1.使用正则完成下列内容的匹配
-
匹配陕西省区号 029-12345
-
匹配邮政编码 745100
-
匹配身份证号 62282519960504337X
代码如下:
python
import re
texts = {
"区号": "029-12345",
"邮编": "123456",
"邮箱": "llllll@xxhhyyzzzz.com",
"身份证": "222333222322211121"
}
patterns = {
"区号": r"029-\d{5}",
"邮编": r"\d{6}",
"邮箱": r".+@.+\..+",
"身份证": r"\d{17}X|\d{18}"
}
for name in texts:
result = re.search(patterns[name], texts[name])
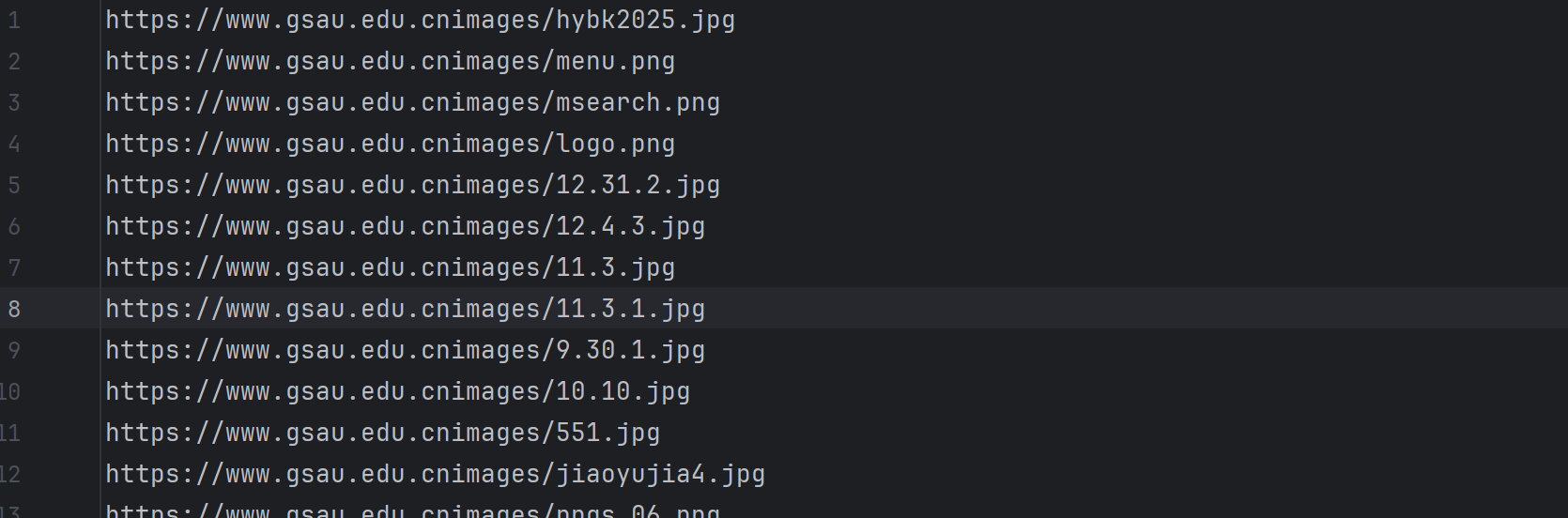
print(f"{name}: {result.group() if result else '没匹配到'}")运行结果如下:
2.爬取学校官网,获取所有图片途径并将路径存储在本地文件中,使用装饰器完成
代码如下:
python
import requests
import re
from functools import wraps
def save_to_file(filename):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
with open(filename, 'w', encoding='utf-8') as f:
for item in result:
f.write(item + '\n')
print(f"已保存 {len(result)} 条到 {filename}")
return result
return wrapper
return decorator
def safe_request(func):
@wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as e:
print(f"请求失败: {e}")
return ""
return wrapper
class Spider:
def __init__(self):
self.url = "https://www.gsau.edu.cn/"
self.headers = {'User-Agent': 'Mozilla/5.0'}
@safe_request
def fetch(self):
res = requests.get(self.url, headers=self.headers)
return res.text
@save_to_file(filename='images.txt')
def get_images(self):
html = self.fetch()
imgs = re.findall(r'<img[^>]+src="([^"]+)"', html)
full_urls = []
for img in imgs:
if img.startswith('http'):
full_urls.append(img)
else:
full_urls.append("https://www.gsau.edu.cn" + img)
return full_urls
spider = Spider()
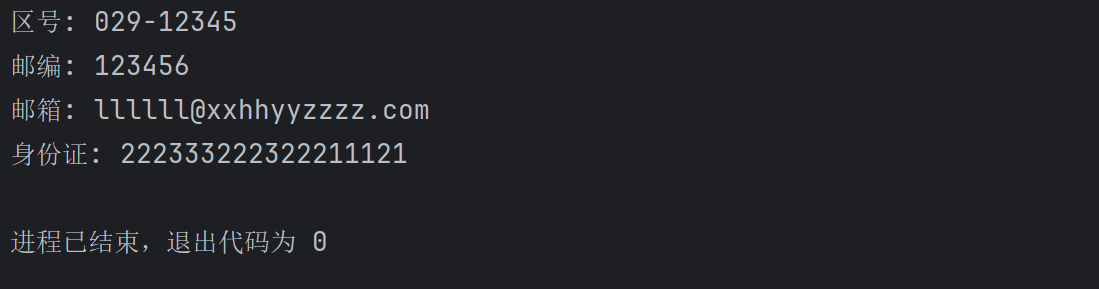
spider.get_images()运行结果如下: