一、基础设施层是什么?为什么重要?
1、定义:
基础设施层是为领域层和应用层提供技术能力支持的"适配器"和"实现者"。
它是技术实现的细节层,为其他层(特别是领域层和应用层)提供技术支持和解耦。它扮演着"支撑"和"实现"的角色,而不是"决定"和"定义"角色。领域层只定义接口,由基础设施层来进行实现。
2、核心价值:
让业务代码保持纯净,技术细节可替换:领域层只管定义一个接口来调用,不管基础设施层是怎么实现的
3、常见痛点:
- 业务逻辑里混着SQL
- 换数据库要重写代码
- 单元测试难做
其实:现在谁家好人,还在业务逻辑里混写SQL啊,真正的解决的痛点应该是后面两条。
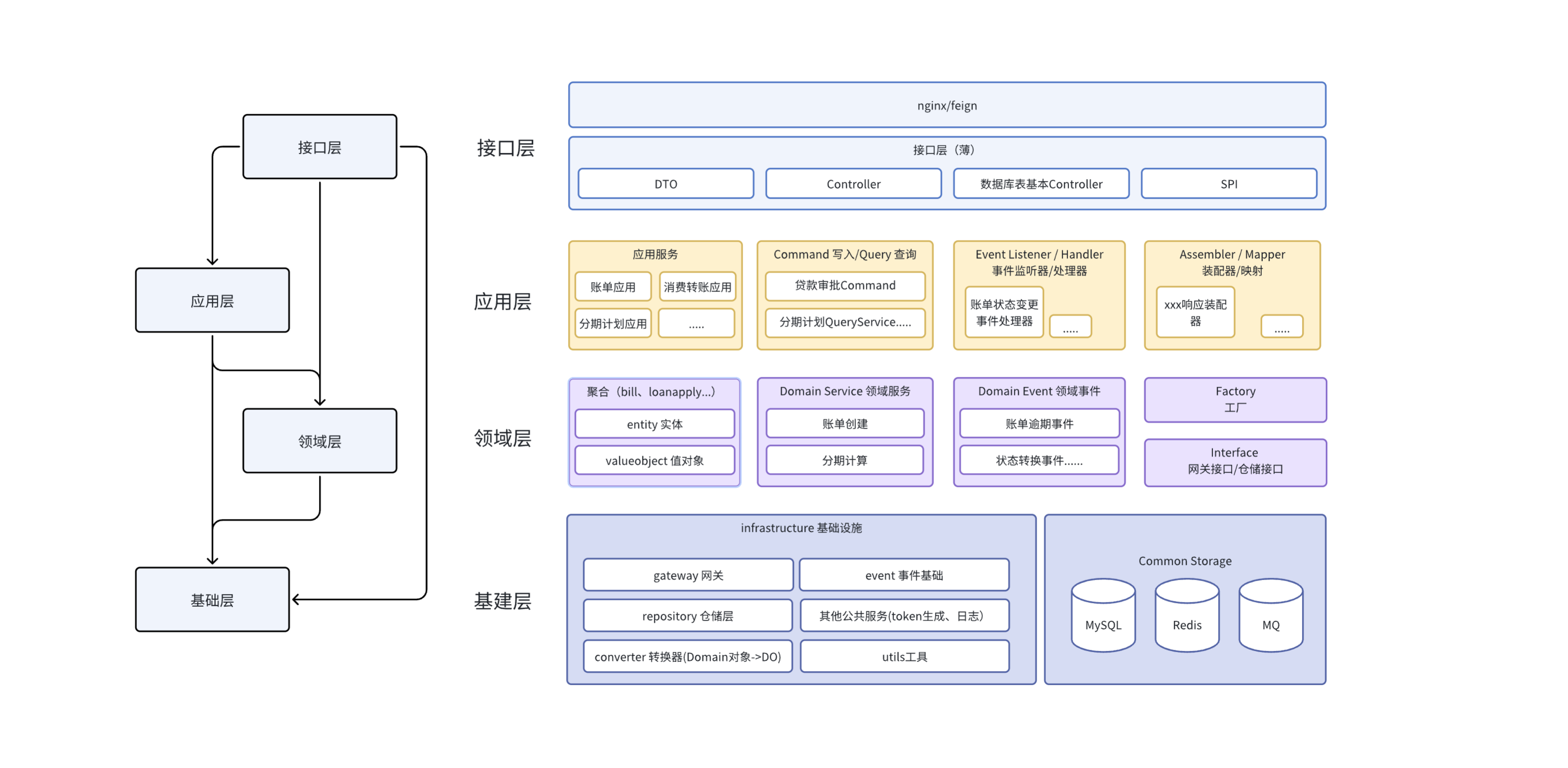
基础设施层示意图:
由高层定义接口,基础设施层来实现:
- 仓储Repository:对数据库的操作
- 网关Gateway、Email等:调用第三方API的下单、发送短信等功能
- DateTimeProvider、FileStorage:调用系统功能,获取当前时间、时区、环境变量,操作文件等等
.
