【算法突围 01】线性结构与哈希表:ArrayList/HashMap 底层原理与性能优化实战
📖 本文导读
你是否好奇:为什么 ArrayList 扩容是 1.5 倍而不是 2 倍?HashMap 如何通过位运算实现 O(1) 查询?双重循环如何用 HashMap 优化 5000 倍?
本文将从生活类比 (仓库货架、朋友手拉手、寻宝地图)出发,深入 JDK 源码 (ArrayList 扩容、HashMap 拉链法+红黑树),手写简易版数据结构 ,并通过实战案例展示如何用空间换时间优化性能。
适合人群:Java 后端开发、准备面试者、想深入理解集合类底层原理的开发者。
阅读收获 :掌握 ArrayList/LinkedList/HashMap 的核心机制,学会根据场景选择合适的数据结构,理解 90% 以上的集合类面试题。
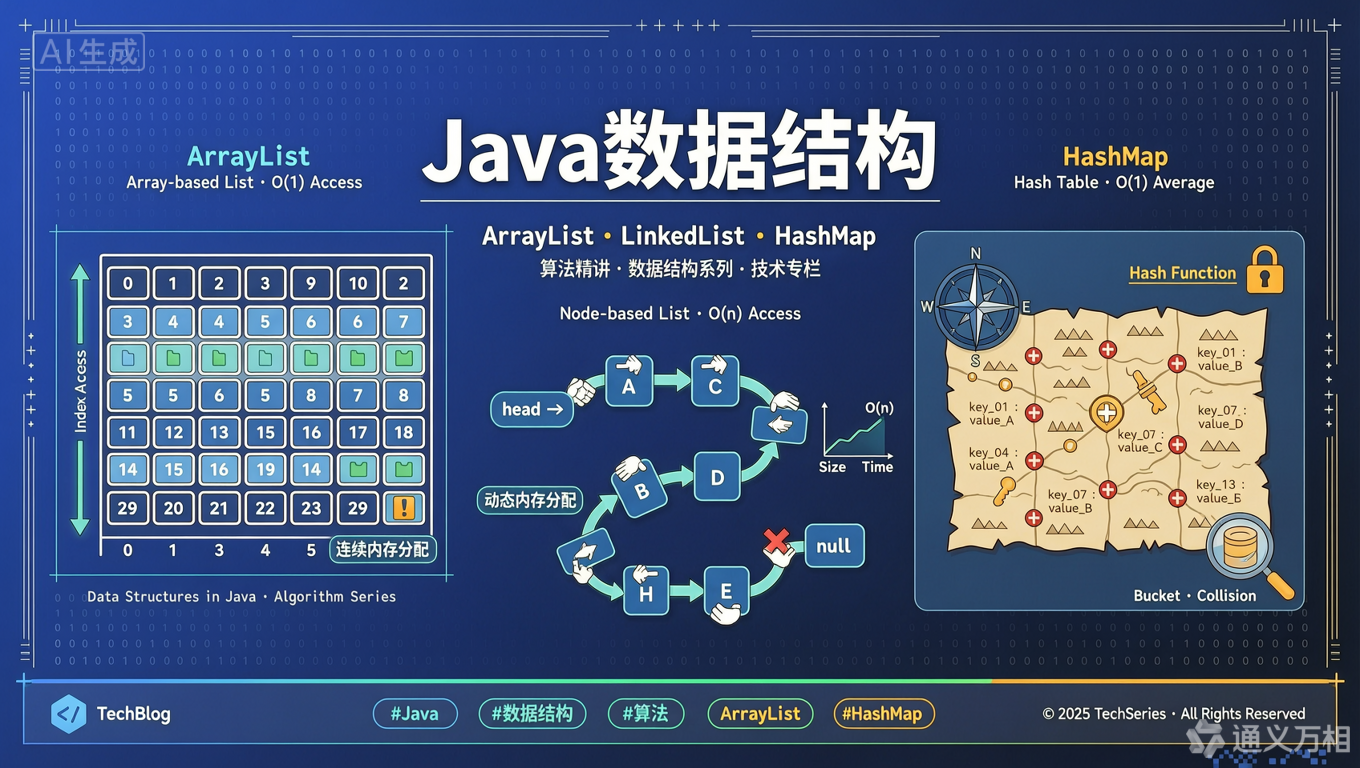
一、引言:为什么后端开发离不开数据结构?
你的代码为什么跑得比别人慢?
