提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
- 一、关键前置知识
-
- [1. UTF-8 BOM 定义](#1. UTF-8 BOM 定义)
- [2. MSVC 源文件解码优先级(官方既定规则)](#2. MSVC 源文件解码优先级(官方既定规则))
- [3. 固定测试环境](#3. 固定测试环境)
- 二、逐场景解析(对应你的4组测试)
- [三、无BOM vs 带BOM UTF-8 全场景对比表](#三、无BOM vs 带BOM UTF-8 全场景对比表)
- 四、补充重要说明
-
- [1. 关于"编译器优化"的精准修正](#1. 关于“编译器优化”的精准修正)
- [2. 编译器兼容性提醒](#2. 编译器兼容性提醒)
- [3. 最佳实践建议](#3. 最佳实践建议)
- 五、总结
我现在把源文件编码改为带bom的utf-8接着继续用上面四种场景测试,测试结果出现了几个与我预想不一样的,你帮我分析下
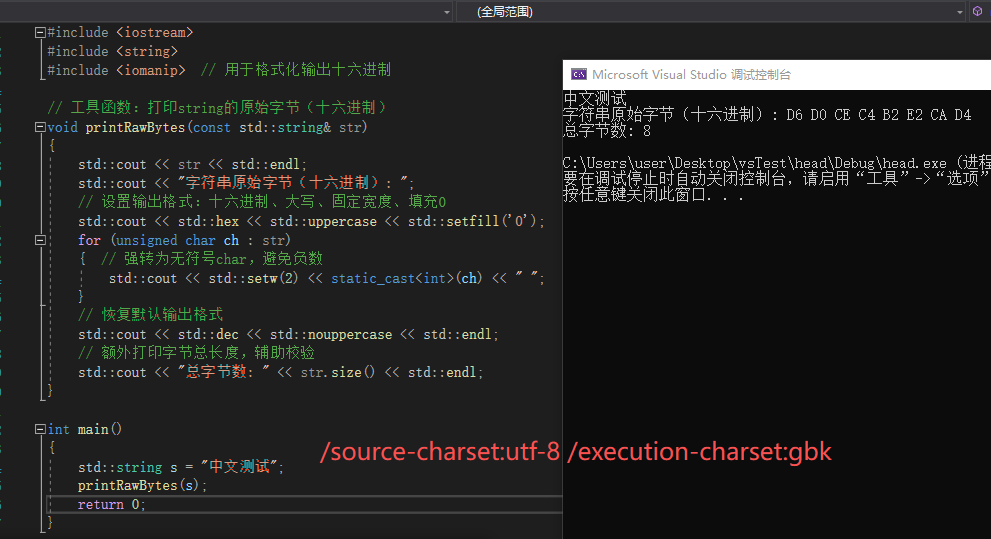
源字符集为utf-8,执行字符集为gbk时,全部正确输出,这完全合理
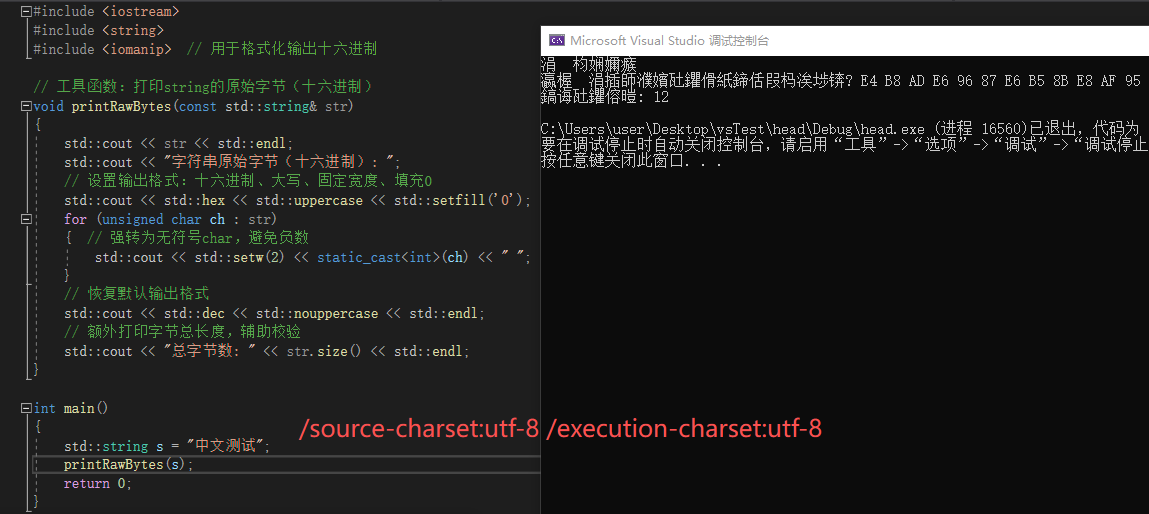
源字符集为utf-8,执行字符集为utf-8时,输出虽然乱码,但也只是输出编码与存储编码不一致导致,合理
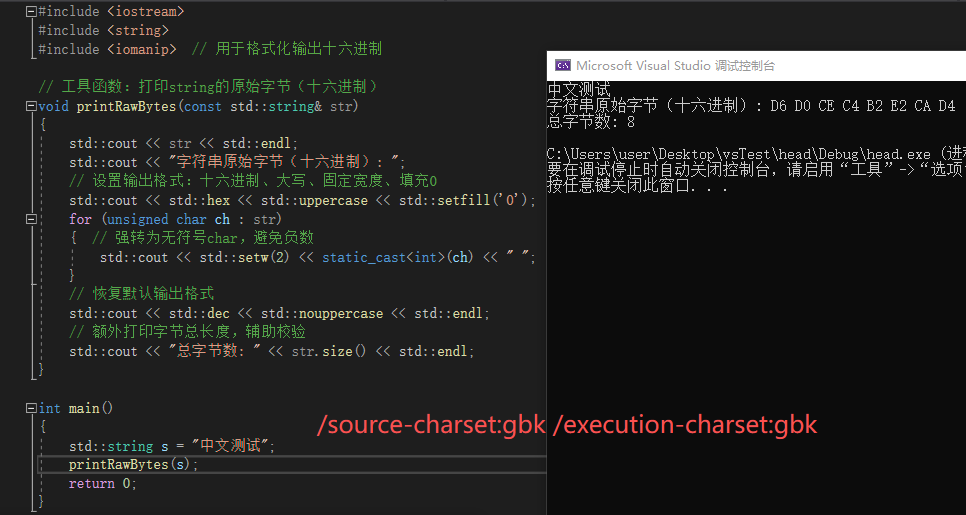
源字符集为gbk,执行字符集为gbk时,这里全部正确输出是怎么回事,不是应该像上面一样错进错出最终得到utf-8字节序列然后乱码吗,这里根据这个结果我推测可能是带bom的utf-8文件会自己优化源字符集,且优先级高于项目设定的/source-charset,是这样吗,我需要你的帮助
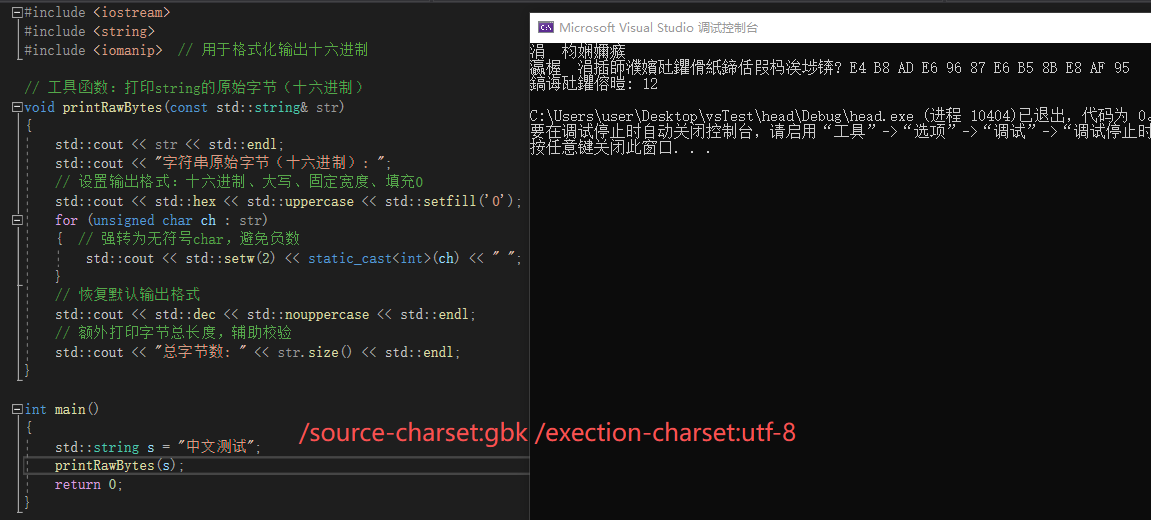
源字符集为gbk,执行字符集为utf-8时,结果也并不是一个错误,而是仅乱码,输出的字节序列也是utf-8的字节序列,如果按照带bom的utf-8文件编译器会自己优化源字符集,且优先级高于项目设定也解释的通,现在需要你给我一个肯定答案
结合你的测试结果和推测,我先给你肯定的核心结论 :
你的推测完全正确! 在你使用的 MSVC 编译器(Visual Studio,Windows 平台主流编译器) 中,带 BOM 的 UTF-8 源文件会触发编译器的编码自动识别逻辑,UTF-8 BOM 的优先级远高于手动指定的 /source-charset:gbk 编译选项 ,编译器会强制以 UTF-8 解码源文件,直接忽略你配置的 GBK 源字符集参数------这就是测试结果与无 BOM 场景完全不同的根本原因。
一、关键前置知识
1. UTF-8 BOM 定义
UTF-8 BOM 是文件开头的3个字节签名 EF BB BF,作用是显式标记文件编码为 UTF-8,主要为兼容 Windows 平台的文本编辑器/编译器。
2. MSVC 源文件解码优先级(官方既定规则)
这是解释所有现象的核心规则,优先级从高到低:
- 最高优先级 :源文件携带 UTF-8 BOM 签名 → 强制以
UTF-8解码,无视/source-charset手动配置; - 次优先级:命令行参数
/source-charset:xxx指定的编码; - 最低优先级:系统默认编码(中文 Windows 为 GBK/ACP)。
3. 固定测试环境
- 源文件:带 BOM 的 UTF-8
- 控制台解码:GBK
- 编译器:MSVC(Visual Studio)
- 核心参数:
/source-charset(源字符集,编译器读取文件的解码方式)、/execution-charset(执行字符集,字符串编译后的存储编码)
二、逐场景解析(对应你的4组测试)
结合 BOM 强制覆盖规则,逐一解释结果,重点说明后两组不符合无BOM场景预期的原因:
| 测试配置 | 你观察到的结果 | 实际编码链路(BOM 强制覆盖后) | 结果合理性分析 |
|---|---|---|---|
| 1. 源字符集=UTF-8 执行字符集=GBK | 中文正常输出,字节序列为GBK | 编译器以UTF-8解码文件 → 编译为GBK字节 → 控制台GBK解码 | 全链路编码匹配,与无BOM场景一致,完全合理 |
| 2. 源字符集=UTF-8 执行字符集=UTF-8 | 中文乱码,字节为标准UTF-8 | 编译器以UTF-8解码文件 → 编译为UTF-8字节 → 控制台用GBK解码UTF-8 | 编译器处理无错误,乱码仅为终端与程序编码不兼容,与无BOM场景一致,合理 |
| 3. 源字符集=GBK(手动配置) 执行字符集=GBK | 中文正常输出(与无BOM场景的错进错出/乱码完全不同) | BOM强制覆盖:编译器以UTF-8解码文件 → 编译为GBK字节 → 控制台GBK解码 | 等价于场景1的标准匹配链路! 你配置的/source-charset:gbk被BOM完全忽略,无任何错误解码,因此不会出现错进错出,正常显示 |
| 4. 源字符集=GBK(手动配置) 执行字符集=UTF-8 | 仅乱码,字节为标准UTF-8(无无效编码) | BOM强制覆盖:编译器以UTF-8解码文件 → 编译为UTF-8字节 → 控制台用GBK解码 | 等价于场景2! 全程无编码错误,字节序列合规,乱码仅由终端编码不匹配导致,不存在"完全错误的无效字节" |
三、无BOM vs 带BOM UTF-8 全场景对比表
整合两次测试结果,直观体现 BOM 带来的核心差异:
| 分组 | 手动配置 源/执行字符集 | 源文件格式 | 编译器实际使用的源字符集 | 控制台效果 | 字节序列有效性 | 核心差异原因 |
|---|---|---|---|---|---|---|
| 1 | UTF-8 / GBK | 无BOM UTF-8 | UTF-8 | 正常 | 标准GBK | 配置与文件编码匹配,标准链路 |
| 2 | UTF-8 / GBK | 带BOM UTF-8 | UTF-8(BOM识别) | 正常 | 标准GBK | 与无BOM行为一致 |
| 3 | UTF-8 / UTF-8 | 无BOM UTF-8 | UTF-8 | 乱码 | 标准UTF-8 | 终端编码不兼容 |
| 4 | UTF-8 / UTF-8 | 带BOM UTF-8 | UTF-8(BOM识别) | 乱码 | 标准UTF-8 | 与无BOM行为一致 |
| 5 | GBK / GBK | 无BOM UTF-8 | GBK(手动配置生效) | 乱码 | 巧合还原UTF-8(错进错出) | 错误解码+错误编码,不稳定行为 |
| 6 | GBK / GBK | 带BOM UTF-8 | UTF-8(BOM强制覆盖) | 正常 | 标准GBK | 手动配置失效,编码全链路匹配 |
| 7 | GBK / UTF-8 | 无BOM UTF-8 | GBK(手动配置生效) | 乱码 | 无效乱码字节 | 双重编码错误,完全失效 |
| 8 | GBK / UTF-8 | 带BOM UTF-8 | UTF-8(BOM强制覆盖) | 乱码 | 标准UTF-8 | 手动配置失效,仅终端不兼容 |
四、补充重要说明
1. 关于"编译器优化"的精准修正
你描述的「自己优化源字符集」不够严谨,准确表述是:
编译器并未优化编码逻辑,而是严格遵循预设的优先级规则 ,BOM 作为文件自带的权威编码签名,优先级高于用户手动配置,属于编译器的标准行为,而非动态优化。
2. 编译器兼容性提醒
该优先级规则仅适用于 MSVC 编译器:
- GCC/Clang 会忽略 UTF-8 BOM ,甚至将其当作普通字符处理,导致字符串开头出现乱码,因此跨平台开发强烈建议使用无BOM的 UTF-8;
- 仅 Windows 单机开发场景可使用带 BOM 的 UTF-8 兼容编辑器识别。
3. 最佳实践建议
- Windows 平台适配 GBK 控制台:带BOM/无BOM UTF-8 源码 +
/source-charset:utf-8+/execution-charset:gbk,这是最稳定的标准方案; - 统一全链路 UTF-8:将控制台编码改为 UTF-8,全程使用 UTF-8,彻底规避编码兼容问题;
- 避免混用配置:不要手动指定与文件签名冲突的编码参数,减少不可预期行为。
五、总结
- 核心推测验证 :你关于「UTF-8 BOM 优先级高于
/source-charset配置」的判断完全正确,这是 MSVC 的官方标准行为; - 后两组测试结果的本质 :手动配置的 GBK 源字符集被 BOM 强制覆盖,编译器实际全程使用 UTF-8 解码,因此编码链路无错误,仅表现为正常输出 或终端兼容型乱码,不再出现无BOM时的错进错出/完全失效;
- 核心结论:带 BOM 的 UTF-8 源文件会让 MSVC 忽略手动指定的源字符集参数,是 Windows 平台下保证源码编码一致性的可靠方式(仅局限于 MSVC)。