用信息,导致训练非常困难,效果一直不如前者。
为了解决这个问题,北京大学 提出了一个名为 PixelGen 的新框架。它的核心思想是:不让模型去死记硬背图像里的每一个像素点(包含无用的噪声),而是通过引入感知损失(Perceptual Loss),像人类看东西一样,只关注图像中"看得见、有意义"的部分。通过结合关注局部的 LPIPS 和关注全局的 DINO 两种监督信号,PixelGen 能够在不需要图像压缩器(VAE)的情况下,仅用很少的训练时间就超越了目前最强的潜在扩散模型,实现了更清晰、更真实的图像生成效果。
一、论文基本信息

- 论文标题:PixelGen: Pixel Diffusion Beats Latent Diffusion with Perceptual Loss
- 作者姓名与单位:Zehong Ma, Ruihan Xu, Shiliang Zhang(北京大学多媒体信息处理国家重点实验室)
- 论文链接:https://arxiv.org/abs/2602.02493
二、主要贡献与创新
- 提出了 PixelGen,一种端到端的像素级扩散框架,完全摒弃了 VAE 和潜在空间表示,消除了压缩带来的伪影和瓶颈。
- 引入了两种互补的感知损失:LPIPS 损失 用于捕捉局部纹理细节,P-DINO 损失用于增强全局语义结构。
- 提出了噪声门控策略(Noise-Gating),仅在低噪声的时间步施加感知监督,有效平衡了生成图像的质量与多样性。
- 在 ImageNet 上仅用 80 个 Epoch 就达到了 5.11 的 FID 分数,显著优于训练了 800 个 Epoch 的强力潜在扩散模型(REPA)。
三、研究方法与原理
该论文提出的核心思路是:在像素空间中,与其让模型费力地学习包含大量不可见高频噪声的"完整图像流形",不如利用感知损失引导模型专注于学习人眼敏感的"感知流形"。
【模型结构图】
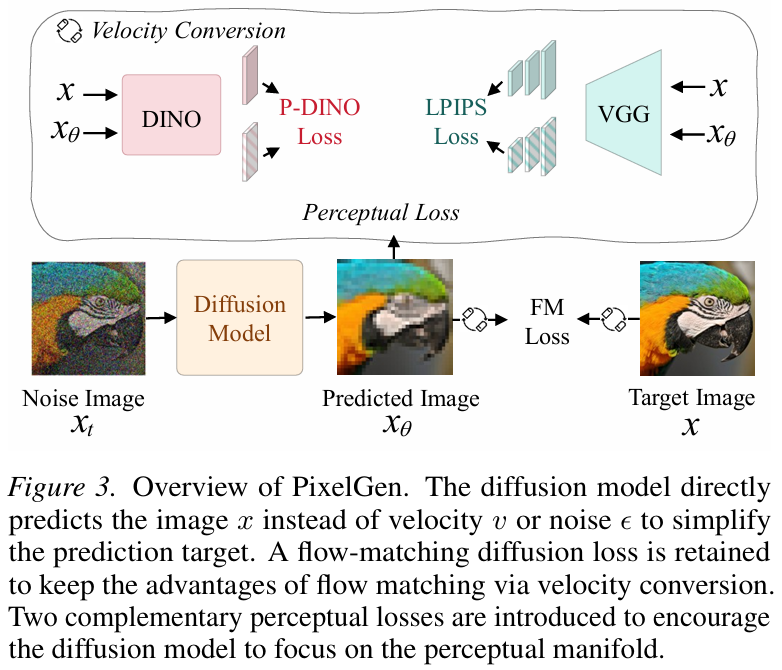
1. 核心架构:图像预测与流匹配
PixelGen 建立在最近提出的 JiT (Just-in-Time) 像素扩散模型基础之上。传统的扩散模型通常预测噪声( ϵ \epsilon ϵ)或速度( v v v),但 PixelGen 采用 x x x-prediction 策略,即让神经网络直接从噪声输入中预测干净的原始图像 x θ x_{\theta} xθ。
为了保持流匹配(Flow Matching)在采样上的优势,模型虽然预测的是图像,但通过数学转换将其映射回速度场。给定时间 t t t 的噪声图像 x t x_t xt,模型预测出 x θ x_{\theta} xθ 后,通过以下公式计算预测速度 v θ v_{\theta} vθ:
v θ = x θ − x t 1 − t v_{\theta} = \frac{x_{\theta} - x_t}{1 - t} vθ=1−txθ−xt
并利用流匹配目标函数进行优化:
L F M = E t , x , ϵ ∥ v θ − v ∥ 2 = E t , x , ϵ ∥ x θ − x 1 − t ∥ 2 L_{FM} = \mathbb{E}{t,x,\epsilon} \\\| v_{\\theta} - v \\\|\^2 = \mathbb{E}{t,x,\epsilon} \left \\left\\\| \\frac{x_{\\theta} - x}{1 - t} \\right\\\|\^2 \\right LFM=Et,x,ϵ∥vθ−v∥2=Et,x,ϵ 1−txθ−x 2
这种方式结合了直接预测图像的稳定性与流匹配的高效采样能力。
2. 关键创新:双重感知监督
仅靠上述的像素级误差(如 L2 损失)会导致生成的图像模糊,因为模型会试图"平均"所有可能性。PixelGen 引入了两个关键的感知损失来引导模型学习感知流形(Perceptual Manifold):
LPIPS 损失(局部细节):
为了解决像素级损失导致的模糊问题,作者使用了 LPIPS 损失。它利用预训练的 VGG 网络提取特征,计算预测图像与真实图像在特征空间层面的距离。公式如下:
L L P I P S = ∑ l ∥ w l ⊙ ( f V G G l ( x θ ) − f V G G l ( x ) ) ∥ 2 2 L_{LPIPS} = \sum_{l} \| w_l \odot (f^l_{VGG}(x_{\theta}) - f^l_{VGG}(x)) \|_2^2 LLPIPS=l∑∥wl⊙(fVGGl(xθ)−fVGGl(x))∥22
这一步迫使模型生成更锐利的边缘和更真实的局部纹理,关注点在于"看起来像真的"。
P-DINO 损失(全局语义):
光有细节是不够的,图像还需要有正确的结构和物体语义。作者提出了基于 DINOv2 的感知损失。DINOv2 是一个强大的自监督视觉模型,对语义非常敏感。通过计算预测图像和真实图像在 DINO 特征块上的余弦相似度 ,来约束全局语义:
L P − D I N O = 1 ∣ P ∣ ∑ p ∈ P ( 1 − cos ( f D I N O p ( x θ ) , f D I N O p ( x ) ) ) L_{P-DINO} = \frac{1}{|P|} \sum_{p \in P} (1 - \cos(f^p_{DINO}(x_{\theta}), f^p_{DINO}(x))) LP−DINO=∣P∣1p∈P∑(1−cos(fDINOp(xθ),fDINOp(x)))
这确保了生成的图像在物体结构和类别上与目标保持一致。
3. 总损失函数与训练策略
最终的训练目标是将流匹配损失与上述感知损失结合。为了防止感知损失在噪声非常大的初期阶段干扰模型的分布学习,PixelGen 采用了噪声门控 策略,即只在去噪过程的后 70%(低噪声阶段)启用感知损失。总公式为:
L = L F M + λ 1 L L P I P S + λ 2 L P − D I N O + L R E P A L = L_{FM} + \lambda_1 L_{LPIPS} + \lambda_2 L_{P-DINO} + L_{REPA} L=LFM+λ1LLPIPS+λ2LP−DINO+LREPA
其中 L R E P A L_{REPA} LREPA 是一种特征对齐损失,用于进一步辅助训练。这种组合让 PixelGen 在不需要 VAE 的情况下,直接在像素空间学会了高质量生成。
四、实验设计与结果分析
1. 实验设置
实验主要在标准的 ImageNet 256x256 数据集上进行。使用了 DiT-L(Large)作为骨干网络,并在 ImageNet 上训练了 200,000 步(约 80 个 Epoch)。评测指标包括衡量图像真实度的 FID (越低越好)、Inception Score (IS) 、以及衡量多样性的 Precision 和 Recall。此外,还进行了大规模的文生图(Text-to-Image)预训练测试。
2. 对比实验结果
在无分类器引导(CFG)的设置下,PixelGen 展现了惊人的效率和效果。
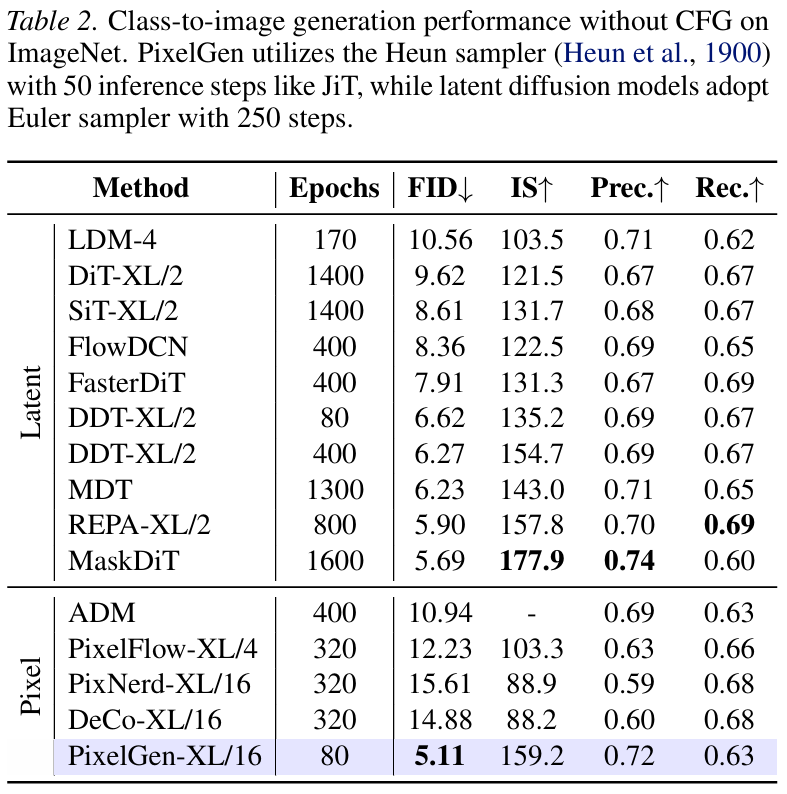
主要发现:
- 超越潜在扩散模型: PixelGen-XL/16 仅训练了 80 个 Epoch 就达到了 5.11 的 FID。相比之下,著名的潜在扩散模型 REPA-XL/2 需要训练 800 个 Epoch 才能达到 5.90 的 FID。这说明直接在像素空间进行感知引导,比去优化潜在空间更加高效且效果更好。
- 超越其他像素模型: 相比于同类的像素扩散模型(如 DeCo 训练 320 Epoch 得到 14.88 FID),PixelGen 的优势是碾压级的。
3. 可视化对比

可视化结果清晰地显示:基线模型生成的图像模糊不清;加入 LPIPS 后,毛发、纹理变得清晰锐利;进一步加入 P-DINO 后,物体的整体结构(如狗的形状、姿态)变得非常准确和连贯。
4. 消融实验
作者详细探究了各个组件的作用。
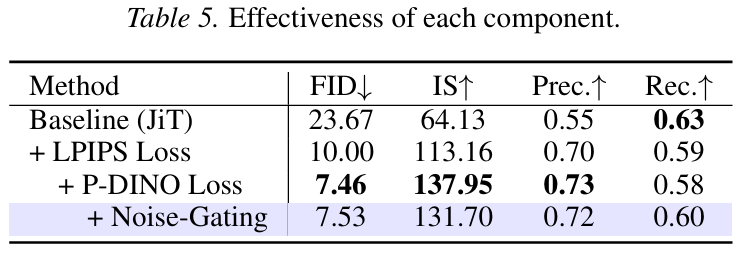
- 基线 (JiT): FID 为 23.67,效果较差。
- + LPIPS: FID 骤降至 10.00,证明了局部纹理监督对像素生成的关键作用。
- + P-DINO: FID 进一步降至 7.46,补全了语义信息的短板。
- + 噪声门控 (Noise-Gating): 虽然 FID 变化不大 (7.53),但 Recall(召回率)有所提升,说明在去噪初期关闭感知损失有助于保持生成样本的多样性,防止模型"死记硬背"。
五、论文结论与评价
总结
本文提出了 PixelGen ,证明了在像素空间直接进行扩散生成不仅是可行的,而且在引入正确的感知监督(LPIPS + P-DINO)后,可以击败目前主流的潜在扩散模型(Latent Diffusion)。PixelGen 不需要复杂的 VAE 进行图像压缩,避免了压缩带来的伪影,提供了一种更简单、更纯粹且性能更强大的生成范式。实验数据表明,它在训练效率和最终生成质量上都取得了突破性进展。
影响与启示
- 简化流程:该研究表明我们可能不需要 VAE 这类"中间商",未来的生成模型架构可能会更加精简,直接面向像素优化。
- 感知损失的重要性:再次印证了在生成任务中,让模型"像人眼一样看世界"(感知空间)比单纯的数学拟合(像素空间或潜在空间)更为关键。
- 大模型扩展性:在文生图任务上的成功(GenEval 得分 0.79)暗示了这种方法在大规模基础模型上的潜力,可能挑战 Stable Diffusion 或 FLUX 等现有霸主的地位。
优缺点分析
- 优点 :
- 画质上限高:没有 VAE 的有损压缩,理论上可以生成最完美的像素细节。
- 架构简单:去除了训练和微调 VAE 的复杂步骤。
- 训练收敛快:在感知损失引导下,极少的 Epochs 就能达到 SOTA 效果。
- 缺点 :
- 计算开销:尽管训练步数少,但像素空间的高维度特性意味着单步计算量依然巨大,显存占用可能较高。
- 依赖预训练模型:需要依赖 VGG 和 DINOv2 等预训练模型来计算损失,这引入了额外的外部依赖。
虽然 PixelGen 在 ImageNet 上表现出色,但像素空间的计算成本随着分辨率提升会呈平方级增长(例如 1024x1024)。论文虽然展示了 512x512 的结果,但对于更高分辨率(如 2K/4K),完全抛弃潜在空间的压缩机制是否在推理速度 和硬件要求上仍然经济可行,是一个值得进一步探讨的问题。未来的研究可以将 PixelGen 与轻量级的下采样或更高效的注意力机制结合,以解决高分辨率下的计算瓶颈。