你有没有遇到过这样的场景------同样的业务需求,同事的接口响应 50ms,你的却要 2 秒?排查了半天,发现瓶颈不在 SQL,不在网络,而在一段看似普通的 for 循环里。
java
// 这段代码看起来没什么问题,但数据量大了就是灾难
for (int i = 0; i < listA.size(); i++) {
for (int j = 0; j < listB.size(); j++) {
if (listA.get(i).getId().equals(listB.get(j).getId())) {
// 找到相同ID
}
}
}两个列表各 10000 条数据,就要比较 1 亿次。 如果换成 HashMap,同样的逻辑只需要约 20000 次操作------性能提升 5000 倍。
数据结构就是程序的"收纳术"
想象一下你搬家:
- 数组 就像一排仓库货架,每个格子紧挨着,编号从 0 开始。你想找第 42 号格子里的东西?直接走过去就行,一步到位。但如果你要在中间插入一个新货架,后面的所有货架都得往后挪,累死人。
- 链表 就像一群朋友手拉手站成一排。你想找第 42 个人?只能从第 1 个人开始,一个一个问过去。但如果你想让某个人离开队伍,只需要他两边的人重新拉手就行,非常方便。
- 队列 就像排队买票,先来的人站在前面,后来的人排在后面。新来的人只能从队尾加入(入队),买完票的人从队首离开(出队),不允许插队。
- 哈希表 就像一张寻宝地图,你告诉它"我要找'张三'",它通过一个魔法公式(哈希函数)瞬间算出张三藏在哪个柜子里,直接打开拿走,根本不需要挨个翻。
选择合适的数据结构,就是给程序找到最高效的"收纳方式"。 下面我们从最基础的线性结构开始,一步步深入到后端开发中使用频率最高的 HashMap。
二、数组 vs 链表:内存里的"邻居"与"朋友"
2.1 数组(ArrayList):内存连续的"邻居社区"
特点
数组在内存中是一块连续的空间,就像一排紧挨着的储物柜:
内存地址: 1000 1004 1008 1012 1016
┌───┬───┬───┬───┬───┐
│ A │ B │ C │ D │ E │
└───┴───┴───┴───┴───┘
下标: 0 1 2 3 4- 查询快(O(1)):知道下标就能直接算出内存地址,一步到位。
- 增删慢(O(N)):在中间插入或删除元素,后面的所有元素都要移动。
JDK 源码解析:ArrayList 的动态扩容
ArrayList 并不是一开始就分配好所有空间,而是采用**"按需扩容"**策略:
java
// ArrayList.add() 方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 先检查容量够不够
elementData[size++] = e; // 直接赋值,O(1)
return true;
}
// 扩容核心逻辑
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
// 关键:新容量 = 旧容量 × 1.5
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// 将旧数据拷贝到新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}为什么是 1.5 倍? 这是一个平衡的艺术:
- 扩容太小(如 1.1 倍)→ 频繁扩容,频繁拷贝,性能浪费。
- 扩容太大(如 2 倍)→ 内存浪费严重。
- 1.5 倍是经过数学验证的折中方案,既能减少扩容次数,又不至于浪费太多内存。
面试 tip :
oldCapacity >> 1等价于oldCapacity / 2,位运算更快。
手写简易版 ArrayList
java
/**
* 简易版 ArrayList,帮助理解底层原理
* @param <E> 泛型参数
*/
public class MyArrayList<E> {
private Object[] elementData; // 存储数据的数组
private int size; // 当前元素个数
public MyArrayList() {
elementData = new Object[10]; // 默认初始容量 10
size = 0;
}
/**
* 在末尾添加元素 ------ O(1) 均摊
*/
public void add(E e) {
// 容量不够时扩容
if (size == elementData.length) {
grow();
}
elementData[size++] = e;
}
/**
* 在指定位置插入元素 ------ O(N)
* 需要将 index 之后的元素全部后移一位
*/
public void add(int index, E e) {
if (size == elementData.length) {
grow();
}
// 将 index 及之后的元素向后移动一位
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = e;
size++;
}
/**
* 根据下标获取元素 ------ O(1)
*/
@SuppressWarnings("unchecked")
public E get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("下标越界: " + index);
}
return (E) elementData[index];
}
/**
* 删除指定位置元素 ------ O(N)
* 需要将 index 之后的元素全部前移一位
*/
@SuppressWarnings("unchecked")
public E remove(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException("下标越界: " + index);
}
E oldValue = (E) elementData[index];
// 将 index 之后的元素向前移动一位
int numMoved = size - index - 1;
if (numMoved > 0) {
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
}
elementData[--size] = null; // 帮助 GC 回收
return oldValue;
}
/**
* 扩容:1.5 倍增长
*/
private void grow() {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 1.5 倍
elementData = Arrays.copyOf(elementData, newCapacity);
}
public int size() {
return size;
}
}2.2 链表(LinkedList):内存分散的"朋友圈"
特点
链表中的元素在内存中不需要连续存放,每个节点除了存储数据,还保存着下一个节点的地址(指针):
内存地址: 2000 3500 1800 4200
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
│ A │ ─┼───→│ B │ ─┼───→│ C │ ─┼───→│ D │null│
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
data next data next data next data next- 查询慢(O(N)):只能从头节点开始,顺着指针一个一个找。
- 增删快(O(1)):只需要修改指针的指向,不需要移动其他元素。
典型应用场景
- 消息队列:生产者往链表尾部添加消息,消费者从头部取出消息(FIFO)。
- 浏览器历史记录:前进/后退功能可以用双向链表实现。
- LRU 缓存淘汰: LinkedHashMap 底层就是链表 + 哈希表的组合。
手写简易版 LinkedList
java
/**
* 简易版单向链表,帮助理解节点关系
* @param <E> 泛型参数
*/
public class MyLinkedList<E> {
/**
* 链表节点:存储数据 + 指向下一个节点的指针
*/
private static class Node<E> {
E data;
Node<E> next;
Node(E data, Node<E> next) {
this.data = data;
this.next = next;
}
}
private Node<E> head; // 头节点
private int size; // 元素个数
public MyLinkedList() {
head = null;
size = 0;
}
/**
* 在链表头部添加元素 ------ O(1)
*/
public void addFirst(E e) {
head = new Node<>(e, head); // 新节点指向原来的头节点
size++;
}
/**
* 在链表尾部添加元素 ------ O(N)(单向链表需要遍历到尾部)
*/
public void addLast(E e) {
if (head == null) {
head = new Node<>(e, null);
} else {
Node<E> current = head;
while (current.next != null) {
current = current.next; // 顺藤摸瓜走到最后一个节点
}
current.next = new Node<>(e, null);
}
size++;
}
/**
* 根据下标获取元素 ------ O(N)
*/
public E get(int index) {
Node<E> current = head;
for (int i = 0; i < index; i++) {
current = current.next;
}
return current.data;
}
/**
* 删除头节点 ------ O(1)
*/
public E removeFirst() {
if (head == null) {
throw new NoSuchElementException("链表为空");
}
E data = head.data;
head = head.next; // 头指针后移,原来的头节点自动被 GC 回收
size--;
return data;
}
public int size() {
return size;
}
}2.3 性能大比拼
| 操作 | ArrayList(数组) | LinkedList(链表) | 说明 |
|---|---|---|---|
| 按下标查询 | O(1) ✅ | O(N) ❌ | 数组直接算地址,链表要遍历 |
| 头部插入 | O(N) ❌ | O(1) ✅ | 数组要移动所有元素,链表改指针即可 |
| 尾部插入 | O(1) 均摊 ✅ | O(N) ❌ | 数组直接赋值(偶尔扩容),单向链表要遍历 |
| 中间插入 | O(N) ❌ | O(1) ✅(已找到位置后) | 数组要移动后续元素,链表改指针 |
| 中间删除 | O(N) ❌ | O(1) ✅(已找到位置后) | 同上 |
| 内存占用 | 连续紧凑 ✅ | 每个节点多一个指针开销 ❌ | 链表每个节点额外存储 next 指针 |
| CPU 缓存友好 | 高 ✅ | 低 ❌ | 连续内存可以利用 CPU 缓存行预读 |
实战建议 :99% 的场景下,ArrayList 的综合性能优于 LinkedList。因为:
- CPU 缓存对连续内存非常友好,数组查询的实际速度远超理论值。
- LinkedList 每个节点都要额外创建对象,有 GC 压力。
- JDK 8 之后,JVM 对数组边界检查做了大量优化。
只有在频繁在头部增删的场景下,LinkedList 才有优势。
三、哈希表(HashMap):后端开发的"瑞士军刀"
HashMap 是后端开发中使用频率最高的数据结构,没有之一。无论是 Spring 的 Bean 容器、MyBatis 的一级缓存,还是 HTTP Session 管理,底层都离不开 HashMap。
3.1 原理:如何通过 Key 快速找到 Value?
哈希表的核心思想是:通过哈希函数,将 Key 直接映射到数组的一个下标,从而实现 O(1) 的查找。
put("张三", 90) 的过程:
Step 1: 计算哈希值
"张三".hashCode() → 774589
Step 2: 计算数组下标(索引)
index = 774589 & (数组长度 - 1) → index = 5
Step 3: 存入数组
table[5] = Node("张三", 90)
get("张三") 的过程:
同样计算 index = 5 → 直接访问 table[5] → 返回 90整个过程只需要一步计算 + 一次数组访问,时间复杂度 O(1)。
3.2 冲突解决:拉链法
不同的 Key 可能算出相同的下标,这就是哈希冲突 。比如 "张三" 和 "李四" 的 hashCode 取模后都等于 5,怎么办?
