1、概述
AI分为分析AI、生成式AI有什么区别呢
分析式AI,通过现有数据训练模型,让模型有能力预测新数据的决策。
生成式AI,让AI生成某种结果,比如:写一段代码,生成一段文字。
2、十大算法
1、分类算法:C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN, Adaboost,CART
2、聚类算法:K-Means,EM
3、关联分析:Apriori
4、连接分析:PageRank
2.1、分类算法
属于监督学习,利用标签的训练数据(既有特征,又有真实结果),让模型学习从输入特征到预定义类别的映射规律,
从而对新的、未见过的数据自动进行类别预测。带标签的数据,是人为提前标注好的。
示例:根据用户信息、信用特征,预测他未来是否会逾期还款。
1、训练模型时,给模型大量带标签的历史数据,模型慢慢会慢慢总结出规律。数据如下:
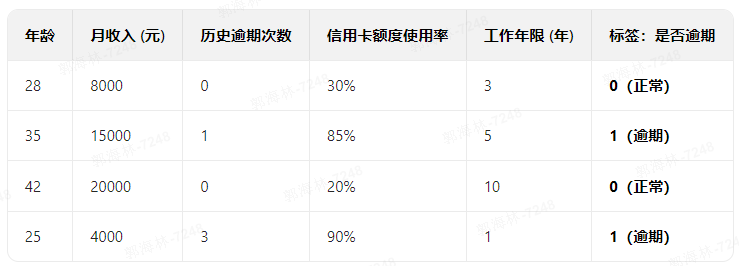
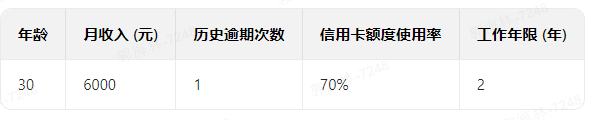
2、模型学会后,当新的用户数据再次给模型时,模型会自动给出预测
输出0:正常 或 输出1:逾期
2.1.1、分类算法:决策树
决策树基本上就是把我们以前的经验总结出来,常见的决策树算法有C4.5、ID3和CART。
从带标签的数据中,自动总结出一套经验判断规则,并以树状结构呈现。模拟人类做决策逻辑,通过一连串简单的问题,层层筛选,最终得出分类结果。
示例:判断要不要带伞
如图每个节点是模型根据带标签的数据,总结出的规律,当新数据来时,从根节点走到叶子节点,预测带伞/不带伞

2.2、聚类算法
属于无监督学习,给出大量无标签数据(不用人工标注),模型根据数据相似性、规律,实现自动分组。
是一种降维思想,把复杂的商品、用户分类几类,方便业务针对每一类做决定。
示例:给模型一堆水果,不贴任何标签,实现自动分组
数据 1:红、圆、甜
数据 2:黄、弯、香
数据 3:红、圆、脆
数据 4:黄、弯、甜
模型自己看:"红圆的都像一类,黄弯的都像一类",自动分成两组,不依赖任何提前标注的标签。
应用场景:把用户自动分成不同群体,做精准运营
常见分群方式
按消费能力:高价值用户、普通用户、低价值用户
按活跃度:活跃用户、沉睡用户、流失用户
按行为偏好:价格敏感型、品牌忠诚型、冲动消费型
应用效果
给高价值用户发专属优惠券,提高复购
给沉睡用户推送唤醒活动,减少流失
给不同偏好用户展示不同商品,提升转化率
2.3、关联分析
属于无监督学习,从大量数据中(购物订单、用户行为),自动找出事务之间隐藏的规律。
示例:啤酒与尿布
沃尔玛分析了大量购物数据,发现一个神奇规律
买尿布的男性,经常同时买啤酒
数据规律
支持度:尿布和啤酒一起出现的频率不低
置信度:买尿布的人,买啤酒的概率很高
提升度:远大于 1,说明是强关联
商业应用
沃尔玛把啤酒和尿布放在相邻货架,结果两者销量都大幅提升!
这就是关联分析的威力:从数据里挖出人类想不到的隐藏规律,直接指导业务决策。
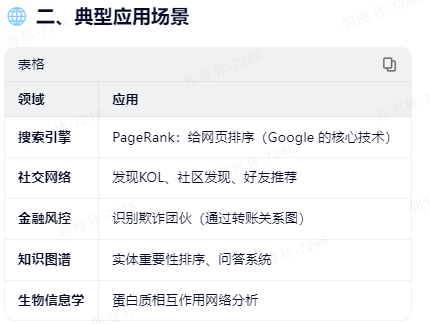
2.4、连接分析
属于无监督学习,研究网络中节点之间的关系,挖掘谁更重要、谁和谁关联紧密。
不关注节点本身的属性,而是只看连接结构,得到每个节点的影响力。
当一个节点引用很多,证明这个节点影响力很高,可以找出连接中哪个是核心人物(影响力)
3、实际问题
阿里云天池比赛:二手车价格预测学习赛
1、比赛中会给出训练数据(数据标签好了),训练自己的模型
2、用训练好的模型,跑验证数据(新数据,没有标签),得出结果
3、把得出的结果上传,会得出比分
1. 训练模型(有标签数据)
比赛方提供训练数据,里面包含:
特征:二手车的各种信息(如品牌、年份、里程、排量、变速箱类型等)
标签:真实的二手车价格(这是我们要预测的目标)
你的任务:用这些带标签的训练数据,训练一个回归模型(因为价格是连续值,属于回归问题),让模型学会 "特征→价格" 的映射规律。
2. 预测结果(无标签数据)
比赛方提供测试数据(验证数据),里面只有特征,没有标签(价格)。
你的任务:把训练好的模型用到测试数据上,自动预测每辆车的价格,生成预测结果文件。
3. 提交评分
把预测结果上传到天池平台,会得出比分