文章目录
[1.1 为什么从顺序表开始?](#1.1 为什么从顺序表开始?)
[1.2 什么是顺序表?](#1.2 什么是顺序表?)
[1.3 为什么需要顺序表?](#1.3 为什么需要顺序表?)
[2.1 静态顺序表:死板的收纳箱](#2.1 静态顺序表:死板的收纳箱)
[2.2 动态顺序表:智能的收纳箱](#2.2 动态顺序表:智能的收纳箱)
[3.1 初始化(使用上面创建的顺序表)](#3.1 初始化(使用上面创建的顺序表))
[3.2 顺序表的销毁](#3.2 顺序表的销毁)
[3.3 顺序表的打印](#3.3 顺序表的打印)
[3.4 顺序表的插入](#3.4 顺序表的插入)
[3.4.1 从顺序表表尾插入数据](#3.4.1 从顺序表表尾插入数据)
[3.4.2 从顺序表表头插入数据](#3.4.2 从顺序表表头插入数据)
[3.4.3 从指定位置插入](#3.4.3 从指定位置插入)
[3.5 删除指定位置的数](#3.5 删除指定位置的数)
[3.6 查找数字在顺序表中的位置](#3.6 查找数字在顺序表中的位置)
[4.1 seqlist.h](#4.1 seqlist.h)
[4.2 seqlist.c](#4.2 seqlist.c)
[4.3 test.c](#4.3 test.c)
前言
我们已经完成了C语言内容的知识,现在开始数据结构的学习。这部分的学习需要我们有较为扎实的C语言编程基础,有需要可以看看这里C语言基础内容学习。然后我们将来开始数据结构第一课------顺序表的学习。
1.顺序表:数据结构的第一课
1.1 为什么从顺序表开始?
如果你问我:"数据结构这么多,为什么先从顺序表开始?"我的回答是:因为顺序表是最接近你已有知识的数据结构。
你已经学过数组,而顺序表就是"会呼吸的数组":
-
数组:固定大小,装满了就没办法
-
顺序表:不够了可以自己扩容,用完了可以缩小
这种"进化"正是数据结构的魅力所在。
1.2 什么是顺序表?

简单理解
想象你要管理一个班级的学生名单:
-
数组方式:预订50个座位,就算只有20个学生,也要占50个位置
-
顺序表方式:先准备20个座位,来新学生就加椅子,有学生转学就撤椅子
顺序表 = 数组 + 智能管理
两个关键点
-
物理上连续:数据在内存中一个挨着一个存放
-
逻辑上连续:数据之间有顺序关系(第1个、第2个...)
1.3 为什么需要顺序表?
看这个例子:
cpp
// 用数组管理学生成绩(问题版)
int scores[100]; // 固定100个位置
int count = 0; // 记录实际有多少学生
void add_score(int score) {
if (count < 100) {
scores[count] = score;
count++;
} else {
printf("满了!加不进去了!\n");
}
}问题:
-
最多只能有100个学生
-
如果只有30个学生,浪费70个位置
-
如果有101个学生,无法处理
顺序表的解决方案:
cpp
// 顺序表方式:动态调整大小
int* scores = malloc(10 * sizeof(int)); // 先申请10个位置
int capacity = 10; // 当前容量
int size = 0; // 实际使用量
void add_score(int score) {
if (size == capacity) { // 满了就扩容
capacity *= 2;
scores = realloc(scores, capacity * sizeof(int));
}
scores[size] = score;
size++;
}2.顺序表的两种形式
2.1 静态顺序表:死板的收纳箱
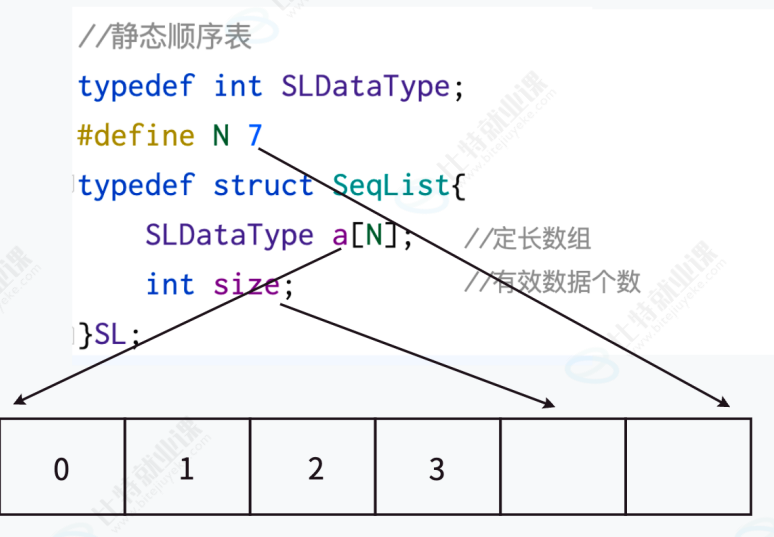
cpp
//静态数据表
struct seqlist
{
int arr[n];
int len;//当前长度,有效数据的个数
};特点:大小固定,不够就溢出,多了就浪费
2.2 动态顺序表:智能的收纳箱

cpp
typedef int sldatatype;
typedef struct seqlist
{
sldatatype* arr;
int len;
int capacity;
}SL;//不需要进行struct sqlist s1;这样的声明,直接SL s1即可
//typedef struct seqlist seqlist;
这里typedef int sldatatype;是为了方便数据替换。
特点:按需分配,不够就扩容,用不完可缩容
3.实现动态顺序表的关键操作
3.1 初始化(使用上面创建的顺序表)
cpp
void seqInit(SL* sl)
{
sl->arr = NULL;
sl->len =sl->capacity = 0;
}这里应该很好理解,就是把指针设为空指针,顺序表的长度与容量设为0,当然也可以将容量设置为4或者其他非零值,那就需要利用malloc函数进行对应大小的内存申请。
3.2 顺序表的销毁
cpp
void seqDestory(SL* sl)
{
if (sl->arr)
free(sl->arr);
sl->arr = NULL;
sl->len = sl->capacity = 0;
}这里就是利用free释放前面申请的空间,否则会发生内存泄漏。
3.3 顺序表的打印
cpp
void seqprint(SL* sl)
{
for (int i = 0;i < sl->len;i++)
{
printf("%d ", sl->arr[i]);
}
printf("\n");
}为了方便观察,我们需要一个函数对顺序表进行打印。
3.4 顺序表的插入
3.4.1 从顺序表表尾插入数据
cpp
void seqpushback(SL* sl, sldatatype data)
{
assert(sl);
seqcheck(sl);
sl->arr[sl->len] = data;
sl->len++;
}3.4.2 从顺序表表头插入数据
cpp
void seqpushfront(SL* sl, sldatatype data)
{
assert(sl);
seqcheck(sl);
for (int i = (sl->len)-1;i > 0;i--)
{
sl->arr[i+1] = sl->arr[i];
}
sl->arr[0] = data;
sl->len++;
}这里需要将数据先往后移,sl->arri+1 = sl->arri;使得下标为0的位置可以插入数据,同时数据不会丢失。
3.4.3 从指定位置插入
cpp
void seqInsert(SL* sl, int index, sldatatype data)
{
assert(sl);
assert(index>=0 && index<=sl->len);
seqcheck(sl);
for (int i = sl->len - 1;i>=index;i--)
{
sl->arr[i + 1] = sl->arr[i];
}
sl->arr[index] = data;
sl->len++;
}这里就是把下标为index的数全部往后移,为了防止数据的丢失,从表尾开始移。
注意:都要对顺序表的有效长度进行更新
3.5 删除指定位置的数
cpp
void seqDelete(SL* sl, int index)
{
assert(sl);
assert(index >= 0 && index < sl->len);
for (int i = index;i < sl->len - 1;i++)
{
sl->arr[i] = sl->arr[i + 1];
}
sl->len--;
}其实就是从ndex+1开始,把前面的值用后面的值覆盖。
3.6 查找数字在顺序表中的位置
cpp
void seqgetlen(SL* sl,sldatatype* data)
{
assert(sl);
for (int i = 0;i < sl->len;i++)
{
if (sl->arr[i] == data)
{
printf("找到了,所在位置数组下标为%d\n", i);
return;
}
}
printf("没有找到\n");
}这里就是利用for循环遍历整个数组,查找对应的数。
4.顺序表基本功能完整代码实现
这里为了方便代码的观看以及修改,用3个文件进行实现
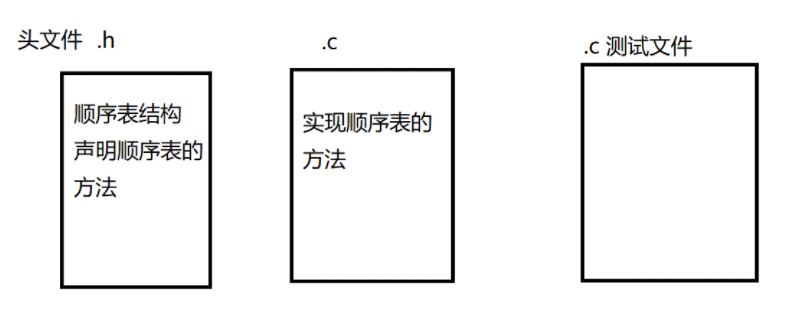
4.1 seqlist.h
cpp
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int sldatatype;
typedef struct seqlist
{
sldatatype* arr;
int len;
int capacity;
}SL;
void seqInit(SL* sl);
void seqDestory(SL* sl);
void seqpushback(SL* sl, sldatatype data);
void seqpushfront(SL* sl,sldatatype data);
void seqcheck(SL* sl);
void seqprint(SL* sl);
void seqinsert(SL* sl, int index, sldatatype data);
void seqdelete(SL* sl, int index);
void seqgetlen(SL* sl,sldatatype* data);4.2 seqlist.c
cpp
#include"seqlist.h"
void seqInit(SL* sl)
{
sl->arr = NULL;
sl->len =sl->capacity = 0;
}
void seqDestory(SL* sl)
{
if (sl->arr)
free(sl->arr);
sl->arr = NULL;
sl->len = sl->capacity = 0;
}
void seqprint(SL* sl)
{
for (int i = 0;i < sl->len;i++)
{
printf("%d ", sl->arr[i]);
}
printf("\n");
}
void seqcheck(SL* sl)
{
if (sl->len == sl->capacity)
{
int newcapacity = sl->capacity==0 ? 4:2*sl->capacity;
