本文从本质原理、结构进化、训练核心、避坑指南四个维度拆解深度学习入门关键,聚焦神经网络核心逻辑,帮初学者建立清晰的知识框架,所有复杂概念均回归基础原理,是入门深度学习的核心参考。
一、神经网络的核心本质
深度学习的核心是人工神经网络,其核心并非模拟人脑的"仿生结构",而是通过矩阵运算拟合数据特征与目标结果之间的真实关系,是一种结构化的数值计算模型。
1.核心四大要素
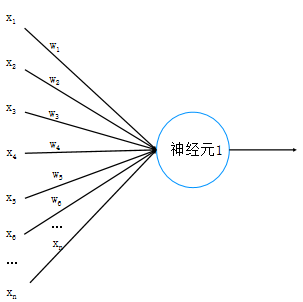
• 神经元:网络基本计算单元,接收输入信号→权重加权求和→激活函数输出,完成一次基础计算;
• 权重(w):节点间的连接"强度",是网络的"记忆",模型训练的核心就是优化所有权重参数;
• 激活函数:引入非线性变换(如sigmoid),解决线性模型无法处理复杂非线性问题的核心,无激活函数则网络失去核心拟合能力;
• 偏置节点:除输出层外各层默认存在,值恒为1,用于调整模型偏移量,提升数据拟合的灵活性。
2.三层基础结构
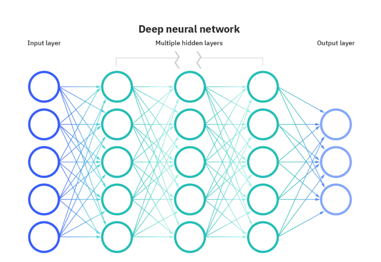
• 输入层:节点数=数据特征维度,仅负责接收原始数据,不做任何计算;
• 隐藏层:网络的核心处理单元,通过多层堆叠实现复杂特征提取(这也是"深度"的由来),是特征从简单到复杂的转化层;
• 输出层:节点数=任务目标维度,输出模型预测结果(如分类任务输出各类别概率、回归任务输出具体数值)。
二、神经网络的进化脉络
神经网络的发展是模型复杂度逐步提升、非线性拟合能力持续增强的过程,核心进化节点清晰,后续所有复杂模型均源于此基础逻辑:
-
感知器:最基础的两层网络(输入层+输出层),仅能做线性运算,无法处理非线性问题,公式可简化为
(g为激活函数),是神经网络的"雏形";
-
多层感知器(MLP):在输入层与输出层之间增加至少1层隐藏层,这是网络能处理非线性任务的关键突破(隐藏层+激活函数实现非线性拟合),隐藏层节点数无固定理论,需通过实验对比选择;
-
深度神经网络:堆叠多个隐藏层,结合海量训练数据与大规模参数(如ChatGPT的1750亿参数),实现对超复杂数据(文本、图像、语音)的精准建模,是当前深度学习的主流形态。
三、模型训练三大核心技术
训练神经网络的唯一目标:优化权重参数,让模型预测结果无限逼近真实值,整个训练过程依赖三大核心技术,三者协同工作实现参数迭代优化:
1. 损失函数:衡量预测误差的"标尺"
核心作用是量化模型预测值与真实值的差异,误差越小,模型效果越好,需根据任务类型选择,主流类型:
• 均方差损失:适用于回归任务(预测连续值,如房价、温度),计算平方差的平均值;
• 交叉熵损失:适用于分类任务(预测离散类别,如图像识别、文本分类),公式核心为 (
为真实标签,
为预测概率),通过-log运算放大错误预测的损失,提升模型对错误的修正能力;
• 其他:0-1损失、平均绝对差损失、合页损失等,适配特定任务场景。
2. 正则化:防止过拟合的"刹车"
过拟合:模型在训练集表现极好,但在测试集(新数据)表现极差,本质是模型过于复杂,过度学习训练集的噪声而非通用规律。
正则化的核心是惩罚复杂的权重参数,强制简化模型,主流两种方式:
• L1正则化:惩罚所有权重的绝对值之和(),可使部分权重变为0,实现特征自动筛选(剔除无用特征);
• L2正则化:惩罚所有权重的平方和,让权重值均匀分布,避免模型过度依赖某几个特征("雨露均沾"的学习逻辑),是最常用的正则化方式。
3. 梯度下降:优化权重参数的"导航"
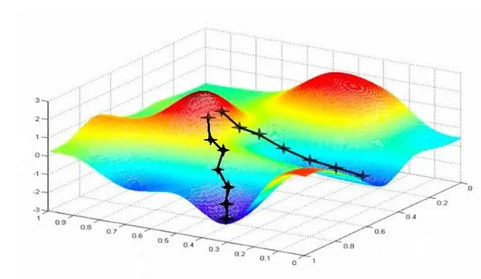
深度学习最核心的优化算法,本质是沿损失函数的梯度方向,逐步调整权重参数,最终找到损失函数的最小值(最优参数),核心要点:
• 梯度:损失函数对所有权重参数的偏导数构成的向量,唯一指示"误差下降最快的方向";
• 学习率(步长):控制每次参数更新的幅度,过大易在最小值附近震荡不收敛,过小则训练速度极慢,是训练中需调优的关键超参数;
• 核心流程:正向传播计算损失→反向传播(BP算法)回传误差→沿梯度方向调整权重,循环迭代直至损失值稳定在低水平(满足收敛要求)。
四、入门必避的4大认知误区
-
误区:神经网络是"仿生人脑"→ 正解:核心是矩阵运算,仿生只是设计灵感,掌握线性代数是理解其原理的关键;
-
误区:隐藏层越多,模型效果越好→ 正解:需平衡模型复杂度与数据量,隐藏层过多易导致过拟合、训练效率低下,甚至出现"梯度消失";
-
误区:权重初始化可以设为0→ 正解:必须随机赋值,若全为0,反向传播时所有参数更新幅度一致,网络无法学习到不同特征,等同于"单节点模型";
-
误区:激活函数可省略/用线性激活→ 正解:激活函数是非线性拟合的核心,省略或用线性激活,多层网络会直接退化为感知器,失去"深度"的意义。
五、核心总结
-
深度学习的本质:通过多层网络的层层堆叠提取数据的复杂特征,通过梯度下降算法迭代优化权重参数,最终实现对数据规律的精准拟合与预测;
-
核心逻辑一脉相承:从简单的感知器到千亿参数的大模型(如ChatGPT),所有深度学习模型均基于"特征提取+参数优化"的底层逻辑,基础原理完全一致;
-
初学者入门路径:先掌握基础原理(神经网络构造、损失函数、正则化、梯度下降)→ 再做简单实操案例(如图像分类、房价回归)→ 逐步过渡到复杂模型,切勿急于追求大模型、多参数;
-
核心能力基础:线性代数(矩阵、偏导数)是理解原理的关键,编程实操(如Python+PyTorch/TensorFlow)是落地的核心,两者缺一不可。
深度学习的魅力在于其强大的泛化能力(适配新数据的能力),而入门的关键并非死记硬背概念,而是拆解复杂、聚焦核心------所有看似高深的技术,最终都回归到"如何更好地提取特征、如何更高效地优化参数"这两个基础问题。