二、基础设施层做什么
基础设施层是技术实现细节的集散地,是领域模型与外部世界(数据库、第三方服务、框架等)的连接器。它确保领域层和应用层可以专注于业务,而无需被技术细节所污染。
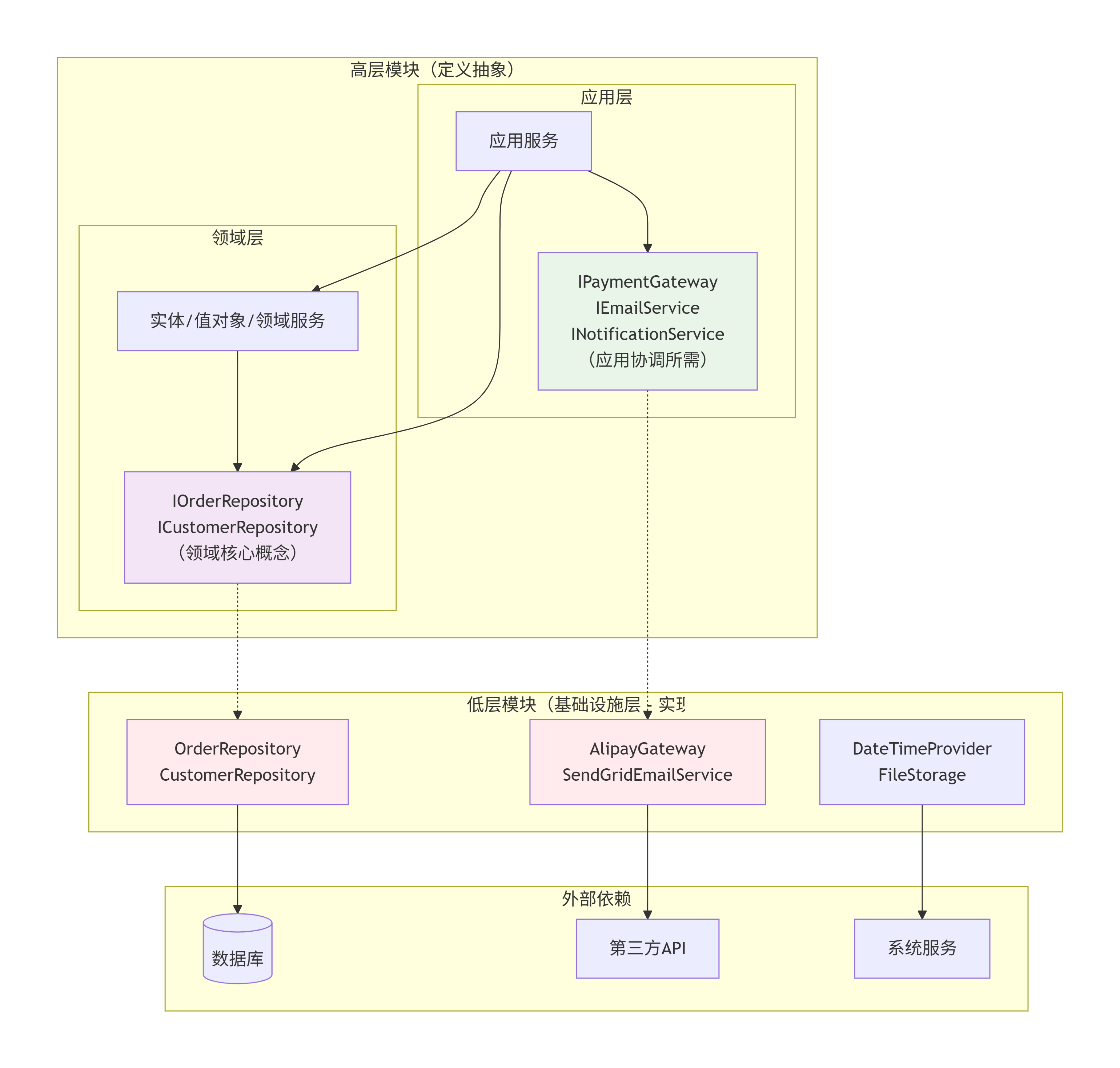
1. 实现持久化(Repository仓储)
- 核心工作:负责将领域实体(Entity)和聚合根(Aggregate Root)持久化到数据库(如MySQL、PostgreSQL、MongoDB)中,以及如何从数据库中将它们重建出来。
- 关键点 :仓储接口定义在领域层 ,但实现在基础设施层 。这严格遵循了依赖倒置原则(DIP),使领域层不依赖于具体的数据技术。
- 具体案例 :
- 领域层有一个
IOrderRepository接口,定义了save(Order order)和findById(OrderId id)等方法。 - 基础设施层会创建一个
JpaOrderRepository类,使用 JPA/Hibernate 编写具体的save和findById实现,里面包含将Order对象映射为数据库表记录的SQL或ORM操作。 - 重建聚合根 是一个精细活:基础设施层需要从多个数据库表中查询数据(如订单主表、订单项表),然后正确地重新组装成内存中一个完整的、保证业务不变性(Invariants)的
Order聚合对象。
- 领域层有一个
2. 调用外部服务
- 当应用需要与外部系统交互时(如调用另一个微服务的API、发送邮件、调用支付网关、使用消息队列等),这些通信的具体实现放在基础设施层。
- 它封装了HTTP客户端(如Feign、RestTemplate)、消息队列生产者/消费者(如Kafka Template)、SMTP客户端、文件存储SDK等所有"脏活累活"。
- 具体案例 :
- 应用层需要调用"支付服务",领域层或应用层定义了
IPaymentService接口。 - 基础设施层实现
AlipayPaymentService,内部封装了调用支付宝API的所有细节:组装请求参数、签名、处理HTTP调用、解析响应、将网络异常转换为领域友好的异常等。
- 应用层需要调用"支付服务",领域层或应用层定义了
3. 提供框架和公用技术组件
- 为整个应用程序提供基础技术框架支持。
- 常见组件 :
- 事件发布器 :实现领域层定义的
DomainEventPublisher接口,底层可能是 SpringApplicationEventPublisher或 Kafka。 - 缓存客户端:对 Redis、Memcached 等缓存操作的具体封装。
- 文件存储服务:对接 AWS S3、阿里云OSS 的具体实现。
- 身份认证与授权适配器:与 Spring Security、OAuth2 服务器集成的代码。
- 事件发布器 :实现领域层定义的
4. 实现领域层定义的接口(依赖倒置的体现)
- 这是DDD中非常关键的一点。高层模块(领域层)定义抽象,低层模块(基础设施层)实现抽象。
- 这不仅适用于仓储,也适用于任何需要外部协作的领域服务接口 (Domain Service)或网关接口(Gateway)。
- 意义 :这使得我们可以轻松地替换技术实现,而不影响核心业务逻辑。例如,为了测试,你可以用一个
InMemoryOrderRepository替换掉基于数据库的仓储;为了更换云服务商,你可以实现一个新的TencentCloudFileService。
.