JDK 采用拉链法(链地址法):每个数组位置挂一个链表,冲突的元素追加到链表尾部。
table 数组:
[0] → null
[1] → Node("王五", 85) → null
[2] → null
[3] → null
[4] → null
[5] → Node("张三", 90) → Node("李四", 78) → null ← 冲突!用链表串起来
[6] → null
[7] → Node("赵六", 95) → null3.3 JDK 8 的进化:引入红黑树
问题:如果某个下标上的链表太长(比如极端情况下所有元素都冲突了),查找就退化为 O(N),HashMap 退化成链表。
JDK 8 的解决方案 :当链表长度超过 8 时,将链表转换为红黑树(一种自平衡二叉搜索树),将查询时间从 O(N) 优化到 O(log N)。
链表长度 ≤ 7: 纯链表结构
链表长度 ≥ 8: 转为红黑树
红黑树节点 ≤ 6: 退回链表(因为节点太少时,树节点的维护开销大于收益)为什么阈值是 8? 根据泊松分布 ,在合理的哈希函数下,链表长度达到 8 的概率仅为 0.00000006(亿分之六)。这意味着红黑树几乎不会被触发,它只是一个"保险机制",防止极端情况下的性能崩塌。
3.4 核心细节
为什么容量必须是 2 的幂次方?
HashMap 的默认初始容量是 16,每次扩容翻倍(16 → 32 → 64 → 128...),始终保持 2 的幂次方。
原因在于位运算优化。计算下标时:
java
// 计算下标的方式
index = hashCode(key) & (n - 1) // n 是数组长度当 n 是 2 的幂次方时,n - 1 的二进制全是 1(比如 16 - 1 = 15 = 1111),位运算 & 等价于取模 %,但速度更快:
n = 16, n - 1 = 15 = 01111
hashCode = 774589 = ...1011110001101101101
n - 1 = 01111
index = 01101 = 13
等价于:774589 % 16 = 13线程不安全体现在哪?
HashMap 在多线程环境下有两个经典问题:
1. 数据覆盖(JDK 7 和 JDK 8 都存在)
两个线程同时执行 put(),恰好在同一个位置插入,可能导致其中一个线程的数据被覆盖。
java
// 两个线程同时执行到这一行,后执行的会覆盖先执行的
table[index] = newNode;2. 死循环(JDK 7 特有)
JDK 7 扩容时采用"头插法",多线程并发扩容可能导致链表成环,形成死循环。JDK 8 改为"尾插法"解决了这个问题,但仍然不能在多线程环境下使用 HashMap ,应该用 ConcurrentHashMap。
手写简易版 HashMap
java
/**
* 简易版 HashMap,帮助理解核心原理
* @param <K> 键类型
* @param <V> 值类型
*/
public class MyHashMap<K, V> {
// 默认容量:16(必须是 2 的幂次方)
private static final int DEFAULT_CAPACITY = 16;
// 负载因子:0.75(元素数量达到容量的 75% 时扩容)
private static final float LOAD_FACTOR = 0.75f;
// 哈希桶数组
private Node<K, V>[] table;
// 当前元素个数
private int size;
/**
* 哈希表节点
*/
private static class Node<K, V> {
final K key;
V value;
Node<K, V> next; // 拉链法:指向下一个冲突节点
Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
@SuppressWarnings("unchecked")
public MyHashMap() {
table = new Node[DEFAULT_CAPACITY];
size = 0;
}
/**
* 存入键值对
*/
public void put(K key, V value) {
// 1. 检查是否需要扩容
if (size >= table.length * LOAD_FACTOR) {
resize();
}
// 2. 计算 Key 的哈希值
int hash = key == null ? 0 : key.hashCode();
// 3. 计算数组下标(位运算优化)
int index = hash & (table.length - 1);
// 4. 遍历链表,如果 Key 已存在则更新 Value
Node<K, V> node = table[index];
while (node != null) {
if (node.key.equals(key)) {
node.value = value; // Key 已存在,更新 Value
return;
}
node = node.next;
}
// 5. Key 不存在,在链表头部插入新节点(头插法)
table[index] = new Node<>(key, value, table[index]);
size++;
}
/**
* 根据 Key 获取 Value
*/
public V get(K key) {
int hash = key == null ? 0 : key.hashCode();
int index = hash & (table.length - 1);
// 遍历链表查找
Node<K, V> node = table[index];
while (node != null) {
if (node.key.equals(key)) {
return node.value;
}
node = node.next;
}
return null; // 未找到
}
/**
* 扩容:容量翻倍
*/
@SuppressWarnings("unchecked")
private void resize() {
Node<K, V>[] oldTable = table;
int newCapacity = oldTable.length << 1; // 翻倍
table = new Node[newCapacity];
size = 0;
// 将旧数据重新哈希到新数组
for (Node<K, V> node : oldTable) {
while (node != null) {
put(node.key, node.value); // 重新计算下标
node = node.next;
}
}
}
public int size() {
return size;
}
}四、实战案例:如何用 HashMap 优化双重循环?
