探索华为CANN框架中的Ops-NN仓库
更多CANN组织详情:https://atomgit.com/cann
Ops-NN仓库:https://atomgit.com/cann/ops-nn
探索华为CANN框架中的Ops-NN仓库
华为的Compute Architecture for Neural Networks(CANN)是一个专为人工智能场景设计的异构计算平台。它连接了上层的AI框架,如MindSpore、PyTorch和TensorFlow,与底层的Ascend硬件之间架起桥梁,实现模型的高效编译、优化和部署。在CANN的核心能力中,运算符库扮演着至关重要的角色,这些库提供了针对各种神经网络操作的优化实现,帮助开发者构建高效的AI应用。
Ops-NN仓库作为CANN组织的一部分,专注于神经网络运算符的开发和优化。这些运算符包括卷积、池化、激活函数、全连接层等基础构建块,是构建和加速AI模型不可或缺的组成部分。该仓库属于Ascend Operator Library(AOL)的一部分,提供预优化的代码,利用Ascend NPU(Neural Processing Units)实现高性能计算。开发者可以通过这些运算符,将模型编译为在华为Ascend硬件上高效运行的形式,从而降低延迟,提高吞吐量,适用于从图像识别到自然语言处理的各种AI应用。
CANN框架的整体架构设计非常精妙,它将AI计算过程分为多个层次,包括前端框架适配、图优化、运算符执行和硬件调度。Ops-NN仓库主要关注运算符的实现和优化,确保每个运算符都能充分利用Ascend芯片的并行计算能力。例如,在卷积运算中,Ops-NN通过特定的内核优化算法,实现数据并行和任务并行,显著提升计算效率。这不仅仅是简单的代码实现,还涉及底层硬件的特性,如DaVinci架构的向量计算单元和立方体计算单元,这些单元专为矩阵运算和张量操作设计。
为了更好地理解Ops-NN在CANN中的位置,我们可以看看CANN的架构图:
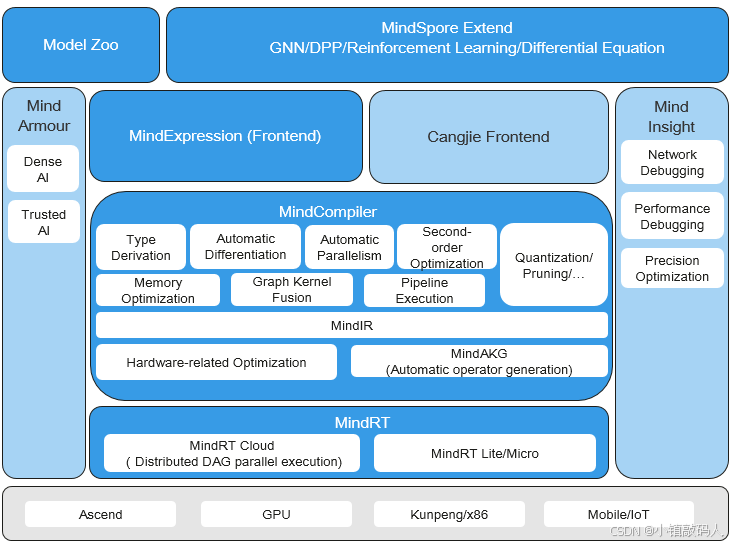
这个图展示了MindSpore框架与CANN的集成,Ops-NN作为运算符库,位于编译器和运行时的中间层,支持自动并行化和内核融合等高级优化。
Ops-NN仓库的核心功能
Ops-NN仓库提供了丰富的神经网络运算符,这些运算符经过硬件加速,确保在Ascend NPU上运行时达到最佳性能。以卷积运算符为例,它支持多种卷积类型,包括标准卷积、深度可分离卷积和分组卷积。这些运算符的实现考虑了数据布局的优化,如NHWC和NCHW格式的转换,以匹配Ascend硬件的内存访问模式。此外,Ops-NN还包括激活函数如ReLU、Sigmoid和Tanh,这些函数在神经网络中用于引入非线性,提高模型的表达能力。
另一个关键功能是池化运算符,包括最大池化和平均池化。这些运算符在计算机视觉任务中广泛使用,用于特征降维和提取。Ops-NN通过SIMD(Single Instruction Multiple Data)指令集优化这些操作,使其在多核NPU上并行执行,显著缩短处理时间。
全连接层运算符是Ops-NN的另一亮点。它处理密集矩阵乘法,利用GEMM(General Matrix Multiply)内核实现高效计算。在大规模模型如Transformer中,全连接层往往是计算瓶颈,Ops-NN通过内核融合技术,将多个运算符合并为一个内核,减少内存访问开销,提高整体性能。
Ops-NN还支持批标准化(Batch Normalization)和层标准化(Layer Normalization)等规范化运算符。这些运算符帮助稳定训练过程,加速收敛。仓库中提供了这些运算符的Ascend特定实现,确保与上层框架无缝集成。
在兼容性和集成方面,Ops-NN与CANN的运行时系统紧密结合。开发者可以使用CANN的API调用这些运算符,实现从云端到边缘设备的模型部署,而无需大量修改代码。这使得Ops-NN成为华为AI生态的重要组成部分,与MindSpore框架结合,能构建端到端的AI解决方案。
以下是神经网络运算符的简单示意图,展示了输入、隐藏层和输出的连接方式:
这个图直观地解释了多层感知机(MLP)的结构,Ops-NN仓库中包含了实现这些层所需的所有运算符。
Ops-NN的优化技术详解
Ops-NN仓库的优化技术是其核心竞争力之一。首先是硬件相关优化。Ascend NPU基于DaVinci架构,拥有专用的AI Core,用于向量和矩阵运算。Ops-NN的运算符代码针对这些核心编写,使用CUBE指令进行立方体计算,这在处理3D卷积时特别高效。
其次是图内核融合(Graph Kernel Fusion)。在传统AI框架中,多个运算符独立执行会导致频繁的内存读写。Ops-NN通过融合技术,将相邻运算符合并,例如将卷积和激活融合为一个内核,减少中间结果的存储,提高带宽利用率。
自动量化也是Ops-NN的一项重要优化。AI模型往往使用浮点数计算,但Ascend硬件支持INT8和FP16等低精度格式。Ops-NN提供量化工具,将模型从FP32转换为低精度,同时最小化精度损失,这在边缘设备上特别有用,能降低功耗并提升速度。
此外,Ops-NN支持并行计算策略,包括数据并行、模型并行和流水线并行。这些策略允许在多NPU集群上分布式训练大型模型,如BERT或ResNet-50。仓库中包含示例代码,展示如何使用这些策略优化训练过程。
在调试和性能分析方面,Ops-NN集成CANN的MindInsight工具,支持可视化运算符执行路径和瓶颈分析。开发者可以监控每个运算符的执行时间、内存使用和计算利用率,从而针对性优化。
看看Ascend NPU芯片的外观和产品线:

这个图片展示了华为Atlas系列产品,这些硬件正是Ops-NN运算符运行的平台,从云端集群到边缘模块,应有尽有。
Ops-NN在实际应用中的案例
Ops-NN仓库在实际AI应用中发挥着关键作用。以图像识别为例,在构建CNN模型时,开发者可以使用Ops-NN的卷积和池化运算符处理输入图像。这些运算符优化后,能在Ascend 910芯片上实现每秒数千帧的推理速度,适用于实时监控系统。
在自然语言处理领域,Ops-NN支持注意力机制和嵌入层运算符,用于Transformer模型。结合MindSpore,开发者可以训练多语言模型,实现机器翻译或情感分析。Ops-NN的量化优化使这些模型能在手机等移动设备上运行,扩展AI的应用边界。
另一个应用是推荐系统。在电商平台,Ops-NN的全连接和激活运算符用于用户特征提取和排序。通过分布式训练,系统能处理海量数据,提供个性化推荐,提高用户体验。
在医疗影像分析中,Ops-NN的运算符用于U-Net等分割模型,帮助医生快速识别病灶。优化后的性能确保在医院边缘设备上实时处理CT或MRI图像。
Ops-NN还鼓励开源贡献。华为将CANN部分开源,开发者可以fork Ops-NN仓库,提交新运算符或优化建议。这促进了社区发展,使其与NVIDIA CUDA等平台竞争。
以下是另一个神经网络运算符的示意图,展示了多层网络的结构:
这个图强调了层与层之间的权重连接,Ops-NN正是优化这些连接的计算。
Ops-NN的未来发展和挑战
展望未来,Ops-NN仓库将继续演进。随着AI模型向更大规模发展,如GPT系列,Ops-NN需要支持更多高级运算符,如Flash Attention和MoE(Mixture of Experts)。华为计划增强Ops-NN的量子计算支持,探索混合经典-量子AI。
挑战方面,一是兼容性。Ops-NN需更好地支持非华为框架,如ONNX标准,以吸引更多开发者。二是性能瓶颈。在极大规模模型中,内存管理仍是问题,Ops-NN需优化动态内存分配。
社区贡献是关键。华为通过文档和教程鼓励参与,Ops-NN的README提供详细安装和使用指南。
MindSpore生态系统的概览图:
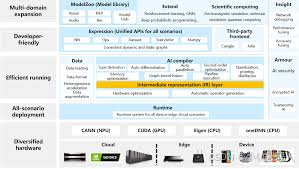
这个图展示了MindSpore的多领域扩展,Ops-NN作为底层支持,驱动整个生态。
通过深入Ops-NN,开发者能洞察低级优化如何驱动AI性能,是华为AI栈的宝贵资源。
深入探讨Ops-NN的代码实现
Ops-NN仓库的代码结构清晰,主要分为几个模块:核心运算符实现、测试用例和文档。核心模块使用C++编写,结合Ascend的ACL(Ascend Computing Language)API。例如,卷积运算符的代码包括内核注册、参数校验和执行逻辑。
在内核实现中,使用Tiling算法将大张量分解为小块,匹配NPU的缓存大小。这避免了缓存缺失,提高效率。测试用例覆盖单元测试和集成测试,确保运算符在不同数据类型和形状下的正确性。
开发者可以克隆仓库,构建自定义运算符。步骤包括定义运算符接口、实现内核和注册到AOL。CANN提供工具链支持编译和调试。
Ops-NN与竞品的比较
相比NVIDIA的cuDNN,Ops-NN在Ascend硬件上的性能更优,尤其在FP16计算中。但cuDNN生态更成熟。Ops-NN的优势在于一体化,与MindSpore无缝集成,适合端到端开发。
与TensorRT类似,Ops-NN强调推理优化,但更注重训练支持。这使它在全流程AI开发中更有竞争力。
结语
Ops-NN仓库是CANN框架的基石,提供高效神经网络运算符,推动AI创新。无论初学者还是专家,都能从中获益。
更多CANN组织详情:https://atomgit.com/cann
Ops-NN仓库:https://atomgit.com/cann/ops-nn