三、基础设施层不做什么
明确基础设施层的边界,是保持架构整洁、核心业务逻辑不被腐蚀的关键。
1. 不包含任何业务逻辑(Business Logic)
- 最重要的红线。业务逻辑(规则、计算、决策)只属于领域层。
- 基础设施层的代码应该是"机械性的"、"技术性的",只关心 "如何做" (How),而不关心 "做什么" (What)和 "为什么做"(Why)。
- 一个鲜明的对比 :
- 领域层逻辑 :
订单.总金额 = 计算所有订单项金额之和 - 可用折扣。这是业务规则。 - 基础设施层逻辑 :
将"订单.总金额"这个数值,通过JDBC的PreparedStatement,安全地插入到orders表的total_amount列中。这是技术实现。
- 领域层逻辑 :
- 常见反例 :
- 在数据库的存储过程或触发器中编写复杂的业务规则校验(如"只有VIP用户才能下单购买奢侈品")。
- 在ORM的实体类 (如JPA的
@Entity)中添加带有业务判断的@PrePersist方法。 - 在消息队列的消费者 代码里,直接写满屏的
if...else业务判断来处理消息。
2. 不决定应用程序流程
- 应用程序的流程和协调工作("先验证用户权限,再创建订单,然后扣减库存,最后发布订单创建事件")是应用层(Application Layer) 的职责。
- 基础设施层提供的服务(如仓储、外部API客户端),就像是工具箱里的工具 。应用服务是那个知道在什么场景下、按什么顺序使用这些工具的"工匠"或"协调者"。
- 反例 :在一个
MessageListener类里,不仅处理了消息反序列化(技术),还直接编排了调用多个仓储和服务来完成一个完整的"用户注册"用例(业务)。
总结与比喻
你可以把整个DDD架构想象成一家现代化餐厅:
- 领域层 :是后厨的核心团队(大厨、副厨),他们精通食材(实体)和烹饪秘籍(业务逻辑),负责制作出一道道美味佳肴(聚合根/领域服务)。
- 应用层 :是餐厅经理和服务员,他们接收顾客点单(用例/请求),协调后厨做菜、酒水台调酒、收银台结账,确保整个用餐流程顺畅。
- 基础设施层 :是整个餐厅的支撑系统 :仓库 (数据库仓储)、采购货车 (外部服务调用)、灶台和烤箱 (框架技术组件)、送餐机器人(消息通信)。它们不决定菜怎么做,但为制作和传递菜品提供了必不可少的、专业的技术实现。
.
四、基础设施层的核心原则:依赖倒置
1、依赖倒置原则的定义
核心思想
高层模块(领域层)不应依赖低层模块(基础设施层),二者都应依赖抽象接口。
抽象(接口)不应依赖细节(具体实现),细节应依赖抽象。
与传统分层架构的区别
传统架构中,领域层依赖基础设施层(如数据库操作),导致业务逻辑与技术实现强耦合。
依赖倒置后,基础设施层需实现领域层定义的抽象接口(如仓储接口),领域层通过接口调用技术能力
如何理解呢,举例:
想象领域层是"老板",基础设施层是"秘书"。
传统模式 :老板需要自己联系快递公司(直接调用数据库API)------老板依赖秘书的具体能力。
依赖倒置后 :老板只对秘书说:"把这份文件发出去"(调用接口),至于秘书用顺丰还是中通、圆通(MySQL或MongoDB),由秘书自己决定。
结果:老板不用关心快递细节,换快递公司时老板的工作流程完全不变。
2、依赖倒置伪代码
场景:保存订单
反例:领域层直接依赖数据库(经典实现模式)
java
// ❌ 领域层代码(直接依赖具体数据库)
class OrderService {
private MySQLDatabase db; // 直接依赖具体实现
void createOrder(Order order) {
db.execute("INSERT INTO orders..."); // SQL侵入业务逻辑