sldatatype* pr = (sldatatype*)realloc(sl->arr, newcapacity * sizeof(sldatatype));
if (pr==NULL)
{
perror("realloc fail!");
exit (1);
}
sl->capacity = newcapacity;
sl->arr = pr;
}
}
void seqpushback(SL* sl, sldatatype data)
{
assert(sl);
seqcheck(sl);
sl->arr[sl->len] = data;
sl->len++;
}
void seqpushfront(SL* sl, sldatatype data)
{
assert(sl);
seqcheck(sl);
for (int i = (sl->len)-1;i > 0;i--)
{
sl->arr[i+1] = sl->arr[i];
}
sl->arr[0] = data;
sl->len++;
}
void seqInsert(SL* sl, int index, sldatatype data)
{
assert(sl);
assert(index>=0 && index<=sl->len);
seqcheck(sl);
for (int i = sl->len - 1;i>=index;i--)
{
sl->arr[i + 1] = sl->arr[i];
}
sl->arr[index] = data;
sl->len++;
}
void seqDelete(SL* sl, int index)
{
assert(sl);
assert(index >= 0 && index < sl->len);
for (int i = index;i < sl->len - 1;i++)
{
sl->arr[i] = sl->arr[i + 1];
}
sl->len--;
}
void seqgetlen(SL* sl,sldatatype* data)
{
assert(sl);
for (int i = 0;i < sl->len;i++)
{
if (sl->arr[i] == data)
{
printf("找到了,所在位置数组下标为%d\n", i);
return;
}
}
printf("没有找到\n");
}4.3 test.c
cpp
#define _CRT_SECURE_NO_WARNINGS
#include"seqlist.h"
void test()
{
SL sl;
seqInit(&sl);
seqpushback(&sl, 1);
seqpushback(&sl, 1);
seqpushback(&sl, 2);
seqpushback(&sl, 3);
seqprint(&sl);
seqpushfront(&sl, 4);
seqprint(&sl);
seqInsert(&sl, 2, 5);
seqprint(&sl);
seqDelete(&sl, 2);
seqprint(&sl);
seqgetlen(&sl, 2);
seqDestory(&sl);
}
int main()
{
test();
return 0;
}
//整体流程
//初始化 销毁 打印 尾部插入 头部插入 尾部删除 头部删除
//指定位置插入数据 指定位置删除数据 查找某个数在顺序表中的位置
//最好写完一个模块就进行测试顺序表的优缺点
优点(为什么用顺序表)
-
随机访问快:知道下标就能直接找到数据
cpp// 瞬间找到第5个数据 int value = list.data[4]; -
缓存友好:数据连续存放,CPU缓存命中率高
缺点(为什么需要其他数据结构)
-
中间插入/删除慢:要移动大量数据
-
扩容成本高:重新分配内存,复制所有数据
学习总结
通过本次学习,我们掌握了顺序表这一基础数据结构。顺序表本质是"智能数组",能够动态调整大小,解决了固定数组空间浪费或不足的问题。我们实现了动态顺序表的核心功能:初始化、销毁、增删改查,并理解了其优缺点。
核心收获
-
理解了数据组织的思维方式:如何根据需求选择数据结构
-
掌握了动态内存管理:malloc/realloc/free的合理使用
-
培养了工程实践能力:从单个功能到完整系统的构建
实战预告:基于顺序表实现通讯录
理论需要实践验证,知识需要应用巩固。
在下一篇文章中,我们将把刚学的顺序表知识应用到实际项目------实现一个完整的通讯录系统。
你将完成:
-
数据结构设计:用顺序表存储联系人信息
-
功能模块实现:添加、删除、查找、修改联系人
-
系统集成:将各个功能组合成完整可用的程序
项目价值:
-
将抽象的数据结构知识转化为具体应用
-
体验从零构建完整系统的过程
-
为后续更复杂的数据结构学习打下坚实基础
下一步行动
准备好你的开发环境,我们将从需求分析开始,一步步构建一个真正可用的通讯录系统。这不仅是技术实践,更是思维训练------学会如何用数据结构解决实际问题。
下一篇,我们将一起完成这个项目,体验"学以致用"的成就感!
欢迎在评论区交流讨论,如果觉得有帮助,请点赞收藏支持!
更多C语言技术文章,请访问我的博客主页:莱克边澄-CSDN博客