目录

概述
线程是相对于进程的概念,进程是系统分配资源的基本单位,有了进程,就可以解决程序独立运行的问题,但是无法高效解决程序内部并发执行多个任务的问题,进程相对线程而言,要面临多个问题:
- 进程是资源分配的单位,每次创建进程,都要给进程分配虚拟地址空间、页表、文件描述符等资源,这个过程就像搭建一个工厂一样麻烦(而线程可以类比工厂里面的设备,可以实际生产,但是又很轻量,可以根据需要来购进设备 -- 创建线程)
- 进程通信成本极高,进程之间可以通过信号、管道、文件、或则套接字来进行通信,必须通过一个中间体,而无法直接访问对方进程的内存空间来读取数据,这主要是为了进程运行时安全。
- 进程切换效率极低,每次进程切换,意味着需要保存完整的上下文来(内存映射、寄存器、页表等信息),再加载此进程的时候又要把他们的上下文给重新加载出来,cpu消耗极大,并发能力有限。
- 进程任务执行的粒度太大,如果进程被阻塞,那么就代表这个任务就停滞,但是如果将这个进程的任务拆分给多个线程来执行,那么可以配备专门的线程来进行io等会被阻塞的操作,其他的任务可以在io线程被阻塞的时候继续运行。
线程就此而生,线程的内存模型如下图所示,线程共享进程的内部资源:
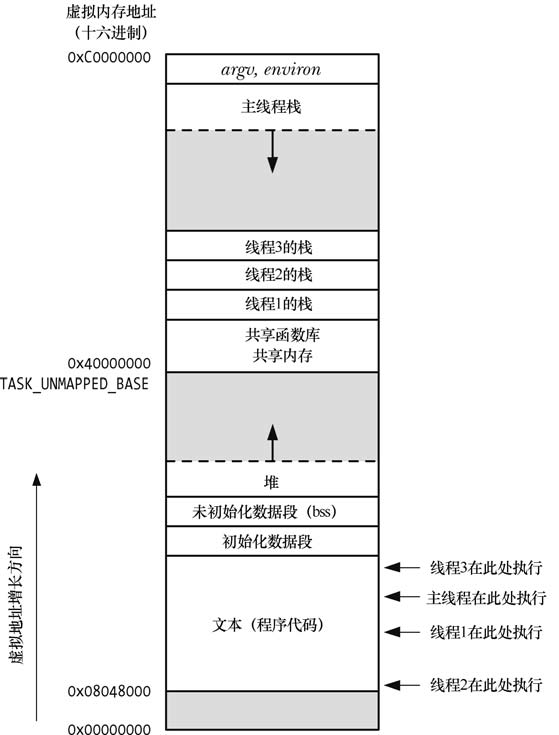
线程共享进程资源体现在:
- 进程ID,任何线程中执行获取pid的操作,都会返回线程所属进程的进程ID。
- 进程组ID,情况同进程ID。
- 打开文件描述符。
- 信号处置。
- 资源限制。
- 等。。。
线程独有的属性如下(列出一部分):
- 线程ID。
- 信号掩码。
- 线程特有数据(类似于Java的ThreadLocal)
- errno变量。
- 线程栈。
- 等。。。
我们在线程中调用malloc()申请的内存,属于整个进程的全局堆区,而非线程私有,只有线程的局部变量(非malloc或者calloc申请的堆区内存空间),才属于线程的栈区。因此我们应小心使用别的线程栈上返回的指针类型的数据。因为这个数据如果不是属于进程全局堆区,那么将无法保证他是否会在线程栈销毁之后,依然存在。
学习线程最主要就是学习线程相关的函数和线程的内存模型,线程的模型已经有了一个大概的了解,后续的模型的学习会贯穿在线程函数的学习中。接下来我们主要介绍线程相关的函数和数据类型。
线程数据类型
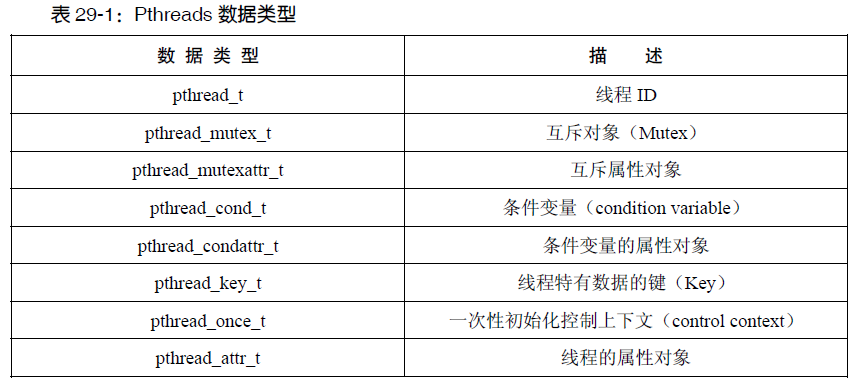
线程的数据类型被设计为不透明类型,其本质是对一些基本数据类型或者结构体进行类型定义,你无需了解里面实现的细节,也就是你不需知道类型定义他的原本的数据类型是什么,因为不同的平台有不同的实现,因此为了保证跨平台移植,不建议将内置的类型转化为他原来的类型来使用,因为你无法保证其他平台也是同样实现这个类型定义。
但是可以大概了解一下他们的实现,这对我们变成也是有帮助的:
- pthread_t类型,早期是unsigned long,现在可能是指向线程描述符的指针(struct pthread*)类型。正是这种实现的不确定性,编程的时候才不能直接拿==去判断两个pthread_t类型是否相等。因此,具体的平台会帮你实现这个功能,你可以调用pthread_equal()去比较。
- 其他的类型差不多也都是整形或者结构体,其实现都遵循不透明数据类型的规范,由平台提供给你这些自定类型的各种函数,以便于你去使用。具体数据类型的实现不一一讲解,主要是看类型的功能。
errno
在一般的编程里面,errno被视为一个全局整型变量,这肯定无法满足多线程的要求的,例如如果多个线程发生错误并记录全局的errno,那么errno会以最后一个生产的errno为主,最先生成的errno被后面的errno覆盖了。
因此多线程里面,每个线程都有自己的errno,具体的使用方法和在单线程中使用一样,使用errno之前必须先引入errno.h的头文件(无论是单线程还是多线程,都需要引入这个头文件)。
这个头文件中,并不是单纯的定义了一个全局变量,其本质是一个宏定义,展开之后是一个函数调用,如下:
cpp
// <errno.h> 中的核心宏定义
#define errno (*__errno_location())可以看到你每次使用errno,其本质都是先调用一个函数,这个函数返回一个指针类型,然后对其解引用得到值,并非定义的全局变量。他返回的是线程私有的errno。
创建线程
你编写好一个.c文件之后去运行,这个进程开始只会有一个线程,被称之为main线程,也叫主线程,在主线程中,你可以写下创建线程的函数代码以此在main线程中创建更多的线程。
使用函数创建的声明如下:
cpp
#include <pthread.h> // 必要的头文件