// 业务规则与技术细节混杂
}
}问题:
- 换数据库需修改所有业务代码
- 无法单独测试业务逻辑(需启动真实数据库)
正例:通过接口解耦(遵循依赖倒置)
java
// ✅ 1. 领域层定义抽象接口(老板提需求)
interface OrderRepository {
void save(Order order);
}
// ✅ 2. 领域服务仅依赖接口
class OrderService {
private OrderRepository repository; // 依赖抽象
void createOrder(Order order) {
// 纯业务逻辑
if (order.isValid()) {
repository.save(order); // 调用接口方法
}
}
}
// ✅ 3. 基础设施层实现接口(秘书干活)
class MySQLOrderRepository implements OrderRepository {
void save(Order order) {
db.execute("INSERT INTO orders..."); // 技术细节在此实现
}
}
class MongoOrderRepository implements OrderRepository {
void save(Order order) {
collection.insert(order.toDocument()); // 切换数据库只需新增实现
}
}
// ✅ 4. 依赖注入:运行时绑定实现
// (Spring/TypeDI等框架示例)
@Inject
OrderService service = new OrderService(new MySQLOrderRepository()); 3、依赖倒置的对比解释
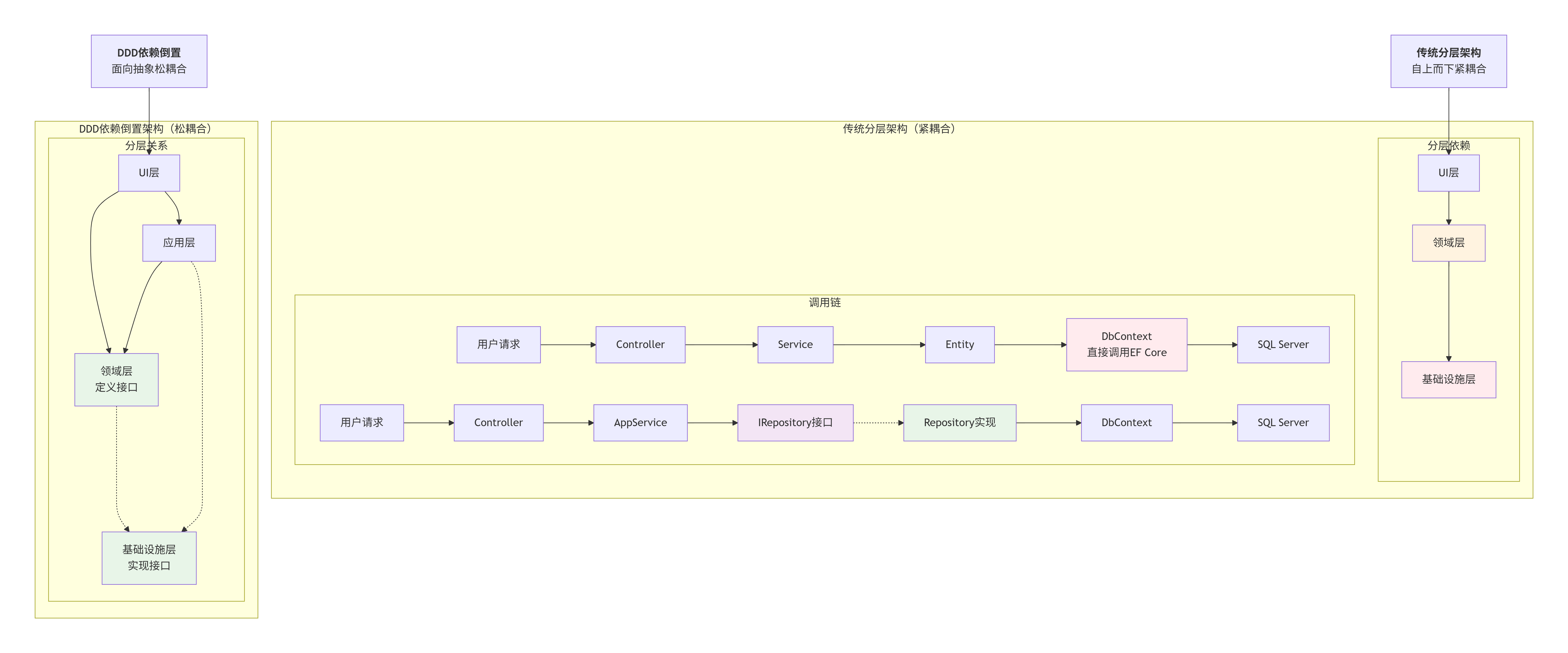
这张图里可以看到传统分层架构,是一种紧密的耦合关系。
而DDD中的领域层和基础设施层之间,不是紧密的耦合关系,是虚线
疑问 :
怎么理解这里的解耦呢?
不管是依赖倒置,还是传统分层架构里的调用链。都是由上层发起,然后由底层数据库层来实现。上层无法脱离底层啊。DDD的应用层和领域层也无法离开或者脱离于基础设施层啊。这个解耦的好像不明显?
答案 :
确实,无论哪种架构,上层最终都需要底层执行。但"解耦"的关键不是"不用",而是"怎么用"。让我用一个现实比喻来解释这个重要区别。
现实世界比喻 :开手动挡车 vs 开自动挡车
传统架构:开手动挡
bash
司机(业务层) → 直接操作:
1. 踩离合 → 机械连杆 → 离合片
2. 挂挡 → 变速箱齿轮直接啮合
3. 踩油门 → 拉线 → 化油器
问题:
- 司机需要理解车辆的机械原理
- 司机如果不知道什么时候该踩离合,配合换挡,他就开不好车
- 改装变速箱类型需要司机重新适应换挡逻辑依赖倒置架构:开自动挡车
bash
司机(业务层) → 统一接口:
1. 踩油门 → 电子信号 → ECU → 控制执行器
2. 刹车 → 电子信号 → ABS系统 → 刹车分泵
优势:
- 司机只需知道"油门、刹车、方向盘"
- 司机不需要什么时候踩离合,不需要知道什么时候换什么档
- 从汽油车换电动车:接口不变,司机操作不变
- 不管换什么类型的变速箱:司机完全无感知关键差异:不是司机不需要车,而是司机不需要知道车的内部构造。
所以这里就能解释上面说的上层依然要依赖底层,但是还是实现了解耦的问题
上层的应用层、领域层不需要知道基础设施层是怎么实现的,它只需要定义好"加速"、"刹车"、"转向"三个接口,由底层去实现,上层只管什么时候调用即可
.
