
这篇不打算做"迁移工具清单"。我更想把它写成替换项目里的对账/验收笔记:哪些坑最爱在切换前后冒头,哪些检查在 Windows + ksql 的环境里就能用很小的成本跑起来。目标也很直白:别只停留在"迁过去了",而是要做到"迁得对、跑得稳、出了事还能回得去"。
@toc
1. 为什么迁移最难的不是"能不能导入",而是"对不对得上"
迁移这事儿,最容易让人放松警惕的一句话就是:"数据都导进去了,查得出来就行。"
可一旦上线,业务真正感知的从来不是"有没有数据",而是下面这两件事:
- 完整性:该有的行有没有都到齐(不丢、不缺、不乱关联);
- 一致性:同一条业务事实在新旧链路上是不是同一个结果(金额、状态、时间、文本都一致)。
我见过不少事故,最后都能归到一句话上:迁移链路把"数据的样子"搬过去了,但没把"数据的含义"一起搬过去。一旦语义悄悄偏了,它通常不会立刻炸锅,更像是慢性病:今天对账差一点、明天某几单状态怪怪的、后天又有人反馈"怎么搜不到"。排查起来最耗人。
2. 完整性 vs 一致性:风险地图(按"怎么验"来分组)
| 风险类型 | 典型表现 | 更容易出现在哪个阶段 | 最有效的验证方式 |
|---|---|---|---|
| 行级缺失/重复 | 少行、重复行、主键冲突后被覆盖 | 全量导入、增量回放 | 分段行数对账 + 主键重复扫描 |
| 参照关系断裂 | 明细找不到主表、外键启用失败 | 导入后补约束 | 断链扫描(left join 找孤儿) |
| 字符集/排序规则偏差 | 文本不等、比较/排序结果变化 | 读写混用期 | 长度/字节长度对照 + 关键查询回归 |
| 时间/时区/精度偏差 | 时间相差 8 小时、同秒内顺序错 | 增量窗口、对账 | 时区基线校验 + 边界时间回放 |
| LOB 截断/损坏 | 文档打不开、长文本尾部丢 | 全量导入 | 长度分布 + 抽样导出文件校验 |
| 增量 checkpoint 设计不当 | 丢数、重复、乱序 | 增量同步、切换日 | 回放窗口 + 双条件断点(时间+主键) |
这张表想表达的就一件事:别把"对账"当成一个动作,它更像一套能重复跑的脚本集合。你不需要靠记忆和感觉去"觉得差不多了",而是让每一步都有输出、有证据。下面的实操也都按"复制到 ksql 就能跑"的思路来写。
3. 切换前先做基线:Windows + ksql 的三类自检
3.1 连接与会话基线
bash
ksql -h 127.0.0.1 -p 54321 -U system -d test进到 test=# 以后,我会先把"会话口径"钉死(后续所有对账都按同一口径来,不然容易各说各话):
sql
SELECT CURRENT_USER;
SELECT CURRENT_TIMESTAMP;
SHOW server_encoding;
SHOW client_encoding;
SHOW lc_collate;
SHOW lc_ctype;
SHOW timezone;
SHOW datestyle;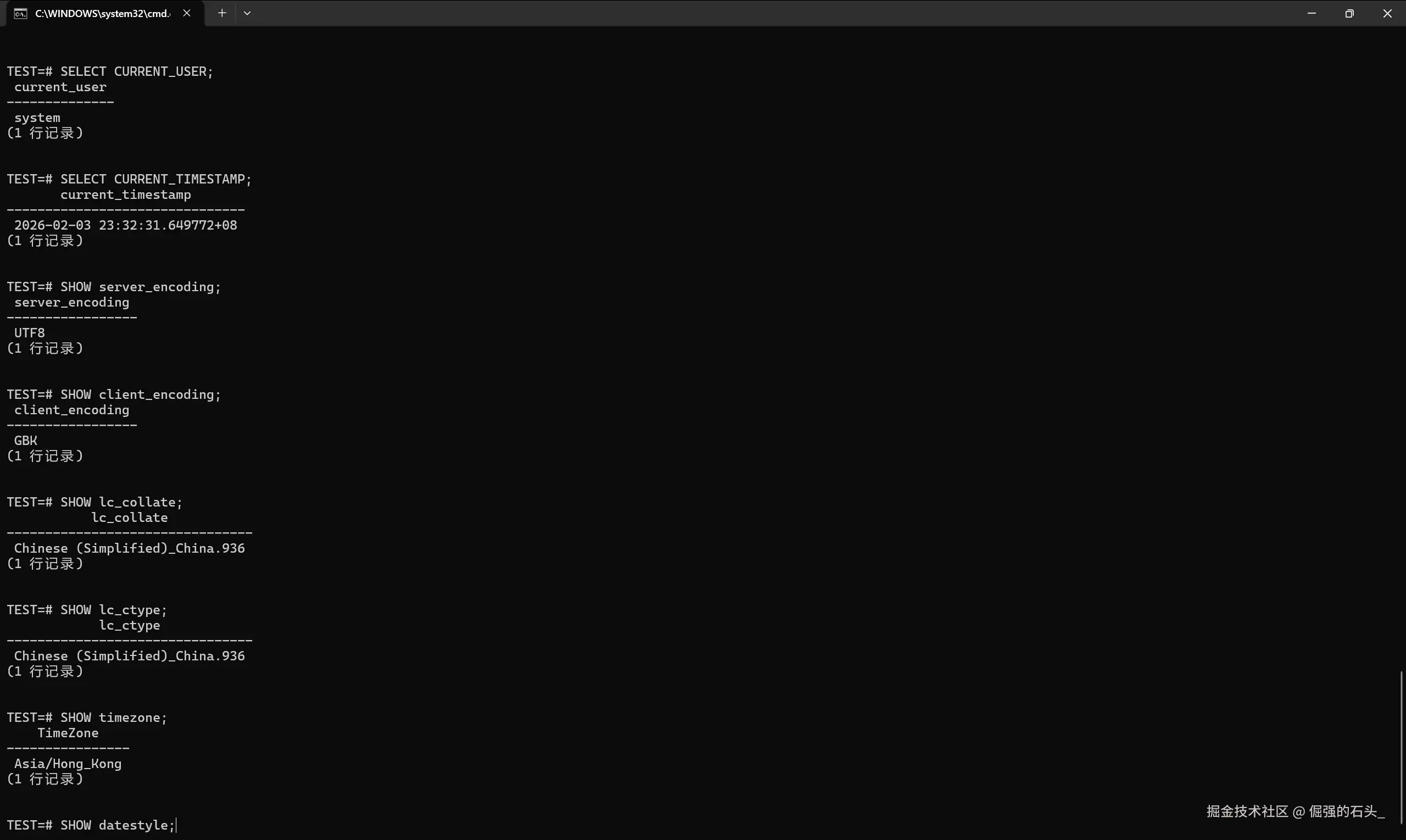
这段输出建议直接保存到迁移记录里。后面如果出现"怎么突然对不上"的情况,十有八九都能从这里找到线索:某个环节时区不一致、编码不一致、排序规则不一致,问题就会变得非常"玄学"。
3.2 给对账留一个落点:断点表与审计表
对账最怕的就是"人肉记断点"。我一般会在目标库里先放一张断点表:切换窗口、增量回放、出问题重跑,全靠它把流程拉回可控状态:
sql
CREATE TABLE IF NOT EXISTS mig_checkpoint (
job_name VARCHAR(50) PRIMARY KEY,
last_ts TIMESTAMP,
last_pk VARCHAR(200),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL
);如果你的主键是复合键也没关系,把 last_pk 存成一个可比较的拼接串就行(后面会给"时间 + 主键"的双条件断点写法)。
3.3 明确对账口径:哪些表必须"强一致"
我会先把表分三类,避免上来就把所有表按同一个标准"压死",最后把精力耗在不关键的地方:
- 强一致表:订单、资金、余额、库存这类表,切换日必须逐表核对到行级;
- 弱一致表:日志、行为、统计类表,允许在窗口内延迟补齐;
- 可重建表:缓存、索引、聚合中间表,允许重刷重算。
对账脚本先把强一致表覆盖住,先把最大的风险关掉,再谈扩面。
4. 全量导入后的"必做四件事":从快到慢逐层加码
下面以"目标库自检"为主来写。源端如果也能跑同口径 SQL,那就最省心:两边直接对输出;如果源端口径不方便统一,就把源端结果落文件,再做比对。
4.1 行数对账:先按时间/分区分段,再汇总