int pthread_create(
pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine) (void *),
void *arg
);其参数说明如下:
- thread ,pthread_t* 类型,这个参数没有被const修饰,在函数调用过程中会被修改,用来记录创建的线程的唯一ID。
- attr,线程的属性(线程的位置、大小、调度策略、调度优先级等),填入NULL表示使用线程的默认属性,一般填NULL即可。
- start_routine,函数指针,参数为void* 类型,返回值也为void* 类型,表示线程的任务,线程在被创建之后就会去执行start_routine函数里面的内容
- arg,start_routine的参数,为void*类型,理论可以穿任意数据类型,只要在start_routine中转回特定的数据类型即可。
下面是一个创建线程,让这个线程执行打印hello world的例子:
cpp
#include <pthread.h>
#include <stdio.h>
void* start_route(void* arg) {
printf("hello world\n");
}
int main()
{
pthread_t thread;
// thread 记录创建的线程id
// 属性设置为NULL,表示使用默认属性,
// start_route 函数指针
// start_route的参数设置为NULL
pthread_create(&thread, NULL, start_route, NULL);
// 连接创建的线程
pthread_join(thread, NULL);
return 0;
}编译并运行:
bash
des@des-virtual-machine:~/test2$ gcc pthread_create_example.c -o pthread_create_example
des@des-virtual-machine:~/test2$ ./pthread_create_example
hello world需要注意的是,pthread_create函数执行之后,现在这个进程就有两个线程了,此时你无法确定哪个线程会先执行,他们遵循着和进程一样的异步执行特性。
此外:
- arg参数本为start_route的入参,但是此处将arg设为NULL,表示start_route没有参数,因此线程进入到start_route并执行的时候,形参arg就是NULL。但如果不为空,需要根据传入的类型,来将其强转为对应的类型,为确保可移植性,需要在传入参数那里将arg强转为void*,以免出现类型不匹配错误,同时在函数体里面也应该严格转回原来的数据类型。
- 后面的pthread_join是连接操作,你可以简单的理解为,main线程执行到pthread_join之后,就会阻塞在这一句代码,然后等待新建的线程执行完毕,pthread_join才会停止阻塞继续运行。
- start_route的返回值也是一个void*类型,在我们的代码中并没有显式的写return 语句,这是不推荐的。但是还需要注意,一个线程被取消的时候,其返回值相当于return -1,这和线程取消的宏定义返回值一样,需要注意区分。
获取线程ID(pthread_t)
进程内部每个线程都有一个唯一标识,称为线程id。
创建线程之后,这个线程的ID就会被存储在调用者传入的pthread_t类型的变量中,此时调用者就可以通过这个ID来找到此新建线程的线程ID。
当然也可以通过函数pthread_self来获得。pthread_self函数会返回调用者的线程ID(pthread_t类型)。
其函数声明如下:
cpp
#include <pthread.h>
pthread_t pthread_self(void);返回值为pthread_t类型,没有参数。这个方法比较简单,就不列举代码案例。
这个线程ID有何用?不同的线程需要利用ID来进行表示目标进程,包括函数pthread_join,pthread_detach,pthread_kill等,都需要显示的指定目标线程ID。
当然这些线程ID不光用于官方库,还可以用于自定义的函数和数据结构。
仍然需要注意的是,两个线程ID(pthrea_t类型)的比较不能直接用==来比较,而是要用专门的函数pthread_equal来比较。其函数声明如下:
cpp
#include <pthread.h>
int pthread_equal(pthread_t t1, pthread_t t2);如果两个相等,该函数就返回一个非零值,否则返回0。
以下的代码是一个返利,它并不具备良好的可移植性:
