一、什么是 Checkpoint?
Checkpoint 是 InnoDB 在运行过程中记录的一个"一致性点",表示:在此 LSN(Log Sequence Number)之前的所有修改都已持久化到磁盘数据文件中。这意味着,崩溃恢复时只需从该 LSN 开始重放 Redo Log,而无需回溯整个日志历史。
核心目的:
- 释放 Redo Log 空间:避免日志文件无限增长。
- 控制恢复时间:确保崩溃后恢复过程在可接受范围内。
- 协调 Buffer Pool 与磁盘 I/O:平衡内存缓存与持久化之间的延迟。
二、Checkpoint 的类型
InnoDB 实现了多种 Checkpoint 类型,主要分为两类:
| 类型 | 别名 | 触发场景 | 特点 |
|---|---|---|---|
| Sharp Checkpoint | 同步检查点 | 关闭数据库、日志切换(旧版本)、innodb_fast_shutdown=0 |
强制刷出所有脏页,LSN 推进至最新,恢复快但 I/O 压力大 |
| Fuzzy Checkpoint | 异步/后台检查点 | 正常运行期间(MySQL 8.0 默认) | 仅刷部分脏页,LSN 渐进推进,I/O 平滑,恢复时间略长 |
注意:自 MySQL 5.6 起,Sharp Checkpoint 已基本被弃用(除 shutdown 场景),日常运行均使用 Fuzzy Checkpoint。
Fuzzy Checkpoint 又可细分为:
- Background Checkpoint:由后台线程周期性触发。
- Flush List Checkpoint:当 Redo Log 空间不足时,强制推进 Checkpoint 以回收日志空间。
三、Checkpoint 的工作机制
Checkpoint 的核心是 推进 last_checkpoint_lsn ,使其尽可能接近当前的 log_lsn。其流程如下:
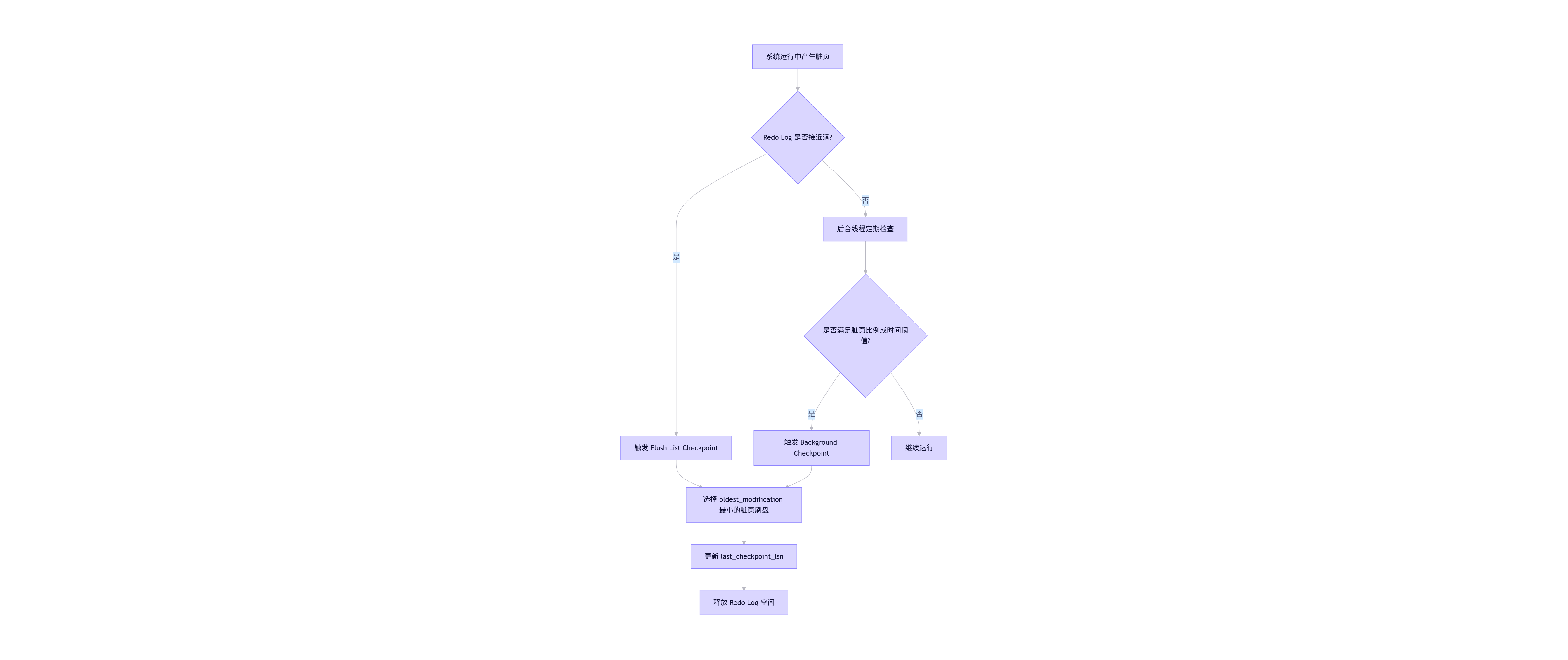
关键概念说明:
- LSN(Log Sequence Number):全局递增的日志序列号,标识 Redo Log 的位置。
- oldest_modification:每个脏页记录的最早被修改的 LSN。
- Checkpoint Age =
current_lsn - last_checkpoint_lsn,反映未持久化的日志量。
当 Checkpoint Age 接近 innodb_log_file_size * innodb_log_files_in_group 时,InnoDB 会强制刷脏页以推进 Checkpoint,防止 Redo Log 被覆盖。
关键参数解释
1. innodb_max_dirty_pages_pct
- 作用 :控制 Buffer Pool 中脏页占比的上限阈值(百分比)。
- 默认值(MySQL 8.0) :
90.00(即 90%) - 触发行为 :当脏页比例 ≥ 此值时,InnoDB 的后台刷新线程(如 page cleaner)会加速刷脏页,以防止脏页堆积过多。
- 注意 :这是一个软限制,InnoDB 会尽量维持脏页比例低于该值,但不保证绝对不超。
示例:若设为
75,则当 Buffer Pool 中超过 75% 的页是脏页时,系统会更积极地刷盘。
2. innodb_max_dirty_pages_pct_lwm(Low Water Mark)
- 作用 :脏页比例的下限恢复阈值。
- 默认值 :
10.00 - 工作机制 :
- 当脏页比例 高于
innodb_max_dirty_pages_pct→ 刷脏加速; - 当脏页比例 回落到低于
innodb_max_dirty_pages_pct_lwm→ 刷脏速度恢复正常。
- 当脏页比例 高于
- 目的 :避免刷脏速率频繁震荡,提供迟滞(hysteresis)控制,使 I/O 更平稳。