对账别一上来就 COUNT(*) 打到底。更稳的做法是"分段对账":先把范围切碎,一旦不一致,定位就会非常快------不用在全表里盲找:
sql
SELECT
TO_CHAR(order_time, 'YYYY-MM-DD') AS d,
COUNT(*) AS cnt
FROM t_order
WHERE order_time >= TO_TIMESTAMP('2026-02-01 00:00:00','YYYY-MM-DD HH24:MI:SS')
AND order_time < TO_TIMESTAMP('2026-03-01 00:00:00','YYYY-MM-DD HH24:MI:SS')
GROUP BY TO_CHAR(order_time, 'YYYY-MM-DD')
ORDER BY d;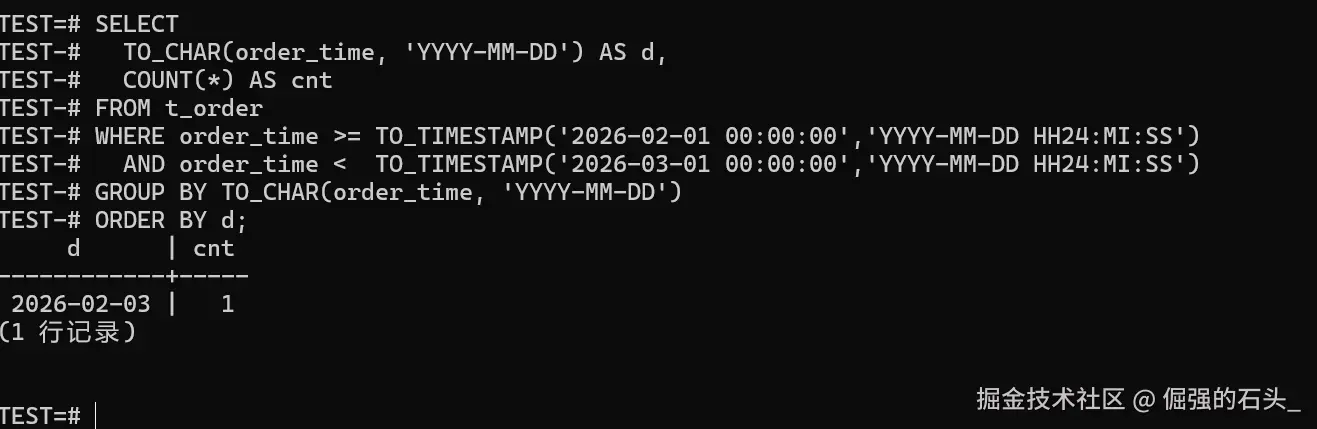
如果你按月/按天分区,这条 SQL 的输出就是最省心的"定位器":哪一天对不上,先把那一天的导入日志和增量回放盯住,效率会高很多。
4.2 主键完整性:空值、重复、异常增长
sql
SELECT COUNT(*) AS pk_null_cnt FROM t_order WHERE order_id IS NULL;
SELECT order_id, COUNT(*) AS dup_cnt
FROM t_order
GROUP BY order_id
HAVING COUNT(*) > 1
ORDER BY dup_cnt DESC;主键重复不一定会当场报错(取决于你导入时有没有先建约束、有没有做冲突处理),但它几乎一定会在后面变成"明细挂错主表""同一订单被覆盖"的隐性事故。
4.3 参照关系断链:找"孤儿行"
sql
SELECT COUNT(*) AS orphan_cnt
FROM t_order_item i
LEFT JOIN t_order o ON o.order_id = i.order_id
WHERE o.order_id IS NULL;如果外键是在导入后才启用的,这一步基本必做。出现断链通常就三种可能:导入顺序不对、导入失败重跑没跑全、或者增量回放漏了主表数据。
4.4 汇总一致性:用"多指标"降低漏检概率
只看一个指标很容易被"正好抵消"骗过(比如金额一增一减总和还不变)。我更喜欢用一个组合拳:数量、范围、时间边界、金额一起看,漏检概率会低很多:
sql
SELECT
COUNT(*) AS cnt,
MIN(order_id) AS min_id,
MAX(order_id) AS max_id,
MIN(order_time) AS min_time,
MAX(order_time) AS max_time,
SUM(total_amount) AS sum_amount
FROM t_order
WHERE order_time >= TO_TIMESTAMP('2026-02-01 00:00:00','YYYY-MM-DD HH24:MI:SS')
AND order_time < TO_TIMESTAMP('2026-03-01 00:00:00','YYYY-MM-DD HH24:MI:SS');如果还想再"硬核"一点,我会把窗口再切成很多段(比如 1000 段,按主键范围或时间范围都行),逐段输出到文件,再做两端比对。麻烦是麻烦点,但确定性很高。
5. 字符集与排序规则:不是"乱码才算问题"
字符集这类问题,最坑的往往不是"乱码",而是下面这种更隐蔽的差异:
- 同一个字符串在两端字节长度不同(尤其是包含表情、少数民族字符、特殊符号时);
- 比较与排序规则差异导致"同条件查询结果不一致"(比如某些大小写/全半角的比较行为)。
5.1 快速排查:字符长度 vs 字节长度分布
在 ksql 里执行时,只复制粘贴 SQL 本体就行,不要把 Markdown 的 sql / 也一起带进去。
下面用第 4 章出现过的 t_order.remark 做演示;你要检查别的业务表也很简单:把 t_order/remark 换成你自己的"文本列"就行。
sql
SELECT
COUNT(*) AS total_cnt,
SUM(CASE WHEN LENGTH(COALESCE(remark,'')) <> OCTET_LENGTH(COALESCE(remark,'')) THEN 1 ELSE 0 END) AS multibyte_cnt
FROM t_order;再抽几个"最容易出事"的样本(长度特别大、包含特殊字符的)出来,人工看一眼,心里会更踏实:
sql
SELECT order_id, remark, LENGTH(remark) AS char_len, OCTET_LENGTH(remark) AS byte_len
FROM t_order