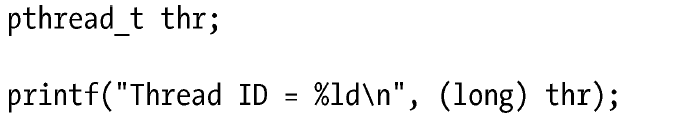
可以看到,你默认pthread_t类型为一个long类型,但是不同的平台具有不同的实现,可能这个设备可以运行,放到下一个unix设备就无法运行了。
内核线程ID vs 线程ID(pthread_t)
我们说了这么半天的pthread,这个p就是指的posix的意思,也就是posix thread,他是posix库下的多线程的具体实现,可以通过pthread_self来获取自己的ID,但是此ID非彼ID,它和在linux系统上调用getid()系统调用返回的ID并不是同一个东西,getid()系统调用返回的ID是内核维护的数据,一般程序无需知道内核的线程ID。
终止线程
可以由以下这几种方法结束掉线程:
- 线程执行到return语句,并有return指定返回值
- 线程调用pthread_exit()函数(本节重点)
- 调用pthread_cancel()来取消函数
- main线程执行了return语句,或者任意线程调用了exit()函数(exit函数是终止进程的意思,源于stdlib.h库,无论在哪个线程,都会结束进程)
接下来我们讲解pthread_exit函数,其函数声明如下:
cpp
#include <pthread.h>
void pthread_exit(void *retval);其中:
- retval,是return value的缩写,表示返回值,通过传入一个指针,来记录返回值。
具体代码案例如下:
我们创建一个线程,让线程返回一个申请在堆区的字符串。在新建的线程中使用pthread_exit返回此字符串给主线程,主线程来打印此字符串。
cpp
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void* thread_function(void* arg) {
char* ret = (char*)malloc(sizeof(100));
ret[0] = 'h';
ret[1] = 'e';
ret[2] = 'l';
ret[3] = 'l';
ret[4] = 'o';
ret[5] = ' '; // 空格字符
ret[6] = 'w';
ret[7] = 'o';
ret[8] = 'r';
ret[9] = 'l';
ret[10] = 'd';
ret[11] = 0;
pthread_exit((void*)ret);
return NULL;
}
int main()
{
pthread_t t;
pthread_create(&t, NULL, thread_function, NULL);
char* s;
pthread_join(t, (void**)&s);
if (s == NULL) {
printf("pthread_exit返回值未生效\n");
}
printf("main: %s\n", s);
return 0;
}执行结果如下:
bash
des@des-virtual-machine:~/test2$ gcc pthread_exit_example.c -o pthread_exit_example
des@des-virtual-machine:~/test2$ ./pthread_exit_example
main: hello world可以看到,我在线程执行的函数中,在pthread_exit函数后面加了一个return语句,如果返回值为null,那就说明pthread_exit的返回值并没生效,但是从结果来看,pthread_exit返回值确实生效了,并没有返回null。
在线程里面调用pthread_exit相当于在线程中执行了return语句,不同之处在于,线程可以在启动函数(start_route)中的或者任意子函数中使用,无论这个线程在调用pthread_exit之前有多少个函数调用栈帧,都会退出当前线程,而return语句仅仅只是返回到上一层的函数栈帧中。
同样需要注意的是,不能在线程私有栈中申请一块非malloc和calloc的内存空间并把它返回给接收的线程,因为你并不能知道这个空间是否可用,这个局部变量的生命周期是随着线程栈帧的销毁而销毁的。
同样,如果在main线程的任何代码中执行了pthread_exit,那么无论如何这个进程都会结束执行,在mian函数中执行return有同样的效果,但是需要注意不是在main线程里面运行的return语句也仅仅只是推出一个函数。
连接(join)
函数pthread_join()等待由pthread_t标记的线程,如果线程依旧终止,那么就会立即返回,否则会线程会阻塞等待。简单来说就是pthread_join这个函数的参数里面指定了一个线程的pthread_t,某个线程调用了pthread_join,就会阻塞等待这个线程ID为传入参数的线程执行结束,如果这个线程已经结束,那么就会立马返回。
其函数声明如下:
cpp
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);其中thread的类型pthread_t,表明线程ID,retval为传入传出参数,表明返回值,返回值使用retval来接收。
其函数返回值如果为0表示调用成功,否则就会返回一个错误码。
下面我们在main线程里面创建一个子线程,然后子线程执行每秒1次的打印,持续20秒,如下:
cpp
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
// 每秒执行一次打印,持续20秒
void* start_route(void* arg) {
printf("新线程开始执行\n");
for(int i = 0; i < 20; i++) {
printf("this is in new thread: i = %d\n", i);
sleep(1);
}
printf("新建线程执行结束\n");
}
int main()
{
pthread_t t1;
pthread_create(&t1, NULL, start_route, NULL);
return 0;
}但是其输入却是如下:

可以看到什么都没输出。我们之前提到过,main线程中执行return语句或者pthread_exit(),会直接导致main线程结束,main线程结束代表进程主流程结束,随之进程也会结束,进程的其他线程都会被回收,所以没有打印,因此我们需要然后新建线程连接上main线程,由main线程去调用pthread_join然后在参数中指明新建线程的pthread_t,也就是线程ID:
cpp
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
// 每秒执行一次打印,持续20秒
void* start_route(void* arg) {
printf("新线程开始执行\n");
for(int i = 0; i < 20; i++) {
printf("this is in new thread: i = %d\n", i);
sleep(1);
}
printf("新建线程执行结束\n");
return NULL; // 标准做法应该是在不需要返回值时候,返回NULL。
}
int main()
{
pthread_t t1;
pthread_create(&t1, NULL, start_route, NULL);
pthread_join(t1, NULL);
printf("main线程执行完毕\n");
return 0;
}输出结果如下:
bash
des@des-virtual-machine:~/test2$ ./pthread_join_example
新线程开始执行
this is in new thread: i = 0
this is in new thread: i = 1
this is in new thread: i = 2
this is in new thread: i = 3
this is in new thread: i = 4
this is in new thread: i = 5
this is in new thread: i = 6
this is in new thread: i = 7
this is in new thread: i = 8
this is in new thread: i = 9
this is in new thread: i = 10
this is in new thread: i = 11
this is in new thread: i = 12
this is in new thread: i = 13
this is in new thread: i = 14
this is in new thread: i = 15
this is in new thread: i = 16
this is in new thread: i = 17
this is in new thread: i = 18
this is in new thread: i = 19
新建线程执行结束
main线程执行完毕有几点需要注意:
- pthread_join函数的返回值为什么是一个void** 类型?作为返回值,按理来说,传入void*就足够完成传入传出参数的功能,为何多此一举?