场景描述
从两个用户列表中找出相同的用户 ID:
java
List<User> listA = ...; // 10000 个用户
List<User> listB = ...; // 10000 个用户
// 找出两个列表中 ID 相同的用户暴力解法:O(N²)
java
public List<Long> findCommonIds_bruteForce(List<User> listA, List<User> listB) {
List<Long> result = new ArrayList<>();
for (User a : listA) { // 外层循环 N 次
for (User b : listB) { // 内层循环 N 次
if (a.getId().equals(b.getId())) {
result.add(a.getId());
}
}
}
return result;
}
// 时间复杂度:O(N × M),10000 × 10000 = 1 亿次比较优化解法:HashMap 空间换时间,O(N)
java
public List<Long> findCommonIds_hashMap(List<User> listA, List<User> listB) {
List<Long> result = new ArrayList<>();
// Step 1: 将 listB 的所有 ID 存入 HashMap ------ O(M)
Set<Long> idSet = new HashSet<>();
for (User b : listB) {
idSet.add(b.getId());
}
// Step 2: 遍历 listA,在 HashMap 中查找 ------ O(N)
for (User a : listA) {
if (idSet.contains(a.getId())) { // HashSet.contains() 是 O(1)
result.add(a.getId());
}
}
return result;
}
// 时间复杂度:O(N + M),10000 + 10000 = 20000 次操作
// 性能提升:1 亿次 → 2 万次,快了 5000 倍!性能对比
| 方案 | 时间复杂度 | 10000 + 10000 数据量 | 空间复杂度 |
|---|---|---|---|
| 暴力双重循环 | O(N × M) | ~1 亿次比较 | O(1) |
| HashMap 优化 | O(N + M) | ~2 万次操作 | O(M) |
核心思想 :HashMap 的
contains()是 O(1),用它替代内层循环,就把 O(N × M) 降为 O(N + M)。这就是经典的**"空间换时间"**策略。
五、总结与面试避坑
核心要点回顾
| 数据结构 | 查询 | 插入/删除 | 内存特点 | 适用场景 |
|---|---|---|---|---|
| 数组 (ArrayList) | O(1) | O(N) | 连续紧凑 | 读多写少、需要按下标访问 |
| 链表 (LinkedList) | O(N) | O(1) | 分散、有指针开销 | 频繁头尾增删 |
| 哈希表 (HashMap) | O(1) | O(1) | 数组 + 链表/红黑树 | 键值对存储、去重、快速查找 |
常见面试题速查
1. HashMap 的扩容过程?
当
size > capacity × loadFactor(默认 0.75)时触发扩容。创建一个容量为原来 2 倍的新数组,将所有元素重新哈希 (rehash)到新数组中。扩容操作非常耗时,应尽量避免频繁扩容------初始化时最好预估容量。
2. ConcurrentHashMap 原理简述?
JDK 7 采用分段锁(Segment) ,将整个 HashMap 分成 16 段,每段有自己的锁,不同段可以并发操作。JDK 8 改为 CAS + synchronized,锁粒度更细(锁住链表头节点),并发性能更好。
3. HashMap 为什么不允许 Key 为 null?
HashMap 允许一个 Key 为 null(存放在下标 0 的位置),但 ConcurrentHashMap 不允许 Key 或 Value 为 null ,因为多线程环境下
get(key)返回 null 时无法区分"key 不存在"和"value 就是 null"。
4. ArrayList 和 LinkedList 如何选择?
绝大多数场景选 ArrayList 。只有在明确需要频繁在头部增删(如实现栈、队列)时才考虑 LinkedList。如果需要两端操作,可以用
ArrayDeque(基于数组的高效双端队列)。
最后记住一句话 :数据结构选对了,代码就成功了一半。下次写代码时,先问自己:我是在频繁查找,还是频繁增删? 答案会直接告诉你该用哪种数据结构。