WHERE remark IS NOT NULL
ORDER BY OCTET_LENGTH(remark) DESC
LIMIT 20;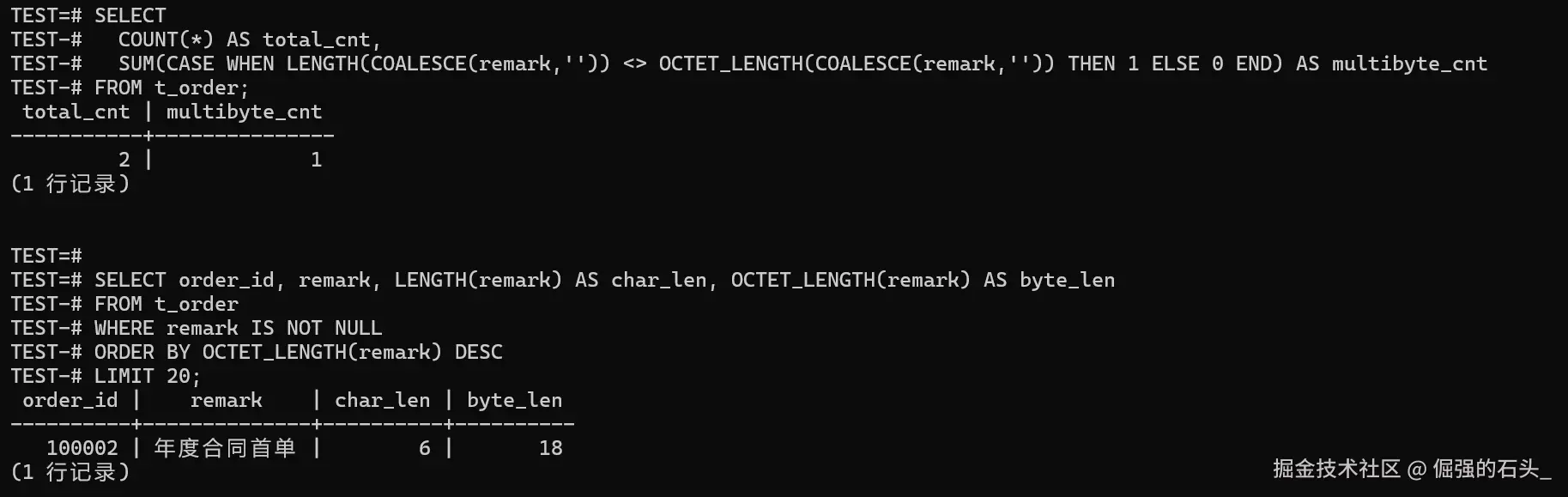
如果这里已经出现明显差异,我会优先回头核对 server_encoding/client_encoding/lc_collate/lc_ctype:抽取端、落地文件、导入端、应用连接端,任何一个环节不一致,都可能把问题"养大"。
6. 时间、时区与精度:一致性风险里最隐蔽的一类
时间字段的风险我一般按三层来拆:
- 时区:同一时刻显示不同;
- 格式:字符串解析口径不同;
- 精度:亚秒部分被截断或四舍五入,导致"同秒内顺序"改变。
6.1 用 ksql 固定时区口径并验证
sql
SHOW timezone;
SELECT CURRENT_TIMESTAMP;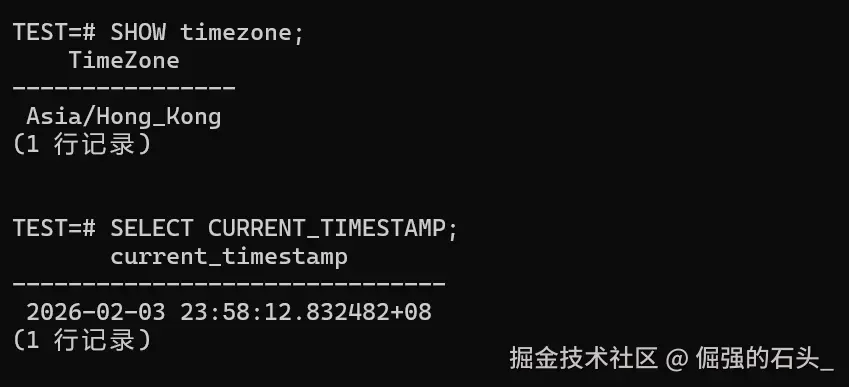
切换前我会把对账会话的时区固定住(你也可以在应用侧统一设置),然后拿同一批样例数据去验证"显示一致、计算一致"。这一步看起来啰嗦,但能省掉后面一大堆扯皮。
6.2 精度风险的定位方法:看"同秒内排序"是否稳定
做个极简测试就能看出很多问题:插入同一秒内不同亚秒的记录,然后按时间排序,看顺序是不是你以为的那样。
sql
DROP TABLE IF EXISTS t_ts_probe;
CREATE TABLE t_ts_probe(
id NUMBER(12,0) PRIMARY KEY,
ts TIMESTAMP NOT NULL
);
INSERT INTO t_ts_probe VALUES (1, TO_TIMESTAMP('2026-02-03 10:00:00.123456','YYYY-MM-DD HH24:MI:SS.FF'));
INSERT INTO t_ts_probe VALUES (2, TO_TIMESTAMP('2026-02-03 10:00:00.123457','YYYY-MM-DD HH24:MI:SS.FF'));
COMMIT;
SELECT id, TO_CHAR(ts,'YYYY-MM-DD HH24:MI:SS.FF6') AS ts_fmt
FROM t_ts_probe
ORDER BY ts;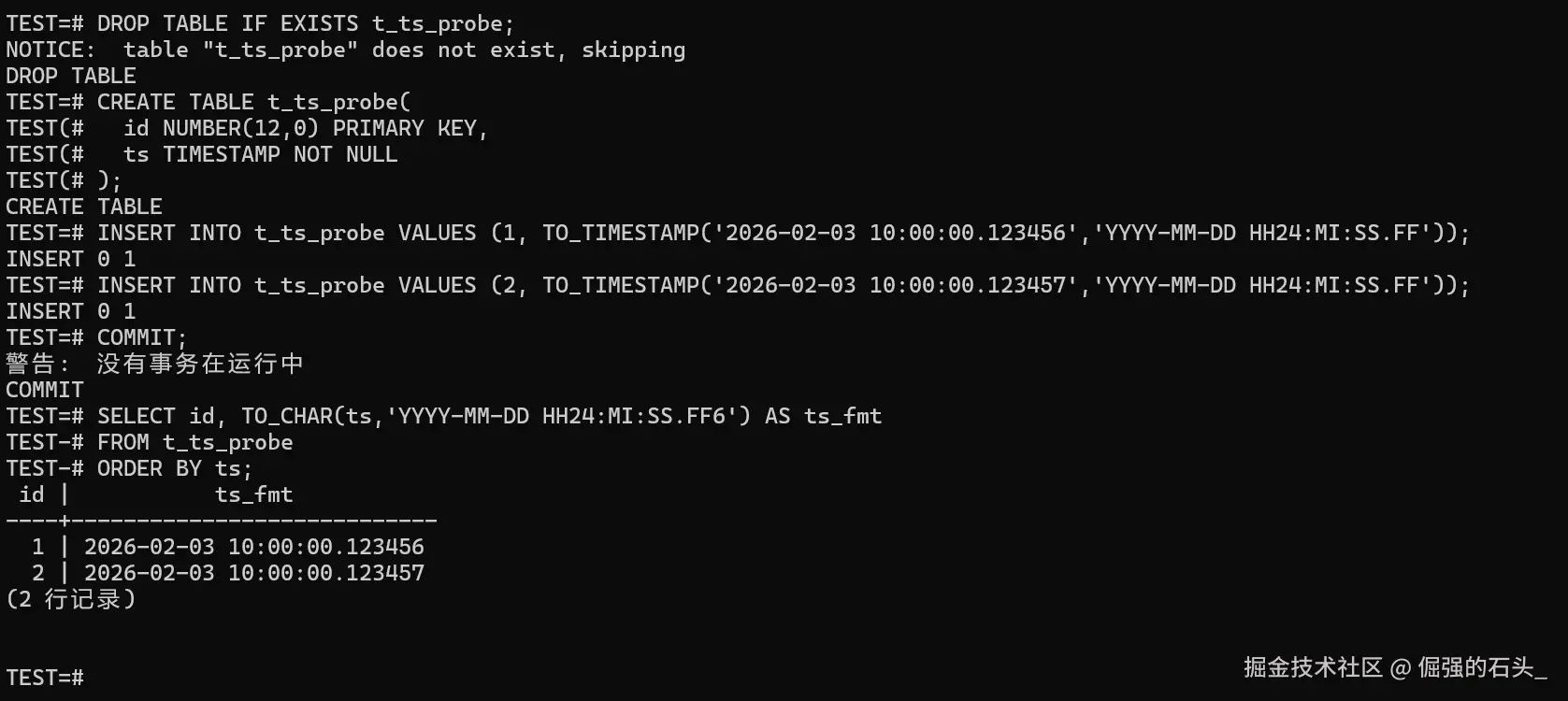
如果源端时间精度更高,而目标端只能落到更低精度,迁移阶段就得提前把策略定下来:是截断还是四舍五入?要不要把"原始时间串/原始刻度"额外落一列?不然到了审计、追责或者复盘的时候,很容易出现"解释不清的顺序差异"。
7. LOB(大对象):迁移"成功"不等于"可用"
LOB 的问题通常不是"有没有值",而是"值是不是还能用":
- 长文本尾部被截断(肉眼不容易发现);
- 二进制内容被编码转换破坏(文件打不开);
- 导入过程中发生分段丢失或拼接顺序错误。
7.1 先做分布检查:长度、空值、极端值
sql
SELECT
COUNT(*) AS total_cnt,
SUM(CASE WHEN doc IS NULL THEN 1 ELSE 0 END) AS null_cnt,
MIN(LENGTH(doc)) AS min_len,
MAX(LENGTH(doc)) AS max_len
FROM t_doc;再把"最长的那一批"抽出来人工验收一下(这一步经常能抓到截断问题):
sql
SELECT doc_id, LENGTH(doc) AS len
FROM t_doc
ORDER BY LENGTH(doc) DESC
LIMIT 20;7.2 抽样导出 + 文件哈希:在 Windows 上最直观
对关键文档/合同/附件这类数据,我更相信"导出到文件再比"。数据库里看一眼字段内容,很多时候并不能说明它真的可用。
在 ksql 里按业务主键抽样导出:
sql
\copy (SELECT doc_id, doc FROM t_doc WHERE doc_id IN (1001,1002,1003) ORDER BY doc_id) TO 'D:\\mig_check\\doc_sample.csv' WITH (FORMAT csv, DELIMITER E'\t', HEADER true)然后在 PowerShell 里计算文件哈希(同一批样本两端导出后比对哈希即可):
powershell
certutil -hashfile D:\mig_check\doc_sample.csv SHA256文件级校验的好处在于:它绕开了"看着差不多"的主观判断,把验证变成一条能复现、能留档的证据链。
8. 增量同步:checkpoint 设计不当会丢数,也会重复
增量同步里最常见的"坑中坑",就是只用一个时间字段当断点:
- 同一秒内多行变更,断点条件写成
>会丢行,写成>=会重复; - 时间字段精度不足或被截断,边界更容易错;
- 更新乱序(先写后补)导致"晚到的数据"被跳过。
8.1 推荐的断点口径:时间 + 主键双条件
更稳的做法是把断点拆成两部分:last_ts 和 last_pk。抽取条件按"时间优先、主键补齐"的思路来写:
sql
SELECT *
FROM t_order
WHERE order_time > :last_ts
OR (order_time = :last_ts AND order_id > :last_pk)
ORDER BY order_time, order_id;跑完一批以后,把最后一行的 order_time/order_id 写回 mig_checkpoint(实际项目里把 order_time 换成你的增量时间字段即可)。
8.2 回放窗口:用小成本换确定性
我基本不会让增量断点"刚好卡边界"。更稳的办法是做回放窗口:比如每次都回放最近 5 分钟的数据,目标端再用主键做幂等落库(同主键更新覆盖或合并)。
这么做的好处很直接:就算出现乱序或延迟写入,也能在下一轮被兜住。
切换日前,我会专门做一轮"边界压测",专打这些最容易翻车的场景:
- 连续制造同一秒内 1000 条变更;
- 制造跨分钟、跨小时的补写;
- 制造回滚再提交的重复变更;
- 验证目标端最终状态与源端一致。
9. 一张图:我常用的"切换日对账闭环"
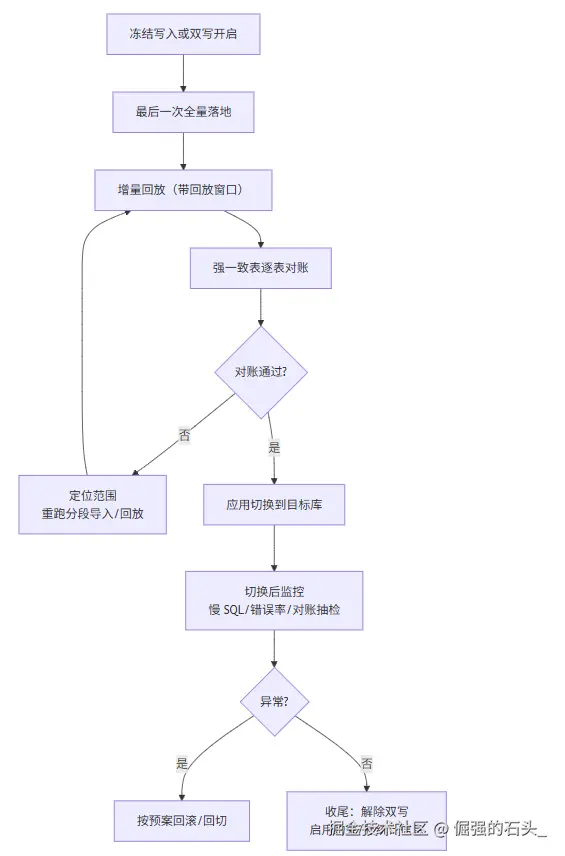
这套流程的重点不在"步骤多",而在于每一步都有可执行的验证输出:出了问题能定位、能重跑,实在不行还能回滚。
10. 验收清单
| 类别 | 必验项 | 通过标准(示例) |
|---|---|---|
| 会话基线 | 编码/排序规则/时区 | 迁移链路所有环节一致 |
| 行级完整性 | 分段行数对账 | 强一致表 100% 对齐 |
| 约束一致性 | 主键/唯一/外键 | 启用成功,孤儿行=0,重复=0 |
| 汇总一致性 | 多指标汇总 | cnt/min/max/sum 全一致 |
| LOB 可用性 | 抽样导出校验 | 文件可打开,哈希一致 |
| 增量可靠性 | checkpoint + 回放窗口 | 无丢数,无重复,最终态一致 |
| 切换可回滚 | 回滚路径可演练 | 回切脚本可执行、耗时可接受 |