💡 类比:就像空调的温控------高温启动制冷,但要等温度明显低于设定值才停机,防止频繁启停。
四、关键配置参数及其影响
| 参数 | 默认值(MySQL 8.0) | 作用 | 调优建议 |
|---|---|---|---|
innodb_max_dirty_pages_pct |
90 | Buffer Pool 中脏页占比上限 | 高写负载下可降低至 50--75,避免突发刷盘 |
innodb_io_capacity |
200 | 磁盘 I/O 能力基准 | SSD 建议设为 2000+,提升刷盘效率 |
innodb_io_capacity_max |
2×innodb_io_capacity |
背压下的最大 I/O 速率 | 可设为 innodb_io_capacity 的 2--4 倍 |
innodb_log_file_size |
48MB(旧版)~128MB+(8.0) | 单个 Redo Log 文件大小 | 建议 1--4GB(需权衡恢复时间与空间) |
innodb_adaptive_flushing |
ON | 自适应刷脏页 | 保持开启,让 InnoDB 动态调整刷盘速率 |
提示:增大
innodb_log_file_size可减少 Checkpoint 频率,但会延长崩溃恢复时间。建议通过SHOW ENGINE INNODB STATUS监控Log sequence number与Last checkpoint at的差值。
五、Checkpoint 对系统的影响
正面影响
- 保障 Redo Log 可循环使用。
- 控制 Buffer Pool 内存压力。
- 使崩溃恢复时间可预测。
潜在问题
- I/O 突刺:若脏页堆积过多,Checkpoint 触发时可能造成 I/O 飙升。
- 吞吐下降:刷脏页占用 I/O 带宽,影响用户查询性能。
- 恢复时间过长:Redo Log 过大 + Checkpoint 推进慢 → 恢复耗时增加。
调优建议
- 监控 Checkpoint Age:理想值应小于 Redo Log 总容量的 75%。
- 使用高速存储:NVMe SSD 可显著缓解刷盘压力。
- 避免大事务:大事务会延迟 oldest_modification,阻碍 Checkpoint 推进。
- 启用
innodb_flush_neighbors=0(SSD 场景):避免无关页刷盘。
六、面试题
Q1:Checkpoint 和 Redo Log 有什么关系?
A:Checkpoint 决定了 Redo Log 可被覆盖的起点。只有 Checkpoint 之前的日志才能安全回收。
Q2:为什么 MySQL 8.0 默认使用 Fuzzy Checkpoint?
A:Sharp Checkpoint 会导致全量刷脏页,I/O 压力大;Fuzzy Checkpoint 渐进刷盘,更适合在线服务。
Q3:如何判断系统是否因 Checkpoint 导致性能抖动?
A:观察
SHOW ENGINE INNODB STATUS中的BUFFER POOL AND MEMORY部分,若Modified db pages持续高位,且Log sequence number - Last checkpoint at接近 Redo Log 容量上限,则可能触发强制刷盘。
Q4:增大 innodb_log_file_size 一定能提升性能吗?
A:不一定。虽然可减少 Checkpoint 频率,但会延长崩溃恢复时间,且首次启动需重建日志文件。需综合评估 RTO(恢复时间目标)。
Q5:什么是 "Async/Sync Flush"?何时发生?
A:当 Redo Log 空间使用超过 76%(Async)或 90%(Sync)时,InnoDB 会分别触发异步或同步刷脏页以推进 Checkpoint。Sync Flush 会阻塞用户线程,应尽量避免。