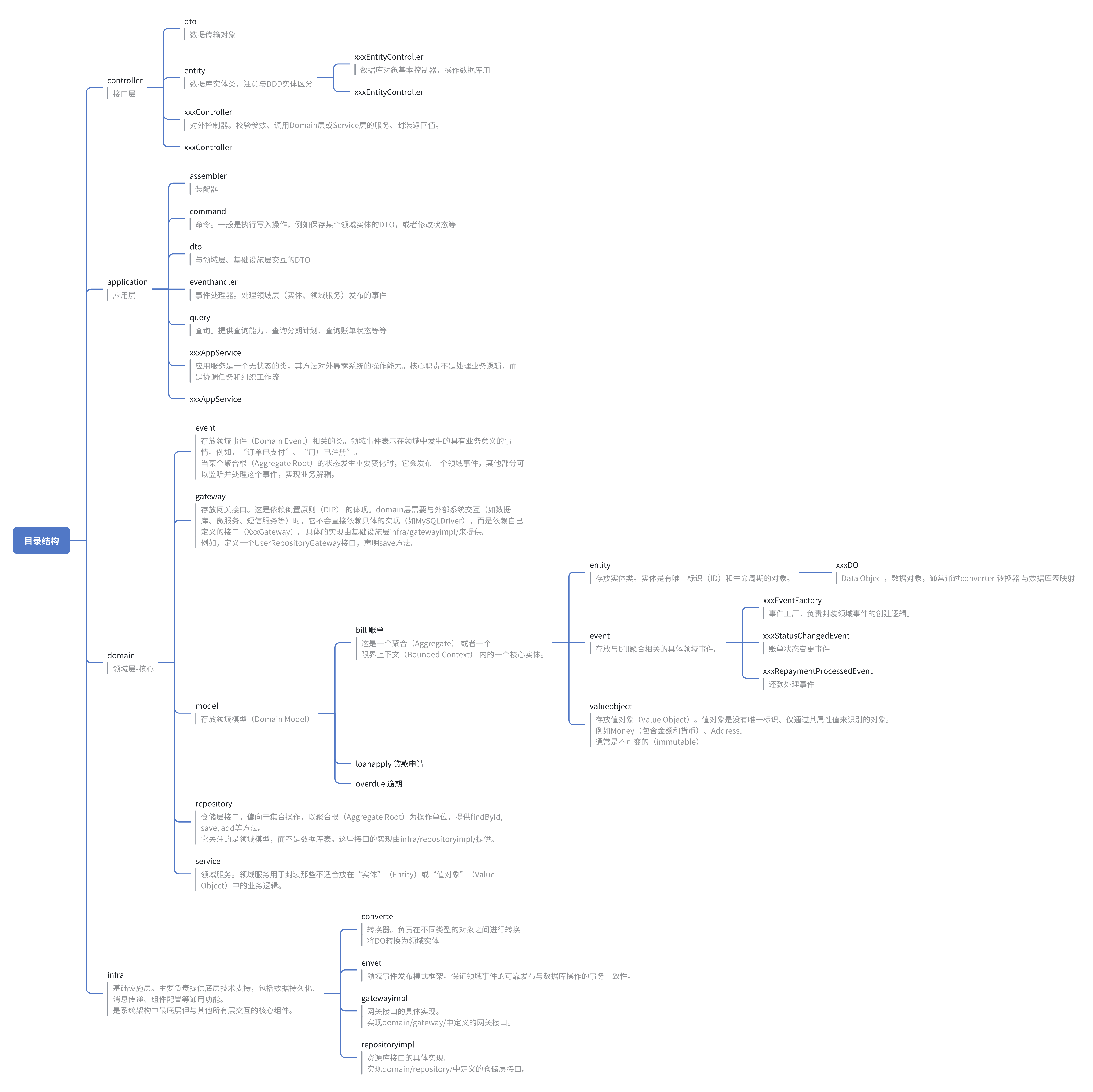
五、项目目录结构参考
项目中,目录的结构参考图: