20251217_大模型的分布式训练
科普下自己,好多过程都没看懂;
这里附上另一个链接,介绍DP DDP和DeepSpeed的,讲的很好,对理解本视频会有帮助: 《动画理解Pytorch 大模型分布式训练技术 DP,DDP,DeepSpeed ZeRO技术》
01
分布式训练------大模型
- 常见的分布式加速库
- DeepSpeed
- Megatron
计算速率 = 单设备计算速率 x 设备数 x 多设备并行效率(加速比)
- 单设备计算速率 => Moore定律(设备工艺限制)+ 算法优化
- 单设备计算速率:提高方式有 混合精度、算子融合、梯度累加
- 设备数:服务器架构、通信拓扑优化
- 多设备并行效率(加速比):数据并行、模型并行、流水并行
超级计算节点
- 集群硬件体系结构
- 作业调度和资源管理
分布式训练推理框架
- 部署和训练(只要是训练) Transformer类型结构的大模型
- 提供数据并行 模型并行和流水线并行等分布式并行模式(PTT多维并行模式)
- 以集合通信和参数服务器方式进行资源整合
架构层(Pytorch) 和 开发层(Python)之间加入使能层(DeepSpeed、Megatron-LM、Huggingface)
常见的分布式加速库
- DeepSpeed
- Megatron-LM
- Colossal-AI
- BMTrain
DeepSpeed:微软开发,提高大模型训练效率和可扩展性
- 加速训练:数据并行(ZeRO系列)、模型并行(PP)、梯度累计、动态缩放、混合精度等;
- 辅助工具:分布式训练管理、内存优化和模型压缩等
- 快速迁移:通过Python Warp方式基于PyTorch来构建,直接调用完成简单迁移;
- 主要是围绕数据并行,训练中小模型,工程实现优雅
Megatron-LM:NVIDIA开发,提高大模型分布式并行训练效率和线性度
- 加速训练:综合数据并行、张量并行和流水线并行(张量并行和流水线并行 属于模型并行的一种)
- 辅助工具:强大的数据处理和Tokenizer,支持LLM和VLM等基于Transformer结构;
- 工程使用难度较高
分布式加速库 能为大模型提供多维分布式并行能力,让大模型能够在AI集群上快速训练/推理;提高模型和算力利用率,提升AI集群的线性度;
模型训练
- 混合精度
- 梯度检查
- 梯度累计
模型微调
- 全参微调
- 低参微调
- 指令微调
推理
- 量化压缩
- 推理加速
02
DeepSpeed分布式并行训练框架
- 基本概念
- 整体架构
- Zero1/2/3
- ZeRO-Offload
- ZeRO-Infinity
- 3D-Parallelism
- RLHF
https://github.com/microsoft/DeepSpeed
做的最好的还是训练
- 配置参数在ds_config.json中,通过API接口可以调用DeepSpeed训练(或推理)模型
- 核心运行时组件,负责管理、执行和优化性能;八廓数据、模型、并行优化、微调、故障检测以及Checkpoint保存和加载等
- 底层内核组件,使用C++和CUDA实现,优化计算和通信;
显存占用:
- Model States:模型本身相关且必须存储的参数
- Parameters 模型参数
- Gradients 梯度模型
- Optimizer States:Adam中 momentum和variance
- Residual States:训练中产生的
- Activation 激活值
- Temporary Buffers:临时存储
- Unusable Fragmented Memory:碎片化存储
ZeRO:Zero Redundancy Optimizer,一系列优化方法的统称
- ZeRO-DP(Data Parallel):ZeRO 1/2/3
- ZeRO-R(Reduce):Activation Checkpointing、Demory Defragmentation
- ZeRO-Offload:Offload Strategy && Offload Schedule
- ZeRO-Infinity:Breaking the GPU Memory Wall for Extreme Scale Deep learning(NVMe固态硬盘扩展)
ZeRO-DP(Data Parallel)
- Optimizer state partitioning(ZeRO stage 1):只对
优化器的状态(显存占用的大头)进行切分,占用内存为原始的1/4; - Gradient partitioning(ZeRO stage2):对
优化器和梯度进行气氛,占用原始内存的1/8; - Parameter partitioning(ZeRO stage3):对
优化器状态、梯度以及模型参数进行切分,内存减少与数据并行度和复杂度成线性,同时通信容量是数据并行性的1.5倍(用通信去换内存);
https://github.com/chenzomi12/DeepLearningSystem
https://github.com/Infrasys-AI/AISystem
ZeRO-1:对优化器状态进行分片
- Batch数据分到每张卡上
- 优化器状态/GPU
- 计算梯度/GPU
- 梯度/GPU
=>实际做的是scatter-reduce,减少通信(替换 梯度=>All-reduce【通信】)
- 梯度/GPU
- 更新权重/GPU
- 权重/GPU
=>All-Gather【通信】
- 权重/GPU
ZeRO-2:对优化器状态和梯度进行分片
- Batch数据分到每张卡上
- 优化器状态/GPU
- 计算梯度/GPU
- 梯度/GPU
=>scatter-reduce,梯度参数更新后马上释放
- 梯度/GPU
- 更新权重/GPU
- 权重/GPU
=>All-Gather【通信】
- 权重/GPU
ZeRO-3:对优化器状态、梯度和模型参数进行分片
- Batch数据分到每张卡上
- 优化器状态/GPU
- 计算梯度/GPU
- Forward计算,对Wn执行all-gather 取回分布在各个NPU上的权重得到完整的W,并把不属于自身的权重Wothers抛弃
- Backward计算,对Wn执行All-Gather,取回完整W,并把不属于自身的权重Wothers抛弃
- Backward后,得到各自梯度Gn,执行Reduce-Scatter,从其他NPU聚合自身维护的梯度,结束后,立刻把 不是自身维护的G抛弃
- 每个NPU只保存其权重参数Wn,由于只维护部分参数Wn,无需对Wn进行All-Reduce
- 更新权重/GPU
- 拆分到forward & backward过程,通过broadcast从其他NPU中获取参数
- 通过增加通信开销,减少每张NPU中的显存占用,用通信换显存
ZeRO3只是形式上的模型并行,实际上还是数据并行;
- 张量并行:相同输入,每个NPU上各计算模型的一部分,NPU只需维护独立的Wn;
- ZeRO并行:前向和反向过程,需要把NPU上维护的Wn进行聚合,本质使用完整W进行计算;
ZeRO-Offload:内存扩展显存
- 把占用显存多的部分卸载到CPU上,计算和激活值放到NPU上,相比于跨机器,更能节省内存,也能减少通信压力;
- 高计算:forward & backward,权重参数计算 & 激活值计算
- 低计算:update计算量低,以通信为主且耗显存,如Optimizer States Update和 Gradients Updates;
DeepSpeed的使用方式
- 方式1:使用DeepSpeed命令行工具运行训练脚本
- 方式2:Huggingface中Transformers库,通过Trainer集成Accelerator以及DeepSpeed
py
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=data_collator,
optimizer=optimizer
)
sh
deepspeed --hostfile=hostfile --master_port 60000 --include="node1:0,1,2,3@node2:0,1,2,3" run.py \
--deepspeed ds_config.json04
Megatron-LM
https://github.com/NVIDIA/Megatron-LM
- Megatron-LM
- Reducing Activation Recomputation
- HFU:算力利用力较高
- PTD:多维并行 减少网络发送字节数
- MFU:模型利用率
PTD:数据并行、张量并行(模型并行的一种)、流水并行(按照模型layer层切分到不同设备,即层间并行)
torchrun 启动训练脚本,常用
启动参数
- nnodes:节点的数量,通常一个节点对应一个主机
- node_rank:节点的序号,从0开始
- nproc_per_node:一个节点中进程/显卡的数量
- master_addr:master节点的ip地址,也就是0号主机的IP地址,该参数是为了让其他节点知道0号主机的位置,好将自己的训练参数传送过去
- master_port:节点port号
- 不同节点上的master_addr和master_port设置时一样的,用来进行通信
PTD:
- TP:张量并行
- DP:数据并行
- PP:流水并行 pipline P
- SP:序列并行
千卡、万卡级别的训练
这里补充一个理解:流水线并行 和 张量并行(涉及行列切分) 都属于模型并行,其中Pipeline并行属于层间并行,Tensor并行输入层内并行;
08
大模型的整体配置:
- h: hidden size
- n: number of attention heads
- p: number of model parallel partitions
- np: n/p(attention heads/mp)
- hp: h/p(hidden size/mp)
- hn: h/n(hidden size/attention heads)
- b: batch size
- s: sequence length
- L: number of layers
- Transformer 输入Shape
[s,b,h],输出Shape[s,b,h]
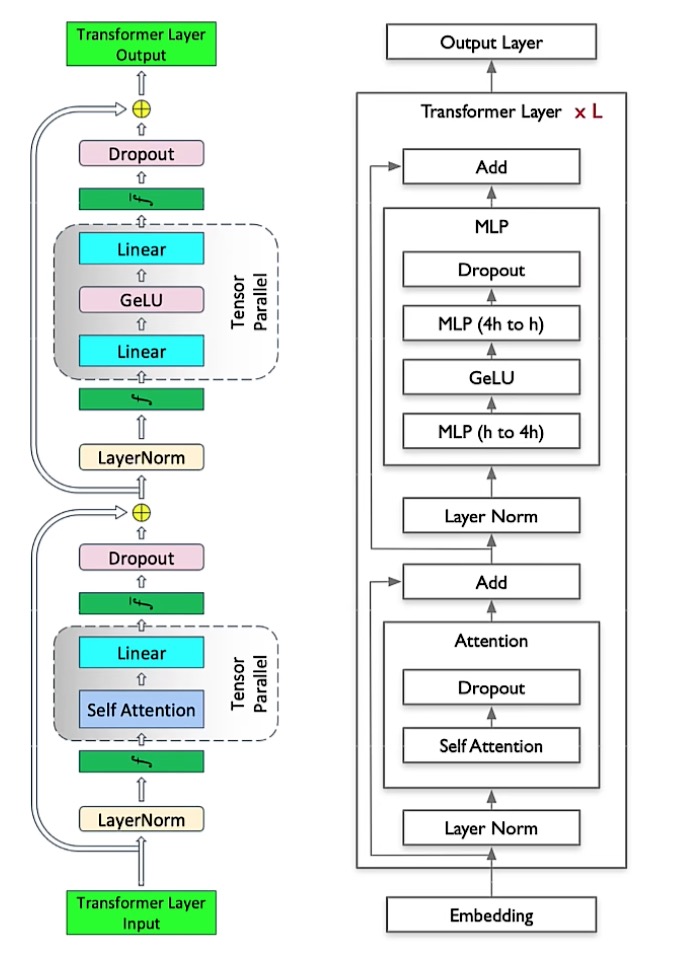
影响模型参数量的几个参数:
--num-layers--hidden-size--num-attention-headsseq-lengthmax-position-embeddings
序列并行 sequence parallel
Activation-Checkpoint 激活检查点、激活重计算
PP: Gpipe、PipeDream-Flush(+1F1B)
其他
补充一张截图,一个stage3的config: