利用已经训练好的模型,然后给他输入,对外应用
python
from PIL import Image
import os
import torchvision.transforms as transforms
from model1 import *
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
image_path="E:\desktop\deeplearning\imgs\plane.png"
image=Image.open(image_path)
image=image.convert("RGB")#确保是3通道图像
transformer=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])#组合多个变换操作
image=transformer(image)#对图像进行变换
image = image.to(device)
print(image.size())#打印变换后图像的尺寸 3通道32x
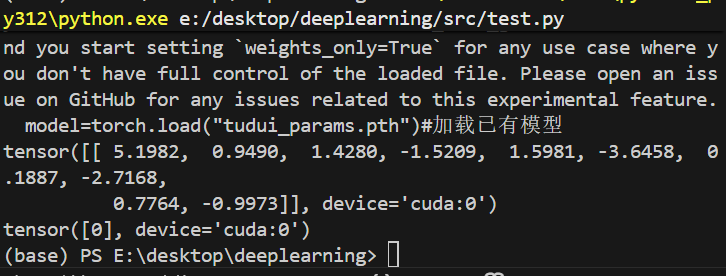
model=torch.load("tudui_params.pth")#加载已有模型
model=model.to(device)#将模型移动到GPU上
output=model(image.unsqueeze(0))#增加一个batch维度 变成1x3x32x32 遗忘batch维度会报错
model.eval()#进入评估模式
with torch.no_grad():
output=model(image.unsqueeze(0))
print(output)#打印输出结果
print(output.argmax(1))#打印分类结果 0-9之间的数字输出