我们先来使用一个正确的例子,来看看如何使用返回值,我们在main线程中创建一个线程,然后让这个线程返回字符串"hello world",然后main线程接收并打印这个字符串:
cpp#include <stdio.h> #include <pthread.h> #include <unistd.h> #include <stdlib.h> void* start_route(void* arg) { char* str = (char*)calloc (100, sizeof(char)); str[0] = '@'; str[1] = 'h'; str[2] = 'e'; str[3] = 'l'; str[4] = 'l'; str[5] = 'o'; str[6] = ' '; str[7] = 'w'; str[8] = 'o'; str[9] = 'r'; str[10] = 'l'; str[11] = 'd'; return str; } int main() { pthread_t t1; char* str = NULL; pthread_create(&t1, NULL, start_route, NULL); pthread_join(t1, (void**)&str); printf("main: %s\n", str); return 0; }输出:
cppdes@des-virtual-machine:~/test2$ ./pthread_join_retval main: @hello world正常输出。那为何不用一级指针?我们来思考一下:
- 第一,pthread_join这个函数设计是具有通用性的,所谓通用性就是设计这个函数的人,肯定不希望他只能传递一种数据类型的返回值。所以为了通用性,肯定有限是传递的通用指针类型,也就是void*或者void**。
- 其次,如何从void*和void**中做出抉择?先来假设pthread_join如果是void*类型,我们需要注意些什么?
- a. 传入的事void*,那么要达到传入传出参数方式的返回值的效果,就必须修改void*指向的内存空间的值来完成返回值传递,那么关键的一步就是,通用指针类型的直接访问是c语言的未定义行为,简而言之就是,你如何知道这个void*所指向的内存大小是多少?所以必须还要新增一个参数来表示大小。
- b. 其次假如这个传入的是野指针,你该如何处理?其子线程中根本就无法判断是否为野指针,最多判NULL。
- 综上,选择二级指针是明智的,二级指针可以直接把main线程中的传入的一级指针的指向改为线程返回的内存空间,从而避免两边数据空间大小的不确定性。
- 如果调用者调用pthread_join的时候,传入了一个已经被join了的线程,将会触发未定义行为。
比如main线程调用pthread_join连接了ID为1000的线程,此后main再次连接这个ID为1000的线程,但是这个线程可能在第二次join的时候已经被回收了(被回收之后ID也会被回收然后给其他线程使用),此时join的并非原来的那个线程。
- 连接也不是任意的,是有限制的,如果随意连接,那么将会发生不安全和未定义行为。比如某个线程去连接由库函数私自创建的线程。
线程应该尽量连接他们所"熟悉"的线程。
分离(detach)
既然有连接,让一个线程的执行结果和顺序和一个线程深度绑定,那么肯定也可以解绑,正如所言,posixc提供了分离的方法,其函数声明如下:
cpp
#include <pthread.h>
int pthread_detach(pthread_t thread);依旧,只有一个类型为pthread_t的入参,指明一个线程ID为thread的线程。成功返回0,否则返回错误码。
默认情况,线程是可连接的,线程退出时,可以使用pthread_join来获取其返回状态。但是并不是所有的线程都需要关注其返回状态,比如有一些清理线程,我只需要他从头到尾执行清理函数即可,无需什么返回值,此时就可以将这个线程分离,让其在结束的时候由操作系统回收其内核数据。
线程分离的时机:
- 在pthread_create函数中的属性选项中指定初始状态为分离状态。
- 一个线程在创建另外一个线程之后,立马调用pthread_detach函数将其分离。
- 一个线程被创建之后,在其内部先使用pthread_self获取自身的线程ID,然后调用pthread_detach自己分离自己。
线程刚开始是可连接的,但是也是可分离的,也就是说一个线程刚被创建得时候,可以被join,也可以被detach,但是二者只能选其一,join之后就不能detach了,同理detach之后就不能重新join了。
但是需要注意的是,即使是分离,依旧会收到main线程的影响,main线程执行return语句,或者main线程调用pthread_exit函数,再或者main线程异常结束,都会导致整个进程结束,当然也包括被分离的线程。